Kurs
Grundlagen von Data Engineering
2 Std.
356.4K
Letztes Semester hatten wir in meinem Datenbank-Kurs ein Abschlussprojekt, das auf den ersten Blick einfach klang: eine funktionierende E-Commerce-App mit Benutzerauthentifizierung, Warenkörben und Bestellabwicklung zu entwickeln. Der Haken? Wir mussten zeigen, dass es mit echten Datenmustern klappt, nicht nur mit drei Testnutzern namens „Ali“, „Shahd“ und „Khalid“.
Mein Team hatte ein dringendes Problem. Wir brauchten hunderte von Kundendatensätzen mit unterschiedlichen Kaufhistorien, um Randfälle wie Großbestellungen, Rückerstattungen und Bestandsverwaltung zu testen. Wir konnten keine echten Daten von bestehenden Websites sammeln; das ist sowohl unethisch als auch illegal. Hunderte von realistischen Datensätzen manuell zu erstellen, würde ewig dauern. Da hat uns unser Professor das Thema Datenmaskierung gezeigt.
In diesem Artikel erzähle ich euch, was ich bei der Umsetzung von Datenmaskierungstechniken gelernt habe. Du wirst erfahren, was Datenmaskierung ist, wann und warum sie wichtig ist und wie du bestimmte Techniken anwenden kannst, um sensible Informationen zu schützen und gleichzeitig die Nutzbarkeit der Daten zu erhalten. Ich zeig dir ein paar praktische Beispiele aus meinem Projekt und wie du die Fehler vermeiden kannst, die ich gemacht hab.
Als ich zum ersten Mal den Begriff „Datenmaskierung“ hörte, dachte ich an so was wie das Schwärzen von Text in Regierungsdokumenten, also einfach sensible Teile schwarz machen. Die Realität ist vielschichtiger und nützlicher. Datenmaskierung macht strukturell ähnliche, aber inhaltlich falsche Versionen von sensiblen Daten.
Der technische Prozess besteht darin, die ursprünglichen Datenwerte durch fiktive Alternativen zu ersetzen, die Format, Typ und statistische Eigenschaften beibehalten. Für unser E-Commerce-Projekt haben wir einen kleinen Datensatz mit echt aussehenden Kundendaten aus einem Tool zur Datengenerierung genommen und Maskierungstechniken angewendet, um Variationen zu erstellen. Eine E-Mail wie khalid.abdelaty@company.com wurde zu ahmed.j@enterprise.com. Beide sind gültige E-Mail-Formate, die die Validierungsprüfungen bestehen, aber die maskierte Version verrät nichts über echte Personen.
Du wirst dieses Konzept unter verschiedenen Namen finden, je nachdem, wer darüber redet. Bei der Datenverschleierung geht's vor allem darum, Sachen zu verstecken. Pseudonymisierung heißt im Grunde, dass man erkennbare Infos austauscht, aber trotzdem die Daten wiederherstellen kann, wenn man sie braucht. Bei der Tokenisierung werden sensible Werte durch zufällig generierte Token ersetzt. Diese Begriffe überschneiden sich ziemlich stark, und nach dem, was ich in Dokumentationen und Tutorials gesehen habe, werden sie oft ziemlich synonym benutzt.
Du fragst dich jetzt vielleicht, ob diese neuen E-Mails oder IDs irgendwie von den ursprünglichen Daten abgeleitet sind. Die kurze Antwort: Es kommt auf die Maskierungstechnik an. Ich hab mehr Infos dazu in den FAQs hinterlassen.
Die Bedeutung wurde mir klar, als unser Professor darauf hinwies, dass unser „Klassenprojekt” echte Herausforderungen in der Produktion widerspiegelte. Firmen müssen Software mit Daten testen, die denen in der Produktion ähneln, und Analysten müssen Modelle mit realistischen Mustern erstellen. Aber die Verwendung von echten Kundendaten in diesen Umgebungen bringt echt große Probleme mit sich.
Die Einhaltung von Vorschriften ist für die meisten Unternehmen ein echtes Top-Thema. Die DSGVO, die europäische Datenschutz-Grundverordnung, verlangt, dass Unternehmen die Datenverarbeitung so gering wie möglich halten und personenbezogene Daten mit geeigneten technischen Maßnahmen schützen. HIPAA verlangt von Gesundheitsdienstleistern, dass sie Patientendaten auch in Testumgebungen schützen. Das kalifornische Verbraucherschutzgesetz bietet den Leuten in Kalifornien ähnliche Schutzmaßnahmen. Aus geschäftlicher Sicht kann das Brechen dieser Regeln zu fetten Geldstrafen führen. Aus ethischer Sicht erwarten die Leute, dass ihre Daten geschützt werden.
Datenmaskierung bietet auch wichtige Sicherheitsvorteile. Jede zusätzliche Umgebung, die echte Daten hat, macht die Angriffsfläche größer. Entwicklungsserver haben normalerweise weniger strenge Sicherheitskontrollen als Produktionssysteme, und Entwickler arbeiten oft mit Daten auf lokalen Rechnern, die vielleicht nicht verschlüsselt sind. Jedes Szenario birgt Risiken für Sicherheitsverletzungen, die durch Datenmaskierung vermieden werden, indem sichergestellt wird, dass Nicht-Produktionsumgebungen niemals echte Informationen enthalten.
Was mich am meisten überrascht hat, war, die praktischen Vorteile für die Entwicklung zu entdecken. Unsere Qualitätssicherungstests haben Fehler aufgedeckt, die wir mit unserem ursprünglichen Testdatensatz mit drei Benutzern nie gefunden hätten. Der Code von einem Teammitglied hat bei der Verarbeitung von Namen mit Apostrophen wie „O'Brien“ Probleme gemacht. Ein anderer hat E-Mail-Adressen mit Pluszeichen-Aliasen wie „user+tag@domain.com."” kaputt gemacht. Diese Randfälle sind nur aufgetreten, weil unser maskierter Datensatz, der aus realistischen Mustern abgeleitet wurde, die Komplexität enthielt, die echte Produktionsdaten haben würden.
Zu wissen, wann Maskierung angewendet wird, hat mir geholfen, sie in verschiedenen Situationen zu erkennen. Das offensichtlichste Szenario passt zu unserem Klassenprojekt: Softwareentwicklung und -tests. Beim Entwickeln neuer Funktionen oder beim Debuggen von vorhandenem Code brauchen Entwickler Daten, die die Komplexität der realen Welt abbilden. Ich habe ewig gebraucht, um rauszufinden, warum die Berechnung unseres Warenkorbs bei bestimmten Produktkombinationen nicht richtig funktioniert hat. Der Fehler ist nur aufgetreten, weil unser maskierter Datensatz Sonderfälle wie Artikel mit einem Wert von null Dollar und Mengenbeschränkungen enthielt.
