
Cursus
Chercheur en apprentissage automatique en Python
85 h
L'apprentissage à partir de zéro (ZSL) est une technique d'apprentissage automatique qui permet aux modèles de traiter des tâches ou de reconnaître des choses qu'ils n'ont jamais rencontrées auparavant. Pour ce faire, il utilise ce qu'il connaît déjà et l'associe à de nouvelles situations, même s'il n'a pas reçu de formation spécifique à cet effet.
Supposons qu'un modèle soit entraîné à reconnaître des animaux, mais qu'il n'ait jamais reçu d'enseignement sur les zèbres au cours de sa phase d'entraînement. Avec ZSL, le modèle peut encore comprendre ce qu'est un zèbre à l'aide d'une description. Mais comment ? Permettez-moi de simplifier un peu les choses (nous entrerons dans les détails techniques dans un instant) et de vous expliquer :
L'apprentissage à partir de zéro est un processus en deux étapes (formation et inférence) qui fait appel à trois éléments clés : les modèles préformés, les informations supplémentaires et le transfert de connaissances.
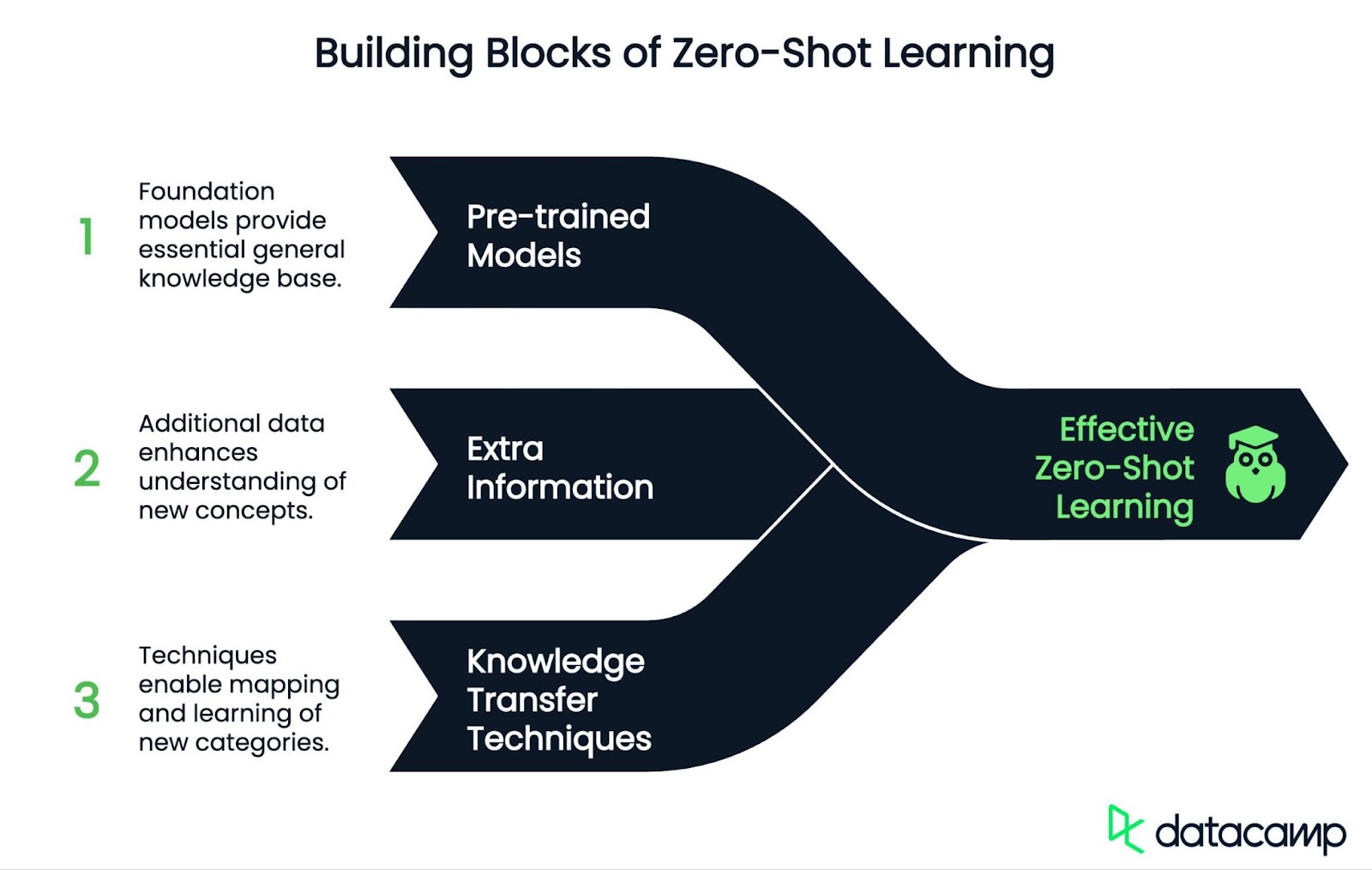
ZSL s'appuie sur des modèles pré-entraînés qui ont été formés sur un grand nombre de données. Par exemple, la famille des GPT (pour le langage) ou CLIP (pour les connexions image-texte). Ces modèles fournissent une base solide de connaissances générales.
