Curso
Introdução à Engenharia de Dados
2 h
355.8K
No semestre passado, minha aula de sistemas de banco de dados deu um projeto final que parecia simples no começo: criar um aplicativo de comércio eletrônico que funcionasse, com autenticação de usuário, carrinhos de compras e processamento de pedidos. O problema? Tivemos que mostrar que funcionava com padrões de dados reais, não só com três usuários de teste chamados “Ali”, “Shahd” e “Khalid”.
Minha equipe teve que lidar com um problema bem urgente. Precisávamos de centenas de registros de clientes com históricos de compra variados para testar casos extremos, como pedidos em massa, reembolsos e gerenciamento de estoque. Não podíamos pegar dados reais de sites que já existiam; isso é antiético e ilegal. Criar centenas de registros realistas manualmente levaria uma eternidade. Foi aí que nosso professor nos apresentou o mascaramento de dados.
Neste artigo, vou compartilhar o que aprendi com minhas próprias experiências na implementação de técnicas de mascaramento de dados. Você vai descobrir o que é o mascaramento de dados, quando e por que ele é importante e como usar técnicas específicas para proteger informações confidenciais sem perder a utilidade dos dados. Vou mostrar exemplos práticos do meu projeto e como evitar os erros que cometi ao longo do caminho.
Quando ouvi pela primeira vez o termo “mascaramento de dados”, imaginei algo como a edição de textos em documentos governamentais, apenas ocultando partes confidenciais. A realidade é mais sofisticada e útil. O mascaramento de dados cria versões estruturalmente semelhantes, mas factualmente falsas, de dados confidenciais.
O processo técnico envolve substituir os valores dos dados originais por alternativas fictícias que mantêm o formato, o tipo e as propriedades estatísticas. Para o nosso projeto de comércio eletrônico, pegamos um pequeno conjunto de dados com informações reais de clientes de uma ferramenta de geração de dados e usamos técnicas de mascaramento para criar variações. Um e-mail como khalid.abdelaty@company.com passou a ser ahmed.j@enterprise.com. Os dois são formatos de e-mail válidos que passam nas verificações de validação, mas a versão mascarada não revela nada sobre pessoas reais.
Você vai encontrar esse conceito com nomes diferentes, dependendo de quem estiver falando sobre ele. A ofuscação de dados dá ênfase à parte de esconder as coisas. Pseudonimização é quando a gente substitui informações que podem identificar alguém, mas ainda dá pra identificar os dados de novo, se precisar. A tokenização envolve substituir valores confidenciais por tokens gerados aleatoriamente. Esses termos se sobrepõem bastante e, pelo que vi em documentos e tutoriais, as pessoas costumam usá-los meio que de forma intercambiável.
Neste momento, você pode estar se perguntando se esses novos e-mails ou IDs são derivados dos dados originais de alguma forma. Resposta curta: depende da técnica de máscara. Deixei mais informações sobre isso nas perguntas frequentes.
A importância disso ficou clara quando nosso professor mostrou que nosso “projeto de aula” refletia os desafios reais da produção. As empresas precisam testar o software com dados parecidos com os da produção, e os analistas precisam criar modelos com padrões realistas. Mas usar dados reais de clientes nesses ambientes cria sérios problemas.
A conformidade regulatória é uma das principais preocupações da maioria das organizações. O GDPR, o regulamento europeu sobre privacidade, exige que as organizações minimizem o processamento de dados e protejam as informações pessoais por meio de medidas técnicas adequadas. A HIPAA exige que os prestadores de serviços de saúde protejam as informações dos pacientes, mesmo em ambientes de teste. A Lei de Privacidade do Consumidor da Califórnia oferece proteções parecidas para quem mora lá. Do ponto de vista comercial, violar essas regulamentações significa multas pesadas. Do ponto de vista ético, as pessoas esperam que seus dados sejam protegidos.
O mascaramento de dados também traz benefícios importantes de segurança. Cada ambiente extra que guarda dados reais aumenta a área de ataque. Os servidores de desenvolvimento geralmente têm controles de segurança mais fracos do que os sistemas de produção, e os desenvolvedores muitas vezes trabalham com dados em máquinas locais que podem não estar criptografados. Cada cenário traz riscos de violação que o mascaramento de dados elimina, garantindo que os ambientes que não são de produção nunca tenham informações reais.
O que mais me surpreendeu foi descobrir os benefícios práticos para o desenvolvimento. Nosso teste de controle de qualidade encontrou bugs que nunca teríamos descoberto com nosso conjunto de dados de teste original de três usuários. O código de um membro da equipe deu problema ao processar nomes com apóstrofos, como “O'Brien”. Outro problema é com endereços de e-mail que usam aliases com sinal de mais, tipo “usuário+tag@domain.com."”; Esses casos extremos só apareceram porque nosso conjunto de dados mascarados, que veio de padrões realistas, tinha a complexidade que os dados de produção reais teriam.
Entender quando o mascaramento se aplica me ajudou a reconhecê-lo em diferentes contextos. O cenário mais óbvio reflete o nosso projeto de aula: desenvolvimento e teste de software. Quando estão criando novos recursos ou depurando código já existente, os desenvolvedores precisam de dados que mostrem a complexidade do mundo real. Passei horas tentando descobrir por que o cálculo do nosso carrinho de compras não funcionava direito com certas combinações de produtos. O bug só apareceu porque nosso conjunto de dados mascarado tinha casos extremos, tipo itens de zero real e limites de quantidade.
