Cours
Présentation de l’ingénierie des données
2 h
358.9K
Au semestre dernier, dans le cadre de mon cours sur les systèmes de bases de données, on nous a assigné un projet final qui semblait simple à première vue : créer une application de commerce électronique fonctionnelle avec authentification des utilisateurs, paniers d'achat et traitement des commandes. Le hic ? Nous devions démontrer que cela fonctionnait avec des modèles de données réalistes, et pas seulement avec trois utilisateurs test nommés « Ali », « Shahd » et « Khalid ».
Mon équipe a été confrontée à un problème immédiat. Nous avions besoin de plusieurs centaines de dossiers clients présentant des historiques d'achat variés afin de tester des cas particuliers tels que les commandes en gros, les remboursements et la gestion des stocks. Nous ne pouvions pas extraire de données réelles à partir de sites existants ; cela serait à la fois contraire à l'éthique et illégal. Créer manuellement des centaines d'enregistrements réalistes prendrait une éternité. C'est à ce moment-là que notre professeur nous a présenté le masquage des données.
Dans cet article, je vais partager ce que j'ai appris de mes propres expériences dans la mise en œuvre de techniques de masquage des données. Vous découvrirez ce qu'est le masquage des données, quand et pourquoi il est important, et comment appliquer des techniques spécifiques pour protéger les informations sensibles tout en conservant l'utilité des données. Je vais vous présenter des exemples concrets tirés de mon projet et vous montrer comment éviter les erreurs que j'ai rencontrées en cours de route.
Lorsque j'ai entendu pour la première fois le terme « masquage des données », j'ai imaginé quelque chose comme la censure de textes dans les documents gouvernementaux, consistant simplement à noircir les parties sensibles. La réalité est plus complexe et plus utile. Le masquage des données consiste à créer des versions structurellement similaires, mais factuellement erronées, des données sensibles.
Le processus technique consiste à remplacer les valeurs des données originales par des valeurs fictives qui préservent le format, le type et les propriétés statistiques. Pour notre projet de commerce électronique, nous avons utilisé un petit ensemble de données contenant des informations clients réalistes provenant d'un outil de génération de données et avons appliqué des techniques de masquage afin de créer des variations. Une adresse électronique telle que khalid.abdelaty@company.com est devenue ahmed.j@enterprise.com. Les deux formats d'adresse e-mail sont valides et passent les contrôles de validation, mais la version masquée ne révèle aucune information sur les personnes réelles.
Vous rencontrerez ce concept sous différents noms selon la personne qui en parle. L'obfuscation des données met l'accent sur l'aspect dissimulation. La pseudonymisation désigne spécifiquement le remplacement d'informations identifiables tout en conservant la possibilité de réidentifier les données si nécessaire. La tokenisation consiste à remplacer les valeurs sensibles par des jetons générés de manière aléatoire. Ces termes se recoupent considérablement, et d'après ce que j'ai pu observer dans la documentation et les tutoriels, ils sont souvent utilisés de manière interchangeable.
À ce stade, vous vous demandez peut-être si ces nouveaux e-mails ou identifiants sont dérivés d'une manière ou d'une autre des données d'origine. En bref, cela dépend de la technique de masquage utilisée. J'ai fourni davantage d'informations à ce sujet dans la FAQ.
L'importance de cette démarche m'est apparue lorsque notre professeur a souligné que notre « projet de classe » reflétait les défis réels de la production. Les entreprises doivent tester les logiciels avec des données similaires à celles utilisées en production, et les analystes doivent élaborer des modèles avec des schémas réalistes. Cependant, l'utilisation de données clients réelles dans ces environnements pose de sérieux problèmes.
La conformité réglementaire est une priorité pour la plupart des organisations. Le RGPD, le règlement européen sur la protection des données, impose aux organisations de minimiser le traitement des données et de protéger les informations personnelles à l'aide de mesures techniques appropriées. La loi HIPAA exige des prestataires de soins de santé qu'ils protègent les informations des patients, même dans les environnements de test. La loi californienne sur la protection de la vie privée des consommateurs (California Consumer Privacy Act) accorde des protections similaires aux résidents de Californie. D'un point de vue commercial, le non-respect de ces réglementations entraîne des amendes importantes. D'un point de vue éthique, les personnes s'attendent à ce que leurs données soient protégées.
Le masquage des données offre également des avantages considérables en matière de sécurité. Chaque environnement supplémentaire contenant des données réelles augmente la surface d'attaque. Les serveurs de développement disposent généralement de contrôles de sécurité moins stricts que les systèmes de production, et les développeurs travaillent souvent avec des données sur des machines locales qui ne sont pas nécessairement cryptées. Chaque scénario présente des risques de violation que le masquage des données élimine en garantissant que les environnements hors production ne contiennent jamais d'informations réelles.
Ce qui m'a le plus surpris, c'est de découvrir les avantages pratiques en matière de développement. Nos tests d'assurance qualité ont permis de détecter des erreurs que nous n'aurions jamais pu identifier avec notre ensemble de données de test initial comprenant trois utilisateurs. Le code d'un membre de l'équipe a rencontré des difficultés lors du traitement de noms contenant des apostrophes, tels que « O'Brien ». Un autre problème concerne les adresses électroniques utilisant des alias avec le signe plus, comme « utilisateur+tag@domain.com." » ; Ces cas limites sont apparus uniquement parce que notre ensemble de données masquées, dérivé de modèles réalistes, présentait la complexité inhérente aux données de production réelles.
Comprendre quand le masquage s'applique m'a aidé à le reconnaître dans différents contextes. Le scénario le plus évident reflète notre projet de classe : le développement et le test de logiciels. Lorsqu'ils développent de nouvelles fonctionnalités ou déboguent du code existant, les développeurs ont besoin de données reflétant la complexité du monde réel. J'ai passé des heures à rechercher pourquoi le calcul de notre panier d'achat ne fonctionnait pas correctement pour certaines combinaisons de produits. Le bug est apparu uniquement parce que notre ensemble de données masquées comprenait des cas limites tels que des articles à zéro dollar et des limites de quantité.
