
Cours
Manipulation de données en SQL
4 h
324.9K
Vous avez sans doute remarqué que MySQL apparaît dans quasiment toutes les fiches de poste liées aux bases de données. Et pour cause : MySQL fait tourner une multitude de services, des réseaux sociaux que vous consultez aux applications que vous utilisez au quotidien.
J'ai réuni dans ce guide les questions d'entretien MySQL les plus fréquentes. Nous passerons en revue l'essentiel — des notions que tout junior doit maîtriser — jusqu'aux sujets plus avancés attendus sur des postes seniors. Je partagerai également des conseils pour vous présenter en candidat(e) sûr(e) de soi lors de vos prochains entretiens autour de la donnée.
MySQL est un SGBDR open source (système de gestion de bases de données relationnelles) fondé sur SQL, qui organise les données en tables structurées. Il est développé par Oracle Corporation.
Il s'est classé comme le SGBD open source le plus populaire en 2024. Cependant, l'enquête Stack Overflow Developer de 2025 a montré que PostgreSQL est devenu la base la plus utilisée par les développeurs professionnels, dépassant MySQL pour la première fois.
Cela ne veut pas dire que MySQL a perdu de sa superbe : il reste extrêmement populaire — 40,5 % d'utilisation chez les développeurs en 2025 — et alimente toujours d'innombrables applications web, CMS et outils d'entreprise. Et si vous travaillez sur des applications web ou la pile LAMP, MySQL demeure une compétence de premier plan.
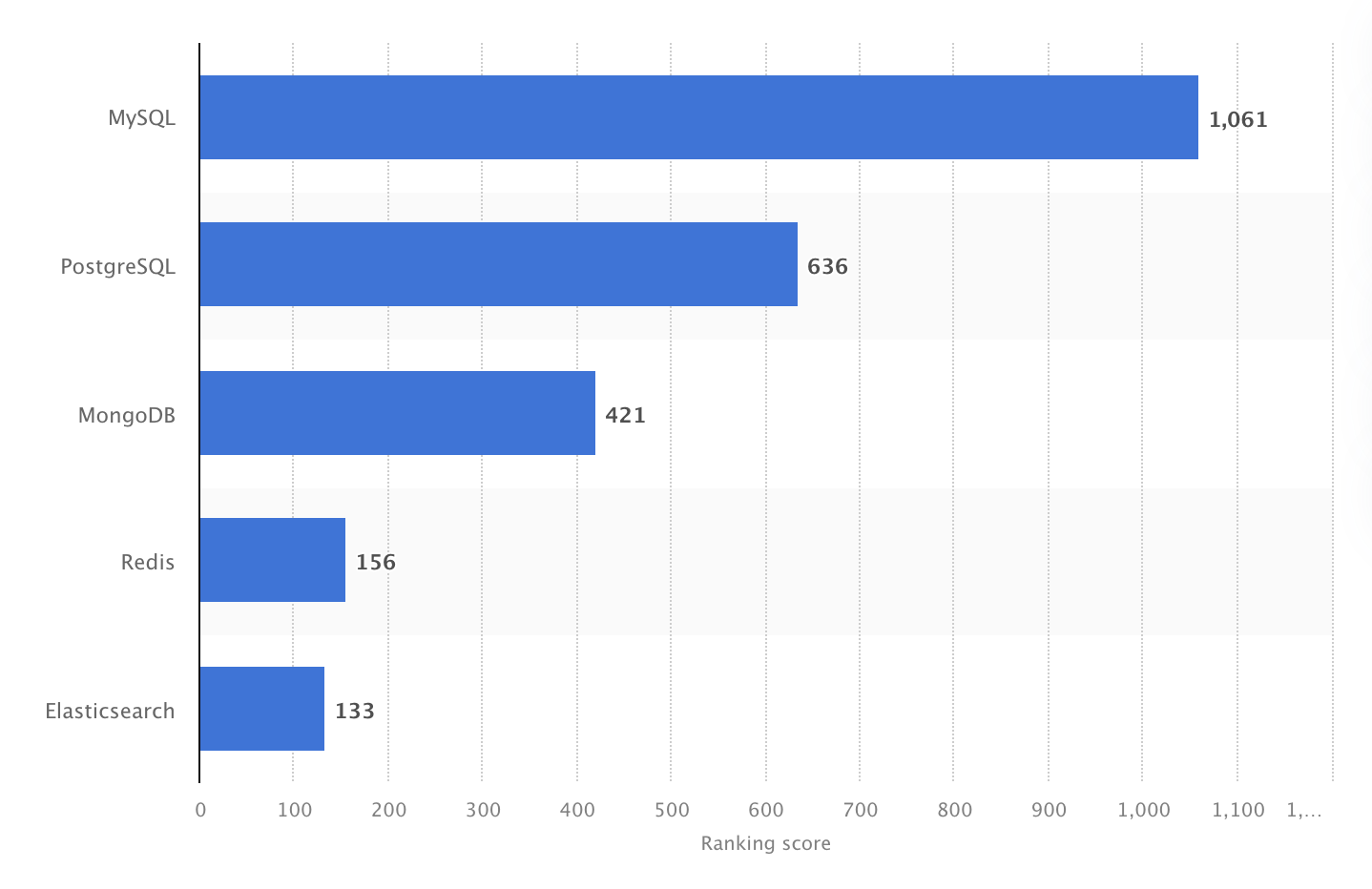
En 2024, MySQL était le SGBD open source le plus populaire au monde, avec un score de 1061. Source : Statista.
Lors des premiers échanges, l'intervieweur peut poser des questions fondamentales pour évaluer votre compréhension des concepts de base des bases de données et de MySQL.
Une base de données est un conteneur de stockage qui conserve des données auxquelles on peut accéder, que l'on peut modifier et analyser. Par exemple, les plateformes sociales stockent dans des bases de données qui a aimé nos publications.