A análise de dados e os projetos de pesquisa geralmente precisam de grandes conjuntos de dados com propriedades estatísticas realistas. Um colega de equipe que estava trabalhando em um projeto de análise separado precisava dos padrões de compra dos clientes para criar algoritmos de recomendação. Ela não precisava dos nomes ou endereços reais dos clientes, só dos padrões de comportamento. Os dados mascarados forneceram esses padrões, ao mesmo tempo que protegeram a privacidade.
A colaboração externa é outro caso de uso comum. As empresas costumam contratar consultores ou prestadores de serviços para projetos de integração que precisam de dados reais, mas não devem ter acesso a informações confidenciais dos clientes. A formação dos funcionários é outra aplicação prática. Antes de alguém mexer nos sistemas de produção, precisa de ambientes de prática com dados realistas, mas seguros. Como último exemplo, o desenvolvimento em nuvem também se beneficia do mascaramento, embora os principais provedores de nuvem ofereçam suas próprias ferramentas de mascaramento como parte de seus serviços de segurança.
O mascaramento de dados atende a várias necessidades organizacionais, desde o desenvolvimento até a conformidade.
Antes de mergulhar nas técnicas específicas, vale a pena entender os principais tipos de máscara e quando usar cada um deles.
O mascaramento estático funciona em conjuntos de dados armazenados, criando cópias mascaradas que são independentes dos dados originais. Foi isso que a gente usou no nosso projeto de comércio eletrônico. Eu rodei um script Python que leu nosso conjunto de dados inicial, aplicou transformações de mascaramento e gravou os resultados em um novo arquivo que todos nós usamos para desenvolvimento. Depois de criado, esse conjunto de dados mascarado ficou estável até precisarmos atualizá-lo com novos padrões. A vantagem ficou clara rapidinho: o impacto no desempenho rolou só uma vez durante o processo de mascaramento, o que é ideal pra ambientes que não são de produção, onde você mascara uma vez e usa a cópia várias vezes.
O mascaramento dinâmico rola em tempo real quando os usuários acessam os dados, aplicando transformações com base nas permissões. Eu conheci esse conceito pela primeira vez quando estava lendo sobre recursos de segurança de bancos de dados. Um administrador de sistema vê os registros completos dos clientes, enquanto um representante de suporte vê os números dos cartões de crédito ocultos. Os dados de base continuam os mesmos, mas o que cada usuário vê depende do nível de autorização dele. Essa abordagem é boa para sistemas de produção onde diferentes usuários precisam de diferentes visualizações com base em suas funções.
O mascaramento determinístico garante a consistência, sempre substituindo a mesma entrada pela mesma saída. Se a cliente “Sarah Ali” se tornar “Eman Mohamed” em uma tabela, essa mudança vai valer para todos os lugares onde Sarah Ali aparecer. Como vou explicar na seção de técnicas, essa consistência é super importante para manter as relações entre as tabelas do banco de dados. Nosso projeto precisava de um mascaramento determinístico pra manter os IDs dos clientes consistentes nas tabelas de clientes, pedidos e avaliações.
O mascaramento instantâneo aplica transformações durante a transferência de dados entre ambientes. Experimentei essa abordagem ao configurar um pipeline de implantação para um projeto pessoal. O mascaramento rolou durante a extração de dados, em vez de ser uma etapa separada, o que simplificou o fluxo de trabalho e ficou perfeito para pipelines de CI/CD.
Os pesquisadores precisam acessar padrões de dados para descobrir tendências, testar hipóteses e criar modelos confiáveis, mas compartilhar dados do mundo real muitas vezes traz o risco de expor informações confidenciais. A ofuscação estatística (outra forma de mascaramento de dados) oferece uma solução. Quando feito da maneira certa, ele mantém as propriedades estatísticas essenciais — tipo médias, variações e correlações — e, ao mesmo tempo, mantém os registros individuais em segredo. Isso permite que os analistas tirem conclusões válidas dos dados sem comprometer a privacidade.
Foi aqui que a teoria se encontrou com a prática no nosso projeto. Cada uma das técnicas que vou explicar na próxima seção resolveu um desafio específico que enfrentamos.
A substituição virou minha abordagem padrão para a maioria das informações pessoais identificáveis. O conceito é simples: trocar valores sensíveis por alternativas realistas, mas totalmente inventadas. Os nomes se transformam em nomes diferentes. Os endereços de e-mail mudam para outros endereços de e-mail. Os valores de substituição mantêm o mesmo formato e parecem genuínos para qualquer pessoa que analise os dados.
Para o nosso projeto de comércio eletrônico, eu precisava ocultar as informações dos clientes rapidinho. Descobri a biblioteca Faker, que pode ser instalada com o comando ` pip install Faker`, e criei uma função simples de mascaramento. O Faker gera uma grande variedade de dados falsos realistas, tornando-o perfeito para operações de mascaramento:
from faker import Faker
import pandas as pd
fake = Faker()
def mask_customer_data(customer_df):
masked_df = customer_df.copy()
masked_df['first_name'] = [fake.first_name() for _ in range(len(masked_df))]
masked_df['last_name'] = [fake.last_name() for _ in range(len(masked_df))]
masked_df['email'] = [fake.email() for _ in range(len(masked_df))]
return masked_df
# Example usage
original_customers = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com']
})
masked_customers = mask_customer_data(original_customers)O código acima pega um DataFrame do pandas com registros de clientes e troca as informações de identificação por alternativas fictícias. Executar isso em nosso conjunto de dados inicial levou talvez dois minutos e nos deu centenas de nomes e endereços de e-mail de clientes com aparência realista. A biblioteca Faker cuidou da complexidade de criar nomes variados e convincentes, além de endereços de e-mail com o formato certo. Também descobri que, como os resultados eram gerados aleatoriamente, eles não eram diretamente reidentificáveis, o que achei ótimo.
