
Lernpfad
Snowflake Stiftungen
7 Std.
Da moderne Datenteams immer komplexere Analyse-Stacks nutzen, hat sich ein Trend hin zur Schaffung von Standardverfahren innerhalb der Datenengineering-Workflows entwickelt. Tools wie dbt (Data Build Tool) sind ein Open-Source-Framework, das bewährte Verfahren der Softwareentwicklung – wie Versionskontrolle, Tests und Dokumentation – in Analyse-Workflows einbringt.
Die Kombination aus dbt und Snowflake (einem Cloud-nativen Data Warehouse) hat sich zu einem wichtigen Teil der Analytics-Engineering-Workflows entwickelt. Dieser Leitfaden erklärt die grundlegenden Konzepte, die Einrichtung und fortgeschrittene Implementierungsstrategien für die Integration von dbt mit Snowflake und hilft Datenteams dabei, besser wartbare, sicherere und leistungsfähigere Datenpipelines zu schaffen.
Wenn du gerade erst anfängst, mit diesen Tools zu arbeiten, empfehle ich dir, unseren Snowflake Foundations Lernpfad und den Einführungskurs in dbtzu machen.
Reden wir mal darüber, wie dbt und Snowflake zusammenarbeiten. Hier geht's um die Funktionen von dbt und wie gut es mit Snowflake zusammenarbeitet. Außerdem zeigen wir dir, was die Integration beider Tools so toll macht.
dbt (Data Build Tool) ist ein Open-Source-Framework, mit dem Datenteams Daten direkt in ihrem Warehouse mit SQL und Jinja-Templates umwandeln, testen und dokumentieren können.
dbt ist keine Programmiersprache an sich, sondern fungiert als Compiler, der modulare SQL-Modelle in ausführbare SQL-Abfragen umwandelt, die im Warehouse (z. B. Snowflake) ausgeführt werden.
Durch die Integration von Versionskontrolle, automatisierten Tests und Dokumentation bringt dbt bewährte Software-Engineering-Praktiken in die Analyseentwicklung und macht Transformationspipelines als Teil eines ELT-Workflows zuverlässiger, wartungsfreundlicher und skalierbarer.
Die Hauptkomponenten sind ein Compiler und ein Runner. Hier sind ihre Funktionen:
Damit dbt funktioniert, gibt's ein paar grundlegende Komponenten, die dafür sorgen, dass alles reibungslos läuft:
select “, gespeichert als .sql-Dateien.Für mehr Infos zu dbt empfehle ich diesen super Einführungskurs zu dbt.
Mit den Jinja-basierten Vorlagen von dbt und den coolen Datentypen von Snowflake, wie Streams, können wir unsere Transformations-Workflows echt kreativ gestalten.
Vielleicht wollen wir zum Beispiel nur neu geladene Daten oder verschiedene Transformationen in unseren Staging-Tabellen im Vergleich zu unseren Produktionstabellen umwandeln, damit wir Datenintegritätsprüfungen durchführen können.
Die beiden werden schnell zu einer gängigen Kombination, die Dateningenieuren mehr Kontrolle und Flexibilität bei ihren Datenpipelines gibt, da immer mehr Firmen dbt regelmäßig einsetzen.
dbt hat echt viele Vorteile: traditionelle Softwareentwicklungsmethoden, automatisierte Tests und mehr Produktivität.
Wir können unsere Daten und SQL eher wie herkömmlichen Code behandeln. Es gibt uns Zugriff auf Modularität, Testbarkeit und Versionskontrolle. Durch die Nutzung von Vorlagen und Python-typischen Anweisungen zur Ablaufsteuerung kriegen wir ein paar echt coole Funktionen von dbt.
Mit der integrierten Konfiguration „ data_test “ von dbt können wir regelmäßig Tests mit unseren Daten machen, ohne komplizierte SQL-Pipelines zu brauchen. Tatsächlich hat dbt schon ein paar starke Basistests, die wir ganz einfach in unseren Konfigurationsdateien einbauen können.
In dbt gibt's Sachen wie Dokumentationsgeneratoren und Pipeline-Visualisierer. Neue Teammitglieder können schneller eingearbeitet werden und die bestehenden Mitglieder kriegen ein besseres Verständnis von den Datenflüssen. Das hilft, die Anlaufzeit zu verkürzen und verbessert das allgemeine Verständnis aller für den Arbeitsablauf.
Die Cloud-Plattform von Snowflake hat echt viele Vorteile. Es hat eine coole Architektur, die Speicher- und Rechenressourcen trennt, um Konflikte zu vermeiden und die Kosten zu senken. Es nutzt Zero-Copy-Cloning, wodurch man Datenbankklone ohne zusätzlichen Speicherplatz erstellen kann.
Außerdem unterstützt es einige komplexe Datentypen für Tabellen wie dynamische Tabellen und Streams, die eine inkrementelle Aktualisierungslogik ermöglichen. Mehr Infos über Snowflake als Plattform findest du in diesem Artikel, der erklärt, wie Snowflake funktioniert.
Das Wichtigste ist, dass diese Funktionen super zu dbt passen. Wir können die inkrementelle Aktualisierung nutzen, um dbt dabei zu helfen, Transformationen basierend auf neuen Daten auszulösen. Wir können auch die Trennung von Rechenleistung und Speicherplatz bei Snowflake nutzen, wodurch dbt rechenintensive Transformationen durchführen kann, ohne dass das Hochladen und Speichern von Daten beeinträchtigt wird.
