
programa
Científico especializado en machine learning en Python
85 h
El aprendizaje cero (ZSL) es una técnica de aprendizaje automático que permite a los modelos enfrentarse a tareas o reconocer cosas con las que nunca se han encontrado antes. Lo hace utilizando lo que ya sabe y conectándolo a situaciones nuevas, incluso sin una formación específica para ellas.
Supongamos que un modelo está entrenado para reconocer animales, pero nunca se le ha enseñado sobre las cebras en su fase de entrenamiento. Con ZSL, el modelo aún podría averiguar qué es una cebra utilizando una descripción. ¿Pero cómo? Permíteme que simplifique un poco las cosas (dentro de un rato entraremos en detalles más técnicos) y me explique:
El aprendizaje cero es un proceso de dos etapas (entrenamiento e inferencia) y utiliza tres componentes clave: modelos preentrenados, información extra y transferencia de conocimientos.
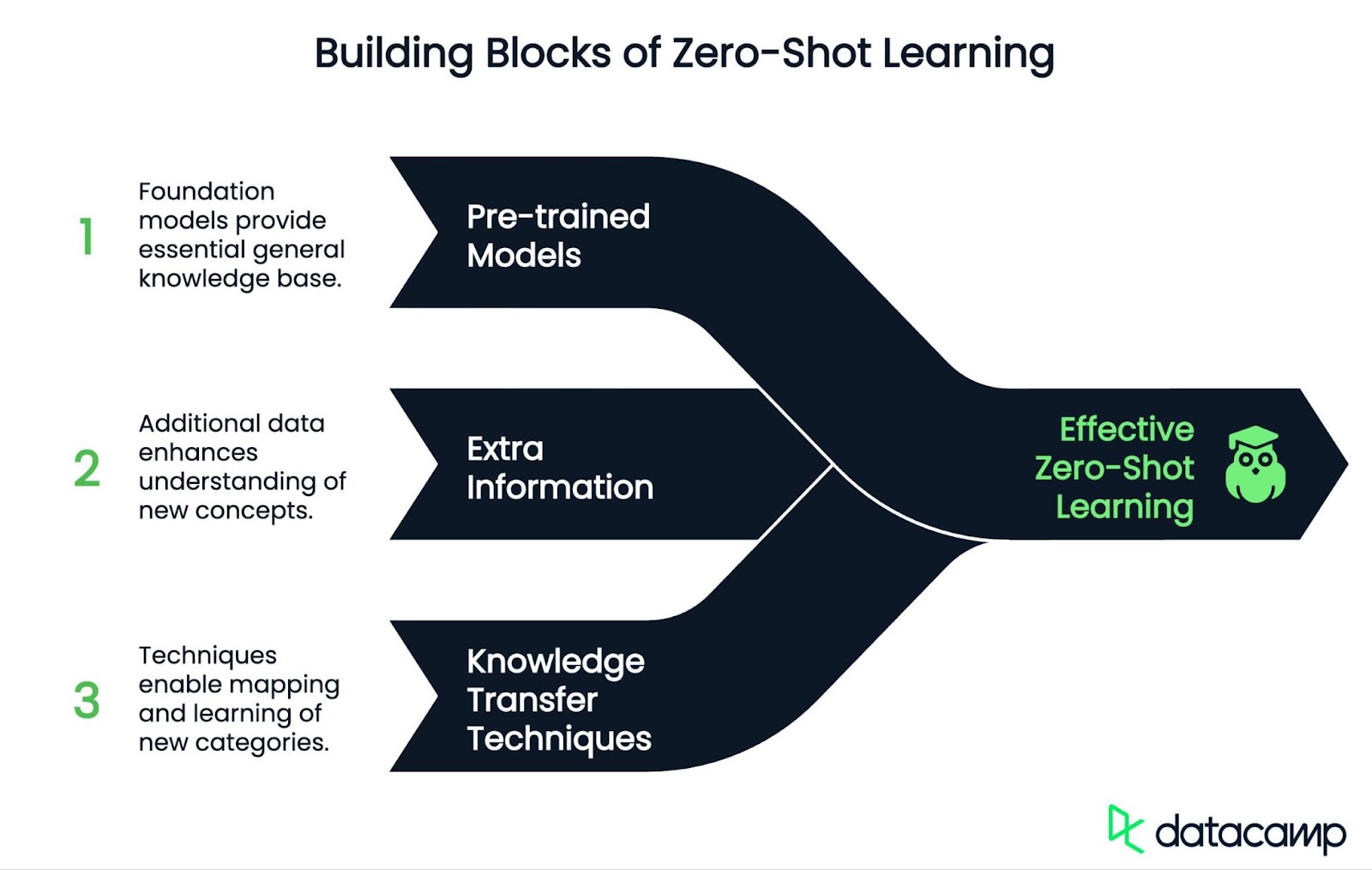
La ZSL se basa en modelos preentrenados que se han entrenado con muchos datos. Por ejemplo, la familia de los GPT (para el lenguaje) o CLIP (para las conexiones imagen-texto). Estos modelos proporcionan una base sólida de conocimientos generales.