Les projets d'analyse de données et de recherche nécessitent souvent de grands ensembles de données présentant des propriétés statistiques réalistes. Un collègue travaillant sur un autre projet d'analyse avait besoin des habitudes d'achat des clients pour élaborer des algorithmes de recommandation. Elle n'avait pas besoin des noms ou adresses réels des clients, mais seulement de connaître leurs habitudes comportementales. Les données masquées ont permis d'identifier ces tendances tout en protégeant la confidentialité.
La collaboration externe constitue un autre cas d'utilisation courant. Les entreprises engagent souvent des consultants ou des sous-traitants pour des projets d'intégration qui ont besoin de données réalistes, mais qui ne doivent pas avoir accès aux informations sensibles des clients. La formation des employés constitue une autre application pratique. Avant que quiconque n'intervienne sur les systèmes de production, il est nécessaire de disposer d'environnements de test avec des données réalistes mais sécurisées. Enfin, le développement cloud bénéficie également du masquage, bien que les principaux fournisseurs de services cloud proposent leurs propres outils de masquage dans le cadre de leurs services de sécurité.
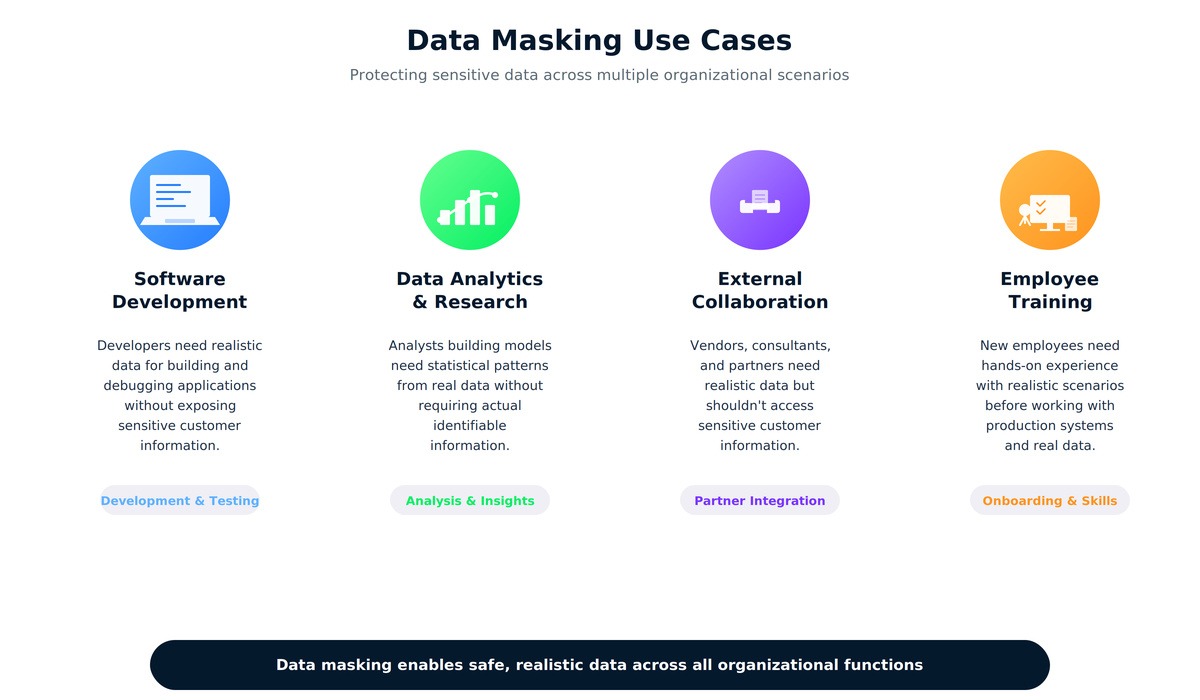
Le masquage des données répond à de multiples besoins organisationnels, du développement à la conformité.
Avant d'aborder les techniques spécifiques, il est important de comprendre les principaux types de masquage et quand les utiliser.
Le masquage statique s'applique aux ensembles de données stockés, créant des copies masquées qui existent indépendamment des données d'origine. C'est ce que nous avons utilisé pour notre projet de commerce électronique. J'ai exécuté un script Python qui a lu notre ensemble de données initial, appliqué des transformations de masquage et enregistré les résultats dans un nouveau fichier que nous avons tous utilisé pour le développement. Une fois créé, cet ensemble de données masquées est resté stable jusqu'à ce que nous ayons dû le mettre à jour avec de nouveaux modèles. L'avantage est rapidement devenu évident : l'impact sur les performances ne se produisait qu'une seule fois pendant le processus de masquage, ce qui le rendait idéal pour les environnements hors production où l'on effectue un masquage unique et utilise la copie à plusieurs reprises.
Le masquage dynamique s'effectue en temps réel lorsque les utilisateurs accèdent aux données, en appliquant des transformations basées sur les autorisations. J'ai découvert ce concept pour la première fois en lisant des articles sur les fonctionnalités de sécurité des bases de données. Un administrateur système a accès à l'intégralité des dossiers clients, tandis qu'un représentant du service d'assistance ne voit que les numéros de carte de crédit masqués. Les données sous-jacentes restent inchangées, mais ce que chaque utilisateur voit dépend de son niveau d'autorisation. Cette approche convient aux systèmes de production où différents utilisateurs ont besoin de vues différentes en fonction de leurs rôles.
Le masquage déterministe garantit la cohérence en remplaçant systématiquement la même entrée par la même sortie. Si la cliente « Sarah Ali » devient « Eman Mohamed » dans un tableau, cette modification s'applique partout où Sarah Ali apparaît. Comme je l'expliquerai dans la section consacrée aux techniques, cette cohérence est essentielle pour maintenir les relations entre les tableaux de la base de données. Notre projet nécessitait un masquage déterministe afin de garantir la cohérence des identifiants clients dans les tableaux clients, commandes et avis.
