
Programa
Fundações para Snowflake
7 h
À medida que as equipes de dados modernas adotam pilhas analíticas cada vez mais complexas, tem havido uma mudança para a criação de práticas padrão dentro dos fluxos de trabalho de engenharia de dados. Ferramentas como o dbt (Data Build Tool) são uma estrutura de código aberto que traz as melhores práticas de engenharia de software — como controle de versão, testes e documentação — para os fluxos de trabalho de análise.
A combinação do dbt com o Snowflake (um warehouse nativo da nuvem) virou uma pedra fundamental dos fluxos de trabalho de engenharia analítica. Este guia fala sobre os conceitos básicos, a configuração e as estratégias avançadas de implementação para integrar o dbt com o Snowflake, ajudando as equipes de dados a terem pipelines de dados mais fáceis de manter, seguros e com melhor desempenho.
Se você está começando a usar essas ferramentas, recomendo que faça nosso programa de habilidades Snowflake Foundations e o curso Introdução ao dbt.
Vamos falar sobre como o dbt e o Snowflake funcionam juntos. Esta seção apresenta os recursos do dbt e destaca sua compatibilidade com o Snowflake e os benefícios de integrá-los.
O dbt (Data Build Tool) é uma estrutura de código aberto que permite que as equipes de dados transformem, testem e documentem dados diretamente em seu warehouse usando SQL aprimorado com modelos Jinja.
O dbt não é uma linguagem de programação em si; ele funciona como um compilador, pegando modelos SQL modulares e transformando-os em consultas SQL executáveis que rodam no warehouse (por exemplo, Snowflake).
Ao juntar controle de versão, testes automáticos e documentação, o dbt traz práticas comprovadas de engenharia de software para a engenharia de análise, tornando os pipelines de transformação mais confiáveis, fáceis de manter e escaláveis como parte de um fluxo de trabalho ELT.
Seus principais componentes incluem um compilador e um executor. Aqui estão suas funções:
Para que o dbt funcione, tem alguns componentes que ajudam tudo a fluir:
select salvas como arquivos .sql.Pra saber mais sobre o dbt, recomendo esse curso super legal de introdução ao dbt.
Usando os modelos baseados em Jinja do dbt junto com os tipos de dados poderosos do Snowflake, como Streams, a gente pode ser bem criativo com nossos fluxos de trabalho de transformação.
Por exemplo, talvez a gente queira transformar só os dados recém-carregados ou fazer transformações diferentes nas nossas tabelas de preparação em comparação com as nossas tabelas de produção, pra poder fazer verificações de integridade dos dados.
Os dois estão rapidamente se tornando uma combinação comum para ajudar os engenheiros de dados a obter mais controle e flexibilidade de seus pipelines de dados, com mais empresas adotando o dbt regularmente.
O dbt traz várias vantagens: metodologia tradicional de desenvolvimento de software, testes automatizados e melhorias na produtividade.
Podemos tratar nossos dados e SQL mais como código tradicional. Isso nos dá acesso à modularidade, testabilidade e controle de versão. Aproveitando os modelos e as instruções de controle de fluxo do Python, a gente consegue algumas funcionalidades bem legais do dbt.
Usando a configuração integrada do dbt ( data_test ), podemos fazer testes regulares nos nossos dados sem precisar de pipelines SQL complicados. Na verdade, o dbt já vem com alguns testes básicos poderosos que podemos implementar facilmente em nossos arquivos de configuração.
Dentro do dbt tem coisas como geradores de documentação e visualizadores de pipeline. Os novos membros da equipe podem ser integrados mais rapidamente e os membros existentes podem obter uma compreensão mais profunda dos fluxos de dados. Isso ajuda a reduzir o tempo de adaptação e melhora a compreensão geral de todos sobre o fluxo de trabalho.
Tem várias vantagens em usar a plataforma baseada em nuvem da Snowflake. Tem uma arquitetura incrível que separa os recursos de armazenamento e computação para minimizar conflitos de recursos e melhorar os custos. Ele usa a clonagem sem cópia, que deixa os usuários criarem clones de bancos de dados sem precisar de armazenamento extra.
Além disso, ele suporta alguns tipos de dados de tabela complexos, como tabelas dinâmicas e Streams, que permitem uma lógica de atualização incremental. Para mais detalhes sobre o Snowflake como plataforma, confira este artigo que explica como o Snowflake funciona.
E o mais importante, esses recursos são super complementares ao dbt. A gente pode usar a atualização incremental pra ajudar o dbt a acionar transformações com base em novos dados. Também podemos aproveitar a separação entre computação e armazenamento do Snowflake, que permite que o dbt faça transformações mais intensas em termos computacionais sem afetar a capacidade de carregar e armazenar dados.
Tudo isso vem com a capacidade do Snowflake de crescer rapidinho e seu modelo de custo por uso. À medida que nossos scripts dbt ficam mais complexos, dá pra aumentar facilmente o tamanho dos nossos warehouses de computação Snowflake pra atender a essas demandas. Ao mesmo tempo, podemos usar o monitoramento do Snowflake para otimizar nossos warehouses e usar o dbt para melhorar o desempenho das nossas consultas.
