
Cursus
Qwen3-VL-8B est le modèle de langage visuel le plus puissant et le plus utilisé de la série Qwen. Il est conçu pour permettre une compréhension unifiée du texte, des images et de la vidéo.
Il apporte des améliorations significatives en matière de génération de texte, de raisonnement visuel, de perception spatiale, de gestion de contextes longs et d'interaction avec des agents, ce qui le rend adapté à la fois à la recherche et au déploiement dans le monde réel, dans des environnements périphériques et cloud.
Dans ce tutoriel, nous allons affiner Qwen3-VL-8B-Instruct sur des schémas électroniques. En formant le modèle à interpréter les symboles schématiques, les connexions et les relations spatiales, nous lui permettons de comprendre avec précision les conceptions de circuits et de déterminer quels composants électroniques doivent être ajoutés dans un circuit réel.
Vous apprendrez à :
- Veuillez charger l'ensemble de données depuis Hugging Face et le nettoyer.
- Veuillez créer un modèle de chat multimodal pour la formation.
- Configurez le pipeline vision-langage Qwen3-VL.
- Veuillez configurer LoRA pour un apprentissage efficace en termes de mémoire.
- Veuillez affiner le modèle et enregistrer le point de contrôle.
- Veuillez publier l'adaptateur formé sur Hugging Face.
- Veuillez comparer les résultats avant et après le réglage fin.
Si Hugging Face est encore nouveau pour vous, les parcours Hugging Face Fundamentals est faite pour vous !
1. Configuration de l'environnement pour le réglage fin du Qwen3-VL-8B
Lorsque vous travaillez avec des modèles de vision-langage, la mémoire du GPU devient une contrainte critique. Les images haute résolution et les encodeurs multimodaux peuvent rapidement épuiser la mémoire VRAM. Il est donc fortement recommandé d'utiliser un GPU doté d'une mémoire suffisante.
Pour ce tutoriel, nous allons démarrer une instance instance RunPod A100 (80 Go) en utilisant la dernière version de image PyTorch. Cette configuration offre une marge VRAM suffisante pour l'entraînement et évite les goulots d'étranglement inutiles en mémoire lors du réglage fin.
Veuillez vous rendre dans la section «Modèle de pod » de l'. Veuillez sélectionner icil'image PyTorch la plus récente d' :. C'est également ici que vous pouvez ajuster les paramètres de stockage et ajouter des variables d'environnement.
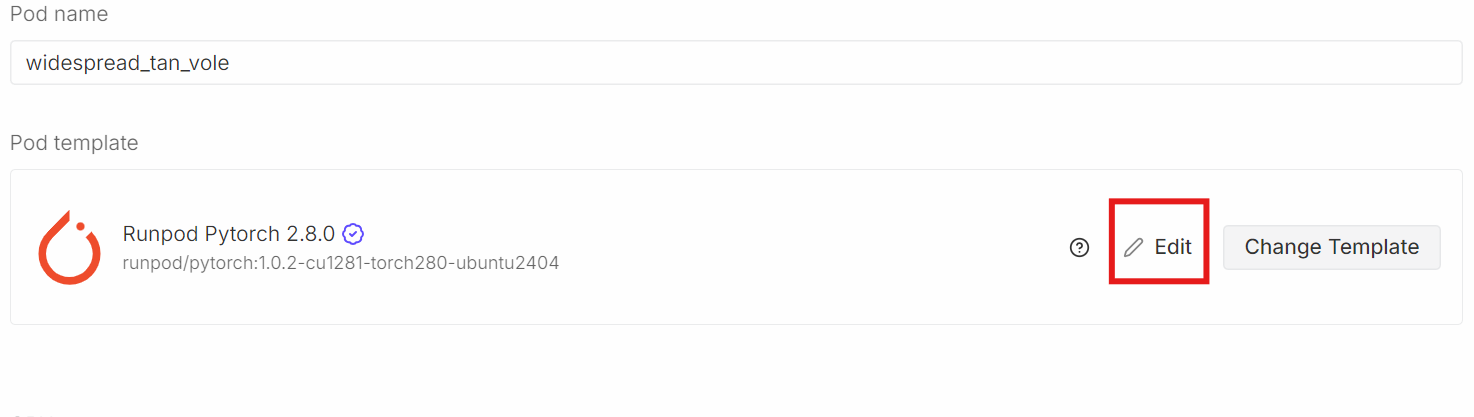
Veuillez cliquer Modifier, puis procédez aux modifications suivantes :
- Taille du disque du conteneur : définie sur 40 Go
- Taille du disque : veuillez définir 40 Go.
- Variables d'environnement : Veuillez ajouter
HF_TOKENet définir sa valeur sur votre jeton d'accès Hugging Face (générez-en un à partir des paramètres Hugging Face).