Datenanalyse- und Forschungsprojekte brauchen oft große Datensätze mit realistischen statistischen Eigenschaften. Ein Teamkollege, der an einem anderen Analyseprojekt arbeitet, brauchte die Kaufmuster der Kunden, um Empfehlungsalgorithmen zu entwickeln. Sie brauchte keine echten Kundennamen oder Adressen, sondern nur die Verhaltensmuster. Die maskierten Daten haben diese Muster gezeigt und gleichzeitig die Privatsphäre geschützt.
Externe Zusammenarbeit ist ein weiterer häufiger Anwendungsfall. Firmen holen sich für Integrationsprojekte oft Berater oder Auftragnehmer dazu, die realistische Daten brauchen, aber nicht an sensible Kundendaten ran dürfen. Die Mitarbeiterschulung ist noch eine praktische Anwendung. Bevor jemand an Produktionssysteme ran darf, braucht er Übungsumgebungen mit realistischen, aber sicheren Daten. Als letztes Beispiel kann man sagen, dass auch die Cloud-Entwicklung von Maskierung profitiert, obwohl die großen Cloud-Anbieter ihre eigenen Maskierungstools als Teil ihrer Sicherheitsdienste anbieten.
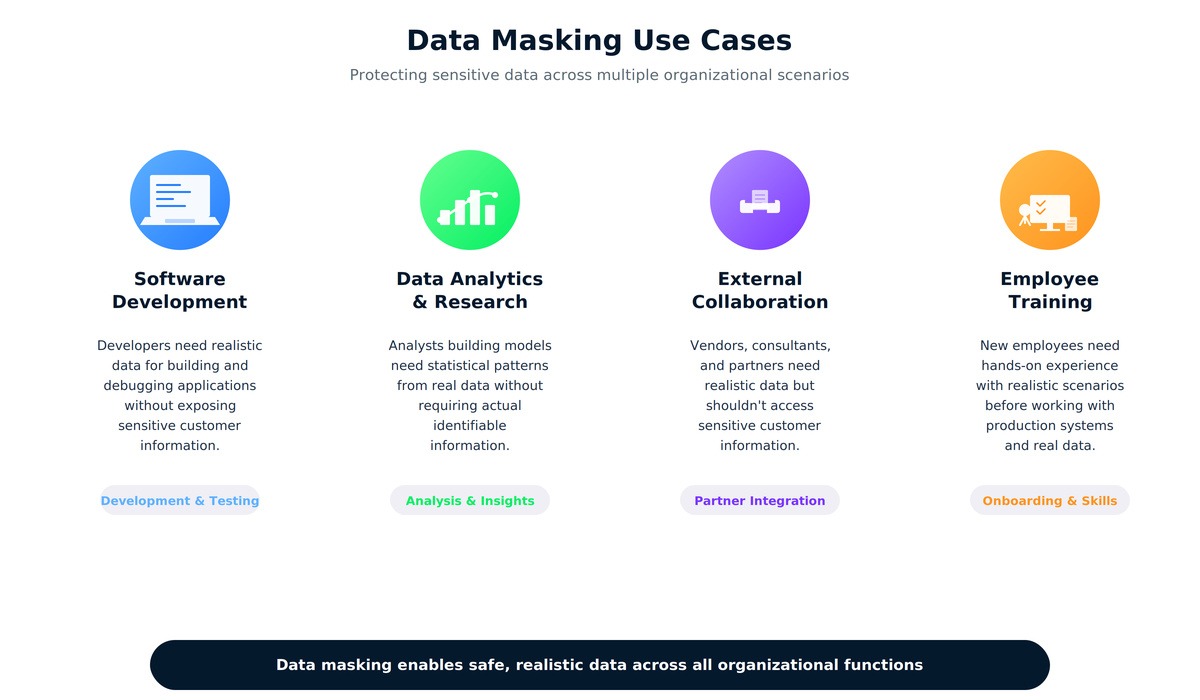
Datenmaskierung hilft bei vielen organisatorischen Sachen, von der Entwicklung bis zur Einhaltung von Vorschriften.
Bevor wir uns mit den einzelnen Techniken beschäftigen, solltest du die wichtigsten Arten der Maskierung kennenlernen und wissen, wann du welche benutzt.
Statisches Maskieren wird auf gespeicherte Datensätze angewendet und erstellt maskierte Kopien, die unabhängig von den Originaldaten existieren. Das haben wir für unser E-Commerce-Projekt benutzt. Ich hab ein Python-Skript laufen lassen, das unseren ersten Datensatz gelesen, Maskierungstransformationen angewendet und die Ergebnisse in eine neue Datei geschrieben hat, die wir alle für die Entwicklung benutzt haben. Nachdem der maskierte Datensatz erstellt war, blieb er stabil, bis wir ihn mit neuen Mustern aktualisieren mussten. Der Vorteil war schnell klar: Die Leistung wurde nur einmal während des Maskierungsprozesses beeinträchtigt, was es super für Nicht-Produktionsumgebungen macht, wo man einmal maskiert und die Kopie dann immer wieder benutzt.
Die dynamische Maskierung läuft in Echtzeit, wenn Leute auf Daten zugreifen, und macht dabei Änderungen, je nachdem, welche Berechtigungen sie haben. Ich bin zum ersten Mal auf dieses Konzept gestoßen, als ich mich mit Sicherheitsfunktionen für Datenbanken beschäftigt habe. Ein Systemadministrator sieht die kompletten Kundendaten, während ein Support-Mitarbeiter maskierte Kreditkartennummern sieht. Die Daten bleiben gleich, aber was jeder Nutzer sieht, hängt von seiner Berechtigungsstufe ab. Dieser Ansatz passt gut zu Produktionssystemen, wo verschiedene Benutzer je nach ihrer Rolle unterschiedliche Ansichten brauchen.
Deterministisches Masking sorgt für Konsistenz, indem es immer die gleiche Eingabe durch die gleiche Ausgabe ersetzt. Wenn die Kundin „Sarah Ali“ in einer Tabelle zu „Eman Mohamed“ wird, gilt diese Änderung überall, wo Sarah Ali auftaucht. Wie ich im Abschnitt „Techniken” erklären werde, ist diese Konsistenz super wichtig, um Beziehungen zwischen Tabellen aufrechtzuerhalten. Für unser Projekt mussten wir die Kunden-IDs in der Kundentabelle, der Auftragstabelle und der Bewertungstabelle einheitlich halten.
