
Curso
Manipulación de datos en SQL
4 h
324.1K
¿Te has fijado en que MySQL aparece como requisito en casi todas las ofertas relacionadas con bases de datos? Tiene su lógica: MySQL impulsa desde tus redes sociales favoritas hasta muchas de las apps que usas a diario.
He preparado esta guía para ayudarte a afrontar preguntas de entrevista sobre MySQL. Veremos desde lo básico que debería dominar cualquier perfil junior hasta aspectos más complejos para roles senior. Además, compartiré algunos trucos para que te presentes como una persona segura en tus próximas entrevistas relacionadas con datos.
MySQL es un SGBDR (sistema de gestión de bases de datos relacionales) de código abierto basado en SQL que organiza los datos en tablas estructuradas. Fue desarrollado por Oracle Corporation.
Fue el SGBD de código abierto más popular en 2024. Sin embargo, la encuesta de desarrolladores de Stack Overflow en 2025 mostró que PostgreSQL pasó a ser la base de datos más utilizada entre desarrolladores profesionales, superando por primera vez a MySQL.
Que no te lleve a engaño: MySQL sigue siendo enormemente popular — con un 40,5% de uso entre desarrolladores en 2025 — y continúa alimentando infinidad de aplicaciones web, gestores de contenidos y herramientas empresariales. Y, especialmente si trabajas con aplicaciones web o con el stack LAMP, MySQL es una competencia de primer nivel.
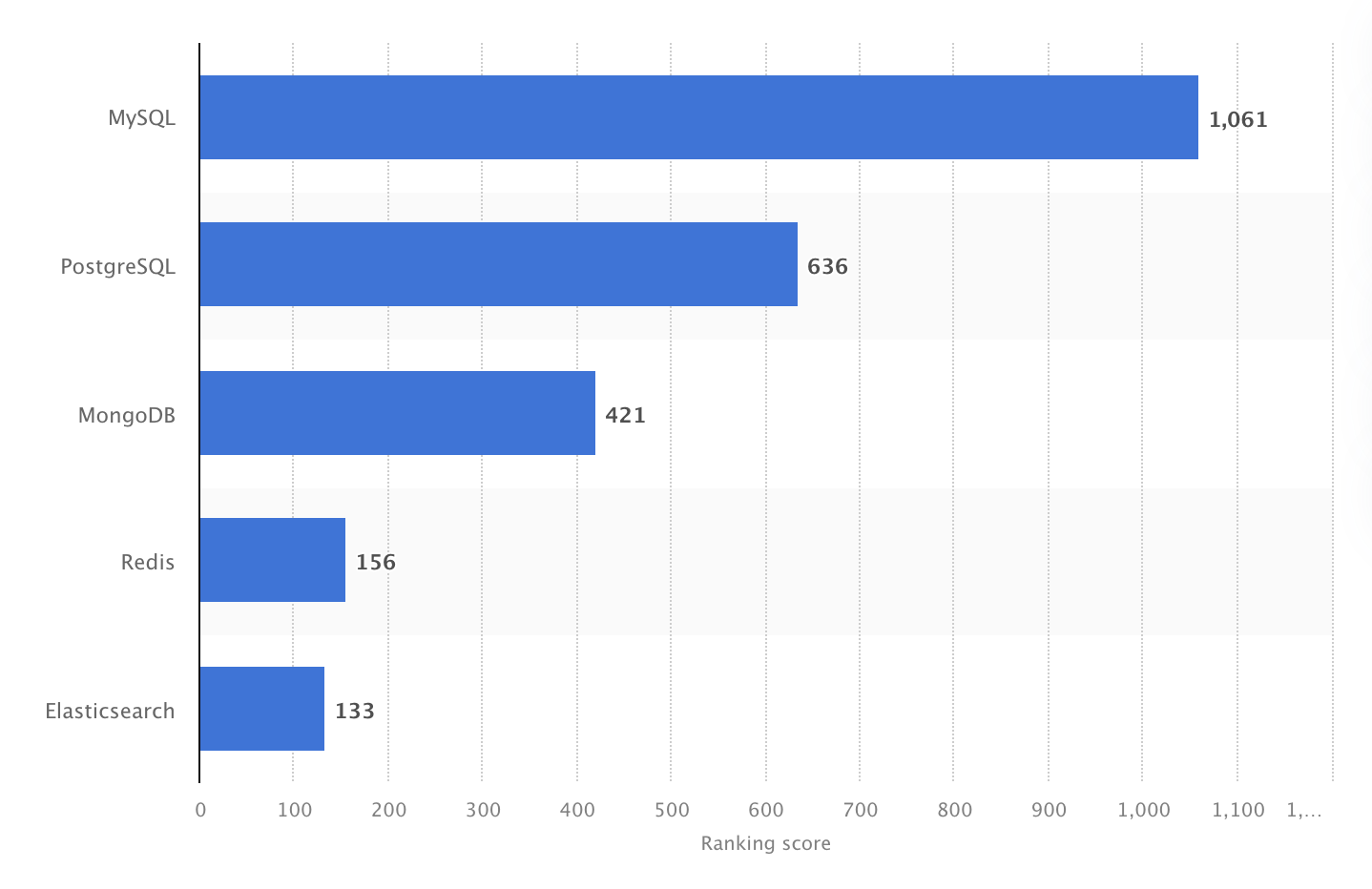
En 2024, MySQL fue el SGBD de código abierto más popular del mundo, con una puntuación de 1061. Fuente: Statista.
En la fase inicial de la entrevista, es habitual que te pregunten conceptos fundamentales para evaluar tu entendimiento de las bases de datos y de MySQL.
