
Lernpfad
Wissenschaftler für maschinelles Lernen in Python
85 Std.
Zero-Shot-Learning (ZSL) ist eine maschinelle Lerntechnik, die es Modellen ermöglicht, Aufgaben zu bewältigen oder Dinge zu erkennen, denen sie noch nie begegnet sind. Er tut dies, indem er das, was er bereits weiß, nutzt und es mit neuen Situationen verbindet, auch wenn er nicht speziell dafür ausgebildet wurde.
Angenommen, ein Modell wird darauf trainiert, Tiere zu erkennen, hat aber in seiner Trainingsphase nie etwas über Zebras gelernt. Bei ZSL konnte das Modell anhand einer Beschreibung herausfinden, was ein Zebra ist. Aber wie? Erlaube mir, die Dinge ein wenig zu vereinfachen (wir werden gleich zu den technischen Details kommen) und lass mich erklären:
Das Zero-Shot-Lernen ist ein zweistufiger Prozess (Training und Inferenz) und nutzt drei Schlüsselkomponenten: vortrainierte Modelle, zusätzliche Informationen und Wissenstransfer.
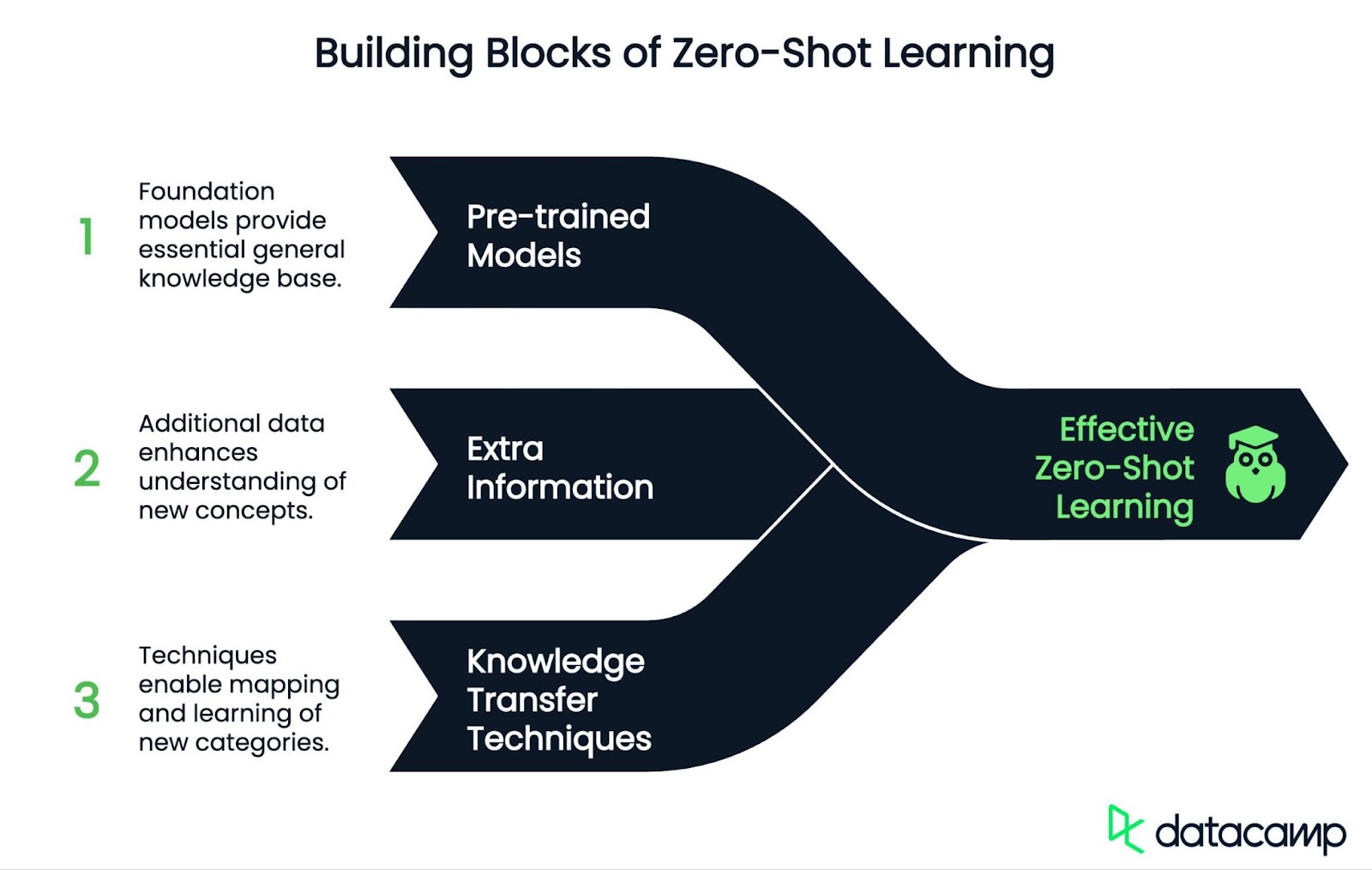
ZSL setzt auf vorgefertigte Modelle, die mit einer großen Anzahl von Daten trainiert wurden. Zum Beispiel die Familie der GPTs (für Sprache) oder CLIP (für Bild-Text-Verbindungen). Diese Modelle bieten eine solide Basis an Allgemeinwissen.
