
programa
Fundamentos de Hugging Face
12 h
Qwen3-VL-8B es el modelo de lenguaje visual más potente y utilizado de la serie Qwen, diseñado para la comprensión unificada de texto, imágenes y vídeo.
Ofrece importantes mejoras en la generación de texto, el razonamiento visual, la percepción espacial, el manejo de contextos largos y la interacción con agentes, lo que lo hace adecuado tanto para la investigación como para su implementación en el mundo real en entornos periféricos y en la nube.
En este tutorial, vamos a ajustar Qwen3-VL-8B-Instruct en diagramas esquemáticos electrónicos. Al entrenar el modelo para interpretar símbolos esquemáticos, conexiones y relaciones espaciales, le permitimos comprender con precisión los diseños de circuitos y determinar qué componentes electrónicos deben añadirse en un circuito real.
Aprenderás a:
Si Hugging Face todavía es nuevo para ti, los Hugging Face Fundamentals es perfecto para ti.
Cuando se trabaja con modelos de visión-lenguaje, la memoria de la GPU se convierte en una limitación crítica. Las imágenes de alta resolución y los codificadores multimodales pueden consumir rápidamente la VRAM, por lo que se recomienda encarecidamente utilizar una GPU con memoria suficiente.
Para este tutorial, iniciaremos una instancia instancia RunPod A100 (80 GB) utilizando la última versión de PyTorch. Esta configuración proporciona suficiente margen de VRAM para el entrenamiento y evita cuellos de botella innecesarios en la memoria durante el ajuste fino.
Desplázate hacia abajo hasta la sección«Plantilla de pod» ( ). Aquí, selecciona laúltima imagen de PyTorch de . Aquí también puedes ajustar la configuración de almacenamiento y añadir variables de entorno.
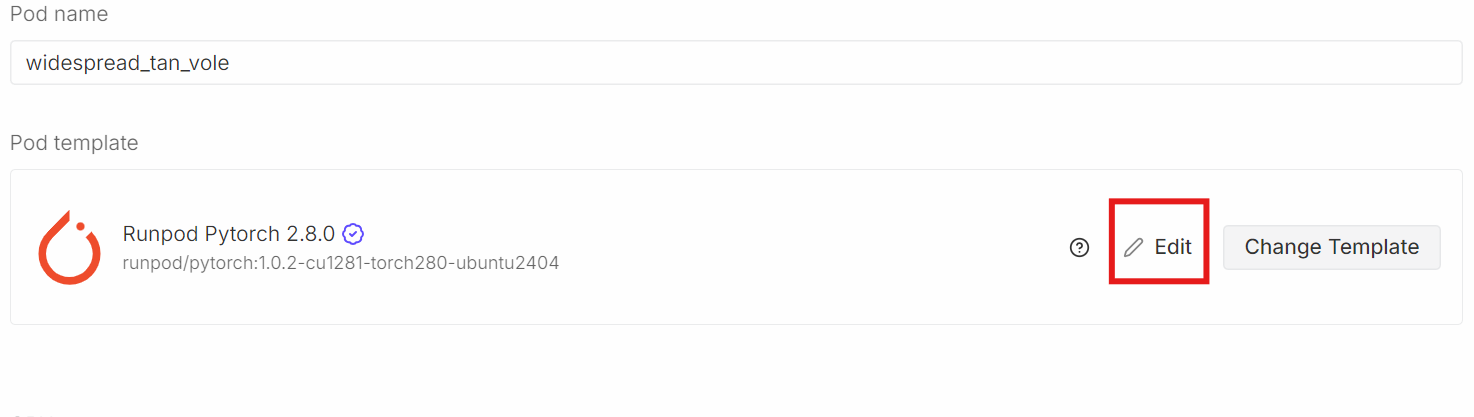
Haz clic en Editary realiza los siguientes cambios:
HF_TOKEN y establece su valor en tu token de acceso a Hugging Face (genéralo desde la configuración de Hugging Face).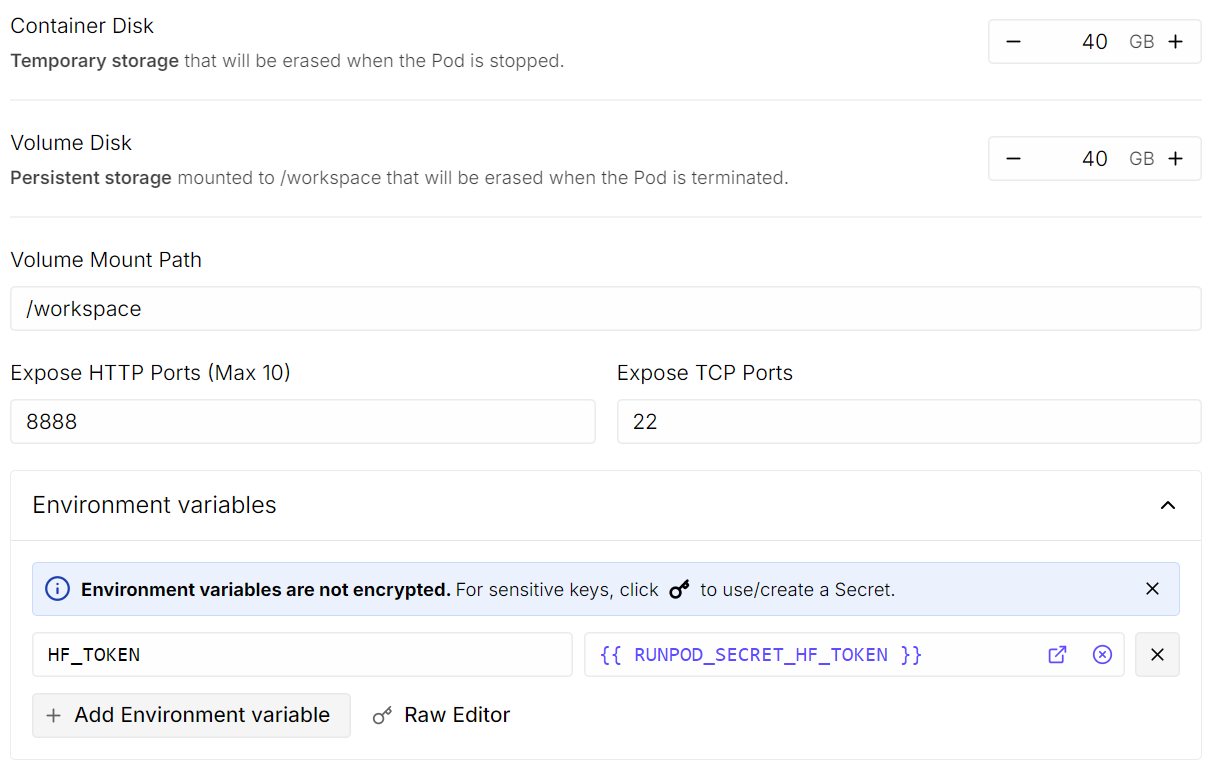