All das geht mit der Fähigkeit von Snowflake einher, schnell zu skalieren, und seinem Pay-per-Use-Kostenmodell. Wenn unsere DBT-Skripte immer komplexer werden, können wir unsere Snowflake-Rechenzentren ganz einfach anpassen, um diesen Anforderungen gerecht zu werden. Gleichzeitig können wir die Überwachungsfunktion von Snowflake nutzen, um unsere Lager zu verschlanken, und dbt einsetzen, um unsere Abfrageleistung zu optimieren.
Zusammen passen Snowflake und dbt echt super zusammen. Die ständige Optimierung von Snowflake hilft dabei, die Cloud-Kosten niedrig zu halten. dbt kann Methoden zur Partitionierung von Tabellen wie Clustering-Schlüssel und das Caching von Snowflake nutzen, um den Datenaufwand zu verbessern.
Snowflake lässt sich nicht so einfach mit Sachen wie Git verwalten. Da dbt auf denselben Prinzipien wie andere Programmiersprachen basiert, können wir Git-basierte Workflows nutzen, um unsere Entwicklungsprozesse mit Dingen wie CI/CD-Pipelines einfacher zu verwalten. Das kann bei der Versionskontrolle unserer Pipelines helfen, was echt schwierig wäre, wenn man das komplett in Snowflake machen müsste.
Damit Entwickler einfacher zusammenarbeiten können, hat dbt auch eine Benutzeroberfläche, die alle deine dbt-Jobs an einem Ort zeigt. Das hilft Teams dabei, Lernpfade gemeinsam zu verfolgen und sicherzustellen, dass sie ordnungsgemäß ablaufen. Außerdem hat dbt kürzlich eine Studio-IDE eingeführt, die eine einfache Git- und Datenbankintegration mit Test-Workflows ermöglicht. Manche Teams entscheiden sich vielleicht sogar dafür, die Benutzeroberfläche von Snowflake für die vollständige Integration zu nutzen.
Viele Datenteams haben angefangen, dbt und Snowflake zusammen zu nutzen, um das Beste aus ihren Datenbanken rauszuholen. Lerne in dieser praktischen Einführung in dbt für Dateningenieure mehr über dbt und verschaffe dir mit diesem Kurs einen Überblick über die Funktionsweise der Datenmodellierung mit Snowflake.
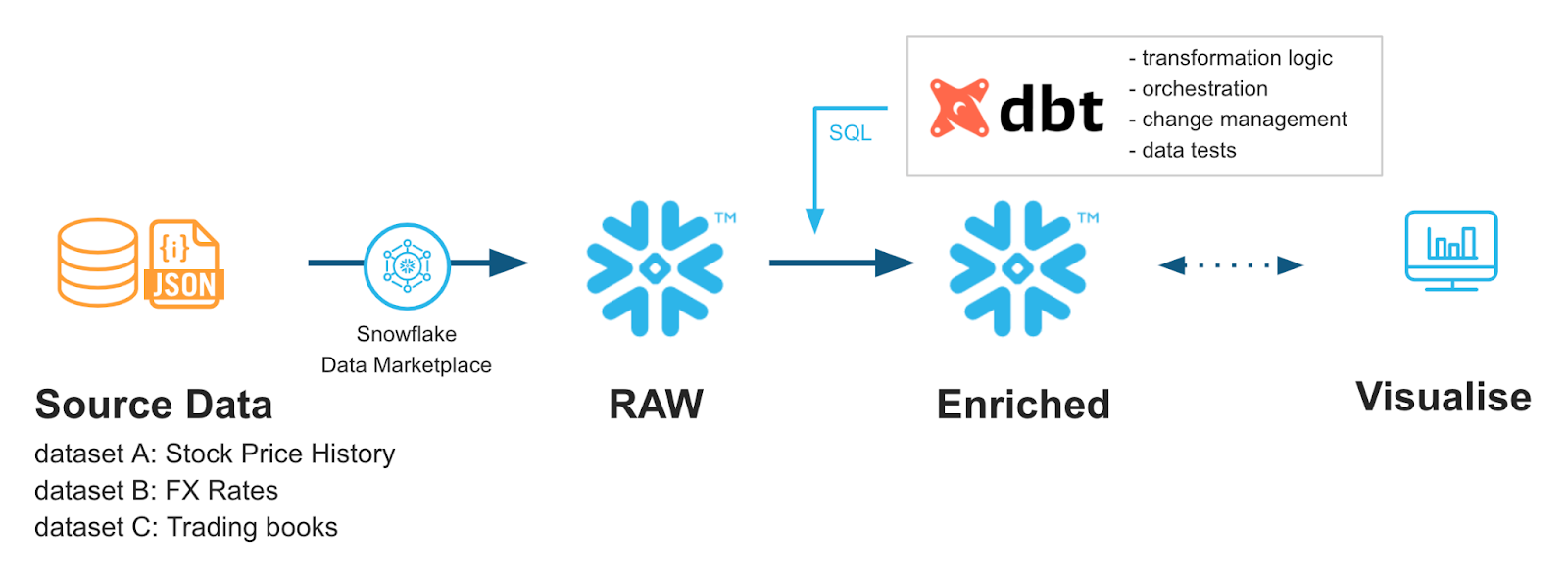
Aus Snowflake Quickstarts: Schneller mit dbt Core und Snowflake
Schauen wir uns mal die Grundlagen an, wie man Snowflake und dbt für eine reibungslose Integration einrichtet. Wir werden auch ein paar Grundlagen zu bewährten Verfahren für die Projektstrukturplanung besprechen.
Wir fangen mit der Einrichtung der Snowflake-Datenbank an und schauen uns dann die Einrichtung von dbt an.
