
Cursus
Ingénieur de données en Python
40 h
Apache Arrow permet à différents outils et systèmes de partager des données rapidement et facilement. Il stocke les données dans un format spécial basé sur des colonnes qui restent en mémoire, ce qui le rend très rapide à utiliser.
Dans ce tutoriel, je vais vous présenter les bases d'Apache Arrow. Vous aurez des exemples pratiques pour comprendre comment il fonctionne et comment l'utiliser dans vos projets.
Apache Arrowest une plateforme open-source et multilingue pour le traitement de données en mémoire à haute performance. Il définit un format de mémoire en colonnes normalisé et optimisépour les processeurs modernes () afin de permettre des analyses efficaces et des calculs vectoriels.
Arrow supprime le besoin de sérialisation entre les systèmes et les langages, ce qui permet une lecture sans copie et réduit les coûts de traitement.
Parce qu'il fonctionne bien avec des outils comme pandas, Apache Spark et Dask, vous pouvez déplacer les données avec un minimum d'effort. Il s'agit donc d'un excellent choix pour tous ceux qui construisent des systèmes rapides et flexibles devant traiter de nombreuses données.
Explorons maintenant Arrow à l'aide de quelques exemples pratiques !
Apache Arrow prend en charge de nombreux langages, notamment C, C++, C#, Python, Rust, Java, JavaScript, Julia, Go, Ruby et R.
Il fonctionne sous Windows, macOS et les distributions Linux les plus courantes, telles que Debian, Ubuntu, CentOS et Red Hat Enterprise Linux.
Dans ce guide, nous l'utiliserons avec Python.
Voyons comment installer Apache Arrow pour Python en utilisant les roues binaires officielles publiées sur PyPI. Ces étapes sont les mêmes pour Windows, macOS et Linux.
Ouvrez votre terminal et exécutez :
python --versionSi vous obtenez un numéro de version, vous pouvez commencer. Si ce n'est pas le cas, installez Python à partir du site officiel.
pyarrow en utilisant pipPour installer Apache Arrow pour Python, exécutez :
pip install 'pyarrow==19.0.* ' Le site * vous permet d'obtenir la dernière version des correctifs de la série 19.0.
Je vous recommande également d'utiliser pyarrow==19.0.* dans votre fichier requirements.txt afin d'assurer la cohérence entre les différents environnements. Cela installera pyarrow ainsi que les bibliothèques binaires Apache Arrow et Parquet C++, fournies avec la roue.
Pour installer Arrow dans une autre langue, consultez la documentation complète.
Vous pouvez exécuter ce petit extrait Python pour vérifier que tout fonctionne :
import pyarrow as pa
# Create a simple Arrow array
data = pa.array([1, 2, 3, 4, 5])
print("Apache Arrow is installed and working!")
print("Arrow Array:", data)Si pyarrow est installé correctement, vous verrez le tableau s'afficher dans votre terminal. Si ce n'est pas le cas, le code génère une erreur.
Avant d'entrer dans le code, nous allons comprendre comment Apache Arrow est construit.
Le format colonne en mémoire est l'une des fonctionnalités les plus importantes d'Apache Arrow. Il définit une structure de données en mémoire indépendante du langage. En outre, il comprend la sérialisation des métadonnées, un protocole pour le transport des données et une méthode standard pour représenter les données entre les systèmes.
Dans un format en colonnes, les données sont stockées en colonnes et non en lignes, ce qui est différent du stockage traditionnel en lignes. Les présentations en colonnes sont très appréciées pour les charges de travail analytiques, car elles sont beaucoup plus rapides à scanner et à traiter.
L'image ci-dessous explique le format :
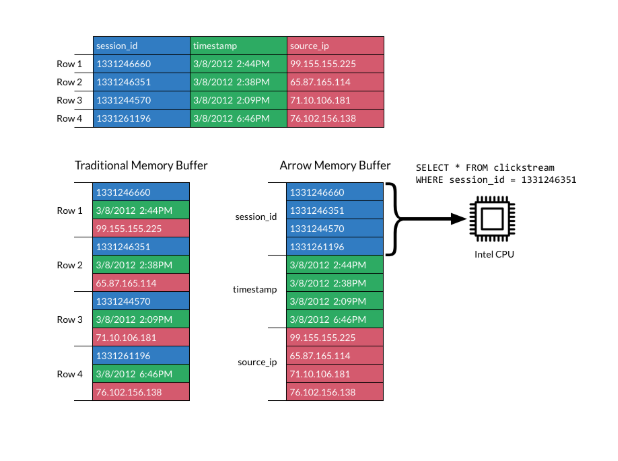
Format en colonnes. Source : Documentation sur Apache Arrow
Le format d'Apache Arrow améliore l'efficacité en répartissant les colonnes dans des blocs de mémoire contigus. Il prend en charge les opérations vectorielles modernes (SIMD), qui accélèrent le traitement des données.