Una vez hecho esto, guarda la plantilla e implementa el pod.
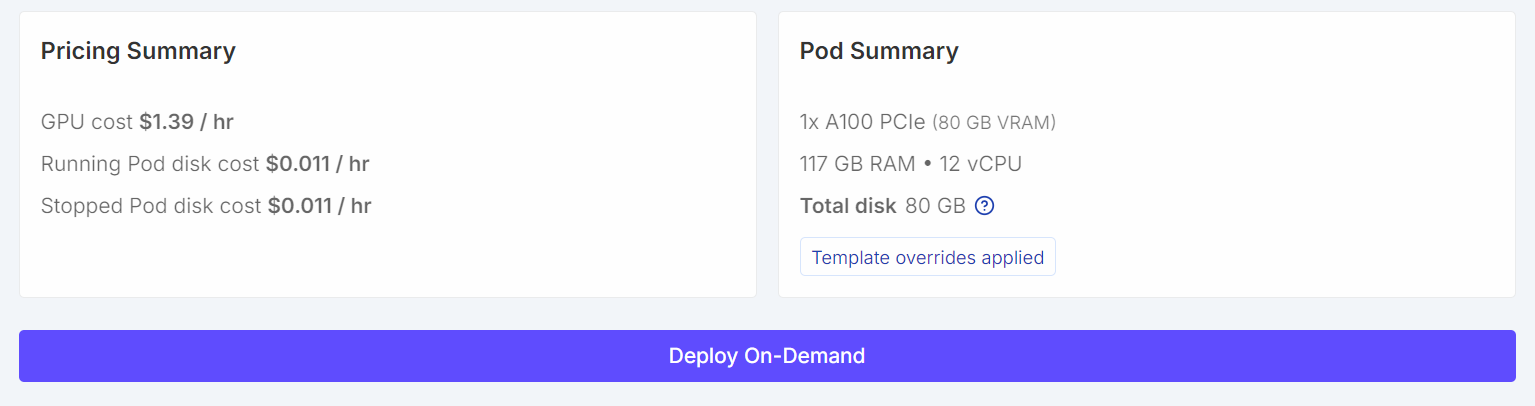
Una vez que el pod esté en funcionamiento:
Para instalar las dependencias, ejecuta la siguiente celda de código. En Jupyter, un signo de exclamación al principio indica al cuaderno que ejecute la línea como un comando de terminal en lugar de como código Python.
!pip -q install -U accelerate datasets pillow sentencepiece safetensors peft
!pip install --quiet "transformers==5.0.0rc1"
!pip install --quiet --no-deps trl
!pip install --no-cache-dir flash-attn --no-build-isolationA continuación, establece una semilla aleatoria fija para garantizar la reproducibilidad y habilita las optimizaciones de rendimiento específicas para A100.
import torch
from transformers import set_seed
set_seed(42)
# A100: TF32 gives speedups without changing your bf16 training setup
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
print("CUDA:", torch.cuda.is_available(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
print("bf16 supported:", torch.cuda.is_available() and torch.cuda.is_bf16_supported())CUDA: True NVIDIA A100 80GB PCIe
bf16 supported: TrueAhora cargaremos el conjunto de datos Open Schematics « » (Comportamiento de los seres humanos en la vida cotidiana) desde Hugging Face Hub. Este conjunto de datos contiene imágenes esquemáticas electrónicas junto con metadatos detallados que describen cada circuito, lo que lo hace muy adecuado para el entrenamiento de visión-lenguaje.
import torch
from datasets import load_dataset
DATASET_ID = "bshada/open-schematics"
ds_all = load_dataset(DATASET_ID, split="train")
print(ds_all)Dataset({
features: ['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'],
num_rows: 84470
})El conjunto de datos contiene más de 84 000 muestras, cada una de las cuales empareja una imagen esquemática con información estructurada, como listas de componentes y formatos legibles por máquina (JSON y YAML).
