
Programa
Engenheiro de dados Em Python
40 h
O Apache Arrow ajuda diferentes ferramentas e sistemas a compartilhar dados de forma rápida e fácil. Ele armazena dados em um formato especial baseado em colunas que permanece na memória, o que o torna muito rápido de trabalhar.
Neste tutorial, mostrarei a você os conceitos básicos do Apache Arrow. Você terá exemplos práticos para entender como ele funciona e como usá-lo em seus projetos.
O Apache Arrowé uma plataforma de código aberto e de várias linguagens para processamento de dados na memória de alto desempenho. Ele define um formato de memória colunar padronizado, otimizadopara CPUs modernas, para permitir análises eficientes e computação vetorizada.
O Arrow também elimina a necessidade de serialização entre sistemas e linguagens, o que permite leituras de cópia zero e reduz a sobrecarga de processamento.
Como ele funciona bem com ferramentas como pandas, Apache Spark e Dask, você pode mover dados com o mínimo de esforço. Isso o torna uma excelente opção para quem está criando sistemas rápidos e flexíveis que precisam lidar com muitos dados.
Agora, vamos explorar o Arrow com alguns exemplos práticos!
O Apache Arrow oferece suporte a várias linguagens, incluindo C, C++, C#, Python, Rust, Java, JavaScript, Julia, Go, Ruby e R.
Ele funciona no Windows, macOS e em distribuições populares do Linux, como Debian, Ubuntu, CentOS e Red Hat Enterprise Linux.
Neste guia, você o usará com Python.
Vamos ver como você pode instalar o Apache Arrow para Python usando as rodas binárias oficiais publicadas no PyPI. Essas etapas funcionam da mesma forma no Windows, macOS e Linux.
Abra seu terminal e execute:
python --versionSe isso retornar um número de versão, você está pronto para começar. Caso contrário, instale o Python do site oficial.
pyarrow usando o pipPara instalar o Apache Arrow para Python, execute:
pip install 'pyarrow==19.0.* ' O site * garante que você receba a versão mais recente do patch da série 19.0.
Também recomendo que você use pyarrow==19.0.* em seu arquivo requirements.txt para manter a consistência entre os ambientes. Isso instalará o pyarrow juntamente com as bibliotecas binárias necessárias do Apache Arrow e do Parquet C++ que acompanham o Wheel.
Para instalar o Arrow em outro idioma, consulte a documentação completa.
Você pode executar este rápido snippet Python para verificar se tudo funciona:
import pyarrow as pa
# Create a simple Arrow array
data = pa.array([1, 2, 3, 4, 5])
print("Apache Arrow is installed and working!")
print("Arrow Array:", data)Se o pyarrow estiver instalado corretamente, você verá a matriz impressa no terminal. Caso contrário, o código exibirá um erro.
Antes de nos aprofundarmos no código, vamos entender como o Apache Arrow foi criado.
O formato colunar na memória é um dos recursos mais importantes do Apache Arrow. Ele define uma estrutura de dados na memória, independente de linguagem. Além disso, inclui serialização de metadados, um protocolo para transporte de dados e uma forma padrão de representar dados entre sistemas.
Em um formato colunar, os dados são armazenados em colunas em vez de linhas, o que é diferente do armazenamento tradicional baseado em linhas. Os layouts colunares são populares para cargas de trabalho analíticas porque são muito mais rápidos de digitalizar e processar.
A imagem abaixo explica o formato:
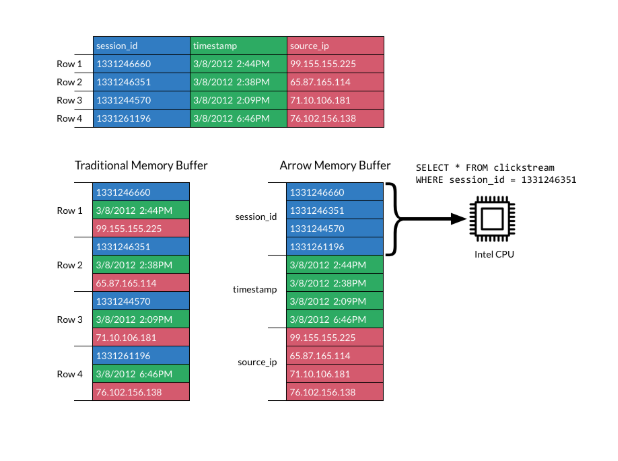
Formato colunar. Fonte: Documentos do Apache Arrow
O formato do Apache Arrow aumenta a eficiência ao colocar as colunas em blocos de memória contíguos. Isso oferece suporte a operações vetoriais modernas (SIMD), que aceleram o processamento de dados.
