
Lernpfad
Dateningenieur in Python
40 Std.
Mit Apache Arrow können verschiedene Tools und Systeme schnell und einfach Daten austauschen. Es speichert Daten in einem speziellen spaltenbasierten Format, das im Speicher bleibt und dadurch sehr schnell ist.
In diesem Lernprogramm führe ich dich durch die Grundlagen von Apache Arrow. Du bekommst praktische Beispiele, um zu verstehen, wie es funktioniert und wie du es in deinen Projekten einsetzen kannst.
Apache Arrowist eine quelloffene, sprachübergreifende Plattform für leistungsstarke In-Memory-Datenverarbeitung. Sie definiert einandardisiertes, spaltenförmiges Speicherformat, das für moderne CPUs optimiert ist und effiziente Analysen und vektorisierte Berechnungen ermöglicht.
Arrow macht auch die Notwendigkeit der Serialisierung zwischen Systemen und Sprachen, was das Lesen von Null-Kopien ermöglicht und den Verarbeitungsaufwand verringert.
Da es gut mit Tools wie Pandas, Apache Spark und Dask zusammenarbeitet, kannst du Daten mit minimalem Aufwand verschieben. Das macht sie zu einer ausgezeichneten Wahl für alle, die schnelle, flexible Systeme bauen, die viele Daten verarbeiten müssen.
Lass uns Arrow mit einigen praktischen Beispielen erkunden!
Apache Arrow unterstützt mehrere Sprachen, darunter C, C++, C#, Python, Rust, Java, JavaScript, Julia, Go, Ruby und R.
Es funktioniert unter Windows, macOS und gängigen Linux-Distributionen wie Debian, Ubuntu, CentOS und Red Hat Enterprise Linux.
In diesem Leitfaden werden wir es mit Python verwenden.
Sehen wir uns an, wie du Apache Arrow für Python mit den offiziellen Binärrädern installierst, die auf PyPI veröffentlicht wurden. Diese Schritte funktionieren unter Windows, macOS und Linux auf die gleiche Weise.
Öffne dein Terminal und führe es aus:
python --versionWenn dies eine Versionsnummer ergibt, kannst du loslegen. Wenn nicht, installiere Python von der offiziellen Seite.
pyarrow mit PipUm Apache Arrow für Python zu installieren, führst du aus:
pip install 'pyarrow==19.0.* ' Die * stellt sicher, dass du die neueste Patch-Version der 19.0-Serie erhältst.
Ich empfehle außerdem, pyarrow==19.0.* in deiner requirements.txt Datei zu verwenden, damit die Dinge in verschiedenen Umgebungen einheitlich bleiben. Dadurch wird pyarrow zusammen mit den erforderlichen Apache Arrow- und Parquet C++-Binärbibliotheken installiert, die mit dem Rad gebündelt sind.
Um Arrow für eine andere Sprache zu installieren, sieh dir die vollständige Dokumentation an.
Du kannst dieses schnelle Python-Snippet ausführen, um zu überprüfen, ob alles funktioniert:
import pyarrow as pa
# Create a simple Arrow array
data = pa.array([1, 2, 3, 4, 5])
print("Apache Arrow is installed and working!")
print("Arrow Array:", data)Wenn pyarrow richtig installiert ist, siehst du das Array in deinem Terminal ausgedruckt. Wenn nicht, wird der Code einen Fehler ausgeben.
Bevor wir tiefer in den Code einsteigen, wollen wir verstehen, wie Apache Arrow aufgebaut ist.
Das In-Memory-Spaltenformat ist eine der wichtigsten Funktionen von Apache Arrow. Sie definiert eine sprachunabhängige In-Memory-Datenstruktur. Darüber hinaus beinhaltet es die Serialisierung von Metadaten, ein Protokoll für den Datentransport und eine Standardmethode zur Darstellung von Daten in verschiedenen Systemen.
