
programa
Ingeniero de datos en Python
40 h
Para gestionar una base de datos de forma eficaz y adecuada, es necesario comprender los fundamentos de los modelos de datos.
En sistemas de gestión de bases de datos (DBMS), los modelos de datos sirven como planos arquitectónicos que definen cómo se almacena, relaciona y accede a la información.
Son la capa de traducción entre los requisitos empresariales («Necesitamos realizar un seguimiento de los clientes, los pedidos y los productos») y la implementación técnica («Almacenaremos esto en cuatro tablas conectadas por claves externas»).
Un modelo de datos bien diseñado ayuda a:
En esta guía, exploraremos modelos de datos clásicos y modernos, niveles de abstracción, procesos de diseño y estrategias de optimización avanzadas, todo ello ilustrado con un conjunto de datos de comercio electrónico de PostgreSQL.
A continuación, te presentamos algunas razones por las que deberías conocer los modelos de datos y por qué son importantes.
Un modelo de datos en un sistema de gestión de bases de datos (DBMS) es un plano utilizado por las bases de datos para definir cómo se organizan, almacenan y acceden a los datos.
El modelo de datos proporciona una forma estructurada de representar los elementos de datos y sus relaciones, lo que permite una gestión y manipulación eficientes de los datos.
Contar con un modelo de datos ayuda a responder preguntas como:
Un modelo de datos hace que toda la información necesaria y las respuestas a estas preguntas sean fácilmente comprensibles para los administradores de bases de datos.
Un modelo de datos estructura y organiza la información en una base de datos. Esto garantiza la claridad y la coherencia en el tratamiento de los datos dentro de un sistema.
A continuación, se indican algunas razones comunes por las que se necesita un modelo de datos:
Sin un modelo de datos definido, corres el riesgo de tener:
Aquí tienes una sencilla consulta SQL que muestra cómo se puede modificar una base de datos para incluir estructura, relaciones y restricciones.
ALTER TABLE Orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (CustomerID)
REFERENCES Customer(CustomerID);Esto garantiza que cada pedido esté vinculado a un cliente existente, lo que constituye una forma sencilla pero eficaz de mantener la integridad.
Antes de continuar con las explicaciones, creemos y utilicemos un conjunto de datos sencillo sobre comercio electrónico para ilustrar los conceptos que se tratan en esta guía.
Incluiremos las siguientes entidades en el conjunto de datos.
Aquí tienes un sencillo diagrama ER ASCII que muestra las relaciones entre las tablas que vamos a crear.
Customer ───< Orders ───< OrderItems >─── ProductEsto se corresponde con la siguiente lógica:
A continuación, crearé las tablas y las ejecutaré en PostgreSQL para ejecutar las consultas.
Aquí tienes el esquema y el código SQL para crear las tablas necesarias.