On-the-fly-Maskierung macht Transformationen während der Datenübertragung zwischen Umgebungen. Ich hab diesen Ansatz ausprobiert, als ich eine Bereitstellungspipeline für ein persönliches Projekt eingerichtet hab. Die Maskierung lief während der Datenextraktion ab und nicht als separater Schritt, was den Arbeitsablauf vereinfachte und ihn besonders gut für CI/CD-Pipelines machte.
Forscher brauchen Zugriff auf Datenmuster, um Trends zu erkennen, Hypothesen zu testen und zuverlässige Modelle zu erstellen, aber beim Austausch von Daten aus der echten Welt besteht oft das Risiko, dass sensible Infos offengelegt werden. Statistische Verschleierung (eine andere Art der Datenmaskierung) ist eine Lösung. Wenn man es richtig macht, bleiben wichtige statistische Eigenschaften wie Mittelwerte, Varianzen und Korrelationen erhalten, während gleichzeitig die einzelnen Datensätze geheim bleiben. So können Analysten aus den Daten sinnvolle Erkenntnisse gewinnen, ohne die Privatsphäre zu verletzen.
Hier hat sich in unserem Projekt die Theorie mit der Praxis getroffen. Jede der Techniken, die ich im nächsten Abschnitt durchgehen werde, hat ein bestimmtes Problem gelöst, mit dem wir konfrontiert waren.
Ersetzen wurde für mich zur Standardmethode für die meisten personenbezogenen Daten. Das Konzept ist einfach: Ersetz sensible Werte durch realistische, aber komplett erfundene Alternativen. Namen werden zu anderen Namen. E-Mail-Adressen werden zu anderen E-Mail-Adressen. Die Ersatzwerte haben das gleiche Format und sehen für jeden, der sich die Daten ansieht, echt aus.
Für unser E-Commerce-Projekt musste ich schnell Kundeninfos maskieren. Ich habe die Faker-Bibliothek entdeckt, die man mit „ pip install Faker “ installieren kann, und eine einfache Maskierungsfunktion erstellt. Faker macht eine Menge realistischer Fake-Daten und ist damit super für Maskierungsoperationen:
from faker import Faker
import pandas as pd
fake = Faker()
def mask_customer_data(customer_df):
masked_df = customer_df.copy()
masked_df['first_name'] = [fake.first_name() for _ in range(len(masked_df))]
masked_df['last_name'] = [fake.last_name() for _ in range(len(masked_df))]
masked_df['email'] = [fake.email() for _ in range(len(masked_df))]
return masked_df
# Example usage
original_customers = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com']
})
masked_customers = mask_customer_data(original_customers)Der obige Code nimmt einen Pandas-DataFrame mit Kundendaten und ersetzt die identifizierenden Infos durch erfundene Alternativen. Die Ausführung auf unserem ursprünglichen Datensatz dauerte etwa zwei Minuten und lieferte uns Hunderte von realistisch aussehenden Kundennamen und E-Mail-Adressen. Die Faker-Bibliothek hat die schwierige Aufgabe übernommen, verschiedene, glaubwürdige Namen und richtig formatierte E-Mail-Adressen zu erstellen. Ich habe auch gelernt, dass die Ergebnisse zufällig generiert wurden und daher nicht direkt wiedererkennbar waren, was ich echt gut fand.
Eine Sache, die ich gelernt habe: Die maskierten Daten müssen echt genug aussehen, damit dein Gehirn sie während der Entwicklung nicht ablehnt. Anfangs habe ich versucht, zufällige Buchstabenkombinationen zu verwenden, aber das Debuggen von Code mit Kunden namens „Xkqp Mmwz” kam mir lächerlich vor und machte es schwieriger, mich auf die eigentlichen logischen Probleme zu konzentrieren. Fake-Namen wie „Jennifer Martinez“ und „Robert Chen“ klangen echt genug, um ernsthaft damit zu arbeiten.
Wenn du mehr über Datenbearbeitung in Python erfahren willst, schau dir unseren Kurs „Einführung in die Datenwissenschaft in Python“ an. Da geht's um grundlegende DataFrame-Operationen, die die Umsetzung dieser und anderer Techniken echt vereinfachen.
Das Mischen hat ein Problem gelöst, das ich anfangs nicht erwartet hatte. Unser Projekt hatte ein Admin-Dashboard, das die durchschnittlichen Kaufbeträge nach Kundendemografie anzeigt. Wir brauchten realistische Kaufbeträge, um zu checken, ob unsere Aggregationsabfragen richtig funktionieren, aber wir brauchten keine bestimmten Kunden, die mit bestimmten Käufen verbunden waren.
Beim Mischen werden die Werte innerhalb einer Spalte zufällig neu sortiert, aber die Gesamtverteilung bleibt gleich:
import numpy as np
import pandas as pd
def shuffle_column(df, column_name):
shuffled_df = df.copy()
shuffled_values = shuffled_df[column_name].values
np.random.seed(42) # For reproducibility
np.random.shuffle(shuffled_values)
shuffled_df[column_name] = shuffled_values
return shuffled_df
# Example with purchase data
purchase_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'product': ['Laptop', 'Headphones', 'Mouse'],
'amount': [1200, 85, 25]
})
shuffled_purchases = shuffle_column(purchase_data, 'amount')Nach dem Mischen waren die Kaufbeträge immer noch im Datensatz (wir konnten immer noch genaue Durchschnittswerte und Verteilungen berechnen), aber die Verbindung zwischen dem Kunden C001 und dem Kauf in Höhe von 1.200 Dollar war nicht mehr da. Kunde C001 könnte jetzt stattdessen einen Kauf im Wert von 25 $ aufweisen.
Die wichtigste Erkenntnis: Durch das Mischen bleiben die statistischen Eigenschaften erhalten, die für die Gesamtanalyse gebraucht werden, während die Verbindungen auf individueller Ebene aufgelöst werden. Das ist super, wenn du Funktionen testest, die mit Aggregaten statt mit einzelnen Datensätzen arbeiten.
Durch Teilmaskierung werden nur die wichtigen Infos angezeigt, während der Rest ausgeblendet wird. Diese Technik kam mir bekannt vor, weil ich sie schon überall gesehen hatte, zum Beispiel auf Websites, die Kreditkartennummern als „ ****-****-****-1234 “ anzeigen, oder in Apps, die Telefonnummern als „ (***) ***-5678 “ zeigen.
Die Umsetzung in unserem Projekt war echt einfach:
def mask_credit_card(card_number):
visible_digits = 4
masked_portion = '*' * (len(card_number) - visible_digits)
return masked_portion + card_number[-visible_digits:]
def mask_phone(phone):
return '***-***-' + phone[-4:]
# Examples
print(mask_credit_card('4532123456781234')) # ************1234
print(mask_phone('555-0123')) # ***-***-0123Wir haben das für die Bestellhistorie benutzt, wo Kunden checken mussten, welche Karte sie für einen Kauf benutzt haben. Die letzten vier Ziffern zu zeigen, reichte aus, um die Nummer zu erkennen, ohne die ganze Nummer preiszugeben. Es fühlte sich an wie die richtige Balance zwischen Nützlichkeit und Privatsphäre.
