
Course
Understanding Data Engineering
2 hr
355.8K
Last semester, my database systems course assigned a final project that seemed straightforward at first: build a working e-commerce application with user authentication, shopping carts, and order processing. The catch? We had to demonstrate it worked with realistic data patterns, not just three test users named "Ali," "Shahd," and "Khalid."
My team faced an immediate problem. We needed hundreds of customer records with varied purchase histories to test edge cases like bulk orders, refunds, and inventory management. We couldn't scrape real data from existing sites; that's both unethical and illegal. Creating hundreds of realistic records manually would take forever. That's when our professor introduced us to data masking.
In this article, I'll share what I learned from my own experiences implementing data masking techniques. You'll discover what data masking is, when and why it matters, and how to apply specific techniques to protect sensitive information while maintaining data usefulness. I'll walk through practical examples from my project and show you how to avoid the mistakes I encountered along the way.
When I first heard the term "data masking," I pictured something like redacting text in government documents, just blacking out sensitive parts. The reality is more sophisticated and useful. Data masking creates structurally similar but factually false versions of sensitive data.
The technical process involves replacing original data values with fictitious alternatives that preserve format, type, and statistical properties. For our e-commerce project, we took a small dataset of real-looking customer information from a data generation tool and applied masking techniques to create variations. An email like khalid.abdelaty@company.com became ahmed.j@enterprise.com. Both are valid email formats that pass validation checks, but the masked version reveals nothing about actual people.
You'll encounter this concept under different names depending on who's talking about it. Data obfuscation emphasizes the concealment aspect. Pseudonymization refers specifically to replacing identifiable information while maintaining the ability to re-identify data if needed. Tokenization involves replacing sensitive values with randomly generated tokens. These terms overlap significantly, and from what I've seen in documentation and tutorials, people often use them somewhat interchangeably.
At this point, you might be wondering whether those new emails or IDs are derived from the original data in some way. The short answer: it depends on the masking technique. I left more info about this in the FAQs.
The importance clicked when our professor pointed out that our "class project" mirrored real production challenges. Companies need to test software with production-like data, and analysts need to build models with realistic patterns. But using actual customer data in these environments creates serious problems.
Regulatory compliance sits at the top of most organizations' concerns. GDPR, the European privacy regulation, mandates that organizations minimize data processing and protect personal information through appropriate technical measures. HIPAA requires healthcare providers to safeguard patient information even in testing environments. The California Consumer Privacy Act extends similar protections to California residents. From a business perspective, violating these regulations means massive fines. From an ethical perspective, people expect that their data is protected.
Data masking also provides critical security benefits. Every additional environment holding real data increases the attack surface. Development servers typically have weaker security controls than production systems, and developers often work with data on local machines that might not be encrypted. Each scenario introduces breach risks that data masking eliminates by ensuring non-production environments never contain real information.
What surprised me most was discovering the practical development benefits. Our QA testing uncovered bugs we'd never have found with our original three-user test dataset. One team member's code broke when processing names with apostrophes like "O'Brien." Another's broke on email addresses using plus-sign aliases like "user+tag@domain.com." These edge cases only appeared because our masked dataset, derived from realistic patterns, contained the complexity real production data would have.
Understanding when masking applies helped me recognize it across different contexts. The most obvious scenario mirrors our class project: software development and testing. When building new features or debugging existing code, developers need data representing real-world complexity. I spent hours debugging why our shopping cart calculation broke on certain product combinations. The bug only appeared because our masked dataset included edge cases like zero-dollar items and quantity limits.
Data analytics and research projects often require large datasets with realistic statistical properties. A teammate working on a separate analytics project needed customer purchase patterns to build recommendation algorithms. She didn't need actual customer names or addresses, just the behavioral patterns. Masked data provided those patterns while protecting privacy.
External collaboration presents another common use case. Companies often hire consultants or contractors for integration projects who need realistic data but shouldn't access sensitive customer information. Employee training represents yet another practical application. Before anyone touches production systems, they need practice environments with realistic but safe data. As a last example, Cloud development also benefits from masking, though major cloud providers offer their own masking tools as part of their security services.