In einem spaltenbasierten Format werden die Daten in Spalten statt in Zeilen gespeichert, was sich von der traditionellen zeilenbasierten Speicherung unterscheidet. Spaltenförmige Layouts sind bei analytischen Workloads beliebt, weil sie viel schneller zu scannen und zu verarbeiten sind.
Das Bild unten erklärt das Format:
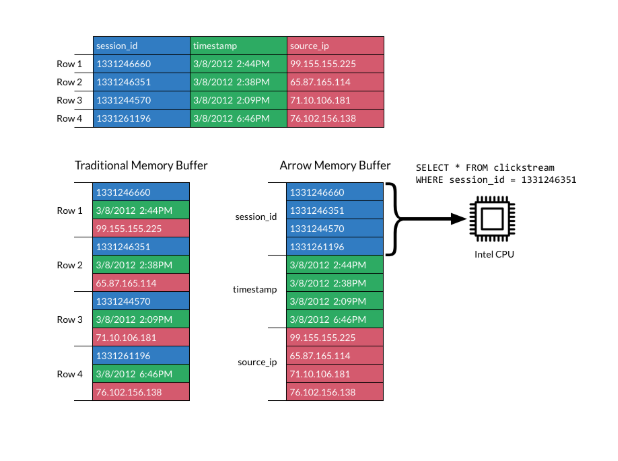
Säulenförmiges Format. Quelle: Apache Arrow Dokumente
Das Format von Apache Arrow steigert die Effizienz, indem es Spalten in zusammenhängende Speicherblöckelegt . Dies unterstützt moderne vektorisierte (SIMD) Operationen, die die Datenverarbeitung beschleunigen.
Durch die Verwendung eines Standardspaltenlayouts muss nicht mehr jedes System sein eigenes internes Datenformat definieren. Das reduziert sowohl den Aufwand für die Serialisierung als auch die doppelte Arbeit.
Systeme können Daten leichter gemeinsam nutzen, und Entwickler können Algorithmen in verschiedenen Sprachen wiederverwenden.
Ohne ein gemeinsames Format wie Arrow muss jede Datenbank oder jedes Tool die Daten serialisieren und deserialisieren, bevor sie weitergegeben werden. Das erhöht die Kosten und die Komplexität. Außerdem müssen gängige Algorithmen für die interne Datenstruktur des jeweiligen Systems neu geschrieben werden.
Arrow ändert das, indem es standardisiert, wie Daten im Speicher dargestellt werden.
Spaltenformate sind zwar gut für die analytische Leistung und die Speicherlokalität, aber sie sind nicht für häufige Aktualisierungen ausgelegt.
Das liegt daran, dass die spaltenbasierte Speicherung für schnelles Lesen und nicht für Änderungen optimiert ist. Wenn du Daten änderst, musst du sie oft kopieren oder den Speicher neu zuweisen, was langsam und ressourcenintensiv sein kann.
Arrow konzentriert sich auf eine effiziente In-Memory-Darstellung und Serialisierung. Wenn dein Anwendungsfall häufige Datenmutationen erfordert, musst du das auf der Implementierungsebene regeln.
Wenn du dich näher mit Arrow-kompatiblen Formaten befassen willst, schau dir diesen Leitfadenide zu Apache Parquet, ideal für dienarische Datenspeicherung.
Apache Arrow bietet zwei wichtige Datenstrukturen: Array und Table:
Array repräsentiert eine einzelne Spalte mit Daten. Sie speichert Werte in einem zusammenhängenden Speicherblock, was einen schnellen Zugriff, effizientes Scannen und die Unterstützung von Optimierungen auf Prozessorebene wie SIMD ermöglicht. Jedes Array kann auch Metadaten wie Nullindikatoren (Bitmaps) und Datentypinformationen enthalten.Arrow Table stellt also einen 2D-Datensatz dar. Jede Spalte ist ein Chunked Array, und alle Spalten folgen einem gemeinsamen Schema, das Feldnamen und -typen definiert. Während sich die Chunks in den Spalten unterscheiden können, muss die Gesamtzahl der Elemente gleich bleiben, damit die Zeilen konsistent bleiben.Du kannst es dir wie ein DataFrame in Pandas oder R vorstellen. Es ist tabellarisch, effizient und unterstützt Operationen über mehrere Spalten gleichzeitig.
