Curso
Introducción a la seguridad de los datos
2 h
12.8K
IA y ML suelen utilizarse indistintamente. Pero si tuviera que definirlos y mostrar sus diferencias rápidamente, diría que la IA se refiere a la tecnología que construye máquinas para imitar las funciones cognitivas asociadas a la inteligencia humana, mientras que el ML se refiere a un subconjunto de algoritmos de IA que aprenden y mejoran a partir de los datos.
En este artículo, quiero hacer un recorrido por la aplicabilidad de las técnicas de aprendizaje automático en la ciberseguridad, mostrando una serie de casos de uso y los retos de la explicabilidadinterpretabilidad y robustez que deben abordarse para aprovechar su potencial.
La detección y respuesta a las amenazas se refiere a la detección de ciberamenazas contra redes o sistemas, seguida de estrategias de mitigación rápidas y eficaces. Este proceso implica detectar comportamientos anómalos en redes y sistemas, identificar intrusiones no autorizadas y analizar muestras de malware para proteger nuestros sistemas.
Detectar anomalías se refiere a identificar patrones en los datos que no se ajustan a una noción bien definida de comportamiento normal.
Este concepto fundamental es aplicable a diversos campos, y la ciberseguridad no es una excepción. Utilizo la detección de anomalías para identificar diversas actividades maliciosas, como la detección de la exfiltración de datos, los ataques distribuidos de denegación de servicio (DDoS), las infecciones de malware y otras.Diversos algoritmos de aprendizaje automático, como Local outlier factor (LOF), Isolation forest, One-class support vector machine (OC-SVM)para detectar anomalías. Sin embargo, la selección de la técnica adecuada para identificar valores atípicos es una tarea compleja que requiere una cuidadosa consideración de varios factores, entre ellos:
Exploraremos cómo seleccionamos las técnicas de aprendizaje automático adecuadas y también explicaremos cómo detectan las actividades maliciosas de ciberseguridad. Nos centraremos en dos aplicaciones críticas en ciberseguridad: la detección de intrusos y el análisis de malware.
Los sistemas de detección de intrusos (IDS) son los ojos y oídos de las redes y sistemas informáticos, que supervisan y analizan el tráfico de red (IDS basados en red) y las llamadas al sistema (IDS basados en host) en busca de actividades maliciosas.
A lo largo de mis experimentos, he sido testigo de la potencia de los enfoques de detección de anomalías de ambos sistemas a la hora de detectar la presencia de amenazas nuevas o previamente desconocidas que eluden las técnicas basadas en firmas, que se basan en patrones de ataque predefinidos para su detección.
Antes de sumergirte en los IDS basados en host, es importante entender qué son las llamadas al sistema. Básicamente, son peticiones que hace un programa al sistema operativo para que realice tareas específicas. Supón que utilizas un editor de texto para modificar un fichero en un sistema operativo Linux. Entre bastidores, tu editor de texto solicita abrir un archivo mediante la llamada al sistema open(), escribir cambios en él mediante write(), y luego guardarlo cerrando el archivo mediante close().
Mientras que las llamadas al sistema de un editor de texto son directas y predecibles, la secuencia de llamadas al sistema de un actor malicioso suele ser engañosa. Un programa malicioso podría emplear una serie como open(), write() para soltar un archivo oculto, y luego utilizar execve() para ejecutarlo con privilegios elevados. A esto le siguen llamadas relacionadas con la red como socket() para establecer potencialmente un ataque por canal de mando y control.
Para solucionarlo, las secuencias de llamadas al sistema suelen transformarse en una representación estática de características adecuada para los algoritmos de aprendizaje automático. Pero, quizá te preguntes, ¿qué técnica de aprendizaje es la más adecuada para entrenar modelos de aprendizaje automático en este caso?
La elección de la técnica de aprendizaje depende en gran medida de la disponibilidad de etiquetas. Si se puede acceder a un conjunto de datos equilibrado que incluya secuencias normales y anómalas de llamadas al sistema, yo optaría sin duda por modelos supervisados de detección de anomalías como Máquinas de vectores de apoyo (SVM).