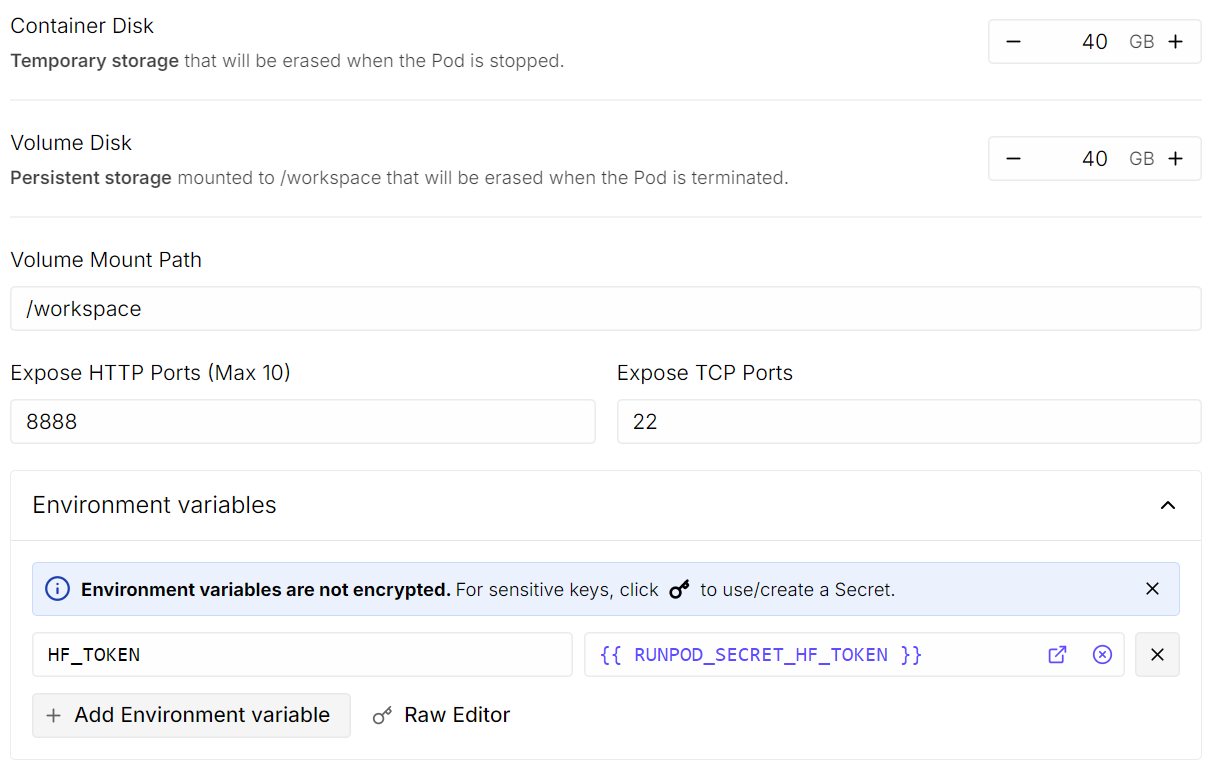
Une fois terminé, veuillez enregistrer le modèle et déployer le pod.
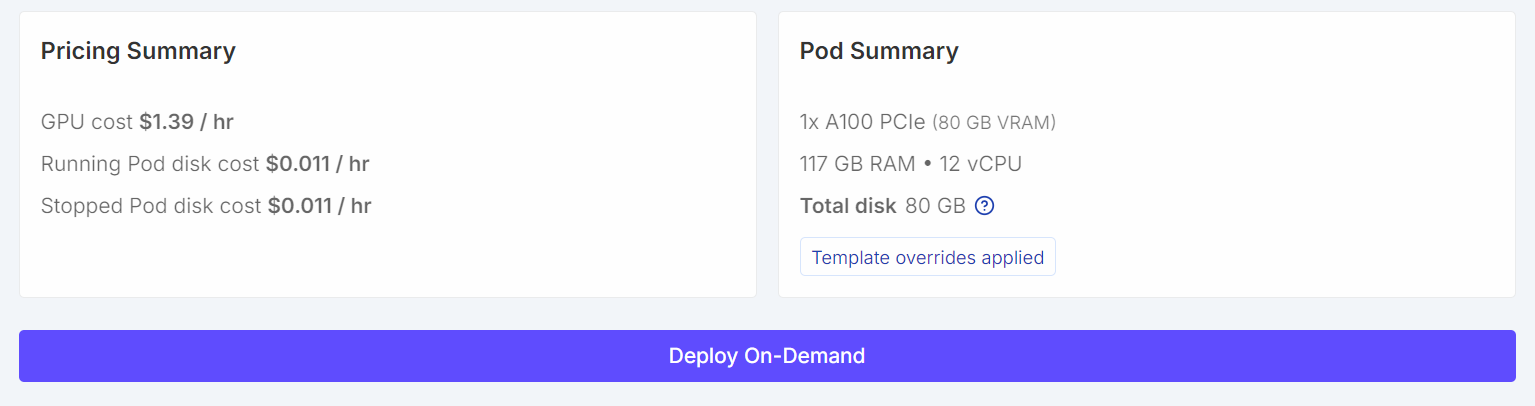
Une fois que le pod est opérationnel :
- Open JupyterLab.
- Veuillez créer un nouveau notebook Python.
- Veuillez installer les dépendances requises.
Pour installer les dépendances, veuillez exécuter la cellule de code suivante. Dans Jupyter, un point d'exclamation au début indique au notebook d'exécuter la ligne en tant que commande shell plutôt qu'en tant que code Python.
