programa
Fundamentos de SQL
26 h
En el mundo actual, impulsado por los datos, nos enfrentamos a un reto importante: ¿cómo almacenamos, gestionamos y extraemos información significativa de los datos de forma eficaz? Las bases de datos ofrecen una solución, proporcionando depósitos estructurados para organizar y acceder a la información.
Sin embargo, para hacer frente a los requisitos únicos de diversas estructuras de datos y casos de uso, han surgido distintos tipos de bases de datos.
En este artículo, exploraremos los cuatro tipos principales que encontrarás en el mundo de la ciencia de datos: bases de datos relacionales, bases de datos NoSQL, bases de datos en la nube y bases de datos vectoriales.
Si quieres aprender sobre diseño de bases de datos, consulta este curso sobre Diseño de Bases de Datos.
Las bases de datos son herramientas esenciales en el mundo digital. Son colecciones organizadas de datos que facilitan el almacenamiento, la recuperación, la gestión y la manipulación de la información.
En esencia, las bases de datos están diseñadas para almacenar datos en un formato estructurado, permitiendo a los usuarios y a las aplicaciones acceder a la información de forma eficaz y actualizarla cuando sea necesario.
La importancia de las bases de datos se extiende a casi todos los campos, pero es especialmente crítica en la ciencia de datos. Los proyectos de ciencia de datos a menudo implican el análisis de grandes volúmenes de datos para obtener ideas, hacer predicciones o fundamentar la toma de decisiones.
Sin bases de datos, la gestión de estos datos -especialmente a medida que crecen en tamaño y complejidad- sería engorrosa y propensa a errores. Las bases de datos proporcionan una forma sistemática de almacenar datos y garantizar su integridad, seguridad y accesibilidad.
Piensa, por ejemplo, en una empresa minorista que realiza un seguimiento de las ventas, las interacciones con los clientes, el inventario y la información sobre los proveedores. Una base de datos sirve de columna vertebral de las operaciones de la empresa, permitiéndoles analizar tendencias, prever la demanda, optimizar los niveles de inventario y mejorar la experiencia del cliente.
Sin una base de datos, la empresa tendría dificultades para manejar las enormes cantidades de datos que se generan a diario, por no hablar de utilizar estos datos para tomar decisiones empresariales con conocimiento de causa.
Los distintos tipos de bases de datos reflejan las variadas necesidades de los casos de uso y la complejidad de los datos que manejan. Se desarrollan distintos tipos de bases de datos para optimizar el rendimiento, mejorar la funcionalidad y atender a casos de uso específicos.
Esta variedad no es sólo una cuestión de abundancia tecnológica, sino también una necesidad para hacer frente a los retos y requisitos únicos que surgen en los distintos casos de uso. La necesidad de distintos tipos de bases de datos se debe a las diferencias en las estructuras de datos, los patrones de acceso, las exigencias de escalabilidad y los requisitos de coherencia.
Por ejemplo, las aplicaciones empresariales tradicionales suelen basarse en datos estructurados que encajan bien en tablas con esquemas predefinidos, lo que hace que las bases de datos relacionales sean una opción ideal.
Sin embargo, con el auge de los big data, las redes sociales y los análisis en tiempo real, se hicieron evidentes las limitaciones de las bases de datos relacionales para manejar datos no estructurados, escalar horizontalmente o gestionar datos altamente conectados.
Esto condujo a la aparición de las bases de datos NoSQL, diseñadas para ofrecer flexibilidad, escalabilidad y ventajas de rendimiento para determinados tipos de datos que no se ajustan a la estructura rígida de las bases de datos tradicionales. Si quieres saber más sobre cómo se comparan las bases de datos SQL y NoSQL, consulta este tutorial sobre Bases de datos SQL vs NoSQL.
Del mismo modo, la llegada del IoT y las aplicaciones sensibles al tiempo hicieron necesario el desarrollo de bases de datos de series temporales optimizadas para manejar eficazmente los datos temporales.
