
Kurs
Datenbearbeitung in SQL
4 Std.
324.2K
Ist dir schon mal aufgefallen, dass MySQL in fast jeder datenbankbezogenen Stellenanzeige gefragt ist? Das hat einen guten Grund — MySQL treibt so ziemlich alles an, von deinen Lieblingsplattformen in den sozialen Medien bis zu den Apps, die du täglich nutzt.
Ich habe diesen Leitfaden zusammengestellt, damit du MySQL-Interviewfragen souverän meisterst. Wir gehen alles durch — von Basics, die Junior-Entwickler draufhaben sollten, bis zu Themen, die für Senior-Rollen entscheidend sind. Außerdem gebe ich dir Tipps, wie du in deinen nächsten datenbezogenen Interviews selbstbewusst auftrittst.
MySQL ist ein Open-Source-RDBMS (relationales Datenbankmanagementsystem) auf Basis von SQL, das Daten in strukturierten Tabellen organisiert. Entwickelt wurde es von Oracle Corporation.
Es belegte 2024 den Spitzenplatz unter den Open-Source-DBMS. Eine Stack Overflow Developer Survey 2025 zeigte jedoch, dass PostgreSQL erstmals MySQL überholt hat und unter professionellen Entwicklern am weitesten verbreitet ist.
Nicht falsch verstehen: MySQL ist weiterhin enorm beliebt — mit 40,5 % Nutzung unter Entwicklern im Jahr 2025 — und treibt unzählige Webanwendungen, Content-Management-Systeme und Enterprise-Tools an. Besonders wenn du mit Webanwendungen oder dem LAMP-Stack arbeitest, gehört MySQL zu den Top-Kompetenzen.
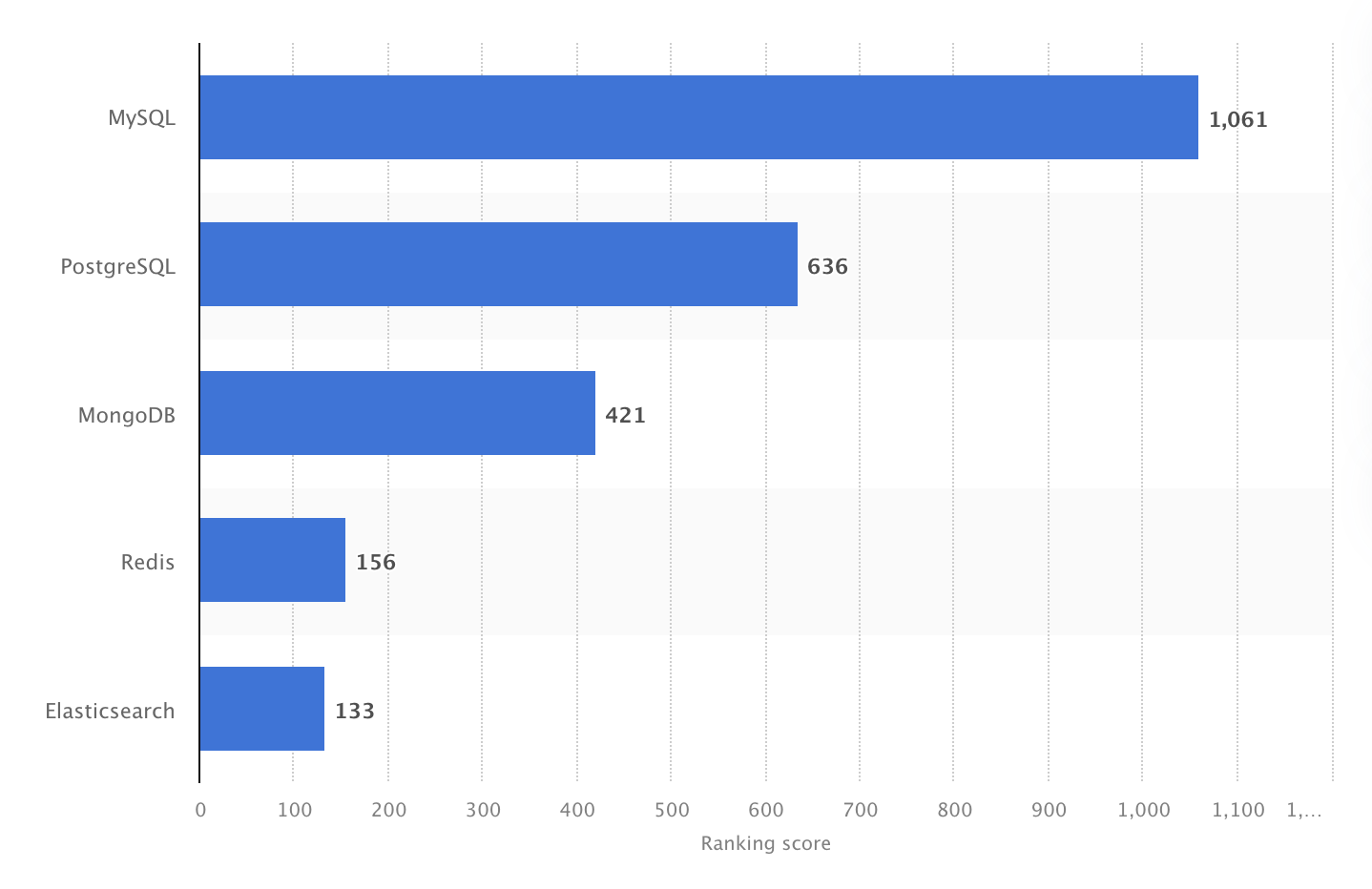
2024 war MySQL das weltweit beliebteste Open-Source-DBMS mit einem Ranking-Score von 1061. Quelle: Statista.
In der ersten Interviewphase werden oft Grundlagen abgefragt, um dein Verständnis zentraler Datenbank- und MySQL-Konzepte einzuschätzen.