Un SGBD (Système de gestion de base de données) est le logiciel qui permet d'interagir avec ces données et de les administrer, par exemple en créant des utilisateurs et en gérant leurs droits. MySQL est l'un des SGBD les plus populaires. D'autres exemples incluent PostgreSQL, MongoDB, et Microsoft SQL Server.
MySQL est un SGBDR open source qui utilise SQL pour gérer les données. Il est réputé pour sa simplicité, sa rapidité et sa compatibilité avec les applications web.
Voici en quoi MySQL se distingue :
MySQL est idéal pour les scénarios nécessitant vitesse et montée en charge. Pour des besoins plus complexes et des fonctionnalités "entreprise", PostgreSQL peut être un meilleur choix.
MySQL prend en charge une variété de types de données, regroupés en :
Numériques : INT, DECIMAL, FLOAT, DOUBLE, etc.
Chaînes : CHAR, VARCHAR, TEXT, BLOB.
Date/heure : DATE, DATETIME, TIMESTAMP, TIME.
JSON : pour stocker des objets JSON.
INT stocke des nombres entiers sans décimales. On l'utilise lorsqu'il n'y a pas besoin de fractions. À l'inverse, DECIMAL permet de stocker des valeurs financières et convient aux calculs précis avec décimales.
Le type DATE dans MySQL stocke une date au format année, mois, jour :
YYYY-MM-DD
Le type DATETIME stocke la date avec l'heure, au format :
YYYY-MM-DD HH:MM:SS
Une clé étrangère est un champ d'une table qui fait référence à la clé primaire d'une autre table.
Par exemple, dans une table customers qui stocke les informations clients, chaque client a un customer_id unique. Dans une autre table appelée transactions (qui enregistre les achats), on utilise customer_id comme clé étrangère. Le customer_id de la table transactions lie chaque achat à un client précis de la table customers .
Voici à quoi cela ressemble en SQL :
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Les jointures combinent des lignes de deux tables ou plus à partir de colonnes liées. Leurs différences :
INNER JOIN : retourne uniquement les lignes ayant une correspondance dans les deux tables.