Por el contrario, en ausencia de datos etiquetados, puedo utilizar modelos de aprendizaje no supervisado como Bosque de aislamiento. Para escenarios en los que sólo el comportamiento normal está representado en los datos de entrenamiento, busco técnicas de aprendizaje semisupervisado como SVM de una clase o DBSCAN.
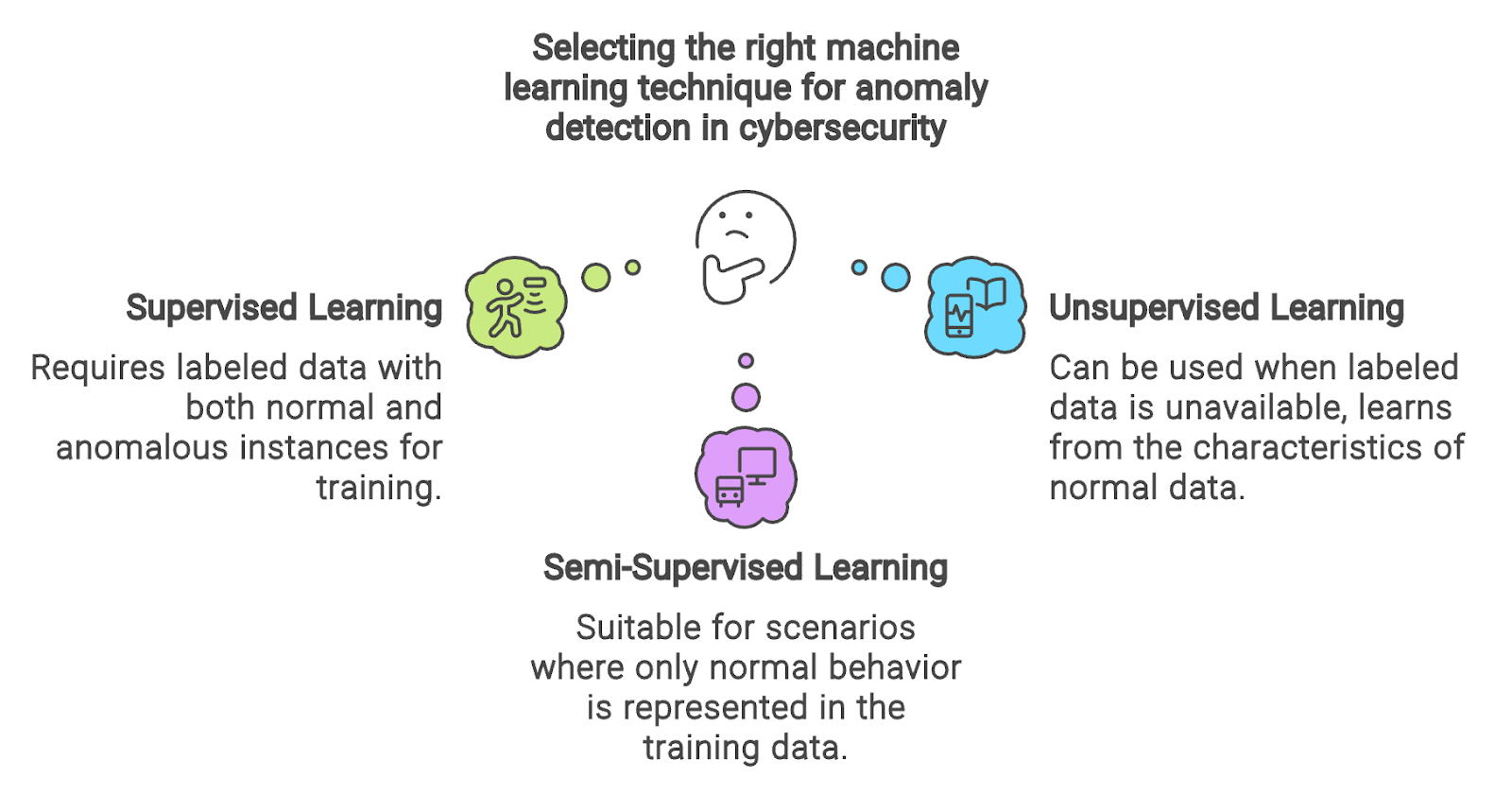
Diagrama creado con Napkin.ai
Ahora que hemos entendido cómo se aplica el ML a los IDS basados en host, pasemos al ámbito de los IDS basados en red. Mientras que los sistemas basados en host se centran en máquinas individuales, los IDS basados en red identifican las intrusiones en los datos de la red; es decir, en lugar de analizar las llamadas al sistema, los IDS de red inspeccionan el robo de información y las actividades de interrupción de la red mediante el control de las estadísticas de flujo de la red, los datos de carga útil y las cabeceras de los paquetes.