Du brauchst eine eigene Datenbank, ein Schema und ein virtuelles Lager, um deine dbt-Daten zu speichern. Außerdem brauchst du eine bestimmte dbt-Benutzerrolle, auf die dbt zugreifen kann. Beim Einrichten von dbt gibst du die Anmeldedaten dieses Benutzers ein, damit es mit Snowflake kommunizieren kann. In diesem Abschnitt gebe ich dir ein paar grundlegende Tipps, aber für mehr Details zur Verwaltung von Snowflake-Datenbanken und Benutzerrollen schau dir bitte den Kurs „Einführung in Snowflake“ an.
CREATE DATABASE analytics_db;
CREATE SCHEMA analytics_db.transformations;
CREATE WAREHOUSE dbt_wh
WITH WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
CREATE ROLE dbt_role;
GRANT USAGE ON WAREHOUSE dbt_wh TO ROLE dbt_role;
GRANT USAGE ON DATABASE analytics_db TO ROLE dbt_role;
GRANT USAGE, CREATE SCHEMA ON DATABASE analytics_db TO ROLE dbt_role;
GRANT ALL PRIVILEGES ON SCHEMA analytics_db.transformations TO ROLE dbt_role;
CREATE USER dbt_user PASSWORD='StrongPassword123'
DEFAULT_ROLE = dbt_role
DEFAULT_WAREHOUSE = dbt_wh
DEFAULT_NAMESPACE = analytics_db.transformations;
GRANT ROLE dbt_role TO USER dbt_user;
Um dbt auszuführen, müssen wir es mit „ pip “ installieren und dann unsere Datei „ profiles.yml “ konfigurieren.
dbt-core ” und „ dbt-snowflake ”.pip install dbt-core dbt-snowflakeprofiles.yml “ fertig und speicher sie unter ~/.dbt/profiles.ymlsnowflake-db:
target:dev
outputs:
dev:
type: snowflake
account: [account_id from earlier]
user: [dbt_user]
password: [dbt_pw]
role: [dbt_role]
warehouse:[dbt_warehouse]
database: [dbt_database]
schema: [dbt_schema]
threads: 4
client_session_keep_alive: False
query_tag: [anything]dbt init --profile snowflake-dbdbt init snowflake-profile-nameDas wird eine schrittweise Initialisierung durchlaufen, die bei Bedarf eine Datei „ profiles.yml “ erstellt!
debug “ nutzen:dbt debug --connectionDieser Befehl checkt, ob deine Verbindungseinstellungen stimmen, und gibt 'nen Fehler aus, wenn das nicht der Fall ist.
Etwas, das du bedenken solltest: Anstatt deinen Benutzernamen und dein Passwort direkt in der Datei „ profiles.yml “ zu speichern, versuch es doch mal mit Umgebungsvariablen. Zum Beispiel könnte die Variable „ dbt_password “ in der Umgebungsvariable „ SNOWFLAKE_PASSWORD “ gespeichert werden. Dann würdest du in der Datei „ profiles.yml “ Folgendes schreiben: password: “{{env_var(‘SNOWFLAKE_PASSWORD’)}}”. Das verhindert, dass Leute die Zugangsdaten in der Konfigurationsdatei sehen können, und sorgt für ein bisschen mehr Sicherheit.
Wenn du dich mit Git verbindest, kannst du das Beste aus deiner dbt-Konfiguration rausholen. Die genauen Schritte können anders sein, wenn du das im Rahmen deines Unternehmens machst. Die Grundidee ist aber ziemlich klar. Mach dir ein Repository auf GitHub oder GitLab oder so. Verbinde dann dein dbt-Konto mit dem GitHub/GitLab-Konto. Sobald das erledigt ist, kannst du dein Repository git clone! Mehr Infos zum Verbinden von Git mit dbt findest du in der dbt-Git-Dokumentation für deine Plattform.
Eine einheitliche und vorgefertigte Projektstruktur hilft dabei, neue Projekte schneller auf den Weg zu bringen, weil alles schon an seinem festen Platz ist.
Teile dein Projekt in Ordner für Staging, Zwischen- und Marts auf. In jedem kannst du verschiedene Abteilungen festlegen, die alle ihre eigenen Modelle und SQL haben.
models/
│ ├── intermediate
│ │ └── finance
│ │ ├── _int_finance__models.yml
│ │ └── int_payments_pivoted_to_orders.sql
│ ├── marts
│ │ ├── finance
│ │ │ ├── _finance__models.yml
│ │ │ ├── orders.sql
│ │ │ └── payments.sql
│ │ └── marketing
│ │ ├── _marketing__models.yml
│ │ └── customers.sql
│ ├── staging
│ │ ├── jaffle_shop
│ │ │ ├── _jaffle_shop__docs.md
│ │ │ ├── _jaffle_shop__models.yml
│ │ │ ├── _jaffle_shop__sources.yml
│ │ │ ├── base
│ │ │ │ ├── base_jaffle_shop__customers.sql
│ │ │ │ └── base_jaffle_shop__deleted_customers.sql
│ │ │ ├── stg_jaffle_shop__customers.sql
│ │ │ └── stg_jaffle_shop__orders.sql
│ │ └── stripe
│ │ ├── _stripe__models.yml
│ │ ├── _stripe__sources.yml
│ │ └── stg_stripe__payments.sql
│ └── utilities
│ └── all_dates.sql/Jeder Ordner in den Modellen hat einen bestimmten Zweck:
Für jede der Konfigurationsdateien der Staging-, Zwischen- und Mart-Modelle kannst du die Konfiguration „ +materialized “ einstellen, um festzulegen, wie die SQL-Ausgabe in Snowflake erstellt wird. Wir können zwischen Ansichten, Tabellen oder inkrementellen Datensätzen wählen.