Quando combinados, o Snowflake e o dbt funcionam muito bem juntos. O ajuste constante do Snowflake ajuda a manter baixos os custos baseados na nuvem. O dbt pode aproveitar métodos de particionamento de tabelas, como chaves de agrupamento e cache do Snowflake, para melhorar a sobrecarga de dados.
O Snowflake não é fácil de gerenciar usando coisas como o Git. Como o dbt é baseado nos mesmos princípios de outras linguagens de programação, podemos usar fluxos de trabalho baseados em Git para ajudar a gerenciar nossos processos de desenvolvimento mais facilmente com coisas como pipelines de CI/CD. Isso pode ajudar no controle de versão dos nossos pipelines, o que seria complicado se fosse feito só no Snowflake.
Para ajudar os desenvolvedores a colaborarem mais facilmente, o dbt também tem uma interface de usuário que mostra todos os seus trabalhos dbt em um só lugar. Isso ajuda as equipes a programar os processos em conjunto e garantir que eles estejam funcionando corretamente. Além disso, a dbt lançou recentemente um IDE Studio que facilita a integração do Git e do banco de dados com os fluxos de trabalho de teste. Algumas equipes podem até optar por usar a interface do usuário do Snowflake para integração total.
Muitas equipes de dados começaram a usar o dbt e o Snowflake juntos pra aproveitar ao máximo seus bancos de dados. Continue a aprender mais sobre o dbt nesta introdução prática ao dbt para engenheiros de dados e entenda como a modelagem de dados do Snowflake funciona com este curso.
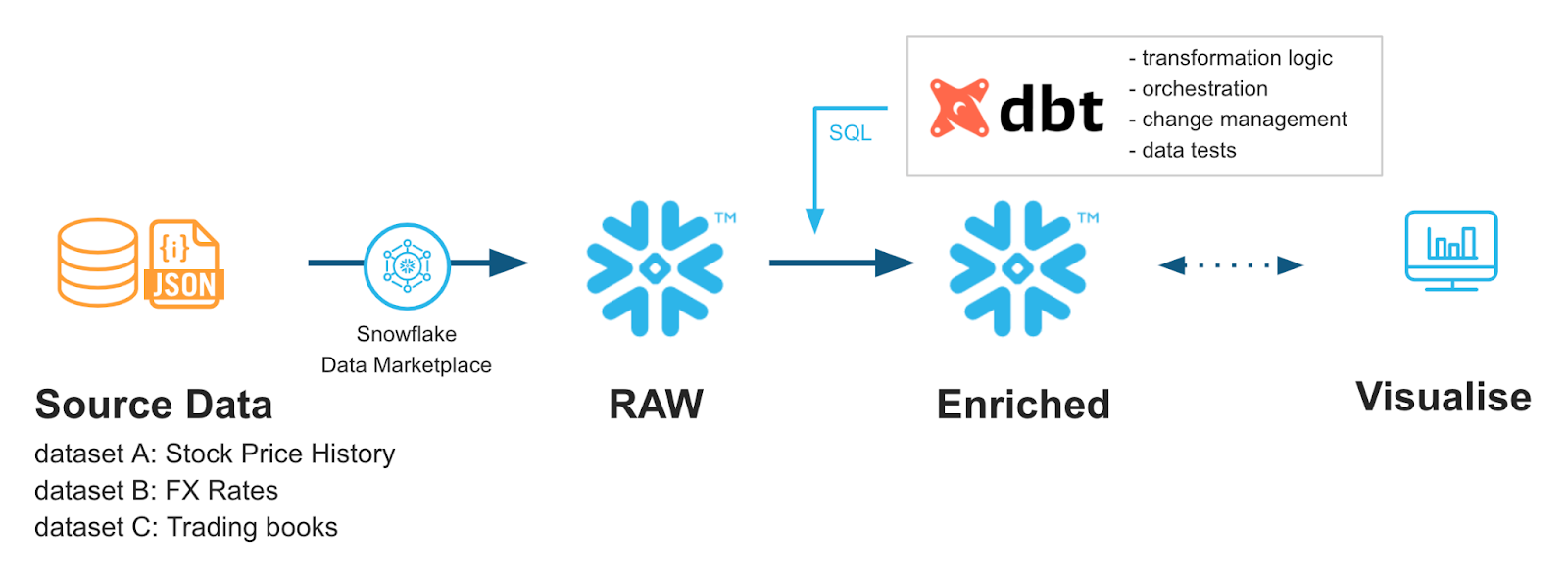
Do Snowflake Quickstarts: Acelerando com o dbt Core e o Snowflake
Vamos ver algumas noções básicas sobre como configurar o Snowflake e o dbt para uma integração adequada. Também vamos falar sobre algumas coisas básicas sobre as melhores práticas para projetar a estrutura de um projeto.
Vamos começar com a configuração do banco de dados Snowflake e, em seguida, passar pela configuração do dbt.