CREATE TABLE Customer (
CustomerID SERIAL PRIMARY KEY,
CustomerName VARCHAR(100) NOT NULL,
Email VARCHAR(100) UNIQUE NOT NULL,
Phone VARCHAR(20),
CreatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE Product (
ProductID SERIAL PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Category VARCHAR(50),
Price NUMERIC(10, 2) NOT NULL
);
CREATE TABLE Orders (
OrderID SERIAL PRIMARY KEY,
CustomerID INT NOT NULL,
OrderDate DATE NOT NULL,
Status VARCHAR(20) DEFAULT 'Pending',
FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID)
);
CREATE TABLE OrderItems (
OrderItemID SERIAL PRIMARY KEY,
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity > 0),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);A continuación, insertemos información básica en el
INSERT INTO Customer (CustomerName, Email, Phone)
VALUES
('Alice Brown’, 'alice@example.com', '91234567'),
('Bob McKee', 'bob@example.com', '98765432');
INSERT INTO Product (ProductName, Category, Price)
VALUES
('Laptop', 'Electronics', 1200.00),
('Wireless Mouse', 'Electronics', 25.50),
('Office Chair', 'Furniture', 150.00);
INSERT INTO Orders (CustomerID, OrderDate, Status)
VALUES
(1, '2025-08-01', 'Shipped'),
(2, '2025-08-02', 'Pending');
INSERT INTO OrderItems (OrderID, ProductID, Quantity)
VALUES
(1, 1, 1),
(1, 2, 2),
(2, 3, 1);Tu diagrama ER para la base de datos debería tener este aspecto:
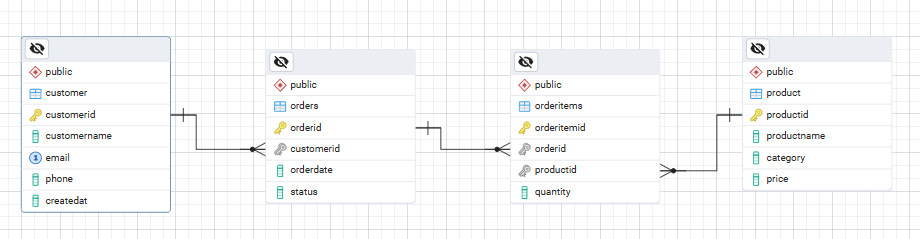
Un modelo de datos robusto consta de cuatro componentes principales:
En el modelado de datos, las entidades representan los objetos o conceptos fundamentales y diferenciados dentro de un sistema sobre los que deseamos almacenar datos. Las entidades suelen representarse como tablas en una base de datos.
Ejemplos de entidades en vuestro conjunto de datos:
CustomerProductOrdersOrderItemsEstas entidades se convierten en los «sustantivos» principales de la base de datos.
Las entidades son la base. Todos los demás aspectos del modelo, como los atributos, las relaciones y las restricciones, se basan en ellos.
En el modelado de datos, los atributos son características o propiedades que describen una entidad. Representan los puntos de datos específicos que definen una entidad, como el nombre, el correo electrónico o la dirección de un cliente.
Ejemplos:
Customer: CustomerName, Email, Phone.Product: ProductName, Price, Category.En pocas palabras, los atributos son los detalles que te interesan de cada entidad. Normalmente son columnas de una tabla.
Las relaciones en un modelo de datos definen cómo se conectan las diferentes entidades o tablas, representando las asociaciones entre ellas. Piensa en ellos como conexiones lógicas entre entidades.
Ejemplos en vuestro conjunto de datos:
Customer puede tener muchos Orders (1 a muchos).Order puede contener muchos Products a través de OrderItems (relaciones muchos a muchos resueltas mediante una tabla de unión).Las relaciones garantizan que el modelo de datos represente con precisión las asociaciones del mundo real.
En el modelado de datos, las restricciones son reglas que limitan los valores permitidos en una base de datos, garantizando la precisión, coherencia e integridad de los datos.
Las restricciones ayudan a mantener la integridad de la base de datos, evitando que se introduzcan datos no válidos o incoherentes.
Ejemplos:
UNIQUE restricción en Customer.Email.CHECK Restricción para garantizar Quantity > 0 en OrderItems.Ejemplo de PostgreSQL
A continuación se muestra un ejemplo del uso de algunos tipos de restricciones en una consulta SQL.
CREATE TABLE OrderItems_Constraint (
OrderItemID SERIAL PRIMARY KEY,
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity > 0),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);En este ejemplo, hemos utilizado las restricciones PRIMARY, CHECK, NOT NULL y REFERENCES.
Existen diferentes tipos de modelos de datos en las bases de datos. Esto refleja la forma en que se almacenan los datos según su naturaleza.
En primer lugar, veamos algunos modelos clásicos comunes utilizados en los sistemas de gestión de bases de datos.
Un modelo de datos jerárquico organiza los datos en una estructura arborescente, en la que cada registro (nodo) tiene un único padre (excepto la raíz) y puede tener varios hijos.