Zusätzliche Informationen helfen dem Modell, neue Dinge zu verstehen. Das kann Folgendes beinhalten:
ZSL bildet sowohl bekannte als auch neue Klassen in einem gemeinsamen "semantischen Raum" ab, in dem sie verglichen werden können. Sie verwendet oft Techniken wie:
ZSL kann als ein zweistufiger Prozess verstanden werden:
Mit diesem Ansatz können ZSL-Modelle dynamisch eine unbegrenzte Anzahl neuer Konzepte im Laufe der Zeit erkennen, indem sie nur Beschreibungen oder semantische Informationen verwenden, ohne dass zusätzliche gelabelte Trainingsdaten benötigt werden.
Kommen wir zurück zu unserem Beispiel der Tierklassifizierung.
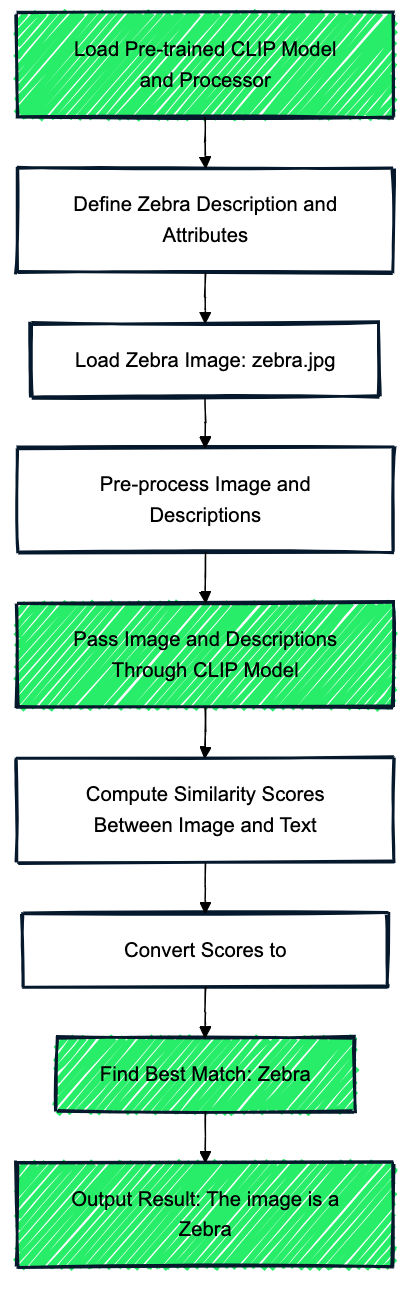
Stell dir vor, wir verwenden das Modell CLIP, das auf einem großen Datensatz von Bild-Text-Paaren trainiert wurde. Dieses vortrainierte Modell bietet eine Grundlage für allgemeines Wissen über Tiere, auch wenn es nicht explizit auf Zebras trainiert wurde.
In unserem Zebra-Beispiel enthalten die Hilfsdaten (zusätzliche Informationen) Textbeschreibungen wie: "Ein pferdeähnliches Tier mit schwarzen und weißen Streifen, das im afrikanischen Grasland lebt." und Attribute wie "hat vier Beine", "hat Streifen", "lebt in der Savanne". Diese Beschreibungen und Attribute verbinden das, was das Modell weiß (allgemeine Tiermerkmale) und die ungesehene Klasse (Zebra).