Les informations supplémentaires aident le modèle à comprendre de nouvelles choses. Il peut s'agir de
ZSL met en correspondance les classes connues et les nouvelles classes dans un "espace sémantique" partagé où elles peuvent être comparées. Elle utilise souvent des techniques telles que :
Le ZSL peut être considéré comme un processus en deux étapes :
Cette approche permet aux modèles ZSL de reconnaître dynamiquement un ensemble ouvert de nouveaux concepts au fil du temps, en utilisant uniquement des descriptions ou des informations sémantiques, sans avoir besoin de données d'apprentissage étiquetées supplémentaires.
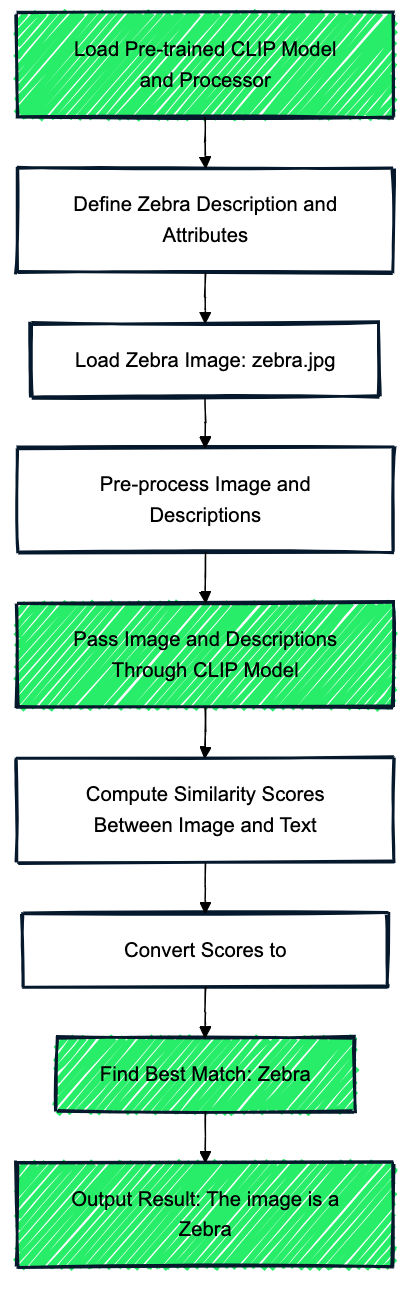
Revenons à notre exemple de classification des animaux.
Imaginons que nous utilisions le modèle CLIP, qui est pré-entraîné sur un vaste ensemble de données de paires image-texte. Ce modèle pré-entraîné fournit une base de connaissances générales sur les animaux, même s'il n'a pas été explicitement entraîné sur les zèbres.