Você vai precisar de um banco de dados dedicado, um esquema e um warehouse virtual pra guardar seus dados dbt. Além disso, você vai precisar de uma função de usuário dbt específica que o dbt possa acessar. Ao configurar o dbt, você vai fornecer as credenciais desse usuário para que ele possa se comunicar com o Snowflake. Nesta seção, vou te dar algumas orientações básicas, mas para mais detalhes sobre como gerenciar bancos de dados Snowflake e funções de usuário, dê uma olhada neste curso Introdução ao Snowflake.
CREATE DATABASE analytics_db;
CREATE SCHEMA analytics_db.transformations;
CREATE WAREHOUSE dbt_wh
WITH WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
CREATE ROLE dbt_role;
GRANT USAGE ON WAREHOUSE dbt_wh TO ROLE dbt_role;
GRANT USAGE ON DATABASE analytics_db TO ROLE dbt_role;
GRANT USAGE, CREATE SCHEMA ON DATABASE analytics_db TO ROLE dbt_role;
GRANT ALL PRIVILEGES ON SCHEMA analytics_db.transformations TO ROLE dbt_role;
CREATE USER dbt_user PASSWORD='StrongPassword123'
DEFAULT_ROLE = dbt_role
DEFAULT_WAREHOUSE = dbt_wh
DEFAULT_NAMESPACE = analytics_db.transformations;
GRANT ROLE dbt_role TO USER dbt_user;
Pra rodar o dbt, a gente precisa instalar usando o ` pip ` e depois configurar o nosso arquivo ` profiles.yml `.
dbt-core e dbt-snowflake.pip install dbt-core dbt-snowflakeprofiles.yml e salve-o em ~/.dbt/profiles.ymlsnowflake-db:
target:dev
outputs:
dev:
type: snowflake
account: [account_id from earlier]
user: [dbt_user]
password: [dbt_pw]
role: [dbt_role]
warehouse:[dbt_warehouse]
database: [dbt_database]
schema: [dbt_schema]
threads: 4
client_session_keep_alive: False
query_tag: [anything]dbt init --profile snowflake-dbdbt init snowflake-profile-nameIsso vai passar por uma inicialização passo a passo que gera um arquivo profiles.yml, se necessário!
debug `:dbt debug --connectionEsse comando vai verificar se suas configurações de conexão estão certas e vai mostrar um erro se não estiverem.
Uma coisa pra pensar: em vez de colocar seu nome de usuário e senha direto no arquivo profiles.yml, tenta usar variáveis de ambiente. Por exemplo, o dbt_password pode ser salvo em uma variável de ambiente SNOWFLAKE_PASSWORD. Então, no arquivo profiles.yml, você escreveria password: “{{env_var(‘SNOWFLAKE_PASSWORD’)}}”. Isso ajuda a impedir que as pessoas vejam as credenciais no arquivo de configuração e adiciona um pouco mais de segurança.
Conectar-se a Git ajuda a aproveitar ao máximo sua configuração do dbt. Os passos exatos podem variar se você estiver fazendo isso como parte da sua empresa. A ideia geral é bem simples, né? Crie um repositório em algo como GitHub ou GitLab. Depois, conecte sua conta dbt à conta GitHub/GitLab. Depois de fazer isso, você pode fazer o commit no seu repositório com o comando ` git clone `! Pra saber mais sobre como conectar o Git ao dbt, dá uma olhada na documentação do Git do dbt para sua plataforma específica.
Uma estrutura de projeto consistente e padronizada ajuda os novos projetos a começarem mais rápido, oferecendo lugares fixos onde tudo deve ser colocado.
Organize seu projeto em pastas entre staging, intermediárias e marts. Dentro de cada um, você pode especificar diferentes departamentos, cada um com seus próprios modelos e SQL.
models/
│ ├── intermediate
│ │ └── finance
│ │ ├── _int_finance__models.yml
│ │ └── int_payments_pivoted_to_orders.sql
│ ├── marts
│ │ ├── finance
│ │ │ ├── _finance__models.yml
│ │ │ ├── orders.sql
│ │ │ └── payments.sql
│ │ └── marketing
│ │ ├── _marketing__models.yml
│ │ └── customers.sql
│ ├── staging
│ │ ├── jaffle_shop
│ │ │ ├── _jaffle_shop__docs.md
│ │ │ ├── _jaffle_shop__models.yml
│ │ │ ├── _jaffle_shop__sources.yml
│ │ │ ├── base
│ │ │ │ ├── base_jaffle_shop__customers.sql
│ │ │ │ └── base_jaffle_shop__deleted_customers.sql
│ │ │ ├── stg_jaffle_shop__customers.sql
│ │ │ └── stg_jaffle_shop__orders.sql
│ │ └── stripe
│ │ ├── _stripe__models.yml
│ │ ├── _stripe__sources.yml
│ │ └── stg_stripe__payments.sql
│ └── utilities
│ └── all_dates.sql/Cada pasta dentro dos modelos tem um propósito:
Para cada um dos arquivos de configuração dos modelos de preparação, intermediário e marts, você pode definir a configuração +materialized para definir como a saída SQL é criada no Snowflake. Podemos escolher entre visualizações, tabelas ou conjuntos de dados incrementais.