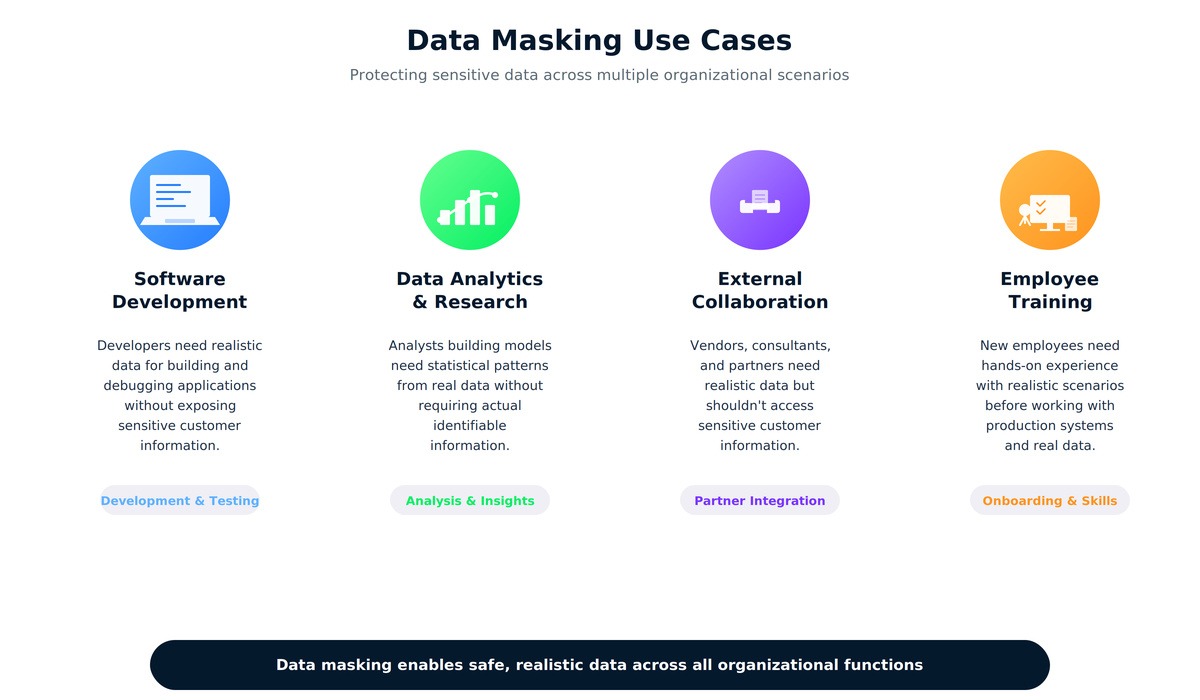
Data masking serves multiple organizational needs from development to compliance
Before diving into specific techniques, it's worth understanding the main types of masking and when to use each one.
Static masking operates on stored datasets, creating masked copies that exist independently from the original data. This is what we used for our e-commerce project. I ran a Python script that read our initial dataset, applied masking transformations, and wrote results to a new file that we all used for development. Once created, that masked dataset remained stable until we needed to refresh it with new patterns. The advantage became obvious quickly: the performance impact happened once during the masking process, making it ideal for non-production environments where you mask once and use the copy repeatedly.
Dynamic masking happens in real time as users access data, applying transformations based on permissions. I first encountered this concept while reading about database security features. A system administrator sees complete customer records while a support representative sees masked credit card numbers. The underlying data remains unchanged, but what each user sees depends on their authorization level. This approach suits production systems where different users need different views based on roles.
Deterministic masking ensures consistency by always replacing the same input with the same output. If customer "Sarah Ali" becomes "Eman Mohamed" in one table, that transformation applies everywhere Sarah Ali appears. As I'll explain in the techniques section, this consistency matters critically for maintaining relationships across database tables. Our project required deterministic masking to keep customer IDs consistent across the customers table, orders table, and reviews table.
On-the-fly masking applies transformations during data transfer between environments. I experimented with this approach when setting up a deployment pipeline for a personal project. The masking happened during data extraction rather than as a separate step, which simplified the workflow and made it particularly ideal for CI/CD pipelines.