Un rápido vistazo a la siguiente tabla puede ayudarte a hacerte una idea de cómo es un conjunto de datos de flujo de red.
|
Puerto de destino |
Fuente Puerto |
Duración del flujo (ms) |
Total Paquetes Fwd |
Total Paquetes Bckwd |
Etiqueta |
|
54865 |
9910 |
6 |
5000 |
600 |
0 |
|
54810 |
9010 |
2 |
2000 |
200 |
1 |
Estadísticas sintéticas de flujos de red normales y anormales.
Cada fila del conjunto de datos representa una sesión de comunicación de red independiente entre dos puntos finales, sin relaciones inherentes con otros flujos del conjunto de datos.
Cada flujo se define mediante atributos como los números de puerto de origen y destino, la duración del flujo en milisegundos y el número total de paquetes intercambiados en ambas direcciones. Una etiqueta categórica indica si el flujo de red se clasifica como anómalo o como ataque, lo que proporciona una verdad de base esencial para los modelos de detección de intrusos.
En particular, cada fila representa un flujo de red independiente sin dependencias secuenciales o relacionales con otros flujos de red del conjunto de datos.
Dada la naturaleza independiente de los flujos de red, el conjunto de datos puede alimentarse tras algunas técnicas de ingeniería de características en algoritmos de aprendizaje automático para la detección de anomalías. Como se ha comentado anteriormente en el contexto de los IDS basados en host, la selección de técnicas de aprendizaje automático adecuadas está condicionada a la disponibilidad de datos etiquetados.
Antes de pasar al análisis del malware, debemos explicar qué es y cómo funciona.
Malware es un término para referirse al software malicioso o ejecutables binarios diseñados para llevar a cabo las intenciones dañinas de un atacante. Este fragmento de código aprovecha intencionadamente las vulnerabilidades de los sistemas objetivo para comprometer su integridad, robar datos confidenciales, borrar datos e incluso cifrar datos para pedir un rescate. Puede presentarse en muchas categorías, como virus, gusanos, spyware, troyanos, ransomware, etc.
Para comprender el tipo de malware, su funcionalidad y su impacto potencial, se extraen varias características del análisis estático y dinámico y se introducen en algoritmos adecuados de aprendizaje automático.
Considera el análisis de malware de ejecutables de Windows, es decir, ejecutables portátiles (PE). Podemos extraer diversas características procedentes del análisis dinámico y estático de los PE, como secuencias de bytes, API/llamadas al sistema, opcodes, red, sistema de archivos, registros de la CPU, características y cadenas de los archivos PE, y luego introducirlas en modelos de aprendizaje automático supervisados, no supervisados y semisupervisados adecuados para detectar malware.
Para mitigar los riesgos de estar expuestos a ciberataques, tenemos que identificar, evaluar y abordar rápidamente las posibles deficiencias de seguridad en nuestras redes, ordenadores y aplicaciones. Veamos el papel que desempeñan la IA y los algoritmos ML en la mejora de la gestión de vulnerabilidades mediante el escaneado de vulnerabilidades, la gestión de parches y la evaluación de riesgos.
Como investigador en ciberseguridad, con frecuencia desarrollo herramientas personalizadas para automatizar tareas de ciberseguridad, como analizadores sintácticos de registros de tráfico de red, fuzzers y otros.
Aunque estas herramientas pueden mejorar significativamente nuestras operaciones de seguridad, es importante someterlas a un riguroso análisis de vulnerabilidades antes de utilizarlas y compartirlas con mis colegas.
De lo contrario, un atacante puede explotar vulnerabilidades no descubiertas ni parcheadas en mi script personalizado para obtener acceso no autorizado, comprometer información sensible o interrumpir los servicios de nuestra empresa.
