
programa
Ingeniero de datos en Python
40 h
Apache Arrow ayuda a diferentes herramientas y sistemas a compartir datos de forma rápida y sencilla. Almacena los datos en un formato especial basado en columnas que permanece en memoria, lo que hace que sea muy rápido trabajar con él.
En este tutorial, te guiaré a través de los fundamentos de Apache Arrow. Tendrás ejemplos prácticos para entender cómo funciona y cómo utilizarlo en tus proyectos.
Apache Arrowes una plataforma multilingüe de código abierto para el procesamiento de datos en memoria de alto rendimiento. Define un formato de memoria columnar estandardizado y optimizadopara las CPU modernas, que permite un análisis eficiente y un cálculo vectorizado.
Arrow también elimina la necesidad de serialización entre sistemas y lenguajes, lo que permite lecturas de copia cero y reduce la sobrecarga de procesamiento.
Como funciona bien con herramientas como pandas, Apache Spark y Dask, puedes mover los datos con el mínimo esfuerzo. Esto lo convierte en una opción excelente para cualquiera que construya sistemas rápidos y flexibles que necesiten manejar muchos datos.
Ahora, ¡exploremos Arrow con algunos ejemplos prácticos!
Apache Arrow es compatible con varios lenguajes, como C, C++, C#, Python, Rust, Java, JavaScript, Julia, Go, Ruby y R.
Funciona en Windows, macOS y distribuciones populares de Linux, como Debian, Ubuntu, CentOS y Red Hat Enterprise Linux.
En esta guía, lo utilizaremos con Python.
Veamos cómo instalar Apache Arrow para Python utilizando las ruedas binarias oficiales publicadas en PyPI. Estos pasos funcionan igual en Windows, macOS y Linux.
Abre tu terminal y ejecuta
python --versionSi esto devuelve un número de versión, estás listo. Si no, instala Python desde el sitio oficial.
pyarrow usando pipPara instalar Apache Arrow para Python, ejecuta:
pip install 'pyarrow==19.0.* ' La página * te garantiza que obtendrás la última versión del parche de la serie 19.0.
También te recomiendo que utilices pyarrow==19.0.* en tu archivo requirements.txt para mantener la coherencia entre entornos. Esto instalará pyarrow junto con las bibliotecas binarias Apache Arrow y Parquet C++ necesarias incluidas con la rueda.
Para instalar Arrow en otro idioma, consulta la documentación completa.
Puedes ejecutar este rápido fragmento de Python para comprobar si todo funciona:
import pyarrow as pa
# Create a simple Arrow array
data = pa.array([1, 2, 3, 4, 5])
print("Apache Arrow is installed and working!")
print("Arrow Array:", data)Si pyarrow está instalado correctamente, verás el arreglo impreso en tu terminal. Si no, el código arrojará un error.
Antes de profundizar en el código, vamos a entender cómo se construye Apache Arrow.
El formato columnar en memoria es una de las características más importantes de Apache Arrow. Define una estructura de datos en memoria independiente del lenguaje. Además, incluye la serialización de metadatos, un protocolo para el transporte de datos y una forma estándar de representar datos entre sistemas.
En un formato columnar, los datos se almacenan en columnas en lugar de filas, lo que difiere del almacenamiento tradicional basado en filas. Las distribuciones en columnas son populares para las cargas de trabajo analíticas porque son mucho más rápidas de escanear y procesar.
La imagen siguiente explica el formato:
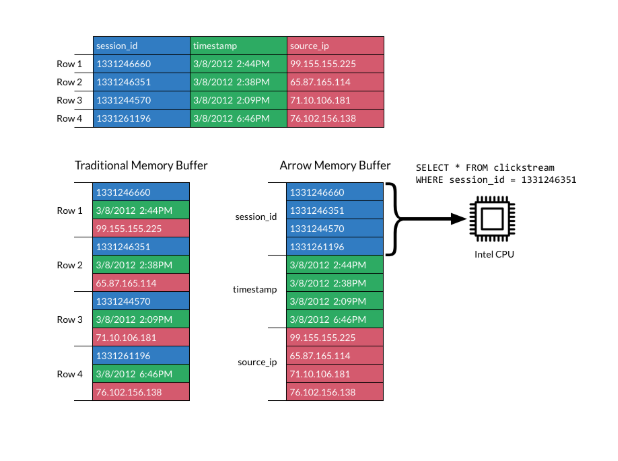
Formato columnar. Fuente: Documentación sobre Apache Arrow
El formato de Apache Arrow aumenta la eficiencia colocando las columnas en bloques de memoria contiguos. Esto admite modernas operaciones vectorizadas (SIMD), que aceleran el procesamiento de datos.