Researchers need access to data patterns to uncover trends, test hypotheses, and build reliable models, but sharing real-world data often risks exposing sensitive info. Statistical obfuscation (another form of data masking) offers a solution. When done right, it preserves essential statistical properties - think means, variances, and correlations while at the same time keeping secret individual records. This allows analysts to draw valid insights from the data without compromising privacy.
This is where theory met practice in our project. Each of the techniques I'll walk through in this next section solved a particular challenge we faced.
Substitution became my default approach for most personally identifiable information. The concept is straightforward: replace sensitive values with realistic but completely fictitious alternatives. Names become different names. Email addresses become different email addresses. The replacement values maintain the same format and appear genuine to anyone looking at the data.
For our e-commerce project, I needed to mask customer information quickly. I discovered the Faker library, which can be installed with pip install Faker, and built a simple masking function. Faker generates a wide variety of realistic fake data, making it perfect for masking operations:
from faker import Faker
import pandas as pd
fake = Faker()
def mask_customer_data(customer_df):
masked_df = customer_df.copy()
masked_df['first_name'] = [fake.first_name() for _ in range(len(masked_df))]
masked_df['last_name'] = [fake.last_name() for _ in range(len(masked_df))]
masked_df['email'] = [fake.email() for _ in range(len(masked_df))]
return masked_df
# Example usage
original_customers = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com']
})
masked_customers = mask_customer_data(original_customers)The above code takes a pandas DataFrame of customer records and replaces identifying information with fictional alternatives. Running this on our initial dataset took maybe two minutes and gave us hundreds of realistic-looking customer names and email addresses. The Faker library handled the complexity of generating diverse, believable names and properly formatted email addresses. I also learned that, because the outputs were randomly generated, they were not directly reidentifiable, which I appreciated.
One thing I learned: The masked data needs to look authentic enough that your brain doesn't reject it during development. Early on, I tried using random letter combinations, but debugging code with customers named "Xkqp Mmwz" felt ridiculous and made it harder to focus on actual logic problems. Faker-generated names like "Jennifer Martinez" and "Robert Chen" felt natural enough to work with seriously.
For learning more about data manipulation in Python, our Introduction to Data Science in Python course covers fundamental DataFrame operations that make implementing these and other techniques much easier.
Shuffling solved a problem I didn't anticipate initially. Our project included an admin dashboard showing average purchase amounts by customer demographic. We needed realistic purchase amounts to test whether our aggregation queries worked correctly, but we didn't need specific customers connected to specific purchases.
Shuffling reorders values within a column randomly while preserving the overall distribution:
import numpy as np
import pandas as pd
def shuffle_column(df, column_name):
shuffled_df = df.copy()
shuffled_values = shuffled_df[column_name].values
np.random.seed(42) # For reproducibility
np.random.shuffle(shuffled_values)
shuffled_df[column_name] = shuffled_values
return shuffled_df
# Example with purchase data
purchase_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'product': ['Laptop', 'Headphones', 'Mouse'],
'amount': [1200, 85, 25]
})
shuffled_purchases = shuffle_column(purchase_data, 'amount')After shuffling, the purchase amounts still existed in the dataset (we could still calculate accurate averages and distributions), but the connection between customer C001 and the $1,200 purchase was broken. Customer C001 might now show a $25 purchase instead.
The key insight: Shuffling maintains statistical properties needed for aggregate analysis while breaking individual-level associations. It's perfect when you're testing features that work with aggregates rather than individual records.
Partial masking reveals only the necessary information while hiding the rest. This technique appeared familiar because I'd seen it everywhere, websites showing credit card numbers as ****-****-****-1234 or apps displaying phone numbers as (***) ***-5678.
Implementing this for our project was straightforward:
def mask_credit_card(card_number):
visible_digits = 4
masked_portion = '*' * (len(card_number) - visible_digits)
return masked_portion + card_number[-visible_digits:]
def mask_phone(phone):
return '***-***-' + phone[-4:]
# Examples
print(mask_credit_card('4532123456781234')) # ************1234
print(mask_phone('555-0123')) # ***-***-0123We used this for the order history view, where customers needed to verify which card they used for a purchase. Showing the last four digits provided enough information for recognition without exposing the complete number. It felt like the right balance between utility and privacy.