Analicemos una sola muestra para comprender mejor la estructura del conjunto de datos.
# quick peek
ex = ds_all[0]
print("\nSample keys:", ex.keys())
print("name:", ex.get("name"))
print("type:", ex.get("type"))
print("components_used:", (ex.get("components_used") or [])[:10])
print("has schematic:", bool(ex.get("schematic")))
print("has json/yaml:", bool(ex.get("json")), bool(ex.get("yaml")))
print("image:", ex.get("image"))Sample keys: dict_keys(['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'])
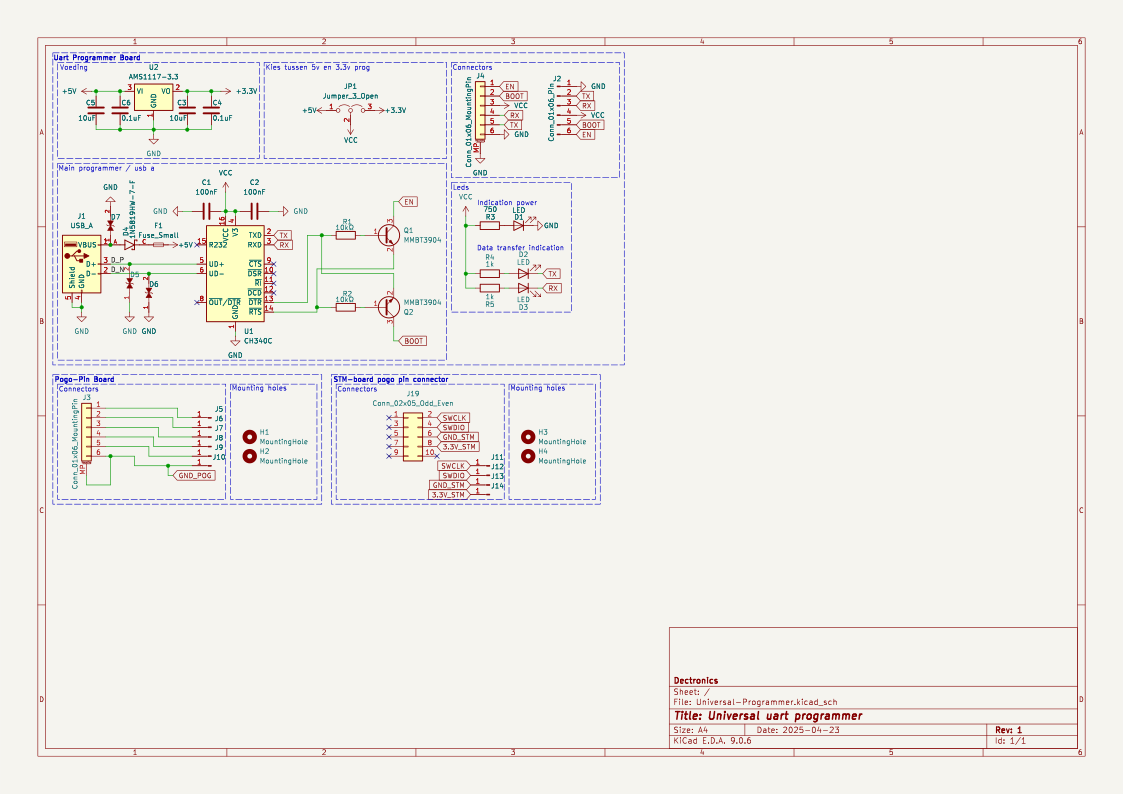
name: TiebeDeclercq/Uart-programmer
type: .kicad_sch
components_used: ['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C']
has schematic: True
has json/yaml: True True
image: <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=1123x794 at 0x7FBC6FD060F0>Esto confirma que cada muestra incluye una imagen esquemática de alta resolución, una lista de componentes y representaciones estructuradas del circuito.
Ahora podemos renderizar la imagen esquemática directamente dentro del cuaderno Jupyter.
ex.get("image")
Por último, revisamos la lista completa de componentes utilizados en este esquema.
print(ex.get("components_used"))['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C', 'Jumper_3_Open', 'MountingHole', 'AMS1117-3.3', 'MMBT3904', '1N5819HW-7-F', 'LESD5D5.0CT1G', '+3.3V', '+5V', 'GND', 'VCC']Esta lista de componentes proporciona una base clara entre la imagen esquemática y los elementos electrónicos presentes en el circuito.
Antes del entrenamiento, limpiamos y filtramos el conjunto de datos para garantizar que cada muestra contenga la información mínima necesaria para el aprendizaje de visión-lenguaje. En particular, nos centramos en conservar ejemplos que tengan anotaciones de componentes válidas y una imagen esquemática correspondiente.