Los modelos de aprendizaje automático tienen la capacidad de ver el bosque por los árboles. Destacan en la extracción de características significativas de grandes conjuntos de datos, descubriendo patrones y correlaciones sutiles. Teniendo esto en cuenta, he empezado a explorarlas para ver si son capaces de automatizar la detección de vulnerabilidades, hacer análisis más rápidos e identificar vulnerabilidades no reveladas anteriormente.
Para construir un modelo de detección de vulnerabilidades basado en ML, empiezo recopilando varios tipos de datos vulnerables y no vulnerables para entrenar el modelo a partir de diversas fuentes, incluida la NVD (Base de Datos Nacional de Vulnerabilidades), OWASPetc.
A continuación, la colección se preprocesa e integra para introducirla en el modelo elegido. La entrada podría representarse como un Gráfico o Árbol que muestre las relaciones entre los distintos elementos del código, como Gráfico de propiedades del código (CPG) o Árboles de sintaxis abstracta (AST).
La entrada también puede tener una representación basada en tokens, en la que el código fuente se transforma en vectores de tokens. Varias técnicas de incrustación que se pueden aplicar posteriormente, como Word2Vec, incrustación de grafos, incrustación en caliente, características N-gram, etc.
Como se ha explicado en aplicaciones anteriores, elegir un modelo de aprendizaje automático y su técnica de aprendizaje depende principalmente de la disponibilidad de etiquetas. En la fase de entrenamiento, el conjunto de datos de detección de vulnerabilidades se separa en conjuntos de entrenamiento y validación, y el modelo aprende de los datos etiquetados.
Los parámetros del modelo se actualizan iterativamente en función de los errores de predicción mediante técnicas de optimización. Después de que el modelo complete su proceso de aprendizaje, se mide su capacidad para detectar vulnerabilidades utilizando datos no vistos. Indicadores clave de rendimiento como exactitud, precisión, recuperación y puntuación F1 para evaluar la capacidad del modelo para detectar vulnerabilidades.
Al detectar vulnerabilidades en mi script personalizado, es esencial realizar una evaluación exhaustiva de los riesgos. Si los controles de seguridad existentes impiden la explotación de las vulnerabilidades descubiertas o las consecuencias potenciales son mínimas, podría aceptarse el riesgo.
Alternativamente, también se podría considerar la posibilidad de evitar por completo el uso del código desarrollado para eliminar cualquier riesgo de explotación. Sin embargo, si la eliminación completa no es factible, es crucial aplicar estrategias de mitigación.
A continuación, exploraremos la aplicación de parches al software vulnerable como principal táctica de mitigación.
Aunque abordar todas las vulnerabilidades abiertas y críticas es lo ideal, a menudo resulta poco práctico. Es esencial un enfoque más estratégico. Utilizando el aprendizaje automático, podemos predecir proactivamente qué vulnerabilidades tendrán más probabilidades de ser explotadas para causar incidentes de seguridad. Esto nos permite priorizar los esfuerzos de parcheado.
Creado con Napkin.ai
Para agilizar nuestro proceso de priorización de parches, utilizamos el método basado en árboles preentrenado Sistema de Puntuación de Predicción de Ataques (EPSS) que combina la información sobre vulnerabilidades con la actividad de explotación del mundo real para predecir la probabilidad de que los atacantes intenten utilizar una vulnerabilidad específica en los próximos treinta días.
El modelo de aprendizaje automático del EPSS identifica patrones y relaciones entre la información sobre vulnerabilidades, como el CVSS, y la actividad de explotación para identificar matemáticamente la probabilidad de que los atacantes utilicen una vulnerabilidad.
Tras la priorización de vulnerabilidades, los parches se someten a una rigurosa adquisición, validación y prueba para mitigar los riesgos operativos. La implantación de parches es un proceso complejo que depende de varios factores, entre ellos:
Dada la escala y diversidad de los entornos informáticos modernos, el despliegue manual de parches suele requerir mucho trabajo y tiempo. La automatización impulsada por la IA puede agilizar este proceso seleccionando y desplegando de forma inteligente el parche adecuado para cada sistema, basándose en estos factores críticos.
Algoritmos de agrupación, como K-meanspueden utilizarse en este caso para agrupar sistemas similares y desplegar parches de forma más eficaz.
La evaluación de riesgos cibernéticos es importante para identificar, evaluar y mitigar las amenazas potenciales y las vulnerabilidades detectadas.