Le masquage à la volée applique des transformations pendant le transfert de données entre les environnements. J'ai expérimenté cette approche lors de la mise en place d'un pipeline de déploiement pour un projet personnel. Le masquage s'est effectué pendant l'extraction des données plutôt que dans une étape distincte, ce qui a simplifié le flux de travail et l'a rendu particulièrement adapté aux pipelines CI/CD.
Les chercheurs ont besoin d'accéder à des modèles de données pour mettre en évidence des tendances, tester des hypothèses et élaborer des modèles fiables, mais le partage de données réelles comporte souvent le risque d'exposer des informations sensibles. L'obscurcissement statistique (une autre forme de masquage des données) constitue une solution. Lorsqu'elle est correctement effectuée, elle préserve les propriétés statistiques essentielles, telles que les moyennes, les variances et les corrélations, tout en garantissant la confidentialité des données individuelles. Cela permet aux analystes de tirer des conclusions pertinentes à partir des données sans compromettre la confidentialité.
C'est ici que la théorie a rencontré la pratique dans le cadre de notre projet. Chacune des techniques que je vais présenter dans la section suivante a permis de résoudre un défi particulier auquel nous étions confrontés.
La substitution est devenue mon approche par défaut pour la plupart des informations personnelles identifiables. Le concept est simple : remplacer les valeurs sensibles par des alternatives réalistes mais entièrement fictives. Les noms deviennent des noms différents. Les adresses électroniques sont modifiées. Les valeurs de remplacement conservent le même format et semblent authentiques à toute personne qui consulte les données.
Dans le cadre de notre projet de commerce électronique, j'avais besoin de masquer rapidement les informations relatives aux clients. J'ai découvert la bibliothèque Faker, qui peut être installée à l'aide de la commande ` pip install Faker`, et j'ai créé une fonction de masquage simple. Faker génère une grande variété de données factices réalistes, ce qui le rend idéal pour les opérations de masquage :
from faker import Faker
import pandas as pd
fake = Faker()
def mask_customer_data(customer_df):
masked_df = customer_df.copy()
masked_df['first_name'] = [fake.first_name() for _ in range(len(masked_df))]
masked_df['last_name'] = [fake.last_name() for _ in range(len(masked_df))]
masked_df['email'] = [fake.email() for _ in range(len(masked_df))]
return masked_df
# Example usage
original_customers = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com']
})
masked_customers = mask_customer_data(original_customers)Le code ci-dessus utilise un DataFrame pandas contenant les enregistrements des clients et remplace les informations d'identification par des alternatives fictives. L'exécution de cette opération sur notre ensemble de données initial a pris environ deux minutes et nous a fourni des centaines de noms et d'adresses e-mail de clients d'apparence réaliste. La bibliothèque Faker a géré la complexité liée à la génération de noms variés et crédibles ainsi que d'adresses e-mail correctement formatées. J'ai également appris que, comme les résultats étaient générés de manière aléatoire, ils n'étaient pas directement réidentifiables, ce que j'ai apprécié.
Une chose que j'ai apprise : Les données masquées doivent paraître suffisamment authentiques pour que votre cerveau ne les rejette pas pendant le développement. Au début, j'ai tenté d'utiliser des combinaisons de lettres aléatoires, mais le débogage de code avec des clients nommés « Xkqp Mmwz » me semblait peu approprié et rendait plus difficile la concentration sur les problèmes logiques réels. Les noms générés par Faker, tels que « Jennifer Martinez » et « Robert Chen », semblaient suffisamment naturels pour être utilisés de manière sérieuse.
Pour approfondir vos connaissances en matière de manipulation de données dans Python, notre cours Introduction à la science des données dans Python couvre les opérations fondamentales sur les DataFrame qui facilitent considérablement la mise en œuvre de ces techniques et d'autres.
Le remaniement a permis de résoudre un problème auquel je ne m'attendais pas initialement. Notre projet comprenait un tableau de bord administratif indiquant les montants d'achat moyens par catégorie démographique de clients. Nous avions besoin de montants d'achat réalistes pour vérifier si nos requêtes d'agrégation fonctionnaient correctement, mais nous n'avions pas besoin que des clients spécifiques soient associés à des achats spécifiques.
Le remaniement réorganise les valeurs d'une colonne de manière aléatoire tout en conservant la distribution globale :
import numpy as np
import pandas as pd
def shuffle_column(df, column_name):
shuffled_df = df.copy()
shuffled_values = shuffled_df[column_name].values
np.random.seed(42) # For reproducibility
np.random.shuffle(shuffled_values)
shuffled_df[column_name] = shuffled_values
return shuffled_df
# Example with purchase data
purchase_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'product': ['Laptop', 'Headphones', 'Mouse'],
'amount': [1200, 85, 25]
})
shuffled_purchases = shuffle_column(purchase_data, 'amount')Après le remaniement, les montants des achats étaient toujours présents dans l'ensemble de données (nous pouvions toujours calculer des moyennes et des distributions précises), mais le lien entre le client C001 et l'achat de 1 200 $ avait été rompu. Le client C001 pourrait désormais afficher un achat de 25 $ à la place.
L'idée principale : Le brassage préserve les propriétés statistiques nécessaires à l'analyse agrégée tout en rompant les associations au niveau individuel. C'est idéal lorsque vous testez des fonctionnalités qui fonctionnent avec des agrégats plutôt qu'avec des enregistrements individuels.
Le masquage partiel ne révèle que les informations nécessaires tout en dissimulant le reste. Cette technique m'était familière, car je l'avais observée à plusieurs reprises, notamment sur des sites web affichant des numéros de carte de crédit sous la forme ****-****-****-1234 ou des applications affichant des numéros de téléphone sous la forme (***) ***-5678.