Sometimes the simplest solution is just removing data entirely. Nulling replaces field values with NULL or empty strings when the information isn't necessary for testing.
def null_fields(df, fields_to_null):
masked_df = df.copy()
for field in fields_to_null:
masked_df[field] = None
return masked_dfOur customer records included a "notes" field where hypothetical customer service reps might write internal comments. This field wasn't relevant for testing shopping cart logic or payment processing, so I just nulled it out. Why bother creating fake notes when we could simply remove the field from our test data?
This taught me an important lesson about masking: don't overcomplicate things. Mask what needs masking, remove what doesn't need to exist at all.
Randomization generates completely new values for fields where maintaining any connection to original data serves no purpose. This worked well for identifiers and reference numbers:
import random
import string
def randomize_order_id():
return 'ORD-' + ''.join(random.choices(string.ascii_uppercase + string.digits, k=8))
order_ids = [randomize_order_id() for _ in range(5)]
print(order_ids)Our order IDs didn't need to match anything from the original dataset. They just needed to look realistic and be unique. Random generation handled both requirements. Each generated ID like "ORD-K7M2N9P4" looked like a plausible order reference without connecting to anything real.
Tokenization replaces sensitive values with randomly generated tokens while securely storing the original data in a separate, highly protected system. Unlike other masking techniques, tokenization is designed for reversibility, but only through controlled access. I learned about this approach while researching payment processing requirements:
import uuid
# Note: Production token vaults use encrypted database storage, not in-memory dicts
class TokenVault:
def __init__(self):
self.token_map = {}
self.reverse_map = {}
def tokenize(self, sensitive_value):
if sensitive_value in self.token_map:
return self.token_map[sensitive_value]
token = str(uuid.uuid4())
self.token_map[sensitive_value] = token
self.reverse_map[token] = sensitive_value
return token
def detokenize(self, token):
return self.reverse_map.get(token)
vault = TokenVault()
token = vault.tokenize('4532-1234-5678-9012')
print(f"Token: {token}")
original = vault.detokenize(token)
print(f"Original: {original}")We didn't implement tokenization in our class project because we had no need for reversibility. But reading about payment systems made the use case clear: Your application database stores only the tokens (useless random strings), while the actual payment details live in a completely separate, heavily secured token vault. If your application database gets compromised, the attacker only gets useless tokens with no way to access the real credit card numbers without breaching the vault itself. This architectural separation is what makes tokenization especially valuable for payment processing compliance.
Cryptographic techniques transform data using mathematical algorithms. I implemented hashing for our password storage after our professor emphasized never storing plain-text passwords. For production systems, you should use bcrypt or Argon2, which incorporate salts and are designed to be computationally expensive to resist brute-force attacks. I'm showing bcrypt here, though Argon2 is also excellent for production:
import bcrypt
def hash_password(password):
# Generate a salt and hash the password
salt = bcrypt.gensalt()
hashed = bcrypt.hashpw(password.encode(), salt)
return hashed
def verify_password(password, hashed):
# Verify a password against its hash
return bcrypt.checkpw(password.encode(), hashed)
# Store the hash, never the actual password
password = 'user_password_123'
password_hash = hash_password(password)
print(f"Stored hash: {password_hash}")
# Output: Stored hash: b'$2b$12$K7g.../XYZ' (different each time due to random salt)
# Verify during login
is_valid = verify_password('user_password_123', password_hash)
print(f"Password valid: {is_valid}") # Output: Password valid: TrueHashing creates one-way transformations useful for verification. When I first tested this, I was amazed that bcrypt generates a different hash each time due to the random salt, yet verify_password() still correctly matches the original password. The salt ensures that even identical passwords produce different hashes, protecting against rainbow table attacks. During login, we hash the submitted password and use bcrypt's verification function to compare it securely. This means even developers with database access can't see user passwords.
Note: You'll need to install bcrypt with pip install bcrypt to use this example.
Encryption differs from hashing by allowing decryption back to the original form using keys. We didn't need encryption for our project, but I understand its purpose: Use it when authorized parties need access to real data, but you want to protect it from unauthorized access.
