
Programa
Engenheiro de dados Em Python
40 h
Para gerenciar um banco de dados de forma eficaz e adequada, é preciso entender os fundamentos dos modelos de dados.
Em sistemas de gerenciamento de banco de dados (DBMS), os modelos de dados funcionam como projetos arquitetônicos que definem como as informações são armazenadas, relacionadas e acessadas.
Eles são a camada de tradução entre os requisitos comerciais (“Precisamos acompanhar clientes, pedidos e produtos”) e a implementação técnica (“Vamos armazenar isso em quatro tabelas conectadas por chaves estrangeiras”).
Um modelo de dados bem projetado ajuda a:
Neste guia, vamos explorar modelos de dados clássicos e modernos, níveis de abstração, processos de design e estratégias avançadas de otimização — tudo ilustrado com um conjunto de dados de comércio eletrônico do PostgreSQL.
Aqui estão algumas razões rápidas pelas quais você deve saber sobre modelos de dados e por que eles são importantes.
Um modelo de dados em um Sistema de Gerenciamento de Banco de Dados (DBMS) é um plano usado por bancos de dados para definir como os dados são organizados, armazenados e acessados.
O modelo de dados oferece uma maneira estruturada de representar elementos de dados e suas relações, permitindo um gerenciamento e manipulação eficientes dos dados.
Ter um modelo de dados ajuda a responder perguntas como:
Um modelo de dados torna todas as informações necessárias e as respostas a essas perguntas facilmente compreensíveis pelos administradores de bancos de dados.
Um modelo de dados estrutura e organiza as informações em um banco de dados. Isso garante clareza e consistência na forma como os dados são tratados dentro de um sistema.
Aqui estão algumas razões comuns pelas quais um modelo de dados é necessário:
Sem um modelo de dados definido, você corre o risco de ter:
Aqui está uma consulta SQL simples mostrando como um banco de dados pode ser modificado para incluir estrutura, relações e restrições.
ALTER TABLE Orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (CustomerID)
REFERENCES Customer(CustomerID);Isso garante que cada pedido esteja vinculado a um cliente existente, o que é uma maneira simples, mas eficaz, de manter a integridade.
Antes de continuarmos com mais explicações, vamos criar e usar um conjunto de dados simples de comércio eletrônico para mostrar os conceitos ao longo deste guia.
Vamos incluir as seguintes entidades no conjunto de dados.
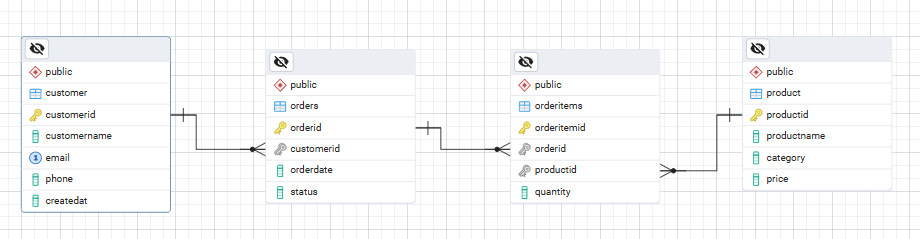
Aqui está um diagrama ER ASCII simples mostrando as relações entre as tabelas que vamos criar.
Customer ───< Orders ───< OrderItems >─── ProductIsso faz sentido assim:
Depois, vou criar as tabelas e colocá-las no PostgreSQL para rodar as consultas.
Aqui está o esquema e o código SQL para criar as tabelas necessárias.
CREATE TABLE Customer (
CustomerID SERIAL PRIMARY KEY,
CustomerName VARCHAR(100) NOT NULL,
Email VARCHAR(100) UNIQUE NOT NULL,
Phone VARCHAR(20),
CreatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE Product (
ProductID SERIAL PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Category VARCHAR(50),
Price NUMERIC(10, 2) NOT NULL
);
CREATE TABLE Orders (
OrderID SERIAL PRIMARY KEY,
CustomerID INT NOT NULL,
OrderDate DATE NOT NULL,
Status VARCHAR(20) DEFAULT 'Pending',
FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID)
);
CREATE TABLE OrderItems (
OrderItemID SERIAL PRIMARY KEY,
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity > 0),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);Agora, vamos colocar algumas informações básicas no
INSERT INTO Customer (CustomerName, Email, Phone)
VALUES
('Alice Brown’, 'alice@example.com', '91234567'),
('Bob McKee', 'bob@example.com', '98765432');
INSERT INTO Product (ProductName, Category, Price)
VALUES
('Laptop', 'Electronics', 1200.00),
('Wireless Mouse', 'Electronics', 25.50),
('Office Chair', 'Furniture', 150.00);
INSERT INTO Orders (CustomerID, OrderDate, Status)
VALUES
(1, '2025-08-01', 'Shipped'),
(2, '2025-08-02', 'Pending');
INSERT INTO OrderItems (OrderID, ProductID, Quantity)
VALUES
(1, 1, 1),
(1, 2, 2),
(2, 3, 1);Seu diagrama ER para o banco de dados deve ficar assim:
Um modelo de dados robusto tem quatro partes principais:
Na modelagem de dados, as entidades são tipo os objetos ou conceitos principais e distintos dentro de um sistema sobre os quais a gente quer guardar dados. As entidades são frequentemente representadas como tabelas em um banco de dados.