Eine Datenbank ist ein Speichercontainer, der Daten vorhält, auf die wir zugreifen, die wir ändern und analysieren können. So speichern etwa soziale Netzwerke in Datenbanken, wer unsere Posts gelikt hat.
Ein DBMS (Database Management System) ist die Software, mit der wir diese Daten verwalten und darauf zugreifen, z. B. Benutzer anlegen und ihre Rechte steuern. MySQL ist eines der beliebtesten DBMS. Weitere Beispiele sind PostgreSQL, MongoDB und Microsoft SQL Server.
MySQL ist ein Open-Source-RDBMS, das SQL zur Datenverwaltung nutzt. Es ist bekannt für Benutzerfreundlichkeit, Geschwindigkeit und hohe Kompatibilität mit webbasierten Anwendungen.
So unterscheidet sich MySQL von anderen RDBMS:
MySQL ist ideal, wenn es auf Tempo und Skalierung ankommt. Für komplexere oder Enterprise-Features kann PostgreSQL die bessere Wahl sein.
MySQL unterstützt verschiedene Datentypen, grob kategorisiert in:
Numerisch: INT, DECIMAL, FLOAT, DOUBLE usw.
Zeichenketten: CHAR, VARCHAR, TEXT, BLOB.
Datum/Zeit: DATE, DATETIME, TIMESTAMP, TIME.
JSON: Zum Speichern von JSON-Objekten.
INT speichert ganze Zahlen ohne Nachkommastellen. Nutze ihn, wenn keine Bruchteile nötig sind. DECIMAL speichert exakte Dezimalwerte (z. B. Geldbeträge) und eignet sich für präzise Berechnungen mit Nachkommastellen.
Der Datentyp DATE speichert das Datum im Format:
YYYY-MM-DD
Der Datentyp DATETIME speichert Datum inklusive Uhrzeit, so:
YYYY-MM-DD HH:MM:SS
Ein Fremdschlüssel ist ein Feld in einer Tabelle, das auf den Primärschlüssel einer anderen Tabelle verweist.
Beispiel: In einer Tabelle customers mit Kundendaten hat jeder Kunde eine eindeutige customer_id. In einer weiteren Tabelle transactions (Kaufhistorie) verwenden wir customer_id als Fremdschlüssel. Die customer_id in transactions verknüpft jeden Kauf mit dem passenden Datensatz in der Tabelle customers .