Usando um layout colunar padrão, o Arrow elimina a necessidade de cada sistema definir seu formato de dados interno. Isso reduz a sobrecarga de serialização e a duplicação de esforços.
Os sistemas podem compartilhar dados com mais facilidade, e os desenvolvedores podem reutilizar algoritmos em diferentes linguagens.
Sem um formato compartilhado como o Arrow, cada banco de dados ou ferramenta precisa serializar e desserializar os dados antes de passá-los adiante. Isso aumenta o custo e a complexidade. E os algoritmos comuns precisam ser reescritos para a estrutura de dados interna de cada sistema.
O Arrow muda isso ao padronizando a forma como os dados são representados na memória.
Embora os formatos colunares sejam ótimos para desempenho analítico e localidade de memória, eles não foram projetados para atualizações frequentes. não foram projetados para atualizações frequentes.
Isso ocorre porque o armazenamento em colunas é otimizado para leitura rápida, não para modificação. Fazer alterações nos dados geralmente significa copiar ou realocar a memória, o que pode ser lento e exigir muitos recursos.
O Arrow se concentra na representação e na serialização eficientes na memória. Se o seu caso de uso precisar de mutação frequente de dados, você precisará lidar com isso no nível da implementação.
Para se aprofundar nos formatos compatíveis com o Arrow, confira este guiapara o Apache Parquet, ideal para o armazenamento de dados columde dados em colunas.
O Apache Arrow fornece duas estruturas de dados importantes: Array e Table:
Array representa uma única coluna de dados. Ele armazena valores em um bloco de memória contíguo, permitindo acesso rápido, varredura eficiente e suporte para otimizações no nível do processador, como SIMD. Cada matriz também pode conter metadados, como indicadores nulos (bitmaps) e informações de tipo de dados.Arrow Table representa um conjunto de dados 2D. Cada coluna é uma matriz em pedaços, e todas as colunas seguem um esquema compartilhado que define os nomes e tipos de campo. Embora os blocos possam ser diferentes nas colunas, o número total de elementos deve permanecer alinhado para manter as linhas consistentes.Você pode pensar nele como um DataFrame em pandas ou R. Ele é tabular, eficiente e suporta operações em várias colunas simultaneamente.
Vamos dar uma olhada em alguns exemplos de criação de uma seta Array e Table em Python.
Certifique-se de que você tenha o site pyarrow instalado antes de executar o código abaixo, seguindo as instruções anteriores.
import pyarrow as pa
# Create an Arrow Array (single column)
data = pa.array([1, 2, 3, 4, 5])
print("Arrow Array:")
print(data)
Imprimir uma matriz de setas. Imagem do autor.
import pyarrow as pa
# Create an Arrow Table (multiple columns)
table = pa.table({
'column1': pa.array([1, 2, 3]),
'column2': pa.array(['a', 'b', 'c'])
})
print("\nArrow Table:")
print(table)
Se você imprimir uma tabela de setas. Imagem do autor.
Vamos ver como você pode trabalhar com Arrow Arrays e realizar operações comuns, como fatiamento, filtragem e verificação de metadados.