These related techniques differ in their reversibility. Pseudonymization replaces identifiable information while maintaining the ability to re-identify individuals when necessary. Anonymization removes identifiable information entirely, making re-identification impossible.
def pseudonymize_data(df, id_column, key_mapping=None):
if key_mapping is None:
key_mapping = {}
pseudo_df = df.copy()
for idx, original_id in enumerate(pseudo_df[id_column].unique()):
if original_id not in key_mapping:
key_mapping[original_id] = f"PSEUDO_{idx:06d}"
pseudo_df.loc[pseudo_df[id_column] == original_id, id_column] = key_mapping[original_id]
return pseudo_df, key_mapping
# Using pseudonymization
customer_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C001'],
'purchase': ['Laptop', 'Mouse', 'Keyboard']
})
pseudonymized_data, mapping = pseudonymize_data(customer_data, 'customer_id')Our project used pseudonymization to maintain customer consistency across multiple purchases while hiding actual customer identifiers. Customer C001's three purchases all mapped to the same pseudonym, preserving the ability to analyze individual customer behavior without exposing real identities.
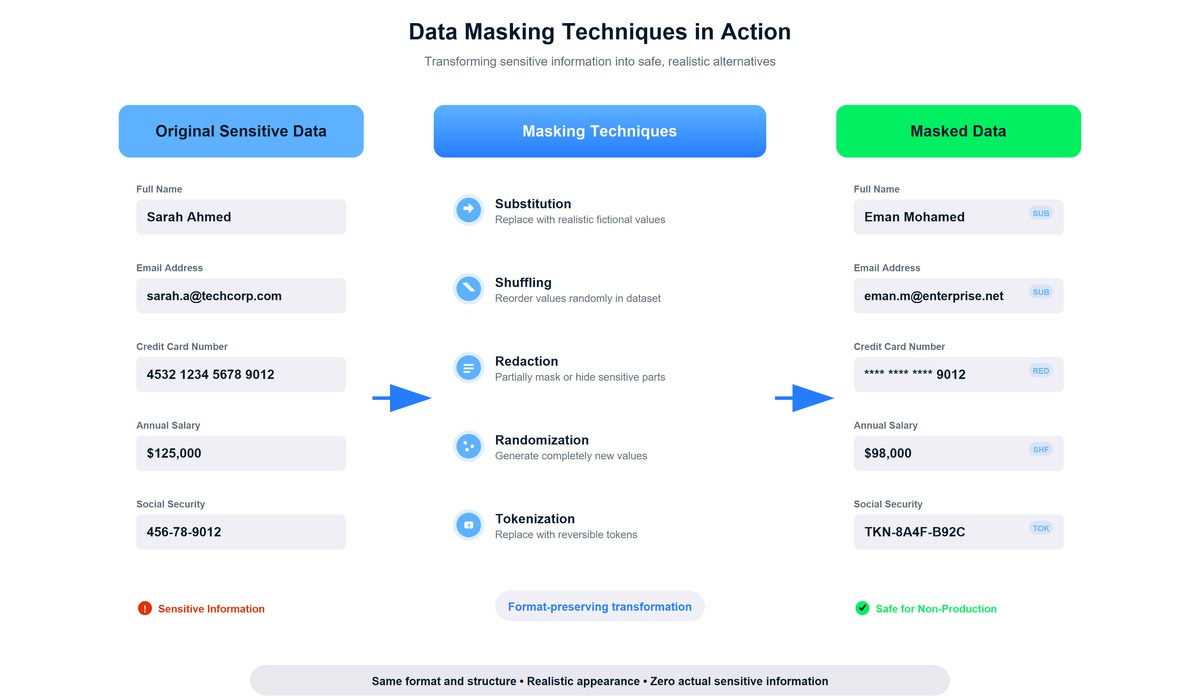
Multiple masking techniques transform sensitive data while maintaining format and usability
Initially, I confused data masking with encryption and anonymization because they all involve protecting sensitive information. Understanding the distinctions helped me choose appropriate techniques for different scenarios. Let me break down the key differences in a way that clarifies when to use each approach.