Isso pode ficar mais ou menos assim:
# The following dbt_project.yml configures a project that looks like this:
# .
# └── models
# ├── csvs
# │ ├── employees.sql
# │ └── goals.sql
# └── events
# ├── stg_event_log.sql
# └── stg_event_sessions.sql
name: my_project
version: 1.0.0
config-version: 2
models:
my_project:
events:
# materialize all models in models/events as tables
+materialized: table
csvs:
# this is redundant, and does not need to be set
+materialized: viewUma grande vantagem de juntar o dbt e o Snowflake é que a gente consegue otimizações das duas plataformas. Para Snowflake, dá pra usar diferentes maneiras de lidar com consultas pra elas rodarem mais rápido. Para o dbt, podemos otimizar nossa codificação com macros e técnicas de materialização.
Tem algumas funcionalidades exclusivas do Snowflake que a gente pode usar pra melhorar o desempenho das nossas consultas.
Duas maneiras importantes de otimização no Snowflake são o predicate pushdown e as chaves de agrupamento.
O pushdown de predicados é a ideia de mudar quando o Snowflake filtra pra que ele leia menos dados. Por exemplo, imagine que estamos consultando nossos dados com duas camadas de filtragem: um filtro de segurança e um filtro categórico.
O filtro de segurança define quem pode ver certas partes da nossa tabela com base nas funções de segurança. O filtro categórico está na nossa instrução ` WHERE ` na consulta. O Snowflake vai escolher o filtro que vai primeiro, que vai precisar ler a menor quantidade de dados.
Para ajudar nessa redução de predicados, podemos pensar em agrupar chaves. Embora o Snowflake faça um bom trabalho no agrupamento de tabelas, quando os dados atingem vários TB, fica difícil para o Snowflake manter partições sensatas.
Ao definir chaves de agrupamento, podemos ajudar o Snowflake a dividir os dados de uma forma que se adapte à maneira como costumamos consultar a tabela. Por exemplo, talvez a gente escolha duas colunas que sempre andam juntas, tipo datas e tipos de imóveis. Cada tipo de propriedade pode ter um número pequeno de datas, o que torna o reparticionamento sensato e a localização dos dados eficaz.
Combinar chaves de agrupamento com a otimização de empurramento de predicados do Snowflake pode tornar a navegação em tabelas grandes muito mais eficiente.
O uso de recursos em um sistema de pagamento por uso como o Snowflake é importante! Você deve seguir alguns princípios simples:
auto-suspend para suspender os warehouses quando seus pipelines estiverem offline por um longo tempo.auto-resume vai te deixar reiniciar o warehouse conforme necessário.Esses ajustes simples no warehouse vão deixar o uso do Snowflake mais eficiente no longo prazo.
No lado do dbt, podemos usar tabelas dinâmicas e modelos incrementais para simplificar a lógica de atualização.
Tabelas dinâmicas são um tipo de tabela do Snowflake que se atualiza automaticamente com base em tempos de atraso definidos. O dbt pode materializar tabelas dinâmicas como parte da sua configuração e configurá-las de forma semelhante à do Snowflake.
models:
<resource-path>:
+materialized: dynamic_table
+on_configuration_change: apply | continue | fail
+target_lag: downstream | <time-delta>
+snowflake_warehouse: <warehouse-name>
+refresh_mode: AUTO | FULL | INCREMENTAL
+initialize: ON_CREATE | ON_SCHEDULEIsso é útil pra ter pipelines de transferência de dados simples que não precisam de SQL complicado. A melhor parte é que podemos conectar-nos a essas tabelas dinâmicas e ter dados atualizados conforme necessário.
Outra maneira flexível de criar tabelas é usar o modelo incremental. Ao escrever nosso SQL, filtramos uma coluna que nos permite saber quais dados são novos. Então, a gente usa a macro ` is_incremental() ` pra avisar o dbt que só deve usar esse filtro quando a gente configurar uma tabela incremental materializada.
Seu SQL de exemplo pode ficar mais ou menos assim, a partir da documentação do documentação do dbt:
{{
config(
materialized='incremental'
)
}}
select
*,
my_slow_function(my_column)
from {{ ref('app_data_events') }}
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
-- (uses >= to include records whose timestamp occurred since the last run of this model)
-- (If event_time is NULL or the table is truncated, the condition will always be true and load all records)
where event_time >= (select coalesce(max(event_time),'1900-01-01') from {{ this }} )
{% endif %}Você me viu fazendo referência a algo chamado “macro”. São trechos de código que podem ser reutilizados no dbt. Podem ser cálculos que são reutilizados ou transformações que acontecem com frequência.
Criamos macros usando o modelo Jinja. Um caso de uso comum pode ser clonar bancos de dados antes de trabalhar neles.
