programa
Fundamentos del aprendizaje automático en Python
16 h
El campo de la ciencia de datos, en constante crecimiento, se nutre de datos, pero la adquisición de grandes conjuntos de datos etiquetados puede suponer un importante cuello de botella en el proceso de desarrollo de modelos. Aquí es donde interviene el aprendizaje de pocos ejemplos, que ofrece un enfoque revolucionario que nos permite extraer información valiosa de sólo un puñado de ejemplos.
A diferencia de los métodos tradicionales de aprendizaje supervisado, que exigen grandes cantidades de datos, el aprendizaje de pocos datos capacita a los modelos para aprender y adaptarse rápidamente, lo que los hace muy pertinentes en dominios en los que los datos son escasos, caros de recopilar o delicados por naturaleza.
Este artículo proporciona una exploración exhaustiva del aprendizaje de pocos disparos, profundizando en su importancia, mecanismos y diversas aplicaciones en varios sectores.
El aprendizaje de pocos ejemplos (FSL) es un subcampo del aprendizaje automático en el que los modelos aprenden a reconocer patrones y a hacer predicciones basándose en un número muy pequeño de ejemplos de entrenamiento. Esto contrasta con el aprendizaje supervisado tradicional, que a menudo requiere grandes cantidades de datos etiquetados para un entrenamiento eficaz.
La LSF hace más hincapié en la generalización que en la memorización. Uno de los primeros trabajos fue el de Tom B. Brown et al "Language Models are Few Shot Learners", que cuestionaba la necesidad de un ajuste exhaustivo.
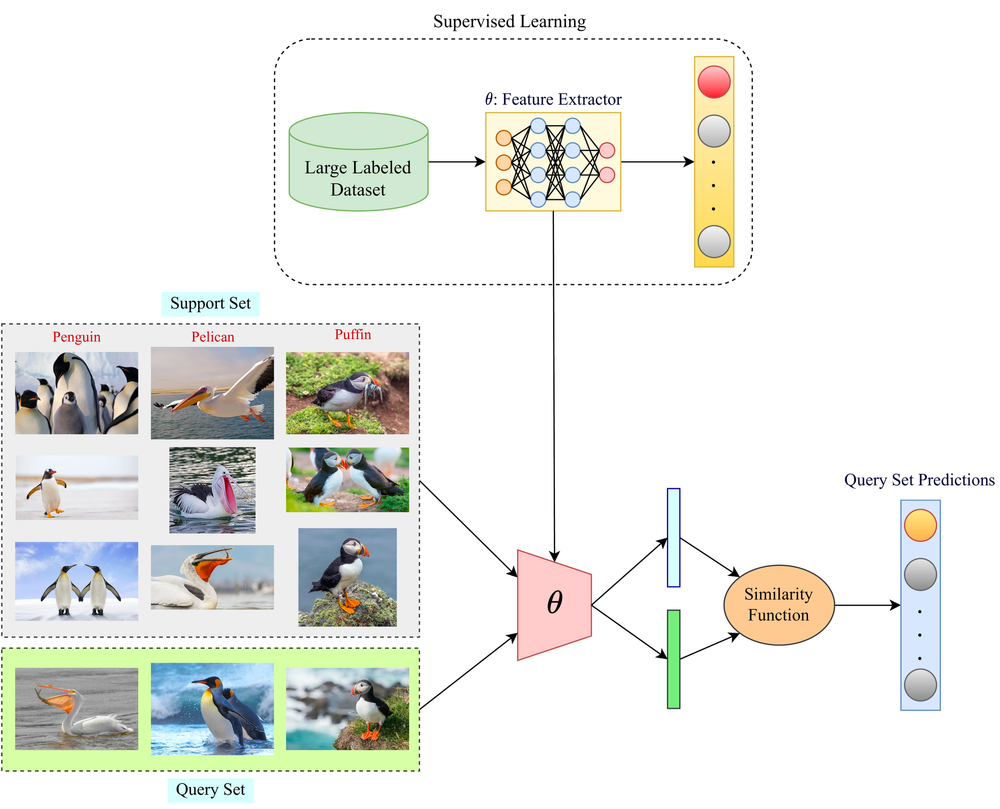
Diagrama que ilustra la diferencia entre los enfoques de aprendizaje supervisado y de aprendizaje de pocos disparos. La sección de aprendizaje supervisado muestra el uso de un gran conjunto de datos etiquetados para entrenar un modelo extractor de características, mientras que la sección de aprendizaje de pocos ejemplos demuestra el uso de un pequeño conjunto de ejemplos de apoyo y una función de similitud para hacer predicciones sobre un conjunto de consultas. Fuente: Paperspace
Piensa en un niño que aprende a identificar diferentes animales. Con sólo unos pocos ejemplos de perros, gatos y pájaros, podrán reconocer y distinguir rápidamente entre estas criaturas en el futuro, aunque se encuentren con razas o especies que no hayan visto antes.