En utilisant une disposition en colonnes standard, Arrow évite à chaque système de devoir définir son format de données interne. Cela réduit à la fois la charge de sérialisation et la duplication des efforts.
Les systèmes peuvent partager des données plus facilement et les développeurs peuvent réutiliser des algorithmes dans différents langages.
Sans un format partagé comme Arrow, chaque base de données ou outil doit sérialiser et désérialiser les données avant de les transmettre. Cela augmente les coûts et la complexité. De plus, les algorithmes communs doivent être réécrits pour la structure de données interne de chaque système.
Arrow change cela en en normalisant la façon dont les données sont représentées dans la mémoire.
Bien que les formats en colonnes soient excellents pour les performances analytiques et la localité de la mémoire, ils ne sont pas conçus pour des mises à jour fréquentes. ne sont pas conçus pour des mises à jour fréquentes.
En effet, le stockage en colonnes est optimisé pour une lecture rapide, et non pour une modification. Pour modifier des données, il faut souvent copier ou réattribuer de la mémoire, ce qui peut être lent et gourmand en ressources.
Arrow se concentre sur une représentation en mémoire et une sérialisation efficaces. Si votre cas d'utilisation nécessite une mutation fréquente des données, vous devrez gérer cela au niveau de l'implémentation.
Pour approfondir les formats compatibles avec Arrow, consultez ce guide sur Apache Parquet. Apache Parquet, idéal pour le stockage de données columpour le stockage de données en colonnes.
Apache Arrow fournit deux structures de données clés : Array et Table:
Array représente une seule colonne de données. Il stocke les valeurs dans un bloc de mémoire contiguë, ce qui permet un accès rapide, un balayage efficace et la prise en charge d'optimisations au niveau du processeur telles que SIMD. Chaque tableau peut également contenir des métadonnées telles que des indicateurs de nullité (bitmaps) et des informations sur le type de données.Arrow Table représente donc un ensemble de données en 2D. Chaque colonne est un tableau fractionné et toutes les colonnes suivent un schéma partagé qui définit les noms et les types de champs. Si les morceaux peuvent varier d'une colonne à l'autre, le nombre total d'éléments doit rester aligné pour que les lignes soient cohérentes.Vous pouvez l'assimiler à un DataFrame dans pandas ou R. Il est tabulaire, efficace et permet d'effectuer des opérations sur plusieurs colonnes simultanément.
Voyons quelques exemples de création d'une flèche Array et Table en Python.
Assurez-vous d'avoir installé pyarrow avant d'exécuter le code ci-dessous, en suivant les instructions précédentes.
import pyarrow as pa
# Create an Arrow Array (single column)
data = pa.array([1, 2, 3, 4, 5])
print("Arrow Array:")
print(data)
Imprimez un tableau de flèches. Image de l'auteur.
import pyarrow as pa
# Create an Arrow Table (multiple columns)
table = pa.table({
'column1': pa.array([1, 2, 3]),
'column2': pa.array(['a', 'b', 'c'])
})
print("\nArrow Table:")
print(table)
Imprimer un tableau de flèches. Image de l'auteur.
Voyons comment travailler avec les tableaux Arrow et effectuer des opérations courantes, telles que le découpage, le filtrage et la vérification des métadonnées.