{% macro clone_tables(table_to_clone) -%}
–- shows all tables within a schema
{% set all_tables_query %}
show tables in schema {{ clone_tables }}
{% endset %}
-- take the set results and use the run_query macro
{% set results = run_query(all_tables_query) %}
{{ "create or replace schema " ~ generate_schema_name(var("custom_tables_list")) ~ ";" }}
--execute the cloning function
{% if execute %}
{% for result_row in results %}
{{ log("create table " ~ generate_schema_name(var("custom_tables_list")) ~ "." ~ result_row[1] ~ " clone " ~ clone_tables~ "." ~ result_row[1] ~ ";") }}
{{ "create table " ~ generate_schema_name(var("custom_tables_list")) ~ "." ~ result_row[1] ~ " clone " ~ clone_tables~ "." ~ result_row[1] ~ ";" }}
{% endfor %}
{% endif %}
{%- endmacro %}Esse modelo pega um esquema fornecido, gera uma lista de tabelas e depois clona elas para o warehouse/esquema que você colocou na sua configuração do dbt. Você pode usar essa macro no seu código dbt ou ao iniciar o dbt.
Pra pegar mais jeito com o Jinja no dbt, recomendo muito esse estudo de caso sobre como criar modelos de dados de comércio eletrônico com o dbt. Ele mostra alguns modelos complexos do Jinja com o dbt e te dá uma experiência prática bem avançada!
Como a gente trabalha com informações dos clientes, pode ser que a gente tenha acesso a informações pessoais identificáveis (PII) e precise ocultá-las em nosso banco de dados. Isso é super fácil de fazer com o Snowflake! A gente pode usar CREATE MASKING POLICY pra dizer pro Snowflake quais colunas e tipos de dados precisam ser mascarados quando as consultas forem executadas. Essas políticas garantem que nenhuma informação pessoal identificável seja divulgada durante a consulta de informações confidenciais.
Aí, a gente pode usar o dbt tests com um SQL personalizado que verifica se as tabelas estão mascarando direitinho. Por exemplo, se a gente definir uma política de mascaramento que só deixa a função ANALYST ver PII, assim:
CREATE OR REPLACE MASKING POLICY email_mask AS (val string) returns string ->
CASE
WHEN current_role() IN ('ANALYST') THEN VAL
ELSE '*********'
END;Então, usando nossa função de usuário dbt_account para consultar os dados, deve retornar uma string '*********'.
Se nosso teste fizer algo simples como:
SELECT *
FROM schema.table
WHERE email <> '*********'Se esse teste der algum resultado, então deve ser considerado uma falha. Nenhum e-mail deve voltar como algo diferente da sequência mascarada. Aí, a gente deve conferir a política de mascaramento no Snowflake e continuar testando até que esteja funcionando direitinho.
Como sempre, a segurança é um pilar fundamental do acesso à nuvem. Nesta seção, vamos ver algumas noções básicas sobre segurança e proteção de dados.
A principal estrutura de segurança da Snowflake é o controle de acesso baseado em função (RBAC) e o uso de contas de serviço.
Definir privilégios RBAC nos permite aplicar configurações de segurança a um grande grupo de usuários sem precisar atribuí-las manualmente a cada um deles. Isso facilita a manutenção.
Como falamos acima, criamos funções usando a instrução ` CREATE ROLE `. Para conceder permissões, usamos GRANT … TO ROLE e, da mesma forma, removemos essas permissões através de REVOKE … FROM ROLE.
Aqui estão algumas dicas:
dbt_reader, acesso pra criar tabelas pra dbt_writer e acesso pra apagar só pra uma conta de administrador como dbt_admin.Contas de serviço são contas especiais baseadas em máquinas que funcionam sem a interação humana. Essas contas não têm nomes de usuário e senhas. Em vez disso, eles usam chaves públicas e restrições de rede para minimizar os riscos.
Criar uma conta de serviço pode ser assim:
CREATE USER dbt_service
RSA_PUBLIC_KEY = <keysring>Assim, você tem uma conta única gerenciada pelos administradores e não precisa mais se preocupar com usuários individuais. É recomendável trocar as chaves de vez em quando pra evitar que elas sejam roubadas. Além disso, fique de olho na atividade da rede usando o Snowflake’s LOGIN_HISTORY.
Proteja seus dados e logins. Embora tenhamos codificado nossas credenciais como exemplo, na verdade isso não é uma boa prática. Use gerenciadores de segredos como o AWS Secrets Manager ou o GitHub Secrets para guardar credenciais importantes.
Isso permite que você armazene credenciais online que só podem ser acessadas por usuários com as chaves RSA/Security certas. Ninguém consegue ver o valor real e é fácil alternar senhas/chaves com o gerenciamento automático.
Certifique-se de que todas as conexões estejam devidamente protegidas e que os usuários estejam na rede corporativa apropriada para acessar os dados. Isso geralmente é feito usando VPNs como o GlobalProtect. Como estamos conectando ao Snowflake, grande parte da criptografia de ponta a ponta é feita pela nuvem. Mais um benefício de estar no Snowflake!
