
Curso
Manipulação de dados em SQL
4 h
324.9K
Já reparou que MySQL aparece em praticamente toda descrição de vaga ligada a bancos de dados? Não é à toa — o MySQL está por trás de tudo, das suas redes sociais favoritas aos apps que você usa no dia a dia.
Preparei este guia para ajudar você a mandar bem nas perguntas de entrevista sobre MySQL. Vou cobrir do básico, que todo júnior precisa saber, até tópicos mais avançados exigidos em posições sênior. Também compartilho dicas para você se apresentar com confiança nas próximas entrevistas na área de dados.
MySQL é um SGBDR (sistema de gerenciamento de banco de dados relacional) open source, baseado em SQL, que organiza dados em tabelas estruturadas. Ele é desenvolvido pela Oracle Corporation.
Ele ficou em primeiro lugar como o DBMS open source mais popular em 2024. Porém, a pesquisa Stack Overflow Developer Survey de 2025 mostrou que o PostgreSQL passou a ser o banco de dados mais usado entre desenvolvedores profissionais, superando o MySQL pela primeira vez.
Mas não se engane: o MySQL continua extremamente popular — com 40,5% de uso entre desenvolvedores em 2025 — e ainda alimenta incontáveis aplicações web, sistemas de gestão de conteúdo e ferramentas corporativas. Especialmente se você trabalha com aplicações web ou com o stack LAMP, MySQL é uma habilidade de altíssimo valor.
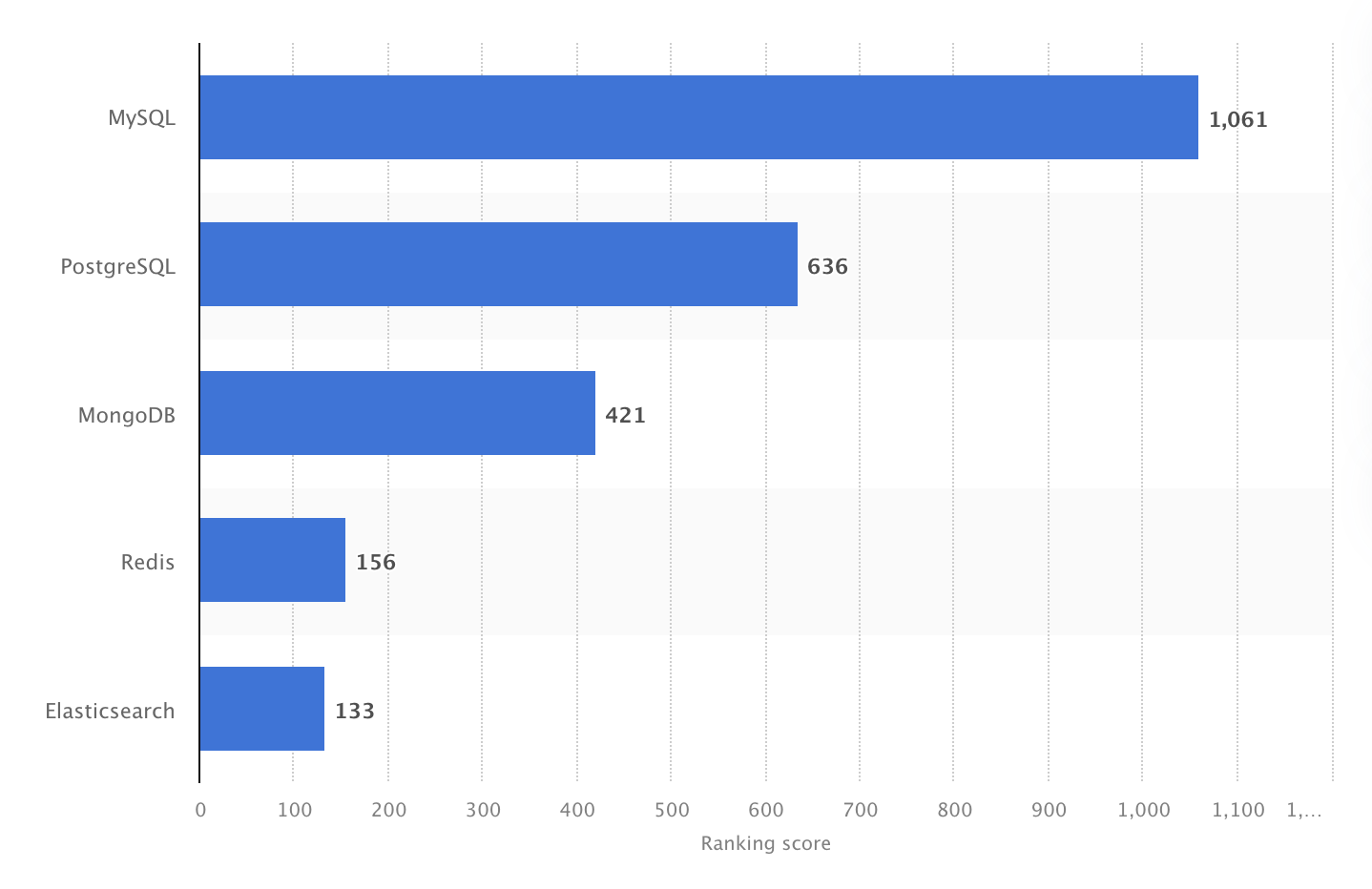
Em 2024, o MySQL foi o DBMS open source mais popular do mundo, com pontuação 1061. Fonte: Statista.
Na fase inicial da entrevista, o recrutador costuma fazer perguntas fundamentais para avaliar seu entendimento de conceitos básicos de banco de dados e de MySQL.
Um banco de dados é um repositório que armazena dados aos quais podemos acessar, modificar e analisar. Por exemplo, redes sociais guardam quem curtiu nossos posts em bancos de dados.