Esta capacidad de generalizar a partir de datos limitados es un rasgo distintivo de la inteligencia humana, y es precisamente lo que pretende conseguir el aprendizaje de pocos datos.
La clave está en la capacidad de discernir la estructura y los rasgos subyacentes que definen una categoría.
Los seres humanos poseen una capacidad innata para extraer información esencial de experiencias limitadas y aplicar ese conocimiento a situaciones nuevas. Los modelos de aprendizaje de pocos datos intentan emular esto aprendiendo una comprensión general de la estructura subyacente de los datos a partir de experiencias anteriores.
Este conocimiento se aprovecha entonces para adaptarse rápidamente a nuevas tareas con una información adicional mínima, como el niño que reconoce una nueva raza de perro basándose en su conocimiento existente de los perros.
FSL ayuda al desarrollador a centrarse en el desarrollo del modelo en lugar de en la adquisición de datos. La capacidad de aprender a partir de datos limitados ofrece varias ventajas:
El aprendizaje de pocos disparos se engloba bajo el paraguas más amplio del aprendizaje de n disparos, que engloba diversas técnicas basadas en el número de ejemplos proporcionados:
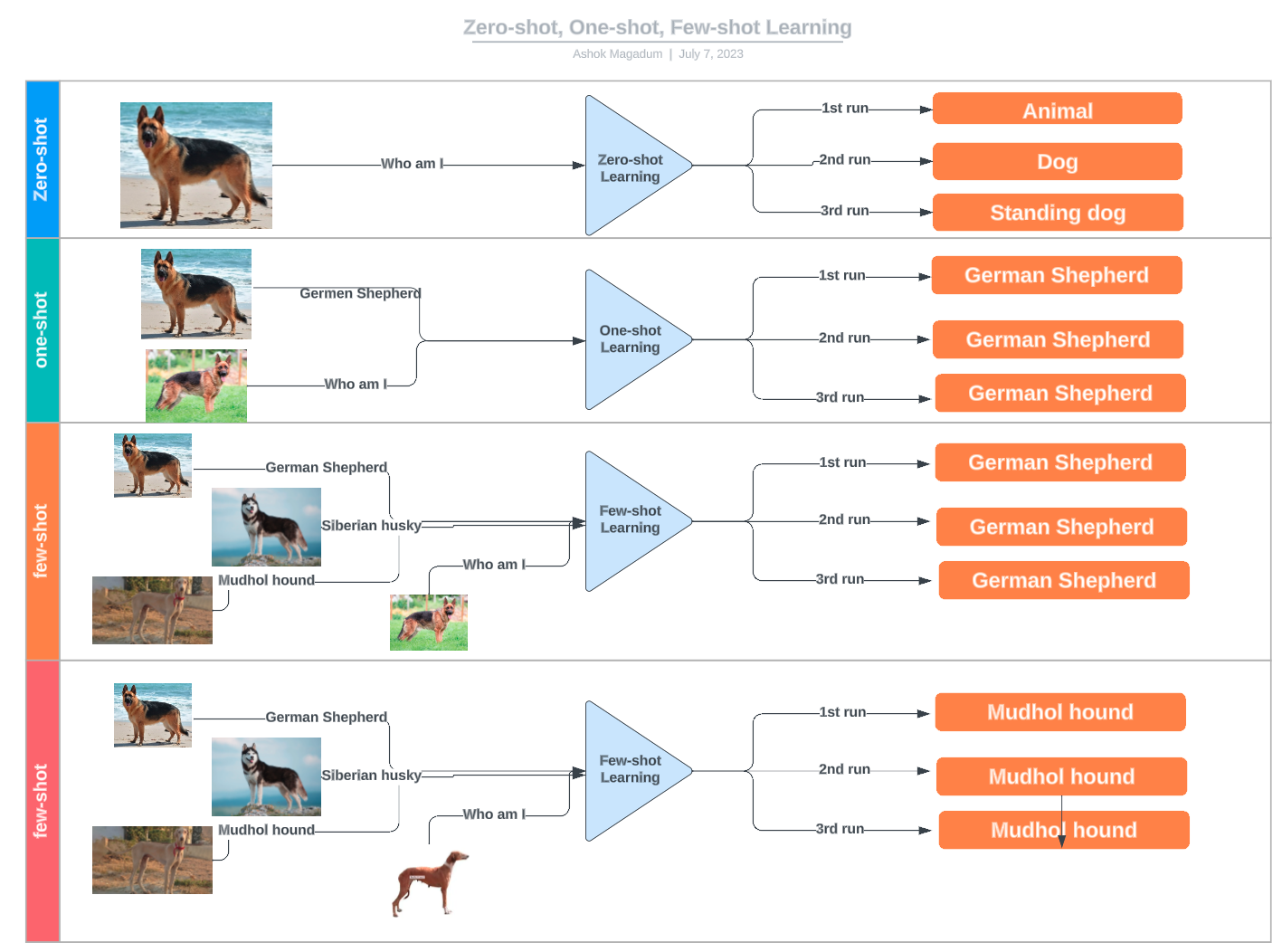
Diagrama que ilustra las diferencias entre el aprendizaje de disparo cero, de disparo único y de pocos disparos, utilizando ejemplos de clasificación de razas caninas. Fuente: LinkedIn
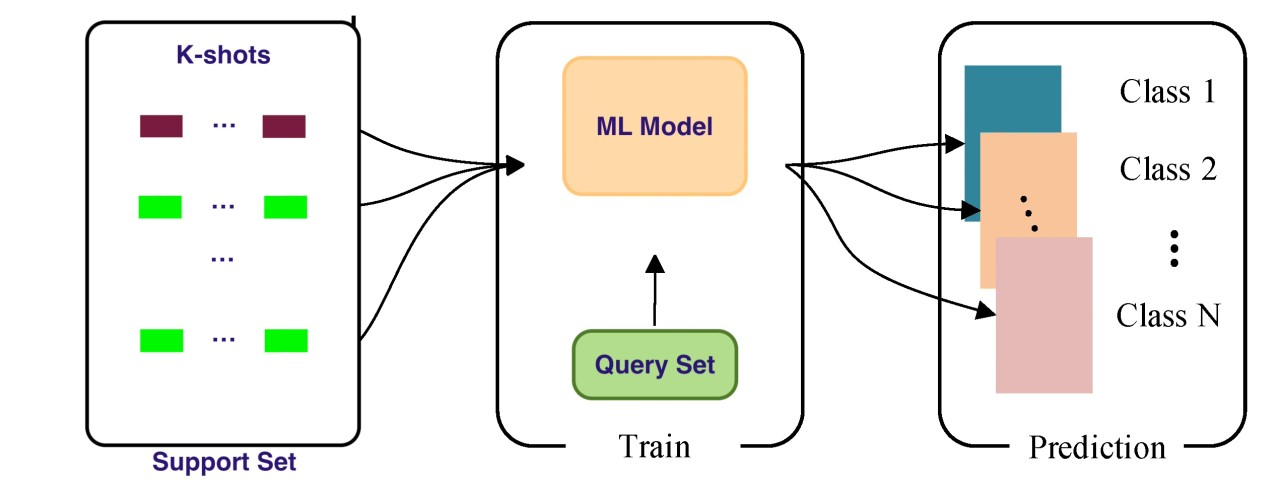
Diagrama que ilustra el proceso de aprendizaje de pocos disparos. Muestra un conjunto de apoyo que contiene ejemplos k para múltiples clases, un modelo de aprendizaje automático que se entrena en un conjunto de consulta, y el modelo que luego hace predicciones para nuevas instancias de datos a través de diferentes clases. Fuente: LinkedIn
A diferencia del aprendizaje supervisado tradicional, que depende de amplios conjuntos de datos de entrenamiento, los modelos de aprendizaje de pocos datos aprovechan el conocimiento previo y las experiencias de aprendizaje para adaptarse rápidamente a nuevas tareas con un mínimo de datos adicionales. Al discernir la estructura subyacente y las características destacadas que definen un concepto, estos modelos pueden generalizar eficazmente, haciendo predicciones precisas sobre nuevos casos con sólo unos pocos ejemplos.