Por fim, queremos fazer uma auditoria da nossa atividade. O Snowflake tem registro de consultas por meio de tabelas como QUERY_HISTORY e QUERY_HISTORY_BY_USER. A gente pode monitorar o uso, os erros e qualquer abuso de segurança nesses registros. Com o dbt, a gente consegue programar novas execuções, mudanças ou edições nos projetos usando nossos pipelines de controle de versão.
O controle de versão e os modelos de codificação ajudam a manter o programa das alterações e a conformidade. Qualquer problema causado pelas mudanças pode ser facilmente percebido durante as solicitações de pull obrigatórias e resolvido antes que se torne uma preocupação.
Vamos conversar sobre como podemos economizar um pouco de dinheiro! No dbt, claro. É super importante acompanhar o desempenho do nosso modelo. É fácil que modelos que costumavam funcionar sem problemas fiquem mais lentos e com desempenho inferior à medida que o tamanho da tabela aumenta.
Com o dbt, a melhor maneira de monitorar o desempenho é usar pacotes integrados, como dbt-snowflake-monitoring, ou ferramentas externas, como Looker e Datafold, para ajudar na visualização e comparação de dados.
Começar a usar o dbt-snowflake-monitoring é bem fácil! No seu dbt packages.yml, adicione o seguinte:
packages:
- package: get-select/dbt_snowflake_monitoring
version: [">=5.0.0", "<6.0.0"] # We'll never make a breaking change without creating a new major version.Depois, no arquivo YAML de cada projeto, adicione o seguinte:
dispatch:
- macro_namespace: dbt
search_order:
- <YOUR_PROJECT_NAME>
- dbt_snowflake_monitoring
- dbt
query-comment:
comment: '{{ dbt_snowflake_monitoring.get_query_comment(node) }}'
append: true # Snowflake removes prefixed comments.Agora você está pronto para usar o pacote para monitorar coisas como o uso do seu warehouse, durações de consultas e modelos com falha! Ele usa o acesso que você já tem como usuário do dbt para gravar tabelas no Snowflake, que têm informações úteis. Por exemplo, se eu quisesse ver meus gastos mensais com warehouse, poderia usar o seguinte SQL:
select
date_trunc(month, date)::date as month,
warehouse_name,
sum(spend_net_cloud_services) as spend
from daily_spend
where service in ('Compute', 'Cloud Services')
group by 1, 2Ferramentas externas como Looker ou Tableau podem ser integradas diretamente com o dbt para facilitar a visualização dos dados e do desempenho. Para alertas, o dbt pode mandar e-mails ou notificações pelo Slack.
Para comparações mais detalhadas, pilhas externas como o Datafold oferecem uma visão mais profunda de como a qualidade dos dados é afetada pelas mudanças. O Datafold automatiza as diferenças de dados a cada alteração de código que você faz. Isso permite que outros membros da equipe revisem facilmente seu código e o impacto que ele terá nos dados. Esse tipo de teste de regressão automatizado nos permite manter a qualidade dos dados sem precisar criar constantemente novas verificações e ferramentas.
Não dá pra evitar a execução dos nossos processos ETL, mas com certeza podemos se planejar com antecedência pra minimizar o impacto dos custos de computação e armazenamento. Graças ao design dividido do Snowflake, podemos otimizar nossos warehouse e armazenamento separadamente para criar um ambiente mais flexível e com custos otimizados.
Para warehouse, o melhor é minimizar o tempo ocioso. Espalhe seus pipelines automatizados o máximo possível para reduzir o tempo ocioso, picos nas necessidades computacionais e recursos concorrentes.
Fique de olho regularmente usando as tabelas WAREHOUSE_LOAD_HISTORY e QUERY_HISTORY para entender como os recursos estão sendo usados. A melhor prática é começar com XS. Se as consultas estiverem muito lentas, é hora de aumentar o tamanho com base no SLA da sua equipe.
Pra armazenamento, o melhor é se livrar das tabelas que não são necessárias. Embora o Snowflake não tenha camadas frias como a AWS e o Google, você pode optar por mover seus dados do Snowflake para a AWS/Google para essas camadas frias e reduzir o custo de armazenamento.
As políticas de retenção de dados podem definir claramente um cronograma para tabelas que são raramente usadas e quando elas serão transferidas para armazenamento em frio.
Para tabelas grandes que crescem com frequência, fique de olho nelas. À medida que ficam maiores, a capacidade do Snowflake de fazer partições de forma automática e eficiente vai perdendo o jeito. Aproveite o agrupamento automático mencionado acima para ajudar o Snowflake a particionar melhor seus dados. Partições melhores reduzem o tempo de leitura do armazenamento e, assim, economizam custos.
Graças à integração nativa do dbt com controle de versão, CI/CD e pipelines automatizados são super fáceis. Vamos falar sobre algumas opções de orquestração automatizada e as melhores práticas de teste.