Les tableaux de flèches fonctionnent avec différents types de données, notamment les chaînes de caractères, les nombres à virgule flottante et les nombres entiers. Voici comment les créer :
import pyarrow as pa
# Integer Array
int_array = pa.array([10, 20, 30], type=pa.int32())
print("Integer Array:")
print(int_array)
# String Array
string_array = pa.array(["apple", "banana", "cherry"], type=pa.string())
print("\nString Array:")
print(string_array)
# Floating-point Array
float_array = pa.array([1.1, 2.2, 3.3], type=pa.float64())
print("\nFloating-point Array:")
print(float_array)
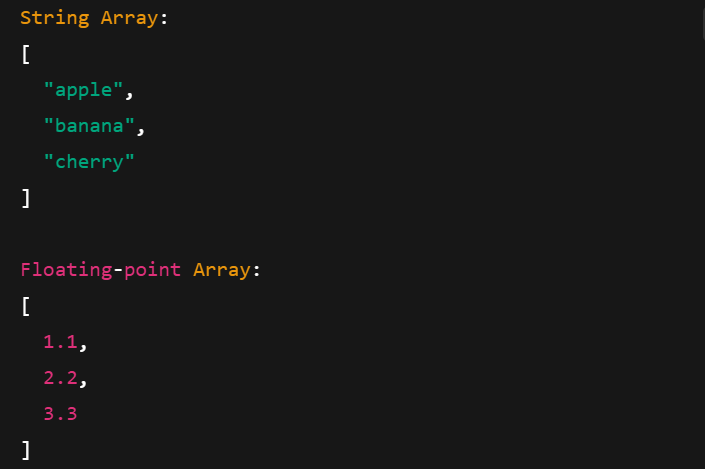
Impression de tableaux de flèches avec différents types de données. Image de l'auteur.
Examinons quelques opérations courantes que vous pouvez effectuer avec les tableaux de flèches.
Le découpage vous permet de saisir une sous-section d'un tableau. Par exemple, vous pouvez extraire des éléments dans des plages d'index spécifiques :
import pyarrow as pa
arr = pa.array([10, 20, 30, 40, 50])
# Slice from index 1 to 4 (3 elements: 20, 30, 40)
sliced = arr.slice(1, 3)
print("Original Array:", arr)
print("Sliced Array (1:4):", sliced)
Impression d'un tableau de flèches tranchées. Image par l'auteur.
Le filtrage utilise un masque booléen pour ne conserver que les valeurs qui correspondent à une condition. Vous pouvez également accéder à des métadonnées telles que le type, la longueur et le nombre de nullités.
import pyarrow.compute as pc
arr = pa.array([10, 20, 30, 40, 50])
# Create a boolean mask: Keep elements > 25
mask = pc.greater(arr, pa.scalar(25))
# Apply the filter
filtered = pc.filter(arr, mask)
print("Filtered Array (values > 25):", filtered)
print("Array Type:", arr.type)
print("Array Length:", len(arr))
print("Null Count:", arr.null_count)
print("Is Null Bitmap Buffers:", arr.buffers())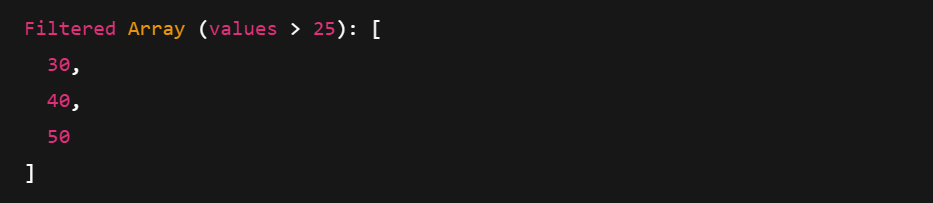
Impression d'un tableau de flèches filtré. Image par l'auteur.

Impression des métadonnées d'un tableau de flèches. Image par l'auteur.
Vous pouvez créer des tableaux Arrow à partir de tableaux Arrow ou directement à partir de structures de données natives de Python comme les dictionnaires. Voyons comment.