As matrizes de setas funcionam com diferentes tipos de dados, incluindo cadeias de caracteres, números de ponto flutuante e inteiros. Veja como você pode criá-los:
import pyarrow as pa
# Integer Array
int_array = pa.array([10, 20, 30], type=pa.int32())
print("Integer Array:")
print(int_array)
# String Array
string_array = pa.array(["apple", "banana", "cherry"], type=pa.string())
print("\nString Array:")
print(string_array)
# Floating-point Array
float_array = pa.array([1.1, 2.2, 3.3], type=pa.float64())
print("\nFloating-point Array:")
print(float_array)
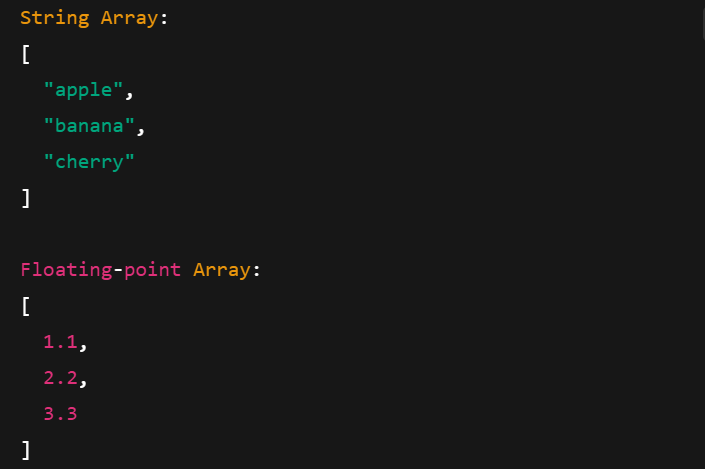
Impressão de matrizes de setas com diferentes tipos de dados. Imagem do autor.
Vejamos algumas operações comuns que você pode realizar com Arrow Arrays.
O fatiamento permite que você pegue uma subseção de uma matriz. Por exemplo, você pode extrair elementos em intervalos de índices específicos:
import pyarrow as pa
arr = pa.array([10, 20, 30, 40, 50])
# Slice from index 1 to 4 (3 elements: 20, 30, 40)
sliced = arr.slice(1, 3)
print("Original Array:", arr)
print("Sliced Array (1:4):", sliced)
Impressão de uma matriz de setas cortadas. Imagem do autor.
A filtragem usa uma máscara booleana para manter apenas os valores que correspondem a uma condição. Você também pode acessar metadados como tipo, comprimento e contagem de nulos.
import pyarrow.compute as pc
arr = pa.array([10, 20, 30, 40, 50])
# Create a boolean mask: Keep elements > 25
mask = pc.greater(arr, pa.scalar(25))
# Apply the filter
filtered = pc.filter(arr, mask)
print("Filtered Array (values > 25):", filtered)
print("Array Type:", arr.type)
print("Array Length:", len(arr))
print("Null Count:", arr.null_count)
print("Is Null Bitmap Buffers:", arr.buffers())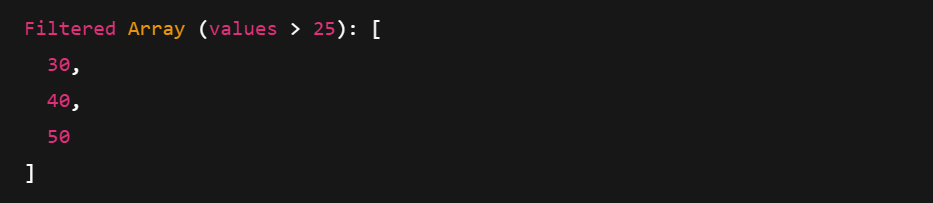
Impressão de uma matriz de setas filtrada. Imagem do autor.

Impressão de metadados de uma matriz de setas. Imagem do autor.
Você pode criar tabelas de setas a partir de matrizes de setas ou diretamente de estruturas de dados nativas do Python, como dicionários. Vamos ver como.
Há duas maneiras comuns de criar uma tabela de setas:
pa.table()Vamos explorar as duas formas, uma a uma.