Dans notre exemple de zèbre, les données auxiliaires (informations supplémentaires) comprennent des descriptions textuelles comme : "Un animal ressemblant à un cheval avec des rayures noires et blanches qui vit dans les prairies africaines" et des attributs comme "a quatre pattes", "a des rayures", "vit dans la savane". Ces descriptions et attributs relient ce que le modèle connaît (les caractéristiques générales des animaux) et la classe non vue (le zèbre).
Ensuite, le modèle met en correspondance les classes vues (par exemple, cheval, tigre) et la classe non vue (zèbre) dans un espace sémantique partagé. Le modèle encode la description du zèbre ("rayures noires et blanches, ressemblant à un cheval") dans le même espace que les animaux connus et utilise sa compréhension d'animaux tels que les chevaux et les tigres pour raisonner sur les zèbres.
Le modèle compare l'encastrement du zèbre aux encastrements d'animaux et de descriptions connus (par exemple, cheval, tigre, "rayures noires et blanches"). En utilisant les scores de similarité, le modèle identifie le zèbre qui correspond le mieux à la description : "Animal ressemblant à un cheval avec des rayures noires et blanches vivant dans les prairies africaines.
Apprentissage à partir de zéro (ZSL) et l'apprentissage à quelques coups (FSL) sont deux méthodes qui aident les modèles à traiter de nouvelles tâches ou de nouveaux objets, même lorsqu'il n'y a que peu ou pas de données disponibles. Ils présentent toutefois quelques différences. Voici un aperçu des deux techniques et de leurs principales différences :
|
Aspect |
Zero-Shot Learning (ZSL) |
Apprentissage à la petite semaine (FSL) |
|
Ce qu'il fait |
Traite les nouvelles tâches sans données de formation étiquetées. |
Apprend de nouvelles tâches à partir de quelques exemples étiquetés. |
|
Comment ça marche |
Détermine de nouvelles catégories en établissant des correspondances entre les descriptions et les connaissances connues. |
Apprend des modèles à partir de quelques exemples pour classer de nouvelles instances. |
|
Données nécessaires |
Nécessite des exemples non étiquetés pour les nouvelles tâches. |
Nécessite 1 à 5 exemples étiquetés pour les nouvelles tâches. |
|
Connaissances préalables |
S'appuie sur les relations apprises entre les concepts et les descriptions. |
Utilise ses connaissances antérieures mais les actualise également sur la base des exemples fournis. |
|
Adaptabilité |
Peut généraliser à des tâches complètement nouvelles mais peut être moins précis. |
S'adapte rapidement à de nouvelles tâches spécifiques et est généralement plus précis. |
|
Exemple 1 |
Détection du spam : Identifie le spam à l'aide de définitions (par exemple, "courriels contenant des liens suspects") sans données de spam étiquetées au préalable. |
Soutien à la clientèle Détection des intentions : Apprend à détecter une nouvelle intention (par exemple, "annuler l'abonnement") après avoir vu quelques conversations étiquetées. |
|
Exemple 2 |
Classification des textes dans l'analyse des sentiments : Détermine le sentiment (par exemple, "satisfait", "en colère") en utilisant uniquement des définitions. |
Identification du type de document : Apprend à classer de nouveaux types de documents (par exemple, les "bons de commande") après en avoir vu quelques exemples. |
ZSL est la meilleure solution lorsque vous ne disposez pas de données étiquetées. Elle est utile lorsque de nouvelles catégories ou tâches apparaissent, pour lesquelles le modèle n'a pas été formé, et que le temps ou les ressources manquent pour rassembler des exemples étiquetés.
Par exemple, un magasin en ligne peut ajouter de nouvelles catégories de produits, et le modèle peut organiser ces articles sur la base de descriptions sans avoir besoin d'exemples étiquetés.
Le ZSL est idéal lorsque vous avez besoin de flexibilité et que la collecte de données étiquetées est trop coûteuse, trop lente ou impossible.
D'autre part, le FLS fonctionne bien lorsque vous pouvez fournir un petit nombre d'exemples étiquetés (généralement de 1 à 5) et que vous avez besoin que le modèle apprenne rapidement avec une meilleure précision.
Par exemple, si un chatbot reçoit un nouveau type de question, comme "Comment puis-je annuler mon abonnement ?", le fait de lui montrer quelques exemples de ce type de requête peut l'aider à classer avec précision les questions similaires.