!pip -q install -U accelerate datasets pillow sentencepiece safetensors peft
!pip install --quiet "transformers==5.0.0rc1"
!pip install --quiet --no-deps trl
!pip install --no-cache-dir flash-attn --no-build-isolationEnsuite, définissez une graine aléatoire fixe pour garantir la reproductibilité et activez les optimisations de performances spécifiques à l'A100.
import torch
from transformers import set_seed
set_seed(42)
# A100: TF32 gives speedups without changing your bf16 training setup
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
print("CUDA:", torch.cuda.is_available(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
print("bf16 supported:", torch.cuda.is_available() and torch.cuda.is_bf16_supported())CUDA: True NVIDIA A100 80GB PCIe
bf16 supported: True2. Téléchargement de l'ensemble de données Open Schematics depuis Hugging Face
Nous allons maintenant charger l'ensemble de données Open Schematics de l', disponible sur le Hugging Face Hub. Cet ensemble de données contient des images schématiques électroniques ainsi que des métadonnées détaillées décrivant chaque circuit, ce qui le rend particulièrement adapté à la formation en vision-langage.
import torch
from datasets import load_dataset
DATASET_ID = "bshada/open-schematics"
ds_all = load_dataset(DATASET_ID, split="train")
print(ds_all)Dataset({
features: ['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'],
num_rows: 84470
})L'ensemble de données contient plus de 84 000 échantillons, chacun associant une image schématique à des informations structurées, telles que des listes de composants et des formats lisibles par machine (JSON et YAML).
3. Analyse de la structure de l'ensemble de données
Veuillez examiner un seul échantillon afin de mieux appréhender la structure de l'ensemble de données.
# quick peek
ex = ds_all[0]
print("\nSample keys:", ex.keys())
print("name:", ex.get("name"))
print("type:", ex.get("type"))
print("components_used:", (ex.get("components_used") or [])[:10])
print("has schematic:", bool(ex.get("schematic")))
print("has json/yaml:", bool(ex.get("json")), bool(ex.get("yaml")))
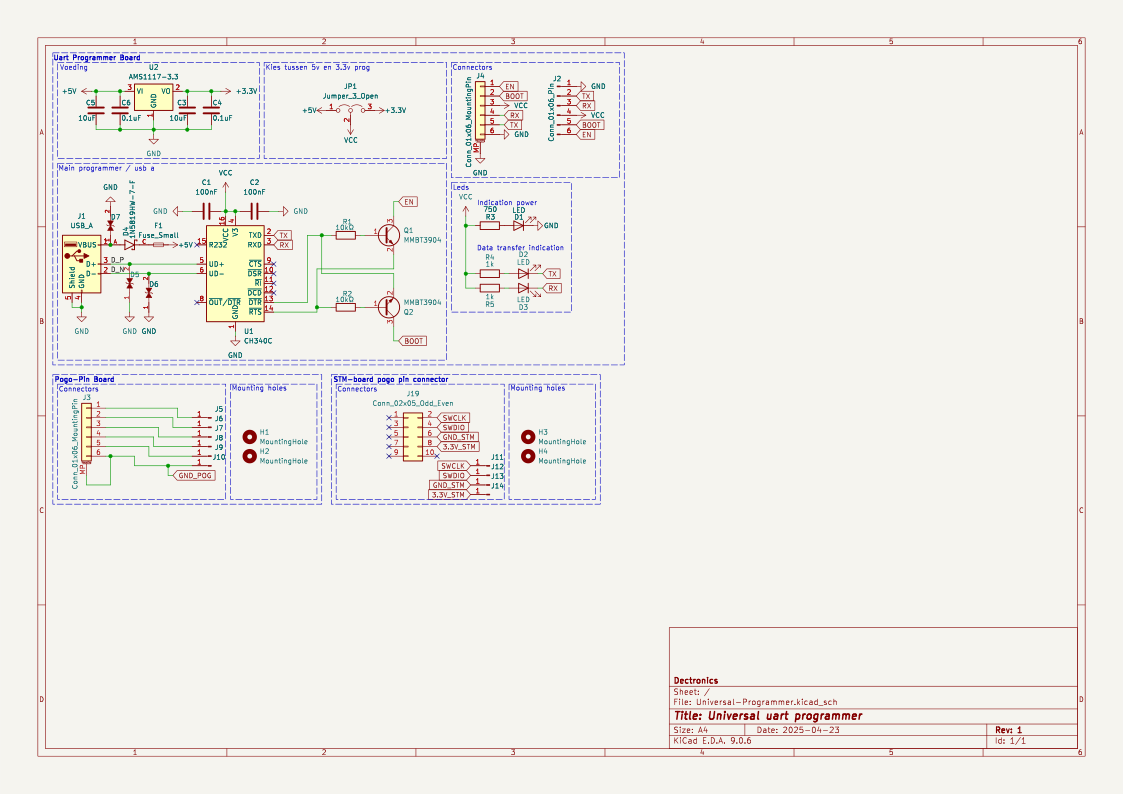
print("image:", ex.get("image"))Sample keys: dict_keys(['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'])
name: TiebeDeclercq/Uart-programmer
type: .kicad_sch
components_used: ['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C']
has schematic: True
has json/yaml: True True
image: <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=1123x794 at 0x7FBC6FD060F0>Cela confirme que chaque échantillon comprend une image schématique haute résolution, une liste des composants et des représentations structurées du circuit.
Nous pouvons désormais afficher l'image schématique directement dans le notebook Jupyter.
ex.get("image")
Enfin, nous examinons la liste complète des composants utilisés dans ce schéma.
print(ex.get("components_used"))['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C', 'Jumper_3_Open', 'MountingHole', 'AMS1117-3.3', 'MMBT3904', '1N5819HW-7-F', 'LESD5D5.0CT1G', '+3.3V', '+5V', 'GND', 'VCC']Cette liste de composants établit un lien clair entre l'image schématique et les éléments électroniques présents dans le circuit.
4. Nettoyage et filtrage de l'ensemble de données
Avant l'entraînement, nous nettoyons et filtrons l'ensemble de données afin de nous assurer que chaque échantillon contient le minimum d'informations nécessaires à l'apprentissage de la vision et du langage. Nous nous concentrons en particulier sur la conservation des exemples qui comportent des annotations de composants valides et une image schématique correspondante.