Ejemplo (representación similar a XML):
<Customer id="1">
<Name>Alice Brown</Name>
<Orders>
<Order id="1" date="2025-08-01"/>
</Orders>
</Customer>Los equivalentes modernos suelen aparecer en el almacenamiento XML/JSON, pero el modelo en sí se remonta a los primeros DBMS de mainframe, como IMS.
Un modelo de datos en red es una forma flexible de representar datos y relaciones, especialmente útil para conexiones complejas de muchos a muchos.
Utiliza una estructura gráfica con nodos (que representan entidades) y aristas (que representan relaciones) para organizar los datos, lo que permite vías de acceso más eficientes y directas en comparación con los modelos jerárquicos.
El modelo de datos relacional es una forma de estructurar los datos en tablas con filas y columnas, lo que permite almacenar, recuperar y gestionar la información de manera eficiente.
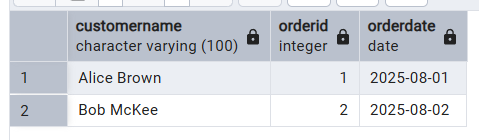
Ejemplo de consulta de nuestro conjunto de datos:
SELECT c.CustomerName, o.OrderID, o.OrderDate
FROM Customer c
JOIN Orders o ON c.CustomerID = o.CustomerID;Esta consulta muestra el uso de la función « JOIN » para crear relaciones entre la tabla « Customer » y la tabla « Orders ».
Esto produce la siguiente tabla como resultado:
A medida que avanza la tecnología de bases de datos, también han surgido algunos modelos modernos. Aquí hay algunos ejemplos:
El modelo orientado a objetos combina conceptos de bases de datos y programación orientada a objetos. Admite herencia y encapsulación.
El modelo objeto-relacional es un híbrido entre el modelo relacional y el orientado a objetos.
Los modelos de datos nosql representan una desviación de las rígidas estructuras basadas en tablas de las bases de datos relacionales tradicionales, ya que ofrecen esquemas flexibles y diversos métodos de organización de datos para manejar grandes volúmenes de datos no estructurados y semiestructurados.
A continuación se muestran algunos ejemplos de modelos nosql:
A continuación se muestra un ejemplo de un modelo de datos de documento (documento MongoDB):
{
"CustomerName": "Alice Brown",
"Orders": [
{"ProductName": "Laptop", "Quantity": 1}
]
}El proceso de modelado de datos se lleva a cabo en tres niveles diferentes: conceptual, lógico y físico.
Estos niveles son las diferentes etapas de detalle que se utilizan al diseñar una base de datos o un sistema de información. Ayudan a gestionar la complejidad centrándose en aspectos específicos de los datos y su estructura.
El modelo conceptual de datos es la abstracción de más alto nivel, independiente de la tecnología, en el proceso de modelado de datos. Se centra en definir las entidades clave y sus relaciones en un sistema sin entrar en detalles técnicos.
Esta capa recoge los requisitos y las relaciones empresariales.
Ejemplo: Tu diagrama ER muestra Customer → Orders.
El modelo de datos lógico es el segundo nivel de abstracción. Describe entidades, atributos y relaciones sin mencionar ninguna base de datos específica.
Esta capa convierte el modelo conceptual en un esquema específico del DBMS. Define tablas, claves y relaciones sin detalles de almacenamiento.
La capa del modelo de datos físicos implementa un esquema con índices, particiones y parámetros de almacenamiento.
Aquí tienes un ejemplo de índice:
CREATE INDEX idx_order_customer ON Orders(CustomerID);Ahora veremos este índice utilizando esta consulta:
SELECT indexname, indexdef
FROM pg_indexes
WHERE tablename = 'orders';Como puedes ver en el índice que aparece a continuación, hemos creado un nuevo índice llamado « idx_order_customer » (El arte de la programación).