Il existe deux façons courantes de créer un tableau fléché :
pa.table()Explorons les deux voies l'une après l'autre.
import pyarrow as pa
# Create individual Arrow Arrays
ids = pa.array([1, 2, 3])
names = pa.array(['Alice', 'Bob', 'Charlie'])
scores = pa.array([85.0, 92.5, 78.3])
# Combine them into a Table
table = pa.table({
'id': ids,
'name': names,
'score': scores
})
print("Arrow Table from Arrays:")
print(table)Dans le code ci-dessus :
pa.table()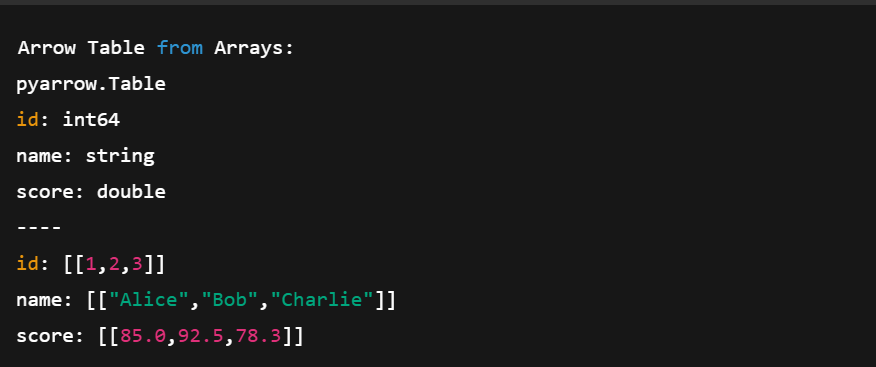
Création d'un tableau de flèches à l'aide de plusieurs tableaux de flèches. Image de l'auteur.
Voyons maintenant comment créer un tableau à partir d'un dictionnaire Python.
# Create a table directly from Python data
data = {
'id': [4, 5, 6],
'name': ['Diana', 'Eve', 'Frank'],
'score': [88.0, 79.5, 91.2]
}
table2 = pa.table(data)
print("\nArrow Table from Dictionary:")
print(table2)Cette méthode est plus courte et plus compacte. Nous n'avons pas besoin de définir manuellement les tableaux ; Arrow s'en charge pour nous.
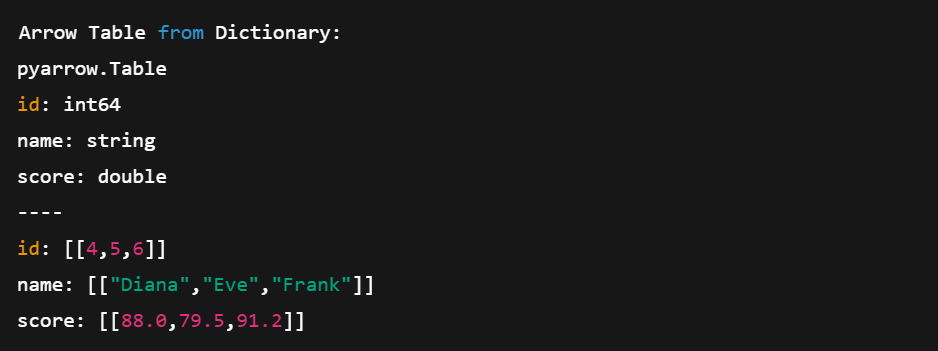
Création d'un tableau de flèches directement à partir des dictionnaires Python. Image de l'auteur.
L'un des principaux atouts d'Arrow est son interopérabilité. Vous pouvez facilement passer d'un tableau Arrow à un DataFrame pandas. Voyons comment procéder :
import pyarrow as pa
import pandas as pd
# Create an Arrow Table
data = {
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
}
arrow_table = pa.table(data)
# Convert Arrow Table to pandas DataFrame
df = arrow_table.to_pandas()
# Show the DataFrame
print(df)
Conversion d'un tableau Arrow en DataFrame Pandas. Image de l'auteur.
Voyons maintenant comment faire l'inverse :
import pyarrow as pa
import pandas as pd
# Create a pandas DataFrame
df = pd.DataFrame({
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
})
# Convert pandas DataFrame to Arrow Table
arrow_table = pa.Table.from_pandas(df)
# Show the Arrow Table
print(arrow_table)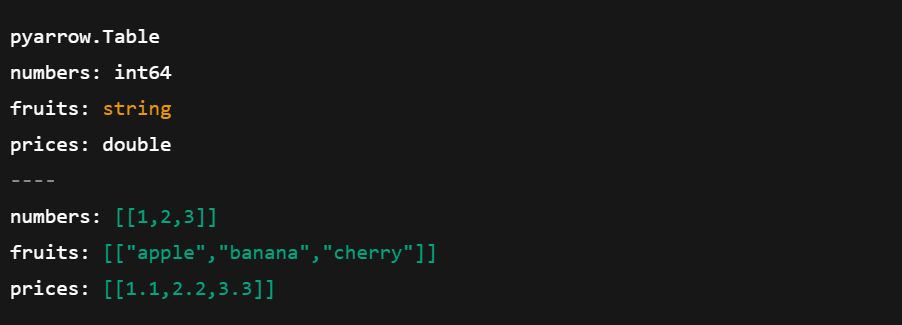
Conversion de pandas DataFrame en tableau. Image de l'auteur.
