
Course
Data Manipulation in SQL
4 hr
324.1K
Have you ever noticed that MySQL is required in almost every database-related job description? There's a good reason for that — MySQL pretty much powers everything from your favorite social media platforms to the apps you use daily.
I've put together this guide to help you tackle MySQL interview questions. I'll cover all the bases, from the basics that junior developers should know to the complex stuff that senior roles require. Also, I'll share some tips to help you appear as a confident candidate in your next data-related interviews.
MySQL is an open-source RDBMS (relational database management system) built on SQL that organizes data into structured tables. It was developed by Oracle Corporation.
It ranked as the most popular DBMS in 2024. However, a Stack Overflow Developer Survey in 2025 showed that PostgreSQL ranked as the most widely used database among professional developers, overtaking MySQL for the first time.
Don't get me wrong: MySQL ist still enormously popular — reaching 40.5% usage among developers in 2025 — and still powers countless web applications, content management systems, and enterprise tools. And especially if you're working with web applications or the LAMP stack, MySQL is a top-tier skill to have.
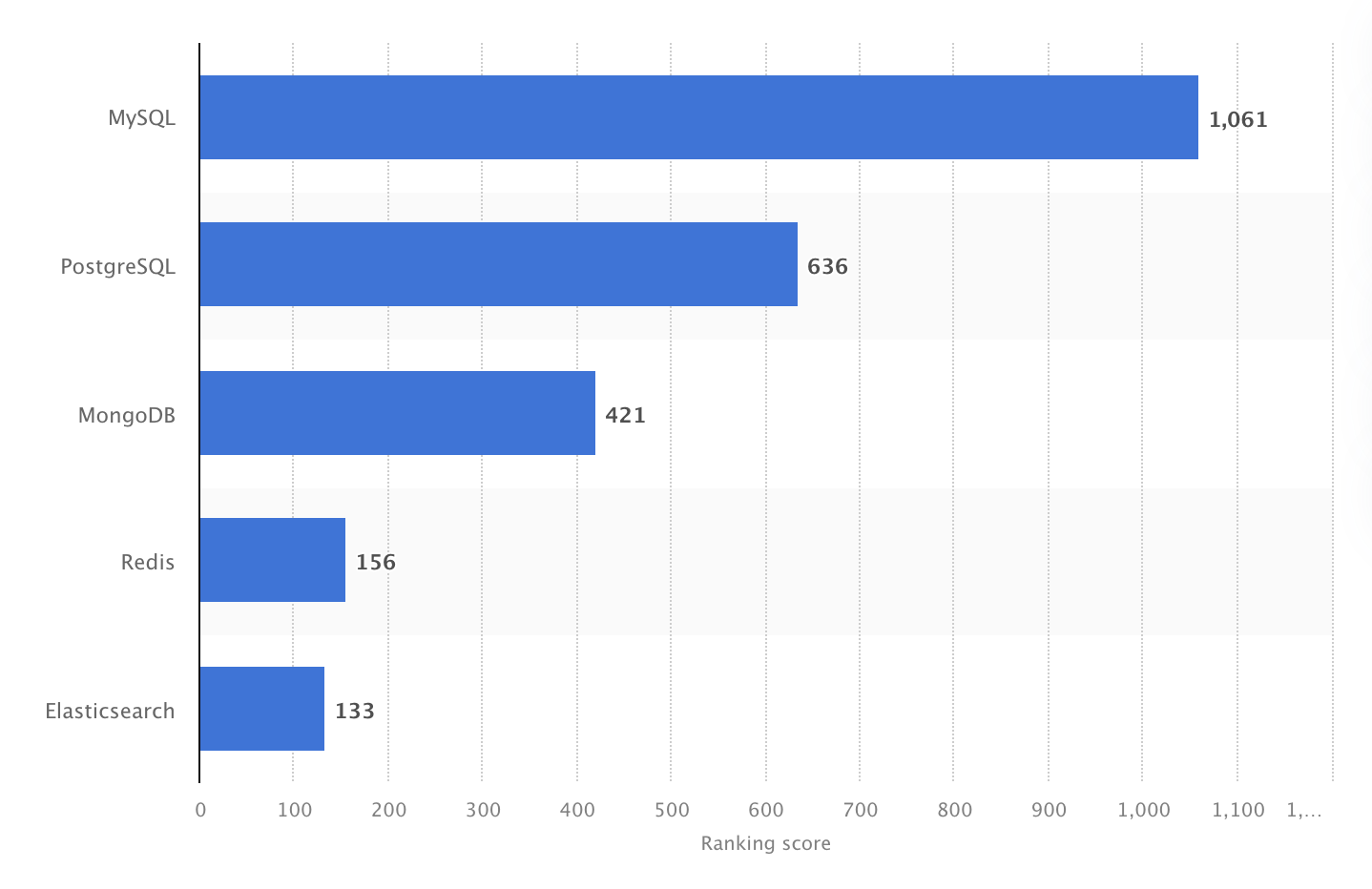
In 2024, MySQL was the world's most popular open-source DBMS, with a ranking score of 1061. Source: Statista.