Das könnte ungefähr so aussehen:
# The following dbt_project.yml configures a project that looks like this:
# .
# └── models
# ├── csvs
# │ ├── employees.sql
# │ └── goals.sql
# └── events
# ├── stg_event_log.sql
# └── stg_event_sessions.sql
name: my_project
version: 1.0.0
config-version: 2
models:
my_project:
events:
# materialize all models in models/events as tables
+materialized: table
csvs:
# this is redundant, and does not need to be set
+materialized: viewEin großer Vorteil, wenn man dbt und Snowflake zusammenbringt, ist, dass wir Optimierungen von beiden Plattformen bekommen. Bei Snowflake können wir verschiedene Methoden zum Bearbeiten von Abfragen nutzen, damit sie schneller laufen. Bei DBT können wir unsere Codierung mit Makros und Materialisierungstechniken optimieren.
Es gibt ein paar coole Funktionen von Snowflake, die wir nutzen können, um die Leistung unserer Abfragen zu verbessern.
Zwei wichtige Methoden, mit denen wir Snowflake optimieren, sind Predikat-Pushdown und Clustering-Schlüssel.
Predicate Pushdown ist die Idee, zu ändern, wann Snowflake filtert, damit es weniger Daten liest. Stell dir zum Beispiel vor, wir würden unsere Daten mit zwei Filterebenen abfragen: einem Sicherheitsfilter und einem Kategoriefilter.
Der Sicherheitsfilter legt fest, wer bestimmte Teile unserer Tabelle sehen darf, basierend auf Sicherheitsrollen. Der kategorische Filter ist in unserer Anweisung „ WHERE “ in der Abfrage. Snowflake sucht den Filter aus, der zuerst kommt und am wenigsten Daten lesen muss.
Um das zu unterstützen, könnten wir überlegen, Schlüssel zu clustern. Snowflake macht einen guten Job beim Clustering von Tabellen, aber wenn die Datenmenge mehrere TB erreicht, wird es schwierig für Snowflake, sinnvolle Partitionen beizubehalten.
Durch das Festlegen von Clustering-Schlüsseln können wir Snowflake dabei helfen, die Daten so zu partitionieren, wie wir die Tabelle normalerweise abfragen. Zum Beispiel könnten wir zwei Spalten auswählen, die immer zusammen gehören, wie Daten und Immobilientypen. Jeder Objekttyp hat vielleicht nur so wenige Daten, dass eine Neuaufteilung sinnvoll und die Datenverteilung effektiv ist.
Wenn du Clustering-Schlüssel mit der Prädikat-Pushdown-Optimierung von Snowflake kombinierst, kannst du große Tabellen viel effizienter durchsuchen.
Die Ressourcennutzung in einem Pay-per-Use-System wie Snowflake ist echt wichtig! Du solltest dich an ein paar einfache Regeln halten:
auto-suspend “ von Snowflake, um Warehouses zu pausieren, wenn deine Pipelines für längere Zeit offline sind.auto-resume “ das Lager nach Bedarf neu starten.Diese einfachen Anpassungen im Lager machen deine Nutzung von Snowflake auf lange Sicht effizienter.
Bei DBT können wir dynamische Tabellen und inkrementelle Modelle nutzen, um die Aktualisierungslogik einfacher zu machen.
Dynamische Tabellen sind eine Snowflake-Tabelle, die sich automatisch nach festgelegten Verzögerungszeiten aktualisiert. dbt kann dynamische Tabellen als Teil seiner Konfiguration erstellen und sie ähnlich wie in Snowflake einrichten.
models:
<resource-path>:
+materialized: dynamic_table
+on_configuration_change: apply | continue | fail
+target_lag: downstream | <time-delta>
+snowflake_warehouse: <warehouse-name>
+refresh_mode: AUTO | FULL | INCREMENTAL
+initialize: ON_CREATE | ON_SCHEDULEDas ist praktisch, wenn du einfache Datenübertragungs-Pipelines brauchst, die kein kompliziertes SQL erfordern. Das Beste daran ist, dass wir uns mit diesen dynamischen Tabellen verbinden und bei Bedarf aktuelle Daten abrufen können.
Eine andere flexible Möglichkeit, Tabellen zu erstellen, ist das inkrementelle Modell. Beim Schreiben unseres SQL filtern wir nach einer Spalte, die uns zeigt, welche Daten neu sind. Dann benutzen wir das Makro „ is_incremental() “, um dbt mitzuteilen, dass es diesen Filter nur verwenden soll, wenn wir eine materialisierte inkrementelle Tabelle konfigurieren.
Dein Beispiel-SQL könnte so aussehen, aus der dbt-Dokumentation:
{{
config(
materialized='incremental'
)
}}
select
*,
my_slow_function(my_column)
from {{ ref('app_data_events') }}
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
-- (uses >= to include records whose timestamp occurred since the last run of this model)
-- (If event_time is NULL or the table is truncated, the condition will always be true and load all records)
where event_time >= (select coalesce(max(event_time),'1900-01-01') from {{ this }} )
{% endif %}Du hast gesehen, dass ich gerade auf etwas namens „Makro“ angespielt habe. Das sind Code-Schnipsel, die man in dbt wiederverwenden kann. Das könnten wiederverwendete Berechnungen oder häufig vorkommende Umwandlungen sein.
Wir erstellen Makros mit Jinja-Vorlagen. Ein typischer Anwendungsfall könnte sein, Datenbanken zu klonen, bevor man daran arbeitet.