Manchmal ist es am einfachsten, Daten einfach komplett zu löschen. Nulling ersetzt Feldwerte durch NULL oder leere Zeichenfolgen, wenn die Infos zum Testen nicht gebraucht werden.
def null_fields(df, fields_to_null):
masked_df = df.copy()
for field in fields_to_null:
masked_df[field] = None
return masked_dfUnsere Kundendaten hatten ein Feld „Notizen”, wo hypothetische Kundendienstmitarbeiter interne Kommentare schreiben konnten. Dieses Feld war für das Testen der Warenkorb-Logik oder der Zahlungsabwicklung nicht wichtig, also hab ich es einfach auf Null gesetzt. Warum sollten wir uns die Mühe machen, gefälschte Notizen zu erstellen, wenn wir das Feld einfach aus unseren Testdaten löschen könnten?
Das hat mir eine wichtige Lektion über Maskierung beigebracht: Mach die Dinge nicht zu kompliziert. Versteck, was versteckt werden muss, und schmeiß weg, was überhaupt nicht gebraucht wird.
Die Randomisierung macht komplett neue Werte für Felder, bei denen es keinen Sinn macht, irgendeine Verbindung zu den Originaldaten zu behalten. Das hat bei Identifikatoren und Referenznummern gut geklappt:
import random
import string
def randomize_order_id():
return 'ORD-' + ''.join(random.choices(string.ascii_uppercase + string.digits, k=8))
order_ids = [randomize_order_id() for _ in range(5)]
print(order_ids)Unsere Bestell-IDs mussten nicht mit irgendwas aus dem ursprünglichen Datensatz übereinstimmen. Sie mussten einfach nur echt aussehen und einzigartig sein. Die zufällige Generierung hat beide Anforderungen erfüllt. Jede generierte ID wie „ORD-K7M2N9P4” sah aus wie eine echte Bestellnummer, hatte aber nichts mit einer echten Bestellung zu tun.
Bei der Tokenisierung werden sensible Werte durch zufällig generierte Tokens ersetzt, während die Originaldaten sicher in einem separaten, hochgeschützten System gespeichert werden. Anders als andere Maskierungstechniken ist die Tokenisierung so gemacht, dass sie rückgängig gemacht werden kann, aber nur mit kontrolliertem Zugriff. Ich hab von diesem Ansatz erfahren, als ich mich mit den Anforderungen für die Zahlungsabwicklung beschäftigt hab:
import uuid
# Note: Production token vaults use encrypted database storage, not in-memory dicts
class TokenVault:
def __init__(self):
self.token_map = {}
self.reverse_map = {}
def tokenize(self, sensitive_value):
if sensitive_value in self.token_map:
return self.token_map[sensitive_value]
token = str(uuid.uuid4())
self.token_map[sensitive_value] = token
self.reverse_map[token] = sensitive_value
return token
def detokenize(self, token):
return self.reverse_map.get(token)
vault = TokenVault()
token = vault.tokenize('4532-1234-5678-9012')
print(f"Token: {token}")
original = vault.detokenize(token)
print(f"Original: {original}")Wir haben in unserem Klassenprojekt keine Tokenisierung gemacht, weil wir keine Umkehrbarkeit brauchten. Aber als ich über Zahlungssysteme gelesen habe, wurde mir der Anwendungsfall klar: Deine Anwendungsdatenbank speichert nur die Tokens (nutzlose Zufallszeichenfolgen), während die tatsächlichen Zahlungsdetails in einem komplett separaten, hochsicheren Token-Tresor gespeichert werden. Wenn deine Anwendungsdatenbank gehackt wird, kriegt der Angreifer nur nutzlose Tokens, mit denen er nicht an die echten Kreditkartennummern kommt, ohne den Tresor selbst zu knacken. Diese architektonische Trennung macht die Tokenisierung besonders wichtig für die Einhaltung von Vorschriften bei der Zahlungsabwicklung.
Kryptografische Techniken wandeln Daten mithilfe von mathematischen Algorithmen um. Ich hab's geschafft, Hashing für unsere Passwortspeicherung einzurichten, nachdem unser Professor gesagt hat, dass man Passwörter niemals im Klartext speichern soll. Für Produktionssysteme solltest du bcrypt oder Argon2 verwenden, die Salts enthalten und so konzipiert sind, dass sie rechenintensiv sind, um Brute-Force-Angriffen standzuhalten. Ich zeige hier bcrypt, obwohl Argon2 auch super für die Produktion ist:
import bcrypt
def hash_password(password):
# Generate a salt and hash the password
salt = bcrypt.gensalt()
hashed = bcrypt.hashpw(password.encode(), salt)
return hashed
def verify_password(password, hashed):
# Verify a password against its hash
return bcrypt.checkpw(password.encode(), hashed)
# Store the hash, never the actual password
password = 'user_password_123'
password_hash = hash_password(password)
print(f"Stored hash: {password_hash}")
# Output: Stored hash: b'$2b$12$K7g.../XYZ' (different each time due to random salt)
# Verify during login
is_valid = verify_password('user_password_123', password_hash)
print(f"Password valid: {is_valid}") # Output: Password valid: TrueHashing macht Einweg-Transformationen, die man gut zur Überprüfung nutzen kann. Als ich das zum ersten Mal ausprobiert habe, war ich echt überrascht, dass bcrypt wegen dem zufälligen Salt jedes Mal einen anderen Hash generiert, aber verify_password() trotzdem immer noch das richtige Passwort findet. Das Salz sorgt dafür, dass selbst gleiche Passwörter unterschiedliche Hashes erzeugen, was vor Rainbow-Table-Angriffen schützt. Beim Einloggen verschlüsseln wir das eingegebene Passwort und nutzen die Verifizierungsfunktion von bcrypt, um es sicher zu vergleichen. Das heißt, dass selbst Entwickler mit Datenbankzugriff die Passwörter der Benutzer nicht sehen können.
Anmerkung: Du musst bcrypt mit „ pip install bcrypt ” installieren, um dieses Beispiel nutzen zu können.
Verschlüsselung ist anders als Hashing, weil man mit Schlüsseln die Daten wieder in ihre ursprüngliche Form zurückverwandeln kann. Wir haben für unser Projekt keine Verschlüsselung gebraucht, aber ich verstehe, wozu sie da ist: Benutz das, wenn bestimmte Leute Zugriff auf echte Daten brauchen, du die aber vor unbefugtem Zugriff schützen willst.