El modelado de datos es un enfoque estructurado para traducir las necesidades empresariales en un plan técnico que rige cómo se almacenarán, relacionarán y recuperarán los datos.
Cuando se hace bien, el modelado de datos reduce la redundancia, mejora la calidad de los datos y facilita el mantenimiento futuro.

Fuente: Hoja de referencia sobre las dimensiones de la calidad de los datos
El proceso suele desarrollarse por etapas. Analicemos esto.
La recopilación de requisitos es la base de todo el proceso de modelado de datos. En esta etapa, estás tratando de comprender cuáles son las necesidades del negocio y por qué.
Hay varias formas de recopilar los requisitos de manera eficaz.
El resultado de esta fase debe ser un conjunto claro de requisitos documentados que describan las entidades de datos, las relaciones y las reglas de negocio.
Por ejemplo, en nuestro conjunto de datos minoristas de muestra, las partes interesadas podrían decir que quieren realizar un seguimiento de los pedidos de los clientes, los productos y las fechas de los pedidos para poder calcular métricas como las ventas totales por categoría de producto y las tasas de clientes habituales.
El diseño conceptual toma esos requisitos empresariales y los convierte en una representación visual de alto nivel de los datos.
En esta etapa, te centras en qué entidades existen y cómo se relacionan, sin preocuparte por detalles técnicos como los tipos de claves primarias o las estrategias de indexación.
Aquí es donde entran en juego los diagramas entidad-relación (ER). Los diagramas ER muestran entidades (por ejemplo, Cliente, Producto, Pedido), sus atributos y las relaciones entre ellas.
Para vuestro conjunto de datos:
Customer Podría incluir el ID de cliente, el nombre y el correo electrónico.Product Podría incluir ProductID, Nombre, Categoría.Order Podría incluir OrderID, OrderDate.OrderItem Podría incluir OrderItemID, OrderID, ProductID, Quantity, Price.Las relaciones podrían ser:
Este diagrama se convierte en un punto de referencia común tanto para los equipos comerciales como para los técnicos.
El diseño lógico se basa en el modelo conceptual mediante la aplicación de reglas de bases de datos, en particular la normalización.
La normalización es el proceso de estructurar una base de datos relacional para minimizar la redundancia y la dependencia. A menudo se hace por etapas (1NF, 2NF, 3NF), cada una con requisitos específicos.
En nuestro ejemplo, la dirección de correo electrónico del cliente solo aparece en la tabla Customer, sin duplicarse en la tabla Order. Del mismo modo, la información sobre las categorías de productos debe residir en la tabla Product, y no dispersarse en múltiples registros en OrderItem.
El diseño físico toma el modelo lógico y lo adapta a un sistema de base de datos específico, como PostgreSQL o MySQL. Esta etapa implica tomar decisiones sobre los tipos de datos, la optimización del almacenamiento y el ajuste del rendimiento.
Los índices son un factor clave a tener en cuenta en este caso. Por ejemplo, añadir un índice a OrderDate en la tabla Order puede acelerar significativamente las consultas que filtran por fecha.
La partición también se puede aplicar a conjuntos de datos grandes, dividiendo los datos en fragmentos manejables por fecha, rango o claves hash para mejorar el rendimiento de las consultas.
También decides las restricciones, como las claves externas, para garantizar la integridad de los datos a nivel de la base de datos.
Una vez completado el diseño, se deben realizar validaciones antes de ponerlo en marcha.
Esto implica cargar datos de muestra, idealmente datos de prueba realistas que reflejen los volúmenes esperados, y ejecutar consultas que simulen el uso en el mundo real.
Por ejemplo, en nuestro conjunto de datos minoristas, puedes ejecutar una consulta para calcular los totales de ventas por mes, asegurándote de que las cifras coincidan con las expectativas de la empresa.
También se probarían casos extremos, como qué ocurre cuando se realiza un pedido sin artículos (lo cual debería ser imposible si las restricciones son correctas).