En primer lugar, examinamos cuántas muestras tienen entradas components_used es que faltan, están vacías o no son válidas.
need_cols = [c for c in ["components_used", "schematic", "name", "type"] if c in ds_all.column_names]
ds_small = ds_all.select_columns(need_cols)
missing_key = none_components = empty_components = missing_any = 0
has_schematic_but_missing = 0
for ex in ds_small:
if "components_used" not in ex:
missing_key += 1
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
continue
cu = ex["components_used"]
bad = (cu is None) or (isinstance(cu, list) and len(cu) == 0)
if cu is None:
none_components += 1
elif isinstance(cu, list) and len(cu) == 0:
empty_components += 1
if bad:
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
print("\n=== Missing components report ===")
print("Total:", len(ds_all))
print("Missing key:", missing_key)
print("None:", none_components)
print("Empty list:", empty_components)
print("Missing (any):", missing_any)
if "schematic" in need_cols:
print("Has schematic but missing components:", has_schematic_but_missing)=== Missing components report ===
Total: 84470
Missing key: 0
None: 47558
Empty list: 8
Missing (any): 47566
Has schematic but missing components: 47566El resumen que figura a continuación muestra que una gran parte de las muestras contienen datos esquemáticos, pero carecen de anotaciones de componentes utilizables.
Para evitar un uso innecesario de memoria durante el filtrado, desactivamos explícitamente la decodificación de imágenes. Esto garantiza que Hugging Face no cargue imágenes en la memoria mientras aplica filtros.
from datasets.features import Image as HFImage
ds_all = ds_all.cast_column("image", HFImage(decode=False))A continuación, definimos un filtro que solo conserva las muestras con una lista de componentes no vacía y una referencia de imagen válida.
def keep_components_and_image(components_used, image):
# keep only rows with components
if not (isinstance(components_used, list) and len(components_used) > 0):
return False
# image must exist
if image is None:
return False
# when decode=False, image is dict-like: {"path": ...} or {"bytes": ...}
if isinstance(image, dict):
return bool(image.get("path")) or bool(image.get("bytes"))
return TrueLa aplicación de este filtro reduce significativamente el conjunto de datos a muestras de alta calidad y totalmente utilizables.
ds_clean = ds_all.filter(
keep_components_and_image,
input_columns=["components_used", "image"],
)
print("Original:", len(ds_all))
print("Clean:", len(ds_clean))
print("Dropped:", len(ds_all) - len(ds_clean))Original: 84470
Clean: 33275
Dropped: 51195Tras el filtrado, nos quedan más de 33 000 muestras limpias que contienen tanto imágenes esquemáticas válidas como anotaciones explícitas de componentes. Este conjunto de datos limpio constituye una base fiable para los pasos posteriores de preprocesamiento y entrenamiento del modelo.
Ahora cargamos el modelo Qwen3-VL-8B-Instruct junto con su procesador correspondiente. Este modelo es un modelo de visión-lenguaje a gran escala capaz de razonar conjuntamente sobre imágenes y texto, lo que lo hace muy adecuado para tareas de comprensión esquemática.
El modelo se carga con una precisión de bfloat16 para reducir el uso de memoria y mantener la estabilidad numérica. También habilitamos Flash Attention 2 para una atención más rápida y eficiente en cuanto a memoria en la GPU A100. La opción « device_map="auto" » (Usar GPU) coloca automáticamente las capas del modelo en la GPU disponible.
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
MODEL_ID = "Qwen/Qwen3-VL-8B-Instruct"
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(MODEL_ID)Este paso define utilidades ligeras para preparar indicaciones, objetivos e imágenes para el entrenamiento de visión-lenguaje. Se utiliza un único canal para múltiples tareas cambiando la variable TASK (componentes, YAML, JSON o reconstrucción esquemática).
Se aplican límites de seguridad básicos para controlar la longitud del objetivo y el tamaño de la imagen, lo que ayuda a mantener la estabilidad del entrenamiento y la eficiencia de la memoria.
from PIL import Image
TASK = "components" # "components" | "yaml" | "json" | "schematic"
MAX_TARGET_CHARS = 5000 # safety cap for long targets like schematic/json
MAX_IMAGE_SIDE = 1024 # bigger side
MAX_IMAGE_PIXELS = 1024 * 1024 # safety cap (1.0 MP). raise to 1.5MP if stableLa función build_prompt() construye el texto de instrucciones que se pasa al modelo. Utiliza metadatos de conjuntos de datos para el contexto y aplica restricciones de salida estrictas para reducir las alucinaciones y mantener una supervisión coherente en todas las tareas.
def build_prompt(example):
# Use dataset fields to give better context (name/type are helpful)
name = example.get("name") or "Unknown project"
ftype = example.get("type") or "unknown format"
if TASK == "components":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, extract all component labels and identifiers exactly as shown "
"(part numbers, values, footprints, net labels like +5V/GND).\n"
"Output only a comma-separated list. Do not generalize or add extra text."
)
if TASK == "yaml":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce YAML metadata for the design.\n"
"Return valid YAML only. No markdown, no explanations."
)
if TASK == "json":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce a JSON representation of the schematic structure.\n"
"Return valid JSON only. No markdown, no explanations."
)
if TASK == "schematic":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, reconstruct the raw KiCad schematic content.\n"
"Return only the schematic text. No markdown, no explanations."