La mise en œuvre de cette fonctionnalité dans notre projet a été simple :
def mask_credit_card(card_number):
visible_digits = 4
masked_portion = '*' * (len(card_number) - visible_digits)
return masked_portion + card_number[-visible_digits:]
def mask_phone(phone):
return '***-***-' + phone[-4:]
# Examples
print(mask_credit_card('4532123456781234')) # ************1234
print(mask_phone('555-0123')) # ***-***-0123Nous avons utilisé cette fonctionnalité pour l'historique des commandes, où les clients devaient vérifier quelle carte ils avaient utilisée pour un achat. L'affichage des quatre derniers chiffres fournissait suffisamment d'informations pour permettre la reconnaissance sans divulguer le numéro complet. Cela semblait être le juste équilibre entre utilité et confidentialité.
Parfois, la solution la plus simple consiste simplement à supprimer complètement les données. La mise à zéro remplace les valeurs des champs par NULL ou des chaînes vides lorsque les informations ne sont pas nécessaires pour les tests.
def null_fields(df, fields_to_null):
masked_df = df.copy()
for field in fields_to_null:
masked_df[field] = None
return masked_dfNos dossiers clients comprenaient un champ « notes » dans lequel les représentants du service clientèle pouvaient éventuellement rédiger des commentaires internes. Ce champ n'était pas pertinent pour tester la logique du panier d'achat ou le traitement des paiements, je l'ai donc simplement mis à zéro. Pourquoi prendre la peine de créer de fausses notes alors que nous pourrions simplement supprimer ce champ de nos données de test ?
Cela m'a enseigné une leçon importante sur le masquage : ne compliquez pas les choses. Masquez ce qui doit être masqué, supprimez ce qui n'a pas besoin d'exister.
La randomisation génère des valeurs entièrement nouvelles pour les champs où le maintien d'un lien avec les données d'origine n'a aucune utilité. Cela a bien fonctionné pour les identifiants et les numéros de référence :
import random
import string
def randomize_order_id():
return 'ORD-' + ''.join(random.choices(string.ascii_uppercase + string.digits, k=8))
order_ids = [randomize_order_id() for _ in range(5)]
print(order_ids)Nos identifiants de commande n'avaient pas besoin de correspondre à ceux du jeu de données original. Il était simplement nécessaire qu'ils aient un aspect réaliste et qu'ils soient uniques. La génération aléatoire répondait aux deux exigences. Chaque identifiant généré, tel que « ORD-K7M2N9P4 », ressemblait à une référence de commande plausible sans être lié à quoi que ce soit de réel.
La tokenisation remplace les valeurs sensibles par des jetons générés de manière aléatoire tout en stockant de manière sécurisée les données d'origine dans un système distinct et hautement protégé. Contrairement à d'autres techniques de masquage, la tokenisation est conçue pour être réversible, mais uniquement par le biais d'un accès contrôlé. J'ai découvert cette approche en effectuant des recherches sur les exigences en matière de traitement des paiements :
import uuid
# Note: Production token vaults use encrypted database storage, not in-memory dicts
class TokenVault:
def __init__(self):
self.token_map = {}
self.reverse_map = {}
def tokenize(self, sensitive_value):
if sensitive_value in self.token_map:
return self.token_map[sensitive_value]
token = str(uuid.uuid4())
self.token_map[sensitive_value] = token
self.reverse_map[token] = sensitive_value
return token
def detokenize(self, token):
return self.reverse_map.get(token)
vault = TokenVault()
token = vault.tokenize('4532-1234-5678-9012')
print(f"Token: {token}")
original = vault.detokenize(token)
print(f"Original: {original}")Nous n'avons pas mis en œuvre la tokenisation dans notre projet de classe, car nous n'avions pas besoin de réversibilité. Cependant, la lecture d'informations sur les systèmes de paiement a permis de clarifier le cas d'utilisation : Votre base de données d'applications stocke uniquement les jetons (chaînes aléatoires sans valeur), tandis que les informations de paiement réelles sont conservées dans un coffre-fort de jetons entièrement séparé et hautement sécurisé. Si votre base de données d'application est compromise, l'attaquant n'obtient que des jetons inutilisables et n'a aucun moyen d'accéder aux numéros de carte de crédit réels sans violer le coffre-fort lui-même. Cette séparation architecturale rend la tokenisation particulièrement utile pour la conformité des processus de paiement.
Les techniques cryptographiques transforment les données à l'aide d'algorithmes mathématiques. J'ai mis en place un système de hachage pour le stockage de nos mots de passe après que notre professeur ait insisté sur l'importance de ne jamais stocker les mots de passe en clair. Pour les systèmes de production, il est recommandé d'utiliser bcrypt ou Argon2, qui intègrent des sels et sont conçus pour être coûteux en termes de calcul afin de résister aux attaques par force brute. Je présente ici bcrypt, bien qu'Argon2 soit également très performant pour la production :
import bcrypt
def hash_password(password):
# Generate a salt and hash the password
salt = bcrypt.gensalt()
hashed = bcrypt.hashpw(password.encode(), salt)
return hashed
def verify_password(password, hashed):
# Verify a password against its hash
return bcrypt.checkpw(password.encode(), hashed)
# Store the hash, never the actual password
password = 'user_password_123'
password_hash = hash_password(password)
print(f"Stored hash: {password_hash}")
# Output: Stored hash: b'$2b$12$K7g.../XYZ' (different each time due to random salt)
# Verify during login
is_valid = verify_password('user_password_123', password_hash)
print(f"Password valid: {is_valid}") # Output: Password valid: TrueLe hachage génère des transformations unidirectionnelles utiles pour la vérification. Lorsque j'ai testé cela pour la première fois, j'ai été surpris de constater que bcrypt génère un hachage différent à chaque fois en raison du sel aléatoire, mais que verify_password() correspond toujours correctement au mot de passe d'origine. Le sel garantit que même des mots de passe identiques produisent des hachages différents, ce qui protège contre les attaques par table arc-en-ciel. Lors de la connexion, nous hachons le mot de passe saisi et utilisons la fonction de vérification de bcrypt pour le comparer de manière sécurisée. Cela signifie que même les développeurs ayant accès à la base de données ne peuvent pas voir les mots de passe des utilisateurs.