|
Approach |
How It Works |
Reversibility |
Best Use Case |
|
Data Masking |
Replaces sensitive data with fictitious but realistic values |
Irreversible (no recovery without source database) |
Development, testing, and analytics environments where realistic data structure is needed but actual values aren't |
|
Encryption |
Scrambles data using mathematical algorithms |
Reversible with decryption keys |
Protecting data in transit or storage when authorized users need to access original values |
|
Anonymization |
Removes or generalizes identifying information |
Irreversible (designed to prevent re-identification) |
Publishing datasets for research or public use while protecting individual privacy |
|
Synthetic Data |
Generates entirely artificial datasets using statistical models or ML |
N/A (no original data to reverse to) |
Training machine learning models or scenarios where even masked real data feels too risky |
I encountered the encryption versus masking distinction clearly during our database security unit. We encrypted database backups so they'd be useless if stolen, but we masked the development database because developers needed to work with the data, just not real customer data. As I mentioned earlier, encryption protects data you'll eventually decrypt, while masking creates permanently safe alternatives.
The difference between masking and anonymization emphasizes different goals. Anonymization focuses specifically on removing identifiable information to prevent re-identification of individuals through techniques like generalization (replacing exact ages with age ranges) and suppression (removing identifying attributes entirely). Masking emphasizes maintaining data utility for development, testing, and analytics.
A classmate working on a machine learning project used synthetic data generated from patterns in a real dataset. The synthetic data contained no actual records but mimicked statistical properties needed for model training. I chose masking over synthetic data for our project because we needed to test specific scenarios like handling duplicate email addresses or processing international addresses. Synthetic data might not capture these edge cases, while masked real data preserved them.
Implementing masking taught me that protecting sensitive information while maintaining data utility involves navigating challenges that aren't obvious until you encounter them. Let me walk you through the major obstacles I faced and how I solved them.
Attribute preservation proved trickier than expected. Simply replacing values randomly breaks patterns applications depend on. Credit card numbers follow the Luhn algorithm for checksum validation, email addresses require properly formatted domains, and ZIP codes correspond to geographic regions. I learned this the hard way when my first masking attempt generated random 16-digit numbers for credit card fields. Everything looked fine until testing revealed our payment validation logic rejected every single card number because I'd forgotten that credit card numbers include check digits calculated using the Luhn algorithm.
Semantic integrity matters beyond just format. Masked data should avoid obviously nonsensical combinations. During testing, one teammate noticed our masked dataset had Alaska ZIP codes assigned to Florida street addresses. While technically valid formats, the geographical mismatch looked suspicious. I spent an afternoon improving semantic consistency by generating complete addresses where all components matched geographically rather than randomly pairing address components.
Referential integrity across tables created significant complexity. As I explained in the techniques section, our database had customers, orders, and reviews tables with customer IDs appearing in all three. If masking transformed customer IDs inconsistently, these relationships broke completely. This happened to me after my first masking attempt, 30% of our integration tests failed because customer orders didn't link to customer records anymore. The breakthrough came when I realized I needed to process tables in dependency order using deterministic masking to ensure customer C001 always became the same masked ID everywhere it appeared.
Balancing security with analytical value requires constant judgment. More aggressive masking provides better privacy but reduces utility. For instance, rounding all ages to the nearest decade improves privacy but eliminates useful age-based analysis. Our project favored utility since we were building application features requiring realistic data behavior. In a real production scenario with actual customer data and compliance obligations, I'd need to weigh privacy protection more heavily and potentially accept reduced data utility.
Statistical relationships can become distorted. If you have two correlated columns, such as income and spending, and you scramble each one independently, the correlation will probably shift. From a statistical perspective, independent scrambling alters the joint distribution of the variables. To preserve this relationship, analysts sometimes use rank-preserving transformations such as shuffling both columns using the same random permutation or adding controlled noise that maintains their joint ordering.
After learning these individual techniques, I wanted to see how they work together in a realistic scenario. Here's a complete example that demonstrates masking a customer database with related orders, the exact challenge we faced in our e-commerce project.