Tout d'abord, nous examinons combien d'échantillons comportent des entrées d'components_used s manquantes, vides ou invalides.
need_cols = [c for c in ["components_used", "schematic", "name", "type"] if c in ds_all.column_names]
ds_small = ds_all.select_columns(need_cols)
missing_key = none_components = empty_components = missing_any = 0
has_schematic_but_missing = 0
for ex in ds_small:
if "components_used" not in ex:
missing_key += 1
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
continue
cu = ex["components_used"]
bad = (cu is None) or (isinstance(cu, list) and len(cu) == 0)
if cu is None:
none_components += 1
elif isinstance(cu, list) and len(cu) == 0:
empty_components += 1
if bad:
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
print("\n=== Missing components report ===")
print("Total:", len(ds_all))
print("Missing key:", missing_key)
print("None:", none_components)
print("Empty list:", empty_components)
print("Missing (any):", missing_any)
if "schematic" in need_cols:
print("Has schematic but missing components:", has_schematic_but_missing)=== Missing components report ===
Total: 84470
Missing key: 0
None: 47558
Empty list: 8
Missing (any): 47566
Has schematic but missing components: 47566Le résumé ci-dessous montre qu'une grande partie des échantillons contiennent des données schématiques, mais qu'il manque des annotations de composants exploitables.
Afin d'éviter toute utilisation inutile de mémoire pendant le filtrage, nous désactivons explicitement le décodage des images. Cela garantit que Hugging Face ne charge pas les images en mémoire lors de l'application des filtres.
from datasets.features import Image as HFImage
ds_all = ds_all.cast_column("image", HFImage(decode=False))Nous définissons ensuite un filtre qui conserve uniquement les échantillons dont la liste des composants n'est pas vide et qui possèdent une référence d'image valide.
def keep_components_and_image(components_used, image):
# keep only rows with components
if not (isinstance(components_used, list) and len(components_used) > 0):
return False
# image must exist
if image is None:
return False
# when decode=False, image is dict-like: {"path": ...} or {"bytes": ...}
if isinstance(image, dict):
return bool(image.get("path")) or bool(image.get("bytes"))
return TrueL'application de ce filtre réduit considérablement l'ensemble de données à des échantillons de haute qualité et pleinement exploitables.
ds_clean = ds_all.filter(
keep_components_and_image,
input_columns=["components_used", "image"],
)
print("Original:", len(ds_all))
print("Clean:", len(ds_clean))
print("Dropped:", len(ds_all) - len(ds_clean))Original: 84470
Clean: 33275
Dropped: 51195Après filtrage, nous disposons de plus de 33 000 échantillons propres contenant à la fois des images schématiques valides et des annotations explicites sur les composants. Cet ensemble de données nettoyé constitue une base fiable pour les étapes suivantes de prétraitement et d'entraînement du modèle.
5. Chargement du modèle de langage visuel Qwen3-VL-8B
Nous chargeons maintenant le modèle Qwen3-VL-8B-Instruct avec son processeur correspondant. Ce modèle est un modèle vision-langage à grande échelle capable de raisonner conjointement sur des images et du texte, ce qui le rend particulièrement adapté aux tâches de compréhension schématique.
Le modèle est chargé avec une précision bfloat16 afin de réduire l'utilisation de la mémoire tout en conservant la stabilité numérique. Nous activons également Flash Attention 2 pour une attention plus rapide et plus efficace en termes de mémoire sur le GPU A100. device_map="auto" L'option « Utiliser le GPU » place automatiquement les couches du modèle sur le GPU disponible.
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
MODEL_ID = "Qwen/Qwen3-VL-8B-Instruct"
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(MODEL_ID)6. Conception rapide pour l'analyse des circuits
Cette étape définit des utilitaires légers pour préparer les invites, les cibles et les images pour la formation en vision-langage. Un seul pipeline est utilisé pour plusieurs tâches en modifiant la variable d'TASK (composants, YAML, JSON ou reconstruction schématique).
Des limites de sécurité de base sont appliquées pour contrôler la longueur de la cible et la taille de l'image, ce qui contribue à maintenir la stabilité de l'entraînement et à optimiser l'utilisation de la mémoire.
from PIL import Image
TASK = "components" # "components" | "yaml" | "json" | "schematic"
MAX_TARGET_CHARS = 5000 # safety cap for long targets like schematic/json
MAX_IMAGE_SIDE = 1024 # bigger side
MAX_IMAGE_PIXELS = 1024 * 1024 # safety cap (1.0 MP). raise to 1.5MP if stableCréation de l'invite
La fonction ` build_prompt() ` construit le texte d'instruction transmis au modèle. Il utilise les métadonnées des ensembles de données pour le contexte et applique des contraintes de sortie strictes afin de réduire les hallucinations et de maintenir une supervision cohérente entre les tâches.
def build_prompt(example):
# Use dataset fields to give better context (name/type are helpful)
name = example.get("name") or "Unknown project"
ftype = example.get("type") or "unknown format"
if TASK == "components":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, extract all component labels and identifiers exactly as shown "
"(part numbers, values, footprints, net labels like +5V/GND).\n"
"Output only a comma-separated list. Do not generalize or add extra text."
)
if TASK == "yaml":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce YAML metadata for the design.\n"
"Return valid YAML only. No markdown, no explanations."
)
if TASK == "json":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce a JSON representation of the schematic structure.\n"
"Return valid JSON only. No markdown, no explanations."