También han ganado importancia las bases de datos en la nube , que ofrecen escalabilidad y accesibilidad alojando los datos en servidores remotos.
Además, las bases de datos vectoriales han surgido para satisfacer las necesidades específicas de las aplicaciones de aprendizaje automático, almacenando y consultando eficazmente vectores de alta dimensión.
La clasificación DB-Engines de mayo de 2024 enumera los principales sistemas de gestión de bases de datos (SGBD) en función de su popularidad. Esta clasificación se actualiza mensualmente e incluye 420 sistemas. En mayo de 2024, las cuatro principales bases de datos serán relacionales: Oracle, MySQL, Microsoft SQL y PostgreSQL.
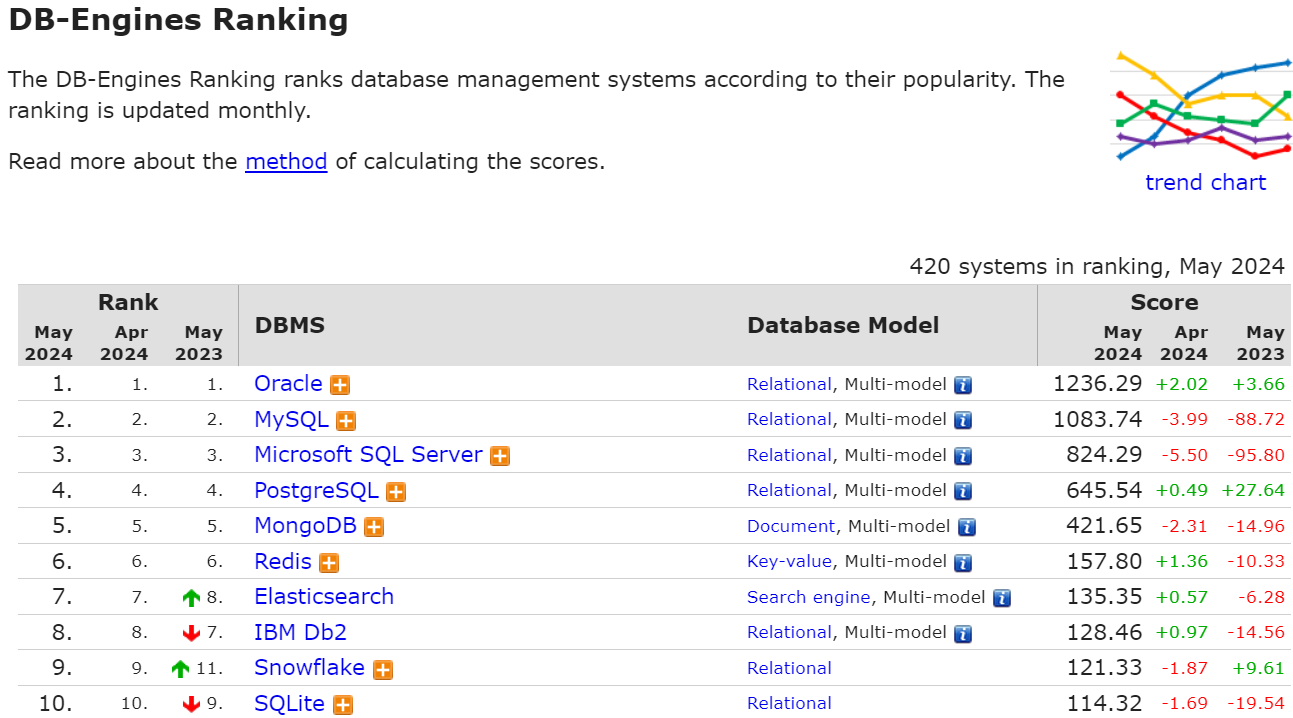
Fuente: db-engines
Cabe destacar que las bases de datos NoSQL como MongoDB y Redis también ocupan posiciones destacadas en la clasificación, lo que refleja la creciente demanda de soluciones flexibles y escalables capaces de gestionar datos no estructurados y aplicaciones de alto tráfico. Estos sistemas NoSQL han experimentado un importante crecimiento interanual, lo que indica un cambio hacia arquitecturas de bases de datos más diversas.