from faker import Faker
import pandas as pd
import numpy as np
import uuid
fake = Faker()
Faker.seed(42) # For reproducible results
# Original datasets (simulating real customer data)
customers_original = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com'],
'phone': ['555-0123', '555-0124', '555-0125'],
'credit_card': ['4532-1234-5678-9012', '4556-7890-1234-5678', '4539-8765-4321-0987'],
'internal_notes': ['VIP customer', 'Requested callback', 'Payment issue resolved']
})
orders_original = pd.DataFrame({
'order_id': ['ORD001', 'ORD002', 'ORD003', 'ORD004'],
'customer_id': ['C001', 'C002', 'C001', 'C003'],
'product': ['Laptop', 'Mouse', 'Keyboard', 'Monitor'],
'amount': [1299.99, 29.99, 89.99, 399.99]
})
# Step 1: Create deterministic ID mapping to maintain referential integrity
def create_id_mapping(ids):
"""Create consistent pseudonymous IDs"""
mapping = {}
for idx, original_id in enumerate(ids):
mapping[original_id] = f"CUST_{idx:06d}"
return mapping
customer_id_mapping = create_id_mapping(customers_original['customer_id'].unique())
# Step 2: Mask customer data using multiple techniques
def mask_customer_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Replace customer IDs consistently
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Substitution: Replace names and emails with realistic fake data
masked['first_name'] = [fake.first_name() for _ in range(len(masked))]
masked['last_name'] = [fake.last_name() for _ in range(len(masked))]
masked['email'] = [fake.email() for _ in range(len(masked))]
# Partial masking/redaction: Show last 4 digits of phone and credit card
masked['phone'] = masked['phone'].apply(lambda x: '***-' + x[-4:])
masked['credit_card'] = masked['credit_card'].apply(lambda x: '****-****-****-' + x[-4:])
# Nulling: Remove internal notes entirely
masked['internal_notes'] = None
return masked
# Step 3: Mask order data with referential integrity
def mask_order_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Use same customer ID mapping to maintain relationships
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Randomization: Generate new order IDs
masked['order_id'] = [f"ORD-{uuid.uuid4().hex[:8].upper()}" for _ in range(len(masked))]
# Shuffling: Preserve amount distribution but break individual associations
shuffled_amounts = masked['amount'].values.copy()
np.random.shuffle(shuffled_amounts)
masked['amount'] = shuffled_amounts
return masked
# Apply masking
customers_masked = mask_customer_database(customers_original, customer_id_mapping)
orders_masked = mask_order_database(orders_original, customer_id_mapping)
print("=== MASKED CUSTOMER DATA ===")
print(customers_masked)
print("\n=== MASKED ORDER DATA ===")
print(orders_masked)
# Verify referential integrity is maintained
print("\n=== VERIFICATION: JOIN STILL WORKS ===")
joined = customers_masked.merge(orders_masked, on='customer_id')
print(f"Original orders: {len(orders_original)}, Joined orders: {len(joined)}")
print("✓ All order-customer relationships preserved!")When I ran this complete masking pipeline on our project data (500 customer records with 1,200 orders), it took about 2 seconds to execute, which was perfectly acceptable for our weekly development database refresh cycle. Several things clicked into place:
Referential integrity worked perfectly. Customer CUST_000000 (originally C001) had orders in both the customers and orders tables. The JOIN queries that power our order history feature worked identically with masked data because we used the same customer_id_mapping for both tables.
Each technique served a specific purpose. Substitution made customer names look realistic. Partial masking lets us verify payment methods without exposing full card numbers. Shuffling preserved our analytics dashboards' ability to show accurate revenue distributions while disconnecting amounts from specific customers. Nulling eliminated data we didn't need for testing.
The output looked and behaved like real data. When I browsed the masked database during development, everything felt authentic. Email addresses validated correctly. Phone numbers displayed properly. The data didn't scream "this is fake," which kept me focused on debugging application logic rather than being distracted by obviously artificial test data.
Data quality remained high. We could still test edge cases like customers with multiple orders, calculate aggregate statistics, and verify database constraints. The masking preserved the complexity and relationships we needed while protecting every single piece of sensitive information.
This approach transformed what initially seemed like an overwhelming problem, creating a safe but realistic test database, into a systematic, reproducible process. Each time we refreshed our development database, running this masking script took under a minute and gave us complete confidence that no real customer data could possibly leak.
Start with comprehensive data discovery. Sensitive information appeared in unexpected places beyond obvious fields like names and emails. Our database had customer notes fields containing free-text entries that might include personal information. I learned to systematically review every field, not just the obviously sensitive ones. In production systems, organizations use automated data discovery tools that scan for patterns matching personally identifiable information.