Uma coisa que aprendi: Os dados mascarados precisam parecer autênticos o suficiente para que seu cérebro não os rejeite durante o desenvolvimento. No começo, tentei usar combinações aleatórias de letras, mas depurar código com clientes chamados “Xkqp Mmwz” parecia ridículo e tornava mais difícil me concentrar nos problemas lógicos reais. Nomes falsos como “Jennifer Martinez” e “Robert Chen” pareciam naturais o suficiente para serem usados com seriedade.
Para saber mais sobre como mexer com dados no Python, nosso curso Introdução à Ciência de Dados em Python fala sobre as operações básicas do DataFrame, que facilitam muito a implementação dessas e de outras técnicas.
A reorganização resolveu um problema que eu não tinha previsto inicialmente. Nosso projeto incluiu um painel administrativo mostrando os valores médios de compra por perfil demográfico do cliente. Precisávamos de valores de compra realistas para testar se nossas consultas de agregação funcionavam corretamente, mas não precisávamos de clientes específicos ligados a compras específicas.
A reorganização embaralha os valores dentro de uma coluna aleatoriamente, mantendo a distribuição geral:
import numpy as np
import pandas as pd
def shuffle_column(df, column_name):
shuffled_df = df.copy()
shuffled_values = shuffled_df[column_name].values
np.random.seed(42) # For reproducibility
np.random.shuffle(shuffled_values)
shuffled_df[column_name] = shuffled_values
return shuffled_df
# Example with purchase data
purchase_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'product': ['Laptop', 'Headphones', 'Mouse'],
'amount': [1200, 85, 25]
})
shuffled_purchases = shuffle_column(purchase_data, 'amount')Depois de embaralhar, os valores das compras ainda estavam no conjunto de dados (ainda podíamos calcular médias e distribuições precisas), mas a conexão entre o cliente C001 e a compra de $1.200 foi perdida. O cliente C001 agora pode mostrar uma compra de $25.
A ideia principal: A reorganização mantém as propriedades estatísticas necessárias para a análise agregada, ao mesmo tempo que quebra as associações individuais. É perfeito quando você está testando recursos que funcionam com agregados, em vez de registros individuais.
O mascaramento parcial mostra só as informações necessárias e esconde o resto. Essa técnica me parecia familiar porque eu já tinha visto em vários lugares, como sites que mostram números de cartão de crédito como ****-****-****-1234 ou aplicativos que mostram números de telefone como (***) ***-5678.
Implementar isso no nosso projeto foi bem simples:
def mask_credit_card(card_number):
visible_digits = 4
masked_portion = '*' * (len(card_number) - visible_digits)
return masked_portion + card_number[-visible_digits:]
def mask_phone(phone):
return '***-***-' + phone[-4:]
# Examples
print(mask_credit_card('4532123456781234')) # ************1234
print(mask_phone('555-0123')) # ***-***-0123Usamos isso pra visualizar o histórico de pedidos, onde os clientes precisavam conferir qual cartão usaram pra fazer uma compra. Mostrar os últimos quatro dígitos era o suficiente pra reconhecer sem precisar expor o número todo. Parecia o equilíbrio certo entre utilidade e privacidade.
Às vezes, a solução mais simples é simplesmente apagar os dados de vez. A anulação substitui os valores dos campos por NULL ou strings vazias quando as informações não são necessárias para o teste.
def null_fields(df, fields_to_null):
masked_df = df.copy()
for field in fields_to_null:
masked_df[field] = None
return masked_dfOs registros dos nossos clientes tinham um campo de “notas” onde os representantes hipotéticos do atendimento ao cliente podiam escrever comentários internos. Esse campo não era importante pra testar a lógica do carrinho de compras ou o processamento de pagamentos, então eu simplesmente o zerei. Por que se dar ao trabalho de criar notas falsas quando podemos simplesmente tirar o campo dos nossos dados de teste?
Isso me ensinou uma lição importante sobre máscaras: não complique demais as coisas. Esconda o que precisa ser escondido, tire o que não precisa estar aí.
A randomização gera valores totalmente novos para campos onde não faz sentido manter qualquer conexão com os dados originais. Isso funcionou bem para identificadores e números de referência:
import random
import string
def randomize_order_id():
return 'ORD-' + ''.join(random.choices(string.ascii_uppercase + string.digits, k=8))
order_ids = [randomize_order_id() for _ in range(5)]
print(order_ids)Os nossos IDs de pedido não precisavam de corresponder a nada do conjunto de dados original. Eles só precisavam parecer realistas e ser únicos. A geração aleatória atendeu a ambos os requisitos. Cada ID gerado, como “ORD-K7M2N9P4”, parecia uma referência de pedido plausível, sem ligação a nada real.