)
raise ValueError("Unknown TASK")La función « build_target() » extrae los resultados reales para la tarea seleccionada directamente del conjunto de datos. El contenido se devuelve textualmente para entrenar al modelo en la reproducción exacta, no en la paráfrasis.
def build_target(example):
if TASK == "components":
comps = example.get("components_used") or []
return ", ".join(comps)
if TASK == "yaml":
return (example.get("yaml") or "").strip()
if TASK == "json":
return (example.get("json") or "").strip()
if TASK == "schematic":
return (example.get("schematic") or "").strip()
raise ValueError("Unknown TASK")La función « clamp_text() » aplica un límite estricto de caracteres a los objetivos. Esto evita que los archivos JSON, YAML o esquemáticos de gran tamaño causen problemas de memoria durante el entrenamiento.
def clamp_text(s: str, max_chars: int = MAX_TARGET_CHARS) -> str:
s = (s or "").strip()
return s if len(s) <= max_chars else s[:max_chars].rstrip()La función « _resize_pil() » normaliza y redimensiona las imágenes esquemáticas antes de procesarlas. Aplica tanto una longitud lateral máxima como un recuento total máximo de píxeles, lo que garantiza un uso predecible de la memoria de la GPU y preserva los detalles visuales.
def _resize_pil(pil: Image.Image, max_side: int = MAX_IMAGE_SIDE, max_pixels: int = MAX_IMAGE_PIXELS) -> Image.Image:
pil = pil.convert("RGB")
w, h = pil.size
# Scale down if max side too large
scale_side = min(1.0, max_side / float(max(w, h)))
# Scale down if too many pixels (area cap)
scale_area = (max_pixels / float(w * h)) ** 0.5 if (w * h) > max_pixels else 1.0
scale = min(scale_side, scale_area)
if scale < 1.0:
nw, nh = max(1, int(w * scale)), max(1, int(h * scale))
pil = pil.resize((nw, nh), resample=Image.BICUBIC)
return pilEn este paso, convertimos cada muestra del conjunto de datos limpio en un formato multimodal similar al de un chat que puede ser utilizado directamente por el modelo de visión-lenguaje Qwen. Este formato alinea explícitamente la imagen esquemática con una instrucción textual y su resultado esperado correspondiente.
def to_messages(example):
prompt = build_prompt(example)
target = clamp_text(build_target(example))
example["messages"] = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": prompt},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": target}],
},
]
return exampleBarajamos el conjunto de datos para eliminar el sesgo de ordenación y seleccionamos un pequeño subconjunto para los experimentos iniciales.
A continuación, el conjunto de datos se mapea a través de to_messages() para generar ejemplos de entrenamiento multimodal. Por último, se vuelve a habilitar la decodificación de imágenes, de modo que estas solo se cargan durante el entrenamiento, lo que permite que el preprocesamiento sea ligero y eficiente en cuanto a memoria.
# Start small (increase later)
train_ds = ds_clean.shuffle(seed=42).select(range(min(800, len(ds_clean)))).map(to_messages)
train_ds = train_ds.cast_column("image", HFImage(decode=True))Antes de realizar ajustes, evaluamos el rendimiento inicial del modelo Qwen3-VL 8B Instruct en nuestra tarea. Esta referencia nos ayuda a comprender en qué medida el modelo preentrenado puede extraer información de imágenes esquemáticas sin ninguna adaptación específica para la tarea.
La función « run_inference() » realiza una única pasada hacia adelante en un ejemplo utilizando la misma lógica de solicitud e imagen de preprocesamiento que se utilizará posteriormente durante el entrenamiento.
import torch
def run_inference(model_, example, max_new_tokens=256):
prompt = build_prompt(example)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": _resize_pil(example["image"])},
{"type": "text", "text": prompt},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
).to(model_.device)
with torch.inference_mode():
out = model_.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
gen = out[0][inputs["input_ids"].shape[1]:]
return processor.decode(gen, skip_special_tokens=True)
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]Primero evaluamos el modelo en una muestra seleccionada aleatoriamente del conjunto de entrenamiento.
print("\n--- BASELINE OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- BASELINE OUTPUT ---
J1,Conn_02x11_Odd_Even,CINT6,CINT5,CINT4,CINT3,CINT2,CINT1,CINT0,CINT15,CINT14,CINT13,CINT12,CINT11,CINT10,CINT9,CINT8,CINT7,CINT16,CINT17,CINT18,CINT19,CINT20,CINT21,CINT22,CINT23,CINT24,CINT25,CINT26,CINT27,CINT28,CINT29,CINT30,CINT31,CINT32,CINT33,CINT34,CINT35,CINT36,CINT37,CINT38,CINT39,CINT40,CINT41,CINT42,CINT43,CINT44,CINT45,CINT46,CINT47,CINT48,CINT49,CINT50,CINT51,CINT52,CINT53,CINT54,CINT55,CINT56,CINT57,CINT58,CINT59,CINT60,CINT61,CINT62
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GNDEn este ejemplo, el modelo identifica correctamente algunos elementos estructurales, pero genera un exceso de nombres de pines y señales, al tiempo que no logra recuperar los identificadores exactos de los componentes utilizados en el conjunto de datos. Observé este mismo patrón en más ejemplos cuando los evalué.