Com a nuvem dbt, a gente pode usar as tarefas do Snowflake para acionar execuções programadas dos nossos projetos dbt. Funciona assim: primeiro criamos um projeto dbt no Snowflake usando nosso repositório Git e, em seguida, criamos uma tarefa que executa esse projeto dbt.
Por exemplo, a gente poderia fazer algo assim pra criar um projeto dbt:
CREATE DBT PROJECT sales_db.dbt_projects_schema.sales_model
FROM '@sales_db.integrations_schema.sales_dbt_git_stage/branches/main'
COMMENT = 'generates sales data models';Então, usamos o seguinte código para rodar esse projeto:
CREATE OR ALTER TASK sales_db.dbt_projects_schema.run_dbt_project
WAREHOUSE = sales_warehouse
SCHEDULE = '6 hours'
AS
EXECUTE DBT PROJECT sales_db.dbt_projects_schema.sales_model args='run --target prod';Na verdade, é tão completo que a gente pode até fazer testes depois pra ter certeza de que o projeto funcionou direitinho:
CREATE OR ALTER TASK sales_db.dbt_projects_schema.test_dbt_project
WAREHOUSE = sales_warehouse
AFTER run_dbt_project
AS
EXECUTE DBT PROJECT sales_db.dbt_projects_schema.test_dbt_project args='test --target prod';Pra agendar, a gente pode escolher entre definir um horário fixo, tipo 60 MINUTES e 12 HOURS, ou usar o cron assim: USING CRON 0 9 * * * UTC..
Nossos modelos raramente ficam parados, e muitas vezes a gente precisa refazê-los. Pode ser demorado construir manualmente cada parte do nosso pipeline. É aí que entram as GitHub Actions. Costumamos usar o GitHub Actions em pipelines de CI/CD para automatizar os testes e a compilação de código.
As GitHub Actions são criadas usando arquivos YAML dentro da pasta .github/workflows no repositório. Podemos fazer com que eles sejam acionados sempre que fizermos uma solicitação pull, de modo que executemos alguns testes dbt.
name: dbt pull test
# CRON job to run dbt at midnight UTC(!) everyday
on:
pull_request:
types:
openedreopened
# Setting some Env variables to work with profiles.yml
# This should be your snowflake secrets
env:
DBT_PROFILE_TARGET: prod
DBT_PROFILE_USER: ${{ secrets.DBT_PROFILE_USER }}
DBT_PROFILE_PASSWORD: ${{ secrets.DBT_PROFILE_PASSWORD }}
jobs:
dbt_run:
name: dbt testing on pull request
runs-on: ubuntu-latest
timeout-minutes: 90
# Steps of the workflow:
steps:
- name: Setup Python environment
uses: actions/setup-python@v4
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
python -m pip install -r requirements.txt
- name: Install dbt packages
run: dbt deps
# optionally use this parameter
# to set a main directory of dbt project:
# working-directory: ./my_dbt_project
- name: Run tests
run: dbt test
# working-directory: ./my_dbt_projectConfigurar suas automações corretamente pode facilitar muito sua vida e ajudar outros desenvolvedores a ver seus modelos testados. Isso simplifica o processo de desenvolvimento, reduzindo a necessidade de testes manuais.
O dbt vem com um conjunto de testes bem poderoso. Ele vem com alguns testes de dados genéricos prontos para uso que podem ser configurados diretamente no seu modelo e permitem uma lógica SQL personalizada. Os testes genéricos são definidos em colunas específicas do seu modelo e verificam se essas colunas específicas passam nesse teste. Os testes prontos para uso são os seguintes:
unique: cada valor nesta coluna deve ser úniconot_nullNão deve ter nenhum valor nulo na coluna.accepted_values: verifica se os valores estão em uma lista de valores aceitosrelationshipsverifica se os valores nesta coluna estão em outra tabela relacionadaAqui está um exemplo de como usar essas relações (da documentação do dbt sobre testes):
version: 2
models:
- name: orders
columns:
- name: order_id
data_tests:
# makes sure this column is unique and has no nulls
- unique
- not_null
- name: status
data_tests:
#makes sure this column only has the below values
- accepted_values:
values: ['placed', 'shipped', 'completed', 'returned']
- name: customer_id
data_tests:
# makes sure that the customer ids in this column are ids in the customers table
- relationships:
to: ref('customers')
field: idA gente pode usar SQL personalizado pra criar testes mais específicos e genéricos. O objetivo aqui é que os testes retornem linhascom falha. Então, se aparecer algum resultado, o teste é considerado reprovado. Esses arquivos SQL personalizados ficam no nosso diretório tests.