Um SGBD (Sistema de Gerenciamento de Banco de Dados) é o software que permite interagir e gerenciar esses dados, criando usuários e controlando acessos. MySQL é um dos SGBDs mais populares. Outros exemplos incluem PostgreSQL, MongoDB e Microsoft SQL Server.
MySQL é um SGBDR open source que usa SQL para gerenciar dados. Ele é conhecido por sua facilidade de uso, velocidade e alta compatibilidade com aplicações web.
Veja como o MySQL se diferencia de outros SGBDRs:
MySQL é ideal para cenários que exigem velocidade e escalabilidade; já para recursos mais complexos e corporativos, o PostgreSQL pode ser a melhor escolha.
O MySQL oferece diversos tipos de dados, categorizados como:
Numéricos: INT, DECIMAL, FLOAT, DOUBLE etc.
Texto: CHAR, VARCHAR, TEXT, BLOB.
Data/hora: DATE, DATETIME, TIMESTAMP, TIME.
JSON: para armazenar objetos JSON.
INT armazena números inteiros, sem casas decimais. Use quando não há necessidade de frações. Já DECIMAL armazena valores financeiros e é indicado para cálculos precisos com decimais.
O tipo DATE armazena a data nos formatos de ano, mês e dia:
YYYY-MM-DD
Já o tipo DATETIME armazena data e hora, neste formato:
YYYY-MM-DD HH:MM:SS
Uma chave estrangeira é um campo em uma tabela que referencia a chave primária de outra tabela.
Por exemplo, em uma tabela customers que guarda informações de clientes, cada cliente tem um customer_id único — em outra tabela chamada transactions (que registra compras), usamos customer_id como chave estrangeira. O customer_id na tabela de transações vincula cada compra a um cliente específico na tabela customers .
Veja como isso fica em SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Joins combinam linhas de duas ou mais tabelas com base em colunas relacionadas. As diferenças são:
INNER JOIN: retorna linhas quando há correspondência em ambas as tabelas.
