
Cursus
Ingénieur de données en Python
40 h
Pour gérer efficacement et correctement une base de données, il est nécessaire de comprendre les principes fondamentaux des modèles de données.
Dans les systèmes de gestion de bases de données (SGBD), les modèles de données servent de plans architecturaux qui définissent la manière dont les informations sont stockées, reliées entre elles et accessibles.
Ils constituent la couche de traduction entre les exigences commerciales (« Nous devons suivre les clients, les commandes et les produits ») et la mise en œuvre technique (« Nous stockerons ces informations dans quatre tableaux reliés par des clés étrangères »).
Un modèle de données bien conçu contribue à :
Dans ce guide, nous examinerons les modèles de données classiques et modernes, les niveaux d'abstraction, les processus de conception et les stratégies d'optimisation avancées, le tout illustré à l'aide d'un ensemble de données de commerce électronique PostgreSQL.
Voici quelques raisons pour lesquelles il est important de connaître les modèles de données et leur importance.
Un modèle de données modèle de données dans un système de gestion de base de données (SGBD) est un plan utilisé par les les bases de données pour définir la manière dont les données sont organisées, stockées et accessibles.
Le modèle de données offre une méthode structurée pour représenter les éléments de données et leurs relations, permettant ainsi une gestion et une manipulation efficaces des données.
Disposer d'un modèle de données permet de répondre à des questions telles que :
Un modèle de données permet aux administrateurs de bases de données de comprendre facilement toutes les informations requises et les réponses à ces questions.
Un modèle de données structure et organise les informations contenues dans une base de données. Cela garantit la clarté et la cohérence dans la manière dont les données sont traitées au sein d'un système.
Voici quelques raisons courantes pour lesquelles un modèle de données est nécessaire :
Sans modèle de données défini, vous risquez de vous retrouver avec :
Voici une requête SQL simple illustrant comment une base de données peut être modifiée pour inclure une structure, des relations et des contraintes.
ALTER TABLE Orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (CustomerID)
REFERENCES Customer(CustomerID);Cela garantit que chaque commande est associée à un client existant, ce qui constitue un moyen simple mais efficace de maintenir l'intégrité.
Avant de poursuivre avec des explications plus approfondies, nous allons créer et utiliser un ensemble de données simple sur le commerce électronique afin d'illustrer les concepts présentés dans ce guide.
Nous inclurons les entités suivantes dans l'ensemble de données.
Voici un diagramme ER ASCII simple illustrant les relations entre les tableaux que nous allons créer.
Customer ───< Orders ───< OrderItems >─── ProductCela correspond à la logique suivante :
Ensuite, je vais créer les tableaux et les exécuter dans PostgreSQL afin de lancer les requêtes.
Voici le schéma et le code SQL permettant de créer les tableaux nécessaires.