import pyarrow as pa
# Create individual Arrow Arrays
ids = pa.array([1, 2, 3])
names = pa.array(['Alice', 'Bob', 'Charlie'])
scores = pa.array([85.0, 92.5, 78.3])
# Combine them into a Table
table = pa.table({
'id': ids,
'name': names,
'score': scores
})
print("Arrow Table from Arrays:")
print(table)No código acima:
pa.table()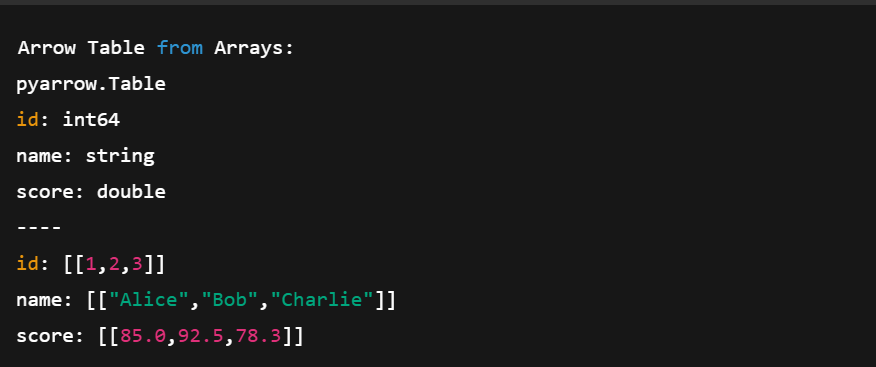
Criando uma tabela de setas usando várias matrizes de setas. Imagem do autor.
Agora, vamos ver como você pode criar uma tabela a partir de um dicionário Python.
# Create a table directly from Python data
data = {
'id': [4, 5, 6],
'name': ['Diana', 'Eve', 'Frank'],
'score': [88.0, 79.5, 91.2]
}
table2 = pa.table(data)
print("\nArrow Table from Dictionary:")
print(table2)Esse método é mais curto e mais compacto. Não precisamos definir matrizes manualmente; o Arrow cuida disso para nós.
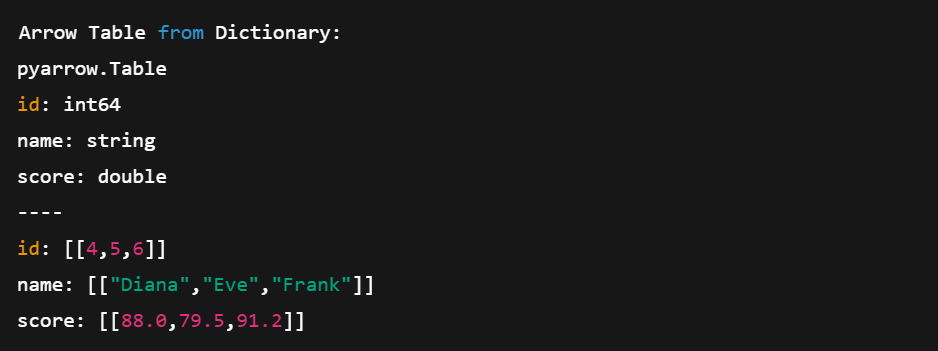
Criando uma tabela de setas diretamente dos dicionários do Python. Imagem do autor.
Um dos maiores pontos fortes do Arrow é sua interoperabilidade. Você pode alternar facilmente entre uma tabela de setas e um DataFrame do pandas. Vamos ver como você pode fazer isso:
import pyarrow as pa
import pandas as pd
# Create an Arrow Table
data = {
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
}
arrow_table = pa.table(data)
# Convert Arrow Table to pandas DataFrame
df = arrow_table.to_pandas()
# Show the DataFrame
print(df)
Convertendo uma tabela de setas em um DataFrame do Pandas. Imagem do autor.
Agora, vamos ver como você pode fazer o contrário:
import pyarrow as pa
import pandas as pd
# Create a pandas DataFrame
df = pd.DataFrame({
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
})
# Convert pandas DataFrame to Arrow Table
arrow_table = pa.Table.from_pandas(df)
# Show the Arrow Table
print(arrow_table)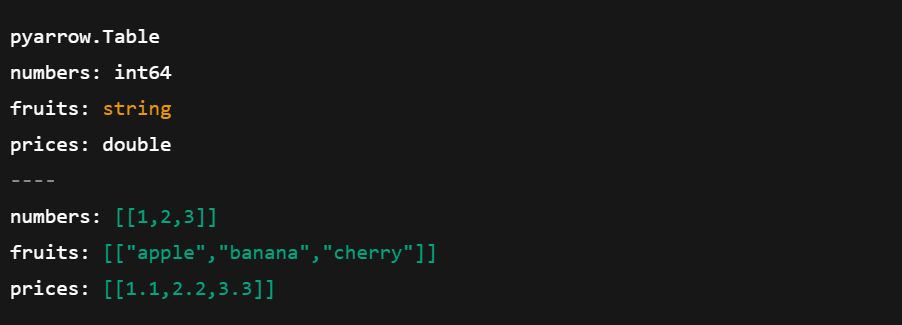
Convertendo o DataFrame do pandas em uma tabela de matriz. Imagem do autor.