A continuación, este conocimiento se aplica para adaptarse rápidamente a nuevas tareas mediante una función de similitud que puede mapear las clases de los conjuntos de consulta y apoyo con un mínimo de información adicional.
Por contexto, el conjunto de consultas se refiere aquí a las muestras de las categorías antiguas y nuevas, sobre las que el modelo generaliza y utiliza para evaluar el rendimiento. En cambio, el conjunto de apoyo está formado por las pocas muestras etiquetadas de cada nueva categoría de datos, que se utilizan para actualizar los parámetros del modelo:
MAML aprende una inicialización general del modelo que puede ajustarse para tareas específicas con sólo unos pocos pasos de gradiente. Es un enfoque de metaaprendizaje versátil y potente, que permite a los modelos adaptarse a nuevas tareas con notable eficacia.
Su fuerza reside en su capacidad para aprender una inicialización del modelo que facilita el aprendizaje rápido mediante unos pocos pasos de descenso gradiente en una nueva tarea.
Esta característica hace que el modelo sea "fácil de afinar", lo que le permite captar rápidamente las complejidades de tareas novedosas con un mínimo de datos.
El MAML funciona según el principio de aprender un conjunto de parámetros iniciales θ que son muy sensibles a los cambios en la tarea. Esta sensibilidad garantiza que pequeños ajustes de los parámetros pueden mejorar significativamente la función de pérdida de cualquier tarea extraída de la distribución de tareas p(T) cuando se actualiza en la dirección del gradiente de esa pérdida.
Aquí tienes un desglose del algoritmo MAML:
El aprendizaje métrico se centra en aprender una función de distancia que mida la similitud entre puntos de datos. Se centra en el aprendizaje de una función de distancia, denotada como d(x, x'), que mide la similitud entre los puntos de datos x y x'. Esto permite a los modelos clasificar nuevos puntos de datos comparándolos con unos pocos ejemplos conocidos.
El aprendizaje por transferencia aprovecha los conocimientos adquiridos en una tarea de origen para mejorar el rendimiento en una tarea de destino relacionada.
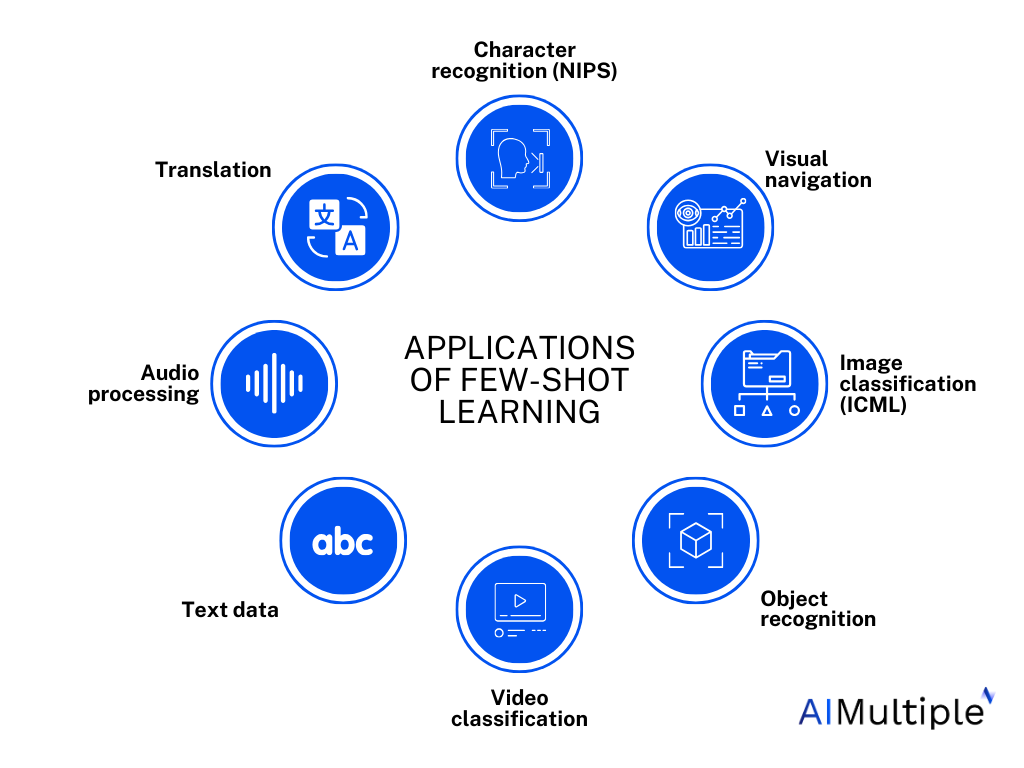
Un resumen de las aplicaciones de la LSF en diversos ámbitos. Fuente: AI Investigación múltiple
Las aplicaciones del aprendizaje de pocos disparos son amplias y de gran alcance, y abarcan campos tan diversos como la visión por ordenador, el procesamiento del lenguaje natural, la robótica y la asistencia sanitaria. En el ámbito de la visión por ordenador, por ejemplo, el aprendizaje de pocos disparos puede permitir a los sistemas reconocer objetos raros o identificar patrones oscuros en imágenes médicas con sólo un puñado de ejemplos de entrenamiento.