CREATE TABLE Customer (
CustomerID SERIAL PRIMARY KEY,
CustomerName VARCHAR(100) NOT NULL,
Email VARCHAR(100) UNIQUE NOT NULL,
Phone VARCHAR(20),
CreatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE Product (
ProductID SERIAL PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Category VARCHAR(50),
Price NUMERIC(10, 2) NOT NULL
);
CREATE TABLE Orders (
OrderID SERIAL PRIMARY KEY,
CustomerID INT NOT NULL,
OrderDate DATE NOT NULL,
Status VARCHAR(20) DEFAULT 'Pending',
FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID)
);
CREATE TABLE OrderItems (
OrderItemID SERIAL PRIMARY KEY,
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity > 0),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);Ensuite, veuillez insérer quelques informations de base dans le
INSERT INTO Customer (CustomerName, Email, Phone)
VALUES
('Alice Brown’, 'alice@example.com', '91234567'),
('Bob McKee', 'bob@example.com', '98765432');
INSERT INTO Product (ProductName, Category, Price)
VALUES
('Laptop', 'Electronics', 1200.00),
('Wireless Mouse', 'Electronics', 25.50),
('Office Chair', 'Furniture', 150.00);
INSERT INTO Orders (CustomerID, OrderDate, Status)
VALUES
(1, '2025-08-01', 'Shipped'),
(2, '2025-08-02', 'Pending');
INSERT INTO OrderItems (OrderID, ProductID, Quantity)
VALUES
(1, 1, 1),
(1, 2, 2),
(2, 3, 1);Votre diagramme ER pour la base de données devrait ressembler à ceci :
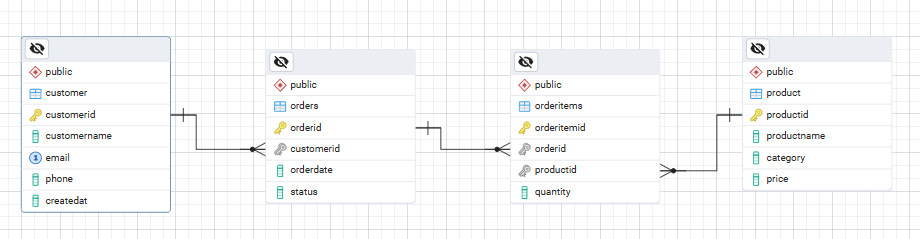
Un modèle de données robuste comprend quatre composantes principales :
Dans la modélisation des données, les entités représentent les objets ou concepts fondamentaux et distincts d'un système pour lesquels nous souhaitons stocker des données. Les entités sont souvent représentées sous forme de tableaux dans une base de données.
Exemples d'entités dans notre ensemble de données :
CustomerProductOrdersOrderItemsCes entités constituent les « noms » principaux de la base de données.
Les entités constituent la base. Tous les autres aspects du modèle, tels que les attributs, les relations et les contraintes, s'appuient sur ces éléments.
Dans la modélisation des données, les attributs sont des caractéristiques ou des propriétés qui décrivent une entité. Ils représentent les points de données spécifiques qui définissent une entité, comme le nom, l'adresse e-mail ou l'adresse postale d'un client.
Exemples :
Customer s : CustomerName, Email, Phone.Product s : ProductName, Price, Category.En termes simples, les attributs sont les détails qui vous intéressent pour chaque entité. Il s'agit généralement de colonnes dans un tableau.
Les relations dans un modèle de données définissent la manière dont différentes entités ou tableaux sont connectées, représentant les associations entre elles. Considérez-les comme des liens logiques entre les entités.
Exemples dans notre ensemble de données :
Customer ) peut avoir plusieurs entités ( Orders ) (relation 1-à-plusieurs).Order ) peut contenir plusieurs entités ( Products ) via une relation de type « OrderItems » (relation plusieurs-à-plusieurs résolue par une table de jonction).Les relations garantissent que le modèle de données représente fidèlement les associations du monde réel.
Dans la modélisation des données, les contraintes sont des règles qui limitent les valeurs autorisées dans une base de données, garantissant ainsi l'exactitude, la cohérence et l'intégrité des données.
Les contraintes contribuent à maintenir l'intégrité de la base de données en empêchant la saisie de données invalides ou incohérentes.
Exemples:
UNIQUE Contrainte sur Customer.Email.CHECK contrainte visant à garantir l'Quantity > 0 dans OrderItems.Exemple PostgreSQL
Voici un exemple d'utilisation de certains types de contraintes dans une requête SQL.
CREATE TABLE OrderItems_Constraint (
OrderItemID SERIAL PRIMARY KEY,
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity > 0),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);Dans cet exemple, nous avons utilisé les contraintes suivantes : PRIMARY, CHECK, NOT NULL et REFERENCES.
Il existe différents types de modèles de données dans les bases de données. Cela reflète la manière dont les données sont stockées en fonction de leur nature.
Tout d'abord, examinons quelques modèles classiques couramment utilisés dans les systèmes de gestion de bases de données.
Un modèle de données hiérarchique organise les données selon une structure arborescente, dans laquelle chaque enregistrement (nœud) possède un seul parent (à l'exception de la racine) et peut avoir plusieurs enfants.