Remarque : Pour utiliser cet exemple, il est nécessaire d'installer bcrypt à l'aide de la commande suivante : ` pip install bcrypt `.
Le chiffrement diffère du hachage en ce qu'il permet de déchiffrer le message pour le ramener à sa forme d'origine à l'aide de clés. Nous n'avions pas besoin de cryptage pour notre projet, mais je comprends son utilité : Utilisez cette option lorsque des personnes autorisées ont besoin d'accéder à des données réelles, mais que vous souhaitez les protéger contre tout accès non autorisé.
Ces techniques connexes diffèrent par leur réversibilité. La pseudonymisation remplace les informations identifiables tout en conservant la possibilité de réidentifier les personnes si nécessaire. L'anonymisation supprime entièrement les informations identifiables, rendant ainsi impossible toute réidentification.
def pseudonymize_data(df, id_column, key_mapping=None):
if key_mapping is None:
key_mapping = {}
pseudo_df = df.copy()
for idx, original_id in enumerate(pseudo_df[id_column].unique()):
if original_id not in key_mapping:
key_mapping[original_id] = f"PSEUDO_{idx:06d}"
pseudo_df.loc[pseudo_df[id_column] == original_id, id_column] = key_mapping[original_id]
return pseudo_df, key_mapping
# Using pseudonymization
customer_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C001'],
'purchase': ['Laptop', 'Mouse', 'Keyboard']
})
pseudonymized_data, mapping = pseudonymize_data(customer_data, 'customer_id')Notre projet a utilisé la pseudonymisation afin de garantir la cohérence des clients sur plusieurs achats tout en masquant les identifiants réels des clients. Les trois achats du client C001 ont tous été associés au même pseudonyme, ce qui permet d'analyser le comportement individuel des clients sans révéler leur véritable identité.
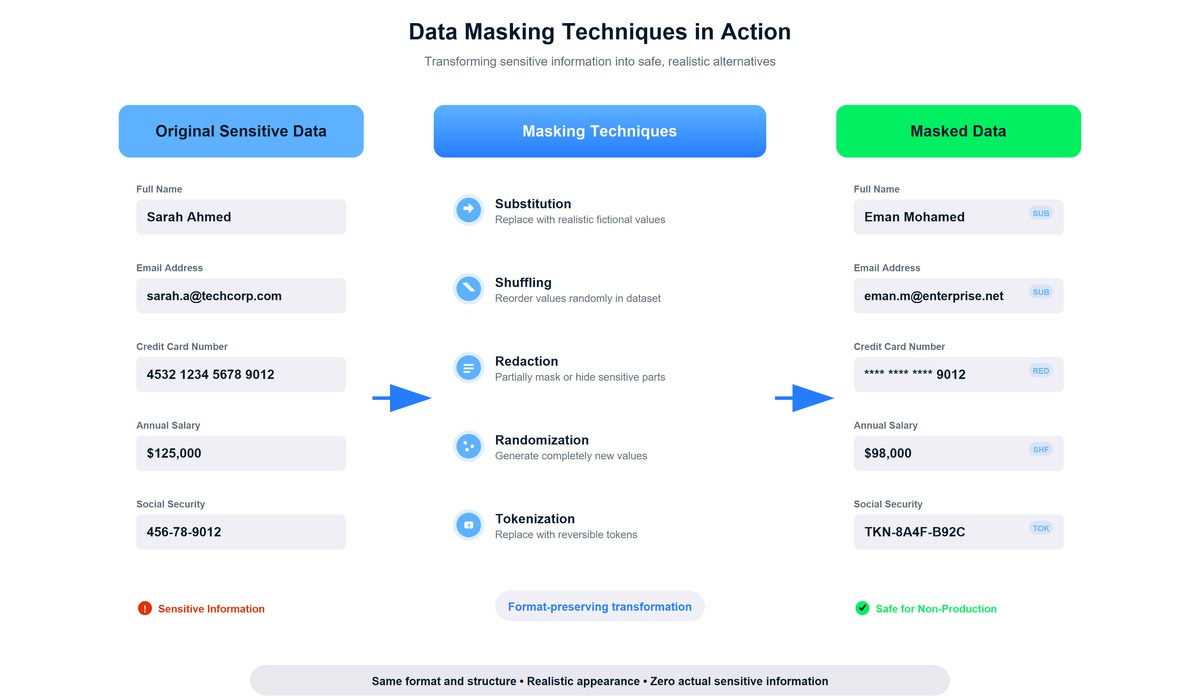
Plusieurs techniques de masquage transforment les données sensibles tout en conservant leur format et leur facilité d'utilisation.
Au départ, j'ai confondu le masquage des données avec le chiffrement et l'anonymisation, car ces trois techniques visent à protéger les informations sensibles. Comprendre ces distinctions m'a aidé à sélectionner les techniques appropriées pour différents scénarios. Permettez-moi de vous expliquer les principales différences afin de clarifier quand utiliser chaque approche.
|
Approche |
Fonctionnement |
Réversibilité |
Meilleur cas d'utilisation |
|
Masquage des données |
Remplace les données sensibles par des valeurs fictives mais réalistes. |
Irréversible (aucune récupération possible sans la base de données source) |
Environnements de développement, de test et d'analyse où une structure de données réaliste est nécessaire, mais où les valeurs réelles ne sont pas disponibles. |
|
Cryptage |
Cryptage des données à l'aide d'algorithmes mathématiques |
Réversible avec des clés de décryptage |
Protection des données en transit ou en stockage lorsque les utilisateurs autorisés doivent accéder aux valeurs originales |
|
Anonymisation |
Supprime ou généralise les informations d'identification |
Irréversible (conçu pour empêcher la réidentification) |
Publier des ensembles de données à des fins de recherche ou d'utilisation publique tout en protégeant la vie privée des individus |
|
Données synthétiques |
Génère des ensembles de données entièrement artificiels à l'aide de modèles statistiques ou d'apprentissage automatique. |
N/A (aucune donnée originale à laquelle se référer) |
Formation de modèles d'apprentissage automatique ou scénarios dans lesquels même les données réelles masquées semblent trop risquées |
J'ai clairement compris la distinction entre le chiffrement et le masquage lors de notre module sur la sécurité des bases de données. Nous avons crypté les sauvegardes de la base de données afin qu'elles soient inutilisables en cas de vol, mais nous avons masqué la base de données de développement car les développeurs devaient travailler avec les données, sans toutefois utiliser les données réelles des clients. Comme je l'ai mentionné précédemment, le chiffrement protège les données que vous finirez par déchiffrer, tandis que le masquage crée des alternatives sécurisées de manière permanente.