Al utilizar una disposición en columnas estándar, Arrow elimina la necesidad de que cada sistema defina su formato de datos interno. Eso reduce tanto la sobrecarga de serialización como la duplicación de esfuerzos.
Los sistemas pueden compartir datos más fácilmente, y los programadores pueden reutilizar algoritmos en distintos lenguajes.
Sin un formato compartido como Arrow, cada base de datos o herramienta tiene que serializar y deserializar los datos antes de pasarlos. Eso añade costes y complejidad. Y los algoritmos comunes tienen que reescribirse para la estructura de datos interna de cada sistema.
Arrow cambia esto normalizando cómo se representan los datos en la memoria.
Aunque los formatos columnares son excelentes para el rendimiento analítico y la localización en memoria, no están diseñados para actualizaciones frecuentes. no están diseñados para actualizaciones frecuentes.
Esto se debe a que el almacenamiento en columnas está optimizado para la lectura rápida, no para la modificación. Hacer cambios en los datos a menudo significa copiar o reasignar memoria, lo que puede ser lento y consumir muchos recursos.
Arrow se centra en la representación y serialización eficientes en memoria. Si tu caso de uso necesita una mutación frecuente de los datos, tendrás que gestionarlo a nivel de implementación.
Para profundizar en los formatos compatibles con Arrow, consulta esta guíade Apache Parquet, ideal para el almacenamienalmacenamiento de datos de columnas.
Apache Arrow proporciona dos estructuras de datos clave: Array y Table:
Array representa una sola columna de datos. Almacena los valores en un bloque de memoria contiguo, lo que permite un acceso rápido, un escaneo eficaz y la compatibilidad con optimizaciones a nivel de procesador como SIMD. Cada arreglo puede llevar también metadatos, como indicadores de nulos (mapas de bits) e información sobre el tipo de datos.Arrow Table representa un conjunto de datos 2D. Cada columna es un arreglo en trozos, y todas las columnas siguen un esquema compartido que define los nombres y tipos de los campos. Aunque los trozos pueden diferir entre columnas, el número total de elementos debe permanecer alineado para mantener la coherencia de las filas.Puedes pensar en él como en un DataFrame en pandas o R. Es tabular, eficiente y admite operaciones en varias columnas simultáneamente.
Veamos algunos ejemplos de creación de una Flecha Array y Table en Python.
Asegúrate de que tienes instalado pyarrow antes de ejecutar el código que aparece a continuación, siguiendo las instrucciones anteriores.
import pyarrow as pa
# Create an Arrow Array (single column)
data = pa.array([1, 2, 3, 4, 5])
print("Arrow Array:")
print(data)
Imprime un arreglo de flechas. Imagen del autor.
import pyarrow as pa
# Create an Arrow Table (multiple columns)
table = pa.table({
'column1': pa.array([1, 2, 3]),
'column2': pa.array(['a', 'b', 'c'])
})
print("\nArrow Table:")
print(table)
Imprimir una tabla de flechas. Imagen del autor.
Veamos cómo trabajar con Arreglos en Flecha y realizar operaciones habituales, como trocear, filtrar y comprobar metadatos.