Le FLS est idéal pour les situations où vous pouvez vous permettre de fournir quelques exemples étiquetés et où le modèle doit être performant, en particulier dans les tâches où la précision est importante, comme l'assistance à la clientèle ou l'imagerie médicale.
ZSL est utile dans de nombreux domaines. Voyons-en quelques-uns.
ZSL est largement utilisé dans la classification des textes, permettant aux modèles de classer les textes dans de nouvelles étiquettes sans formation préalable.
Par exemple, il peut classer les courriels comme étant des spams ou non spams sur la base des descriptions de ces catégories, sans avoir besoin d'exemples étiquetés. Cette capacité profite également aux chatbots en les aidant à comprendre les demandes des utilisateurs sans avoir à les former à toutes les requêtes possibles.
Dans le cadre de analyse des sentimentsZSL permet aux modèles de déterminer si un avis est positif ou négatif en interprétant uniquement la signification des étiquettes. Il joue également un rôle dans la modération des médias sociaux, en identifiant les contenus nuisibles ou trompeurs sur la base de descriptions textuelles, par exemple en détectant les informations erronées qualifiées de "diffusion de fausses allégations médicales", même si le modèle n'a jamais rencontré de tels cas auparavant.
Dans la classification des images, ZSL permet aux modèles de reconnaître des objets qu'ils n'ont jamais vus en associant des images à des descriptions textuelles. Des outils tels que CLIP peuvent identifier des objets inconnus, comme un "panda rouge", et aligner les images sur le texte, ce qui permet aux moteurs de recherche visuelle d'extraire plus efficacement des images sur la base des descriptions de l'utilisateur.
Le ZSL est également précieux pour la surveillance de l'environnement, où il détecte les changements dans l'imagerie satellitaire sans données d'entraînement étiquetées. Par exemple, il peut identifier l'exploitation forestière illégale en reconnaissant les zones décrites comme "une perte significative de la canopée dans les régions forestières", même si le modèle n'a jamais été explicitement formé sur les schémas de déforestation.