La clasificación también revela la creciente popularidad de las bases de datos basadas en la nube, como Snowflake, que ofrece una solución de almacén de datos totalmente gestionada y escalable. Elasticsearch, un potente motor de búsqueda y plataforma de análisis, también ha subido en la clasificación, subrayando la importancia de las capacidades de búsqueda y análisis en la gestión moderna de datos.
Veamos ahora el siguiente gráfico lineal, que ilustra el panorama dinámico de la popularidad de las bases de datos de 2014 a 2024.
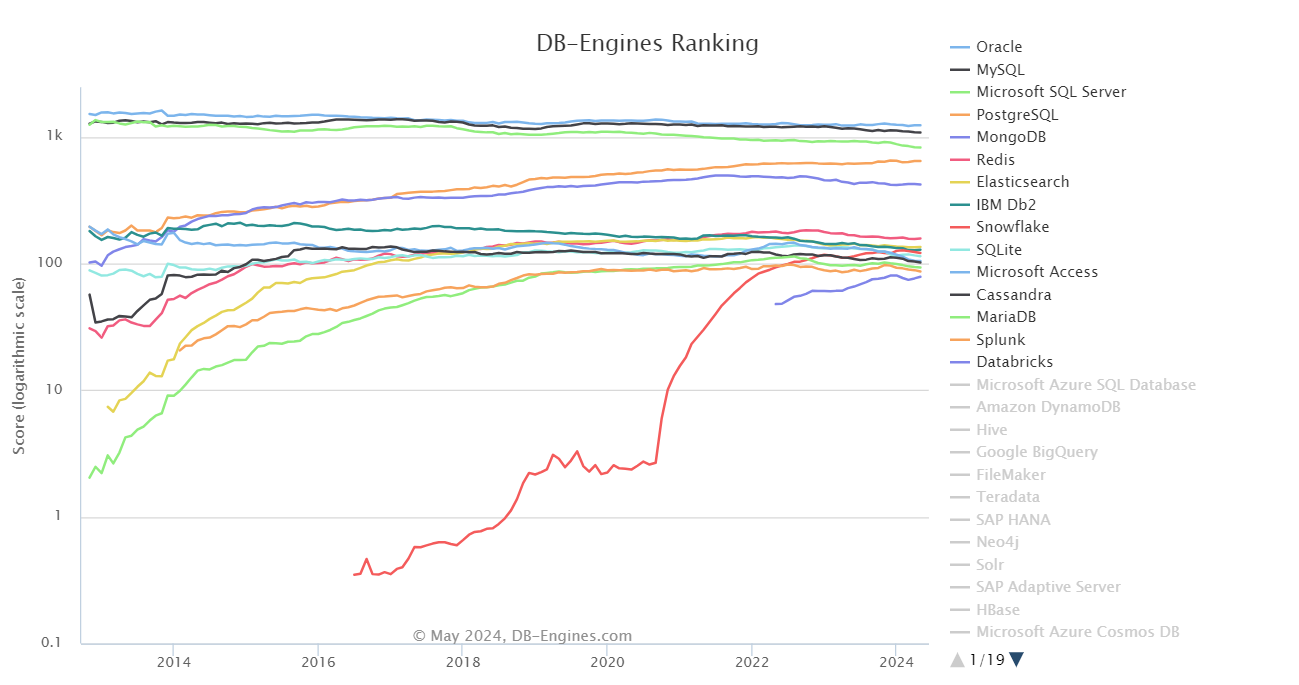
Fuente: db-engines
Un aspecto clave es el dominio duradero de los sistemas de gestión de bases de datos relacionales (RDBMS) como Oracle, MySQL, Microsoft SQL Server y PostgreSQL. Éstas han mantenido sistemáticamente sus primeras posiciones a lo largo de la década, lo que pone de relieve su importancia en el tratamiento de datos estructurados y el apoyo a consultas complejas en diversas aplicaciones.