A tokenização substitui valores confidenciais por tokens gerados aleatoriamente, enquanto armazena os dados originais de forma segura em um sistema separado e altamente protegido. Diferente de outras técnicas de mascaramento, a tokenização foi feita pra ser reversível, mas só com acesso controlado. Eu aprendi sobre essa abordagem enquanto pesquisava os requisitos de processamento de pagamentos:
import uuid
# Note: Production token vaults use encrypted database storage, not in-memory dicts
class TokenVault:
def __init__(self):
self.token_map = {}
self.reverse_map = {}
def tokenize(self, sensitive_value):
if sensitive_value in self.token_map:
return self.token_map[sensitive_value]
token = str(uuid.uuid4())
self.token_map[sensitive_value] = token
self.reverse_map[token] = sensitive_value
return token
def detokenize(self, token):
return self.reverse_map.get(token)
vault = TokenVault()
token = vault.tokenize('4532-1234-5678-9012')
print(f"Token: {token}")
original = vault.detokenize(token)
print(f"Original: {original}")Não implementamos a tokenização no nosso projeto de aula porque não precisávamos de reversibilidade. Mas ler sobre sistemas de pagamento deixou o caso de uso bem claro: O banco de dados do seu aplicativo guarda só os tokens (sequências aleatórias sem utilidade), enquanto os detalhes reais do pagamento ficam num cofre de tokens totalmente separado e super seguro. Se o banco de dados do seu aplicativo for comprometido, o invasor só vai conseguir tokens inúteis, sem ter como acessar os números reais dos cartões de crédito sem invadir o cofre em si. Essa separação arquitetônica é o que torna a tokenização especialmente valiosa para a conformidade do processamento de pagamentos.
As técnicas criptográficas transformam os dados usando algoritmos matemáticos. Eu implementei o hash para o armazenamento de senhas depois que nosso professor insistiu para nunca armazenarmos senhas em texto simples. Para sistemas de produção, você deve usar bcrypt ou Argon2, que têm salts e são feitos pra serem caros em termos de computação, pra resistir a ataques de força bruta. Estou mostrando o bcrypt aqui, embora o Argon2 também seja ótimo para produção:
import bcrypt
def hash_password(password):
# Generate a salt and hash the password
salt = bcrypt.gensalt()
hashed = bcrypt.hashpw(password.encode(), salt)
return hashed
def verify_password(password, hashed):
# Verify a password against its hash
return bcrypt.checkpw(password.encode(), hashed)
# Store the hash, never the actual password
password = 'user_password_123'
password_hash = hash_password(password)
print(f"Stored hash: {password_hash}")
# Output: Stored hash: b'$2b$12$K7g.../XYZ' (different each time due to random salt)
# Verify during login
is_valid = verify_password('user_password_123', password_hash)
print(f"Password valid: {is_valid}") # Output: Password valid: TrueO hash cria transformações unidirecionais úteis para verificação. Quando testei isso pela primeira vez, fiquei impressionado com o fato de que o bcrypt gera um hash diferente a cada vez devido ao salt aleatório, mas verify_password() ainda corresponde corretamente à senha original. O sal garante que mesmo senhas idênticas produzam hashes diferentes, protegendo contra ataques de tabela arco-íris. Durante o login, fazemos o hash da senha enviada e usamos a função de verificação do bcrypt para comparar de forma segura. Isso quer dizer que mesmo os desenvolvedores com acesso ao banco de dados não conseguem ver as senhas dos usuários.
Observação: Você vai precisar instalar o bcrypt com pip install bcrypt pra usar esse exemplo.
A criptografia é diferente do hash porque permite descriptografar de volta para a forma original usando chaves. Não precisávamos de criptografia para o nosso projeto, mas entendo o propósito dela: Use isso quando as pessoas autorizadas precisarem acessar dados reais, mas você quiser proteger esses dados contra acesso não autorizado.
Essas técnicas parecidas são diferentes na reversibilidade. A pseudonimização substitui as informações identificáveis, mas mantém a possibilidade de identificar as pessoas de novo, se for preciso. A anonimização tira todas as informações que podem identificar alguém, tornando impossível ser identificado de novo.
def pseudonymize_data(df, id_column, key_mapping=None):
if key_mapping is None:
key_mapping = {}
pseudo_df = df.copy()
for idx, original_id in enumerate(pseudo_df[id_column].unique()):
if original_id not in key_mapping:
key_mapping[original_id] = f"PSEUDO_{idx:06d}"
pseudo_df.loc[pseudo_df[id_column] == original_id, id_column] = key_mapping[original_id]
return pseudo_df, key_mapping
# Using pseudonymization
customer_data = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C001'],
'purchase': ['Laptop', 'Mouse', 'Keyboard']
})
pseudonymized_data, mapping = pseudonymize_data(customer_data, 'customer_id')Nosso projeto usou pseudonimização para manter a consistência do cliente em várias compras, ao mesmo tempo em que ocultou os identificadores reais do cliente. As três compras do cliente C001 foram todas mapeadas para o mesmo pseudônimo, preservando a capacidade de analisar o comportamento individual do cliente sem expor identidades reais.
