
Track
Data Engineer in Python
40 hr
Managing a database effectively and properly requires understanding the fundamentals of data models.
In database management systems (DBMS), data models serve as the architectural blueprints that define how information is stored, related, and accessed.
They are the translation layer between business requirements (“We need to track customers, orders, and products”) and technical implementation (“We’ll store this in four tables connected by foreign keys”).
A well-designed data model helps to:
In this guide, we’ll explore both classical and modern data models, abstraction levels, design processes, and advanced optimization strategies — all illustrated with a PostgreSQL e-commerce dataset.
Here are some quick reasons why you should know about data models and why they are important.
A data model in a Database Management System (DBMS) is a blueprint used by databases to define how data is organized, stored, and accessed.
The datamodel provides a structured way to represent data elements and their relationships, enabling efficient data management and manipulation.
Having a data model helps to answer questions like:
A data model makes all the required information and answers to these questions easily understandable by database administrators.
A data model structures and organizes information in a database. This ensures clarity and consistency in how data is handled within a system.
Here are some common reasons why a data model is needed:
Without a defined data model, you risk having:
Here’s a simple SQL query showing how a database can be modified to include structure, relationships, and constraints.
ALTER TABLE Orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (CustomerID)
REFERENCES Customer(CustomerID);This enforces that every order is tied to an existing customer, which is a simple but powerful way to maintain integrity.
Before we move on to further explanations, let’s create and use a simple e-commerce dataset to demonstrate concepts throughout this guide.
We’ll include the following entities in the dataset.
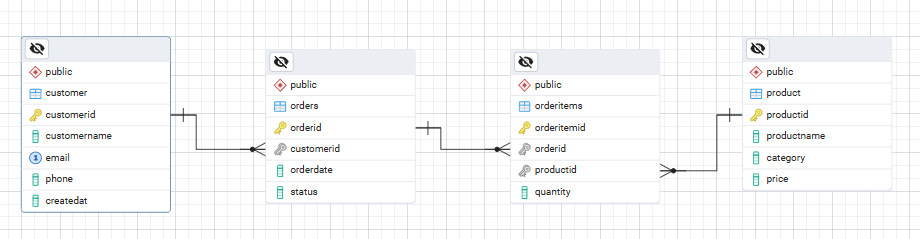
Here’s a simple ASCII ER Diagram showing the relationships between the tables we’ll create.
Customer ───< Orders ───< OrderItems >─── ProductThis corresponds to this logic:
Next, I’ll be creating the tables and running them in PostgreSQL to run the queries.
Here’s the schema and SQL code to create the necessary tables.
CREATE TABLE Customer (
CustomerID SERIAL PRIMARY KEY,
CustomerName VARCHAR(100) NOT NULL,
Email VARCHAR(100) UNIQUE NOT NULL,
Phone VARCHAR(20),
CreatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE Product (
ProductID SERIAL PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Category VARCHAR(50),
Price NUMERIC(10, 2) NOT NULL
);
CREATE TABLE Orders (
OrderID SERIAL PRIMARY KEY,
CustomerID INT NOT NULL,
OrderDate DATE NOT NULL,
Status VARCHAR(20) DEFAULT 'Pending',
FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID)
);
CREATE TABLE OrderItems (
OrderItemID SERIAL PRIMARY KEY,
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity > 0),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);Next, let’s insert some basic information into the
INSERT INTO Customer (CustomerName, Email, Phone)
VALUES
('Alice Brown’, 'alice@example.com', '91234567'),
('Bob McKee', 'bob@example.com', '98765432');
INSERT INTO Product (ProductName, Category, Price)
VALUES
('Laptop', 'Electronics', 1200.00),
('Wireless Mouse', 'Electronics', 25.50),
('Office Chair', 'Furniture', 150.00);
INSERT INTO Orders (CustomerID, OrderDate, Status)
VALUES
(1, '2025-08-01', 'Shipped'),
(2, '2025-08-02', 'Pending');
INSERT INTO OrderItems (OrderID, ProductID, Quantity)
VALUES
(1, 1, 1),
(1, 2, 2),
(2, 3, 1);Your ER diagram for the database should look like this:
A robust data model consists of four main components:
In data modeling, entities represent the core, distinct objects or concepts within a system that we want to store data about. Entities are often represented as tables in a database.
Examples of entities in our dataset:
CustomerProductOrdersOrderItemsThese entities become the core “nouns” of the database.
Entities are the foundation. Every other aspect of the model, such as attributes, relationships, and constraints, builds on them.
In data modeling, attributes are characteristics or properties that describe an entity. They represent the specific data points that define an entity, like a customer's name, email, or address.
Examples:
Customer: CustomerName, Email, Phone.Product: ProductName, Price, Category.Put simply, attributes are the details you care about for each entity. They are typically columns in a table.