)
if TASK == "schematic":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, reconstruct the raw KiCad schematic content.\n"
"Return only the schematic text. No markdown, no explanations."
)
raise ValueError("Unknown TASK")Définir l'objectif
La fonction « build_target() » extrait directement du jeu de données la sortie de référence pour la tâche sélectionnée. Le contenu est restitué mot pour mot afin de former le modèle à la reproduction exacte, et non à la paraphrase.
def build_target(example):
if TASK == "components":
comps = example.get("components_used") or []
return ", ".join(comps)
if TASK == "yaml":
return (example.get("yaml") or "").strip()
if TASK == "json":
return (example.get("json") or "").strip()
if TASK == "schematic":
return (example.get("schematic") or "").strip()
raise ValueError("Unknown TASK")La fonction « clamp_text() » applique une limite stricte au nombre de caractères pour les cibles. Cela empêche les fichiers JSON, YAML ou schématiques trop volumineux de causer des problèmes de mémoire pendant l'entraînement.
def clamp_text(s: str, max_chars: int = MAX_TARGET_CHARS) -> str:
s = (s or "").strip()
return s if len(s) <= max_chars else s[:max_chars].rstrip()Redimensionnement des images
La fonction « _resize_pil() » normalise et redimensionne les images schématiques avant leur traitement. Il impose à la fois une longueur maximale par côté et un nombre maximal de pixels, garantissant ainsi une utilisation prévisible de la mémoire GPU tout en préservant les détails visuels.
def _resize_pil(pil: Image.Image, max_side: int = MAX_IMAGE_SIDE, max_pixels: int = MAX_IMAGE_PIXELS) -> Image.Image:
pil = pil.convert("RGB")
w, h = pil.size
# Scale down if max side too large
scale_side = min(1.0, max_side / float(max(w, h)))
# Scale down if too many pixels (area cap)
scale_area = (max_pixels / float(w * h)) ** 0.5 if (w * h) > max_pixels else 1.0
scale = min(scale_side, scale_area)
if scale < 1.0:
nw, nh = max(1, int(w * scale)), max(1, int(h * scale))
pil = pil.resize((nw, nh), resample=Image.BICUBIC)
return pil7. Configuration d'un modèle de chat multimodal
Au cours de cette étape, nous convertissons chaque échantillon de données nettoyé en un format multimodal de type chat qui peut être directement utilisé par le modèle de vision-langage Qwen. Ce format aligne explicitement l'image schématique avec une instruction textuelle et son résultat cible correspondant.
def to_messages(example):
prompt = build_prompt(example)
target = clamp_text(build_target(example))
example["messages"] = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": prompt},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": target}],
},
]
return exampleNous mélangeons l'ensemble de données afin d'éliminer tout biais lié à l'ordre et sélectionnons un petit sous-ensemble pour les expériences initiales.
L'ensemble de données est ensuite mappé via to_messages() afin de générer des exemples d'entraînement multimodaux. Enfin, le décodage des images est réactivé, de sorte que les images ne sont chargées qu'au moment de l'entraînement, ce qui permet de conserver un prétraitement léger et efficace en termes de mémoire.
# Start small (increase later)
train_ds = ds_clean.shuffle(seed=42).select(range(min(800, len(ds_clean)))).map(to_messages)
train_ds = train_ds.cast_column("image", HFImage(decode=True))8. Évaluation de Qwen3-VL-8B (pré-réglage fin)
Avant de procéder à l'ajustement, nous évaluons les performances initiales du modèle Qwen3-VL 8B Instruct sur notre tâche. Cette base de référence nous aide à comprendre dans quelle mesure le modèle pré-entraîné est capable d'extraire des informations à partir d'images schématiques sans aucune adaptation spécifique à la tâche.
La fonction d'run_inference() ion effectue un seul passage en avant sur un exemple en utilisant la même logique de prompt et de prétraitement d'image qui sera utilisée ultérieurement pendant l'entraînement.
import torch
def run_inference(model_, example, max_new_tokens=256):
prompt = build_prompt(example)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": _resize_pil(example["image"])},
{"type": "text", "text": prompt},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
).to(model_.device)
with torch.inference_mode():
out = model_.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
gen = out[0][inputs["input_ids"].shape[1]:]
return processor.decode(gen, skip_special_tokens=True)
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]Nous évaluons d'abord le modèle sur un échantillon sélectionné de manière aléatoire à partir de l'ensemble d'apprentissage.
print("\n--- BASELINE OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- BASELINE OUTPUT ---
J1,Conn_02x11_Odd_Even,CINT6,CINT5,CINT4,CINT3,CINT2,CINT1,CINT0,CINT15,CINT14,CINT13,CINT12,CINT11,CINT10,CINT9,CINT8,CINT7,CINT16,CINT17,CINT18,CINT19,CINT20,CINT21,CINT22,CINT23,CINT24,CINT25,CINT26,CINT27,CINT28,CINT29,CINT30,CINT31,CINT32,CINT33,CINT34,CINT35,CINT36,CINT37,CINT38,CINT39,CINT40,CINT41,CINT42,CINT43,CINT44,CINT45,CINT46,CINT47,CINT48,CINT49,CINT50,CINT51,CINT52,CINT53,CINT54,CINT55,CINT56,CINT57,CINT58,CINT59,CINT60,CINT61,CINT62
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GNDDans cet exemple, le modèle identifie correctement certains éléments structurels, mais génère un nombre excessif de noms de broches et de signaux, tout en ne parvenant pas à récupérer les identifiants exacts des composants utilisés dans l'ensemble de données. J'ai observé ce même schéma dans plusieurs autres exemples lors de mon évaluation.