La información adicional ayuda al modelo a comprender cosas nuevas. Esto puede incluir:
El ZSL mapea tanto las clases conocidas como las nuevas en un "espacio semántico" compartido donde se pueden comparar. A menudo utiliza técnicas como:
La ZSL puede conceptualizarse como un proceso en dos fases:
Este enfoque permite a los modelos ZSL reconocer dinámicamente un conjunto abierto de nuevos conceptos a lo largo del tiempo, utilizando sólo descripciones o información semántica, sin necesidad de datos de entrenamiento etiquetados adicionales.
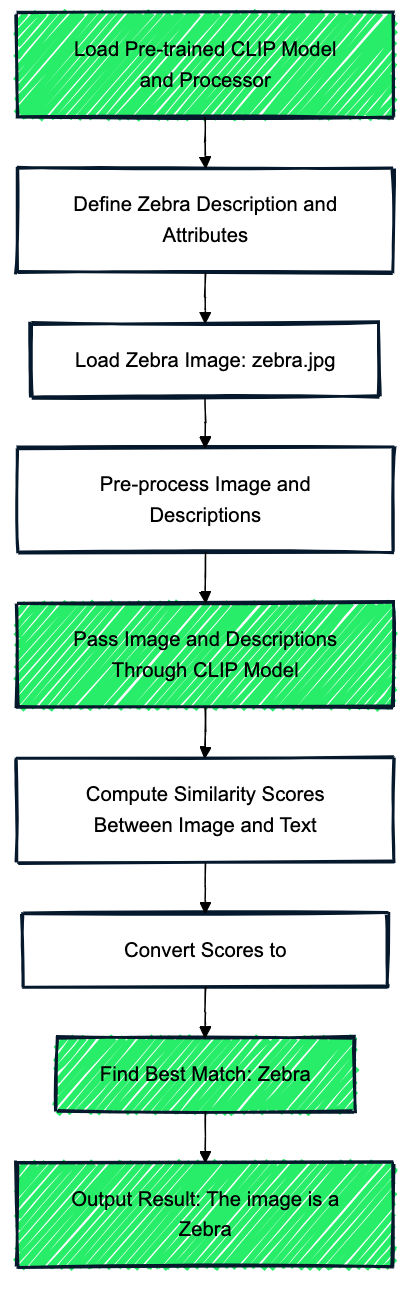
Volvamos a nuestro ejemplo de clasificación de animales.
Imagina que utilizamos el modelo CLIP, que está preentrenado en un conjunto de datos masivo de pares imagen-texto. Este modelo preentrenado proporciona una base de conocimientos generales sobre los animales, aunque no se haya entrenado explícitamente sobre las cebras.
En nuestro ejemplo de la cebra, los datos auxiliares (información extra) incluyen descripciones de texto como "Un animal parecido a un caballo con rayas blancas y negras que vive en las praderas africanas" y atributos como "tiene cuatro patas", "tiene rayas", "vive en la sabana". Estas descripciones y atributos conectan lo que el modelo conoce (rasgos generales del animal) y la clase no vista (cebra).