A serialização é o processo de conversão de objetos complexos ou estruturas de dados em um fluxo de bytes para armazenar ou enviar dados entre sistemas. Mas o Apache Arrow adota uma abordagem diferente.
Como o Arrow usa um formato de memória colunar projetado para velocidade, ele evita a serialização tradicional. Em vez disso, ele se baseia em ummodelo de memória compartilhada , em que vários processos podem acessar os mesmos dados diretamente sem copiá-los ou convertê-los.
Veja o que ele faz:
Vamos ver como você pode salvar os dados da seta usando o formato de arquivo Feather e carregá-los de volta em uma tabela usando Python.
import pandas as pd
import pyarrow as pa
import pyarrow.feather as feather
# Create a sample pandas DataFrame
df = pd.DataFrame({
'id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie'],
'score': [95.5, 82.0, 77.5]
})
# Convert DataFrame to Arrow Table
table = pa.Table.from_pandas(df)
# Save Arrow Table to a Feather file
feather.write_feather(table, 'example.feather')
print("Arrow table saved to 'example.feather'")
Convertendo DataFrame em tabela de setas. Imagem do autor.
Em seguida, podemos fazer o oposto e carregar uma tabela de setas do arquivo Feather criado anteriormente.
import pyarrow.feather as feather
# Load the Feather file into an Arrow Table
loaded_table = feather.read_table('example.feather')
# (Optional) Convert back to pandas DataFrame
df_loaded = loaded_table.to_pandas()
# Print the loaded data
print(df_loaded)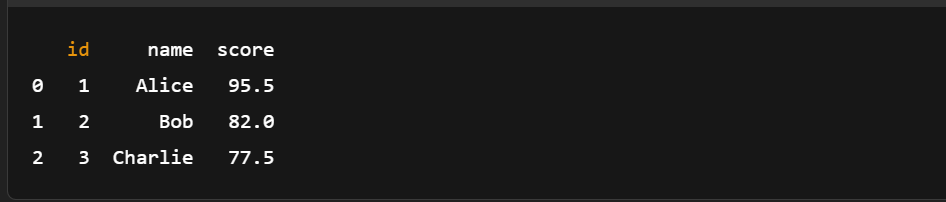
Carregando a tabela de setas de um arquivo Feather. Imagem do autor.
Como você pode ver, não há necessidade de serialização manual. Para salvar e carregar os dados do Arrow, você só precisa de algumas linhas de código.
Se você é novo no pandas ou precisa se atualizar, esta folha de dicas sobre o pandas é uma ótima companhia para o Arrow para manipulações rápidas de dados.
Vamos dar uma olhada em um exemplo real de como o Arrow pode ser rápido e eficaz ao carregar, filtrar e analisar um grande conjunto de dados.
Começaremos criando um DataFrame do pandas com um milhão de linhas.
import pandas as pd
import pyarrow as pa
import pyarrow.compute as pc
import time
df = pd.DataFrame({
'id': range(1, 1_000_001), #assuming a dataset with a million rows
'value': pd.np.random.randint(1, 1000, size=1_000_000),
'category': pd.np.random.choice(['A', 'B', 'C'], size=1_000_000)
})start = time.time()
arrow_table = pa.Table.from_pandas(df)
end = time.time()
print(f"Conversion to Arrow Table took {end - start:.4f} seconds")# Example: Filter rows where 'value' > 990
start = time.time()
filtered_table = pc.filter(arrow_table, pc.greater(arrow_table['value'], pa.scalar(990)))
end = time.time()
# Result summary
print(f"Filtering took {end - start:.4f} seconds")
print(f"Filtered row count: {filtered_table.num_rows}")start = time.time()
filtered_df = filtered_table.to_pandas()
end = time.time()
print(f"Conversion to pandas DataFrame took {end - start:.4f} seconds")
Carregando um grande conjunto de dados em uma matriz. Imagem do autor.