Sehen wir uns ein paar Beispiele für die Erstellung eines Pfeils Array und Table in Python an.
Vergewissere dich, dass du pyarrow installiert hast, bevor du den untenstehenden Code ausführst, indem du die vorherigen Anweisungen befolgst.
import pyarrow as pa
# Create an Arrow Array (single column)
data = pa.array([1, 2, 3, 4, 5])
print("Arrow Array:")
print(data)
Drucke ein Pfeil-Array. Bild vom Autor.
import pyarrow as pa
# Create an Arrow Table (multiple columns)
table = pa.table({
'column1': pa.array([1, 2, 3]),
'column2': pa.array(['a', 'b', 'c'])
})
print("\nArrow Table:")
print(table)
Drucke eine Tabelle mit Pfeilen. Bild vom Autor.
Sehen wir uns an, wie du mit Arrow Arrays arbeitest und gängige Operationen durchführst, z. B. Slicen, Filtern und Prüfen von Metadaten.
Arrow Arrays arbeiten mit verschiedenen Datentypen, darunter Strings, Fließkommazahlen und ganze Zahlen. Hier erfährst du, wie du sie erstellst:
import pyarrow as pa
# Integer Array
int_array = pa.array([10, 20, 30], type=pa.int32())
print("Integer Array:")
print(int_array)
# String Array
string_array = pa.array(["apple", "banana", "cherry"], type=pa.string())
print("\nString Array:")
print(string_array)
# Floating-point Array
float_array = pa.array([1.1, 2.2, 3.3], type=pa.float64())
print("\nFloating-point Array:")
print(float_array)
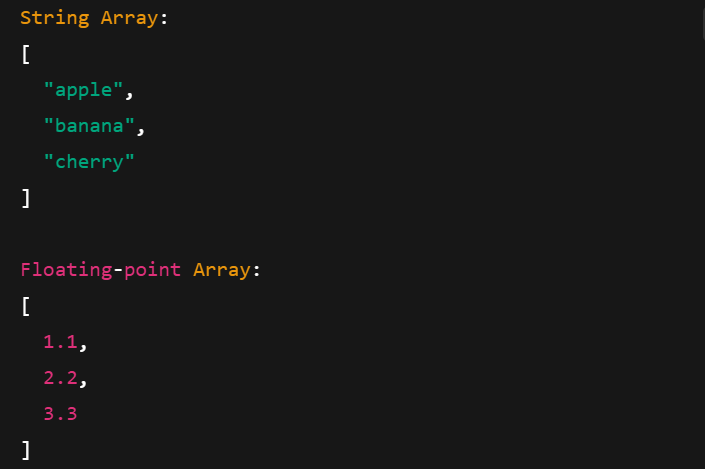
Drucken von Arrow Arrays mit verschiedenen Datentypen. Bild vom Autor.
Sehen wir uns ein paar gängige Operationen an, die du mit Arrow Arrays durchführen kannst.
Mit Slicing kannst du einen Teilbereich eines Arrays greifen. Du kannst zum Beispiel Elemente in bestimmten Indexbereichen extrahieren:
import pyarrow as pa
arr = pa.array([10, 20, 30, 40, 50])
# Slice from index 1 to 4 (3 elements: 20, 30, 40)
sliced = arr.slice(1, 3)
print("Original Array:", arr)
print("Sliced Array (1:4):", sliced)
Drucken eines aufgeschnittenen Pfeilfeldes. Bild vom Autor.