Diese Techniken unterscheiden sich in ihrer Umkehrbarkeit. Pseudonymisierung ersetzt identifizierbare Infos, aber man kann die Leute trotzdem wiedererkennen, wenn es nötig ist. Durch die Anonymisierung werden alle identifizierbaren Infos komplett entfernt, sodass eine erneute Identifizierung unmöglich ist.
def pseudonymize_data(df, id_column, key_mapping=None):
if key_mapping is None:
key_mapping = {}
pseudo_df = df.copy()
for idx, original_id in enumerate(pseudo_df[id_column].unique()):
if original_id not in key_mapping:
key_mapping[original_id] = f"PSEUDO_{idx:06d}"
pseudo_df.loc[pseudo_df[id_column] == original_id, id_column] = key_mapping[original_id]
return pseudo_df, key_mapping
# Using pseudonymization
customer_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C001'],
'purchase': ['Laptop', 'Mouse', 'Keyboard']
})
pseudonymized_data, mapping = pseudonymize_data(customer_data, 'customer_id')Bei unserem Projekt haben wir Pseudonymisierung genutzt, um die Kundenkonsistenz über mehrere Käufe hinweg zu gewährleisten und gleichzeitig die tatsächlichen Kundenidentifikatoren zu verbergen. Die drei Einkäufe von Kunde C001 wurden alle demselben Pseudonym zugeordnet, sodass das Verhalten einzelner Kunden analysiert werden kann, ohne dass ihre echten Identitäten preisgegeben werden.
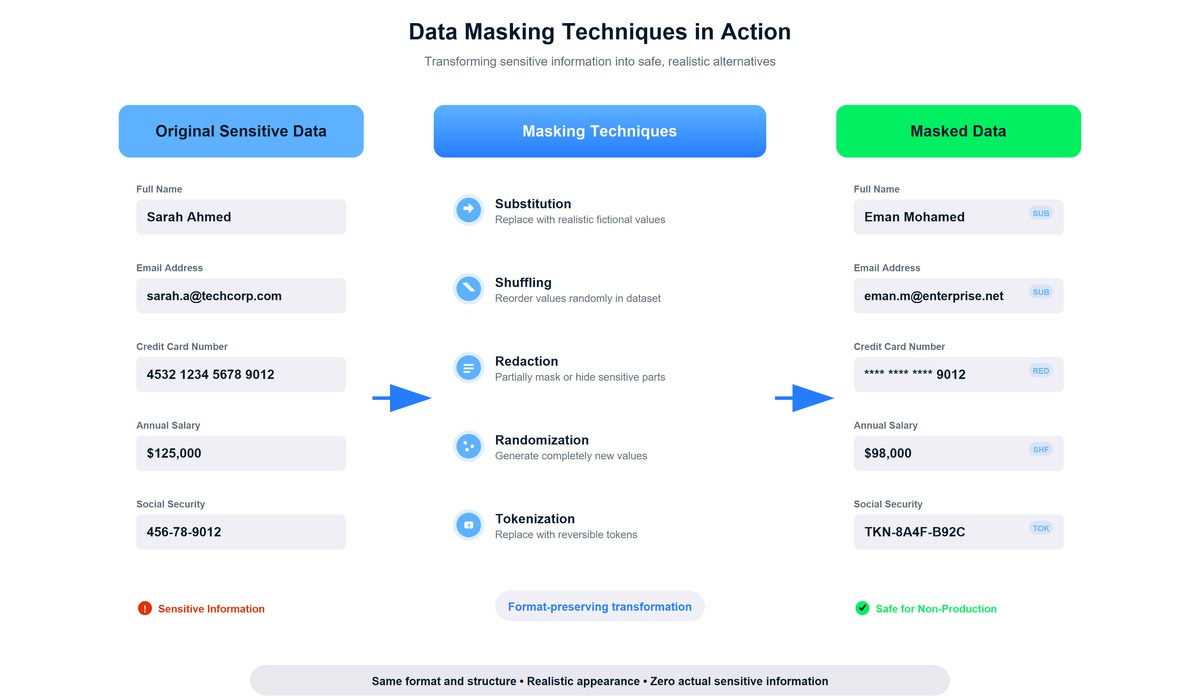
Verschiedene Maskierungstechniken wandeln sensible Daten um, ohne das Format und die Benutzerfreundlichkeit zu beeinträchtigen.
Anfangs habe ich Datenmaskierung mit Verschlüsselung und Anonymisierung verwechselt, weil es bei allen darum geht, sensible Infos zu schützen. Das Verständnis der Unterschiede hat mir geholfen, die richtigen Techniken für verschiedene Situationen auszuwählen. Ich erkläre dir mal die wichtigsten Unterschiede, damit du besser verstehst, wann man welchen Ansatz nimmt.
|
Ansatz |
Wie es funktioniert |
Umkehrbarkeit |
Bester Anwendungsfall |
|
Datenmaskierung |
Ersetzt sensible Daten durch erfundene, aber realistisch klingende Werte |
Irreversibel (keine Wiederherstellung ohne Quelldatenbank) |
Entwicklungs-, Test- und Analyseumgebungen, wo man eine realistische Datenstruktur braucht, aber keine echten Werte |
|
Verschlüsselung |
Verschlüsselt Daten mit mathematischen Algorithmen |
Mit Entschlüsselungsschlüsseln umkehrbar |
Schutz von Daten während der Übertragung oder Speicherung, wenn autorisierte Benutzer auf Originalwerte zugreifen müssen |
|
Anonymisierung |
Entfernt oder verallgemeinert identifizierende Infos |
Irreversibel (soll eine erneute Identifizierung verhindern) |
Veröffentlichung von Datensätzen für Forschungszwecke oder zur öffentlichen Nutzung unter Wahrung der Privatsphäre |
|
Synthetische Daten |
Erzeugt komplett künstliche Datensätze mit statistischen Modellen oder ML |
N/A (keine Originaldaten, auf die man zurückgreifen könnte) |
Das Trainieren von Modellen für maschinelles Lernen oder Situationen, in denen selbst maskierte echte Daten zu riskant sind |
Während unserer Einheit zur Datenbanksicherheit habe ich den Unterschied zwischen Verschlüsselung und Maskierung klar erkannt. Wir haben die Datenbank-Backups verschlüsselt, damit sie bei einem Diebstahl nutzlos sind, aber die Entwicklungsdatenbank haben wir maskiert, weil die Entwickler mit den Daten arbeiten mussten, nur eben nicht mit echten Kundendaten. Wie ich schon gesagt habe, schützt die Verschlüsselung Daten, die du irgendwann wieder entschlüsseln wirst, während die Maskierung dauerhaft sichere Alternativen schafft.