A continuación, el modelo mapea ambas clases vistas (por ejemplo, caballo, tigre) y la clase no vista (cebra) en un espacio semántico compartido. El modelo codifica la descripción de la cebra ("rayas blancas y negras, parecida a un caballo") en el mismo espacio que los animales conocidos y utiliza su comprensión de animales como los caballos y los tigres para razonar sobre las cebras.
El modelo compara la incrustación de la cebra con incrustaciones de animales conocidos y descripciones (por ejemplo, caballo, tigre, "rayas blancas y negras"). Mediante puntuaciones de similitud, el modelo identifica la cebra que más se ajusta a la descripción: "Un animal parecido a un caballo con rayas blancas y negras que vive en las praderas africanas".
Aprendizaje de cero disparos (ZSL) y aprendizaje de pocos disparos (FSL) son dos métodos que ayudan a los modelos a enfrentarse a nuevas tareas u objetos, incluso cuando hay pocos o ningún dato disponible. Sin embargo, tienen algunas diferencias. Veamos un resumen de ambas técnicas y sus principales diferencias:
|
Aspecto |
Aprendizaje Cero Tiros (ZSL) |
Aprendizaje de Pocos Tiros (FSL) |
|
Qué hace |
Maneja nuevas tareas sin datos de entrenamiento etiquetados. |
Aprende nuevas tareas a partir de unos pocos ejemplos etiquetados. |
|
Cómo funciona |
Infiere nuevas categorías asignando descripciones a conocimientos conocidos. |
Aprende patrones a partir de unos pocos ejemplos para clasificar nuevas instancias. |
|
Datos necesarios |
Requiere cero ejemplos etiquetados para las nuevas tareas. |
Requiere de 1 a 5 ejemplos etiquetados para nuevas tareas. |
|
Conocimientos previos |
Se basa en relaciones aprendidas entre conceptos y descripciones. |
Utiliza conocimientos previos, pero también actualiza basándose en los ejemplos proporcionados. |
|
Adaptabilidad |
Puede generalizar a tareas completamente nuevas, pero puede ser menos preciso. |
Se adapta rápidamente a nuevas tareas específicas y suele ser más preciso. |
|
Ejemplo 1 |
Detección de spam: Identifica el spam utilizando definiciones (por ejemplo, "correos electrónicos con enlaces sospechosos") sin datos previos de spam etiquetado. |
Detección de Intenciones de Atención al Cliente: Aprende a detectar una nueva intención (por ejemplo, "cancelar suscripción") tras ver unas cuantas conversaciones etiquetadas. |
|
Ejemplo 2 |
Clasificación de textos en el análisis de sentimientos: Determina el sentimiento (por ejemplo, "satisfecho", "enfadado") utilizando sólo definiciones. |
Identificación del tipo de documento: Aprende a clasificar nuevos tipos de documentos (por ejemplo, "órdenes de compra") tras ver unos cuantos ejemplos. |
La ZSL es mejor cuando no tienes datos etiquetados con los que trabajar. Es útil para situaciones en las que aparecen nuevas categorías o tareas para las que el modelo no fue entrenado, y no hay tiempo ni recursos para reunir ejemplos etiquetados.
Por ejemplo, una tienda online puede añadir nuevas categorías de productos, y el modelo puede organizar estos artículos basándose en descripciones sin necesidad de ejemplos etiquetados.
La ZSL es perfecta cuando necesitas flexibilidad y recopilar datos etiquetados es demasiado caro, lento o imposible.
Por otra parte, FSL funciona bien cuando puedes proporcionar un número reducido de ejemplos etiquetados (normalmente 1-5) y necesitas que el modelo aprenda rápidamente con mayor precisión.
Por ejemplo, si un chatbot recibe un nuevo tipo de pregunta como "¿Cómo cancelo mi suscripción?", mostrarle sólo unos pocos ejemplos de este tipo de consulta puede ayudarle a clasificar con precisión otras similares.