Los Arreglos en Flecha funcionan con distintos tipos de datos, como cadenas, números en coma flotante y enteros. Aquí te explicamos cómo crearlos:
import pyarrow as pa
# Integer Array
int_array = pa.array([10, 20, 30], type=pa.int32())
print("Integer Array:")
print(int_array)
# String Array
string_array = pa.array(["apple", "banana", "cherry"], type=pa.string())
print("\nString Array:")
print(string_array)
# Floating-point Array
float_array = pa.array([1.1, 2.2, 3.3], type=pa.float64())
print("\nFloating-point Array:")
print(float_array)
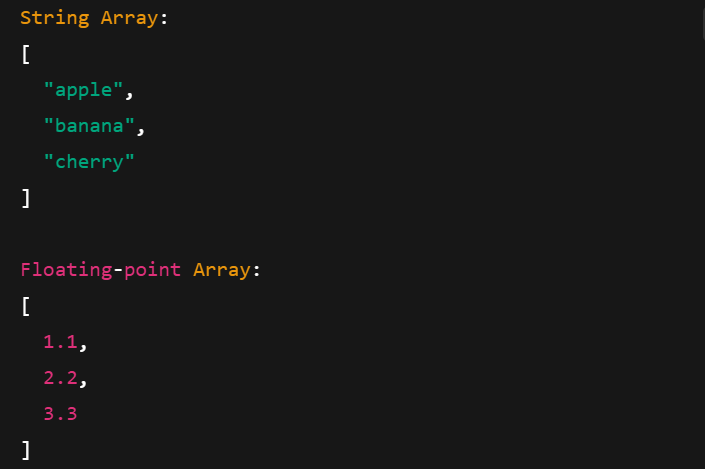
Imprimir Arreglos de flechas con distintos tipos de datos. Imagen del autor.
Veamos algunas operaciones habituales que puedes realizar con los Arreglos en Flecha.
Rebanar te permite tomar una subsección de un arreglo. Por ejemplo, puedes extraer elementos en rangos de índices concretos:
import pyarrow as pa
arr = pa.array([10, 20, 30, 40, 50])
# Slice from index 1 to 4 (3 elements: 20, 30, 40)
sliced = arr.slice(1, 3)
print("Original Array:", arr)
print("Sliced Array (1:4):", sliced)
Imprimir un arreglo de flechas troceado. Imagen del autor.
El filtrado utiliza una máscara booleana para conservar sólo los valores que cumplen una condición. También puedes acceder a metadatos como tipo, longitud y recuento de nulos.
import pyarrow.compute as pc
arr = pa.array([10, 20, 30, 40, 50])
# Create a boolean mask: Keep elements > 25
mask = pc.greater(arr, pa.scalar(25))
# Apply the filter
filtered = pc.filter(arr, mask)
print("Filtered Array (values > 25):", filtered)
print("Array Type:", arr.type)
print("Array Length:", len(arr))
print("Null Count:", arr.null_count)
print("Is Null Bitmap Buffers:", arr.buffers())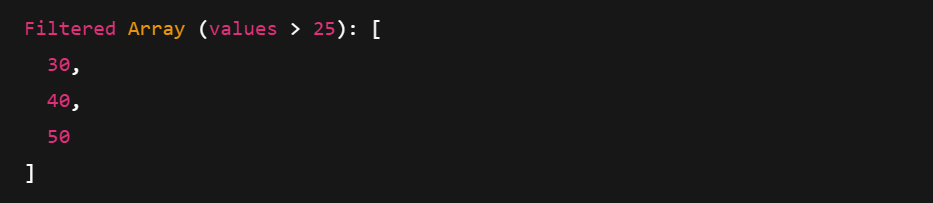
Imprimir un arreglo de flechas filtrado. Imagen del autor.

Impresión de metadatos de un arreglo de flechas. Imagen del autor.
Puedes crear Tablas Flecha a partir de Arreglos Flecha o directamente a partir de estructuras de datos nativas de Python, como los diccionarios. Veamos cómo.
Hay dos formas habituales de crear una tabla de flechas:
pa.table()Exploremos ambas vías una por una.