Dann ordnet das Modell die beiden gesehenen Klassen (z. B. Pferd, Tiger) und die ungesehene Klasse (Zebra) in einen gemeinsamen semantischen Raum ein. Das Modell kodiert die Beschreibung des Zebras ("schwarz-weiß gestreift, pferdeähnlich") in denselben Raum wie bekannte Tiere und nutzt sein Verständnis von Tieren wie Pferden und Tigern, um über Zebras nachzudenken.
Das Modell vergleicht die Einbettung des Zebras mit Einbettungen von bekannten Tieren und Beschreibungen (z. B. Pferd, Tiger, "schwarz-weiß gestreift"). Anhand von Ähnlichkeitswerten identifiziert das Modell das Zebra, das der Beschreibung am ehesten entspricht: "Ein pferdeähnliches Tier mit schwarzen und weißen Streifen, das im afrikanischen Grasland lebt."
Null-Schuss-Lernen (ZSL) und few-shot learning (FSL) sind zwei Methoden, die den Modellen helfen, mit neuen Aufgaben oder Objekten umzugehen, auch wenn nur wenige oder gar keine Daten vorhanden sind. Es gibt jedoch einige Unterschiede. Schauen wir uns einen Überblick über die beiden Techniken und ihre wichtigsten Unterschiede an:
|
Aspekt |
Zero-Shot Learning (ZSL) |
Few-Shot Learning (FSL) |
|
Was es tut |
Bearbeitet neue Aufgaben ohne gelabelte Trainingsdaten. |
Lernt neue Aufgaben aus wenigen beschrifteten Beispielen. |
|
Wie es funktioniert |
Erschließt neue Kategorien, indem er Beschreibungen auf bekanntes Wissen abbildet. |
Lernt Muster aus wenigen Beispielen, um neue Instanzen zu klassifizieren. |
|
Benötigte Daten |
Benötigt null beschriftete Beispiele für neue Aufgaben. |
Benötigt 1-5 beschriftete Beispiele für neue Aufgaben. |
|
Vorwissen |
Verlässt sich auf gelernte Beziehungen zwischen Konzepten und Beschreibungen. |
Nutzt das Vorwissen, aktualisiert es aber auch anhand der Beispiele. |
|
Anpassungsfähigkeit |
Kann auf völlig neue Aufgaben verallgemeinern, ist aber möglicherweise weniger präzise. |
Passt sich schnell an spezifische neue Aufgaben an und ist in der Regel genauer. |
|
Beispiel 1 |
Spam-Erkennung: Identifiziert Spam anhand von Definitionen (z. B. "E-Mails mit verdächtigen Links"), ohne dass zuvor markierte Spam-Daten vorliegen. |
Kundenbetreuung Intent Detection: Lernt, eine neue Absicht zu erkennen (z. B. "Abonnement kündigen"), nachdem er ein paar beschriftete Konversationen gesehen hat. |
|
Beispiel 2 |
Textklassifizierung in der Stimmungsanalyse: Ermittelt die Stimmung (z. B. "zufrieden", "verärgert") nur anhand von Definitionen. |
Identifikation der Dokumentenart: Lernt, neue Dokumenttypen zu klassifizieren (z. B. "Bestellungen"), nachdem er ein paar Beispiele gesehen hat. |
ZSL ist am besten geeignet, wenn du keine beschrifteten Daten zur Verfügung hast, mit denen du arbeiten kannst. Sie ist nützlich, wenn neue Kategorien oder Aufgaben auftauchen, für die das Modell nicht trainiert wurde, und keine Zeit oder Ressourcen vorhanden sind, um beschriftete Beispiele zu sammeln.
Wenn zum Beispiel ein Online-Shop neue Produktkategorien hinzufügt, kann das Modell diese Artikel anhand von Beschreibungen ordnen, ohne dass beschriftete Beispiele benötigt werden.
ZSL ist perfekt, wenn du Flexibilität brauchst und das Sammeln von beschrifteten Daten zu teuer, langsam oder unmöglich ist.
Auf der anderen Seite funktioniert FSL gut, wenn du eine kleine Anzahl von beschrifteten Beispielen (normalerweise 1-5) zur Verfügung stellen kannst und das Modell schnell und mit höherer Genauigkeit lernen soll.
Wenn ein Chatbot z. B. eine neue Art von Frage erhält, wie "Wie kündige ich mein Abonnement?", kann es ihm helfen, ähnliche Fragen genau zu klassifizieren, wenn man ihm ein paar Beispiele für diese Art von Fragen zeigt.