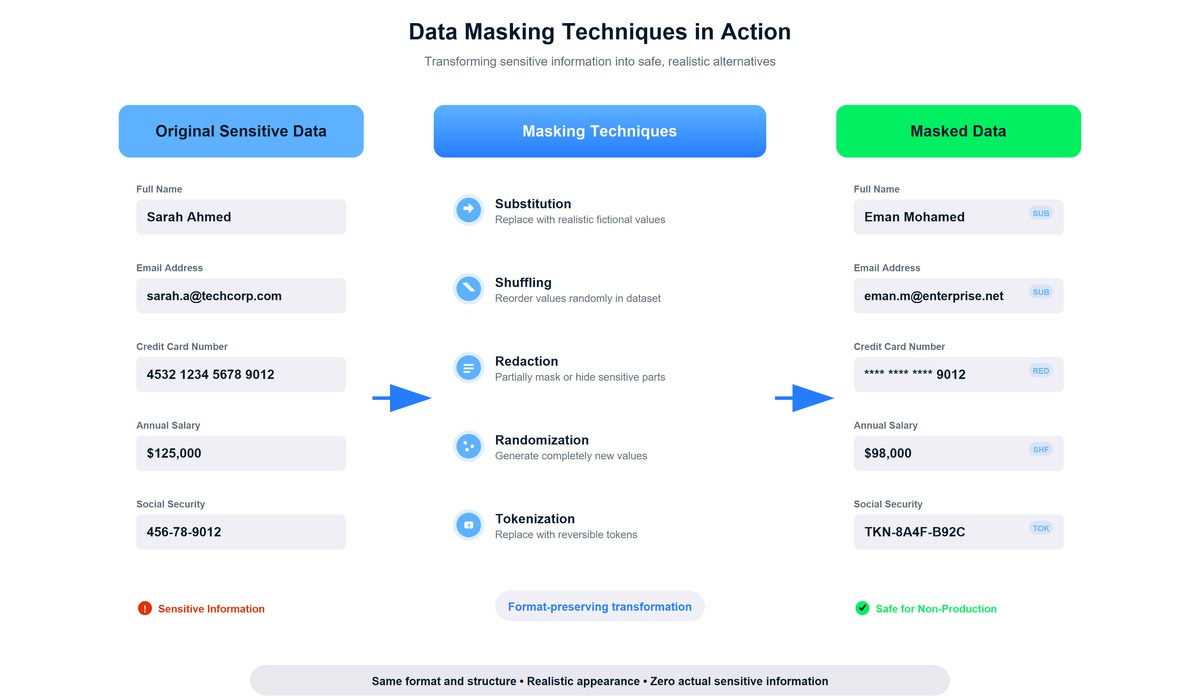
Várias técnicas de mascaramento transformam dados confidenciais, mantendo o formato e a usabilidade.
No começo, eu confundia o mascaramento de dados com criptografia e anonimização, porque todos eles envolvem proteger informações confidenciais. Entender as diferenças me ajudou a escolher as técnicas certas para cada situação. Deixa eu explicar as principais diferenças de um jeito que fique claro quando usar cada abordagem.
|
Abordagem |
Como funciona |
Reversibilidade |
Melhor caso de uso |
|
Mascaramento de dados |
Substitui dados confidenciais por valores fictícios, mas realistas. |
Irreversível (sem recuperação sem o banco de dados de origem) |
Ambientes de desenvolvimento, teste e análise onde é preciso uma estrutura de dados realista, mas os valores reais não são necessários. |
|
Criptografia |
Mistura os dados usando algoritmos matemáticos |
Reversível com chaves de descriptografia |
Proteger os dados em trânsito ou armazenados quando os usuários autorizados precisam acessar os valores originais |
|
Anonimização |
Tira ou generaliza informações que podem identificar alguém. |
Irreversível (feito pra impedir que a identificação seja recuperada) |
Publicar conjuntos de dados para pesquisa ou uso público, protegendo a privacidade individual |
|
Dados sintéticos |
Cria conjuntos de dados totalmente artificiais usando modelos estatísticos ou ML. |
N/A (não há dados originais para reverter) |
Treinar modelos de machine learning ou cenários em que até mesmo dados reais mascarados parecem muito arriscados |
Eu percebi claramente a diferença entre criptografia e mascaramento durante nossa unidade sobre segurança de banco de dados. Criptografamos os backups do banco de dados para que ficassem inutilizáveis se fossem roubados, mas ocultamos o banco de dados de desenvolvimento porque os desenvolvedores precisavam trabalhar com os dados, mas não com os dados reais dos clientes. Como eu falei antes, a criptografia protege os dados que você vai acabar descriptografando, enquanto o mascaramento cria alternativas seguras de forma permanente.
A diferença entre mascaramento e anonimização mostra objetivos diferentes. A anonimização foca especificamente em tirar informações que possam identificar alguém, pra evitar que as pessoas sejam identificadas de novo, usando técnicas como generalização (trocando idades exatas por faixas etárias) e supressão (tirando completamente atributos que possam identificar alguém). O mascaramento dá ênfase à manutenção da utilidade dos dados para desenvolvimento, testes e análises.
Um colega de turma que estava trabalhando num projeto de machine learning usou dados sintéticos gerados a partir de padrões num conjunto de dados reais. Os dados sintéticos não tinham registros reais, mas imitavam as propriedades estatísticas necessárias para treinar o modelo. Optei pelo mascaramento em vez de dados sintéticos para o nosso projeto porque precisávamos testar cenários específicos, como lidar com endereços de e-mail duplicados ou processar endereços internacionais. Os dados sintéticos podem não capturar esses casos extremos, enquanto os dados reais mascarados os preservam.