La distinction entre le masquage et l'anonymisation met en évidence des objectifs différents. L'anonymisation vise spécifiquement à supprimer les informations identifiables afin d'empêcher la réidentification des personnes grâce à des techniques telles que la généralisation (remplacement des âges exacts par des tranches d'âge) et la suppression (suppression totale des attributs identifiables). Le masquage met l'accent sur le maintien de l'utilité des données pour le développement, les tests et l'analyse.
Un camarade de classe travaillant sur un projet d'apprentissage automatique a utilisé des données synthétiques générées à partir de modèles issus d'un ensemble de données réelles. Les données synthétiques ne contenaient aucun enregistrement réel, mais reproduisaient les propriétés statistiques nécessaires à l'entraînement du modèle. J'ai préféré le masquage aux données synthétiques pour notre projet, car nous devions tester des scénarios spécifiques tels que la gestion des adresses e-mail en double ou le traitement des adresses internationales. Les données synthétiques pourraient ne pas refléter ces cas particuliers, tandis que les données réelles masquées les ont conservés.
La mise en œuvre du masquage m'a appris que la protection des informations sensibles tout en conservant l'utilité des données implique de relever des défis qui ne sont pas évidents tant qu'on ne les rencontre pas. Permettez-moi de vous présenter les principaux obstacles auxquels j'ai été confronté et comment je les ai surmontés.
La préservation des attributs s'est avérée plus complexe que prévu. Le simple fait de remplacer des valeurs de manière aléatoire perturbe les modèles dont dépendent les applications. Les numéros de carte de crédit suivent l'algorithme de Luhn pour la validation de la somme de contrôle, les adresses e-mail doivent comporter des domaines correctement formatés et les codes postaux correspondent à des régions géographiques. J'ai appris cela à mes dépens lorsque ma première tentative de masquage a généré des numéros aléatoires à 16 chiffres pour les champs de carte de crédit. Tout semblait fonctionner correctement jusqu'à ce que les tests révèlent que notre logique de validation des paiements rejetait tous les numéros de carte, car j'avais omis que les numéros de carte de crédit comprennent des chiffres de contrôle calculés à l'aide de l'algorithme de Luhn.
L'intégrité sémantique est importante au-delà du simple format. Les données masquées doivent éviter les combinaisons manifestement absurdes. Au cours des tests, un collègue a remarqué que notre ensemble de données masquées comportait des codes postaux de l'Alaska attribués à des adresses postales en Floride. Bien que techniquement valides, les formats présentaient une incohérence géographique qui semblait suspecte. J'ai consacré un après-midi à améliorer la cohérence sémantique en générant des adresses complètes où tous les éléments correspondaient géographiquement, plutôt que d'associer les éléments d'adresse de manière aléatoire.
L'intégrité référentielle entre les tables a entraîné une complexité significative. Comme je l'ai expliqué dans la section consacrée aux techniques, notre base de données comportait des tableaux clients, commandes et avis, avec des identifiants clients apparaissant dans les trois. Si le masquage transformait les identifiants clients de manière incohérente, ces relations étaient complètement rompues. Cela m'est arrivé après ma première tentative de masquage : 30 % de nos tests d'intégration ont échoué car les commandes des clients n'étaient plus liées aux dossiers clients. La solution m'est apparue lorsque j'ai compris que je devais traiter les tableaux dans l'ordre de dépendance à l'aide d'un masquage déterministe afin de garantir que le client C001 obtienne toujours le même identifiant masqué, quel que soit l'endroit où il apparaissait.
Trouver le juste équilibre entre sécurité et valeur analytique nécessite un jugement constant. Un masquage plus strict améliore la confidentialité mais réduit l'utilité. Par exemple, arrondir tous les âges à la décennie la plus proche améliore la confidentialité, mais empêche toute analyse utile basée sur l'âge. Notre projet privilégiait l'utilité, car nous développions des fonctionnalités d'application nécessitant un comportement réaliste des données. Dans un scénario de production réel avec des données clients réelles et des obligations de conformité, je devrais accorder davantage d'importance à la protection de la vie privée et éventuellement accepter une utilité réduite des données.
Les relations statistiques peuvent être faussées. Si vous disposez de deux colonnes corrélées, telles que les revenus et les dépenses, et que vous les mélangez indépendamment l'une de l'autre, la corrélation est susceptible de changer. D'un point de vue statistique, le brouillage indépendant modifie la distribution conjointe des variables. Afin de préserver cette relation, les analystes ont parfois recours à des transformations préservant le classement, telles que le remaniement des deux colonnes à l'aide de la même permutation aléatoire ou l'ajout d'un bruit contrôlé qui maintient leur ordre conjoint.