FSL eignet sich hervorragend für Situationen, in denen du es dir leisten kannst, ein paar beschriftete Beispiele bereitzustellen, und in denen das Modell eine gute Leistung erbringen muss, vor allem bei Aufgaben, bei denen es auf Genauigkeit ankommt, wie z. B. im Kundensupport oder in der medizinischen Bildgebung.
Es gibt so viele Bereiche, in denen die ZSL nützlich ist. Schauen wir uns nur ein paar davon an.
ZSL wird häufig in der Textklassifizierung eingesetzt und ermöglicht es Modellen, Texte ohne vorheriges Training in neue Kategorien einzuordnen.
Zum Beispiel kann es E-Mails anhand von Beschreibungen dieser Kategorien als Spam oder Nicht-Spam sortieren, ohne dass dafür beschriftete Beispiele benötigt werden. Diese Fähigkeit kommt auch den Chatbots zugute, denn sie helfen ihnen, Nutzeranfragen zu verstehen, ohne dass sie für jede mögliche Anfrage trainiert werden müssen.
In Stimmungsanalysekönnen ZSL-Modelle allein durch die Interpretation der Label-Bedeutung feststellen, ob eine Rezension positiv oder negativ ist. Es spielt auch eine Rolle bei der Moderation sozialer Medien, indem es schädliche oder irreführende Inhalte anhand von Textbeschreibungen identifiziert, wie z. B. die Erkennung von Fehlinformationen, die als "Verbreitung falscher medizinischer Behauptungen" bezeichnet werden, selbst wenn das Modell noch nie auf solche Fälle gestoßen ist.
Bei der Bildklassifizierung ermöglicht ZSL Modellen, Objekte zu erkennen, die sie noch nie gesehen haben, indem sie Bilder mit Textbeschreibungen verknüpfen. Tools wie CLIP können unbekannte Objekte, wie z. B. einen "roten Panda", identifizieren und Bilder mit Text abgleichen, so dass visuelle Suchmaschinen Bilder auf der Grundlage von Nutzerbeschreibungen effektiver auffinden können.
ZSL ist auch bei der Umweltüberwachung wertvoll, wo es Veränderungen in Satellitenbildern ohne beschriftete Trainingsdaten erkennt. Es kann zum Beispiel illegalen Holzeinschlag erkennen, indem es Gebiete erkennt, die als "signifikanter Verlust der Baumkronen in bewaldeten Regionen" beschrieben werden, auch wenn das Modell nie explizit auf Entwaldungsmuster trainiert wurde.
Im Einzelhandel hilft ZSL dabei, neue Produkte nur mit Hilfe von Textbeschreibungen in Bestandskategorien einzuordnen. Ein Modell kann neue Artikel automatisch Labels wie "umweltfreundliche Materialien" zuordnen, auch wenn diese Kategorie beim Training nicht berücksichtigt wurde.
Es löst auch das Kaltstartproblem in Empfehlungssystemen, indem es Produkte oder Inhalte ohne vorherige Nutzerdaten vorschlägt. Algorithmen wie ZESRec können Elemente aus einem völlig neuen Datensatz empfehlen, ohne dass es zu Überschneidungen mit bereits gesehenen Daten kommt.
ZSL ist zwar flexibel und kann für neue Aufgaben verallgemeinert werden, steht aber vor einigen Herausforderungen.