Der Unterschied zwischen Maskierung und Anonymisierung zeigt, dass man unterschiedliche Ziele verfolgt. Bei der Anonymisierung geht's vor allem darum, erkennbare Infos zu entfernen, damit man Personen nicht wiederfindet. Dazu werden Techniken wie Verallgemeinerung (genaues Alter wird durch Altersspannen ersetzt) und Unterdrückung (erkennbare Attribute werden komplett entfernt) genutzt. Die Maskierung konzentriert sich darauf, die Daten für Entwicklung, Tests und Analysen nutzbar zu halten.
Ein Klassenkamerad, der an einem Projekt zum maschinellen Lernen arbeitet, hat synthetische Daten benutzt, die aus Mustern in einem echten Datensatz gemacht wurden. Die synthetischen Daten hatten keine echten Datensätze, sondern ahmten die statistischen Eigenschaften nach, die man für das Modelltraining braucht. Ich habe mich bei unserem Projekt für Maskierung statt für synthetische Daten entschieden, weil wir bestimmte Szenarien testen mussten, wie zum Beispiel den Umgang mit doppelten E-Mail-Adressen oder die Verarbeitung internationaler Adressen. Synthetische Daten erfassen diese Randfälle möglicherweise nicht, während maskierte reale Daten sie beibehalten haben.
Durch die Implementierung von Maskierung habe ich gelernt, dass man beim Schutz sensibler Daten und der gleichzeitigen Aufrechterhaltung der Datennutzbarkeit Herausforderungen meistern muss, die erst dann offensichtlich werden, wenn man ihnen begegnet. Ich erzähl dir mal, welche großen Probleme ich hatte und wie ich sie gelöst hab.
Das Erhalten der Eigenschaften war schwieriger als gedacht. Wenn du Werte einfach nach dem Zufallsprinzip ersetzt, zerstörst du Muster, auf die Anwendungen angewiesen sind. Kreditkartennummern werden nach dem Luhn-Algorithmus auf ihre Prüfsumme überprüft, E-Mail-Adressen brauchen richtig formatierte Domains und Postleitzahlen müssen zu den richtigen Regionen passen. Ich hab das auf die harte Tour gelernt, als mein erster Versuch, Daten zu maskieren, zufällige 16-stellige Zahlen für Kreditkartenfelder erzeugt hat. Alles sah gut aus, bis die Tests zeigten, dass unsere Zahlungsvalidierungslogik jede einzelne Kartennummer abgelehnt hat, weil ich vergessen hatte, dass Kreditkartennummern Prüfziffern enthalten, die mit dem Luhn-Algorithmus berechnet werden.
Semantische Integrität ist wichtiger als nur das Format. Verschleierte Daten sollten offensichtlich unsinnige Kombinationen vermeiden. Während der Tests hat ein Teammitglied gemerkt, dass in unserem maskierten Datensatz Postleitzahlen aus Alaska zu Straßenadressen in Florida zugeordnet waren. Obwohl die Formate technisch gesehen okay waren, kam mir die geografische Diskrepanz komisch vor. Ich habe einen Nachmittag damit verbracht, die semantische Konsistenz zu verbessern, indem ich vollständige Adressen erstellt habe, bei denen alle Teile geografisch zusammenpassen, anstatt Adressbestandteile einfach nur wahllos zu kombinieren.
Die referenzielle Integrität über Tabellen hinweg hat zu erheblicher Komplexität geführt. Wie ich im Abschnitt „Techniken“ erklärt habe, hatte unsere Datenbank Tabellen für Kunden, Bestellungen und Bewertungen, wobei die Kunden-IDs in allen drei Tabellen vorkamen. Wenn die Maskierung die Kunden-IDs nicht einheitlich geändert hat, sind diese Beziehungen komplett kaputt gegangen. Das ist mir nach meinem ersten Versuch mit Maskierung passiert: 30 % unserer Integrationstests sind schiefgegangen, weil Kundenbestellungen nicht mehr mit den Kundendatensätzen verknüpft waren. Der Durchbruch kam, als mir klar wurde, dass ich Tabellen in Abhängigkeitsreihenfolge mit deterministischer Maskierung bearbeiten musste, um sicherzustellen, dass der Kunde C001 überall, wo er auftauchte, immer die gleiche maskierte ID bekam.
Sicherheit und analytischen Wert unter einen Hut zu bringen, braucht echt viel Erfahrung. Aggressiveres Maskieren sorgt für mehr Privatsphäre, macht das Ding aber weniger nützlich. Wenn man zum Beispiel alle Altersangaben auf die nächsten zehn Jahre rundet, schützt das zwar die Privatsphäre, macht aber nützliche Analysen nach Alter unmöglich. Bei unserem Projekt war die Nützlichkeit wichtig, weil wir App-Funktionen entwickelt haben, die echtes Datenverhalten brauchen. In einer echten Produktionsumgebung mit echten Kundendaten und Compliance-Verpflichtungen müsste ich den Datenschutz stärker berücksichtigen und möglicherweise eine geringere Datennutzbarkeit in Kauf nehmen.
Statistische Zusammenhänge können verzerrt werden. Wenn du zwei miteinander verbundene Spalten hast, wie zum Beispiel Einkommen und Ausgaben, und du jede Spalte für sich durcheinanderwirbelst, wird sich die Verbindung wahrscheinlich ändern. Aus statistischer Sicht verändert unabhängiges Scrambling die gemeinsame Verteilung der Variablen. Um diese Beziehung zu behalten, nehmen Analysten manchmal Rang-erhaltende Transformationen vor, wie zum Beispiel das Mischen beider Spalten mit derselben zufälligen Permutation oder das Hinzufügen von kontrolliertem Rauschen, das ihre gemeinsame Reihenfolge beibehält.