Exemple (représentation de type XML) :
<Customer id="1">
<Name>Alice Brown</Name>
<Orders>
<Order id="1" date="2025-08-01"/>
</Orders>
</Customer>Les équivalents modernes apparaissent souvent dans le stockage XML/JSON, mais le modèle lui-même remonte aux premiers SGBD pour ordinateurs centraux tels que IMS.
Un modèle de données en réseau constitue une méthode flexible pour représenter les données et les relations, particulièrement utile pour les connexions complexes et multiples.
Il utilise une structure graphique avec des nœuds (représentant des entités) et des arêtes (représentant des relations) pour organiser les données, ce qui permet des chemins d'accès plus efficaces et plus directs par rapport aux modèles hiérarchiques.
Le modèle de données relationnel est une méthode permettant de structurer les données en tableaux composés de lignes et de colonnes, ce qui facilite le stockage, la récupération et la gestion efficaces des informations.
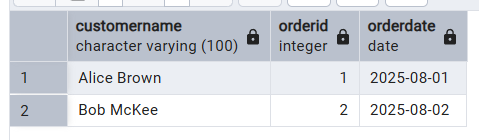
Exemple de requête à partir de notre ensemble de données :
SELECT c.CustomerName, o.OrderID, o.OrderDate
FROM Customer c
JOIN Orders o ON c.CustomerID = o.CustomerID;Cette requête illustre l'utilisation de la fonction JOIN pour établir des relations entre la table Customer et la table Orders.
Ceci génère le tableau suivant :
À mesure que la technologie des bases de données progresse, certains modèles modernes ont également fait leur apparition. Voici quelques exemples :
Le modèle orienté objet combine les concepts de base de données et de programmation orientée objet. Il prend en charge l'héritage et l'encapsulation.
Le modèle objet-relationnel est un hybride entre le modèle relationnel et le modèle orienté objet.
Les modèles de données nosql s'éloignent des structures rigides basées sur des tableaux des bases de données relationnelles traditionnelles, offrant des schémas flexibles et diverses méthodes d'organisation des données pour traiter de grands volumes de données non structurées et semi-structurées.
Voici quelques exemples de modèles nosql :
Voici un exemple de modèle de données de document (document MongoDB) :
{
"CustomerName": "Alice Brown",
"Orders": [
{"ProductName": "Laptop", "Quantity": 1}
]
}Le processus de modélisation des données se déroule à trois niveaux différents : conceptuel, logique et physique.
Ces niveaux correspondent aux différentes étapes de détail utilisées lors de la conception d'une base de données ou d'un système d'information. Ils contribuent à gérer la complexité en se concentrant sur des aspects spécifiques des données et de leur structure.
Le modèle de données conceptuel est l'abstraction de plus haut niveau, indépendante de la technologie, dans le processus de modélisation des données. Il se concentre sur la définition des entités clés et de leurs relations dans un système sans entrer dans les détails techniques.
Cette couche capture les exigences et les relations commerciales.
Exemple : Notre diagramme ER illustrant l'Customer e → Orders.
Le modèle de données logique représente le deuxième niveau d'abstraction. Il décrit les entités, les attributs et les relations sans mentionner de base de données spécifique.
Cette couche transforme le modèle conceptuel en un schéma spécifique au SGBD. Il définit les tableaux, les clés et les relations sans détails de stockage.
La couche du modèle de données physiques implémente un schéma avec des index, des partitions et des paramètres de stockage.
Voici un exemple d'index :
CREATE INDEX idx_order_customer ON Orders(CustomerID);Nous allons maintenant examiner cet index à l'aide de cette requête :
SELECT indexname, indexdef
FROM pg_indexes
WHERE tablename = 'orders';Comme vous pouvez le constater dans l'index ci-dessous, nous avons créé un nouvel index appelé idx_order_customer.