Beim Filtern wird eine boolesche Maske verwendet, um nur die Werte zu behalten, die eine Bedingung erfüllen. Du kannst auch auf Metadaten wie Typ, Länge und Anzahl der Nullen zugreifen.
import pyarrow.compute as pc
arr = pa.array([10, 20, 30, 40, 50])
# Create a boolean mask: Keep elements > 25
mask = pc.greater(arr, pa.scalar(25))
# Apply the filter
filtered = pc.filter(arr, mask)
print("Filtered Array (values > 25):", filtered)
print("Array Type:", arr.type)
print("Array Length:", len(arr))
print("Null Count:", arr.null_count)
print("Is Null Bitmap Buffers:", arr.buffers())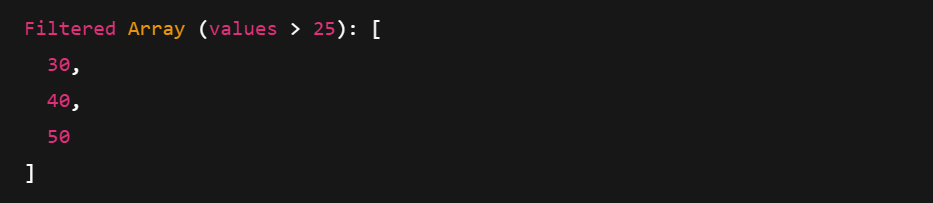
Drucken eines gefilterten Pfeilfeldes. Bild vom Autor.

Drucken von Metadaten eines Arrow Arrays. Bild vom Autor.
Du kannst Tabellen aus Arrow-Arrays oder direkt aus nativen Python-Datenstrukturen wie Wörterbüchern erstellen. Lass uns sehen, wie.
Es gibt zwei gängige Möglichkeiten, eine Pfeiltabelle zu erstellen:
pa.table()Lass uns beide Wege nacheinander erkunden.
import pyarrow as pa
# Create individual Arrow Arrays
ids = pa.array([1, 2, 3])
names = pa.array(['Alice', 'Bob', 'Charlie'])
scores = pa.array([85.0, 92.5, 78.3])
# Combine them into a Table
table = pa.table({
'id': ids,
'name': names,
'score': scores
})
print("Arrow Table from Arrays:")
print(table)Im obigen Code:
pa.table()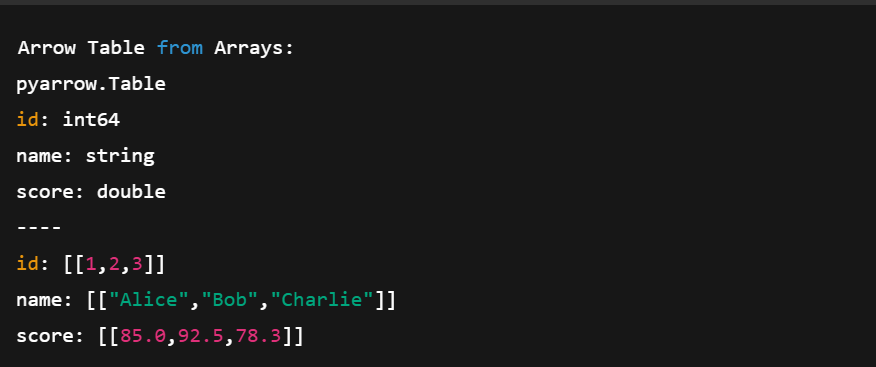
Erstelle eine Tabelle mit mehreren Pfeiltabellen. Bild vom Autor.
Sehen wir uns nun an, wie man eine Tabelle aus einem Python-Wörterbuch erstellt.
# Create a table directly from Python data
data = {
'id': [4, 5, 6],
'name': ['Diana', 'Eve', 'Frank'],
'score': [88.0, 79.5, 91.2]
}
table2 = pa.table(data)
print("\nArrow Table from Dictionary:")
print(table2)Diese Methode ist kürzer und kompakter. Wir müssen die Arrays nicht manuell definieren, das übernimmt Arrow für uns.