La sérialisation est le processus de conversion d'objets complexes ou de structures de données en un flux d'octets pour stocker ou envoyer des données entre systèmes. Mais Apache Arrow adopte une approche différente.
Comme Arrow utilise un format de mémoire en colonnes conçu pour la vitesse, il évite la sérialisation traditionnelle. Il s'appuie au contraire sur unmodèle de mémoire partagée , dans lequel plusieurs processus peuvent accéder directement aux mêmes données sans les copier ou les convertir.
Voici ce qu'il fait :
Voyons comment vous pouvez enregistrer les données Arrow à l'aide du format de fichier Feather et les charger à nouveau dans un tableau à l'aide de Python.
import pandas as pd
import pyarrow as pa
import pyarrow.feather as feather
# Create a sample pandas DataFrame
df = pd.DataFrame({
'id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie'],
'score': [95.5, 82.0, 77.5]
})
# Convert DataFrame to Arrow Table
table = pa.Table.from_pandas(df)
# Save Arrow Table to a Feather file
feather.write_feather(table, 'example.feather')
print("Arrow table saved to 'example.feather'")
Conversion d'un DataFrame en tableau Arrow. Image de l'auteur.
Ensuite, nous pouvons faire l'inverse et charger un tableau de flèches à partir du fichier Plume créé précédemment.
import pyarrow.feather as feather
# Load the Feather file into an Arrow Table
loaded_table = feather.read_table('example.feather')
# (Optional) Convert back to pandas DataFrame
df_loaded = loaded_table.to_pandas()
# Print the loaded data
print(df_loaded)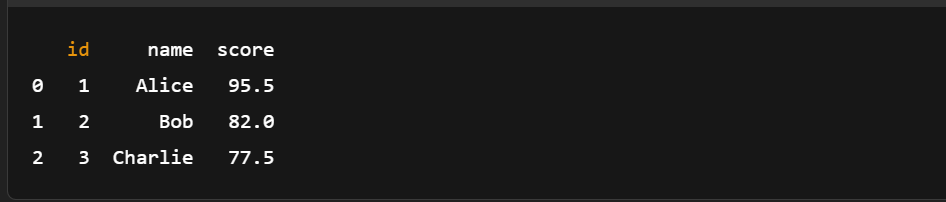
Chargement du tableau des flèches à partir d'un fichier Plume. Image de l'auteur.
Comme vous pouvez le constater, il n'est pas nécessaire de procéder à une sérialisation manuelle. L'enregistrement et le chargement des données Arrow ne nécessitent que quelques lignes de code.
Si vous êtes novice en matière de pandas ou si vous avez besoin d'une remise à niveau, cet aide-mémoire sur les pandas est un excellent compagnon d'Arrow pour les manipulations rapides de données.
Voyons un exemple concret de la rapidité et de l'efficacité avec lesquelles Arrow peut charger, filtrer et analyser un grand ensemble de données.
Nous commencerons par créer un DataFrame pandas d'un million de lignes.
import pandas as pd
import pyarrow as pa
import pyarrow.compute as pc
import time
df = pd.DataFrame({
'id': range(1, 1_000_001), #assuming a dataset with a million rows
'value': pd.np.random.randint(1, 1000, size=1_000_000),
'category': pd.np.random.choice(['A', 'B', 'C'], size=1_000_000)
})start = time.time()
arrow_table = pa.Table.from_pandas(df)
end = time.time()
print(f"Conversion to Arrow Table took {end - start:.4f} seconds")# Example: Filter rows where 'value' > 990
start = time.time()
filtered_table = pc.filter(arrow_table, pc.greater(arrow_table['value'], pa.scalar(990)))
end = time.time()
# Result summary
print(f"Filtering took {end - start:.4f} seconds")
print(f"Filtered row count: {filtered_table.num_rows}")start = time.time()
filtered_df = filtered_table.to_pandas()
end = time.time()
print(f"Conversion to pandas DataFrame took {end - start:.4f} seconds")
Chargement d'un grand ensemble de données dans un tableau. Image de l'auteur.