O formato colunar do Arrow e as funções de computação com tecnologia SIMD fazem dele uma excelente opção para operações de grande escala na memória. E graças à conversão de cópia zero, você pode voltar a usar o pandas de forma rápida e eficiente.
Para fluxos de trabalho em que você carrega dados antes da conversão do Arrow, este cursosobre ingestão de dados simplificada com pandas pode otimizarseu pipeline.
Você também pode usar a API de computação da Arrow para executar análises básicas. Aqui está uma demonstração rápida com um conjunto de dados de amostra menor.
import pyarrow as pa
import pyarrow.compute as pc
# Sample data
data = {
'id': pa.array([1, 2, 3, 4, 5]),
'score': pa.array([85, 92, 76, 88, 95]),
'category': pa.array(['A', 'B', 'A', 'B', 'A'])
}
# Create Arrow Table
table = pa.table(data)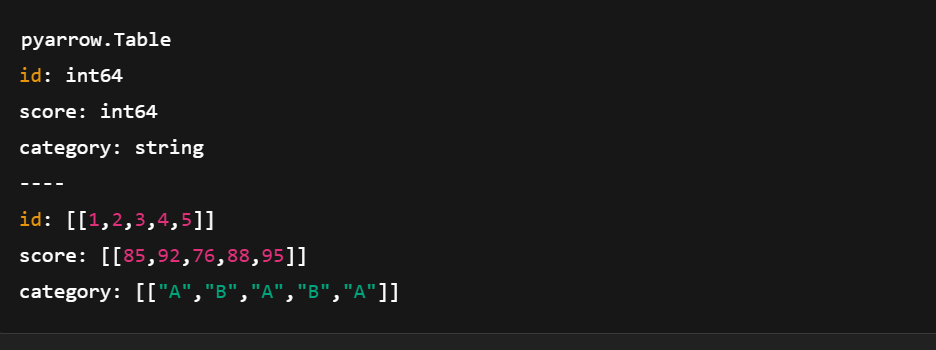
Criando uma tabela de setas usando pyarrow.compute. Imagem do autor.
# Filter rows where score > 90
filter_mask = pc.greater(table['score'], pa.scalar(90))
filtered_table = pc.filter(table, filter_mask)
print(filtered_table.to_pandas())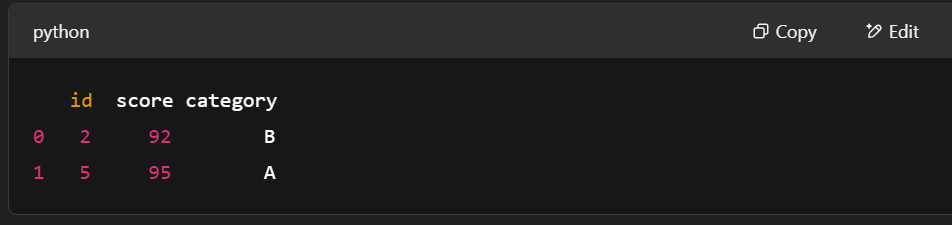
Filtragem de linhas usando pyarrow.compute. Imagem do autor.
# Compute mean of the "score" column
mean_result = pc.mean(table['score'])
print("Mean score:", mean_result.as_py())![]()
Cálculo da pontuação média usando pyarrow.compute. Imagem do autor.
import pandas as pd
# Convert to pandas for more complex grouping
df = table.to_pandas()
grouped = df.groupby('category')['score'].mean()
print(grouped)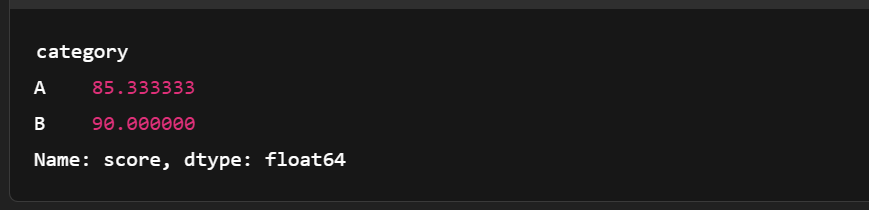
Agrupando a tabela de setas. Imagem do autor.