El FSL es estupendo para situaciones en las que puedes permitirte proporcionar unos pocos ejemplos etiquetados y necesitas que el modelo funcione bien, especialmente en tareas en las que la precisión es importante, como la atención al cliente o el diagnóstico médico por imagen.
Hay muchas áreas en las que la ZSL es útil. Veamos sólo algunos.
La ZSL se utiliza ampliamente en la clasificación de textos, ya que permite a los modelos categorizar el texto en nuevas etiquetas sin entrenamiento previo.
Por ejemplo, puede clasificar los correos electrónicos como spam o no spam basándose en las descripciones de esas categorías, sin necesidad de ejemplos etiquetados. Esta capacidad también beneficia a los chatbots, ya que les ayuda a comprender las peticiones de los usuarios sin tener que entrenarse en todas las consultas posibles.
En análisis del sentimientola ZSL permite a los modelos determinar si una reseña es positiva o negativa simplemente interpretando los significados de las etiquetas. También desempeña un papel en la moderación de las redes sociales, identificando contenidos dañinos o engañosos basándose en descripciones de texto, como la detección de información errónea etiquetada como "difusión de afirmaciones médicas falsas", aunque el modelo nunca se haya encontrado antes con casos así.
En la clasificación de imágenes, la ZSL permite a los modelos reconocer objetos que nunca han visto vinculando imágenes con descripciones de texto. Herramientas como CLIP pueden identificar objetos desconocidos, como un "panda rojo", y alinear las imágenes con el texto, haciendo que los buscadores visuales sean más eficaces a la hora de recuperar imágenes basándose en las descripciones de los usuarios.
La ZSL también es valiosa en la vigilancia medioambiental, donde detecta cambios en las imágenes de satélite sin datos de entrenamiento etiquetados. Por ejemplo, puede identificar talas ilegales reconociendo zonas descritas como "pérdida significativa de dosel en regiones boscosas", aunque el modelo nunca haya sido entrenado explícitamente en patrones de deforestación.