Dans l'ensemble, ces résultats de référence indiquent que, bien que le modèle présente une bonne compréhension visuelle et textuelle générale, il manque d'alignement avec les annotations des composants spécifiques à l'ensemble de données. Ce comportement souligne la nécessité d'un ajustement minutieux afin de réduire les résultats fantaisistes et d'améliorer la précision.
9. Développement d'un collecteur de données visuelles et linguistiques pour la formation
Cette section définit un collecteur de données personnalisé qui prépare des lots multimodaux de type chat pour la formation. Il convertit chaque exemple en tenseurs prêts à être modélisés en codant conjointement le texte et les images, tout en veillant à ce que la perte ne soit calculée que sur la réponse de l'assistant.
Le collateur génère deux versions du texte de la conversation : une version complète (invite et cible) pour l'encodage des entrées, et une version contenant uniquement les invites pour calculer la longueur des jetons d'invite. En utilisant ces longueurs, tous les jetons d'invite et de remplissage sont masqués dans les étiquettes, de sorte que seule la sortie de l'assistant contribue à la perte. Les images sont redimensionnées de manière cohérente et une longueur maximale fixe est appliquée pour le contrôle de la mémoire.
from typing import List, Dict, Any
import torch
MAX_LEN = 1500
def collate_fn(batch: List[Dict[str, Any]]):
# 1) Build full chat text (includes assistant answer)
full_texts = [
processor.apply_chat_template(
ex["messages"],
tokenize=False,
add_generation_prompt=False,
)
for ex in batch
]
# 2) Build prompt-only text (up to user turn; generation prompt on)
prompt_texts = [
processor.apply_chat_template(
ex["messages"][:-1],
tokenize=False,
add_generation_prompt=True,
)
for ex in batch
]
# 3) Images
images = [_resize_pil(ex["image"]) for ex in batch]
# 4) Tokenize full inputs ONCE (text + images)
enc = processor(
text=full_texts,
images=images,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
)
input_ids = enc["input_ids"]
pad_id = processor.tokenizer.pad_token_id
# 5) Compute prompt lengths with TEXT-ONLY tokenization (much cheaper than text+images)
prompt_ids = processor.tokenizer(
prompt_texts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
add_special_tokens=False, # chat template already includes special tokens
)["input_ids"]
# Count non-pad tokens in prompt
prompt_lens = (prompt_ids != pad_id).sum(dim=1)
# 6) Labels: copy + mask prompt tokens + mask padding
labels = input_ids.clone()
bs, seqlen = labels.shape
for i in range(bs):
pl = int(prompt_lens[i].item())
pl = min(pl, seqlen)
labels[i, :pl] = -100
# Mask padding positions too
labels[labels == pad_id] = -100
# If your processor produces pixel_values / image_grid_thw, keep them
enc["labels"] = labels
return encCe collateur permet une supervision efficace et précise pour l'ajustement de la vision et du langage.
10. Configuration de LoRA pour un réglage fin efficace du Qwen3-VL-8B
Nous allons maintenant configurer LoRA (Low-Rank Adaptation) afin d'ajuster efficacement le modèle Qwen3-VL sans mettre à jour tous les poids du modèle. LoRA intègre des matrices de rang faible entraînables dans des couches de projection sélectionnées, ce qui réduit considérablement l'utilisation de la mémoire tout en préservant les performances.
from peft import LoraConfig, TaskType, get_peft_model
lora = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM,
target_modules=[
"q_proj","k_proj","v_proj","o_proj",
"gate_proj","up_proj","down_proj"
],
)Nous définissons ensuite la configuration de l'entraînement à l'aide de ` SFTConfig`, en définissant la taille du lot, le taux d'apprentissage, la précision et les options de journalisation adaptées à un réglage fin stable sur le GPU A100.
from trl import SFTTrainer, SFTConfig
args = SFTConfig(
output_dir=f"qwen3vl-open-schematics-{TASK}-lora",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=False,
learning_rate=1e-4,
warmup_steps=10,
weight_decay=0.01,
max_grad_norm=1.0,
bf16=True,
fp16=False,
lr_scheduler_type="cosine",
logging_steps=10,
report_to="none",
remove_unused_columns=False,
)Enfin, nous initialisons l'SFTTrainer, en combinant le modèle, l'ensemble de données, le collateur personnalisé et la configuration LoRA pour commencer le réglage fin supervisé.
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=train_ds,
data_collator=collate_fn,
peft_config=lora
)11. Ajustement du modèle Qwen3-VL-8B sur l'ensemble de données Open Schematics
Nous entamons maintenant le processus de réglage fin à l'aide du trainer configuré.