So sieht das in SQL aus:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Joins kombinieren Zeilen aus zwei oder mehr Tabellen über verknüpfte Spalten. Das sind die Unterschiede:
INNER JOIN: Gibt nur Zeilen mit Treffern in beiden Tabellen zurück.
LEFT JOIN: Gibt alle Zeilen der linken Tabelle und passende Zeilen der rechten Tabelle zurück. Ohne Treffer stehen die Spalten der rechten Tabelle auf NULL.
RIGHT JOIN: Analog zu LEFT JOIN, aber alle Zeilen der rechten Tabelle und passende der linken.
FULL JOIN: Vereint die Ergebnisse von LEFT JOIN und RIGHT JOIN, inkl. nicht übereinstimmender Zeilen beider Tabellen. Hinweis: MySQL unterstützt FULL JOIN nicht nativ. Nutze stattdessen eine UNION aus LEFT JOIN und RIGHT JOIN.
Befehle wie DELETE, TRUNCATE und DROP klingen ähnlich, verhalten sich aber unterschiedlich:
DELETE: Löscht Zeilen anhand einer Bedingung. Innerhalb einer Transaktion rückgängig machbar. Beispiel:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: Löscht alle Zeilen einer Tabelle, die Struktur bleibt erhalten. Schneller als DELETE und nicht rückgängig machbar. Beispiel:
TRUNCATE TABLE employees;DROP: Entfernt die Tabelle inklusive Struktur und Daten vollständig, inkl. Abhängigkeiten wie Indizes. Beispiel:
DROP TABLE employees;Zum Erstellen nutzt du CREATE TABLE, zum Ändern meist ALTER TABLE. Beispiele:
Tabelle erstellen:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Spalte hinzufügen:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Eine temporäre Tabelle existiert nur während der aktuellen Datenbanksitzung. Nach dem Schließen wird sie gelöscht. Sie eignet sich, um Zwischenergebnisse vorübergehend zu speichern, z. B. für Tests, Filterungen oder zur Vorbereitung von Daten vor dem Einfügen in eine permanente Tabelle.
Beispiel:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;Eine Subquery (auch verschachtelte Abfrage) liegt innerhalb einer anderen Abfrage. So lassen sich komplexe Operationen in handhabbare Schritte zerlegen. Beispiel: Mitarbeitende mit überdurchschnittlichem Gehalt finden:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);So funktioniert es:
Die innere Abfrage SELECT AVG(salary) FROM employees berechnet zuerst den Durchschnitt.
Die äußere Abfrage nutzt diesen Wert, um alle darüberliegenden Gehälter zu finden.
Mit INSERT fügst du Daten in eine Tabelle ein. Die Basissyntax:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Best Practices für INSERT:
Spalten immer explizit angeben. Das macht den Code robuster bei Schemaänderungen.
AUTO_INCREMENT-Spalten wie IDs im INSERT auslassen. MySQL vergibt diese automatisch und verhindert doppelte IDs.
String-Anführungen konsistent halten. Ich nutze gerne einfache Anführungszeichen, beides ist aber möglich.
Mehrere Zeilen in einer Anweisung einfügen — das ist performanter.
AUTO_INCREMENT erzeugt eindeutige, aufsteigende Werte für eine Spalte, typischerweise den Primärschlüssel.
So erstellst du eine Tabelle mit AUTO_INCREMENT:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);Und so fügst du Zeilen ein:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');Eine View ist eine gespeicherte Abfrage und verhält sich wie eine virtuelle Tabelle. Du gibst einer komplexen Abfrage einen Namen und nutzt sie künftig wie eine Tabelle. So musst du sie nicht jedes Mal neu schreiben.
Beispiel: Um Mitarbeitende inklusive Abteilungsname leichter abzufragen:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Die View employee_details kannst du dann wie eine Tabelle abfragen:
SELECT * FROM employee_details;Einfügen und Aktualisieren über Views ist meist nicht möglich. Viele Views sind read-only und schirmen die zugrunde liegenden Tabellen ab, was die Datensicherheit erhöht. Allerdings können Views Abfragen verlangsamen, da bei jedem Zugriff die zugrunde liegende Abfrage ausgeführt wird.
Entdecke mehr zu SQL mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Zoumana Keita
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
Tutorial
Kurtis Pykes