Implementar o mascaramento me ensinou que proteger informações confidenciais e, ao mesmo tempo, manter a utilidade dos dados envolve enfrentar desafios que não são óbvios até você se deparar com eles. Deixa eu te contar os principais desafios que enfrentei e como os superei.
A preservação dos atributos acabou sendo mais complicada do que a gente esperava. A simples substituição aleatória de valores quebra os padrões dos quais os aplicativos dependem. Os números dos cartões de crédito seguem o algoritmo de Luhn para validação da soma de verificação, os endereços de e-mail precisam ter domínios formatados corretamente e os códigos postais correspondem a regiões geográficas. Aprendi isso da maneira mais difícil quando minha primeira tentativa de mascaramento gerou números aleatórios de 16 dígitos para os campos do cartão de crédito. Tudo parecia estar bem até que os testes mostraram que nossa lógica de validação de pagamentos rejeitava todos os números de cartão porque eu tinha esquecido que os números de cartão de crédito incluem dígitos de verificação calculados usando o algoritmo de Luhn.
A integridade semântica é importante, não só no formato. Os dados mascarados devem evitar combinações obviamente sem sentido. Durante os testes, um colega de equipe percebeu que nosso conjunto de dados mascarados tinha códigos postais do Alasca atribuídos a endereços na Flórida. Embora fossem formatos tecnicamente válidos, a incompatibilidade geográfica parecia suspeita. Passei uma tarde melhorando a consistência semântica, criando endereços completos em que todos os componentes correspondiam geograficamente, em vez de juntar os componentes dos endereços aleatoriamente.
A integridade referencial entre tabelas criou uma complexidade significativa. Como expliquei na seção de técnicas, nosso banco de dados tinha tabelas de clientes, pedidos e avaliações, com os IDs dos clientes aparecendo nas três. Se o mascaramento transformasse os IDs dos clientes de forma inconsistente, essas relações seriam completamente rompidas. Isso aconteceu comigo depois da minha primeira tentativa de mascaramento: 30% dos nossos testes de integração falharam porque os pedidos dos clientes não estavam mais vinculados aos registros dos clientes. A grande descoberta veio quando percebi que precisava processar as tabelas na ordem de dependência usando mascaramento determinístico para garantir que o cliente C001 sempre tivesse o mesmo ID mascarado em todos os lugares em que aparecesse.
Equilibrar segurança com valor analítico exige um julgamento constante. Um mascaramento mais agressivo oferece mais privacidade, mas diminui a utilidade. Por exemplo, arredondar todas as idades para a década mais próxima melhora a privacidade, mas acaba com análises úteis baseadas na idade. Nosso projeto priorizou a utilidade, já que estávamos criando recursos de aplicativos que precisavam de um comportamento realista dos dados. Num cenário real de produção, com dados reais de clientes e obrigações de conformidade, eu teria que dar mais importância à proteção da privacidade e, talvez, aceitar uma menor utilidade dos dados.
As relações estatísticas podem ficar distorcidas. Se você tiver duas colunas relacionadas, tipo renda e gastos, e misturar cada uma por conta própria, a relação provavelmente vai mudar. Do ponto de vista estatístico, a codificação independente altera a distribuição conjunta das variáveis. Para manter essa relação, os analistas às vezes usam transformações que preservam a classificação, como embaralhar as duas colunas usando a mesma permutação aleatória ou adicionar ruído controlado que mantém a ordem conjunta.
Depois de aprender essas técnicas individuais, eu queria ver como elas funcionam juntas em um cenário realista. Aqui está um exemplo completo que mostra como ocultar um banco de dados de clientes com pedidos relacionados, exatamente o desafio que enfrentamos no nosso projeto de comércio eletrônico.
from faker import Faker
import pandas as pd
import numpy as np
import uuid
fake = Faker()
Faker.seed(42) # For reproducible results
# Original datasets (simulating real customer data)
customers_original = pd.DataFrame({
'customer_id': ['C001', 'C002', 'C003'],
'first_name': ['Khalid', 'Sarah', 'Mohamed'],
'last_name': ['Abdelaty', 'Ahmed', 'Ali'],
'email': ['khalid.a@email.com', 'sarah.a@email.com', 'mali@email.com'],
'phone': ['555-0123', '555-0124', '555-0125'],
'credit_card': ['4532-1234-5678-9012', '4556-7890-1234-5678', '4539-8765-4321-0987'],
'internal_notes': ['VIP customer', 'Requested callback', 'Payment issue resolved']
})
orders_original = pd.DataFrame({
'order_id': ['ORD001', 'ORD002', 'ORD003', 'ORD004'],
'customer_id': ['C001', 'C002', 'C001', 'C003'],
'product': ['Laptop', 'Mouse', 'Keyboard', 'Monitor'],
'amount': [1299.99, 29.99, 89.99, 399.99]
})
# Step 1: Create deterministic ID mapping to maintain referential integrity
def create_id_mapping(ids):
"""Create consistent pseudonymous IDs"""
mapping = {}
for idx, original_id in enumerate(ids):
mapping[original_id] = f"CUST_{idx:06d}"
return mapping
customer_id_mapping = create_id_mapping(customers_original['customer_id'].unique())
# Step 2: Mask customer data using multiple techniques
def mask_customer_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Replace customer IDs consistently
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Substitution: Replace names and emails with realistic fake data
masked['first_name'] = [fake.first_name() for _ in range(len(masked))]