La modélisation des données est une approche structurée visant à traduire les besoins opérationnels en un plan technique qui régit la manière dont les données seront stockées, reliées et récupérées.
Lorsqu'elle est effectuée correctement, la modélisation des données réduit la redondance, améliore la qualité des données et facilite la maintenance future.

Source : Fiche récapitulative sur les dimensions de la qualité des données
Le processus se déroule généralement par étapes. Analysons ces éléments.
La collecte des exigences constitue la base de l'ensemble du processus de modélisation des données. À ce stade, vous essayez de comprendre les besoins de l'entreprise et les raisons qui les motivent.
Il existe plusieurs méthodes pour recueillir efficacement les exigences.
Le résultat de cette phase devrait être un ensemble clair d'exigences documentées décrivant les entités de données, les relations et les règles métier.
Par exemple, dans notre échantillon de données de vente au détail, les parties prenantes pourraient indiquer qu'elles souhaitent suivre les commandes des clients, les produits et les dates de commande afin de pouvoir calculer des indicateurs tels que le chiffre d'affaires total par catégorie de produits et le taux de fidélisation des clients.
La conception conceptuelle prend en compte ces exigences commerciales et les transforme en une représentation visuelle de haut niveau des données.
À ce stade, vous vous concentrez sur les entités existantes et leurs relations, sans vous préoccuper des détails techniques tels que les types de clés primaires ou les stratégies d'indexation.
C'est là que les diagrammes entité-relation (ER) prennent toute leur importance. Les diagrammes ER représentent les entités (par exemple, Client, Produit, Commande), leurs attributs et les relations entre elles.
Pour notre ensemble de données :
Customer peut inclure l'identifiant client, le nom et l'adresse e-mail.Product peut inclure le numéro d'identification du produit, le nom et la catégorie.Order peut inclure OrderID, OrderDate.OrderItem peut inclure OrderItemID, OrderID, ProductID, Quantity, Price.Les relations pourraient être les suivantes :
Ce diagramme constitue un point de référence commun pour les équipes commerciales et techniques.
La conception logique s'appuie sur le modèle conceptuel en appliquant les règles relatives aux bases de données, en particulier la normalisation.
La normalisation est le processus qui consiste à structurer une base de données relationnelle afin de minimiser la redondance et la dépendance. Ce processus est généralement réalisé par étapes (1NF, 2NF, 3NF), chacune comportant des exigences spécifiques.
Dans notre exemple, l'adresse e-mail du client figure uniquement dans la table Customer et n'est pas dupliquée dans la table Order. De même, les informations relatives aux catégories de produits devraient être regroupées dans la table Product, et non dispersées dans plusieurs enregistrements de la table OrderItem.
La conception physique adapte le modèle logique à un système de base de données spécifique, tel que PostgreSQL ou MySQL. Cette étape implique la prise de décisions concernant les types de données, l'optimisation du stockage et l'amélioration des performances.
Les index constituent un élément essentiel à prendre en considération dans ce contexte. Par exemple, l'ajout d'un index à OrderDate dans le tableau Order peut considérablement accélérer les requêtes filtrées par date.
Le partitionnement peut également être appliqué à des ensembles de données volumineux, en divisant les données en segments gérables par date, plage ou clés de hachage afin d'améliorer les performances des requêtes.
Vous définissez également des contraintes, telles que les clés étrangères, afin de garantir l'intégrité des données au niveau de la base de données.
Une fois la conception terminée, des validations doivent être effectuées avant la mise en service.
Cela implique de charger des données échantillons, idéalement des données de test réalistes qui reflètent les volumes attendus, et d'exécuter des requêtes qui simulent une utilisation réelle.
Par exemple, dans notre ensemble de données sur le commerce de détail, vous pourriez exécuter une requête pour calculer le total des ventes par mois, afin de vous assurer que les chiffres correspondent aux attentes de l'entreprise.
Vous testeriez également les cas limites, par exemple ce qui se passe lorsqu'une commande est passée sans aucun article (ce qui devrait être impossible si les contraintes sont correctes).