Après avoir appris ces techniques individuelles, j'ai souhaité observer comment elles s'appliquent ensemble dans un scénario réaliste. Voici un exemple complet illustrant le masquage d'une base de données clients avec les commandes associées, ce qui correspond exactement au défi auquel nous avons été confrontés dans le cadre de notre projet de commerce électronique.
from faker import Faker
import pandas as pd
import numpy as np
import uuid
fake = Faker()
Faker.seed(42) # For reproducible results
# Original datasets (simulating real customer data)
customers_original = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com'],
'phone': ['555-0123', '555-0124', '555-0125'],
'credit_card': ['4532-1234-5678-9012', '4556-7890-1234-5678', '4539-8765-4321-0987'],
'internal_notes': ['VIP customer', 'Requested callback', 'Payment issue resolved']
})
orders_original = pd.DataFrame({
'order_id': ['ORD001', 'ORD002', 'ORD003', 'ORD004'],
'customer_id': ['C001', 'C002', 'C001', 'C003'],
'product': ['Laptop', 'Mouse', 'Keyboard', 'Monitor'],
'amount': [1299.99, 29.99, 89.99, 399.99]
})
# Step 1: Create deterministic ID mapping to maintain referential integrity
def create_id_mapping(ids):
"""Create consistent pseudonymous IDs"""
mapping = {}
for idx, original_id in enumerate(ids):
mapping[original_id] = f"CUST_{idx:06d}"
return mapping
customer_id_mapping = create_id_mapping(customers_original['customer_id'].unique())
# Step 2: Mask customer data using multiple techniques
def mask_customer_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Replace customer IDs consistently
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Substitution: Replace names and emails with realistic fake data
masked['first_name'] = [fake.first_name() for _ in range(len(masked))]
masked['last_name'] = [fake.last_name() for _ in range(len(masked))]
masked['email'] = [fake.email() for _ in range(len(masked))]
# Partial masking/redaction: Show last 4 digits of phone and credit card
masked['phone'] = masked['phone'].apply(lambda x: '***-' + x[-4:])
masked['credit_card'] = masked['credit_card'].apply(lambda x: '****-****-****-' + x[-4:])
# Nulling: Remove internal notes entirely
masked['internal_notes'] = None
return masked
# Step 3: Mask order data with referential integrity
def mask_order_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Use same customer ID mapping to maintain relationships
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Randomization: Generate new order IDs
masked['order_id'] = [f"ORD-{uuid.uuid4().hex[:8].upper()}" for _ in range(len(masked))]
# Shuffling: Preserve amount distribution but break individual associations
shuffled_amounts = masked['amount'].values.copy()
np.random.shuffle(shuffled_amounts)
masked['amount'] = shuffled_amounts
return masked
# Apply masking
customers_masked = mask_customer_database(customers_original, customer_id_mapping)
orders_masked = mask_order_database(orders_original, customer_id_mapping)
print("=== MASKED CUSTOMER DATA ===")
print(customers_masked)
print("\n=== MASKED ORDER DATA ===")
print(orders_masked)
# Verify referential integrity is maintained
print("\n=== VERIFICATION: JOIN STILL WORKS ===")
joined = customers_masked.merge(orders_masked, on='customer_id')
print(f"Original orders: {len(orders_original)}, Joined orders: {len(joined)}")
print("✓ All order-customer relationships preserved!")Lorsque j'ai exécuté ce pipeline de masquage complet sur les données de notre projet (500 enregistrements clients avec 1 200 commandes), l'exécution a pris environ 2 secondes, ce qui était tout à fait acceptable pour notre cycle hebdomadaire de rafraîchissement de la base de données de développement. Plusieurs éléments se sont mis en place :
L'intégrité référentielle a fonctionné de manière optimale. C001La table « Customer » (initialement « CUST_000000 ») contenait des commandes à la fois dans les tableaux « Customers » et « Orders ». Les requêtes d'JOIN s qui alimentent notre fonctionnalité d'historique des commandes ont fonctionné de manière identique avec les données masquées, car nous avons utilisé la même customer_id_mapping s pour les deux tables.
Chaque technique avait un objectif spécifique. La substitution a rendu les noms des clients plus réalistes. Le masquage partiel nous permet de vérifier les méthodes de paiement sans divulguer l'intégralité des numéros de carte. Le remaniement a permis à nos tableaux de bord analytiques de continuer à afficher des répartitions précises des revenus tout en dissociant les montants des clients spécifiques. Nous avons supprimé les données inutiles pour les tests.
Le résultat ressemblait et se comportait comme de véritables données d'. Lorsque j'ai examiné la base de données masquée pendant le développement, tout semblait authentique. Les adresses électroniques ont été validées correctement. Les numéros de téléphone s'affichent correctement. Les données ne semblaient pas indiquer qu'elles étaient fausses, ce qui m'a permis de me concentrer sur le débogage de la logique de l'application plutôt que d'être distrait par des données de test manifestement artificielles.
La qualité des données est restée élevée. Nous pourrions toujours tester des cas particuliers, tels que les clients ayant passé plusieurs commandes, calculer des statistiques agrégées et vérifier les contraintes de la base de données. Le masquage a permis de préserver la complexité et les relations dont nous avions besoin tout en protégeant chaque élément d'information sensible.
Cette approche a transformé ce qui semblait initialement être un problème insurmontable, à savoir la création d'une base de données de test sûre mais réaliste, en un processus systématique et reproductible. À chaque fois que nous actualisions notre base de données de développement, l'exécution de ce script de masquage prenait moins d'une minute et nous garantissait qu'aucune donnée client réelle ne pouvait être divulguée.
Commencez par une exploration complète des données. Des informations sensibles ont été identifiées dans des emplacements inattendus, au-delà des champs évidents tels que les noms et les adresses électroniques. Notre base de données comportait des champs de notes clients contenant des entrées en texte libre pouvant inclure des informations personnelles. J'ai appris à examiner systématiquement tous les domaines, et pas seulement ceux qui sont manifestement sensibles. Dans les systèmes de production, les organisations utilisent des outils automatisés de découverte de données qui recherchent des modèles correspondant à des informations personnelles identifiables.
Définissez clairement et dès le début les politiques de masquage. Au départ, les différents membres de l'équipe ont pris des décisions indépendantes en matière de masquage, ce qui a entraîné des incohérences. Une personne a masqué entièrement les numéros de téléphone, une autre a utilisé un masquage partiel et une troisième les a laissés tels quels. Nous avons finalement standardisé notre approche : masquage complet pour les noms et les adresses e-mail, masquage partiel pour les numéros de téléphone et les cartes, et mise à zéro pour les notes internes. Les politiques documentées précisent les éléments de données qui doivent être masqués, les techniques à appliquer aux différents types de données et la manière de traiter les cas particuliers.