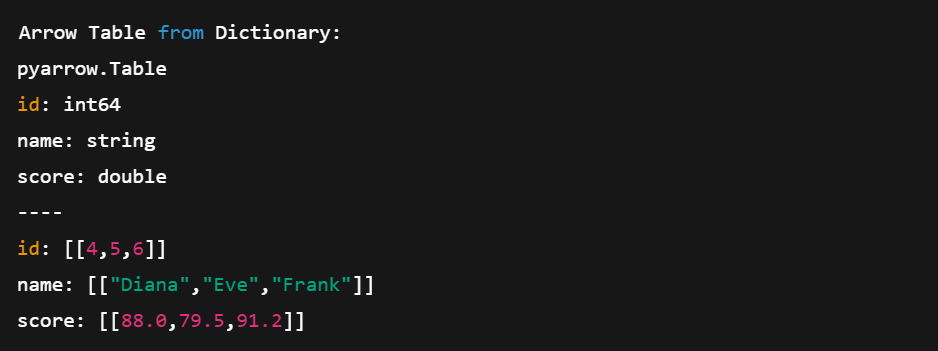
Erstellen einer Pfeiltabelle direkt aus Python-Wörterbüchern. Bild vom Autor.
Eine der größten Stärken von Arrow ist seine Interoperabilität. Du kannst ganz einfach zwischen einer Pfeiltabelle und einem DataFrame von Pandas wechseln. Mal sehen, wie man das macht:
import pyarrow as pa
import pandas as pd
# Create an Arrow Table
data = {
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
}
arrow_table = pa.table(data)
# Convert Arrow Table to pandas DataFrame
df = arrow_table.to_pandas()
# Show the DataFrame
print(df)
Konvertieren einer Tabelle in einen Pandas DataFrame. Bild vom Autor.
Jetzt wollen wir mal sehen, wie man das Gegenteil macht:
import pyarrow as pa
import pandas as pd
# Create a pandas DataFrame
df = pd.DataFrame({
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
})
# Convert pandas DataFrame to Arrow Table
arrow_table = pa.Table.from_pandas(df)
# Show the Arrow Table
print(arrow_table)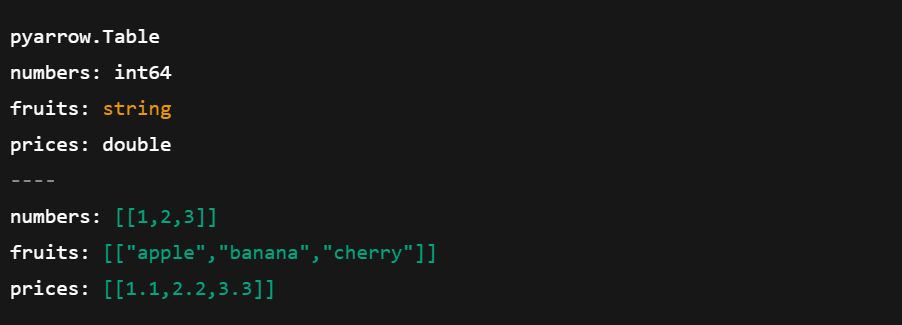
Konvertieren von Pandas DataFrame in eine Array-Tabelle. Bild vom Autor.
Serialisierung ist der Prozess der Umwandlung komplexer Objekte oder Datenstrukturen in einen Strom von Bytes, um Daten zwischen Systemen zu speichern oder zu senden. Aber Apache Arrow verfolgt einen anderen Ansatz.
Da Arrow ein spaltenförmiges Speicherformat verwendet, das auf Geschwindigkeit ausgelegt ist, vermeidet es die traditionelle Serialisierung. Stattdessen setzt sie auf ein Shared-Memory-Modell, bei dem mehrere Prozesse direkt auf dieselben Daten zugreifen können, ohne sie zu kopieren oder zu konvertieren.
So funktioniert es:
Sehen wir uns an, wie du Pfeildaten mit dem Feather-Dateiformat speichern und mit Python wieder in eine Tabelle laden kannst.
import pandas as pd
import pyarrow as pa
import pyarrow.feather as feather
# Create a sample pandas DataFrame
df = pd.DataFrame({
'id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie'],
'score': [95.5, 82.0, 77.5]
})
# Convert DataFrame to Arrow Table
table = pa.Table.from_pandas(df)
# Save Arrow Table to a Feather file
feather.write_feather(table, 'example.feather')
print("Arrow table saved to 'example.feather'")
DataFrame in eine Pfeiltabelle umwandeln. Bild vom Autor.