masked['last_name'] = [fake.last_name() for _ in range(len(masked))]
masked['email'] = [fake.email() for _ in range(len(masked))]
# Partial masking/redaction: Show last 4 digits of phone and credit card
masked['phone'] = masked['phone'].apply(lambda x: '***-' + x[-4:])
masked['credit_card'] = masked['credit_card'].apply(lambda x: '****-****-****-' + x[-4:])
# Nulling: Remove internal notes entirely
masked['internal_notes'] = None
return masked
# Step 3: Mask order data with referential integrity
def mask_order_database(df, id_mapping):
masked = df.copy()
# Pseudonymization: Use same customer ID mapping to maintain relationships
masked['customer_id'] = masked['customer_id'].map(id_mapping)
# Randomization: Generate new order IDs
masked['order_id'] = [f"ORD-{uuid.uuid4().hex[:8].upper()}" for _ in range(len(masked))]
# Shuffling: Preserve amount distribution but break individual associations
shuffled_amounts = masked['amount'].values.copy()
np.random.shuffle(shuffled_amounts)
masked['amount'] = shuffled_amounts
return masked
# Apply masking
customers_masked = mask_customer_database(customers_original, customer_id_mapping)
orders_masked = mask_order_database(orders_original, customer_id_mapping)
print("=== MASKED CUSTOMER DATA ===")
print(customers_masked)
print("\n=== MASKED ORDER DATA ===")
print(orders_masked)
# Verify referential integrity is maintained
print("\n=== VERIFICATION: JOIN STILL WORKS ===")
joined = customers_masked.merge(orders_masked, on='customer_id')
print(f"Original orders: {len(orders_original)}, Joined orders: {len(joined)}")
print("✓ All order-customer relationships preserved!")Quando eu rodei esse pipeline de mascaramento completo nos dados do nosso projeto (500 registros de clientes com 1.200 pedidos), levou cerca de 2 segundos pra executar, o que foi perfeitamente aceitável pro nosso ciclo semanal de atualização do banco de dados de desenvolvimento. Várias coisas se encaixaram:
A integridade referencial funcionou perfeitamente. O cliente CUST_000000 (originalmente C001) tinha pedidos nas tabelas de clientes e pedidos. As consultas do JOIN que alimentam nosso recurso de histórico de pedidos funcionaram da mesma forma com dados mascarados, porque usamos o mesmo customer_id_mapping para ambas as tabelas.
Cada técnica tinha um objetivo específico. A substituição fez com que os nomes dos clientes parecessem mais reais. O mascaramento parcial permite que a gente verifique os métodos de pagamento sem mostrar os números completos dos cartões. A reorganização preservou a capacidade dos nossos painéis analíticos de mostrar distribuições precisas de receitas, ao mesmo tempo que desvinculou os valores de clientes específicos. A anulação eliminou os dados que não precisávamos para os testes.
A saída parecia e funcionava como dados reais. Quando eu dei uma olhada no banco de dados mascarado durante o desenvolvimento, tudo parecia autêntico. Os endereços de e-mail foram validados corretamente. Os números de telefone aparecem direitinho. Os dados não gritavam “isso é falso”, o que me manteve focado na depuração da lógica da aplicação, em vez de me distrair com dados de teste obviamente artificiais.
A qualidade dos dados continuou alta. Ainda poderíamos testar casos extremos, como clientes com vários pedidos, calcular estatísticas agregadas e verificar restrições do banco de dados. A máscara preservou a complexidade e as relações de que precisávamos, ao mesmo tempo que protegeu cada informação confidencial.
Essa abordagem transformou o que inicialmente parecia um problema insuperável, criando um banco de dados de testes seguro, mas realista, em um processo sistemático e reproduzível. Cada vez que atualizávamos nosso banco de dados de desenvolvimento, a execução desse script de mascaramento levava menos de um minuto e nos dava total confiança de que nenhum dado real do cliente poderia vazar.
Comece com uma descoberta abrangente de dados. Informações confidenciais apareceram em lugares inesperados, além de campos óbvios como nomes e e-mails. Nosso banco de dados tinha campos de notas de clientes com entradas de texto livre que podiam incluir informações pessoais. Aprendi a revisar sistematicamente todos os campos, não só os que são obviamente sensíveis. Nos sistemas de produção, as organizações usam ferramentas automatizadas de descoberta de dados que procuram padrões que correspondam a informações pessoais identificáveis.
Defina logo no início políticas claras sobre o uso de máscara. No começo, cada um do time tomava suas próprias decisões sobre o uso de máscaras, o que acabava criando confusão. Uma pessoa ocultou completamente os números de telefone, outra usou o ocultamento parcial e uma terceira deixou-os intactos. Acabamos padronizando nossa abordagem: mascaramento total para nomes e e-mails, mascaramento parcial para números de telefone e cartões e anulação para notas internas. As políticas documentadas mostram quais elementos de dados precisam ser mascarados, quais técnicas se aplicam a diferentes tipos e como lidar com casos extremos.
Use algoritmos que preservam o formato. Em vez de trocar os dados por valores aleatórios, esses algoritmos criam substituições realistas que seguem as mesmas regras de validação dos dados originais. Como mostrei antes, o mascaramento do meu cartão de crédito precisava gerar números que passassem na validação Luhn, e o mascaramento do e-mail precisava de endereços formatados corretamente com padrões de domínio válidos.