Relationships in a data model define how different entities or tables are connected, representing associations between them. Think of them as logical connections between entities.
Examples in our dataset:
Customer can have many Orders (1-to-many).Order can contain many Products via OrderItems (many-to-many resolved through a junction table).Relationships ensure that the data model represents real-world associations accurately.
In data modeling, constraints are rules that limit the values allowed in a database, ensuring data accuracy, consistency, and integrity.
Constraints help maintain the integrity of the database, preventing invalid or inconsistent data from being entered.
Examples:
UNIQUE constraint on Customer.Email.CHECK constraint to ensure Quantity > 0 in OrderItems.PostgreSQL Example
Here’s an example of using some types of constraints in an SQL query.
CREATE TABLE OrderItems_Constraint (
OrderItemID SERIAL PRIMARY KEY,
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity > 0),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);In this example, we used the PRIMARY, CHECK, NOT NULL, and REFERENCES constraints.
Different types of data models exist in databases. This reflects the way in which data is stored according to the nature of the data.
Firstly, let’s look at some common classical models used in database management systems.
A hierarchical data model organizes data in a tree-like structure, where each record (node) has a single parent (except for the root) and can have multiple children.
Example (XML-like representation):
<Customer id="1">
<Name>Alice Brown</Name>
<Orders>
<Order id="1" date="2025-08-01"/>
</Orders>
</Customer>Modern equivalents often appear in XML/JSON storage, but the model itself dates back to early mainframe DBMS like IMS.
A network data model is a flexible way to represent data and relationships, especially useful for complex, many-to-many connections.
It uses a graph structure with nodes (representing entities) and edges (representing relationships) to organize data, allowing for more efficient and direct access paths compared to hierarchical models.
The relational data model is a way to structure data into tables with rows and columns, enabling efficient storage, retrieval, and management of information.
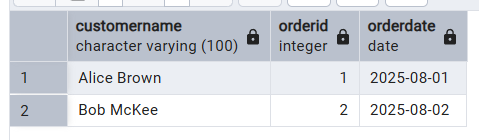
Example query from our dataset:
SELECT c.CustomerName, o.OrderID, o.OrderDate
FROM Customer c
JOIN Orders o ON c.CustomerID = o.CustomerID;This query demonstrates the use of the JOIN function to create relationships between the Customer table and the Orders table.
This produces the following table as a result:
As database technology advances, some modern models have also surfaced. Here are some examples:
The object-oriented model combines database and object-oriented programming concepts. It supports inheritance and encapsulation.
The object-relational model is a hybrid of relational and object-oriented.
NoSQL data models represent a departure from the rigid, table-based structures of traditional relational databases, offering flexible schemas and diverse data organization methods to handle large volumes of unstructured and semi-structured data.
Here are some examples of NoSQL models:
Here’s an example of a document data model (MongoDB document):
{
"CustomerName": "Alice Brown",
"Orders": [
{"ProductName": "Laptop", "Quantity": 1}
]
}The process of data modeling occurs at three different levels – conceptual, logical, and physical.
These levels are the different stages of detail used when designing a database or information system. They help manage complexity by focusing on specific aspects of the data and its structure.
The conceptual data model is the highest-level, technology-agnostic abstraction in the data modeling process. It focuses on defining the key entities and their relationships in a system without delving into technical details.
This layer captures business requirements and relationships.
Example: Our ER diagram showing Customer → Orders.
The logical data model is the second abstraction level. It outlines entities, attributes, and relationships with no mention of any specific database.
This layer converts the conceptual model into a DBMS-specific schema. It defines tables, keys, and relationships without storage details.
The physical data model layer implements a schema with indexes, partitions, and storage parameters.
Here’s an example of an index:
CREATE INDEX idx_order_customer ON Orders(CustomerID);Now we’ll view this index using this query:
SELECT indexname, indexdef
FROM pg_indexes
WHERE tablename = 'orders';As you can see in the index below, we created a new index called idx_order_customer.

Data modeling is a structured approach to translating business needs into a technical blueprint that governs how data will be stored, related, and retrieved.
When done well, data modeling reduces redundancy, improves data quality, and makes future maintenance easier.

Source: Data Quality Dimensions Cheat Sheet
The process typically moves in stages. Let’s break these down.
Requirement gathering is the foundation of the entire data modeling process. At this stage, you’re trying to understand what the business needs are and why.
There are several ways to gather requirements effectively.
The output of this phase should be a clear set of documented requirements describing the data entities, relationships, and business rules.
For example, in our sample retail dataset, stakeholders might say they want to track customer orders, products, and order dates so they can calculate metrics like total sales per product category and repeat customer rates.