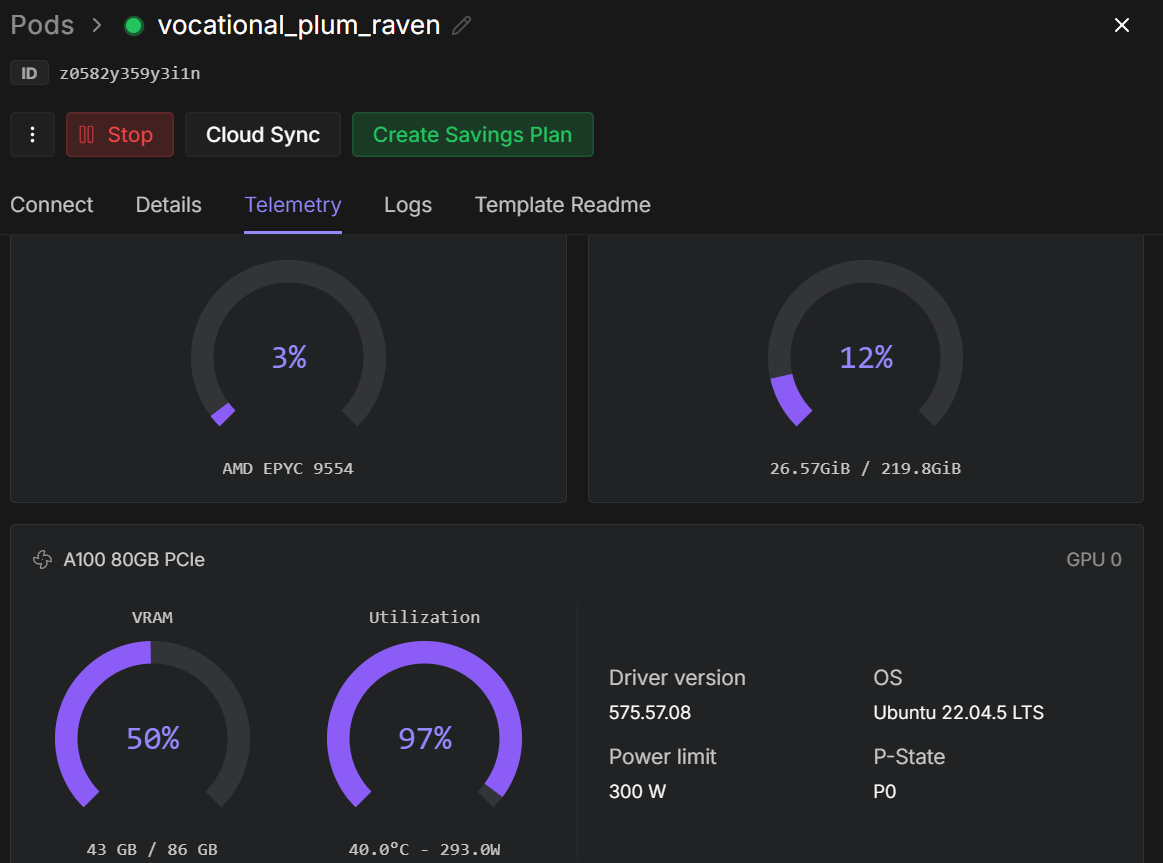
trainer.train()Une fois l'entraînement commencé, vous pouvez surveiller le tableau de bord télémétrique RunPod. Sur une instance A100 de 80 Go, le processus utilise généralement entre 40 et 45 Go de VRAM et atteint une utilisation quasi maximale du GPU, ce qui indique une utilisation efficace du matériel.
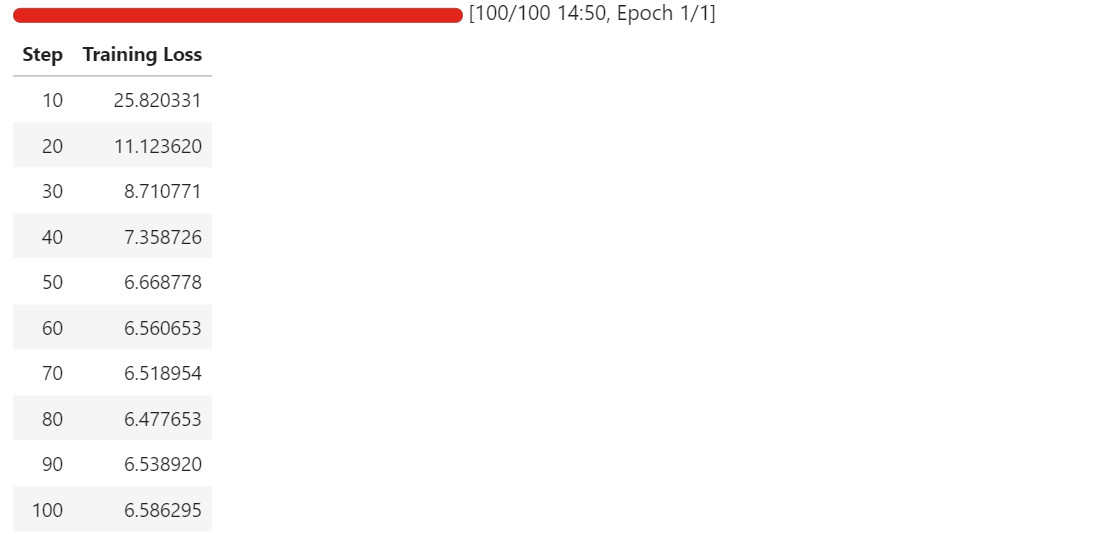
Au fur et à mesure que la formation progresse, vous devriez observer une diminution régulière de la perte de formation avant qu'elle ne se stabilise. Dans notre cas, la perte converge et se stabilise à environ 6,5, ce qui sert d'indicateur de référence indiquant que le modèle s'est adapté à la tâche d'extraction schématique des composants.
À ce stade, les adaptateurs LoRA ont été ajustés avec succès et sont prêts à être évalués et exportés.