El último paso es trasladar el diseño validado a la fase de producción. Esto debe hacerse utilizando scripts de migración controlados por versiones, de modo que se pueda realizar un seguimiento de los cambios a lo largo del tiempo.
La implementación también implica configurar la supervisión del rendimiento y los errores, y garantizar que el esquema esté bien documentado para que los cambios futuros se puedan realizar sin confusión.
Tras la implementación, es habitual revisar periódicamente el diseño a medida que surgen nuevos requisitos.
Un modelo de datos bien diseñado ofrece múltiples ventajas.
El modelado de datos también puede contar con métodos avanzados para su implementación.
El modelado dimensional es habitual en el almacenamiento de datos, donde el objetivo es hacer que las consultas analíticas sean intuitivas y rápidas.
Esto implica el uso de esquemas específicos:
OrderItems) almacena métricas, mientras que varias tablas de dimensiones (por ejemplo, Customer, Product, Date) almacenan atributos descriptivos. Esta estructura facilita las consultas de las herramientas de BI.Así es como podría verse:
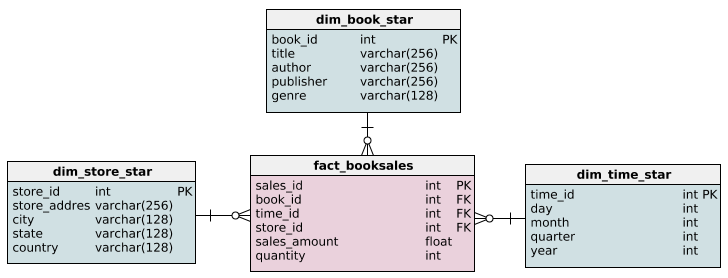
Fuente: Consultas en el esquema en estrella
Product podría dividirse en las tablas Product y Category.El modelado ER es más habitual en los sistemas transaccionales. Hace hincapié en la normalización para garantizar la integridad de los datos. En algunos casos, la desnormalización se aplica de forma selectiva para mejorar el rendimiento de lectura, especialmente en el caso de datos a los que se accede con frecuencia.
El modelado políglota utiliza diferentes tipos de bases de datos para diferentes cargas de trabajo.
Por ejemplo, puedes utilizar PostgreSQL para las transacciones de pedidos y MongoDB para un catálogo de productos con atributos flexibles. Esto te permite utilizar la herramienta adecuada para cada tarea, pero aumenta la complejidad operativa.
En los sistemas nosql, el diseño suele basado en patrones de acceso en lugar de en una normalización estricta. Los datos se organizan para minimizar el número de consultas necesarias para las operaciones comunes, y la partición es esencial para evitar cuellos de botella.
Los sistemas relacionales como PostgreSQL son totalmente compatibles con las propiedades ACID, lo que garantiza la coherencia de los datos. Muchas bases de datos nosql relajan estas garantías para mejorar la velocidad y la escalabilidad, sacrificando la coherencia a cambio de una convergencia eventual.
Los modelos de datos son una parte fundamental del diseño de bases de datos y pueden adoptar muchas formas. Sin embargo, en las empresas modernas, para garantizar que estos modelos puedan alcanzar su máximo rendimiento, es necesario realizar las optimizaciones correspondientes.
La tecnología está en constante evolución y actualización, por lo que el aprendizaje y la adaptación continuos son una necesidad en el sector de los datos. Para obtener más información sobre bases de datos, consulta nuestro curso sobre Diseño de bases de datos o Introducción a las bases de datos relacionales en SQL para empezar.
¿Prefieres leer? Nuestros artículos sobre herramientas de modelado de datos o preguntas de entrevista sobre DBMS pueden resultarte útiles.
Los mejores cursos de DataCamp
programa
programa
Curso
blog
Mona Khalil
5 min
blog
Tim Lu
12 min
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
Tutorial
Oluseye Jeremiah