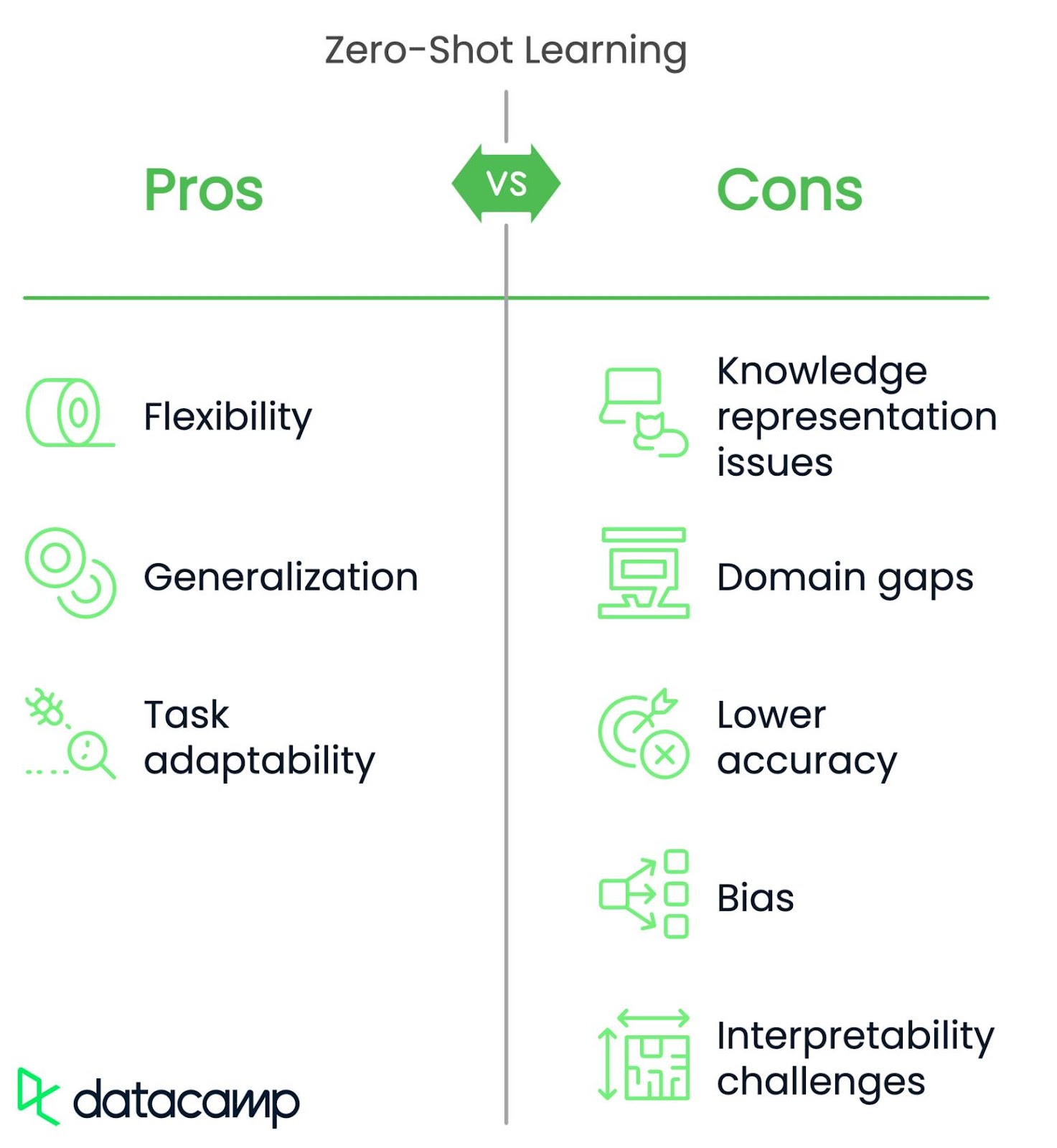
ZSL-Modelle haben Schwierigkeiten, detaillierte oder subtile Unterschiede zwischen Dingen darzustellen. Ein Modell könnte zum Beispiel einen Leoparden und einen Geparden verwechseln, weil beide als "gefleckte Großkatzen" beschrieben werden und die Beschreibungen die feineren Unterschiede nicht erfassen.
ZSL-Modelle können versagen, wenn sich die neue Aufgabe oder die Daten stark von dem unterscheiden, auf dem sie trainiert wurden. Ein Modell, das für die Erkennung von Haushaltsgegenständen trainiert wurde, kann zum Beispiel medizinische Werkzeuge nicht erkennen, weil sie zu unterschiedlich sind.
ZSL ist oft weniger genau als überwachtes Lernen (bei dem das Modell auf markierten Daten trainiert wird) für bestimmte Aufgaben. Eine Lösung für diese Herausforderung ist die Kombination von ZSL mit einer Feinabstimmung bestimmter Daten, um die Genauigkeit zu verbessern und gleichzeitig flexibel zu bleiben.
ZSL stützt sich auf vortrainierte Daten, die Verzerrungen enthalten können. Das kann oft zu unfairen Vorhersagen führen. Ein Einstellungsmodell mit ZSL abbilden. Es könnte bestimmte demografische Gruppen bevorzugen, wenn die vortrainierten Daten geschlechts- oder rassenbezogene Verzerrungen aufweisen. Eine Abhilfestrategie besteht darin, Verzerrungen in den Daten im Voraus zu erkennen und zu reduzieren oder Methoden wie das adversarische Debiasing anzuwenden, um das Modell fairer zu machen.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Lernpfad
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