En general, estos resultados de referencia muestran que, si bien el modelo tiene una sólida comprensión visual y textual general, carece de alineación con las anotaciones de componentes específicas del conjunto de datos. Este comportamiento pone de manifiesto la necesidad de realizar ajustes para reducir los resultados alucinados y mejorar la precisión.
Esta sección define un clasificador de datos personalizado que prepara lotes multimodales de estilo chat para el entrenamiento. Convierte cada ejemplo en tensores listos para el modelo mediante la codificación conjunta de texto e imágenes, al tiempo que garantiza que la pérdida se calcule únicamente sobre la respuesta del asistente.
El clasificador crea dos versiones del texto del chat: una versión completa (prompt y destino) para la codificación de la entrada, y una versión solo con prompt para calcular las longitudes de los tokens de prompt. Utilizando estas longitudes, todos los tokens de indicaciones y relleno se ocultan en las etiquetas, por lo que solo la salida del asistente contribuye a la pérdida. Las imágenes se redimensionan de forma coherente y se aplica una longitud máxima fija de secuencia para controlar la memoria.
from typing import List, Dict, Any
import torch
MAX_LEN = 1500
def collate_fn(batch: List[Dict[str, Any]]):
# 1) Build full chat text (includes assistant answer)
full_texts = [
processor.apply_chat_template(
ex["messages"],
tokenize=False,
add_generation_prompt=False,
)
for ex in batch
]
# 2) Build prompt-only text (up to user turn; generation prompt on)
prompt_texts = [
processor.apply_chat_template(
ex["messages"][:-1],
tokenize=False,
add_generation_prompt=True,
)
for ex in batch
]
# 3) Images
images = [_resize_pil(ex["image"]) for ex in batch]
# 4) Tokenize full inputs ONCE (text + images)
enc = processor(
text=full_texts,
images=images,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
)
input_ids = enc["input_ids"]
pad_id = processor.tokenizer.pad_token_id
# 5) Compute prompt lengths with TEXT-ONLY tokenization (much cheaper than text+images)
prompt_ids = processor.tokenizer(
prompt_texts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
add_special_tokens=False, # chat template already includes special tokens
)["input_ids"]
# Count non-pad tokens in prompt
prompt_lens = (prompt_ids != pad_id).sum(dim=1)
# 6) Labels: copy + mask prompt tokens + mask padding
labels = input_ids.clone()
bs, seqlen = labels.shape
for i in range(bs):
pl = int(prompt_lens[i].item())
pl = min(pl, seqlen)
labels[i, :pl] = -100
# Mask padding positions too
labels[labels == pad_id] = -100
# If your processor produces pixel_values / image_grid_thw, keep them
enc["labels"] = labels
return encEste comparador permite una supervisión eficiente y correcta para el ajuste preciso de la visión y el lenguaje.
Ahora vamos a configurar LoRA (Low-Rank Adaptation) para ajustar el modelo Qwen3-VL de manera eficiente sin actualizar todos los pesos del modelo. LoRA inyecta matrices de rango bajo entrenables en capas de proyección seleccionadas, lo que reduce significativamente el uso de memoria sin comprometer el rendimiento.
from peft import LoraConfig, TaskType, get_peft_model
lora = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM,
target_modules=[
"q_proj","k_proj","v_proj","o_proj",
"gate_proj","up_proj","down_proj"
],
)A continuación, definimos la configuración de entrenamiento utilizando SFTConfig, estableciendo el tamaño del lote, la tasa de aprendizaje, la precisión y las opciones de registro adecuadas para un ajuste fino estable en la GPU A100.
from trl import SFTTrainer, SFTConfig
args = SFTConfig(
output_dir=f"qwen3vl-open-schematics-{TASK}-lora",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=False,
learning_rate=1e-4,
warmup_steps=10,
weight_decay=0.01,
max_grad_norm=1.0,
bf16=True,
fp16=False,
lr_scheduler_type="cosine",
logging_steps=10,
report_to="none",
remove_unused_columns=False,
)Por último, inicializamos el modelo de entrenamiento ( SFTTrainer), combinando el modelo, el conjunto de datos, el clasificador personalizado y la configuración LoRA para comenzar el ajuste supervisado.
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=train_ds,
data_collator=collate_fn,
peft_config=lora
)Ahora comenzamos el proceso de ajuste utilizando el entrenador configurado.