{% macro clone_tables(table_to_clone) -%}
–- shows all tables within a schema
{% set all_tables_query %}
show tables in schema {{ clone_tables }}
{% endset %}
-- take the set results and use the run_query macro
{% set results = run_query(all_tables_query) %}
{{ "create or replace schema " ~ generate_schema_name(var("custom_tables_list")) ~ ";" }}
--execute the cloning function
{% if execute %}
{% for result_row in results %}
{{ log("create table " ~ generate_schema_name(var("custom_tables_list")) ~ "." ~ result_row[1] ~ " clone " ~ clone_tables~ "." ~ result_row[1] ~ ";") }}
{{ "create table " ~ generate_schema_name(var("custom_tables_list")) ~ "." ~ result_row[1] ~ " clone " ~ clone_tables~ "." ~ result_row[1] ~ ";" }}
{% endfor %}
{% endif %}
{%- endmacro %}Diese Vorlage nimmt ein vorgegebenes Schema, erstellt eine Liste von Tabellen und kopiert sie dann in das Warehouse/Schema, das du in deiner dbt-Konfiguration angegeben hast. Du kannst dieses Makro dann in deinem dbt-Code oder beim Starten von dbt verwenden.
Um mehr Erfahrung mit Jinja in dbt zu sammeln, empfehle ich dir diese Fallstudien zum Aufbau von E-Commerce-Datenmodellen mit dbt. Es führt dich durch ein paar knifflige Jinja-Templates mit dbt und gibt dir ein paar ziemlich fortgeschrittene praktische Erfahrungen!
Da wir mit Kundendaten arbeiten, kann es sein, dass wir an personenbezogene Daten (PII) kommen und diese in unserer Datenbank verstecken müssen. Mit Snowflake ist das ganz einfach! Wir können „ CREATE MASKING POLICY “ nutzen, um Snowflake mitzuteilen, welche Spalten und Datentypen bei der Ausführung von Abfragen maskiert werden müssen. Diese Richtlinien sorgen dafür, dass bei der Abfrage sensibler Daten keine personenbezogenen Daten durchs Netz gehen.
Dann können wir dbt- tests en mit benutzerdefiniertem SQL nutzen, um zu checken, ob die Tabellen richtig maskiert sind. Wenn wir zum Beispiel eine Maskierungsrichtlinie festlegen, die nur der Rolle „ ANALYST ” erlaubt, personenbezogene Daten zu sehen, dann sieht das so aus:
CREATE OR REPLACE MASKING POLICY email_mask AS (val string) returns string ->
CASE
WHEN current_role() IN ('ANALYST') THEN VAL
ELSE '*********'
END;Wenn wir dann mit unserer Benutzerrolle „ dbt_account ” die Daten abfragen, sollte das Ergebnis eine Zeichenfolge „ '*********' ” sein.
Wenn unser Test was Einfaches macht wie:
SELECT *
FROM schema.table
WHERE email <> '*********'Wenn dieser Test Ergebnisse liefert, sollte er als Fehlschlag angesehen werden. E-Mails sollten nur als maskierte Zeichenfolge zurückkommen. Dann sollten wir die Maskierungsrichtlinie auf Snowflake checken und weiter testen, bis alles richtig läuft.
Wie immer ist Sicherheit ein wichtiger Teil beim Cloud-Zugang. In diesem Abschnitt gehen wir auf ein paar Grundlagen zur Sicherheit und zum Datenschutz ein.
Das Haupt-Sicherheitskonzept von Snowflake basiert auf rollenbasierter Zugriffskontrolle (RBAC) und der Verwendung von Dienstkonten.
Durch das Festlegen von RBAC-Berechtigungen können wir Sicherheitseinstellungen auf eine große Gruppe von Benutzern anwenden, ohne sie einzeln manuell zuweisen zu müssen. Das macht die Wartung einfacher.
Wie oben erwähnt, erstellen wir Rollen mit der Anweisung „ CREATE ROLE “. Um Berechtigungen zu vergeben, benutzen wir GRANT … TO ROLE und um sie zu entfernen, REVOKE … FROM ROLE.
Hier sind ein paar bewährte Methoden:
dbt_reader Lesezugriff, dbt_writer Zugriff zum Erstellen von Tabellen und nur einem Admin-Konto wie dbt_admin Löschzugriff.Dienstkonten sind spezielle Maschinenkonten, die ohne menschliches Zutun interagieren. Diese Konten haben keine Benutzernamen und Passwörter. Stattdessen nutzen sie öffentliche Schlüssel und Netzwerkbeschränkungen, um das Risiko zu minimieren.
Ein Dienstkonto zu erstellen könnte so aussehen:
CREATE USER dbt_service
RSA_PUBLIC_KEY = <keysring>So hast du ein einziges Konto, das von Admins verwaltet wird, und musst dich nicht mehr um einzelne Nutzer kümmern. Es ist ratsam, die Schlüssel regelmäßig zu wechseln, damit sie nicht durchsickern können. Achte auch darauf, die Netzwerkaktivität mit Snowflakes „ LOGIN_HISTORY “ genau im Auge zu behalten.
Schütze deine Daten und Anmeldedaten. Auch wenn wir unsere Anmeldedaten hier als Beispiel fest codiert haben, ist das in der Praxis eigentlich keine gute Idee. Benutz Geheimnismanager wie AWS Secrets Manager oder GitHub Secrets, um wichtige Zugangsdaten sicher zu speichern.
Damit kannst du Anmeldedaten online speichern, auf die nur Leute mit den richtigen RSA/Sicherheitsschlüsseln zugreifen können. Niemand kann den echten Wert sehen, und das Rotieren von Passwörtern/Schlüsseln ist dank der automatisierten Verwaltung echt einfach.
Stell sicher, dass alle Verbindungen richtig gesichert sind und die Leute im richtigen Unternehmensnetzwerk sind, um auf die Daten zugreifen zu können. Das wird oft mit VPNs wie GlobalProtect gemacht. Da wir uns mit Snowflake verbinden, läuft ein Großteil der End-to-End-Verschlüsselung über die Cloud. Noch ein Vorteil von Snowflake!