Veuillez utiliser des algorithmes préservant le format. Plutôt que de remplacer les données par des valeurs aléatoires, ces algorithmes génèrent des remplacements réalistes qui satisfont aux mêmes règles de validation que les données originales. Comme je l'ai démontré précédemment, le masquage de ma carte de crédit devait générer des numéros passant la validation Luhn, et le masquage des adresses e-mail nécessitait des adresses correctement formatées avec des modèles de domaine valides.
Veuillez tester rigoureusement la qualité du masquage. J'ai rédigé des tests simples pour vérifier la qualité des données masquées avant leur utilisation dans le développement. Ces tests ont permis de vérifier si les adresses e-mail masquées passaient la validation regex, si les identifiants clients restaient uniques après le masquage, si les relations entre clés étrangères restaient valides et si l'ensemble de données masqué avait la même taille que l'original. Ces tests ont permis de détecter des problèmes tels que la génération de doublons et les violations d'intégrité référentielle avant que nous ne les rencontrions lors des tests d'application.
Automatisez l'ensemble du processus. Ma première tentative de masquage consistait à exécuter manuellement des scripts Python et à copier des fichiers, ce qui est rapidement devenu fastidieux. J'ai finalement créé un script unique qui gère l'ensemble du processus : lecture des données d'origine, application de toutes les transformations de masquage, validation des résultats et écriture des données masquées. Pour les projets réels avec des pipelines d'intégration continue, le masquage s'intégrerait comme une étape automatisée à laquelle les développeurs n'auraient même pas à réfléchir.
Veuillez garantir l'irréversibilité et la répétabilité. Le processus de masquage doit être irréversible pour offrir une protection authentique, mais reproductible lorsque vous devez actualiser les bases de données de test avec des résultats cohérents. L'utilisation de techniques déterministes avec des graines cohérentes, comme je l'ai démontré dans l'exemple complet, permet d'atteindre cet équilibre.
Le masquage des données évolue rapidement grâce à l'intelligence artificielle et à l'apprentissage automatique. Bien que notre projet de classe ait utilisé des techniques de masquage traditionnelles, les solutions modernes exploitent de plus en plus l'IA pour automatiser et améliorer le processus de masquage.
La possibilité qui me semble la plus intéressante est la découverte automatisée des données. J'ai passé plusieurs heures à examiner manuellement le schéma de notre base de données afin d'identifier les champs contenant des informations sensibles. Imaginez un outil qui identifie automatiquement les champs sensibles en analysant les modèles, les noms de colonnes et les distributions de valeurs, plutôt que de nécessiter une vérification manuelle. Un système d'apprentissage automatique pourrait reconnaître qu'une colonne portant le nom inhabituel « user_identifier » contient en réalité des adresses électroniques, ce que je pourrais facilement négliger lors d'une inspection manuelle. Cela m'aurait permis de gagner un temps considérable.
J'ai également lu des articlessur les techniques d'apprentissage automatique préservant la confidentialité qui vont au-delà du masquage traditionnel. La confidentialité différentielle, par exemple, ajoute un bruit mathématique soigneusement calibré aux données d'entraînement ou aux résultats des modèles. L'apprentissage fédéré permet de former des modèles à partir d'ensembles de données distribués sans centraliser les informations sensibles. Ces approches traitent des scénarios dans lesquels le masquage standard pourrait supprimer des modèles dont les modèles ont besoin pour apprendre.
La génération de données synthétiques à l'aide de l'IA générative m'intéresse particulièrement pour de futurs projets. Au lieu de masquer les enregistrements réels, les systèmes d'IA formés sur des modèles de données réels génèrent des ensembles de données entièrement artificiels. Je n'ai pas encore essayé de mettre cela en œuvre moi-même, mais je comprends l'intérêt de cette approche dans les cas où des ensembles de données d'entraînement volumineux sont nécessaires ou lorsque même les données réelles masquées présentent un risque. Le défi consisterait à garantir que les données synthétiques représentent fidèlement les cas limites et la complexité qui ont rendu les données réelles masquées si précieuses pour nos tests.
En observant l'évolution du domaine, les workflows de développement cloud natifs commencent à intégrer le masquage automatisé comme infrastructure standard. Plutôt que de masquer manuellement à l'aide de scripts Python, les pipelines de déploiement pourraient gérer cela automatiquement lors de l'approvisionnement des bases de données de développement. Les développeurs devraient définir les exigences de masquage dans les fichiers de configuration, parallèlement aux schémas de base de données. C'est le type d'automatisation que j'aimerais mettre en œuvre dans de futurs projets, en transformant le masquage d'une étape de prétraitement manuelle en un comportement automatique de l'infrastructure.
Cependant, l'IA représente une arme à double tranchant pour la confidentialité des données. Tout en améliorant les techniques de masquage, cela rend également les attaques de réidentification plus sophistiquées. Les modèles d'apprentissage automatique peuvent recouper des données apparemment anonymisées avec des informations publiques afin de réidentifier des individus. Des chercheurs ont réussi à réidentifier des personnes dans des données « anonymisées » de Netflix en les corrélant avec des critiques IMDb. À mesure que les outils de masquage deviennent plus sophistiqués, les méthodes permettant de les contourner évoluent également.
Le masquage des données offre un équilibre parfait entre l'utilité des données et la confidentialité. En appliquant les techniques appropriées, telles que la substitution, le masquage déterministe et les méthodes de préservation du format, il est possible de conserver des données réalistes tout en protégeant les informations sensibles.
Commencez par identifier vos ensembles de données les plus critiques et appliquez le masquage dans les environnements hors production. Automatisez dès le début afin d'intégrer la protection de la vie privée dans votre flux de travail.
Pour approfondir vos compétences, nous vous invitons à explorer nos cours sur la confidentialité et l'anonymisation des données dans Python ou sur l'ingénierie des données pour tous.
Apprenez avec DataCamp
Cours
Cours
Cours