Una base de datos es un contenedor donde almacenamos datos a los que podemos acceder, modificar y analizar. Por ejemplo, las redes sociales guardan en bases de datos quién ha dado like a nuestras publicaciones.
Un SGBD (sistema de gestión de bases de datos) es el software que nos permite interactuar con esos datos y administrarlos, por ejemplo, creando usuarios y gestionando sus permisos. MySQL es uno de los SGBD más populares. Otros ejemplos incluyen PostgreSQL, MongoDB y Microsoft SQL Server.
MySQL es un SGBDR de código abierto que usa SQL para gestionar datos. Es conocido por su facilidad de uso, rapidez y compatibilidad con aplicaciones web.
Así se diferencia de otros SGBDR:
MySQL es ideal cuando necesitas velocidad y escalabilidad; para requisitos más complejos o de nivel corporativo, PostgreSQL puede ser mejor elección.
MySQL admite varios tipos de datos, agrupados en:
Numéricos: INT, DECIMAL, FLOAT, DOUBLE, etc.
Cadena: CHAR, VARCHAR, TEXT, BLOB.
Fecha/hora: DATE, DATETIME, TIMESTAMP, TIME.
JSON: para almacenar objetos JSON.
INT almacena números enteros, sin decimales. Úsalo cuando no necesitas fracciones. En cambio, DECIMAL puede almacenar valores financieros y es adecuado para cálculos con decimales de forma precisa.
La columna DATE en MySQL almacena la fecha en formato de año, mes y día:
YYYY-MM-DD
Por su parte, DATETIME guarda fecha y hora con este formato:
YYYY-MM-DD HH:MM:SS
Una clave foránea es un campo de una tabla que enlaza con la clave primaria de otra.
Por ejemplo, en una tabla customers que almacena información de clientes, cada cliente tiene un customer_id único; en otra tabla llamada transactions (que guarda compras), usamos customer_id como clave foránea. El customer_id en transactions vincula cada compra con un cliente concreto en la tabla customers .
Así se vería en SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Los joins combinan filas de dos o más tablas en base a columnas relacionadas. Diferencias:
INNER JOIN: devuelve filas con coincidencia en ambas tablas.
LEFT JOIN: devuelve todas las filas de la tabla izquierda y las coincidentes de la derecha. Si no hay coincidencia, las columnas de la derecha van como NULL.
RIGHT JOIN: similar a LEFT JOIN, devuelve todas las filas de la derecha y las coincidentes de la izquierda.
FULL JOIN: combina los resultados de LEFT JOIN y RIGHT JOIN, incluyendo filas sin coincidencia de ambas tablas. Nota: MySQL no admite de forma nativa la sintaxis FULL JOIN. Para lograr el mismo resultado, usa un UNION de un LEFT JOIN y un RIGHT JOIN
Comandos como DELETE, TRUNCATE y DROP pueden sonar parecidos, pero se comportan de forma distinta:
DELETE: elimina filas de una tabla según una condición. Se puede deshacer si está dentro de una transacción. Ejemplo:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: borra todas las filas de una tabla, pero mantiene su estructura. Es más rápido que DELETE y no se puede deshacer. Ejemplo:
TRUNCATE TABLE employees;DROP: elimina por completo la tabla y sus datos, junto con dependencias como índices. Ejemplo:
DROP TABLE employees;Para crear tablas, usa CREATE TABLE y, para modificarlas, normalmente ALTER TABLE. Ejemplos:
Crear tabla:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Añadir una columna:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Una tabla temporal solo existe durante la sesión actual. Al cerrar la sesión, se elimina. Sirve para guardar resultados intermedios temporalmente. Puedes usarla para pruebas, filtrado o preparar datos antes de insertarlos en una tabla permanente.
Ejemplo:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;Una subconsulta (o consulta anidada) va dentro de otra consulta. Permite descomponer operaciones complejas en pasos manejables. Por ejemplo, para encontrar empleados que cobran por encima de la media:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Desglose:
La consulta interna SELECT AVG(salary) FROM employees calcula primero el salario medio.
La externa usa esa media para encontrar quienes cobran por encima.
Usamos INSERT para añadir datos. Sintaxis básica:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Buenas prácticas:
Indica explícitamente las columnas: el código es más claro y evita errores si cambia el esquema.
En columnas AUTO_INCREMENT como IDs, omítelas en el INSERT: MySQL las gestiona y evitas duplicados.
Sé consistente con las comillas de cadenas. Yo prefiero comillas simples, pero ambas opciones valen.
Para varias filas, insértalas en una sola sentencia por rendimiento.
AUTO_INCREMENT genera números únicos y secuenciales para una columna, normalmente la clave primaria.
Ejemplo de tabla con AUTO_INCREMENT:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);E inserción de filas:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');Una vista es una consulta guardada que funciona como una tabla virtual. Te permite dar nombre a una consulta compleja y reutilizarla como si fuera una tabla. Así evitas reescribirla cada vez.
Por ejemplo, para simplificar el acceso a datos de empleados con su departamento, puedes crear una vista:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Ahora puedes consultar employee_details como si fuera una tabla:
SELECT * FROM employee_details;Eso sí, en general las vistas son de solo lectura y no se usan para insertar o actualizar. Además, pueden ralentizar si cada acceso ejecuta la consulta subyacente.
¡Sigue aprendiendo SQL con estos cursos!
Curso
Curso
Curso
blog
Elena Kosourova
15 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Josep Ferrer
15 min
blog
Javier Canales Luna
15 min