Sin embargo, el gráfico también revela un cambio notable en los últimos años. Mientras que los sistemas RDBMS han experimentado un descenso gradual de popularidad, las bases de datos NoSQL como MongoDB y Redis han experimentado un crecimiento significativo. Esta trayectoria ascendente refleja la creciente adopción de estas soluciones flexibles y escalables para gestionar datos no estructurados y dar cabida a aplicaciones de alto tráfico.
Otra tendencia interesante es el auge de las bases de datos basadas en la nube. Databricks, una plataforma de ingeniería de datos y aprendizaje automático basada en la nube, ha disparado su popularidad, mostrando la creciente demanda de soluciones basadas en la nube que ofrezcan escalabilidad, facilidad de uso y potentes capacidades analíticas.
Del mismo modo, Snowflake, un almacén de datos en la nube totalmente gestionado, ha experimentado un crecimiento significativo, lo que pone de relieve el atractivo de su arquitectura escalable y fácil de usar.
Las bases de datos relacionales almacenan los datos en tablas estructuradas en filas y columnas. Cada fila representa un registro único, y cada columna representa un atributo específico de ese registro.
Imagínatelas como hojas de cálculo meticulosamente organizadas, donde los datos se almacenan en tablas compuestas por filas (registros) y columnas (atributos). Cada fila representa una entidad distinta, como un cliente o un producto, mientras que cada columna captura una característica específica, como un nombre, una dirección o un precio.
El verdadero poder de las bases de datos relacionales reside en su capacidad para enlazar estas tablas mediante relaciones. Estas relaciones, establecidas mediante claves foráneas, nos permiten conectar datos de distintas tablas, creando una visión unificada de la información.
Por ejemplo, en un sistema de gestión de relaciones con los clientes (CRM), una tabla de clientes podría estar vinculada a una tabla de pedidos, lo que nos permitiría seguir el historial de compras de un cliente.
Para interactuar con las bases de datos relacionales, utilizamos el Lenguaje de Consulta Estructurado (SQL). Este potente lenguaje nos permite consultar, insertar, actualizar y eliminar datos, así como realizar operaciones complejas como unir datos de varias tablas. La naturaleza estructurada de SQL garantiza la integridad y coherencia de los datos mediante las propiedades ACID:
Si quieres aprender más sobre SQL, consulta este temario de siete cursos sobre Fundamentos de SQL.
Las bases de datos relacionales son estupendas cuando necesitamos
Sin embargo, puede que no sean los más adecuados para:
Algunas opciones populares de RDBMS son
Si quieres aprender a utilizar bases de datos relacionales en Python, consulta este curso gratuito sobre Introducción a las Bases de Datos en Python.
Las bases de datos NoSQL, abreviatura de "no sólo SQL", han surgido como una potente alternativa a las bases de datos relacionales, sobre todo en escenarios en los que la flexibilidad, la escalabilidad y el alto rendimiento son primordiales.
A diferencia de sus homólogas relacionales, las bases de datos NoSQL pueden manejar datos no estructurados o semiestructurados sin las restricciones de un esquema fijo. Esto significa que podemos almacenar datos en varios formatos, como documentos JSON, pares clave-valor o estructuras de grafos, sin tener que definir una estructura rígida por adelantado.
Estas bases de datos suelen ofrecer funciones para escalar a través de múltiples servidores y clusters, lo que las hace adecuadas para entornos de datos distribuidos.
A diferencia de las bases de datos relacionales, que utilizan el Lenguaje de Consulta Estructurado (SQL), las bases de datos NoSQL no tienen un lenguaje de consulta universal. En su lugar, cada tipo de base de datos NoSQL suele tener su propio lenguaje de consulta o API adaptado a su modelo y estructura de datos específicos.
Aunque las bases de datos NoSQL priorizan la flexibilidad y la escalabilidad, a menudo relajan algunas de las propiedades ACID que se encuentran en las bases de datos relacionales. Por ejemplo, algunas bases de datos NoSQL priorizan la coherencia eventual sobre la inmediata, lo que significa que los cambios pueden no reflejarse en todos los nodos al instante. Esta compensación permite un mejor rendimiento y escalabilidad, pero requiere una cuidadosa consideración cuando se diseñan aplicaciones que dependen de una estricta coherencia de los datos.
Si quieres aprender a consultar bases de datos NoSQL, consulta este curso de Introducción a NoSQL.
Las bases de datos NoSQL son especialmente adecuadas para escenarios en los que:
Los casos de uso más comunes son:
Aunque ofrecen ventajas significativas, las bases de datos NoSQL pueden no ser ideales para aplicaciones que requieren fuertes garantías transaccionales o consultas relacionales complejas. Muchas organizaciones adoptan un enfoque híbrido, utilizando bases de datos relacionales y NoSQL para aprovechar sus respectivos puntos fuertes.
Algunas de las bases de datos NoSQL más populares son:
Si quieres saber más sobre las cuatro principales bases de datos NoSQL, consulta este curso sobre Conceptos NoSQL.
Las bases de datos en la nube han revolucionado la gestión de datos aprovechando los vastos recursos y la escalabilidad de las plataformas de computación en la nube. Estas bases de datos residen en servidores remotos y se accede a ellas a través de Internet, eliminando la necesidad de que las organizaciones inviertan y mantengan su propio hardware e infraestructura.
Las bases de datos en la nube funcionan con un modelo de pago por uso, en el que sólo pagamos por los recursos que realmente utilizamos. Esto elimina los costes iniciales y los gastos continuos de mantenimiento asociados a las bases de datos locales tradicionales. Los proveedores de la nube se encargan de la infraestructura subyacente, incluidos los servidores, el almacenamiento y las redes, mientras tú te centras en crear y gestionar tus aplicaciones.
Si quieres aprender sobre la computación en nube, consulta este curso sobre Comprender la computación en nube.
La consulta de bases de datos en la nube suele implicar el uso de las mismas herramientas y lenguajes que utilizaríamos con las bases de datos locales. Para las bases de datos relacionales en la nube, utilizaríamos SQL para interactuar con los datos. Las bases de datos NoSQL en la nube suelen tener sus propios lenguajes de consulta o API, similares a sus homólogas locales.
Los proveedores de la nube suelen ofrecer herramientas y servicios adicionales para simplificar la gestión y consulta de las bases de datos. Pueden incluir consolas basadas en la web, interfaces de línea de comandos y SDK para varios lenguajes de programación.
Las bases de datos en la nube son una opción excelente cuando:
Los principales proveedores de la nube ofrecen una serie de servicios de bases de datos, cada uno con sus propios puntos fuertes y especialidades:
Puedes obtener más información sobre las bases de datos en la nube en este curso sobre Tecnología y servicios en la nube de AWS.
Las bases de datos vectoriales han surgido como una herramienta especializada para manejar las demandas únicas de las aplicaciones de inteligencia artificial y aprendizaje automático.
Las bases de datos vectoriales están diseñadas para almacenar, indexar y gestionar incrustaciones vectoriales, que son representaciones de datos de alta dimensión utilizadas a menudo en modelos de aprendizaje automático. Esto permite una búsqueda eficaz de similitudes, en la que la base de datos puede identificar rápidamente los vectores que están "cerca" de un vector de consulta dado, basándose en métricas de distancia como la similitud coseno o la distancia euclídea.
Estas características los hacen adecuados para aplicaciones como el reconocimiento de imágenes, los sistemas de recomendación y el procesamiento del lenguaje natural. Utilizan estructuras de indexación que optimizan la recuperación de vectores similares basándose en métricas de distancia.
Si quieres saber más sobre las bases de datos vectoriales, puedes leer este artículo: Introducción a las bases de datos vectoriales para el aprendizaje automático.
La consulta de una base de datos vectorial suele implicar los siguientes pasos:
Las distintas bases de datos vectoriales pueden ofrecer varias opciones y parámetros de consulta, como especificar el número de vecinos más próximos que se devolverán o establecer un umbral de distancia. Algunas bases de datos también admiten el filtrado basado en metadatos o la combinación de la búsqueda vectorial con el filtrado escalar tradicional.
Las bases de datos vectoriales son especialmente adecuadas para escenarios en los que:
Si quieres saber más sobre cuáles son las bases de datos más populares, consulta este artículo sobre Las 5 mejores bases de datos vectoriales.
Aunque las bases de datos relacionales, NoSQL, en la nube y vectoriales cubren una amplia gama de casos de uso, existen otros tipos de bases de datos, cada uno adaptado a modelos de datos y patrones de acceso específicos. Exploremos brevemente algunas de estas soluciones especializadas.
Las bases de datos de series temporales están optimizadas para almacenar y analizar datos con fecha y hora, como lecturas de sensores, precios de acciones o registros de servidores. Destacan en la ingestión de grandes volúmenes de datos y en la consulta eficaz de puntos de datos basados en intervalos de tiempo. Entre las opciones más populares están InfluxDB, TimescaleDB y Prometheus.
Las bases de datos orientadas a objetos (OODB) almacenan los datos como objetos, de forma similar a la programación orientada a objetos. Esto puede simplificar el modelado de estructuras y relaciones de datos complejas. Sin embargo, las OODB no se han adoptado de forma generalizada debido a los problemas de normalización y optimización de las consultas. Las opciones más populares son ObjectDB y Versant Object Database.
Las bases de datos de grafos son excelentes para representar y consultar relaciones entre entidades. Almacenan los datos como nodos (entidades) y aristas (relaciones), lo que los hace muy adecuados para redes sociales, motores de recomendación, sistemas de detección de fraudes y grafos de conocimiento. Algunas opciones populares son Neo4j, Amazon Neptune y JanusGraph.
Las bases de datos jerárquicas organizan los datos en una estructura arborescente, con relaciones padre-hijo entre los registros. Esta estructura es adecuada para algunas aplicaciones especializadas, pero puede resultar poco flexible para modelos de datos complejos. Aunque históricamente importantes, las bases de datos jerárquicas son menos habituales en las aplicaciones modernas.
Las bases de datos en red son similares a las bases de datos jerárquicas, pero permiten relaciones más complejas entre los registros. Aunque ofrecen flexibilidad, también pueden ser más difíciles de gestionar y consultar. Las bases de datos en red han sido sustituidas en gran medida por bases de datos relacionales y gráficas en la mayoría de las aplicaciones.
En este resumen, hemos explorado el variado panorama de las bases de datos, cada tipo adaptado para abordar retos de datos específicos. Desde los datos estructurados en bases de datos relacionales hasta la flexibilidad de NoSQL, la escalabilidad de las soluciones en la nube y las capacidades especializadas de las bases de datos vectoriales, hemos visto cómo estas herramientas apuntalan la gestión moderna de datos.
Elegir la base de datos adecuada es una decisión crítica, que depende de la comprensión de las ventajas y desventajas únicas de cada tipo. Evaluando cuidadosamente tus necesidades y limitaciones específicas, puedes seleccionar la base de datos que mejor potencie tus aplicaciones e iniciativas basadas en datos.
Si quieres profundizar más en las bases de datos, puedes probar este curso de cuatro cursos sobre SQL para Administradores de Bases de Datos.
Más información sobre bases de datos
programa
Curso
Curso
blog
Kurtis Pykes
11 min
blog
Mona Khalil
5 min
Tutorial
Sejal Jaiswal