12. Publication du modèle optimisé sur Hugging Face Hub
Une fois le réglage fin terminé, nous enregistrons d'abord localement les adaptateurs LoRA entraînés et le processeur associé.
out_dir = trainer.args.output_dir # from your SFTConfig/TrainingArguments
trainer.save_model(out_dir) # saves model/adapters into output_dir
processor.save_pretrained(out_dir) # save processor (tokenizer + image processor)Ensuite, nous publions le modèle ajusté sur le Hugging Face Hub. Cela permet de réutiliser les adaptateurs et le processeur pour l'inférence ou un réglage plus précis.
import os
repo_id = "kingabzpro/qwen3vl-open-schematics-lora" # replace with your username/repo
# Push model/adapters
trainer.model.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
# Push processor
processor.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
Une fois le téléchargement terminé, les adaptateurs LoRA et le processeur optimisés sont accessibles au public dans le référentiel spécifié.
12. Évaluation du modèle Qwen3-VL-8B optimisé
Après avoir procédé aux réglages nécessaires, nous rechargeons le modèle et le processeur directement depuis le Hugging Face Hub. Cela garantit que l'évaluation est effectuée à l'aide des adaptateurs LoRA exportés, exactement comme ils seraient utilisés dans un contexte d'inférence réel.
model = Qwen3VLForConditionalGeneration.from_pretrained(
repo_id,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(repo_id)
```
We now repeat the same inference procedure used during the baseline evaluation, allowing for a direct comparison between pre-fine-tuning and post-fine-tuning behavior.
```python
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- FINETUNED OUTPUT ---
Conn_02x11_0dd_Even, P3.3V
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GNDPar rapport au modèle de référence, le modèle optimisé produit un résultat beaucoup plus court et plus ciblé, évitant ainsi la génération excessive de noms de broches et de signaux déduits à grande échelle.
Bien que la prédiction soit encore incomplète et comporte des erreurs mineures, elle montre une nette évolution vers des identifiants de composants alignés sur les ensembles de données.
Nous allons maintenant examiner un deuxième exemple afin de confirmer ce comportement.
baseline_ex = train_ds.shuffle(seed=170).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- FINETUNED OUTPUT ---
ATMEGA328P-PU, +5V, GND, R, C, C16MHz, SERVO_A, SERVO_B, SERVO_C, SERVO_D, SERVO_E, SERVO_F, SERVO_G
--- TARGET (dataset) ---
+5V, 7.62MM-3P, 7.62MM-3P_1, 7.62MM-3P_2, 7.62MM-3P_3, 7.62MM-3P_4, 7.62MM-3P_5, 7.62MM-3P_6, ATMEGA328P-PU, ATMEGA328P-PU_1, GND, MBB02070C1002FCT00, MBB02070C1002FCT00_1, Unknown_0_-806, X49SD16MSD2SC, Y5P102K2KV16CC0224, Y5P102K2KV16CC0224_1, Y5P102K2KV16CC0224_2Ici, le modèle optimisé identifie correctement les composants essentiels tels que le microcontrôleur et les réseaux d'alimentation, et réduit considérablement les signaux parasites non pertinents. Cependant, il continue d'abstraire ou de généraliser certains composants au lieu de reproduire les identifiants spécifiques à l'ensemble de données exact.
Dans l'ensemble, ces résultats démontrent que le réglage fin permet de supprimer efficacement la surgénération et d'améliorer l'alignement avec l'extraction des composants au niveau schématique. Bien que la précision puisse être encore améliorée grâce à des époques supplémentaires, des ensembles d'entraînement plus importants ou des contraintes de sortie plus strictes, le comportement post-ajustement fin représente une amélioration claire et mesurable par rapport à la base de référence.
Si vous rencontrez des difficultés lors de l'exécution du code de ce tutoriel, veuillez vous référer au cahier d'exercices.
Conclusions finales
Les modèles de vision-langage sont fondamentalement différents des modèles textuels, et les traiter de la même manière conduit presque toujours à des résultats médiocres.
Si vous ne faites pas attention, il est très facile de rencontrer des erreurs de mémoire insuffisante, même avec une taille de lot de un, ou d'ajuster un modèle qui semble s'entraîner mais qui ne parvient pas à apprendre la tâche. C'est une leçon que j'ai apprise à mes dépens.
Ce qui a finalement fait la différence, c'est le fait de prêter attention aux détails qui importent particulièrement pour la formation multimodale.
Il est essentiel de redimensionner les images pour les limiter à des dimensions sûres, de nettoyer l'ensemble de données afin de supprimer les échantillons endommagés ou inutilisables, et de s'assurer que seules les paires image-texte valides sont transmises au modèle. Le fait de négliger l'un de ces éléments peut rapidement entraîner une instabilité ou un gaspillage de ressources informatiques.
En ce qui concerne la modélisation, l'utilisation exclusive des couches cibles LoRA pertinentes a permis de maintenir l'efficacité et la précision de l'entraînement, tandis que le réglage minutieux des arguments d'entraînement a amélioré la convergence sans augmenter la pression sur la mémoire.
L'optimisation pour le GPU A100, l'activation de Flash Attention et l'utilisation de bfloat16 ont permis de maintenir la stabilité de l'entraînement tout en réduisant considérablement le temps d'exécution. En pratique, ces optimisations réduisent de près de moitié la durée de la formation sans compromettre la qualité.
Les résultats finaux démontrent que même un modèle vision-langage pré-entraîné performant bénéficie considérablement d'un ajustement spécifique au domaine. Grâce à un prétraitement, une configuration et des optimisations adaptées au matériel appropriés, il est possible d'adapter de manière fiable et efficace de grands modèles multimodaux.
Si vous souhaitez approfondir vos connaissances en matière de réglage fin, je vous recommande de suivre la formation cours « Fine-Tuning with Llama 3 ». .