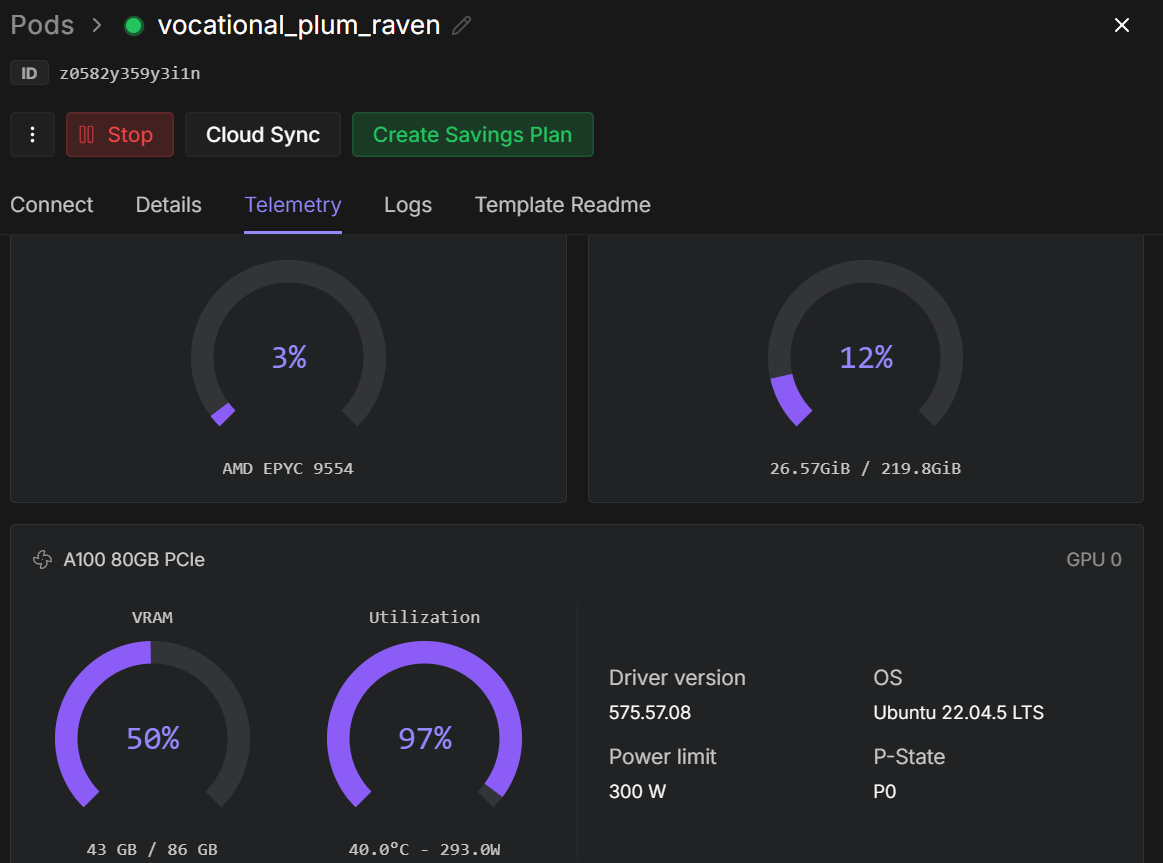
trainer.train()Una vez que comience el entrenamiento, podrás supervisar el panel de control de telemetría de RunPod. En una instancia A100 de 80 GB, el proceso suele utilizar entre 40 y 45 GB de VRAM y alcanza una utilización casi total de la GPU, lo que indica un uso eficiente del hardware.
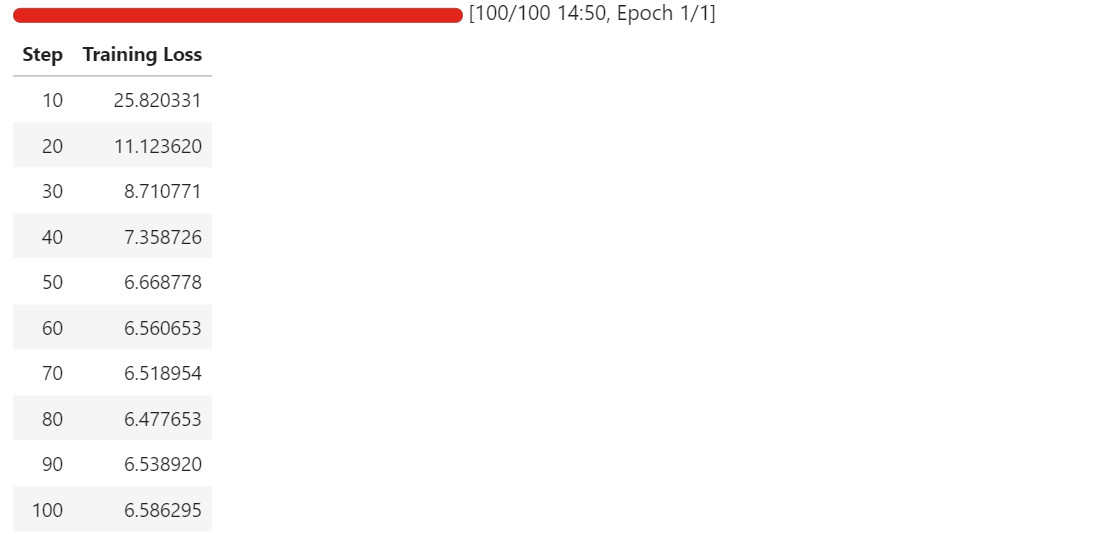
A medida que avanza el entrenamiento, deberías observar que la pérdida de entrenamiento disminuye de forma constante antes de estabilizarse. En nuestro caso, la pérdida converge y se estabiliza en aproximadamente 6,5, lo que sirve como indicador de referencia de que el modelo se ha adaptado a la tarea de extracción de componentes esquemáticos.
En este punto, los adaptadores LoRA están correctamente ajustados y listos para su evaluación y exportación.