Le format en colonnes d'Arrow et les fonctions de calcul à base de SIMD en font un excellent choix pour les opérations en mémoire à grande échelle. Et grâce à la conversion sans copie, le retour à pandas est rapide et efficace.
Pour les flux de travail où vous chargez des données avant la conversion Arrow, ce courssur l'ingestion de données rationalisée avec pandas peut optimiservotre pipeline.
Vous pouvez également utiliser l'API de calcul d'Arrow pour effectuer des analyses de base. Voici une démonstration rapide avec un petit échantillon de données.
import pyarrow as pa
import pyarrow.compute as pc
# Sample data
data = {
'id': pa.array([1, 2, 3, 4, 5]),
'score': pa.array([85, 92, 76, 88, 95]),
'category': pa.array(['A', 'B', 'A', 'B', 'A'])
}
# Create Arrow Table
table = pa.table(data)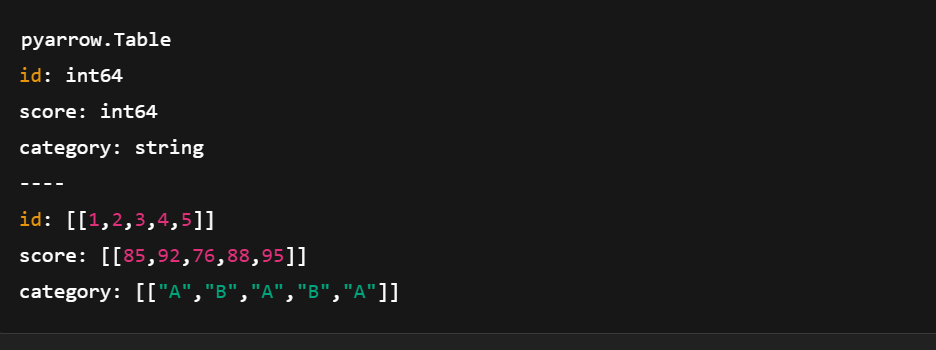
Création d'un tableau de flèches à l'aide de pyarrow.compute. Image de l'auteur.
# Filter rows where score > 90
filter_mask = pc.greater(table['score'], pa.scalar(90))
filtered_table = pc.filter(table, filter_mask)
print(filtered_table.to_pandas())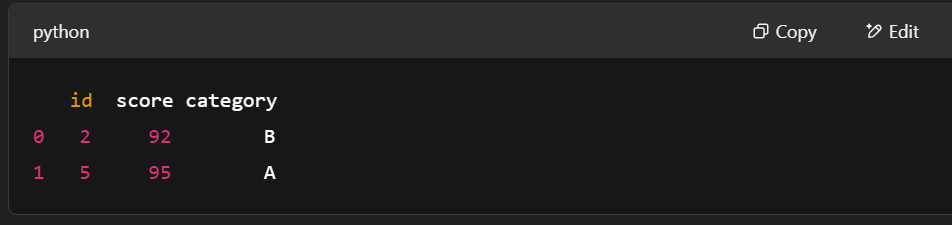
Filtrer les lignes en utilisant pyarrow.compute. Image de l'auteur.
# Compute mean of the "score" column
mean_result = pc.mean(table['score'])
print("Mean score:", mean_result.as_py())![]()
Calcul du score moyen à l'aide de pyarrow.compute. Image de l'auteur.
import pandas as pd
# Convert to pandas for more complex grouping
df = table.to_pandas()
grouped = df.groupby('category')['score'].mean()
print(grouped)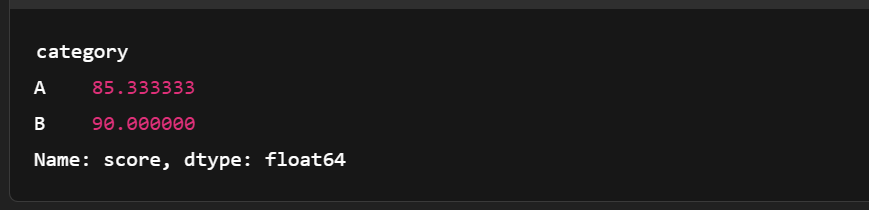
Regroupement du tableau des flèches. Image de l'auteur.