LEFT JOIN : retourne toutes les lignes de la table de gauche et les lignes correspondantes de la table de droite. S'il n'y a pas de correspondance, les colonnes de la table de droite valent NULL.
RIGHT JOIN : similaire au LEFT JOIN, mais retourne toutes les lignes de la table de droite et les correspondances de la gauche.
FULL JOIN : combine les résultats de LEFT JOIN et RIGHT JOIN, en incluant les lignes sans correspondance des deux côtés. Remarque : MySQL ne prend pas en charge nativement la syntaxe FULL JOIN. Pour obtenir le même résultat, utilisez un UNION d'un LEFT JOIN et d'un RIGHT JOIN
Les commandes DELETE, TRUNCATE et DROP peuvent paraître similaires, mais leur comportement diffère :
DELETE : supprime des lignes d'une table selon une condition. Peut être annulé si exécuté dans une transaction. Exemple :
DELETE FROM employees WHERE department_id = 5;TRUNCATE : supprime toutes les lignes d'une table, mais la structure reste intacte. Plus rapide que DELETE et non annulable. Exemple :
TRUNCATE TABLE employees;DROP : supprime complètement la table (structure et données), ainsi que ses dépendances (index, etc.). Exemple :
DROP TABLE employees;Pour créer des tables, utilisez l'instruction CREATE TABLE, et pour les modifier, le plus souvent ALTER TABLE. Exemples :
Création de table :
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Ajout d'une colonne :
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Une table temporaire n'existe que pendant la session en cours. Une fois la session fermée, la table est supprimée. Elle sert à stocker des résultats intermédiaires, par exemple pour tester, filtrer ou préparer des données avant de les insérer dans une table permanente.
Exemple :
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;Une sous-requête (ou requête imbriquée) est une requête incluse dans une autre. Elle permet de décomposer des opérations complexes en étapes plus simples. Par exemple, pour trouver les employés gagnant au-dessus de la moyenne :
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Décomposition :
La requête interne SELECT AVG(salary) FROM employees calcule d'abord le salaire moyen.
La requête externe utilise ensuite cette moyenne pour trouver les employés qui la dépassent.
On utilise l'instruction INSERT pour ajouter des données. La syntaxe de base :
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Quelques bonnes pratiques à suivre avec INSERT :
Lister explicitement les colonnes. Le code est plus clair et reste robuste si la structure évolue.
Pour les colonnes AUTO_INCREMENT (comme les IDs), ne pas les inclure dans l'INSERT. MySQL les gère pour éviter les doublons.
Être cohérent dans l'usage des guillemets pour les chaînes. Les simples quotes sont souvent préférées, mais les deux fonctionnent.
Pour insérer plusieurs lignes, privilégier une seule instruction pour de meilleures performances.
L'attribut AUTO_INCREMENT génère des nombres uniques et séquentiels pour une colonne, en général la clé primaire.
Exemple de création d'une table avec une colonne AUTO_INCREMENT :
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);Et insertion de lignes :
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');Une vue est une requête enregistrée qui se comporte comme une table virtuelle. Elle permet d'encapsuler une requête complexe sous un nom et de la réutiliser comme une table. Ainsi, vous n'avez pas à retaper la requête entière à chaque fois.
Par exemple, pour simplifier l'interrogation des employés avec le nom de leur service, vous pouvez créer une vue :
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Vous pouvez ensuite interroger la vue employee_details comme une table :
SELECT * FROM employee_details;En revanche, l'insertion et la mise à jour via des vues sont limitées. La plupart sont en lecture seule et masquent l'accès direct aux tables, renforçant ainsi la sécurité. Les vues peuvent aussi ralentir certaines requêtes, car la requête sous-jacente est exécutée à chaque accès.
Apprenez-en plus sur SQL avec ces cours !
Cours
Cours
Cours
blog
Zoumana Keita
15 min
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
Tutoriel
Kurtis Pykes
Tutoriel