The conceptual design takes those business requirements and turns them into a visual, high-level representation of the data.
At this stage, you focus on what entities exist and how they relate, without worrying about technical details like primary key types or indexing strategies.
This is where Entity-Relationship (ER) diagrams come in. ER diagrams show entities (e.g., Customer, Product, Order), their attributes, and the relationships between them.
For our dataset:
Customer might include CustomerID, Name, Email.Product might include ProductID, Name, Category.Order might include OrderID, OrderDate.OrderItem might include OrderItemID, OrderID, ProductID, Quantity, Price.The relationships could be:
This diagram becomes a common reference point for both business and technical teams.
Logical design builds upon the conceptual model by applying database rules, particularly normalization.
Normalization is the process of structuring a relational database to minimize redundancy and dependency. It’s often done in stages (1NF, 2NF, 3NF), each with specific requirements.
For our example, the customer’s email address belongs only in the Customer table, not duplicated in the Order table. Similarly, product category information should reside in the Product table, not scattered across multiple records in OrderItem.
Physical design takes the logical model and adapts it for a specific database system, like PostgreSQL or MySQL. This stage involves decisions about data types, storage optimization, and performance tuning.
Indexes are a key consideration here. For example, adding an index to OrderDate in the Order table can significantly speed up queries that filter by date.
Partitioning can also be applied for large datasets, splitting data into manageable chunks by date, range, or hash keys to improve query performance.
You also decide on constraints, such as foreign keys, to enforce data integrity at the database level.
Once the design is complete, validations must be made before going live.
This involves loading sample data, ideally, realistic test data that mirrors expected volumes, and running queries that simulate real-world usage.
For example, in our retail dataset, you might run a query to calculate sales totals by month, ensuring the numbers match what the business expects.
You’d also test edge cases, such as what happens when an order is placed with no items (which should be impossible if constraints are correct).
The final step is moving the validated design into production. This should be done using version-controlled migration scripts so that changes are tracked over time.
Deployment also involves setting up monitoring for performance and errors, and ensuring that the schema is well-documented so that future changes can be made without confusion.
Post-deployment, it’s common to periodically review the design as new requirements emerge as well.
A well-designed data model offers multiple benefits.
Data modeling can also have advanced methods for implementation.
Dimensional modeling is common in data warehousing, where the goal is to make analytical queries intuitive and fast.
This involves using specific schemas:
OrderItems) stores metrics, while multiple dimension tables (e.g., Customer, Product, Date) store descriptive attributes. This structure is easy for BI tools to query.Here’s what it might look like:
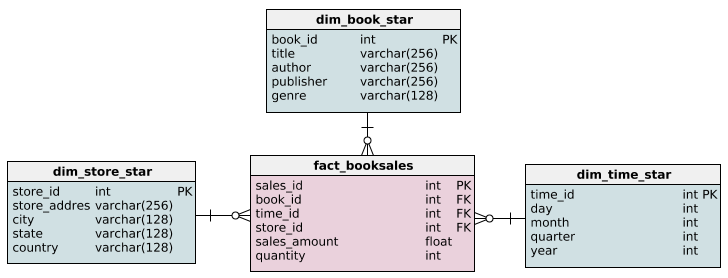
Source: Querying the star schema
Product could be split into Product and Category tables.ER modeling is more typical in transactional systems. It emphasizes normalization to ensure data integrity. In some cases, denormalization is selectively applied to improve read performance, especially for frequently accessed data.
Polyglot modeling uses different database types for different workloads.
For example, you might use PostgreSQL for order transactions and MongoDB for a product catalog with flexible attributes. This allows you to use the right tool for the right job, but it does increase operational complexity.
In NoSQL systems, design is often based on access patterns rather than strict normalization. Data is organized to minimize the number of queries needed for common operations, and partitioning is essential to avoid bottlenecks.
Relational systems like PostgreSQL fully support ACID properties, ensuring data consistency. Many NoSQL databases relax these guarantees to improve speed and scalability, trading off consistency for eventual convergence.
Data models are a crucial part of database design and can take on many forms. However, in modern enterprises, to ensure that these models are able to achieve their best performance, optimizations have to be done accordingly.
Technology is constantly evolving and being updated, and ongoing learning and adaptation are a need in the data industry. To learn more about databases, check out our course on Database Design or Introduction to Relational Databases in SQL to get started.
Prefer reading instead? Our articles on Data Modeling Tools or DBMS Interview Questions might be helpful.
Top DataCamp Courses
Track
Track
Course
blog
Kurtis Pykes
9 min
blog
Laiba Siddiqui
15 min
blog
Moez Ali
9 min
blog
Javier Canales Luna
15 min
blog
Jake Roach
8 min
Tutorial
Dario Radečić