Establish clear masking policies early. Different team members made independent masking decisions initially, creating inconsistencies. One person masked phone numbers completely, another used partial masking, and a third left them untouched. We eventually standardized our approach: full masking for names and emails, partial masking for phone numbers and cards, and nulling for internal notes. Documented policies specify which data elements require masking, which techniques apply to different types, and how to handle edge cases.
Use format-preserving algorithms. Rather than replacing data with random values, these algorithms generate realistic replacements satisfying the same validation rules as the original data. As I demonstrated earlier, my credit card masking needed to generate numbers passing Luhn validation, and email masking needed properly formatted addresses with valid domain patterns.
Test masking quality rigorously. I wrote simple tests verifying masked data quality before we used it for development. These tests checked whether masked email addresses pass regex validation, customer IDs remain unique after masking, foreign key relationships remain valid, and the masked dataset has the same size as the original. These tests caught problems like duplicate generation and referential integrity breaks before we encountered them during application testing.
Automate the entire process. My first masking attempt involved manually running Python scripts and copying files around, which became tedious quickly. I eventually created a single script handling the entire process: read original data, apply all masking transformations, validate results, and write masked output. For real projects with continuous integration pipelines, masking would integrate as an automated step where developers wouldn't even think about it.
Ensure irreversibility and repeatability. The masking process should be irreversible to provide genuine protection, but repeatable when you need to refresh test databases with consistent results. Using deterministic techniques with consistent seeds, as I showed in the complete example, provides this balance.
Data masking is evolving rapidly with artificial intelligence and machine learning. While our class project used traditional masking techniques, modern solutions are increasingly leveraging AI to automate and enhance the masking process.
The most exciting possibility to me is automated data discovery. I spent hours manually reviewing our database schema to identify which fields contained sensitive information. Imagine a tool that automatically identifies sensitive fields by analyzing patterns, column names, and value distributions rather than requiring manual review. An ML system might recognize that a column oddly named "user_identifier" actually contains email addresses, something I could easily overlook during manual inspection. This would have saved me significant time.
I've also been reading about privacy-preserving machine learning techniques that go beyond traditional masking. Differential privacy, for instance, adds carefully calibrated mathematical noise to training data or model outputs. Federated learning trains models across distributed datasets without centralizing sensitive information. These approaches address scenarios where standard masking might strip away patterns that models need to learn from.
Synthetic data generation leveraging generative AI particularly interests me for future projects. Instead of masking real records, AI systems trained on real data patterns generate entirely artificial datasets. I haven't tried implementing this myself yet, but I can see the appeal for scenarios requiring massive training datasets or where even masked real data feels risky. The challenge would be ensuring that synthetic data accurately represents the edge cases and complexity that made masked real data so valuable for our testing.
Looking at where the field is heading, cloud-native development workflows are starting to incorporate automated masking as standard infrastructure. Rather than masking being something I run manually with Python scripts, deployment pipelines could handle it automatically when provisioning development databases. Developers would specify masking requirements in configuration files alongside database schemas. That's the kind of automation I'd love to implement in future projects, turning masking from a manual preprocessing step into automatic infrastructure behavior.
However, AI presents a double-edged sword for data privacy. While it improves masking techniques, it also makes re-identification attacks more sophisticated. Machine learning models can cross-reference seemingly anonymized data with public information to re-identify individuals. Researchers famously re-identified people in "anonymized" Netflix data by correlating it with IMDb reviews. As masking tools get smarter, so do the methods for breaking them.
Data masking strikes the perfect balance between data utility and privacy. By applying the right techniques, like substitution, deterministic masking, and format-preserving methods, you can maintain realistic data while safeguarding sensitive information.
Start by identifying your most critical datasets and apply masking in non-production environments. Automate early to make privacy protection a standard part of your workflow.
To deepen your skills, explore our Data Privacy and Anonymization in Python or the Data Engineering for Everyone courses.
Learn with DataCamp
Course
Course
Course
blog
Andrea Valenzuela
12 min
blog
Kurtis Pykes
9 min
blog
Kevin Babitz
12 min
blog
Sanjana Putchala
10 min
blog
Sejal Jaiswal
12 min
blog
Kurtis Pykes
15 min
