
Track
Data Engineer in Python
40 hr
Apache Arrow helps different tools and systems share data quickly and easily. It stores data in a special column-based format that stays in memory, which makes it really fast to work with.
In this tutorial, I’ll walk you through the basics of Apache Arrow. You’ll get hands-on examples to understand how it works and how to use it in your projects.
Apache Arrow is an open-source, cross-language platform for high-performance in-memory data processing. It defines a standardized, columnar memory format optimized for modern CPUs to enable efficient analytics and vectorized computation.
Arrow also removes the need for serialization between systems and languages, which allows for zero-copy reads and cuts down processing overhead.
Because it works well with tools like pandas, Apache Spark, and Dask, you can move data around with minimal effort. That makes it an excellent choice for anyone building fast, flexible systems that need to handle lots of data.
Now, let’s explore Arrow with some practical examples!
Apache Arrow supports multiple languages, including C, C++, C#, Python, Rust, Java, JavaScript, Julia, Go, Ruby, and R.
It works on Windows, macOS, and popular Linux distributions, such as Debian, Ubuntu, CentOS, and Red Hat Enterprise Linux.
In this guide, we’ll use it with Python.
Let’s see how to install Apache Arrow for Python using the official binary wheels published on PyPI. These steps work the same across Windows, macOS, and Linux.
Open your terminal and run:
python --versionIf this returns a version number, you're good to go. If not, install Python from the official site.
pyarrow using pipTo install Apache Arrow for Python, run:
pip install 'pyarrow==19.0.* ' The * ensures you get the latest patch release in the 19.0 series.
I also recommend using pyarrow==19.0.* in your requirements.txt file to keep things consistent across environments. This will install pyarrow along with the required Apache Arrow and Parquet C++ binary libraries bundled with the wheel.
To install Arrow for another language, check out the complete documentation.
You can run this quick Python snippet to check if everything works:
import pyarrow as pa
# Create a simple Arrow array
data = pa.array([1, 2, 3, 4, 5])
print("Apache Arrow is installed and working!")
print("Arrow Array:", data)If pyarrow is installed correctly, you’ll see the array printed in your terminal. If not, the code will throw an error.
Before we get deeper into code, let’s understand how Apache Arrow is built.
The in-memory columnar format is one of Apache Arrow’s most important features. It defines a language-independent, in-memory data structure. In addition, it includes metadata serialization, a protocol for data transport, and a standard way to represent data across systems.
In a columnar format, data is stored in columns instead of rows, which is different from traditional row-based storage. Columnar layouts are popular for analytical workloads because they’re much faster to scan and process.
The image below explains the format:
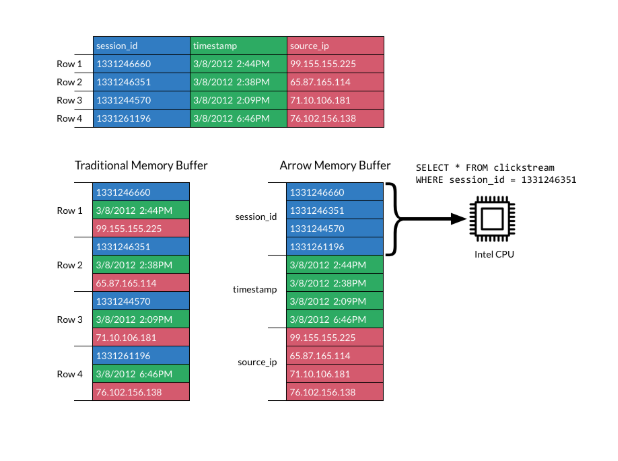
Columnar format. Source: Apache Arrow docs
Apache Arrow’s format boosts efficiency by laying columns in contiguous memory blocks. This supports modern vectorized (SIMD) operations, which speed up data processing.
Using a standard columnar layout, Arrow removes the need for every system to define its internal data format. That reduces both serialization overhead and duplication of effort.
Systems can share data more easily, and developers can reuse algorithms across different languages.
Without a shared format like Arrow, each database or tool needs to serialize and deserialize data before passing it on. That adds cost and complexity. And common algorithms have to be rewritten for each system’s internal data structure.
Arrow changes that by standardizing how data is represented in memory.
While columnar formats are great for analytical performance and memory locality, they’re not designed for frequent updates.
That’s because columnar storage is optimized for fast reading, not modifying. Making changes to data often means copying or reallocating memory, which can be slow and resource-intensive.
Arrow focuses on efficient in-memory representation and serialization. If your use case needs frequent data mutation, you’ll need to handle that at the implementation level.
To dive deeper into Arrow-compatible formats, check out this guide to Apache Parquet, ideal for columnar data storage.
Apache Arrow provides two key data structures: Array and Table:
Array represents a single column of data. It stores values in a contiguous memory block, allowing fast access, efficient scanning, and support for processor-level optimizations like SIMD. Each array can also carry metadata such as null indicators (bitmaps) and data type information.Arrow Table represents a 2D dataset. Each column is a chunked array, and all columns follow a shared schema that defines field names and types. While the chunks can differ across columns, the total number of elements must stay aligned to keep the rows consistent.You can think of it like a DataFrame in pandas or R. It’s tabular, efficient, and supports operations across multiple columns simultaneously.
Let’s look at a few examples of creating an Arrow Array and Table in Python.
Make sure you have pyarrow installed before running the code below, following the previous instructions.
import pyarrow as pa
# Create an Arrow Array (single column)
data = pa.array([1, 2, 3, 4, 5])
print("Arrow Array:")
print(data)
Print an Arrow Array. Image by author.
import pyarrow as pa
# Create an Arrow Table (multiple columns)
table = pa.table({
'column1': pa.array([1, 2, 3]),
'column2': pa.array(['a', 'b', 'c'])
})
print("\nArrow Table:")
print(table)
Print an Arrow Table. Image by author.
Let’s see how to work with Arrow Arrays and perform common operations, such as slicing, filtering, and checking metadata.
Arrow Arrays work with different data types, including strings, floating-point numbers, and integers. Here's how to create them:
import pyarrow as pa
# Integer Array
int_array = pa.array([10, 20, 30], type=pa.int32())
print("Integer Array:")
print(int_array)
# String Array
string_array = pa.array(["apple", "banana", "cherry"], type=pa.string())
print("\nString Array:")
print(string_array)
# Floating-point Array
float_array = pa.array([1.1, 2.2, 3.3], type=pa.float64())
print("\nFloating-point Array:")
print(float_array)
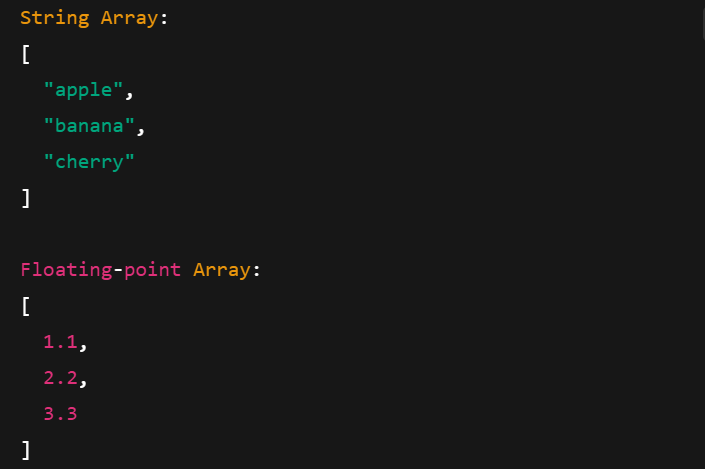
Printing Arrow Arrays with different data types. Image by author.
Let’s look at a few common operations you can perform with Arrow Arrays.
Slicing lets you grab a subsection of an array. For example, you can extract elements at specific index ranges:
import pyarrow as pa
arr = pa.array([10, 20, 30, 40, 50])
# Slice from index 1 to 4 (3 elements: 20, 30, 40)
sliced = arr.slice(1, 3)
print("Original Array:", arr)
print("Sliced Array (1:4):", sliced)
Printing a sliced Arrow Array. Image by Author.
Filtering uses a Boolean mask to keep only values that match a condition. You can also access metadata like type, length, and null counts.
import pyarrow.compute as pc
arr = pa.array([10, 20, 30, 40, 50])
# Create a boolean mask: Keep elements > 25
mask = pc.greater(arr, pa.scalar(25))
# Apply the filter
filtered = pc.filter(arr, mask)
print("Filtered Array (values > 25):", filtered)
print("Array Type:", arr.type)
print("Array Length:", len(arr))
print("Null Count:", arr.null_count)
print("Is Null Bitmap Buffers:", arr.buffers())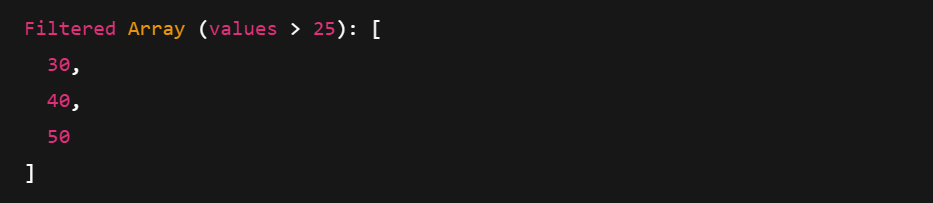
Printing a filtered Arrow Array. Image by Author.

Printing Metadata of an Arrow Array. Image by Author.
You can create Arrow Tables from Arrow Arrays or directly from native Python data structures like dictionaries. Let’s see how.
There are two common ways to create an Arrow Table:
pa.table()Let’s explore both ways one by one.
import pyarrow as pa
# Create individual Arrow Arrays
ids = pa.array([1, 2, 3])
names = pa.array(['Alice', 'Bob', 'Charlie'])
scores = pa.array([85.0, 92.5, 78.3])
# Combine them into a Table
table = pa.table({
'id': ids,
'name': names,
'score': scores
})
print("Arrow Table from Arrays:")
print(table)In the code above:
pa.table()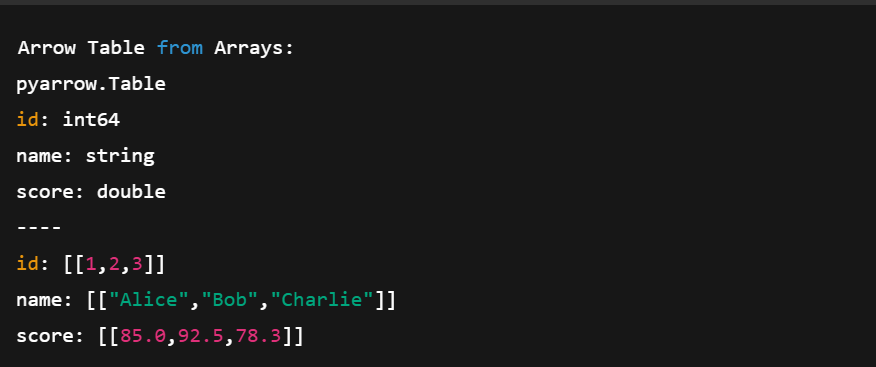
Creating an Arrow Table using multiple Arrow Arrays. Image by author.
Now, let’s see how to create a Table from a Python dictionary.
# Create a table directly from Python data
data = {
'id': [4, 5, 6],
'name': ['Diana', 'Eve', 'Frank'],
'score': [88.0, 79.5, 91.2]
}
table2 = pa.table(data)
print("\nArrow Table from Dictionary:")
print(table2)This method is shorter and more compact. We don’t have to define arrays manually; Arrow handles that for us.
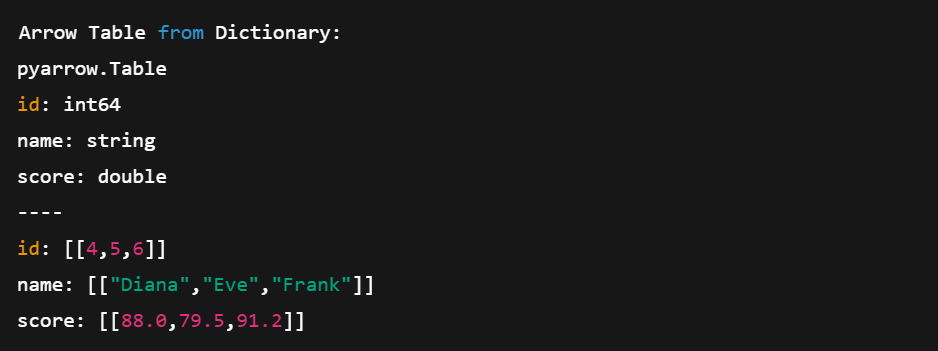
Creating an Arrow Table directly from Python dictionaries. Image by author.
One of Arrow’s biggest strengths is its interoperability. You can easily move between an Arrow Table and a pandas DataFrame. Let’s see how to do that:
import pyarrow as pa
import pandas as pd
# Create an Arrow Table
data = {
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
}
arrow_table = pa.table(data)
# Convert Arrow Table to pandas DataFrame
df = arrow_table.to_pandas()
# Show the DataFrame
print(df)
Converting an Arrow Table to a Pandas DataFrame. Image by author.
Now, let’s see how to do the opposite:
import pyarrow as pa
import pandas as pd
# Create a pandas DataFrame
df = pd.DataFrame({
'numbers': [1, 2, 3],
'fruits': ['apple', 'banana', 'cherry'],
'prices': [1.1, 2.2, 3.3]
})
# Convert pandas DataFrame to Arrow Table
arrow_table = pa.Table.from_pandas(df)
# Show the Arrow Table
print(arrow_table)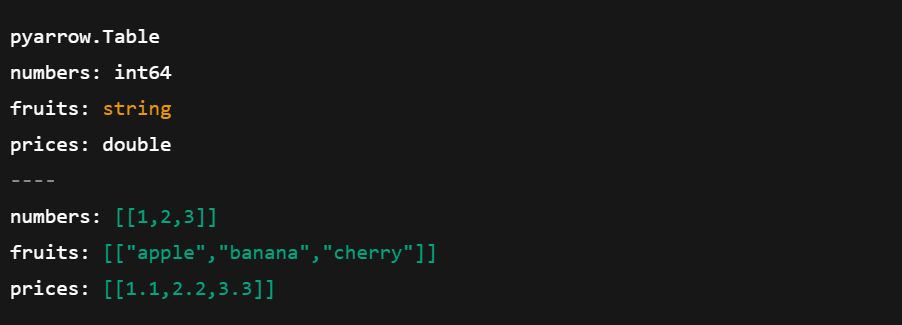
Converting pandas DataFrame to an Array Table. Image by author.
Serialization is the process of converting complex objects or data structures into a stream of bytes to store or send data between systems. But Apache Arrow takes a different approach.
Since Arrow uses a columnar memory format designed for speed, it avoids traditional serialization. Instead, it relies on a shared memory model, where multiple processes can access the same data directly without copying or converting it.
Here’s what it does:
Let’s see how you can save Arrow data using the Feather file format and load it back into a Table using Python.
import pandas as pd
import pyarrow as pa
import pyarrow.feather as feather
# Create a sample pandas DataFrame
df = pd.DataFrame({
'id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie'],
'score': [95.5, 82.0, 77.5]
})
# Convert DataFrame to Arrow Table
table = pa.Table.from_pandas(df)
# Save Arrow Table to a Feather file
feather.write_feather(table, 'example.feather')
print("Arrow table saved to 'example.feather'")
Converting DataFrame to Arrow Table. Image by author.
Then, we can do the opposite and load an Arrow Table from the Feather file created before.
import pyarrow.feather as feather
# Load the Feather file into an Arrow Table
loaded_table = feather.read_table('example.feather')
# (Optional) Convert back to pandas DataFrame
df_loaded = loaded_table.to_pandas()
# Print the loaded data
print(df_loaded)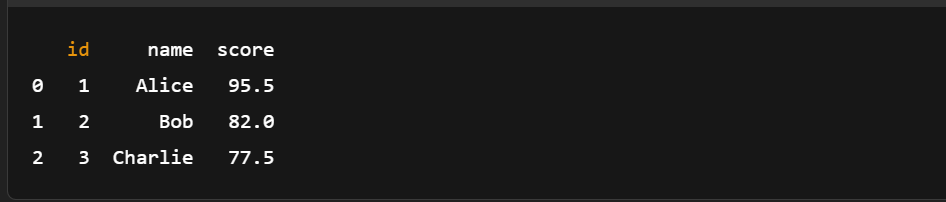
Loading Arrow Table from a Feather file. Image by author.
As you can see, there’s no need for manual serialization. Saving and loading Arrow data only takes a few lines of code.
If you're new to pandas or need a refresher, this pandas cheat sheet is a great companion to Arrow for quick data manipulations.
Let’s look at a real example of how fast and effective Arrow can be when loading, filtering, and analyzing a large dataset.
We'll start by creating a pandas DataFrame with one million rows.
import pandas as pd
import pyarrow as pa
import pyarrow.compute as pc
import time
df = pd.DataFrame({
'id': range(1, 1_000_001), #assuming a dataset with a million rows
'value': pd.np.random.randint(1, 1000, size=1_000_000),
'category': pd.np.random.choice(['A', 'B', 'C'], size=1_000_000)
})start = time.time()
arrow_table = pa.Table.from_pandas(df)
end = time.time()
print(f"Conversion to Arrow Table took {end - start:.4f} seconds")# Example: Filter rows where 'value' > 990
start = time.time()
filtered_table = pc.filter(arrow_table, pc.greater(arrow_table['value'], pa.scalar(990)))
end = time.time()
# Result summary
print(f"Filtering took {end - start:.4f} seconds")
print(f"Filtered row count: {filtered_table.num_rows}")start = time.time()
filtered_df = filtered_table.to_pandas()
end = time.time()
print(f"Conversion to pandas DataFrame took {end - start:.4f} seconds")
Loading a large dataset into an Array. Image by author.
Arrow’s columnar format and SIMD-powered compute functions make it an excellent choice for large-scale in-memory operations. And thanks to zero-copy conversion, moving back to pandas is fast and efficient.
For workflows where you load data before Arrow conversion, this course on streamlined data ingestion with pandas can optimize your pipeline.
You can also use Arrow’s compute API to run basic analytics. Here's a quick demo with a smaller sample dataset.
import pyarrow as pa
import pyarrow.compute as pc
# Sample data
data = {
'id': pa.array([1, 2, 3, 4, 5]),
'score': pa.array([85, 92, 76, 88, 95]),
'category': pa.array(['A', 'B', 'A', 'B', 'A'])
}
# Create Arrow Table
table = pa.table(data)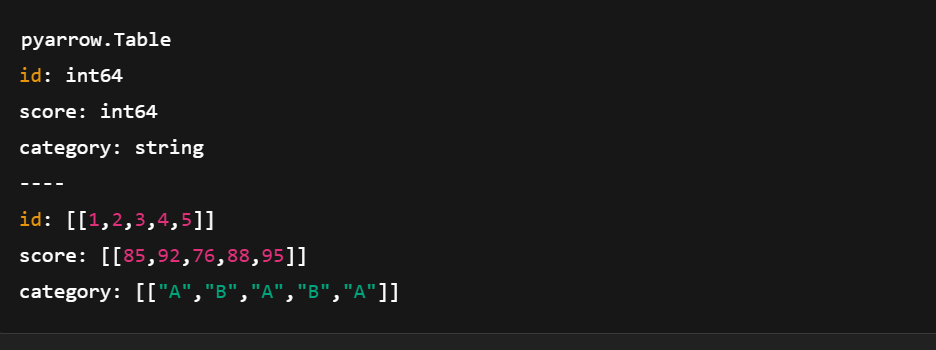
Creating an Arrow Table using pyarrow.compute. Image by author.
# Filter rows where score > 90
filter_mask = pc.greater(table['score'], pa.scalar(90))
filtered_table = pc.filter(table, filter_mask)
print(filtered_table.to_pandas())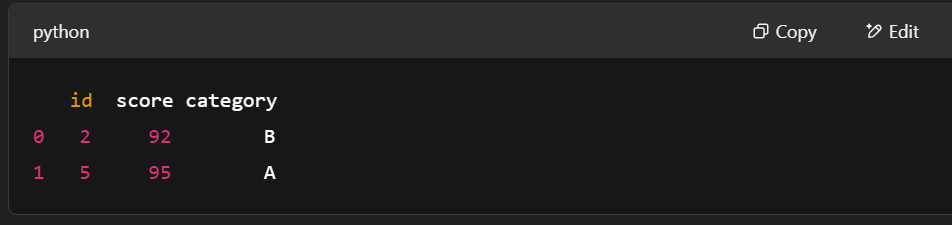
Filtering Rows using pyarrow.compute. Image by author.