Aqui está uma rápida comparação entre o Apache Arrow e o pandas. Ele mostra onde a linha Arse destaca para cargas de trabalho analíticas e de grande escala.
|
Recurso |
Flecha Apache |
Pandas |
|
Formato da memória |
Colunar, de cópia zero, bem compactado |
Baseado em linhas (internamente usa matrizes NumPy) |
|
Velocidade (filtragem, E/S) |
Mais rápido devido ao SIMD e à vetorização |
Mais lento em dados grandes (cópias, loops Python) |
|
Uso da memória |
Mais compacto e eficiente |
Maior uso de memória devido à sobrecarga do Python |
|
Interoperabilidade |
Excelente (compartilhado entre idiomas/ferramentas) |
Principalmente centrado em Python |
|
Caso de uso Adequado |
Otimizado para grandes cargas de trabalho analíticas |
Excelente para dados pequenos/médios e prototipagem |
|
Serialização |
Feather/Parquet com suporte a cópia zero |
CSV/Excel, geralmente mais lento e mais volumoso |
Como vimos, as tabelas Arrow se integram bem com o pandas, especialmente quando você realiza uniões. Explore mais neste curso do cousobre como unir dados com o pandas.
O Arrow pode funcionar bem com outras ferramentas de dados, o que facilita a movimentação de dados entre ambientes sem perder velocidade ou estrutura.
No Apache Arrow, o Table é semelhante a um pandas DataFrame, ambos usam colunas nomeadas de igual comprimento. Mas as tabelas Arrow vão além. Eles suportam colunas aninhadas para que você possa representar estruturas de dados mais complexas do que no pandas.
Dito isso, nem todas as conversões são perfeitas. Ainda assim, a conversão entre Arrow e pandas é simples. Veja como:
Tabela de setas → DataFrame do pandas
table.to_pandas()pandas DataFrame → Tabela de setas
pa.Table.from_pandas(df)E é isso! Você só precisa de uma linha de código.
Você também pode trabalhar com outras estruturas do pandas, como Series, usando Arrow. Consulte a documentação para saber mais. Além disso, tanto o Arrow quanto o pandas se beneficiam do design voltado para o desempenho - saiba mais neste curso sobre como escrever código eficiente com o pandas.
O Apache Arrow foi incorporado ao Spark para acelerar a troca de dados entre a JVM (Java Virtual Machine) e o Python. Isso é muito útil para usuários de pandas e NumPy. Ele não é ativado por padrão, portanto, talvez você precise alterar algumas configurações para ativá-lo. Porém, quando está em execução, o Arrow melhora o desempenho de várias maneiras:
Para começar, siga o guia oficial do PySpark with Arrow.
O Arrow também funciona bem com bibliotecas de machine learning, como o TensorFlow.
Seu formato colunar permite o carregamento e o pré-processamento mais rápidos dos dados, etapas essenciais no treinamento de modelos de machine learning. E, ao lidar com grandes conjuntos de dados de forma eficiente, o Arrow ajuda a criar pipelines de ML dimensionáveis que treinam mais rapidamente e funcionam melhor em diferentes ferramentas.
E isso é tudo! Examinamos as ideias centrais por trás do Apache Arrow, vimos como ele é diferente dos formatos de dados mais tradicionais, como configurá-lo e como trabalhar com ele em Python.
Também exploramos exemplos práticos de criação de matrizes e tabelas Arrow e vimos como o Arrow ajuda a ignorar a serialização lenta para manter o processamento de dados rápido e eficiente.
Se você deseja continuar aprendendo e desenvolver o que já foi abordado, aqui estão alguns ótimos recursos para seguir:
Seja qual for o seu próximo passo, esperamos que o Arrow ajude você a criar fluxos de trabalho mais limpos e dimensionáveis!
Saiba mais sobre engenharia de dados com estes cursos!
Programa
Curso
Curso
Tutorial
Vidhi Chugh
Tutorial
Natassha Selvaraj
Tutorial
Natassha Selvaraj
Tutorial
Tim Lu
Tutorial
Karlijn Willems