Por exemplo, se a gente quisesse saber se alguma venda foi negativa, poderíamos usar o seguinte:
select
order_id,
sum(amount) as total_amount
from {{ ref('sales') }}
group by 1
having total_amount < 0Depois, a gente ia referenciar esse teste no nosso arquivo schema.yml dentro da nossa pasta de testes:
version: 2
data_tests:
- name: assert_sales_amount_is_positive
description: >
Sales should always be positive and are not inclusive of refunds
Se a gente quisesse usar esse tipo de verificação em mais tabelas e colunas, talvez fosse legal transformar isso em um teste genérico. Isso pode ficar assim:
{% test negative_values(model, group,sum_column) %}
select {{group}},
sum({{sum_column}}) as total_amt
from {{ model }}
group by 1
having total_amt < 0
{% endtest %}Agora podemos usar esse teste no arquivo yaml dos nossos modelos, assim como os outros testes genéricos que vêm com o dbt! Você pode verificar se há passageiros negativos em uma viagem ou lucro negativo e assim por diante! As possibilidades são infinitas.
Para tornar esse teste mais simples e fácil, podemos usar a clonagem sem cópia do Snowflake. O Snowflake Então, todos os seus testes e CI podem ser feitos com base no objeto clonado. A vantagem disso é que não precisamos de espaço de armazenamento extra para ter um ambiente de teste seguro. Além disso, sempre que precisarmos de mais espaço para testes, podemos criar mais ambientes de teste com essa clonagem instantânea. Vamos dar uma olhada nas melhorias e tendências futuras que estão por vir com o dbt e o Snowflake. A dbt está sempre melhorando sua integração tanto com seu produto principal quanto com a IA. No Snowflake, a gente pode usar o Snowsight como uma interface de usuário pra ajudar a gerenciar nossos espaços de trabalho dbt. Ao integrar de forma mais harmoniosa ao nosso ambiente Snowflake, a gente minimiza a necessidade de trabalhar em modelos dbt externamente. Em vez disso, podemos centralizar nossos fluxos de trabalho, permitindo que as equipes editem e colaborem por meio da interface do Snowflake. Pra ajudar a acelerar o desenvolvimento, o dbt oferece um assistente com inteligência artificial chamado dbt Copilot. Esse assistente pode ser acessado pelo IDE do dbt Studio, Canvas ou Insights e usa processamento de linguagem natural pra ajudar a acelerar as partes mais demoradas do desenvolvimento de modelos, como escrever documentação e criar testes. O dbt Copilot pode até ser usado pra ajudar a integrar novos analistas, fornecendo a eles resumos concisos de projetos e modelos. Use essas duas ferramentas para acelerar o tempo de produção e reduzir o tempo de desenvolvimento, permitindo que sua equipe lide com os problemas de dados mais difíceis e desafiadores da sua organização. Os pipelines de machine learning precisam de dados sempre limpos e bem organizados. O dbt é a ferramenta perfeita para pipelines de transformação de dados que alimentam modelos de machine learning. Podemos aproveitar a flexibilidade e o poder do dbt para automatizar transformações de dados que se integram perfeitamente aos nossos pipelines de machine learning. Por exemplo, podemos transformar nossos dados diretamente em um warehouse de machine learning. Esses dados podem então ser usados com o Cortex AI da Snowflake para obter insights mais profundos. Se a gente tiver vários modelos que precisam de transformações parecidas, os modelos do dbt podem simplificar a forma como limpamos nossos dados e trazer mais consistência e uma governança de dados mais fácil. Para entender melhor as ferramentas de IA da Snowflake, dá uma olhada neste guia sobre o Snowflake Arctic, que é o LLM da Snowflake. Graças ao suporte nativo do Snowflake ao Python e à API Snowpark para Python, podemos executar códigos localmente sem precisar mover os dados para fora do Snowflake. O próximo nível é usar os Snowpark Containers, que atualmente (no momento da redação deste artigo) só estão disponíveis nas regiões AWS e Azure, para executar nosso código dbt de forma totalmente isolada. Para isso, colocamos nossos modelos e ambiente dbt em um contêiner, que fica no repositório de imagens do Snowflake. Aí, a gente pode usar esse projeto dbt em contêiner facilmente dentro do Snowpark. Qual é a principal vantagem? A capacidade de usar mais facilmente os recursos do Snowflake para transformações complexas de dados baseadas em Python e integração de transformações dbt dentro do ambiente Snowflake mais amplo. Se você quiser saber mais sobre o Snowpark, dá uma olhada nessas informações que falam sobre o Snowflake Snowpark em detalhes. Integrar o dbt com o Snowflake ajuda as equipes de dados a criar pipelines de transformação modulares, controlados e escaláveis. Com recursos como testes automatizados, fluxos de trabalho de CI/CD baseados em Git e escalabilidade perfeita, essa pilha é ideal para operações de dados modernas. Para continuar competitivas, as equipes de dados devem priorizar: À medida que as duas ferramentas continuam a evoluir, a integração entre o dbt e o Snowflake só vai ficar mais poderosa para as equipes de engenharia de dados. Se você quiser saber mais sobre o dbt ou o Snowflake, dá uma olhada nesses recursos:CREATE TABLE CLONE pode criar um clone zero-copy no seu ambiente de desenvolvimento/teste.
Tendências emergentes e perspectivas futuras
Desenvolvimentos de integração nativa
Integração de machine learning
Execução em contêiner
Conclusão
Principais cursos da DataCamp
Programa
Programa
Curso