Dann können wir das Gegenteil tun und eine Pfeiltabelle aus der zuvor erstellten Feather-Datei laden.
import pyarrow.feather as feather
# Load the Feather file into an Arrow Table
loaded_table = feather.read_table('example.feather')
# (Optional) Convert back to pandas DataFrame
df_loaded = loaded_table.to_pandas()
# Print the loaded data
print(df_loaded)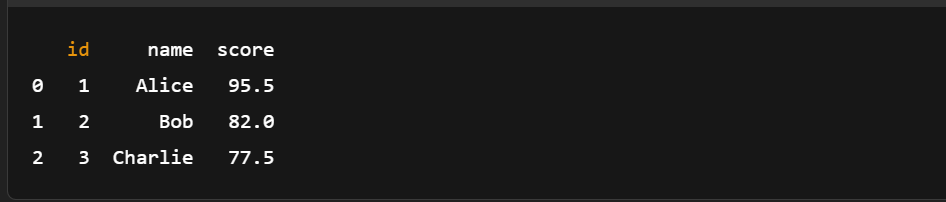
Laden einer Pfeiltabelle aus einer Feather-Datei. Bild vom Autor.
Wie du siehst, ist eine manuelle Serialisierung nicht nötig. Das Speichern und Laden von Pfeildaten erfordert nur ein paar Zeilen Code.
Wenn du neu in Pandas bist oder eine Auffrischung brauchst, ist dieser Pandas-Spickzettel ein toller Begleiter zu Arrow für schnelle Datenmanipulationen.
Schauen wir uns ein echtes Beispiel dafür an, wie schnell und effektiv Arrow beim Laden, Filtern und Analysieren eines großen Datensatzes sein kann.
Wir beginnen damit, einen Pandas DataFrame mit einer Million Zeilen zu erstellen.
import pandas as pd
import pyarrow as pa
import pyarrow.compute as pc
import time
df = pd.DataFrame({
'id': range(1, 1_000_001), #assuming a dataset with a million rows
'value': pd.np.random.randint(1, 1000, size=1_000_000),
'category': pd.np.random.choice(['A', 'B', 'C'], size=1_000_000)
})start = time.time()
arrow_table = pa.Table.from_pandas(df)
end = time.time()
print(f"Conversion to Arrow Table took {end - start:.4f} seconds")# Example: Filter rows where 'value' > 990
start = time.time()
filtered_table = pc.filter(arrow_table, pc.greater(arrow_table['value'], pa.scalar(990)))
end = time.time()
# Result summary
print(f"Filtering took {end - start:.4f} seconds")
print(f"Filtered row count: {filtered_table.num_rows}")start = time.time()
filtered_df = filtered_table.to_pandas()
end = time.time()
print(f"Conversion to pandas DataFrame took {end - start:.4f} seconds")
Laden eines großen Datensatzes in ein Array. Bild vom Autor.
Das spaltenförmige Format und die SIMD-basierten Rechenfunktionen machen Arrow zu einer hervorragenden Wahl für umfangreiche In-Memory-Operationen. Und dank der Null-Kopie-Konvertierung ist der Wechsel zurück zu Pandas schnell und effizient.
Für Arbeitsabläufe, bei denen du Daten vor der Arrow-Konvertierung lädst,kann dieser Kursüber die optimierte Dateneingabe mit Pandasdeine Pipeline optimieren.