LEFT JOIN: retorna todas as linhas da tabela da esquerda e as que casam na tabela da direita. Se não houver correspondência, as colunas da direita vêm como NULL.
RIGHT JOIN: semelhante ao LEFT JOIN, mas retorna todas as linhas da tabela da direita e as correspondentes da esquerda.
FULL JOIN: combina os resultados de LEFT JOIN e RIGHT JOIN, incluindo linhas sem correspondência de ambas as tabelas. Observação: o MySQL não suporta nativamente a sintaxe de FULL JOIN. Para obter o mesmo resultado, use um UNION entre um LEFT JOIN e um RIGHT JOIN
Comandos como DELETE, TRUNCATE e DROP podem parecer semelhantes, mas se comportam de forma diferente:
DELETE: remove linhas de uma tabela com base em uma condição. Pode ser desfeito se estiver dentro de uma transação. Exemplo:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: apaga todas as linhas de uma tabela, mas mantém a estrutura. É mais rápido que DELETE e não pode ser desfeito. Exemplo:
TRUNCATE TABLE employees;DROP: remove completamente a tabela e seus dados, além de dependências como índices. Exemplo:
DROP TABLE employees;Para criar tabelas, use a instrução CREATE TABLE; para modificar, geralmente ALTER TABLE. Exemplos:
Criar tabela:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Adicionar uma coluna:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Uma tabela temporária existe apenas durante a sessão atual do banco. Ao encerrar a sessão, ela é excluída. Esse tipo de tabela armazena resultados intermediários temporariamente, servindo para testes, filtragens ou preparação de dados antes de inseri-los em uma tabela permanente.
Exemplo:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;Uma subquery (também chamada de consulta aninhada) é uma consulta dentro de outra. Ela ajuda a decompor operações complexas em etapas mais gerenciáveis. Por exemplo, para encontrar funcionários que ganham acima da média:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Dividindo a lógica:
A consulta interna SELECT AVG(salary) FROM employees calcula a média salarial.
A consulta externa usa essa média para filtrar quem ganha acima dela.
Usamos a instrução INSERT para incluir dados em uma tabela. A sintaxe básica é:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Algumas boas práticas ao usar INSERT:
Liste as colunas explicitamente. O código fica mais claro e evita erros quando a estrutura muda.
Para colunas AUTO_INCREMENT (como IDs), omita-as no INSERT. O MySQL cuida disso e evita IDs duplicados.
Seja consistente nas aspas de strings. Eu prefiro aspas simples, mas ambas funcionam.
Para inserir várias linhas, faça em uma única instrução para melhor performance.
O AUTO_INCREMENT gera números únicos e sequenciais para uma coluna, normalmente a chave primária da tabela.
Exemplo de criação de tabela com coluna AUTO_INCREMENT:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);E para inserir linhas:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');Uma view é uma consulta salva que funciona como uma tabela virtual. Você pega uma query complexa, dá um nome a ela e passa a usá-la como se fosse uma tabela em futuras consultas — sem precisar reescrever tudo toda vez.
Por exemplo, para facilitar a consulta de dados do funcionário com o nome do departamento, crie uma view:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Agora você pode consultar employee_details como se fosse uma tabela:
SELECT * FROM employee_details;No entanto, não podemos usar views para inserir ou atualizar dados em muitos casos. A maioria é somente leitura e restringe o acesso direto às tabelas, aumentando a segurança. Em alguns cenários, views podem deixar as consultas mais lentas, pois executam a query subjacente a cada acesso.
Aprenda mais sobre SQL com estes cursos!
Curso
Curso
Curso
blog
Javier Canales Luna
15 min
blog
Javier Canales Luna
15 min
blog
Chloe Lubin
15 min
Tutorial
Javier Canales Luna
Tutorial
Sejal Jaiswal