En el procesamiento del lenguaje natural, el aprendizaje de pocos disparos podría allanar el camino a modelos lingüísticos personalizados capaces de imitar el estilo de escritura o el dialecto únicos de un individuo, revolucionando la creación de contenidos y la comunicación. Además, encierra un inmenso potencial para preservar y traducir lenguas de escasos recursos, fomentando una mayor comprensión cultural e inclusividad.
Quizá una de las aplicaciones más transformadoras se encuentre en el descubrimiento de fármacos y la asistencia sanitaria. Al entrenar modelos con datos limitados de ensayos clínicos o casos de enfermedades raras, el aprendizaje de pocos datos podría acelerar el desarrollo de tratamientos que salvan vidas y permitir un diagnóstico más preciso, mejorando en última instancia los resultados de los pacientes.
A pesar de su inmenso potencial, el aprendizaje de pocos disparos no está exento de dificultades. Uno de los principales obstáculos es el riesgo de sobreajuste, en el que los modelos se especializan demasiado en los limitados datos de entrenamiento y no consiguen generalizarse eficazmente a nuevas instancias. Además, seleccionar la medida de similitud o la función de distancia adecuadas es crucial para un rendimiento preciso, y la ambigüedad de la tarea o los datos ruidosos pueden impedir aún más la eficacia del modelo.
Sin embargo, estos retos no han hecho sino alimentar una oleada de investigación e innovación en este campo. Enfoques como el meta-aprendizaje, el aprendizaje métrico y el aprendizaje por transferencia han surgido como estrategias prometedoras para mejorar las capacidades de aprendizaje de pocos aprendizajes. Técnicas como el Metaaprendizaje Diagnóstico de Modelos (MAML) y las Redes Prototípicas han demostrado un éxito notable en la adaptación rápida a nuevas tareas con datos mínimos.
A medida que el campo siga evolucionando, podemos esperar que surjan métodos de aprendizaje de pocos disparos aún más sofisticados y robustos, que amplíen los límites de lo que es posible con datos limitados. En última instancia, el verdadero poder del aprendizaje de pocos datos reside en su capacidad para democratizar la IA, haciéndola accesible a dominios y aplicaciones antes obstaculizados por la escasez de datos, y marcando el comienzo de una nueva era de inteligencia artificial eficiente en datos, adaptable e inclusiva.
El aprendizaje de pocos datos representa un avance significativo en el campo del aprendizaje automático, ya que nos permite extraer ideas a partir de datos limitados. Al comprender los distintos enfoques y aplicaciones, los profesionales noveles de los datos pueden aprovechar esta poderosa herramienta para abordar problemas del mundo real en diversos ámbitos.
A medida que continúe la investigación, podemos esperar que surjan técnicas de aprendizaje de pocos disparos aún más innovadoras y eficientes, que amplíen aún más los límites de la ciencia de datos.
Si te interesa dominar otros conceptos de aprendizaje automático, consulta nuestro itinerario profesional de Científico de Aprendizaje Automático con Python.
Sigue aprendiendo con DataCamp
programa
programa
Curso
blog
Kurtis Pykes
8 min
blog
Kurtis Pykes
9 min
blog
Natassha Selvaraj
15 min
Tutorial
Joanne Xiong
Tutorial
Moez Ali