Schließlich wollen wir unsere Aktivitäten überprüfen. Snowflake hat eine Abfrageprotokollierung über Tabellen wie QUERY_HISTORY und QUERY_HISTORY_BY_USER. Wir können die Nutzung, Fehler und jeglichen Sicherheitsmissbrauch in diesen Protokollen überwachen. Mit DBT können wir neue Durchläufe, Änderungen oder Bearbeitungen von Projekten über unsere Versionskontroll-Pipelines verfolgen.
Versionskontrolle und Codierungsvorlagen helfen dabei, den Lernpfad zu verfolgen und die Compliance sicherzustellen. Probleme, die durch Änderungen entstehen, kann man bei den obligatorischen Pull-Anfragen leicht erkennen und beheben, bevor sie zum Problem werden.
Lass uns darüber reden, wie wir etwas Geld sparen können! Natürlich in dbt. Die Überwachung der Leistung unseres Modells ist super wichtig. Modelle, die früher ohne Probleme liefen, werden mit zunehmender Größe einer Tabelle schnell langsamer und weniger leistungsfähig.
Mit dbt kannst du die Leistung am besten überwachen, indem du integrierte Pakete wie „ dbt-snowflake-monitoring “ oder externe Tools wie Looker und Datafold nutzt, die bei der Visualisierung und beim Datenvergleich helfen.
Der Einstieg in „ dbt-snowflake-monitoring “ ist echt einfach! Füge in deiner dbt- packages.yml -Datei Folgendes hinzu:
packages:
- package: get-select/dbt_snowflake_monitoring
version: [">=5.0.0", "<6.0.0"] # We'll never make a breaking change without creating a new major version.Dann füge in der YAML-Datei jedes Projekts Folgendes hinzu:
dispatch:
- macro_namespace: dbt
search_order:
- <YOUR_PROJECT_NAME>
- dbt_snowflake_monitoring
- dbt
query-comment:
comment: '{{ dbt_snowflake_monitoring.get_query_comment(node) }}'
append: true # Snowflake removes prefixed comments.Jetzt kannst du das Paket nutzen, um Sachen wie deine Lagerauslastung, Abfragedauer und fehlgeschlagene Modelle zu überwachen! Es nutzt den bestehenden Zugriff deines dbt-Benutzers, um Tabellen mit nützlichen Infos in Snowflake zu schreiben. Wenn ich zum Beispiel meine monatlichen Lagerkosten sehen will, könnte ich den folgenden SQL-Befehl verwenden:
select
date_trunc(month, date)::date as month,
warehouse_name,
sum(spend_net_cloud_services) as spend
from daily_spend
where service in ('Compute', 'Cloud Services')
group by 1, 2Externe Tools wie Looker oder Tableau können direkt in dbt eingebaut werden, um Daten und Leistung einfach zu visualisieren. Für Benachrichtigungen kann dbt E-Mails oder Slack-Nachrichten verschicken.
Für genauere Vergleiche bieten externe Stacks wie Datafold einen tieferen Einblick, wie sich Änderungen auf die Datenqualität auswirken. Datafold macht automatisch Datenvergleiche bei jeder Codeänderung, die du machst. So können andere Teammitglieder deinen Code und die Auswirkungen auf die Daten ganz einfach überprüfen. Mit solchen automatisierten Regressionstests können wir die Qualität der Daten aufrechterhalten, ohne ständig neue Prüfungen und Tools entwickeln zu müssen.
Wir können es nicht vermeiden, unsere ETL-Prozesse auszuführen, aber wir können auf jeden Fall im Voraus planen, um die Kosten für Rechenleistung und Speicherplatz zu minimieren. Dank dem geteilten Design von Snowflake können wir unsere Lager und Speicher separat optimieren, um eine flexiblere und kostenoptimierte Umgebung zu schaffen.
Für Lagerhäuser ist es am besten, Leerlaufzeiten so gering wie möglich zu halten. Verteil deine automatisierten Pipelines so weit wie möglich, um Leerlaufzeiten, Spitzen im Rechenbedarf und konkurrierende Ressourcen zu reduzieren.
Schau regelmäßig in den Tabellen „ WAREHOUSE_LOAD_HISTORY “ und „ QUERY_HISTORY “ nach, um zu sehen, wie die Ressourcen genutzt werden. Am besten fängt man mit XS an. Wenn die Abfragen zu langsam laufen, ist es Zeit, die Größe basierend auf dem SLA deines Teams anzupassen.
Für die Speicherung ist es am besten, unnötige Tabellen zu löschen. Snowflake selbst hat zwar keine Cold-Tiers wie AWS und Google, aber du kannst deine Daten von Snowflake zu AWS/Google für diese Cold-Tiers verschieben und so die Speicherkosten senken.
Richtlinien zur Datenaufbewahrung können ganz klar festlegen, wie lange selten genutzte Tabellen aufbewahrt werden und wann sie in den Cold Storage verschoben werden.
Behalte große Tabellen, die oft wachsen, genau im Auge. Wenn sie größer werden, funktioniert die automatische und effiziente Partitionierung von Snowflake nicht mehr so gut. Nutze das oben erwähnte automatische Clustering, damit Snowflake deine Daten besser partitionieren kann. Bessere Partitionen bedeuten weniger Zeit beim Lesen des Speichers und sparen so Kosten.
Dank der nativen Integration von dbt in die Versionskontrolle sind CI/CD und automatisierte Pipelines ein Kinderspiel. Wir schauen uns ein paar automatisierte Orchestrierungsoptionen und bewährte Testverfahren an.
Mit dbt Cloud können wir Snowflake Tasks nutzen, um geplante Ausführungen unserer dbt-Projekte zu starten. So läuft's ab: Erst erstellen wir mit unserem Git-Repository ein dbt-Projekt in Snowflake und dann machen wir eine Aufgabe, die dieses dbt-Projekt ausführt.