Voici une comparaison rapide entre Apache Arrow et pandas. Il montre où la rangée Arse distingue pour les charges de travail analytiques à grande échelle.
|
Fonctionnalité |
Flèche Apache |
Pandas |
|
Format de la mémoire |
Colonnaires, sans copie, très serrés |
Basé sur des lignes (utilise en interne des tableaux NumPy) |
|
Vitesse (filtrage, E/S) |
Plus rapide grâce au SIMD et à la vectorisation |
Plus lent sur les données volumineuses (copies, boucles Python) |
|
Utilisation de la mémoire |
Plus compact, plus efficace |
Utilisation plus importante de la mémoire en raison de la surcharge de Python |
|
Interopérabilité |
Excellent (partagé entre les langues/outils) |
Principalement centré sur Python |
|
Cas d'utilisation Fit |
Optimisé pour les charges de travail analytiques importantes |
Idéal pour les petites/moyennes données et le prototypage |
|
Sérialisation |
Plume/Parquet avec prise en charge de la copie zéro |
CSV/Excel, souvent plus lent et plus volumineux |
Comme nous l'avons vu, les tableaux fléchés s'intègrent bien à pandas, notamment lors de l'exécution de jointures. Pour en savoir plus, consultez cette pagerse sur l'assemblage de données avec pandas.
Arrow peut fonctionner avec d'autres outils de données, ce qui facilite le transfert des données entre les environnements sans perte de vitesse ou de structure.
Dans Apache Arrow, Table est similaire à pandas DataFrame, les deux utilisent des colonnes nommées de même longueur. Mais les tableaux Arrow vont plus loin. Ils prennent en charge les colonnes imbriquées, ce qui vous permet de représenter des structures de données plus complexes qu'avec pandas.
Cela dit, toutes les conversions ne se font pas sans heurts. Pourtant, la conversion entre Arrow et les pandas est simple. Voici comment :
Tableau de flèches → pandas DataFrame
table.to_pandas()pandas DataFrame → Tableau fléché
pa.Table.from_pandas(df)Et c'est tout ! Une ligne de code suffit.
Vous pouvez également travailler avec d'autres structures pandas telles que Series en utilisant Arrow. Consultez la documentation pour en savoir plus. De plus, Arrow et pandas bénéficient d'une conception axée sur les performances - apprenez-en plus dans ce cours sur l' écriture d'un code efficace avec pandas.
Apache Arrow est intégré à Spark pour accélérer l'échange de données entre la JVM (machine virtuelle Java) et Python. Ceci est très utile pour les utilisateurs de pandas et de NumPy. Il n'est pas activé par défaut, il se peut donc que vous deviez modifier certains paramètres pour l'activer. Mais une fois qu'il fonctionne, Arrow améliore les performances de plusieurs façons :
Pour commencer, suivez le guide officiel PySpark with Arrow.
Arrow fonctionne également bien avec des bibliothèques d'apprentissage automatique comme TensorFlow.
Son format en colonnes permet d'accélérer le chargement et le prétraitement des données, étapes clés de la formation des modèles d'apprentissage automatique. En traitant efficacement les grands ensembles de données, Arrow aide à construire des pipelines ML évolutifs qui s'entraînent plus rapidement et fonctionnent mieux avec différents outils.
Et c'est tout ! Nous avons passé en revue les idées fondamentales qui sous-tendent Apache Arrow, examiné en quoi il est différent des formats de données plus traditionnels, comment le configurer et comment travailler avec lui en Python.
Nous avons également exploré des exemples pratiques de construction de tableaux et de matrices Arrow et nous avons vu comment Arrow permet d'éviter une sérialisation lente pour que le traitement des données reste rapide et efficace.
Si vous souhaitez continuer à apprendre et à approfondir ce que nous avons abordé, voici d'excellentes ressources à consulter :
Quelle que soit votre prochaine étape, nous espérons qu'Arrow vous aidera à construire des flux de travail plus propres et plus évolutifs !
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cursus
Cours
Cours