Nachdem ich diese einzelnen Techniken gelernt hatte, wollte ich sehen, wie sie in einem echten Szenario zusammen funktionieren. Hier ist ein komplettes Beispiel, das zeigt, wie man eine Kundendatenbank mit den dazugehörigen Bestellungen maskiert – genau die Herausforderung, mit der wir in unserem E-Commerce-Projekt konfrontiert waren.
from faker import Faker
import pandas as pd
import numpy as np
import uuid
fake = Faker()
Faker.seed(42) # For reproducible results
# Original datasets (simulating real customer data)
customers_original = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com'],
'phone': ['555-0123', '555-0124', '555-0125'],
'credit_card': ['4532-1234-5678-9012', '4556-7890-1234-5678', '4539-8765-4321-0987'],
'internal_notes': ['VIP customer', 'Requested callback', 'Payment issue resolved']
})
orders_original = pd.DataFrame({
'order_id': ['ORD001', 'ORD002', 'ORD003', 'ORD004'],
'customer_id': ['C001', 'C002', 'C001', 'C003'],
'product': ['Laptop', 'Mouse', 'Keyboard', 'Monitor'],
'amount': [1299.99, 29.99, 89.99, 399.99]
})
# Step 1: Create deterministic ID mapping to maintain referential integrity
def create_id_mapping(ids):
"""Create consistent pseudonymous IDs"""
mapping = {}
for idx, original_id in enumerate(ids):
mapping[original_id] = f"CUST_{idx:06d}"
return mapping
customer_id_mapping = create_id_mapping(customers_original['customer_id'].unique())
# Step 2: Mask customer data using multiple techniques
def mask_customer_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Replace customer IDs consistently
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Substitution: Replace names and emails with realistic fake data
masked['first_name'] = [fake.first_name() for _ in range(len(masked))]
masked['last_name'] = [fake.last_name() for _ in range(len(masked))]
masked['email'] = [fake.email() for _ in range(len(masked))]
# Partial masking/redaction: Show last 4 digits of phone and credit card
masked['phone'] = masked['phone'].apply(lambda x: '***-' + x[-4:])
masked['credit_card'] = masked['credit_card'].apply(lambda x: '****-****-****-' + x[-4:])
# Nulling: Remove internal notes entirely
masked['internal_notes'] = None
return masked
# Step 3: Mask order data with referential integrity
def mask_order_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Use same customer ID mapping to maintain relationships
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Randomization: Generate new order IDs
masked['order_id'] = [f"ORD-{uuid.uuid4().hex[:8].upper()}" for _ in range(len(masked))]
# Shuffling: Preserve amount distribution but break individual associations
shuffled_amounts = masked['amount'].values.copy()
np.random.shuffle(shuffled_amounts)
masked['amount'] = shuffled_amounts
return masked
# Apply masking
customers_masked = mask_customer_database(customers_original, customer_id_mapping)
orders_masked = mask_order_database(orders_original, customer_id_mapping)
print("=== MASKED CUSTOMER DATA ===")
print(customers_masked)
print("\n=== MASKED ORDER DATA ===")
print(orders_masked)
# Verify referential integrity is maintained
print("\n=== VERIFICATION: JOIN STILL WORKS ===")
joined = customers_masked.merge(orders_masked, on='customer_id')
print(f"Original orders: {len(orders_original)}, Joined orders: {len(joined)}")
print("✓ All order-customer relationships preserved!")Als ich diese komplette Maskierungspipeline auf unsere Projektdaten (500 Kundendatensätze mit 1.200 Bestellungen) angewandt habe, hat die Ausführung etwa 2 Sekunden gedauert, was für unseren wöchentlichen Aktualisierungszyklus der Entwicklungsdatenbank völlig okay war. Ein paar Sachen haben sich geklärt:
Die Referenzintegrität hat super funktioniert. Die Kunden- CUST_000000 -Datenbank (ursprünglich C001) hatte Einträge sowohl in der Kundentabelle als auch in der Auftragstabelle. Die Abfragen „ JOIN “, die unsere Bestellhistorie-Funktion unterstützen, funktionierten mit maskierten Daten genauso, weil wir für beide Tabellen denselben „ customer_id_mapping “ verwendet haben .
Jede Technik hatte ihren eigenen Zweck. Durch die Ersetzung sahen die Kundennamen echt aus. Durch die teilweise Maskierung können wir Zahlungsmethoden überprüfen, ohne die kompletten Kartennummern anzuzeigen. Durch das Mischen konnten wir die Genauigkeit unserer Analyse-Dashboards bei der Darstellung der Umsatzverteilung beibehalten und gleichzeitig die Beträge bestimmter Kunden trennen. Durch das Löschen haben wir Daten entfernt, die wir für die Tests nicht brauchten.
Die Ausgabe sah aus und funktionierte wie echte Daten. Als ich während der Entwicklung die maskierte Datenbank durchstöberte, kam mir alles echt vor. Die E-Mail-Adressen wurden erfolgreich überprüft. Die Telefonnummern werden richtig angezeigt. Die Daten haben nicht direkt „Das ist gefälscht“ geschrien, sodass ich mich auf die Fehlerbehebung in der Anwendungslogik konzentrieren konnte, anstatt mich von offensichtlich künstlichen Testdaten ablenken zu lassen.
Die Datenqualität blieb auf hohem Niveau. Wir könnten trotzdem noch Randfälle wie Kunden mit mehreren Bestellungen testen, Gesamtstatistiken berechnen und Datenbankbeschränkungen überprüfen. Die Maskierung hat die Komplexität und die Beziehungen, die wir brauchten, beibehalten und gleichzeitig alle sensiblen Infos geschützt.
Dieser Ansatz hat ein Problem, das zuerst echt schwierig aussah, nämlich eine sichere, aber realistische Testdatenbank zu erstellen, in einen systematischen, reproduzierbaren Prozess verwandelt. Jedes Mal, wenn wir unsere Entwicklungsdatenbank aktualisiert haben, hat das Ausführen dieses Maskierungsskripts weniger als eine Minute gedauert und uns die Gewissheit gegeben, dass keine echten Kundendaten durchsickern konnten.
Fang mit einer umfassenden Datenermittlung an. Heikle Infos tauchten an unerwarteten Stellen auf, nicht nur in den offensichtlichen Bereichen wie Namen und E-Mail-Adressen. Unsere Datenbank hatte Felder für Kundenanmerkungen, in denen Freitexteingaben gemacht werden konnten, die möglicherweise persönliche Infos enthielten. Ich habe gelernt, jeden Bereich systematisch zu überprüfen, nicht nur die offensichtlich sensiblen. In Produktionssystemen nutzen Unternehmen automatisierte Tools zur Datenerkennung, die nach Mustern suchen, die mit personenbezogenen Daten übereinstimmen.
Leg frühzeitig klare Regeln für die Maskierung fest. Verschiedene Teammitglieder haben am Anfang eigenständig entschieden, was sie maskieren, was zu Unstimmigkeiten geführt hat. Eine Person hat die Telefonnummern komplett maskiert, eine andere hat sie teilweise maskiert und eine dritte hat sie einfach so gelassen, wie sie waren. Wir haben unseren Ansatz schließlich standardisiert: vollständige Maskierung für Namen und E-Mail-Adressen, teilweise Maskierung für Telefonnummern und Karten und Nullung für interne Notizen. Die dokumentierten Richtlinien sagen, welche Datenelemente maskiert werden müssen, welche Techniken für verschiedene Typen gelten und wie man mit Sonderfällen umgeht.