import pyarrow as pa
# Create individual Arrow Arrays
ids = pa.array([1, 2, 3])
names = pa.array(['Alice', 'Bob', 'Charlie'])
scores = pa.array([85.0, 92.5, 78.3])
# Combine them into a Table
table = pa.table({
'id': ids,
'name': names,
'score': scores
})
print("Arrow Table from Arrays:")
print(table)En el código anterior:
pa.table()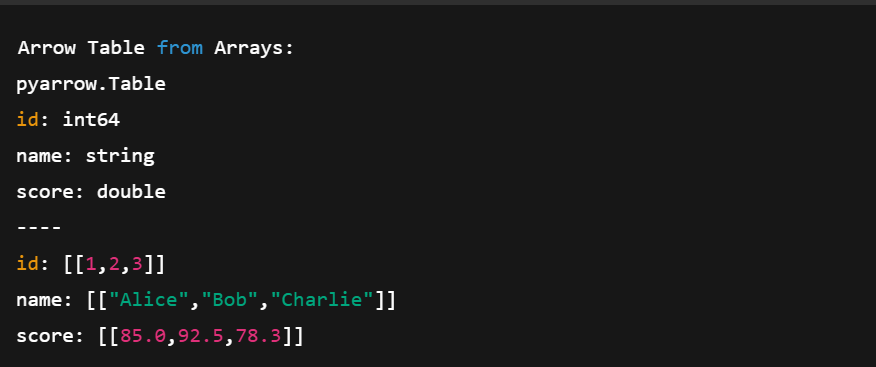
Crear una tabla de flechas utilizando varios arreglos de flechas. Imagen del autor.
Veamos ahora cómo crear una Tabla a partir de un diccionario Python.
# Create a table directly from Python data
data = {
'id': [4, 5, 6],
'name': ['Diana', 'Eve', 'Frank'],
'score': [88.0, 79.5, 91.2]
}
table2 = pa.table(data)
print("\nArrow Table from Dictionary:")
print(table2)Este método es más corto y compacto. No tenemos que definir los arreglos manualmente; Arrow lo hace por nosotros.
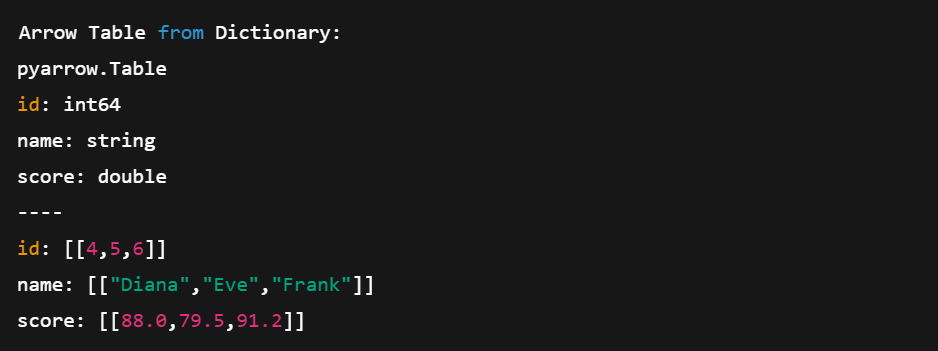
Crear una tabla de flechas directamente a partir de diccionarios de Python. Imagen del autor.
Uno de los mayores puntos fuertes de Arrow es su interoperabilidad. Puedes moverte fácilmente entre una Tabla Flecha y un DataFrame pandas. Veamos cómo hacerlo:
import pyarrow as pa
import pandas as pd
# Create an Arrow Table
data = {
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
}
arrow_table = pa.table(data)
# Convert Arrow Table to pandas DataFrame
df = arrow_table.to_pandas()
# Show the DataFrame
print(df)
Convertir una tabla Arrow en un DataFrame Pandas. Imagen del autor.
Veamos ahora cómo hacer lo contrario:
import pyarrow as pa
import pandas as pd
# Create a pandas DataFrame
df = pd.DataFrame({
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
})
# Convert pandas DataFrame to Arrow Table
arrow_table = pa.Table.from_pandas(df)
# Show the Arrow Table
print(arrow_table)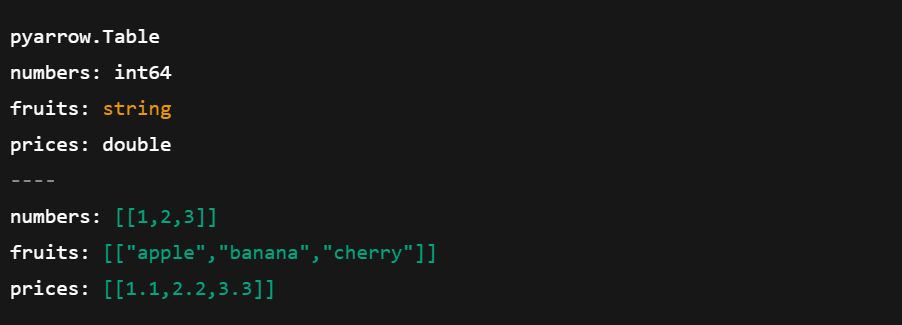
Convertir un DataFrame de pandas en una tabla de arreglo. Imagen del autor.