Zum Beispiel könnten wir so was wie das hier machen, um ein dbt-Projekt zu erstellen:
CREATE DBT PROJECT sales_db.dbt_projects_schema.sales_model
FROM '@sales_db.integrations_schema.sales_dbt_git_stage/branches/main'
COMMENT = 'generates sales data models';Dann machen wir das Projekt mit dem folgenden Code:
CREATE OR ALTER TASK sales_db.dbt_projects_schema.run_dbt_project
WAREHOUSE = sales_warehouse
SCHEDULE = '6 hours'
AS
EXECUTE DBT PROJECT sales_db.dbt_projects_schema.sales_model args='run --target prod';Es ist echt so umfassend, dass wir danach sogar Tests machen können, um sicherzugehen, dass das Projekt richtig gelaufen ist:
CREATE OR ALTER TASK sales_db.dbt_projects_schema.test_dbt_project
WAREHOUSE = sales_warehouse
AFTER run_dbt_project
AS
EXECUTE DBT PROJECT sales_db.dbt_projects_schema.test_dbt_project args='test --target prod';Für die Zeitplanung können wir entweder eine feste Zeit wie 60 MINUTES und 12 HOURS festlegen oder Cron wie folgt verwenden: USING CRON 0 9 * * * UTC..
Unsere Modelle bleiben aber selten so, wie sie sind, und wir müssen sie oft überarbeiten. Es kann echt zeitaufwendig sein, jedes Teil unserer Pipeline manuell zu erstellen. Hier kommen GitHub Actions ins Spiel. Wir nutzen GitHub Actions oft in CI/CD-Pipelines, um das Testen und Erstellen von Code zu automatisieren.
GitHub Actions werden mit YAML-Dateien im Ordner „ .github/workflows “ im Repository erstellt. Wir können sie so einrichten, dass sie jedes Mal ausgelöst werden, wenn wir einen Pull-Request machen, damit wir ein paar dbt-Tests durchlaufen.
name: dbt pull test
# CRON job to run dbt at midnight UTC(!) everyday
on:
pull_request:
types:
openedreopened
# Setting some Env variables to work with profiles.yml
# This should be your snowflake secrets
env:
DBT_PROFILE_TARGET: prod
DBT_PROFILE_USER: ${{ secrets.DBT_PROFILE_USER }}
DBT_PROFILE_PASSWORD: ${{ secrets.DBT_PROFILE_PASSWORD }}
jobs:
dbt_run:
name: dbt testing on pull request
runs-on: ubuntu-latest
timeout-minutes: 90
# Steps of the workflow:
steps:
- name: Setup Python environment
uses: actions/setup-python@v4
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
python -m pip install -r requirements.txt
- name: Install dbt packages
run: dbt deps
# optionally use this parameter
# to set a main directory of dbt project:
# working-directory: ./my_dbt_project
- name: Run tests
run: dbt test
# working-directory: ./my_dbt_projectWenn du deine Automatisierungen richtig einrichtest, kann das dein Leben echt vereinfachen und anderen Entwicklern helfen, deine getesteten Modelle zu sehen. Das macht den Entwicklungsprozess einfacher, weil weniger manuelle Tests nötig sind.
dbt hat eine echt starke Testsuite. Es gibt ein paar vorgefertigte generische Datentests, die du direkt in deinem Modell einstellen kannst und die eine benutzerdefinierte SQL-Logik ermöglichen. Die generischen Tests werden auf bestimmte Spalten in deinem Modell angewendet und prüfen, ob diese Spalten den Test bestehen. Die Tests, die du direkt nutzen kannst, sind:
uniqueJeder Wert in dieser Spalte sollte einzigartig sein.not_null: In der Spalte sollten keine Nullwerte vorkommen.accepted_values: Schaut nach, ob die Werte in einer Liste mit akzeptierten Werten drauf sind.relationshipsSchaut nach, ob die Werte in dieser Spalte in einer anderen, damit verbundenen Tabelle vorkommen.Hier ist ein Beispiel, wie man diese Beziehungen nutzen kann (aus der dbt-Dokumentation zu Tests):
version: 2
models:
- name: orders
columns:
- name: order_id
data_tests:
# makes sure this column is unique and has no nulls
- unique
- not_null
- name: status
data_tests:
#makes sure this column only has the below values
- accepted_values:
values: ['placed', 'shipped', 'completed', 'returned']
- name: customer_id
data_tests:
# makes sure that the customer ids in this column are ids in the customers table
- relationships:
to: ref('customers')
field: idWir können benutzerdefiniertes SQL nutzen, um spezifischere und allgemeinere Tests zu erstellen. Das Ziel ist, dass die Tests Zeilen zurückgeben,die nicht erfüllen. Wenn also irgendwelche Ergebnisse auftauchen, gilt der Test als nicht bestanden. Diese benutzerdefinierten SQL-Dateien sind in unserem Verzeichnis „ tests “ gespeichert.
Wenn wir zum Beispiel wissen wollen, ob irgendwelche Umsätze negativ waren, könnten wir Folgendes verwenden:
select
order_id,
sum(amount) as total_amount
from {{ ref('sales') }}
group by 1
having total_amount < 0Dann verweisen wir auf diesen Test in unserer Datei „ schema.yml “ in unserem Testordner:
version: 2
data_tests:
- name: assert_sales_amount_is_positive
description: >
Sales should always be positive and are not inclusive of refunds
Wenn wir diese Art von Überprüfung auf mehr Tabellen und Spalten anwenden wollen, sollten wir das vielleicht in einen generischen Test umwandeln. Das könnte so aussehen:
{% test negative_values(model, group,sum_column) %}
select {{group}},
sum({{sum_column}}) as total_amt
from {{ model }}
group by 1
having total_amt < 0
{% endtest %}Wir können diesen Test jetzt in der YAML-Datei unserer Modelle genauso wie die anderen generischen Tests von dbt verwenden! Du könntest nach negativen Passagieren auf einer Reise oder nach negativen Gewinnen und so weiter suchen! Die Möglichkeiten sind echt unbegrenzt.