Dado que los enfoques tradicionales a menudo se quedan cortos a la hora de encontrar indicadores de ciberriesgos impredecibles, los investigadores han empezado a recurrir al aprendizaje automático.
Utilizando ML de clasificación supervisada y multiclase, los investigadores pueden mejorar la evaluación del ciberriesgo mediante un análisis exhaustivo de los factores clave.
Como se indica en la tabla siguiente, estos factores incluyen la inversión en ciberseguridad, las características de la plantilla, el historial de ataques, las vulnerabilidades de la infraestructura, el asesoramiento externo y el riesgo asociado. Su marco basado en la prueba de concepto SecRiskAI ML demuestra el potencial del ML para predecir la probabilidad de ataques DDoS o phishing.
|
Información |
Ejemplo |
|
Ingresos |
2,500,000 |
|
Inversión en ciberseguridad |
500,000 |
|
Ataques con éxito |
5 |
|
Ataques fallidos |
10 |
|
Número de empleados |
4,450 |
|
Formación de empleados |
Medio |
|
Vulnerabilidades conocidas |
9 |
|
Asesor externo en ciberseguridad |
No |
|
Riesgo |
Baja |
Un ejemplo de atributos clave para la evaluación del riesgo cibernético (Fuente)
Ahora vamos a explorar cómo la IA y el ML están cambiando la respuesta a incidentes. Exploraremos cómo automatizan los flujos de trabajo de respuesta a incidentes, reducen los tiempos de respuesta, descubren proactivamente amenazas ocultas y mejoran el análisis forense para rastrear los orígenes y el impacto de los ciberataques.
He observado de primera mano cómo los sistemas SOAR están diseñados para recibir alertas de los sistemas de Gestión de Información y Eventos de Seguridad (SIEM) y activar los libros de jugadas adecuados que automatizan y coordinan una serie de tareas de seguridad.
Estas tareas pueden incluir acciones de investigación, como comprobar la reputación de las URL o recuperar detalles de usuarios y activos, así como acciones de respuesta, como bloquear una dirección IP en un cortafuegos o matar un proceso malicioso en un endpoint.
Sin embargo, actualmente nos enfrentamos a importantes limitaciones dentro de estos sistemas. Los analistas de seguridad tienen que definir, crear y modificar manualmente los libros de jugadas, y la selección entre varios libros de jugadas se rige por reglas establecidas por los analistas de seguridad.
Para superar estas limitaciones, he visto cómo la integración de la IA y el ML en las plataformas SOC puede revolucionar este proceso, permitiéndonos generar automáticamente libros de jugadas capaces de
responder a alertas desconocidas.
Esto no sólo aumenta la eficacia de nuestra respuesta, sino que también permite a los analistas centrarse en más tareas. Mediante algoritmos ML, también podemos entrenarlo para que calcule el coste de penalización de cada acción de respuesta en función de la alerta recibida y seleccione la respuesta con la penalización más baja.
Imagina lo estresante que sería cribar millones de registros, intentando identificar posibles amenazas.
Ahora, amplía el reto a la escala de una empresa, donde todos y cada uno de los registros deben examinarse uno por uno y clasificarse como maliciosos o benignos.
Al incorporar el aprendizaje automático al proceso, podemos simplificar esta tarea y acelerar la detección de amenazas. Los algoritmos de IA y ML, es decir, SVM, Random Forest, pueden entrenarse para analizar y categorizar los registros de forma eficaz, lo que permite identificar rápidamente las amenazas y reducir la carga de los equipos de seguridad.
A medida que los datos digitales siguen creciendo en volumen y complejidad, la integración de la IA y el ML en la ciencia forense digital -el análisis de las pruebas digitales para investigar los ciberdelitos- se ha vuelto esencial.
Esta integración nos permite mejorar la rapidez, precisión y eficacia de la identificación y respuesta a las ciberamenazas.
La IA y el ML pueden utilizarse en el triaje forense, por ejemplo. En este caso, utilizamos algoritmos de ML para clasificar y categorizar un gran número de archivos digitales en función de su relevancia para una investigación.
La integración de la IA en la ciberseguridad presenta importantes oportunidades. Sin embargo, también es importante reconocer sus retos y limitaciones inherentes.