La serialización es el proceso de convertir objetos complejos o estructuras de datos en un flujo de bytes para almacenar o enviar datos entre sistemas. Pero Apache Arrow adopta un enfoque diferente.
Como Arrow utiliza un formato de memoria columnar diseñado para la velocidad, evita la serialización tradicional. En su lugar, se basa en unmodelo de memoria compartida , en el que varios procesos pueden acceder directamente a los mismos datos sin copiarlos ni convertirlos.
Esto es lo que hace:
Veamos cómo puedes guardar los datos de las Flechas utilizando el formato de archivo Feather y volver a cargarlos en una Tabla utilizando Python.
import pandas as pd
import pyarrow as pa
import pyarrow.feather as feather
# Create a sample pandas DataFrame
df = pd.DataFrame({
'id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie'],
'score': [95.5, 82.0, 77.5]
})
# Convert DataFrame to Arrow Table
table = pa.Table.from_pandas(df)
# Save Arrow Table to a Feather file
feather.write_feather(table, 'example.feather')
print("Arrow table saved to 'example.feather'")
Convertir DataFrame en tabla de flechas. Imagen del autor.
A continuación, podemos hacer lo contrario y cargar una Tabla de Flechas desde el archivo Pluma creado anteriormente.
import pyarrow.feather as feather
# Load the Feather file into an Arrow Table
loaded_table = feather.read_table('example.feather')
# (Optional) Convert back to pandas DataFrame
df_loaded = loaded_table.to_pandas()
# Print the loaded data
print(df_loaded)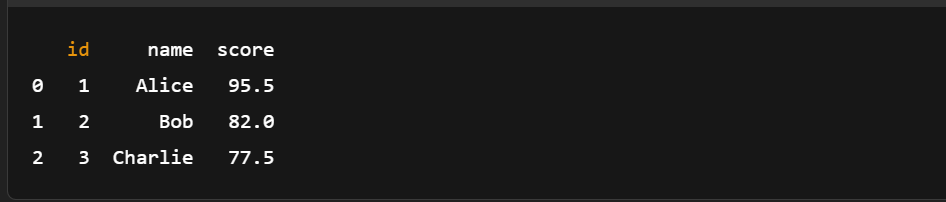
Cargar tabla de flechas desde un archivo de Pluma. Imagen del autor.
Como puedes ver, no es necesaria la serialización manual. Guardar y cargar datos de Flecha sólo requiere unas pocas líneas de código.
Si eres nuevo en pandas o necesitas un repaso, esta hoja de trucos de pandas es una gran compañera de Arrow para manipulaciones rápidas de datos.
Veamos un ejemplo real de lo rápido y eficaz que puede ser Arrow a la hora de cargar, filtrar y analizar un gran conjunto de datos.
Empezaremos creando un DataFrame de pandas con un millón de filas.
import pandas as pd
import pyarrow as pa
import pyarrow.compute as pc
import time
df = pd.DataFrame({
'id': range(1, 1_000_001), #assuming a dataset with a million rows
'value': pd.np.random.randint(1, 1000, size=1_000_000),
'category': pd.np.random.choice(['A', 'B', 'C'], size=1_000_000)
})start = time.time()
arrow_table = pa.Table.from_pandas(df)
end = time.time()
print(f"Conversion to Arrow Table took {end - start:.4f} seconds")# Example: Filter rows where 'value' > 990
start = time.time()
filtered_table = pc.filter(arrow_table, pc.greater(arrow_table['value'], pa.scalar(990)))
end = time.time()
# Result summary
print(f"Filtering took {end - start:.4f} seconds")
print(f"Filtered row count: {filtered_table.num_rows}")start = time.time()
filtered_df = filtered_table.to_pandas()
end = time.time()
print(f"Conversion to pandas DataFrame took {end - start:.4f} seconds")
Cargar un gran conjunto de datos en un arreglo. Imagen del autor.