Du kannst auch die Compute-API von Arrow nutzen, um grundlegende Analysen durchzuführen. Hier ist eine kurze Demo mit einem kleineren Beispieldatensatz.
import pyarrow as pa
import pyarrow.compute as pc
# Sample data
data = {
'id': pa.array([1, 2, 3, 4, 5]),
'score': pa.array([85, 92, 76, 88, 95]),
'category': pa.array(['A', 'B', 'A', 'B', 'A'])
}
# Create Arrow Table
table = pa.table(data)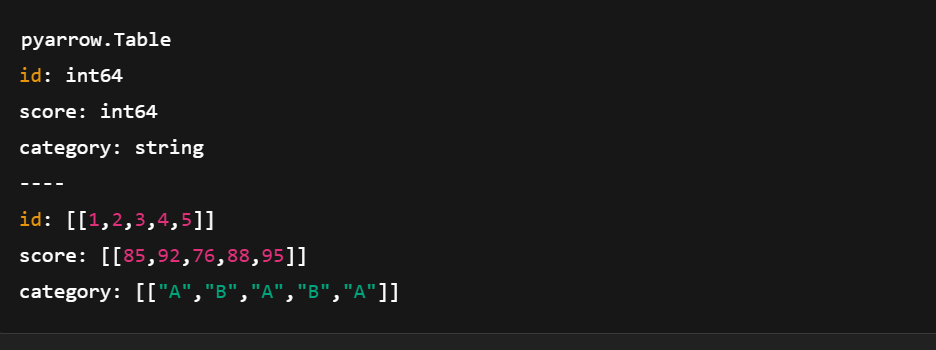
Erstelle eine Tabelle mit pyarrow.compute. Bild vom Autor.
# Filter rows where score > 90
filter_mask = pc.greater(table['score'], pa.scalar(90))
filtered_table = pc.filter(table, filter_mask)
print(filtered_table.to_pandas())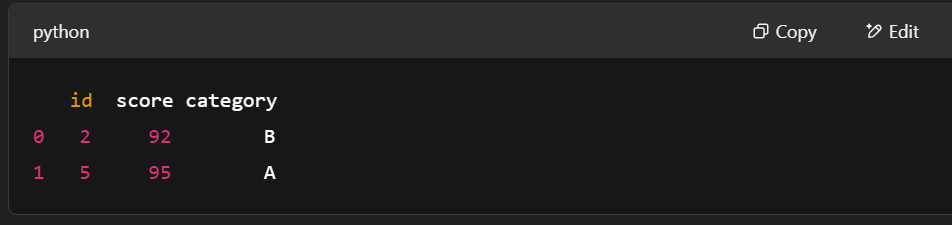
Filtern von Zeilen mit pyarrow.compute. Bild vom Autor.
# Compute mean of the "score" column
mean_result = pc.mean(table['score'])
print("Mean score:", mean_result.as_py())![]()
Berechnung des Mittelwerts mit pyarrow.compute. Bild vom Autor.
import pandas as pd
# Convert to pandas for more complex grouping
df = table.to_pandas()
grouped = df.groupby('category')['score'].mean()
print(grouped)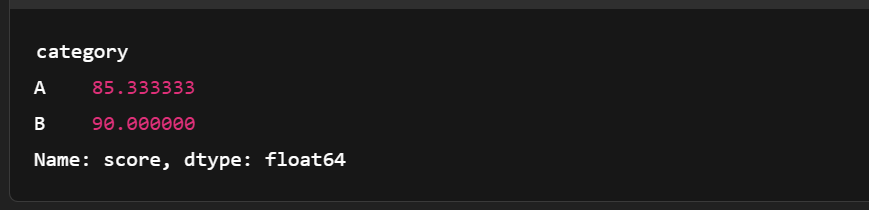
Gruppieren der Tabelle mit den Pfeilen. Bild vom Autor.