In the initial interview phase, the interviewer can ask foundational questions to assess your understanding of basic database and MySQL concepts.
A database is a storage container that holds data we can access, modify, and analyze. For example, social media platforms store data about who liked our posts in databases.
A DBMS (Database Management System) is the software that lets us interact with and manage that data by creating users and managing their access. MySQL is one of the most popular DBMS options. Other examples include PostgreSQL, MongoDB, and Microsoft SQL Server.
MySQL is an open-source relational database management system (RDBMS) that uses SQL to manage data. It’s known for its ease of use, speed, and compatibility with web-based applications.
Here’s how MySQL differs from other RDBMSs:
MySQL is ideal for scenarios requiring speed and scalability, but for more complex or enterprise-grade features, PostgreSQL might be a better choice.
MySQL supports a variety of data types categorized as:
Numeric: INT, DECIMAL, FLOAT, DOUBLE, etc.
String: CHAR, VARCHAR, TEXT, BLOB.
Date/time: DATE, DATETIME, TIMESTAMP, TIME.
JSON: For storing JSON objects.
INT stores whole numbers with no decimal points. We can use it if there is no need for fractions. On the contrary, DECIMAL can store financial values and is suitable for precise calculations with decimals.
The DATE function in MySQL stores the date in year, month, and day format:
YYYY-MM-DD
However, the DATETIME function stores the date with the time, and it looks like this:
YYYY-MM-DD HH:MM:SS
A foreign key is a field in one table that links to the primary key of another table.
For example, in a customers table that stores customer information, each customer has a unique customer_id—in another table called transactions (which stores purchase records), we use customer_id as a foreign key. The customer_id in the transactions table will link each purchase to a specific customer in the customers table.
Here’s how that looks in SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Joins combine rows from two or more tables based on related columns. Here are their differences:
INNER JOIN: Returns rows where there is a match in both tables.
LEFT JOIN: Returns all rows from the left table and matching rows from the right table. If there’s no match, NULL is returned for the right table's columns.
RIGHT JOIN: Similar to LEFT JOIN, it returns all rows from the right table and matching rows from the left.
FULL JOIN: Combines the LEFT JOIN and RIGHT JOIN results, including unmatched rows from both tables. Note: MySQL does not natively support FULL JOIN syntax. To achieve the same result, use a UNION of a LEFT JOIN and a RIGHT JOIN
Commands like DELETE, TRUNCATE, and DROP may sound similar, but they actually have different behavior:
DELETE: Removes rows from a table based on a condition. It can be rolled back if inside a transaction. Example:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: Deletes all rows from a table, but the table structure remains intact. It is faster than DELETE and cannot be rolled back. Example:
TRUNCATE TABLE employees;DROP: Completely removes the table structure and data, along with any dependencies like indexes. Example:
DROP TABLE employees;For creating tables, you can use the CREATE TABLE statement, and for modifying, usually the ALTER TABLE. Here are some examples:
Create table:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Modify to add a column:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);A temporary table only exists during the current database session. Once we close the session, the table is deleted. This type of table can temporarily store intermediate results. We can use it for testing, filtering, or preparing data before inserting it into a permanent table.
Here’s an example:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;A subquery (also known as a nested query) is nested inside another query. It breaks down complex database operations into more manageable steps. For example, you can create a subquery to find employees earning above the average pay:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Let's break this down:
The inner query SELECT AVG(salary) FROM employees calculates the average salary first.
The outer query then uses this average to find employees who earn above it.
We can use the INSERT statement to add data to a table. The basic syntax is:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Here are a few best practices to follow when using the INSERT statement
Explicitly list your columns. This makes the code clearer and prevents errors if the table structure changes later.
For AUTO_INCREMENT columns like IDs, skip them in the INSERT statement. MySQL handles these automatically to prevent duplicate IDs.
Be consistent with string quotes. I personally prefer single quotes, but either works.
If you're inserting multiple rows, you can do it in a single statement for better performance.
The AUTO_INCREMENT attribute in MySQL generates unique, sequential numbers for a column, typically the primary key of a table.
Here’s an example of how to create a table with an AUTO_INCREMENT column:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);And to insert rows into it:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');A view is a saved query that works like a virtual table. With this, we can take a complex query, give it a name, and use it like a table for future queries. This way, you don’t have to retype the entire query every time.
For example, to simplify querying employee details along with their department names, you can create a view:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;You can now query the employee_details view just like a table:
SELECT * FROM employee_details;However, we cannot use views to insert and update the data. Most support the read-only option and prevent users from accessing the database, enhancing data security. Views can sometimes slow down queries, as they run the underlying query every time they are accessed.
Learn more about SQL with these courses!
Course
Course
Course
blog
Dario Radečić
15 min
blog
Elena Kosourova
15 min
blog
Kurtis Pykes
15 min
blog
Kevin Babitz
14 min
blog
Srujana Maddula
12 min
blog
Josep Ferrer
14 min