Exemplos de entidades em nosso conjunto de dados:
CustomerProductOrdersOrderItemsEssas entidades se tornam os principais “substantivos” do banco de dados.
As entidades são a base. Todos os outros aspectos do modelo, como atributos, relações e restrições, se baseiam neles.
Na modelagem de dados, atributos são características ou propriedades que descrevem uma entidade. Eles são os pontos de dados específicos que definem uma entidade, tipo o nome, e-mail ou endereço de um cliente.
Exemplos:
Customer: CustomerName, Email, Phone.Product: ProductName, Price, Category.Simplificando, atributos são os detalhes que você considera importantes para cada entidade. Normalmente são colunas em uma tabela.
As relações em um modelo de dados mostram como diferentes entidades ou tabelas estão conectadas, representando as associações entre elas. Pense nelas como conexões lógicas entre entidades.
Exemplos em nosso conjunto de dados:
Customer pode ter muitos Orders (1 para muitos).Order pode ter vários Products através de OrderItems (muitos para muitos resolvidos por meio de uma tabela de junção).As relações garantem que o modelo de dados represente com precisão as associações do mundo real.
Na modelagem de dados, as restrições são regras que limitam os valores permitidos em um banco de dados, garantindo a precisão, consistência e integridade dos dados.
As restrições ajudam a manter a integridade do banco de dados, impedindo que dados inválidos ou inconsistentes sejam inseridos.
Exemplos:
UNIQUE restrição em Customer.Email.CHECK restrição para garantir Quantity > 0 em OrderItems.Exemplo do PostgreSQL
Aqui está um exemplo de como usar alguns tipos de restrições em uma consulta SQL.
CREATE TABLE OrderItems_Constraint (
OrderItemID SERIAL PRIMARY KEY,
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity > 0),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);Neste exemplo, usamos as restrições PRIMARY, CHECK, NOT NULL e REFERENCES.
Existem diferentes tipos de modelos de dados em bancos de dados. Isso mostra como os dados são guardados de acordo com o tipo de informação.
Primeiro, vamos dar uma olhada em alguns modelos clássicos comuns usados em sistemas de gerenciamento de banco de dados.
Um modelo de dados hierárquico organiza os dados numa estrutura tipo árvore, onde cada registro (nó) tem um único pai (exceto a raiz) e pode ter vários filhos.
Exemplo (representação tipo XML):
<Customer id="1">
<Name>Alice Brown</Name>
<Orders>
<Order id="1" date="2025-08-01"/>
</Orders>
</Customer>Os equivalentes modernos geralmente aparecem no armazenamento XML/JSON, mas o modelo em si vem desde os primeiros DBMS de mainframe, como o IMS.
Um modelo de dados em rede é uma maneira flexível de representar dados e relações, especialmente útil para conexões complexas e muitos-para-muitos.
Ele usa uma estrutura gráfica com nós (que representam entidades) e arestas (que representam relações) para organizar os dados, permitindo caminhos de acesso mais eficientes e diretos em comparação com os modelos hierárquicos.
O modelo de dados relacional é uma maneira de organizar os dados em tabelas com linhas e colunas, permitindo armazenar, recuperar e gerenciar informações de forma eficiente.
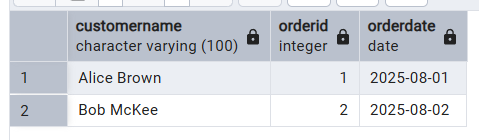
Exemplo de consulta do nosso conjunto de dados:
SELECT c.CustomerName, o.OrderID, o.OrderDate
FROM Customer c
JOIN Orders o ON c.CustomerID = o.CustomerID;Essa consulta mostra como usar a função ` JOIN ` para criar relações entre a tabela ` Customer ` e a tabela ` Orders `.
Isso gera a seguinte tabela como resultado:
Com o avanço da tecnologia de bancos de dados, alguns modelos modernos também surgiram. Aqui estão alguns exemplos:
O modelo orientado a objetos junta conceitos de banco de dados e programação orientada a objetos. Ele suporta herança e encapsulamento.