Hier ist ein kurzer Vergleich zwischen Apache Arrow und Pandas. Sie zeigt, wo sich die ArReihe für große, analytische Workloads auszeichnet.
|
Feature |
Apachenpfeil |
Pandas |
|
Speicher Format |
Säulenförmig, Null-Kopie, dicht gepackt |
Zeilenbasiert (verwendet intern NumPy-Arrays) |
|
Geschwindigkeit (Filterung, I/O) |
Schneller durch SIMD und Vektorisierung |
Langsamer bei großen Daten (Kopien, Python-Schleifen) |
|
Speichernutzung |
Kompakter, effizienter |
Höherer Speicherverbrauch aufgrund von Python-Overhead |
|
Interoperabilität |
Ausgezeichnet (über alle Sprachen/Tools hinweg) |
Meistens Python-zentriert |
|
Anwendungsfall Fit |
Optimiert für große, analytische Workloads |
Ideal für kleine/mittlere Daten und Prototyping |
|
Serialisierung |
Feather/Parquet mit Null-Kopie-Unterstützung |
CSV/Excel, oft langsamer und unhandlicher |
Wie wir gesehen haben, lassen sich Pfeiltabellen gut mit Pandas integrieren, insbesondere bei der Durchführung von Joins. Erfahre mehr in diesemrse über das Verbinden von Daten mit Pandas.
Arrow kann gut mit anderen Datentools zusammenarbeiten, was es einfach macht, Daten zwischen Umgebungen zu verschieben, ohne Geschwindigkeit oder Struktur zu verlieren.
In Apache Arrow ähnelt die Table einem Pandas DataFrame, beide verwenden benannte Spalten gleicher Länge. Aber Pfeiltabellen gehen noch weiter. Sie unterstützen verschachtelte Spalten, sodass du komplexere Datenstrukturen als in Pandas darstellen kannst.
Allerdings sind nicht alle Umstellungen nahtlos. Trotzdem ist die Umrechnung zwischen Arrow und Pandas einfach. Und so geht's:
Pfeiltabelle → pandas DataFrame
table.to_pandas()pandas DataFrame → Pfeiltabelle
pa.Table.from_pandas(df)Und das war's! Eine Zeile Code reicht aus.
Du kannst auch mit anderen Pandastrukturen wie Reihen arbeiten, indem du Arrow benutzt. In der Dokumentation findest du weitere Informationen. Außerdem profitieren sowohl Arrow als auch Pandas von einem leistungsorientierten Design - erfahre mehr in diesem Kurs über das Schreiben von effizientem Code mit Pandas.
Apache Arrow ist in Spark integriert, um den Datenaustausch zwischen der JVM (Java Virtual Machine) und Python zu beschleunigen. Das ist sehr hilfreich für Pandas- und NumPy-Nutzer. Sie ist nicht standardmäßig aktiviert, also musst du eventuell einige Einstellungen ändern, um sie einzuschalten. Aber wenn es einmal läuft, verbessert Arrow die Leistung auf verschiedene Weise:
Um loszulegen, folge der offiziellen PySpark with Arrow-Anleitung.
Arrow funktioniert auch gut mit Bibliotheken für maschinelles Lernen wie TensorFlow.
Das Spaltenformat ermöglicht ein schnelleres Laden der Daten und eine schnellere Vorverarbeitung - wichtige Schritte beim Training von Machine-Learning-Modellen. Durch die effiziente Verarbeitung großer Datenmengen hilft Arrow beim Aufbau skalierbarer ML-Pipelines, die schneller trainieren und besser über verschiedene Tools hinweg funktionieren.
Und das war's dann auch schon! Wir haben uns die Grundideen von Apache Arrow angeschaut, wie es sich von herkömmlichen Datenformaten unterscheidet, wie man es einrichtet und wie man damit in Python arbeitet.
Wir haben auch praktische Beispiele für die Erstellung von Arrow-Arrays und -Tabellen kennengelernt und gesehen, wie Arrow dabei hilft, langsame Serialisierungen zu überspringen, um die Datenverarbeitung schnell und effizient zu halten.
Wenn du dich weiterbilden und auf dem, was wir behandelt haben, aufbauen möchtest, findest du hier einige großartige Ressourcen, auf die du zurückgreifen kannst:
Wo auch immer du als Nächstes hingehst, wir hoffen, dass Arrow dir hilft, sauberere und skalierbarere Arbeitsabläufe zu erstellen!
Lerne mehr über Data Engineering mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