Teste a qualidade do mascaramento com rigor. Escrevi testes simples pra conferir a qualidade dos dados mascarados antes de usá-los no desenvolvimento. Esses testes verificaram se os endereços de e-mail mascarados passaram na validação regex, se os IDs dos clientes continuaram únicos depois da máscara, se as relações de chaves estrangeiras continuaram válidas e se o conjunto de dados mascarado tem o mesmo tamanho que o original. Esses testes detectaram problemas como geração de duplicatas e quebras de integridade referencial antes que os encontrássemos durante os testes do aplicativo.
Automatize todo o processo. Minha primeira tentativa de mascaramento envolveu executar manualmente scripts Python e copiar arquivos, o que rapidamente se tornou tedioso. Acabei criando um único script que cuida de todo o processo: ler os dados originais, aplicar todas as transformações de mascaramento, validar os resultados e gravar a saída mascarada. Em projetos reais com pipelines de integração contínua, o mascaramento seria integrado como uma etapa automática, sem que os desenvolvedores precisassem se preocupar com isso.
Garanta que não dá pra voltar atrás e que dá pra repetir. O processo de mascaramento deve ser irreversível para oferecer proteção de verdade, mas repetível quando você precisar atualizar bancos de dados de teste com resultados consistentes. Usar técnicas determinísticas com sementes consistentes, como mostrei no exemplo completo, dá esse equilíbrio.
O mascaramento de dados está evoluindo rapidamente com a inteligência artificial e o machine learning. Embora nosso projeto de aula tenha usado técnicas tradicionais de máscara, as soluções modernas estão cada vez mais usando IA para automatizar e melhorar o processo de máscara.
A possibilidade mais empolgante para mim é a descoberta automatizada de dados. Passei horas revisando manualmente o esquema do nosso banco de dados para ver quais campos tinham informações confidenciais. Imagina uma ferramenta que identifica automaticamente campos confidenciais analisando padrões, nomes de colunas e distribuições de valores, em vez de precisar de revisão manual. Um sistema de ML pode perceber que uma coluna com o nome estranho de “user_identifier” na verdade tem endereços de e-mail, algo que eu poderia facilmente deixar passar durante uma inspeção manual. Isso teria me poupado um tempão.
Também tenho lidosobre técnicas de machine learning que preservam a privacidade e vão além do mascaramento tradicional. A privacidade diferencial, por exemplo, adiciona ruído matemático cuidadosamente calibrado aos dados de treinamento ou aos resultados do modelo. O aprendizado federado treina modelos em conjuntos de dados distribuídos sem centralizar informações confidenciais. Essas abordagens tratam de cenários em que o mascaramento padrão pode eliminar padrões dos quais os modelos precisam aprender.
A geração de dados sintéticos usando IA generativa me interessa bastante para projetos futuros. Em vez de esconder registros reais, os sistemas de IA treinados com padrões de dados reais criam conjuntos de dados totalmente artificiais. Ainda não tentei implementar isso sozinho, mas consigo ver o apelo para cenários que exigem conjuntos de dados de treinamento enormes ou onde até mesmo dados reais mascarados parecem arriscados. O desafio seria garantir que os dados sintéticos representassem com precisão os casos extremos e a complexidade que tornaram os dados reais mascarados tão valiosos para nossos testes.
Olhando para o rumo que o setor está tomando, os fluxos de trabalho de desenvolvimento nativos da nuvem estão começando a incorporar o mascaramento automatizado como infraestrutura padrão. Em vez de mascarar ser algo que eu faço manualmente com scripts Python, os pipelines de implantação poderiam lidar com isso automaticamente ao provisionar bancos de dados de desenvolvimento. Os desenvolvedores especificariam os requisitos de mascaramento nos arquivos de configuração junto com os esquemas do banco de dados. Esse é o tipo de automação que eu adoraria implementar em projetos futuros, transformando o mascaramento de uma etapa manual de pré-processamento em um comportamento automático da infraestrutura.
Mas a IA é tipo uma faca de dois gumes pra privacidade dos dados. Embora melhore as técnicas de mascaramento, também torna os ataques de reidentificação mais sofisticados. Os modelos de machine learning podem cruzar dados aparentemente anônimos com informações públicas para identificar novamente as pessoas. Pesquisadores conseguiram identificar pessoas em dados “anonimizados” da Netflix, comparando-os com avaliações do IMDb. À medida que as ferramentas de mascaramento ficam mais inteligentes, o mesmo acontece com os métodos para quebrá-las.
O mascaramento de dados é o equilíbrio perfeito entre a utilidade dos dados e a privacidade. Usando as técnicas certas, como substituição, mascaramento determinístico e métodos que preservam o formato, você pode manter dados realistas e, ao mesmo tempo, proteger informações confidenciais.
Comece identificando seus conjuntos de dados mais críticos e aplique o mascaramento em ambientes que não sejam de produção. Automatize logo de cara pra tornar a proteção de privacidade uma parte padrão do seu fluxo de trabalho.
Para aprofundar seus conhecimentos, dê uma olhada nos nossos cursos Privacidade e Anonimização de Dados em Python ou Engenharia de Dados para Todos.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Sejal Jaiswal
12 min
blog
Christine Cepelak
15 min
blog
Elena Kosourova
15 min
blog
Mike Shakhomirov
11 min
blog
Matt Crabtree
15 min