En el comercio minorista, la ZSL ayuda a clasificar los nuevos productos en categorías de inventario utilizando sólo descripciones textuales. Un modelo puede asignar automáticamente nuevos elementos a etiquetas como "materiales ecológicos" aunque esa categoría no se incluyera durante el entrenamiento.
También resuelve el problema del arranque en frío en los sistemas de recomendación, sugiriendo productos o contenidos sin datos previos del usuario. Algoritmos como ZESRec pueden recomendar elementos de un conjunto de datos completamente nuevo, sin solaparse con los datos vistos anteriormente.
Aunque la ZSL es flexible y puede generalizarse a nuevas tareas, se enfrenta a varios retos.
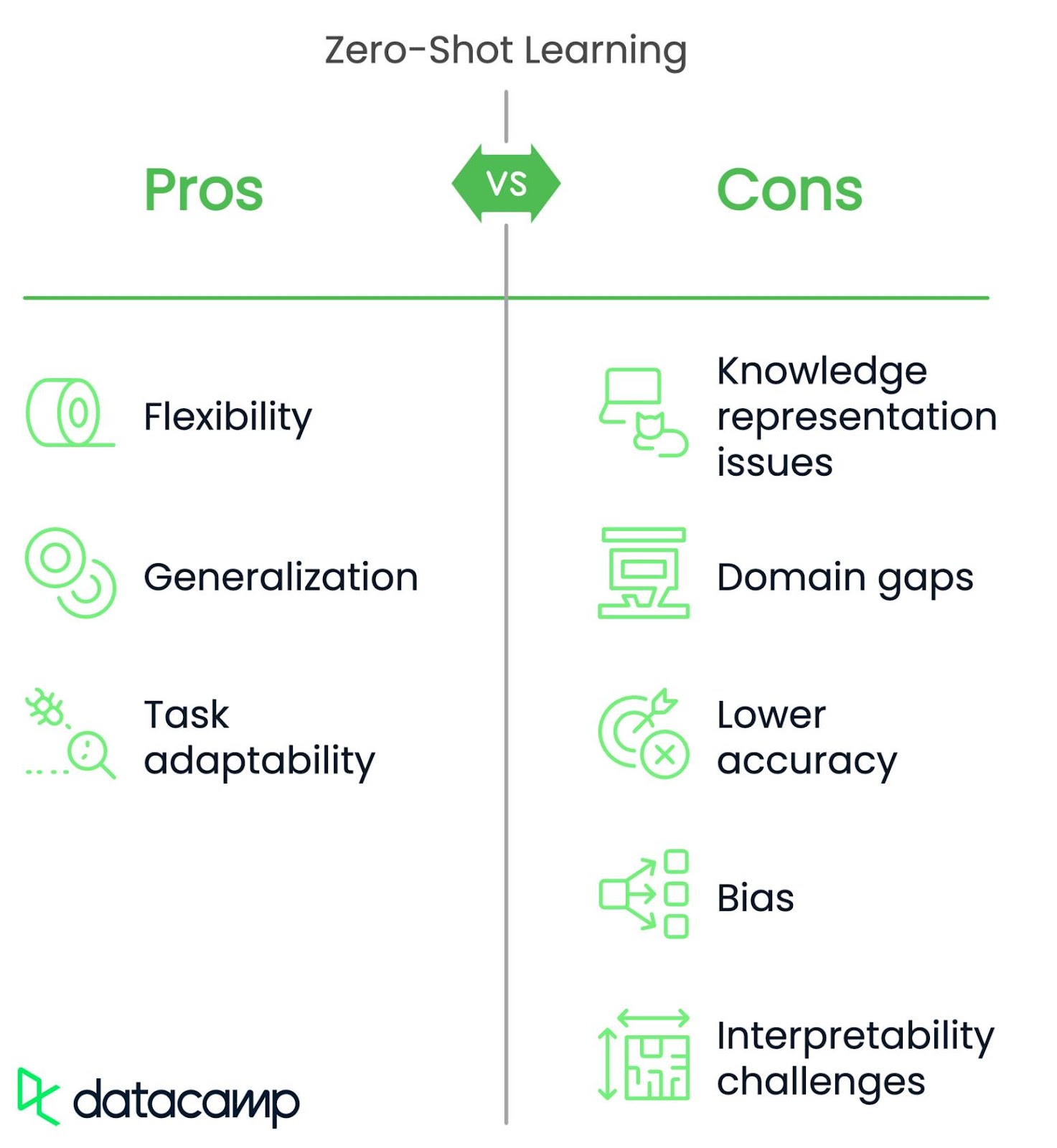
Los modelos ZSL tienen dificultades para representar diferencias detalladas o sutiles entre las cosas. Por ejemplo, un modelo podría confundir un leopardo y un guepardo porque ambos se describen como "grandes felinos moteados", y las descripciones no captan las diferencias más sutiles.
Los modelos ZSL pueden fallar cuando la nueva tarea o los nuevos datos son muy diferentes de aquellos con los que fueron entrenados. Por ejemplo, un modelo entrenado para reconocer objetos domésticos podría no identificar las herramientas médicas porque son demasiado diferentes.
La ZSL suele ser menos precisa que el aprendizaje supervisado (en el que el modelo se entrena con datos etiquetados) para tareas específicas. Una solución a este reto es combinar la ZSL con algunos ajustes en datos específicos para mejorar la precisión, manteniendo la flexibilidad.
La ZSL se basa en datos preentrenados, que pueden contener sesgos. Esto puede llevar a menudo a predicciones injustas. Imagen de un modelo de contratación mediante ZSL. Podría favorecer a ciertos grupos demográficos si los datos preentrenados tienen sesgos de género o raciales. Una estrategia de mitigación consiste en detectar y reducir de antemano los sesgos en los datos o utilizar métodos como el debiasing adversarial para que el modelo sea más justo.
Aprende IA con estos cursos
programa
programa
programa
blog
Zoumana Keita
14 min
blog
Kurtis Pykes
8 min
Tutorial
Abid Ali Awan
Tutorial