Una vez completado el ajuste, primero guardamos localmente los adaptadores LoRA entrenados y el procesador asociado.
out_dir = trainer.args.output_dir # from your SFTConfig/TrainingArguments
trainer.save_model(out_dir) # saves model/adapters into output_dir
processor.save_pretrained(out_dir) # save processor (tokenizer + image processor)A continuación, publicamos el modelo ajustado en Hugging Face Hub. Esto permite reutilizar los adaptadores y el procesador para la inferencia o un ajuste más preciso.
import os
repo_id = "kingabzpro/qwen3vl-open-schematics-lora" # replace with your username/repo
# Push model/adapters
trainer.model.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
# Push processor
processor.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
Una vez completada la carga, los adaptadores LoRA y el procesador ajustados están disponibles públicamente en el repositorio especificado.
Tras el ajuste, recargamos el modelo y el procesador directamente desde Hugging Face Hub. Esto garantiza que la evaluación se realice utilizando los adaptadores LoRA exportados, exactamente como se utilizarían en un entorno de inferencia real.
model = Qwen3VLForConditionalGeneration.from_pretrained(
repo_id,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(repo_id)
```
We now repeat the same inference procedure used during the baseline evaluation, allowing for a direct comparison between pre-fine-tuning and post-fine-tuning behavior.
```python
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- FINETUNED OUTPUT ---
Conn_02x11_0dd_Even, P3.3V
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GNDEn comparación con el modelo de referencia, el modelo ajustado produce un resultado mucho más breve y específico, evitando la generación excesiva a gran escala de nombres de pines y señales inferidas.
Aunque la predicción aún es incompleta y contiene errores menores, muestra un claro avance hacia identificadores de componentes alineados con el conjunto de datos.
Ahora evaluaremos un segundo ejemplo para confirmar este comportamiento.
baseline_ex = train_ds.shuffle(seed=170).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- FINETUNED OUTPUT ---
ATMEGA328P-PU, +5V, GND, R, C, C16MHz, SERVO_A, SERVO_B, SERVO_C, SERVO_D, SERVO_E, SERVO_F, SERVO_G
--- TARGET (dataset) ---
+5V, 7.62MM-3P, 7.62MM-3P_1, 7.62MM-3P_2, 7.62MM-3P_3, 7.62MM-3P_4, 7.62MM-3P_5, 7.62MM-3P_6, ATMEGA328P-PU, ATMEGA328P-PU_1, GND, MBB02070C1002FCT00, MBB02070C1002FCT00_1, Unknown_0_-806, X49SD16MSD2SC, Y5P102K2KV16CC0224, Y5P102K2KV16CC0224_1, Y5P102K2KV16CC0224_2Aquí, el modelo ajustado identifica correctamente los componentes principales, como el microcontrolador y las redes de alimentación, y reduce significativamente las alucinaciones irrelevantes a nivel de señal. Sin embargo, sigue abstrayendo o generalizando algunos componentes en lugar de reproducir los identificadores específicos del conjunto de datos exactos.
En general, estos resultados demuestran que el ajuste fino suprime con éxito la sobregeneración y mejora la alineación con la extracción de componentes a nivel esquemático. Aunque la precisión puede mejorarse aún más con épocas adicionales, conjuntos de entrenamiento más grandes o restricciones de salida más estrictas, el comportamiento posterior al ajuste fino representa una mejora clara y cuantificable con respecto a la línea de base.
Si tienes algún problema al ejecutar el código de este tutorial, consulta el cuaderno adjunto.
Los modelos de visión-lenguaje son fundamentalmente diferentes de los modelos solo de texto, y tratarlos de la misma manera casi siempre conduce a malos resultados.
Si no tienes cuidado, es muy fácil encontrarte con errores de memoria insuficiente, incluso con un tamaño de lote de uno, o ajustar un modelo que parece entrenarse pero que en realidad no aprende la tarea. Esto es algo que aprendí por las malas.
Lo que finalmente marcó la diferencia fue prestar atención a los detalles que son importantes específicamente para el entrenamiento multimodal.
Cambiar el tamaño de las imágenes a límites seguros, limpiar el conjunto de datos para eliminar muestras dañadas o inutilizables y garantizar que solo se pasen al modelo pares válidos de imágenes y texto son pasos esenciales. Omitir cualquiera de estos pasos conduce rápidamente a la inestabilidad o al desperdicio de recursos informáticos.
En cuanto al modelado, el uso exclusivo de las capas objetivo LoRA relevantes contribuyó a que el entrenamiento fuera eficiente y específico, mientras que el ajuste cuidadoso de los argumentos de entrenamiento mejoró la convergencia sin aumentar la presión sobre la memoria.
La optimización para la GPU A100, la habilitación de Flash Attention y el uso de bfloat16 permitieron que el entrenamiento se mantuviera estable y, al mismo tiempo, se redujera significativamente el tiempo de ejecución. En la práctica, estas optimizaciones reducen el tiempo de formación casi a la mitad sin sacrificar la calidad.
Los resultados finales muestran que incluso un modelo de visión-lenguaje preentrenado potente se beneficia enormemente del ajuste específico para cada dominio. Con el preprocesamiento, la configuración y las optimizaciones adecuadas para el hardware, es posible adaptar modelos multimodales de gran tamaño de forma fiable y eficiente.
Si te interesa seguir practicando el ajuste fino, te recomiendo que realices el curso Ajuste fino con Llama 3 .
Cursos de máster en Derecho
programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan



