Curso
Comprender la ingeniería de datos
2 h
355.8K
El semestre pasado, en tu curso de sistemas de bases de datos, se asignó un proyecto final que, en un principio, parecía sencillo: crear una aplicación de comercio electrónico funcional con autenticación de usuarios, carritos de la compra y procesamiento de pedidos. ¿Cuál es el problema? Teníamos que demostrar que funcionaba con patrones de datos realistas, no solo con tres usuarios de prueba llamados «Ali», «Shahd» y «Khalid».
Mi equipo se enfrentó a un problema inmediato. Necesitábamos cientos de registros de clientes con historiales de compra variados para probar casos extremos como pedidos masivos, reembolsos y gestión de inventario. No podíamos extraer datos reales de sitios web existentes; eso es poco ético e ilegal. Crear cientos de registros realistas manualmente llevaría una eternidad. Fue entonces cuando nuestro profesor nos habló del enmascaramiento de datos.
En este artículo, compartiré lo que he aprendido de mis propias experiencias al implementar técnicas de enmascaramiento de datos. Descubrirás qué es el enmascaramiento de datos, cuándo y por qué es importante, y cómo aplicar técnicas específicas para proteger la información confidencial sin perder la utilidad de los datos. Repasaré ejemplos prácticos de mi proyecto y te mostraré cómo evitar los errores que encontré por el camino.
Cuando escuché por primera vez el término «enmascaramiento de datos», me imaginé algo parecido a la censura de textos en documentos gubernamentales, simplemente tachando las partes sensibles. La realidad es más sofisticada y útil. El enmascaramiento de datos crea versiones de datos confidenciales que son estructuralmente similares, pero falsas en cuanto a los hechos.
El proceso técnico consiste en sustituir los valores originales de los datos por alternativas ficticias que conservan el formato, el tipo y las propiedades estadísticas. Para nuestro proyecto de comercio electrónico, tomamos un pequeño conjunto de datos con información real de clientes procedente de una herramienta de generación de datos y aplicamos técnicas de enmascaramiento para crear variaciones. Un correo electrónico como khalid.abdelaty@company.com se convirtió en ahmed.j@enterprise.com. Ambos son formatos de correo electrónico válidos que superan las comprobaciones de validación, pero la versión enmascarada no revela nada sobre personas reales.
Encontrarás este concepto con diferentes nombres dependiendo de quién lo mencione. La ofuscación de datos hace hincapié en el aspecto de ocultación. La seudonimización se refiere específicamente a la sustitución de información identificable, manteniendo la capacidad de volver a identificar los datos si fuera necesario. La tokenización consiste en sustituir valores confidenciales por tokens generados aleatoriamente. Estos términos se solapan significativamente y, por lo que he visto en la documentación y los tutoriales, la gente suele utilizarlos de forma intercambiable.
En este punto, es posible que te preguntes si esos nuevos correos electrónicos o identificadores se derivan de alguna manera de los datos originales. La respuesta corta: depende de la técnica de enmascaramiento. He dejado más información al respecto en las preguntas frecuentes.
La importancia de esto quedó clara cuando nuestro profesor señaló que vuestro «proyecto de clase» reflejaba los retos reales de la producción. Las empresas necesitan probar el software con datos similares a los de producción, y los analistas necesitan crear modelos con patrones realistas. Sin embargo, el uso de datos reales de clientes en estos entornos plantea graves problemas.
El cumplimiento normativo es una de las principales preocupaciones de la mayoría de las organizaciones. El RGPD, el reglamento europeo sobre privacidad, exige que las organizaciones minimicen el tratamiento de datos y protejan la información personal mediante medidas técnicas adecuadas. La HIPAA exige a los proveedores de atención médica que protejan la información de los pacientes incluso en entornos de prueba. La Ley de Privacidad del Consumidor de California extiende protecciones similares a los residentes de California. Desde el punto de vista empresarial, infringir estas normas conlleva multas cuantiosas. Desde una perspectiva ética, las personas esperan que sus datos estén protegidos.
El enmascaramiento de datos también ofrece importantes ventajas en materia de seguridad. Cada entorno adicional que contiene datos reales aumenta la superficie de ataque. Los servidores de desarrollo suelen tener controles de seguridad más débiles que los sistemas de producción, y los programadores suelen trabajar con datos en equipos locales que pueden no estar cifrados. Cada escenario presenta riesgos de violación que el enmascaramiento de datos elimina al garantizar que los entornos que no son de producción nunca contengan información real.
Lo que más me sorprendió fue descubrir los beneficios prácticos para el desarrollo. Nuestras pruebas de control de calidad revelaron errores que nunca hubiéramos encontrado con nuestro conjunto de datos de prueba original de tres usuarios. El código de un miembro del equipo falló al procesar nombres con apóstrofos como «O'Brien». Otro se rompió en direcciones de correo electrónico que usaban alias con signos más, como «usuario+tag@domain.com."»; Estos casos extremos solo aparecieron porque nuestro conjunto de datos enmascarados, derivado de patrones realistas, contenía la complejidad que tendrían los datos de producción reales.
Entender cuándo se aplica el enmascaramiento me ayudó a reconocerlo en diferentes contextos. El escenario más obvio refleja nuestro proyecto de clase: desarrollo y pruebas de software. Al crear nuevas funciones o depurar código existente, los programadores necesitan datos que representen la complejidad del mundo real. Pasé horas depurando por qué el cálculo de tu carrito de la compra fallaba en determinadas combinaciones de productos. El error solo apareció porque nuestro conjunto de datos enmascarados incluía casos extremos, como artículos de cero dólares y límites de cantidad.
Los proyectos de análisis de datos e investigación suelen requerir grandes conjuntos de datos con propiedades estadísticas realistas. Un compañero de equipo que trabajaba en otro proyecto de análisis necesitaba conocer los patrones de compra de los clientes para crear algoritmos de recomendación. No necesitaba los nombres ni las direcciones reales de los clientes, solo los patrones de comportamiento. Los datos enmascarados proporcionaron esos patrones al tiempo que protegían la privacidad.
La colaboración externa presenta otro caso de uso común. Las empresas suelen contratar a consultores o contratistas para proyectos de integración que necesitan datos realistas, pero no deben tener acceso a información confidencial de los clientes. La formación de los empleados representa otra aplicación práctica más. Antes de que alguien toque los sistemas de producción, necesitáis entornos de práctica con datos realistas pero seguros. Como último ejemplo, el desarrollo en la nube también se beneficia del enmascaramiento, aunque los principales proveedores de servicios en la nube ofrecen sus propias herramientas de enmascaramiento como parte de sus servicios de seguridad.
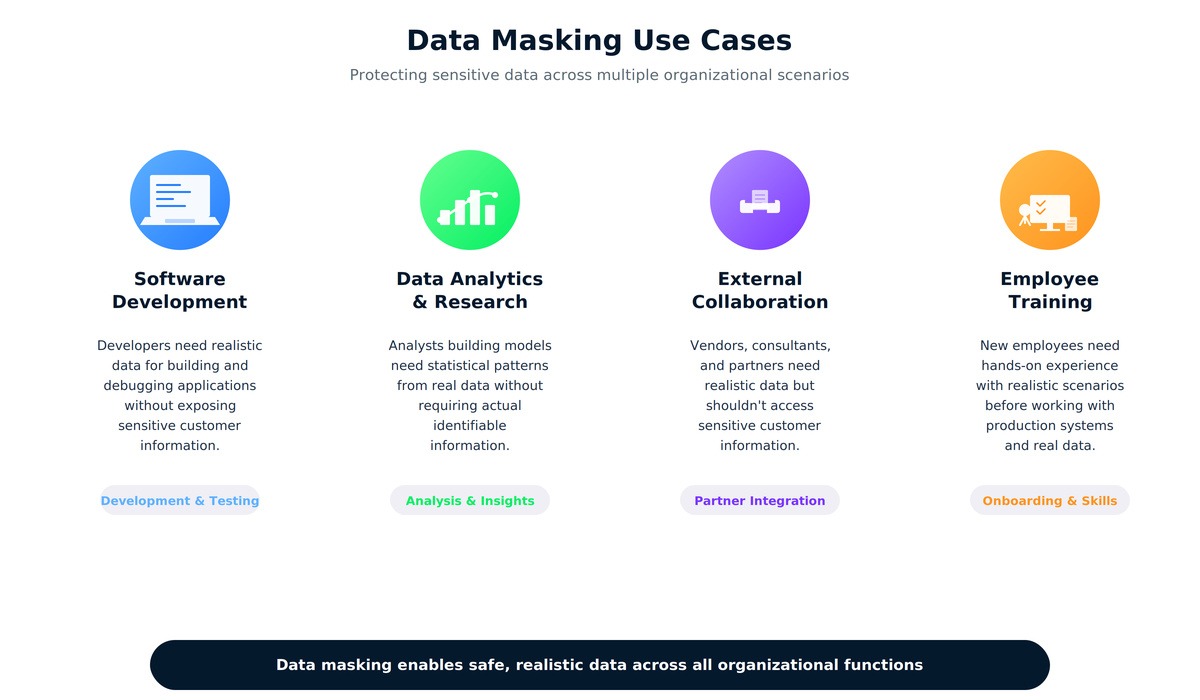
El enmascaramiento de datos satisface múltiples necesidades organizativas, desde el desarrollo hasta el cumplimiento normativo.
Antes de profundizar en técnicas específicas, conviene comprender los principales tipos de enmascaramiento y cuándo utilizar cada uno de ellos.
El enmascaramiento estático opera sobre conjuntos de datos almacenados, creando copias enmascaradas que existen independientemente de los datos originales. Esto es lo que utilizamos para nuestro proyecto de comercio electrónico. Ejecuté un script de Python que leía nuestro conjunto de datos inicial, aplicaba transformaciones de enmascaramiento y escribía los resultados en un nuevo archivo que todos utilizabamos para el desarrollo. Una vez creado, ese conjunto de datos enmascarado se mantuvo estable hasta que fue necesario actualizarlo con nuevos patrones. La ventaja se hizo evidente rápidamente: el impacto en el rendimiento se produjo una sola vez durante el proceso de enmascaramiento, lo que lo hacía ideal para entornos que no fueran de producción, en los que se enmascara una sola vez y se utiliza la copia repetidamente.
El enmascaramiento dinámico se produce en tiempo real a medida que los usuarios acceden a los datos, aplicando transformaciones basadas en los permisos. Descubrí este concepto por primera vez mientras leía sobre las funciones de seguridad de las bases de datos. Un administrador del sistema ve los registros completos de los clientes, mientras que un representante de soporte técnico ve los números de las tarjetas de crédito ocultos. Los datos subyacentes permanecen sin cambios, pero lo que ve cada usuario depende de su nivel de autorización. Este enfoque se adapta a los sistemas de producción en los que diferentes usuarios necesitan diferentes vistas en función de sus roles.
El enmascaramiento determinista garantiza la coherencia al sustituir siempre la misma entrada por la misma salida. Si la clienta «Sarah Ali» pasa a ser «Eman Mohamed» en una tabla, esa transformación se aplica a todos los lugares en los que aparece Sarah Ali. Como explicaré en la sección de técnicas, esta coherencia es fundamental para mantener las relaciones entre las tablas de la base de datos. Nuestro proyecto requería un enmascaramiento determinista para mantener la coherencia de los ID de los clientes en las tablas de clientes, pedidos y reseñas.
El enmascaramiento sobre la marcha aplica transformaciones durante la transferencia de datos entre entornos. Probé este enfoque al configurar un canal de implementación para un proyecto personal. El enmascaramiento se realizó durante la extracción de datos, en lugar de como un paso independiente, lo que simplificó el flujo de trabajo y lo hizo especialmente ideal para los procesos de CI/CD.
Los investigadores necesitan acceder a patrones de datos para descubrir tendencias, comprobar hipótesis y crear modelos fiables, pero compartir datos del mundo real a menudo conlleva el riesgo de exponer información confidencial. La ofuscación estadística (otra forma de enmascaramiento de datos) ofrece una solución. Cuando se hace correctamente, conserva las propiedades estadísticas esenciales (por ejemplo, medias, varianzas y correlaciones) y, al mismo tiempo, mantiene el secreto de los registros individuales. Esto permite a los analistas extraer conclusiones válidas de los datos sin comprometer la privacidad.
Aquí es donde la teoría se unió a la práctica en nuestro proyecto. Cada una de las técnicas que voy a explicar en la siguiente sección resolvió un reto concreto al que nos enfrentábamos.
La sustitución se convirtió en mi enfoque predeterminado para la mayoría de la información de identificación personal. El concepto es sencillo: sustituir los valores confidenciales por alternativas realistas, pero completamente ficticias. Los nombres se convierten en nombres diferentes. Las direcciones de correo electrónico se convierten en direcciones de correo electrónico diferentes. Los valores de sustitución mantienen el mismo formato y parecen auténticos para cualquiera que vea los datos.
Para nuestro proyecto de comercio electrónico, necesitaba ocultar rápidamente la información de los clientes. Descubrí la biblioteca Faker, que se puede instalar con pip install Faker, y creé una función de enmascaramiento sencilla. Faker genera una amplia variedad de datos falsos realistas, lo que lo hace perfecto para operaciones de enmascaramiento:
from faker import Faker
import pandas as pd
fake = Faker()
def mask_customer_data(customer_df):
masked_df = customer_df.copy()
masked_df['first_name'] = [fake.first_name() for _ in range(len(masked_df))]
masked_df['last_name'] = [fake.last_name() for _ in range(len(masked_df))]
masked_df['email'] = [fake.email() for _ in range(len(masked_df))]
return masked_df
# Example usage
original_customers = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com']
})
masked_customers = mask_customer_data(original_customers)El código anterior toma un DataFrame de pandas con registros de clientes y sustituye la información identificativa por alternativas ficticias. Ejecutar esto en nuestro conjunto de datos inicial tardó unos dos minutos y nos proporcionó cientos de nombres y direcciones de correo electrónico de clientes con un aspecto muy realista. La biblioteca Faker se encargó de la complejidad de generar nombres diversos y creíbles, así como direcciones de correo electrónico con el formato adecuado. También aprendí que, dado que los resultados se generaban aleatoriamente, no eran directamente reidentificables, lo cual me pareció muy bien.
Una cosa que aprendí: Los datos enmascarados deben parecer lo suficientemente auténticos como para que tu cerebro no los rechace durante el desarrollo. Al principio, probé a utilizar combinaciones aleatorias de letras, pero depurar código con clientes llamados «Xkqp Mmwz» me parecía ridículo y me dificultaba concentrarme en los problemas lógicos reales. Los nombres generados por el falsificador, como «Jennifer Martínez» y «Robert Chen», parecían lo suficientemente naturales como para tomarlos en serio.
Para obtener más información sobre la manipulación de datos en Python, nuestro curso Introducción a la ciencia de datos en Python cubre las operaciones fundamentales de DataFrame que facilitan la implementación de estas y otras técnicas.
El barajado resolvió un problema que no había previsto inicialmente. Nuestro proyecto incluía un panel de administración que mostraba los importes medios de compra por perfil demográfico de los clientes. Necesitábamos importes de compra realistas para comprobar si nuestras consultas de agregación funcionaban correctamente, pero no necesitábamos clientes específicos vinculados a compras específicas.
La reorganización aleatoria reordena los valores dentro de una columna de forma aleatoria, conservando la distribución general:
import numpy as np
import pandas as pd
def shuffle_column(df, column_name):
shuffled_df = df.copy()
shuffled_values = shuffled_df[column_name].values
np.random.seed(42) # For reproducibility
np.random.shuffle(shuffled_values)
shuffled_df[column_name] = shuffled_values
return shuffled_df
# Example with purchase data
purchase_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'product': ['Laptop', 'Headphones', 'Mouse'],
'amount': [1200, 85, 25]
})
shuffled_purchases = shuffle_column(purchase_data, 'amount')Después de la reorganización, los importes de las compras seguían existiendo en el conjunto de datos (aún podíamos calcular medias y distribuciones precisas), pero se había perdido la conexión entre el cliente C001 y la compra de 1200 $. El cliente C001 ahora podría mostrar una compra de 25 dólares en su lugar.
La idea clave: El barajado mantiene las propiedades estadísticas necesarias para el análisis agregado, al tiempo que rompe las asociaciones a nivel individual. Es perfecto cuando se prueban funciones que trabajan con agregados en lugar de registros individuales.
El enmascaramiento parcial revela solo la información necesaria y oculta el resto. Esta técnica me resultaba familiar porque la había visto en todas partes, en sitios web que mostraban números de tarjetas de crédito como ****-****-****-1234 o en aplicaciones que mostraban números de teléfono como (***) ***-5678.
Implementar esto en nuestro proyecto fue muy sencillo:
def mask_credit_card(card_number):
visible_digits = 4
masked_portion = '*' * (len(card_number) - visible_digits)
return masked_portion + card_number[-visible_digits:]
def mask_phone(phone):
return '***-***-' + phone[-4:]
# Examples
print(mask_credit_card('4532123456781234')) # ************1234
print(mask_phone('555-0123')) # ***-***-0123Lo utilizamos para la vista del historial de pedidos, donde los clientes necesitaban verificar qué tarjeta habían utilizado para una compra. Mostrar los últimos cuatro dígitos proporcionaba información suficiente para el reconocimiento sin revelar el número completo. Me pareció que era el equilibrio perfecto entre utilidad y privacidad.
A veces, la solución más sencilla es simplemente eliminar los datos por completo. La anulación sustituye los valores de los campos por NULL o cadenas vacías cuando la información no es necesaria para la prueba.
def null_fields(df, fields_to_null):
masked_df = df.copy()
for field in fields_to_null:
masked_df[field] = None
return masked_dfNuestros registros de clientes incluían un campo de «notas» en el que los hipotéticos representantes del servicio de atención al cliente podían escribir comentarios internos. Este campo no era relevante para probar la lógica del carrito de la compra ni el procesamiento de pagos, así que lo dejé en blanco. ¿Por qué molestarse en crear notas falsas cuando simplemente podríamos eliminar el campo de nuestros datos de prueba?
Esto me enseñó una lección importante sobre el enmascaramiento: no hay que complicar demasiado las cosas. Enmascara lo que sea necesario enmascarar, elimina lo que no sea necesario.
La aleatorización genera valores completamente nuevos para los campos en los que no tiene sentido mantener ninguna conexión con los datos originales. Esto funcionó bien para los identificadores y los números de referencia:
import random
import string
def randomize_order_id():
return 'ORD-' + ''.join(random.choices(string.ascii_uppercase + string.digits, k=8))
order_ids = [randomize_order_id() for _ in range(5)]
print(order_ids)Nuestros ID de pedido no tenían que coincidir con nada del conjunto de datos original. Solo tenían que parecer realistas y ser únicos. La generación aleatoria cumplía ambos requisitos. Cada ID generado, como «ORD-K7M2N9P4», parecía una referencia de pedido plausible sin conexión con nada real.
La tokenización sustituye los valores confidenciales por tokens generados aleatoriamente, al tiempo que almacena de forma segura los datos originales en un sistema independiente y altamente protegido. A diferencia de otras técnicas de enmascaramiento, la tokenización está diseñada para ser reversible, pero solo a través de un acceso controlado. Aprendí sobre este enfoque mientras investigaba los requisitos para el procesamiento de pagos:
import uuid
# Note: Production token vaults use encrypted database storage, not in-memory dicts
class TokenVault:
def __init__(self):
self.token_map = {}
self.reverse_map = {}
def tokenize(self, sensitive_value):
if sensitive_value in self.token_map:
return self.token_map[sensitive_value]
token = str(uuid.uuid4())
self.token_map[sensitive_value] = token
self.reverse_map[token] = sensitive_value
return token
def detokenize(self, token):
return self.reverse_map.get(token)
vault = TokenVault()
token = vault.tokenize('4532-1234-5678-9012')
print(f"Token: {token}")
original = vault.detokenize(token)
print(f"Original: {original}")No implementamos la tokenización en nuestro proyecto de clase porque no necesitábamos reversibilidad. Pero al leer sobre los sistemas de pago, el caso de uso quedó claro: Tu base de datos de aplicaciones solo almacena los tokens (cadenas aleatorias sin valor), mientras que los datos de pago reales se guardan en una caja fuerte de tokens totalmente independiente y altamente protegida. Si tu base de datos de aplicaciones se ve comprometida, el atacante solo obtendrá tokens inútiles sin posibilidad de acceder a los números reales de las tarjetas de crédito sin violar la propia bóveda. Esta separación arquitectónica es lo que hace que la tokenización sea especialmente valiosa para el cumplimiento normativo en el procesamiento de pagos.
Las técnicas criptográficas transforman los datos utilizando algoritmos matemáticos. Implementé el hash para el almacenamiento de contraseñas después de que nuestro profesor insistiera en que nunca se almacenaran contraseñas en texto plano. Para los sistemas de producción, debes utilizar bcrypt o Argon2, que incorporan sales y están diseñados para ser computacionalmente costosos y resistir los ataques de fuerza bruta. Aquí muestro bcrypt, aunque Argon2 también es excelente para la producción:
import bcrypt
def hash_password(password):
# Generate a salt and hash the password
salt = bcrypt.gensalt()
hashed = bcrypt.hashpw(password.encode(), salt)
return hashed
def verify_password(password, hashed):
# Verify a password against its hash
return bcrypt.checkpw(password.encode(), hashed)
# Store the hash, never the actual password
password = 'user_password_123'
password_hash = hash_password(password)
print(f"Stored hash: {password_hash}")
# Output: Stored hash: b'$2b$12$K7g.../XYZ' (different each time due to random salt)
# Verify during login
is_valid = verify_password('user_password_123', password_hash)
print(f"Password valid: {is_valid}") # Output: Password valid: TrueEl hash crea transformaciones unidireccionales útiles para la verificación. Cuando probé esto por primera vez, me sorprendió que bcrypt generara un hash diferente cada vez debido a la sal aleatoria, pero verify_password() siguiera coincidiendo correctamente con la contraseña original. La sal garantiza que incluso contraseñas idénticas produzcan hash diferentes, lo que protege contra los ataques de tablas arcoíris. Durante el inicio de sesión, realizamos un hash de la contraseña enviada y utilizamos la función de verificación de bcrypt para compararla de forma segura. Esto significa que ni siquiera los programadores con acceso a la base de datos pueden ver las contraseñas de los usuarios.
Nota: Para utilizar este ejemplo, deberás instalar bcrypt con pip install bcrypt.
El cifrado se diferencia del hash en que permite descifrar el texto hasta recuperar la forma original mediante claves. No necesitábamos cifrado para nuestro proyecto, pero entiendo su finalidad: Úsalo cuando las partes autorizadas necesiten acceder a datos reales, pero quieras protegerlos del acceso no autorizado.
Estas técnicas relacionadas difieren en su reversibilidad. La seudonimización sustituye la información identificable, al tiempo que mantiene la capacidad de volver a identificar a las personas cuando sea necesario. La anonimización elimina por completo la información identificable, lo que hace imposible la reidentificación.
def pseudonymize_data(df, id_column, key_mapping=None):
if key_mapping is None:
key_mapping = {}
pseudo_df = df.copy()
for idx, original_id in enumerate(pseudo_df[id_column].unique()):
if original_id not in key_mapping:
key_mapping[original_id] = f"PSEUDO_{idx:06d}"
pseudo_df.loc[pseudo_df[id_column] == original_id, id_column] = key_mapping[original_id]
return pseudo_df, key_mapping
# Using pseudonymization
customer_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C001'],
'purchase': ['Laptop', 'Mouse', 'Keyboard']
})
pseudonymized_data, mapping = pseudonymize_data(customer_data, 'customer_id')Nuestro proyecto utilizó la seudonimización para mantener la coherencia de los clientes en múltiples compras, al tiempo que ocultaba los identificadores reales de los clientes. Las tres compras del cliente C001 se asignaron al mismo seudónimo, lo que permitió analizar el comportamiento individual del cliente sin revelar su identidad real.
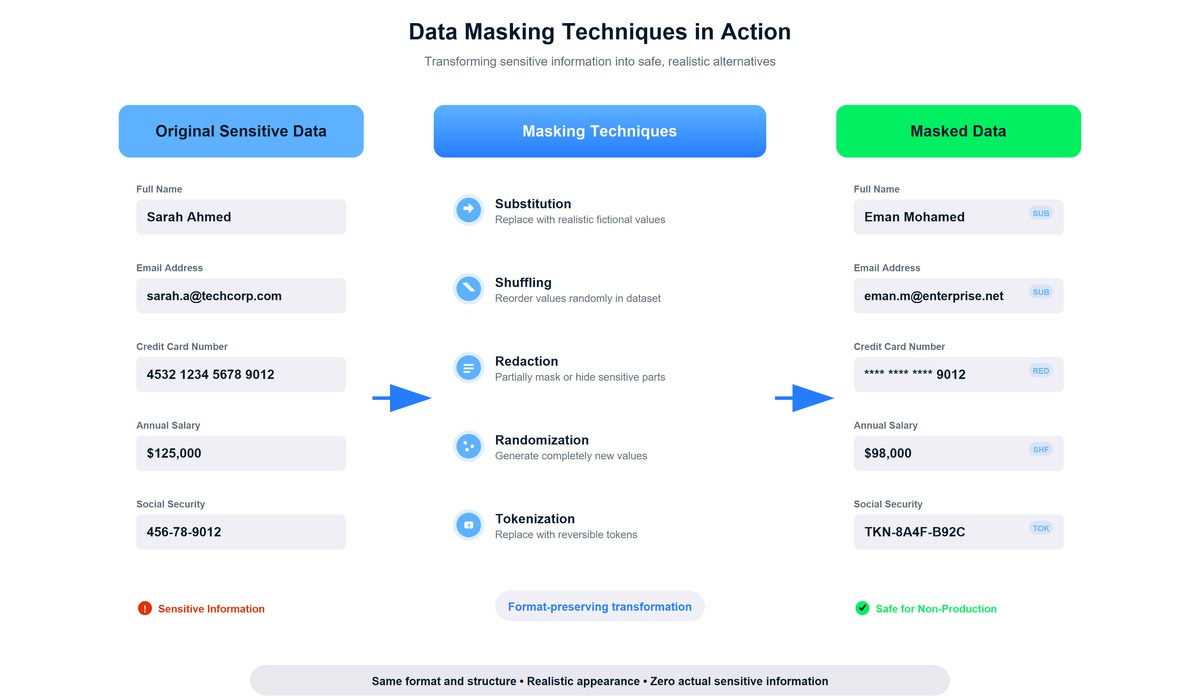
Las múltiples técnicas de enmascaramiento transforman los datos confidenciales sin alterar el formato ni la usabilidad.
Al principio, confundía el enmascaramiento de datos con el cifrado y la anonimización, ya que todos ellos implican la protección de información confidencial. Comprender las diferencias me ayudó a elegir las técnicas adecuadas para cada situación. Permíteme desglosar las diferencias clave de manera que quede claro cuándo utilizar cada enfoque.
|
Enfoque |
Cómo funciona |
Reversibilidad |
Mejor caso de uso |
|
Enmascaramiento de datos |
Reemplaza los datos confidenciales por valores ficticios pero realistas. |
Irreversible (sin recuperación sin la base de datos de origen) |
Entornos de desarrollo, pruebas y análisis en los que se necesita una estructura de datos realista, pero no valores reales. |
|
Cifrado |
Cifra los datos utilizando algoritmos matemáticos. |
Reversible con claves de descifrado |
Protección de los datos en tránsito o almacenados cuando los usuarios autorizados necesitan acceder a los valores originales. |
|
Anonimización |
Elimina o generaliza la información identificativa. |
Irreversible (diseñado para impedir la reidentificación) |
Publicación de conjuntos de datos para investigación o uso público, protegiendo al mismo tiempo la privacidad individual. |
|
Datos sintéticos |
Genera conjuntos de datos totalmente artificiales utilizando modelos estadísticos o ML. |
N/A (no hay datos originales a los que recurrir) |
Entrenamiento de modelos de machine learning o escenarios en los que incluso los datos reales enmascarados parecen demasiado arriesgados. |
Durante la unidad sobre seguridad de bases de datos, comprendí claramente la diferencia entre cifrado y enmascaramiento. Ciframos las copias de seguridad de la base de datos para que fueran inútiles en caso de robo, pero ocultamos la base de datos de desarrollo porque los programadores necesitaban trabajar con los datos, pero no con los datos reales de los clientes. Como mencioné anteriormente, el cifrado protege los datos que eventualmente descifrarás, mientras que el enmascaramiento crea alternativas seguras de forma permanente.
La diferencia entre el enmascaramiento y la anonimización pone de relieve objetivos diferentes. La anonimización se centra específicamente en eliminar la información identificable para evitar la reidentificación de las personas mediante técnicas como la generalización (sustitución de edades exactas por rangos de edad) y la supresión (eliminación total de los atributos identificativos). El enmascaramiento hace hincapié en mantener la utilidad de los datos para el desarrollo, las pruebas y el análisis.
Un compañero de clase que trabajaba en un proyecto de machine learning utilizó datos sintéticos generados a partir de patrones de un conjunto de datos reales. Los datos sintéticos no contenían registros reales, sino que imitaban las propiedades estadísticas necesarias para el entrenamiento del modelo. Elegí el enmascaramiento en lugar de los datos sintéticos para nuestro proyecto porque necesitábamos probar escenarios específicos, como el manejo de direcciones de correo electrónico duplicadas o el procesamiento de direcciones internacionales. Es posible que los datos sintéticos no capturen estos casos extremos, mientras que los datos reales enmascarados los conservan.
La implementación del enmascaramiento me enseñó que proteger la información confidencial y, al mismo tiempo, mantener la utilidad de los datos implica superar retos que no son evidentes hasta que te enfrentas a ellos. Permíteme explicarte los principales obstáculos a los que me enfrenté y cómo los superé.
La conservación de los atributos resultó más complicada de lo esperado. El simple hecho de sustituir valores al azar rompe los patrones de los que dependen las aplicaciones. Los números de tarjetas de crédito siguen el algoritmo de Luhn para la validación de la suma de comprobación, las direcciones de correo electrónico requieren dominios con el formato adecuado y los códigos postales se corresponden con regiones geográficas. Aprendí esto por las malas cuando tu primer intento de enmascaramiento generó números aleatorios de 16 dígitos para los campos de la tarjeta de crédito. Todo parecía estar bien hasta que las pruebas revelaron que nuestra lógica de validación de pagos rechazaba todos los números de tarjeta porque había olvidado que los números de tarjetas de crédito incluyen dígitos de control calculados mediante el algoritmo de Luhn.
La integridad semántica es importante más allá del formato. Los datos enmascarados deben evitar combinaciones que sean obviamente absurdas. Durante las pruebas, un compañero de equipo se dio cuenta de que nuestro conjunto de datos enmascarados tenía códigos postales de Alaska asignados a direcciones postales de Florida. Aunque se trataba de formatos técnicamente válidos, la discrepancia geográfica resultaba sospechosa. Pasé una tarde mejorando la coherencia semántica generando direcciones completas en las que todos los componentes coincidían geográficamente, en lugar de emparejar aleatoriamente los componentes de las direcciones.
La integridad referencial entre tablas generaba una complejidad significativa. Como expliqué en la sección de técnicas, nuestra base de datos tenía tablas de clientes, pedidos y reseñas, y los ID de los clientes aparecían en las tres. Si el enmascaramiento transformaba los ID de los clientes de forma inconsistente, estas relaciones se rompían por completo. Esto me ocurrió después de mi primer intento de enmascaramiento: el 30 % de nuestras pruebas de integración fallaron porque los pedidos de los clientes ya no se vinculaban con los registros de los clientes. El avance se produjo cuando me di cuenta de que necesitaba procesar las tablas en orden de dependencia utilizando un enmascaramiento determinista para garantizar que el cliente C001 siempre se convirtiera en el mismo ID enmascarado dondequiera que apareciera.
Equilibrar la seguridad con el valor analítico requiere un juicio constante. Un enmascaramiento más agresivo proporciona mayor privacidad, pero reduce la utilidad. Por ejemplo, redondear todas las edades a la década más cercana mejora la privacidad, pero elimina análisis útiles basados en la edad. Nuestro proyecto favorecía la utilidad, ya que estábamos creando funciones para aplicaciones que requerían un comportamiento realista de los datos. En un escenario de producción real con datos reales de clientes y obligaciones de cumplimiento normativo, tendría que dar más importancia a la protección de la privacidad y, posiblemente, aceptar una menor utilidad de los datos.
Las relaciones estadísticas pueden distorsionarse. Si tienes dos columnas correlacionadas, como ingresos y gastos, y las mezclas de forma independiente, es probable que la correlación cambie. Desde una perspectiva estadística, la codificación independiente altera la distribución conjunta de las variables. Para preservar esta relación, los analistas a veces utilizan transformaciones que conservan el orden, como mezclar ambas columnas utilizando la misma permutación aleatoria o añadir ruido controlado que mantenga su orden conjunto.
Después de aprender estas técnicas individuales, quería ver cómo funcionaban juntas en un escenario realista. Aquí tienes un ejemplo completo que muestra cómo ocultar una base de datos de clientes con los pedidos relacionados, el mismo reto al que nos enfrentamos en nuestro proyecto de comercio electrónico.
from faker import Faker
import pandas as pd
import numpy as np
import uuid
fake = Faker()
Faker.seed(42) # For reproducible results
# Original datasets (simulating real customer data)
customers_original = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com'],
'phone': ['555-0123', '555-0124', '555-0125'],
'credit_card': ['4532-1234-5678-9012', '4556-7890-1234-5678', '4539-8765-4321-0987'],
'internal_notes': ['VIP customer', 'Requested callback', 'Payment issue resolved']
})
orders_original = pd.DataFrame({
'order_id': ['ORD001', 'ORD002', 'ORD003', 'ORD004'],
'customer_id': ['C001', 'C002', 'C001', 'C003'],
'product': ['Laptop', 'Mouse', 'Keyboard', 'Monitor'],
'amount': [1299.99, 29.99, 89.99, 399.99]
})
# Step 1: Create deterministic ID mapping to maintain referential integrity
def create_id_mapping(ids):
"""Create consistent pseudonymous IDs"""
mapping = {}
for idx, original_id in enumerate(ids):
mapping[original_id] = f"CUST_{idx:06d}"
return mapping
customer_id_mapping = create_id_mapping(customers_original['customer_id'].unique())
# Step 2: Mask customer data using multiple techniques
def mask_customer_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Replace customer IDs consistently
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Substitution: Replace names and emails with realistic fake data
masked['first_name'] = [fake.first_name() for _ in range(len(masked))]
masked['last_name'] = [fake.last_name() for _ in range(len(masked))]
masked['email'] = [fake.email() for _ in range(len(masked))]
# Partial masking/redaction: Show last 4 digits of phone and credit card
masked['phone'] = masked['phone'].apply(lambda x: '***-' + x[-4:])
masked['credit_card'] = masked['credit_card'].apply(lambda x: '****-****-****-' + x[-4:])
# Nulling: Remove internal notes entirely
masked['internal_notes'] = None
return masked
# Step 3: Mask order data with referential integrity
def mask_order_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Use same customer ID mapping to maintain relationships
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Randomization: Generate new order IDs
masked['order_id'] = [f"ORD-{uuid.uuid4().hex[:8].upper()}" for _ in range(len(masked))]
# Shuffling: Preserve amount distribution but break individual associations
shuffled_amounts = masked['amount'].values.copy()
np.random.shuffle(shuffled_amounts)
masked['amount'] = shuffled_amounts
return masked
# Apply masking
customers_masked = mask_customer_database(customers_original, customer_id_mapping)
orders_masked = mask_order_database(orders_original, customer_id_mapping)
print("=== MASKED CUSTOMER DATA ===")
print(customers_masked)
print("\n=== MASKED ORDER DATA ===")
print(orders_masked)
# Verify referential integrity is maintained
print("\n=== VERIFICATION: JOIN STILL WORKS ===")
joined = customers_masked.merge(orders_masked, on='customer_id')
print(f"Original orders: {len(orders_original)}, Joined orders: {len(joined)}")
print("✓ All order-customer relationships preserved!")Cuando ejecuté este proceso completo de enmascaramiento en los datos de nuestro proyecto (500 registros de clientes con 1200 pedidos), tardó unos 2 segundos en completarse, lo cual era perfectamente aceptable para nuestro ciclo semanal de actualización de la base de datos de desarrollo. Varias cosas encajaron:
La integridad referencial funcionó perfectamente. El cliente CUST_000000 (originalmente C001) tenía pedidos tanto en la tabla de clientes como en la de pedidos. Las consultas de la tabla « JOIN » que alimentan nuestra función de historial de pedidos funcionaban de forma idéntica con los datos enmascarados, ya que utilizábamos el mismo « customer_id_mapping » para ambas tablas.
Cada técnica tenía un propósito específico. La sustitución hizo que los nombres de los clientes parecieran realistas. El enmascaramiento parcial nos permite verificar los métodos de pago sin revelar los números completos de las tarjetas. El barajado preservó la capacidad de nuestros paneles de análisis para mostrar distribuciones precisas de ingresos, al tiempo que desconectaba los importes de clientes específicos. La anulación eliminó los datos que no necesitábamos para las pruebas.
El resultado tenía el aspecto y el comportamiento de datos reales. Cuando exploré la base de datos enmascarada durante el desarrollo, todo me pareció auténtico. Direcciones de correo electrónico validadas correctamente. Los números de teléfono se muestran correctamente. Los datos no gritaban «esto es falso», lo que me permitió centrarme en depurar la lógica de la aplicación en lugar de distraerme con datos de prueba obviamente artificiales.
La calidad de los datos se mantuvo alta. Aún podríamos probar casos extremos, como clientes con múltiples pedidos, calcular estadísticas agregadas y verificar las restricciones de la base de datos. El enmascaramiento preservó la complejidad y las relaciones que necesitábamos, al tiempo que protegía cada dato confidencial.
Este enfoque transformó lo que inicialmente parecía un problema abrumador, creando una base de datos de pruebas segura pero realista, en un proceso sistemático y reproducible. Cada vez que actualizábamos nuestra base de datos de desarrollo, ejecutar este script de enmascaramiento llevaba menos de un minuto y nos daba la total seguridad de que no se filtraría ningún dato real de los clientes.
Comienza con un descubrimiento exhaustivo de datos. La información confidencial apareció en lugares inesperados, más allá de campos obvios como nombres y correos electrónicos. Nuestra base de datos tenía campos de notas de clientes que contenían entradas de texto libre que podían incluir información personal. Aprendí a revisar sistemáticamente todos los campos, no solo los que eran obviamente delicados. En los sistemas de producción, las organizaciones utilizan herramientas automatizadas de detección de datos que buscan patrones que coincidan con información de identificación personal.
Establece políticas claras sobre el uso de mascarillas desde el principio. Al principio, los distintos miembros del equipo tomaban decisiones independientes sobre el enmascaramiento, lo que generaba inconsistencias. Una persona ocultó los números de teléfono por completo, otra utilizó el ocultamiento parcial y una tercera los dejó tal cual. Finalmente, estandarizamos nuestro enfoque: enmascaramiento completo para nombres y correos electrónicos, enmascaramiento parcial para números de teléfono y tarjetas, y anulación para notas internas. Las políticas documentadas especifican qué elementos de datos requieren enmascaramiento, qué técnicas se aplican a los diferentes tipos y cómo manejar los casos extremos.
Utiliza algoritmos que conserven el formato. En lugar de sustituir los datos por valores aleatorios, estos algoritmos generan sustituciones realistas que cumplen las mismas reglas de validación que los datos originales. Como demostré anteriormente, el enmascaramiento de mi tarjeta de crédito necesitaba generar números que superaran la validación de Luhn, y el enmascaramiento del correo electrónico necesitaba direcciones con el formato adecuado y patrones de dominio válidos.
Comprueba rigurosamente la calidad del enmascaramiento. Escribí pruebas sencillas para verificar la calidad de los datos enmascarados antes de utilizarlos para el desarrollo. Estas pruebas verificaron si las direcciones de correo electrónico enmascaradas pasan la validación regex, si los ID de los clientes siguen siendo únicos después del enmascaramiento, si las relaciones de claves externas siguen siendo válidas y si el conjunto de datos enmascarado tiene el mismo tamaño que el original. Estas pruebas detectaron problemas como la generación de duplicados y las infracciones de integridad referencial antes de que los encontráramos durante las pruebas de la aplicación.
Automatiza todo el proceso. Mi primer intento de enmascaramiento consistió en ejecutar manualmente scripts de Python y copiar archivos, lo que rápidamente se volvió tedioso. Finalmente, creé un único script que se encargaba de todo el proceso: leer los datos originales, aplicar todas las transformaciones de enmascaramiento, validar los resultados y escribir la salida enmascarada. En proyectos reales con procesos de integración continua, el enmascaramiento se integraría como un paso automatizado en el que los programadores ni siquiera tendrían que pensar.
Garantizar la irreversibilidad y la repetibilidad. El proceso de enmascaramiento debe ser irreversible para proporcionar una protección auténtica, pero repetible cuando sea necesario actualizar las bases de datos de prueba con resultados coherentes. El uso de técnicas deterministas con semillas consistentes, como mostré en el ejemplo completo, proporciona este equilibrio.
El enmascaramiento de datos está evolucionando rápidamente gracias a la inteligencia artificial y machine learning. Aunque en nuestro proyecto de clase utilizamos técnicas de enmascaramiento tradicionales, las soluciones modernas aprovechan cada vez más la inteligencia artificial para automatizar y mejorar el proceso de enmascaramiento.
La posibilidad que más me entusiasma es el descubrimiento automatizado de datos. Pasé horas revisando manualmente el esquema de nuestra base de datos para identificar qué campos contenían información confidencial. Imagina una herramienta que identifica automáticamente los campos confidenciales mediante el análisis de patrones, nombres de columnas y distribuciones de valores, en lugar de requerir una revisión manual. Un sistema de aprendizaje automático podría reconocer que una columna con el extraño nombre «user_identifier» contiene en realidad direcciones de correo electrónico, algo que yo podría pasar por alto fácilmente durante una inspección manual. Esto me habría ahorrado mucho tiempo.
También he estado leyendosobre técnicas de machine learning que preservan la privacidad yque van más allá del enmascaramiento tradicional. La privacidad diferencial, por ejemplo, añade ruido matemático cuidadosamente calibrado a los datos de entrenamiento o a los resultados de los modelos. El aprendizaje federado entrena modelos a través de conjuntos de datos distribuidos sin centralizar información confidencial. Estos enfoques abordan situaciones en las que el enmascaramiento estándar podría eliminar patrones que los modelos necesitan aprender.
La generación de datos sintéticos mediante IA generativa me interesa especialmente para futuros proyectos. En lugar de ocultar registros reales, los sistemas de IA entrenados con patrones de datos reales generan conjuntos de datos totalmente artificiales. Todavía no he probado a implementarlo yo mismo, pero entiendo su atractivo para situaciones que requieren conjuntos de datos de entrenamiento masivos o en las que incluso los datos reales enmascarados pueden suponer un riesgo. El reto sería garantizar que los datos sintéticos representaran con precisión los casos extremos y la complejidad que hacían que los datos reales enmascarados fueran tan valiosos para nuestras pruebas.
Teniendo en cuenta la dirección que está tomando el sector, los flujos de trabajo de desarrollo nativos en la nube están empezando a incorporar el enmascaramiento automatizado como infraestructura estándar. En lugar de que el enmascaramiento sea algo que ejecuto manualmente con scripts de Python, los procesos de implementación podrían gestionarlo automáticamente al aprovisionar las bases de datos de desarrollo. Los programadores especificarían los requisitos de enmascaramiento en los archivos de configuración junto con los esquemas de la base de datos. Ese es el tipo de automatización que me encantaría implementar en futuros proyectos, convirtiendo el enmascaramiento de un paso de preprocesamiento manual en un comportamiento automático de la infraestructura.
Sin embargo, la IA es un arma de doble filo para la privacidad de los datos. Si bien mejora las técnicas de enmascaramiento, también hace que los ataques de reidentificación sean más sofisticados. Los modelos de machine learning pueden cruzar datos aparentemente anonimizados con información pública para volver a identificar a las personas. Los investigadores volvieron a identificar a personas en datos «anonimizados» de Netflix correlacionándolos con reseñas de IMDb. A medida que las herramientas de enmascaramiento se vuelven más inteligentes, también lo hacen los métodos para burlarlas.
El enmascaramiento de datos logra el equilibrio perfecto entre la utilidad de los datos y la privacidad. Mediante la aplicación de las técnicas adecuadas, como la sustitución, el enmascaramiento determinista y los métodos de conservación del formato, puedes mantener datos realistas al tiempo que proteges la información confidencial.
Comienza por identificar tus conjuntos de datos más críticos y aplica el enmascaramiento en entornos que no sean de producción. Automatiza desde el principio para que la protección de la privacidad sea una parte estándar de tu flujo de trabajo.
Para profundizar tus conocimientos, explora nuestros cursos Privacidad y anonimización de datos en Python o Ingeniería de datos para todos.
Aprende con DataCamp
Curso
Curso
Curso
blog
Sejal Jaiswal
12 min
blog
Mike Shakhomirov
11 min
blog
Tim Lu
12 min
blog
Javier Canales Luna
12 min
blog
Javier Canales Luna
14 min
Tutorial
Joleen Bothma