Verwende Algorithmen, die das Format beibehalten. Anstatt Daten durch zufällige Werte zu ersetzen, machen diese Algorithmen realistische Ersetzungen, die die gleichen Validierungsregeln wie die Originaldaten erfüllen. Wie ich schon gezeigt habe, musste meine Kreditkartenmaskierung Zahlen erzeugen, die die Luhn-Validierung bestehen, und die E-Mail-Maskierung brauchte richtig formatierte Adressen mit gültigen Domain-Mustern.
Die Maskierungsqualität muss streng geprüft werden. Ich hab einfache Tests geschrieben, um die Qualität der maskierten Daten zu checken, bevor wir sie für die Entwicklung benutzt haben. Diese Tests haben überprüft, ob maskierte E-Mail-Adressen die Regex-Validierung bestehen, Kunden-IDs nach dem Maskieren einzigartig bleiben, Fremdschlüsselbeziehungen gültig bleiben und der maskierte Datensatz genauso groß ist wie der ursprüngliche. Diese Tests haben Probleme wie doppelte Datensätze und Referenzintegritätsverletzungen aufgedeckt, bevor wir bei den Anwendungstests drauf gestoßen sind.
Den ganzen Prozess automatisieren. Bei meinem ersten Versuch, etwas zu maskieren, musste ich Python-Skripte manuell ausführen und Dateien kopieren, was schnell nervig wurde. Schließlich habe ich ein einziges Skript erstellt, das den ganzen Prozess abdeckt: Originaldaten lesen, alle Maskierungstransformationen anwenden, Ergebnisse überprüfen und maskierte Ausgabe schreiben. Bei echten Projekten mit kontinuierlichen Integrationspipelines würde das Maskieren als automatischer Schritt eingebaut werden, sodass Entwickler gar nicht mehr darüber nachdenken müssten.
Sicher, dass es nicht rückgängig gemacht werden kann und immer wieder funktioniert. Der Maskierungsprozess sollte nicht rückgängig gemacht werden können, damit er wirklich schützt, aber man sollte ihn wiederholen können, wenn man Testdatenbanken mit konsistenten Ergebnissen aktualisieren muss. Wie ich im vollständigen Beispiel gezeigt habe, sorgt die Verwendung deterministischer Techniken mit konsistenten Startwerten für dieses Gleichgewicht.
Die Datenmaskierung entwickelt sich dank künstlicher Intelligenz und maschinellem Lernen ziemlich schnell weiter. Während wir in unserem Klassenprojekt traditionelle Maskierungstechniken benutzt haben, setzen moderne Lösungen immer öfter KI ein, um den Maskierungsprozess zu automatisieren und zu verbessern.
Am spannendsten finde ich die automatische Datenerkennung. Ich habe stundenlang unser Datenbankschema durchgesehen, um herauszufinden, welche Felder sensible Infos enthalten. Stell dir ein Tool vor, das sensible Felder automatisch erkennt, indem es Muster, Spaltennamen und Werteverteilungen analysiert, anstatt dass du das manuell machen musst. Ein ML-System könnte erkennen, dass eine Spalte mit dem komischen Namen „user_identifier“ eigentlich E-Mail-Adressen enthält, was ich bei einer manuellen Überprüfung leicht übersehen könnte. Das hätte mir echt viel Zeit gespart.
Ich hab auchüber Techniken zum maschinellen Lernen gelesen,die die Privatsphäre schützen und über das normale Maskieren hinausgehen. Differential Privacy fügt zum Beispiel Trainingsdaten oder Modellausgaben sorgfältig abgestimmtes mathematisches Rauschen hinzu. Beim föderierten Lernen werden Modelle über verteilte Datensätze hinweg trainiert, ohne dass sensible Infos zentralisiert werden. Diese Ansätze sind für Fälle gedacht, in denen Standardmaskierungen Muster entfernen könnten, von denen Modelle lernen müssen.
Die Erzeugung synthetischer Daten mithilfe generativer KI finde ich für zukünftige Projekte besonders spannend. Anstatt echte Datensätze zu verschleiern, erstellen KI-Systeme, die mit echten Datenmustern trainiert wurden, komplett künstliche Datensätze. Ich hab das selbst noch nicht ausprobiert, aber ich verstehe, warum das für Fälle interessant ist, wo man riesige Trainingsdatensätze braucht oder wo selbst maskierte echte Daten riskant sind. Die Herausforderung wäre, sicherzustellen, dass die synthetischen Daten die Randfälle und die Komplexität genau abbilden, die die maskierten echten Daten für unsere Tests so wertvoll gemacht haben.
Wenn man sich anschaut, wie sich das Feld entwickelt, werden Cloud-native Entwicklungsabläufe langsam automatisierte Maskierung als Standardinfrastruktur einbauen. Anstatt das Maskieren manuell mit Python-Skripten zu machen, könnten Deployment-Pipelines das beim Einrichten von Entwicklungsdatenbanken automatisch übernehmen. Entwickler würden die Maskierungsanforderungen in Konfigurationsdateien zusammen mit den Datenbankschemata festlegen. Genau diese Art von Automatisierung würde ich gerne in zukünftigen Projekten umsetzen, um das Maskieren von einem manuellen Vorverarbeitungsschritt zu einem automatischen Infrastrukturverhalten zu machen.
Allerdings ist KI in Sachen Datenschutz ein zweischneidiges Schwert. Es verbessert zwar die Maskierungstechniken, macht aber auch Re-Identifizierungsangriffe raffinierter. Machine-Learning-Modelle können scheinbar anonymisierte Daten mit öffentlichen Infos abgleichen, um Personen wieder zu identifizieren. Forscher haben Leute in „anonymisierten“ Netflix-Daten wiedererkannt, indem sie die Daten mit IMDb-Bewertungen abgeglichen haben. Je smarter die Maskierungswerkzeuge werden, desto smarter werden auch die Methoden, um sie zu knacken.
Datenmaskierung schafft die perfekte Balance zwischen Datennutzung und Datenschutz. Mit den richtigen Techniken wie Substitution, deterministischer Maskierung und formatbewahrenden Methoden kannst du realistische Daten behalten und gleichzeitig sensible Infos schützen.
Fang damit an, deine wichtigsten Datensätze zu identifizieren, und wende die Maskierung in Nicht-Produktionsumgebungen an. Automatisiere frühzeitig, damit Datenschutz ein fester Teil deines Arbeitsablaufs wird.
Um deine Kenntnisse zu vertiefen, schau dir doch mal unsere Kurse „Datenschutz und Anonymisierung in Python“ oder „Data Engineering für alle“ an.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Tutorial
Laiba Siddiqui
Tutorial
Javier Canales Luna