La dernière étape consiste à mettre en production la conception validée. Il est recommandé d'utiliser des scripts de migration contrôlés par version afin de pouvoir suivre les modifications au fil du temps.
Le déploiement implique également la mise en place d'un suivi des performances et des erreurs, ainsi que la vérification que le schéma est bien documenté afin que les modifications futures puissent être effectuées sans confusion.
Après le déploiement, il est courant de revoir périodiquement la conception à mesure que de nouvelles exigences apparaissent.
Un modèle de données bien conçu offre de nombreux avantages.
La modélisation des données peut également faire appel à des méthodes avancées pour sa mise en œuvre.
La modélisation dimensionnelle est couramment utilisée dans le domaine du stockage de données, où l'objectif est de rendre les requêtes analytiques intuitives et rapides.
Cela implique l'utilisation de schémas spécifiques:
OrderItems) stocke les métriques, tandis que plusieurs tableaux de dimensions (par exemple, Customer, Product, Date) stockent les attributs descriptifs. Cette structure est facile à interroger pour les outils BI.Voici à quoi cela pourrait ressembler :
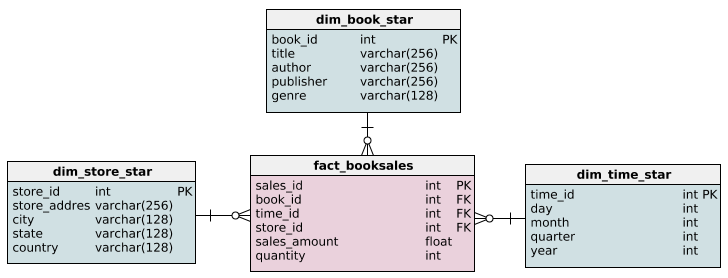
Source : Interroger le schéma en étoile
Product pourrait être divisé en deux tableaux distincts : Product et Category.La modélisation ER est plus courante dans les systèmes transactionnels. Il met l'accent sur la normalisation afin de garantir l'intégrité des données. Dans certains cas, la dénormalisation est appliquée de manière sélective afin d'améliorer les performances de lecture, en particulier pour les données fréquemment consultées.
La modélisation polyglotte utilise différents types de bases de données pour différentes charges de travail.
Par exemple, vous pourriez utiliser PostgreSQL pour les transactions de commande et MongoDB pour un catalogue de produits avec des attributs flexibles. Cela vous permet d'utiliser l'outil approprié pour chaque tâche, mais cela augmente la complexité opérationnelle.
Dans les systèmes nosql, la conception est souvent basée sur les modèles d'accès plutôt que sur une normalisation stricte. Les données sont organisées de manière à minimiser le nombre de requêtes nécessaires pour les opérations courantes, et le partitionnement est essentiel pour éviter les goulots d'étranglement.
Les systèmes relationnels tels que PostgreSQL prennent entièrement en charge les propriétés ACID. propriétés ACID, garantissant ainsi la cohérence des données. De nombreuses bases de données nosql assouplissent ces garanties afin d'améliorer la vitesse et l'évolutivité, privilégiant la convergence finale au détriment de la cohérence.
Les modèles de données constituent un élément essentiel de la conception d'une base de données et peuvent prendre différentes formes. Cependant, dans les entreprises modernes, afin de garantir que ces modèles puissent atteindre leur meilleur rendement, des optimisations doivent être effectuées en conséquence.
La technologie évolue et se renouvelle constamment, et l'apprentissage et l'adaptation continus sont indispensables dans le secteur des données. Pour en savoir plus sur les bases de données, veuillez consulter notre cours sur la Conception de bases de données ou Introduction aux bases de données relationnelles en SQL pour vous familiariser avec le sujet.
Vous préférez lire ? Nos articles sur les outils de modélisation de données Outils de modélisation des données ou questions d'entretien sur les SGBD pourraient vous être utiles.
Meilleurs cours DataCamp
Cursus
Cursus
Cours