O modelo objeto-relacional é uma mistura do relacional e do orientado a objetos.
Os modelos de dados nosql são bem diferentes das estruturas rígidas baseadas em tabelas dos bancos de dados relacionais tradicionais, oferecendo esquemas flexíveis e vários métodos de organização de dados para lidar com grandes volumes de dados não estruturados e semiestruturados.
Aqui estão alguns exemplos de modelos nosql:
Aqui está um exemplo de um modelo de dados de documento (documento MongoDB):
{
"CustomerName": "Alice Brown",
"Orders": [
{"ProductName": "Laptop", "Quantity": 1}
]
}O processo de modelagem de dados rola em três níveis diferentes: conceitual, lógico e físico.
Esses níveis são os diferentes estágios de detalhe usados ao projetar um banco de dados ou sistema de informação. Eles ajudam a lidar com a complexidade, focando em partes específicas dos dados e na sua estrutura.
O modelo conceitual de dados é a abstração de nível mais alto e independente de tecnologia no processo de modelagem de dados. Ele foca em definir as principais entidades e suas relações em um sistema, sem entrar em detalhes técnicos.
Essa camada mostra os requisitos e as relações do negócio.
Exemplo: Nosso diagrama ER mostrando Customer → Orders.
O modelo de dados lógico é o segundo nível de abstração. Ele descreve entidades, atributos e relações sem mencionar nenhum banco de dados específico.
Essa camada transforma o modelo conceitual em um esquema específico do DBMS. Define tabelas, chaves e relações sem detalhes de armazenamento.
A camada do modelo de dados físicos implementa um esquema com índices, partições e parâmetros de armazenamento.
Aqui está um exemplo de um índice:
CREATE INDEX idx_order_customer ON Orders(CustomerID);Agora vamos ver esse índice usando essa consulta:
SELECT indexname, indexdef
FROM pg_indexes
WHERE tablename = 'orders';Como você pode ver no índice abaixo, criamos um novo índice chamado idx_order_customer.

A modelagem de dados é uma maneira organizada de transformar as necessidades do negócio em um plano técnico que decide como os dados vão ser armazenados, relacionados e recuperados.
Quando bem feita, a modelagem de dados reduz a redundância, melhora a qualidade dos dados e facilita a manutenção futura.

Fonte: Folha de referência sobre dimensões da qualidade dos dados
O processo geralmente acontece em etapas. Vamos analisar isso.
A coleta de requisitos é a base de todo o processo de modelagem de dados. Nesta fase, você está tentando entender quais são as necessidades do negócio e por quê.
Tem várias maneiras de juntar os requisitos de forma eficaz.
O resultado dessa fase deve ser um conjunto claro de requisitos documentados que descrevam as entidades de dados, as relações e as regras de negócios.
Por exemplo, no nosso conjunto de dados de varejo de amostra, as partes interessadas podem dizer que querem acompanhar os pedidos dos clientes, os produtos e as datas dos pedidos para poderem calcular métricas como o total de vendas por categoria de produto e as taxas de clientes recorrentes.
O design conceitual pega esses requisitos de negócios e transforma-os em uma representação visual de alto nível dos dados.
Nesta fase, você se concentra nas entidades existentes e em como elas se relacionam, sem se preocupar com detalhes técnicos, como tipos de chaves primárias ou estratégias de indexação.
É aí que entram os diagramas Entidade-Relacionamento (ER). Os diagramas ER mostram entidades (por exemplo, Cliente, Produto, Pedido), seus atributos e as relações entre elas.
Para o nosso conjunto de dados:
Customer pode incluir ID do cliente, nome, e-mail.Product pode incluir ID do produto, nome, categoria.Order pode incluir OrderID, OrderDate.OrderItem pode incluir OrderItemID, OrderID, ProductID, Quantidade, Preço.As relações podem ser:
Esse diagrama vira uma referência comum tanto para as equipes comerciais quanto para as técnicas.
O design lógico se baseia no modelo conceitual, aplicando regras de banco de dados, principalmente a normalização.
Normalização é o processo de organizar um banco de dados relacional para minimizar redundância e dependência. Isso geralmente é feito em etapas (1NF, 2NF, 3NF), cada uma com requisitos específicos.
No nosso exemplo, o endereço de e-mail do cliente só aparece na tabela Customer, sem estar duplicado na tabela Order. Da mesma forma, as informações sobre categorias de produtos devem ficar na tabela Product, e não espalhadas por vários registros em OrderItem.
O design físico pega o modelo lógico e adapta-o para um sistema de banco de dados específico, como PostgreSQL ou MySQL. Essa etapa envolve decisões sobre tipos de dados, otimização de armazenamento e ajuste de desempenho.