Dans le commerce de détail, ZSL aide à classer les nouveaux produits dans les catégories d'inventaire en utilisant uniquement des descriptions textuelles. Un modèle peut automatiquement attribuer de nouveaux éléments à des étiquettes telles que "matériaux écologiques", même si cette catégorie n'a pas été incluse lors de la formation.
Il résout également le problème du démarrage à froid des systèmes de recommandation en suggérant des produits ou des contenus sans données utilisateur préalables. Des algorithmes tels que ZESRec peuvent recommander des éléments provenant d'un ensemble de données entièrement nouveau sans aucun chevauchement avec des données vues précédemment.
Bien que ZSL soit flexible et puisse s'adapter à de nouvelles tâches, il est confronté à plusieurs défis.
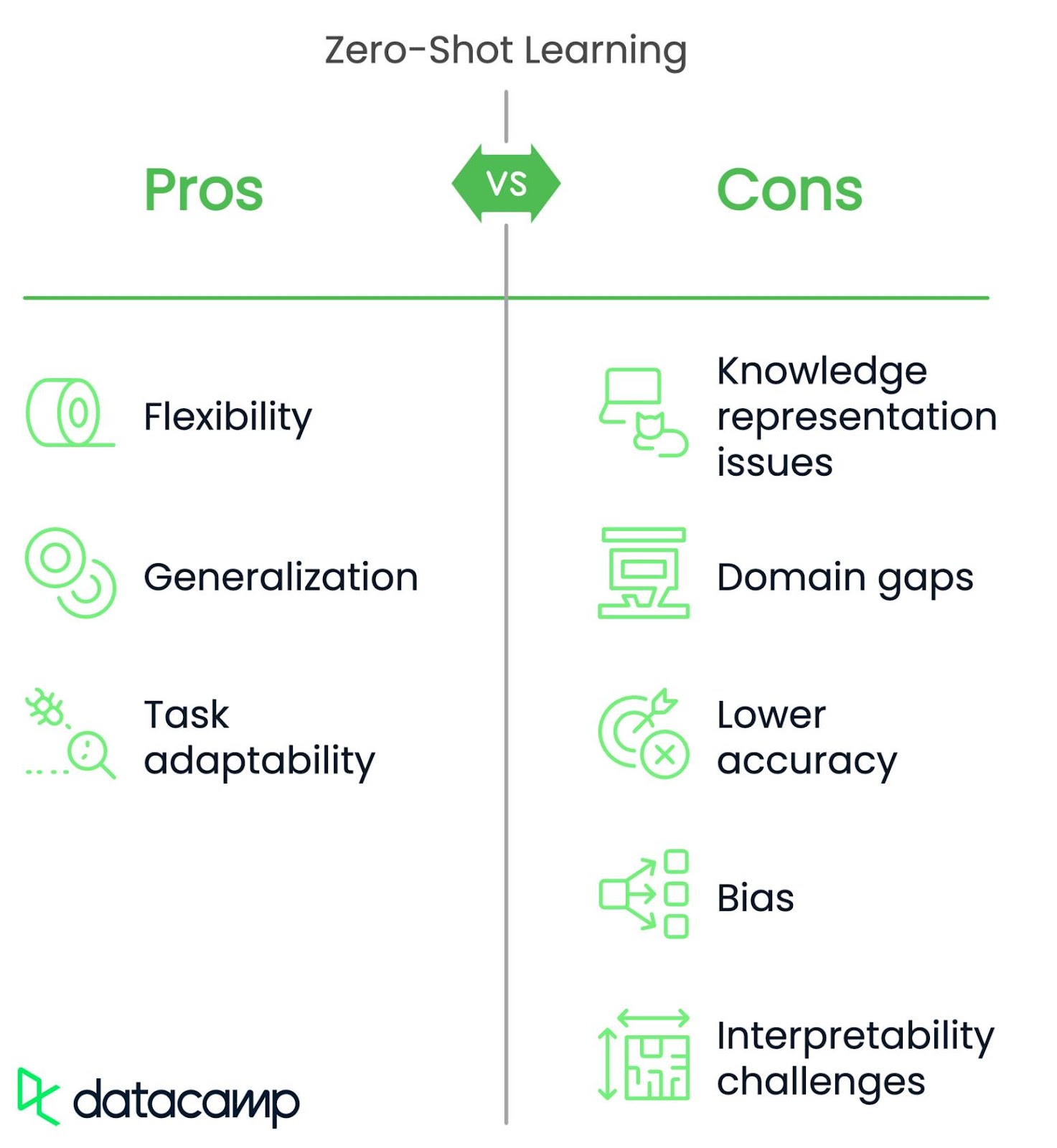
Les modèles ZSL peinent à représenter les différences détaillées ou subtiles entre les objets. Par exemple, un modèle peut confondre un léopard et un guépard parce que les deux sont décrits comme des "grands félins tachetés" et que les descriptions ne rendent pas compte des différences les plus fines.
Les modèles ZSL peuvent échouer lorsque la nouvelle tâche ou les nouvelles données sont très différentes de celles sur lesquelles ils ont été formés. Par exemple, un modèle formé pour reconnaître des objets ménagers peut ne pas réussir à identifier des outils médicaux parce qu'ils sont trop différents.
ZSL est souvent moins précis que l'apprentissage l'apprentissage supervisé (où le modèle est formé sur des données étiquetées) pour des tâches spécifiques. Une solution à ce problème consiste à combiner le ZSL avec des ajustements précis sur des données spécifiques afin d'améliorer la précision tout en conservant la flexibilité.
ZSL s'appuie sur des données pré-entraînées, qui peuvent contenir des biais. Cela peut souvent conduire à des prédictions injustes. Imagerie d'un modèle d'embauche à l'aide de ZSL. Il peut favoriser certaines catégories démographiques si les données préformées présentent des biais liés au sexe ou à la race. Une stratégie d'atténuation consiste à détecter et à réduire les biais dans les données à l'avance ou à utiliser des méthodes telles que le débiaisage contradictoire pour rendre le modèle plus équitable.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cursus