Um diese Tests nahtloser und einfacher zu gestalten, können wir die Zero-Copy-Klonfunktion von Snowflake nutzen. Mit dem Snowflake-Tool „ Dann kannst du alle deine Tests und CI am geklonten Objekt machen. Der Vorteil dabei ist, dass wir keinen zusätzlichen Speicherplatz brauchen, um eine sichere Testumgebung zu haben. Außerdem können wir mit diesem Instant-Cloning jederzeit mehr Testumgebungen erstellen, wenn wir mehr Platz zum Testen brauchen. Schauen wir mal, welche Verbesserungen und Trends in Zukunft von dbt und Snowflake kommen werden. dbt arbeitet ständig daran, die Integration sowohl mit seinem Hauptprodukt als auch mit KI zu verbessern. In Snowflake können wir Snowsight als Benutzeroberfläche nutzen, um unsere dbt-Arbeitsbereiche zu verwalten. Durch die nahtlosere Integration in unsere Snowflake-Umgebung müssen wir weniger an dbt-Modellen außerhalb arbeiten. Stattdessen können wir unsere Arbeitsabläufe zentralisieren, indem wir den Teams erlauben, über die Benutzeroberfläche von Snowflake zu bearbeiten und zusammenzuarbeiten. Um die Entwicklung zu beschleunigen, hat dbt einen KI-gestützten Assistenten namens dbt Copilot entwickelt. Dieser Assistent ist über die dbt Studio IDE, Canvas oder Insights erreichbar und nutzt natürliche Sprachverarbeitung, um die zeitaufwändigeren Teile der Modellentwicklung, wie das Schreiben von Dokumentationen und das Erstellen von Tests, zu beschleunigen. Mit dem dbt Copilot kann man sogar neue Analysten einarbeiten, indem man ihnen kurze Zusammenfassungen von Projekten und Modellen gibt. Nutze diese beiden Tools, um schneller produktiv zu werden und die Entwicklungszeit zu verkürzen, damit dein Team sich um die schwierigeren und anspruchsvolleren Datenprobleme in deinem Unternehmen kümmern kann. Machine-Learning-Pipelines brauchen immer saubere und gut aufbereitete Daten. dbt ist das perfekte Tool für Datenumwandlungspipelines, die Machine-Learning-Modelle mit Daten füttern. Wir können die Flexibilität und Leistungsfähigkeit von dbt nutzen, um Datenumwandlungen zu automatisieren, die sich nahtlos in unsere Machine-Learning-Pipelines einfügen. Zum Beispiel können wir unsere Daten direkt in ein Machine-Learning-Warehouse umwandeln. Diese Daten können dann mit Snowflake's Cortex AI verwendet werden, um tiefere Einblicke zu gewinnen. Wenn wir mehrere Modelle haben, die ähnliche Transformationen brauchen, kann die Vorlagenfunktion von dbt die Bereinigung unserer Daten vereinfachen und für mehr Konsistenz und eine einfachere Datenverwaltung sorgen. Um einen besseren Eindruck von den KI-Tools von Snowflake zu bekommen, lies diesen Leitfaden zu Snowflake Arctic, dem LLM von Snowflake. Dank der nativen Python-Unterstützung von Snowflake und der Snowpark-API für Python können wir Code lokal ausführen, ohne Daten aus Snowflake verschieben zu müssen. Die nächste Stufe ist die Verwendung von Snowpark Containern, die im Moment (zum Zeitpunkt des Verfassens dieses Artikels) nur in AWS- und Azure-Regionen verfügbar sind, um unseren dbt-Code komplett isoliert auszuführen. Dafür packen wir unsere dbt-Modelle und -Umgebung in einen Container, der dann im Image-Repository von Snowflake gespeichert wird. Dann können wir dieses containerisierte dbt-Projekt ganz einfach in Snowpark nutzen. Der größte Vorteil? Die Möglichkeit, die Ressourcen von Snowflake einfacher für komplexe Python-basierte Datentransformationen und die Integration von dbt-Transformationen in die größere Snowflake-Umgebung zu nutzen. Wenn du mehr über den Snowpark erfahren möchtest, schau dir diese Infos an, die den Snowflake Snowpark im Detail. Durch die Integration von dbt mit Snowflake können Datenteams modulare, kontrollierte und skalierbare Transformationspipelines erstellen. Mit Funktionen wie automatisierten Tests, Git-gesteuerten CI/CD-Workflows und nahtloser Skalierbarkeit ist dieser Stack perfekt für moderne Datenoperationen. Um wettbewerbsfähig zu bleiben, sollten Datenteams folgende Prioritäten setzen: Da beide Tools immer weiter verbessert werden, wird die Integration von dbt und Snowflake für Datenentwicklungsteams immer leistungsfähiger. Wenn du mehr über DBT oder Snowflake erfahren möchtest, schau dir die folgenden Ressourcen an:CREATE TABLE CLONE “ kannst du einen Zero-Copy-Klon in deiner Entwicklungs-/Testumgebung erstellen.
Neue Trends und Zukunftsaussichten
Native Integrationsentwicklungen
Integration von maschinellem Lernen
Containerisierte Ausführung
Fazit
Top-Kurse von DataCamp
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