Muchos sistemas de IA son susceptibles de ataques de adversarioses decir, envenenamiento, evasión, extracción de modelos inyección puntuale inferencia, que explotan sus vulnerabilidades.
En estos ataques, los adversarios añaden cuidadosamente perturbaciones a la entrada que son imperceptibles para los humanos, pero que pueden hacer que los modelos hagan predicciones incorrectas. Esto plantea problemas de seguridad sobre el despliegue de estos sistemas en entornos críticos para la seguridad, y la ciberseguridad no es una excepción.
Para combatir eficazmente estos ataques, empleamos varios mecanismos defensivos, como el entrenamiento adversarial, la destilación defensiva destilacióny enmascaramiento de gradiente.
Aunque los algoritmos de IA demuestran su eficacia en la consecución de resultados y predicciones, me cuesta entender sus mecanismos internos de funcionamiento.
Esto es muy importante en mi campo, ya que confiar decisiones críticas a un sistema inexplicable presenta riesgos evidentes.
En este caso, la IA explicable (XAI) ofrece una vía para desarrollar sistemas de ciberseguridad impulsados por IA con mayor explicabilidad, manteniendo al mismo tiempo un alto rendimiento. Al proporcionar transparencia en la toma de decisiones sobre IA, XAI me ayuda a realizar análisis bien informados y a tomar las medidas más adecuadas en respuesta a los incidentes de seguridad.
Los recientes avances en las técnicas de XAI, es decir, el análisis de importancia de las características y la visualización del árbol de decisión, están haciendo posible esta transparencia.
Siempre que selecciono un conjunto de datos para entrenar mis soluciones de ciberseguridad basadas en IA, me aseguro de que no esté sesgado. De lo contrario, mis modelos desarrollados podrían dar lugar a resultados injustos o discriminatorios. Empleo técnicas de preprocesamiento de datos para identificar y eliminar sesgos, presento el entrenamiento en datos e implemento técnicas de imparcialidad para evaluar el resultado del modelo en busca de posibles sesgos.
Si has leído hasta aquí, habrás visto cómo la IA y el ML están cambiando la forma en que protegemos nuestros ordenadores, dispositivos móviles, redes y aplicaciones. Has sido testigo de cómo potencian a los equipos de seguridad, detectan las amenazas más rápidamente y refuerzan diversas herramientas de ciberseguridad.
Y esto es lo emocionante: Creo que acabamos de empezar.
El futuro de la ciberseguridad reside en la evolución continua de la IA y el ML, especialmente en grandes modelos lingüísticos (LLM). Gracias a su límite de tokens ampliado, su capacidad de interpretación del código y su análisis detallado, estos modelos avanzados mejorarán nuestra capacidad de analizar y responder a las amenazas, ampliando el análisis del malware con mayor rapidez y precisión.
Considera el caso de modelo Gemini 1.5 que se utiliza actualmente para detectar malware en archivos enormes. A pesar de carecer de formación específica en ciberseguridad, pueden resolver tareas relevantes mediante ingeniería rápidaaprendizaje en contexto y cadenas de pensamiento.
También estamos vislumbrando ese futuro a través del perfeccionamiento de los LLM de peso abierto, entre ellos Llamapara tareas relacionadas con la ciberseguridad, como Hackmentor.
En este blog, hemos examinado cómo las herramientas de ciberseguridad basadas en IA y ML son útiles para hacer frente a la naturaleza dinámica y compleja de las ciberamenazas modernas. Estas herramientas son eficaces para detectar, responder y mitigar los riesgos mediante aplicaciones específicas de detección de amenazas, gestión de vulnerabilidades y respuesta a incidentes.
Sin embargo, también debemos considerar los importantes retos e implicaciones éticas asociados al desarrollo y despliegue de soluciones de ciberseguridad basadas en la IA.
A pesar de estos retos, el avance continuo de las tecnologías de IA y ML es muy prometedor para reforzar nuestras defensas contra las ciberamenazas en evolución.
Más información sobre la seguridad de los datos
Curso
Curso
Curso
blog
Javier Canales Luna
10 min
blog
Bhavishya Pandit
7 min
blog
Javier Canales Luna
14 min
blog
Austin Chia
Tutorial
Zoumana Keita