# Compute mean of the "score" column
mean_result = pc.mean(table['score'])
print("Mean score:", mean_result.as_py())![]()
Calculating Mean score using pyarrow.compute. Image by author.
import pandas as pd
# Convert to pandas for more complex grouping
df = table.to_pandas()
grouped = df.groupby('category')['score'].mean()
print(grouped)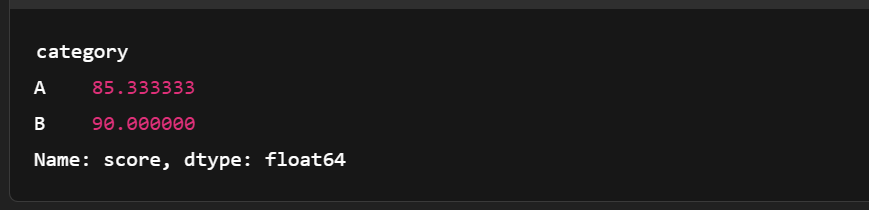
Grouping the Arrow Table. Image by author.
Here’s a quick comparison of Apache Arrow and pandas. It shows where Arrow stands out for large-scale, analytical workloads.
|
Feature |
Apache Arrow |
Pandas |
|
Memory Format |
Columnar, zero-copy, tightly packed |
Row-based (internally uses NumPy arrays) |
|
Speed (Filtering, I/O) |
Faster due to SIMD & vectorization |
Slower on large data (copies, Python loops) |
|
Memory Usage |
More compact, efficient |
Higher memory usage due to Python overhead |
|
Interoperability |
Excellent (shared across languages/tools) |
Mostly Python-centric |
|
Use case Fit |
Optimized for large, analytical workloads |
Great for small/medium data & prototyping |
|
Serialization |
Feather/Parquet with zero-copy support |
CSV/Excel, often slower and bulkier |
As we’ve seen, Arrow Tables integrate well with pandas, especially when performing joins. Explore more in this course about joining data with pandas.
Arrow can work well with other data tools, which makes it easy to move data between environments without losing speed or structure.
In Apache Arrow, the Table is similar to a pandas DataFrame, both use named columns of equal length. But Arrow Tables go further. They support nested columns so you can represent more complex data structures than in pandas.
That said, not all conversions are seamless. Still, converting between Arrow and pandas is simple. Here’s how:
Arrow Table → pandas DataFrame
table.to_pandas()pandas DataFrame → Arrow Table
pa.Table.from_pandas(df)And that’s it! One line of code is all it takes.
You can also work with other pandas structures like Series using Arrow. Check the docs to learn more. Also, both Arrow and pandas benefit from performance-minded design—learn more in this course on writing efficient code with pandas.
Apache Arrow is built into Spark to speed up data exchange between the JVM (Java Virtual Machine) and Python. This is quite helpful for pandas and NumPy users. It’s not enabled by default, so you may need to change some settings to turn it on. But once it’s running, Arrow improves performance in several ways:
To get started, follow the official PySpark with Arrow guide.
Arrow also works well with machine learning libraries like TensorFlow.
Its columnar format allows faster data loading and preprocessing, key steps in training machine learning models. And by handling large datasets efficiently, Arrow helps build scalable ML pipelines that train faster and work better across different tools.
And that’s a wrap! We walked through the core ideas behind Apache Arrow, looked at how it’s different from more traditional data formats, how to set it up, and how to work with it in Python.
We also explored hands-on examples for building Arrow Arrays and Tables and saw how Arrow helps skip slow serialization to keep data processing fast and efficient.
If you’re keen to keep learning and build on what we’ve covered, here are some great resources to go next:
Wherever you go next, we hope Arrow helps you build cleaner and more scalable workflows!
Learn more about data engineering with these courses!
Track
Course
Course
blog
Moez Ali
9 min
cheat-sheet
Karlijn Willems
Tutorial
Laiba Siddiqui
Tutorial
Karlijn Willems
Tutorial
Jake Roach
Tutorial
Natassha Selvaraj