El formato columnar de Arrow y sus funciones de cálculo SIMD la convierten en una excelente opción para operaciones en memoria a gran escala. Y gracias a la conversión a copia cero, volver a pandas es rápido y eficaz.
Para los flujos de trabajo en los que cargas datos antes de la conversión a Flecha, este cursosobre la ingestión de datos racionalizada con pandas puede optimizartu canalización.
También puedes utilizar la API de cálculo de Arrow para ejecutar análisis básicos. Aquí tienes una demostración rápida con un conjunto de datos de muestra más pequeño.
import pyarrow as pa
import pyarrow.compute as pc
# Sample data
data = {
'id': pa.array([1, 2, 3, 4, 5]),
'score': pa.array([85, 92, 76, 88, 95]),
'category': pa.array(['A', 'B', 'A', 'B', 'A'])
}
# Create Arrow Table
table = pa.table(data)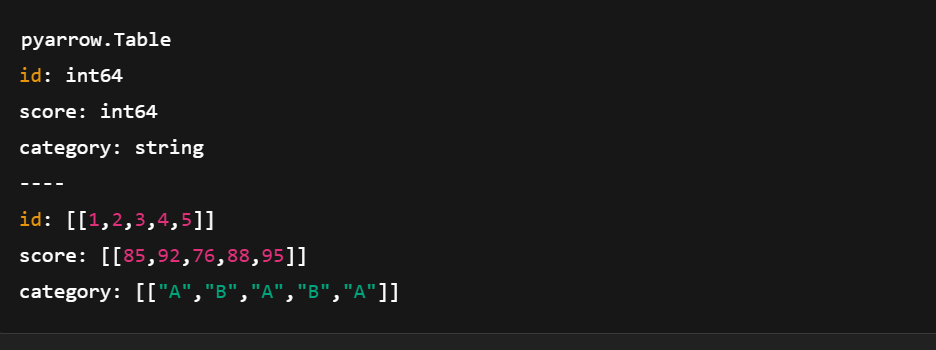
Crear una tabla de flechas con pyarrow.compute. Imagen del autor.
# Filter rows where score > 90
filter_mask = pc.greater(table['score'], pa.scalar(90))
filtered_table = pc.filter(table, filter_mask)
print(filtered_table.to_pandas())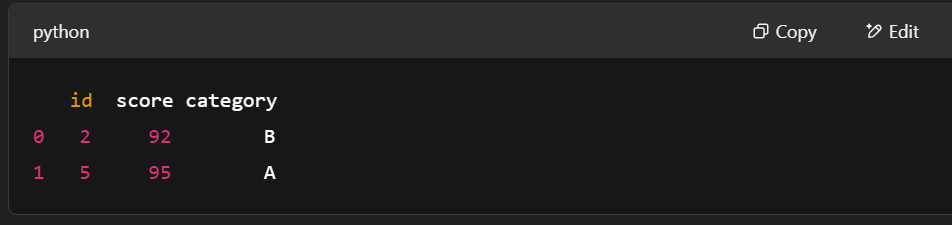
Filtrar filas con pyarrow.compute. Imagen del autor.
# Compute mean of the "score" column
mean_result = pc.mean(table['score'])
print("Mean score:", mean_result.as_py())![]()
Calcular la puntuación media con pyarrow.compute. Imagen del autor.
import pandas as pd
# Convert to pandas for more complex grouping
df = table.to_pandas()
grouped = df.groupby('category')['score'].mean()
print(grouped)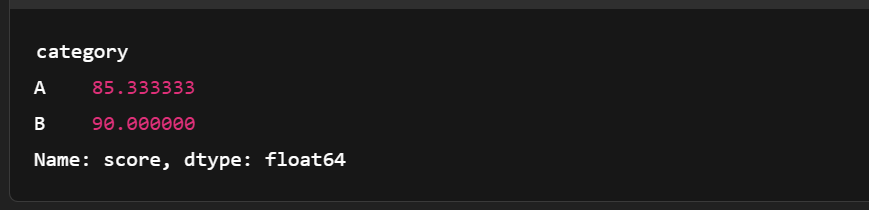
Agrupar la tabla de flechas. Imagen del autor.