Os índices são uma consideração importante aqui. Por exemplo, adicionar um índice a OrderDate na tabela Order pode acelerar bastante as consultas que filtram por data.
A partição também pode ser usada em conjuntos de dados grandes, dividindo os dados em partes fáceis de gerenciar por data, intervalo ou chaves hash para melhorar o desempenho das consultas.
Você também decide sobre restrições, como chaves estrangeiras, para garantir a integridade dos dados no nível do banco de dados.
Depois que o design estiver pronto, é preciso fazer as validações antes de colocar no ar.
Isso envolve carregar dados de amostra, de preferência dados de teste realistas que reflitam os volumes esperados, e executar consultas que simulem o uso no mundo real.
Por exemplo, no nosso conjunto de dados de varejo, você pode fazer uma consulta para calcular os totais de vendas por mês, garantindo que os números correspondam ao que a empresa espera.
Você também testaria casos extremos, como o que acontece quando um pedido é feito sem itens (o que deveria ser impossível se as restrições estiverem corretas).
A última etapa é levar o projeto validado para a produção. Isso deve ser feito usando scripts de migração controlados por versão, para que as alterações sejam rastreadas ao longo do tempo.
A implantação também envolve configurar o monitoramento de desempenho e erros, além de garantir que o esquema esteja bem documentado para que futuras alterações possam ser feitas sem confusão.
Depois da implementação, é normal revisar o projeto de vez em quando, já que novos requisitos também aparecem.
Um modelo de dados bem projetado traz várias vantagens.
A modelagem de dados também pode ter métodos avançados para implementação.
A modelagem dimensional é comum no warehouse, onde o objetivo é tornar as consultas analíticas intuitivas e rápidas.
Isso envolve o uso de esquemas específicos:
OrderItems) guarda métricas, enquanto várias tabelas de dimensões (por exemplo, Customer, Product, Date) guardam atributos descritivos. Essa estrutura é fácil de consultar pelas ferramentas de BI.Aqui está como poderia ser:
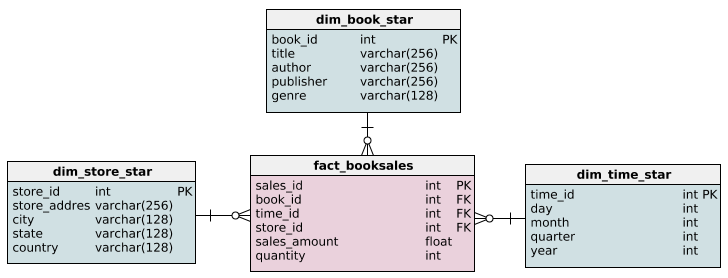
Fonte: Consultando o esquema em estrela
Product poderia ser dividido em tabelas Product e Category.A modelagem ER é mais comum em sistemas transacionais. Ele dá uma ênfase na normalização pra garantir a integridade dos dados. Em alguns casos, a desnormalização é aplicada de forma seletiva para melhorar o desempenho da leitura, especialmente para dados acessados com frequência.
A modelagem poliglota usa diferentes tipos de banco de dados para diferentes cargas de trabalho.
Por exemplo, você pode usar o PostgreSQL para transações de pedidos e o MongoDB para um catálogo de produtos com atributos flexíveis. Isso permite que você use a ferramenta certa para o trabalho certo, mas aumenta a complexidade operacional.
Nos sistemas nosql, o design geralmente é baseado em padrões de acesso em vez de uma normalização rígida. Os dados são organizados para minimizar o número de consultas necessárias para operações comuns, e o particionamento é essencial para evitar gargalos.
Sistemas relacionais como o PostgreSQL suportam totalmente as propriedades ACID. ACID, garantindo a consistência dos dados. Muitos bancos de dados nosql relaxam essas garantias para melhorar a velocidade e a escalabilidade, trocando a consistência pela convergência final.
Os modelos de dados são uma parte essencial do design de bancos de dados e podem ter várias formas. Mas, nas empresas de hoje, pra garantir que esses modelos funcionem da melhor maneira possível, é preciso fazer algumas otimizações.
A tecnologia está sempre mudando e sendo atualizada, e aprender e se adaptar o tempo todo é uma necessidade no setor de dados. Para saber mais sobre bancos de dados, confira nosso curso sobre Design de Banco de Dados ou Introdução a bancos de dados relacionais em SQL para começar.
Prefere ler? Nossos artigos sobre Ferramentas de Modelagem de Dados ou Perguntas de entrevista sobre DBMS podem ser úteis.
Cursos mais populares do DataCamp
Programa
Programa
Curso
blog
Matt Crabtree
10 min
blog
Mona Khalil
5 min
blog
Kurtis Pykes
11 min
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team