He aquí una rápida comparación entre Apache Arrow y los pandas. Muestra dónde destaca la fila Arpara cargas de trabajo analíticas a gran escala.
|
Función |
Flecha Apache |
Pandas |
|
Formato de memoria |
Columnar, de copia cero, apretada |
Basado en filas (internamente utiliza arreglos NumPy) |
|
Velocidad (Filtrado, E/S) |
Más rápido gracias a SIMD y vectorización |
Más lento con datos grandes (copias, bucles Python) |
|
Uso de la memoria |
Más compacto y eficiente |
Mayor uso de memoria debido a la sobrecarga de Python |
|
Interoperabilidad |
Excelente (compartido en todas las lenguas/herramientas) |
Principalmente centrado en Python |
|
Caso práctico Ajustar |
Optimizado para grandes cargas de trabajo analíticas |
Genial para datos pequeños/medianos y creación de prototipos |
|
Serialización |
Pluma/Parquet con soporte de copia cero |
CSV/Excel, a menudo más lento y voluminoso |
Como hemos visto, las Tablas Flecha se integran bien con pandas, especialmente al realizar uniones. Explora más en este course sobre la unión de datos con pandas.
Arrow funciona bien con otras herramientas de datos, lo que facilita el traslado de datos entre entornos sin perder velocidad ni estructura.
En Apache Arrow, el Table es similar a un pandas DataFrame, ambos utilizan columnas con nombre de igual longitud. Pero las Tablas Flechadas van más allá. Admiten columnas anidadas, por lo que puedes representar estructuras de datos más complejas que en pandas.
Dicho esto, no todas las conversiones son perfectas. Aun así, convertir entre Arrow y pandas es sencillo. He aquí cómo:
Tabla de flechas → pandas DataFrame
table.to_pandas()pandas DataFrame → Tabla de flechas
pa.Table.from_pandas(df)Y ya está. Basta con una línea de código.
También puedes trabajar con otras estructuras pandas como Series utilizando Flecha. Consulta la documentación para saber más. Además, tanto Arrow como los pandas se benefician de un diseño orientado al rendimiento: aprende más en este curso sobre cómo escribir código eficiente con pandas.
Apache Arrow está integrado en Spark para acelerar el intercambio de datos entre la JVM (Máquina Virtual Java) y Python. Esto es muy útil para los usuarios de pandas y NumPy. No está activado por defecto, así que puede que tengas que cambiar algunos ajustes para activarlo. Pero una vez en marcha, Arrow mejora el rendimiento de varias maneras:
Para empezar, sigue la guía oficial de PySpark con Arrow.
Arrow también funciona bien con bibliotecas de machine learning como TensorFlow.
Su formato en columnas permite cargar y preprocesar los datos más rápidamente, pasos clave en el entrenamiento de modelos de machine learning. Y al manejar grandes conjuntos de datos de forma eficiente, Arrow ayuda a construir pipelines ML escalables que se entrenan más rápido y funcionan mejor en diferentes herramientas.
¡Y ya está! Repasamos las ideas básicas de Apache Arrow, analizamos en qué se diferencia de otros formatos de datos más tradicionales, cómo configurarlo y cómo trabajar con él en Python.
También exploramos ejemplos prácticos para construir Arrow Arrays y Tablas y vimos cómo Arrow ayuda a omitir la lenta serialización para mantener el procesamiento de datos rápido y eficiente.
Si te apetece seguir aprendiendo y profundizar en lo que hemos tratado, aquí tienes algunos recursos estupendos para seguir:
Vayas donde vayas, ¡esperamos que Arrow te ayude a crear flujos de trabajo más limpios y escalables!
¡Aprende más sobre ingeniería de datos con estos cursos!
programa
Curso
Curso
Tutorial
Natassha Selvaraj
Tutorial
Moez Ali
Tutorial
Natassha Selvaraj
Tutorial
Vidhi Chugh
Tutorial
Abid Ali Awan