
Programa
Fundamentos de Hugging Face
12 h
Qwen3-VL-8B é o modelo de linguagem visual mais poderoso e amplamente utilizado da série Qwen, projetado para a compreensão unificada de texto, imagens e vídeo.
Ele traz melhorias importantes na geração de texto, raciocínio visual, percepção espacial, tratamento de contextos longos e interação com agentes, tornando-o adequado tanto para pesquisa quanto para implantação no mundo real em ambientes de ponta e na nuvem.
Neste tutorial, vamos ajustar o Qwen3-VL-8B-Instruct em diagramas esquemáticos eletrônicos. Ao treinar o modelo para entender símbolos esquemáticos, conexões e relações espaciais, a gente faz com que ele entenda direitinho os projetos de circuitos e decida quais componentes eletrônicos precisam ser adicionados em um circuito de verdade.
Você vai aprender como:
Se você ainda não conhece o Hugging Face, o Fundamentos de Hugging Face é pra você!
Ao trabalhar com modelos de linguagem de visão, a memória da GPU se torna uma limitação crítica. Imagens de alta resolução e codificadores multimodais podem consumir rapidamente a VRAM, por isso é super recomendável usar uma GPU com bastante memória.
Pra esse tutorial, vamos lançar uma instância instância RunPod A100 (80 GB) usando o mais recente PyTorch. Essa configuração dá espaço suficiente na VRAM para o treinamento e evita gargalos de memória desnecessários durante o ajuste fino.
Desça até a seçãoModelo de Pod. Aqui, escolha aimagem PyTorch mais recente do . É aqui também que você pode ajustar as configurações de armazenamento e adicionar variáveis de ambiente.
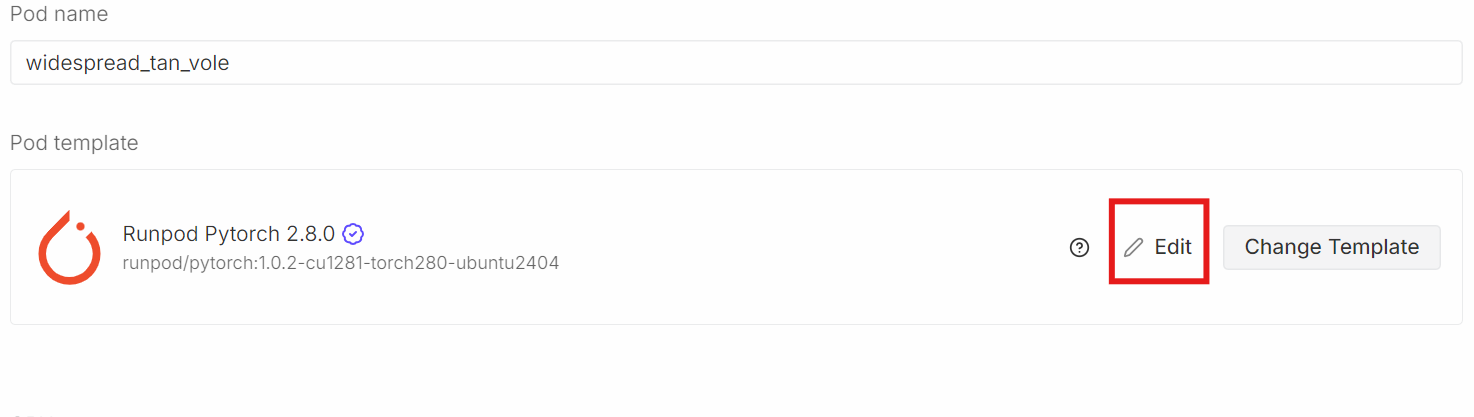
Clique Editare faça as seguintes alterações:
HF_TOKEN e defina seu valor como seu token de acesso ao Hugging Face (gerar um nas configurações do Hugging Face).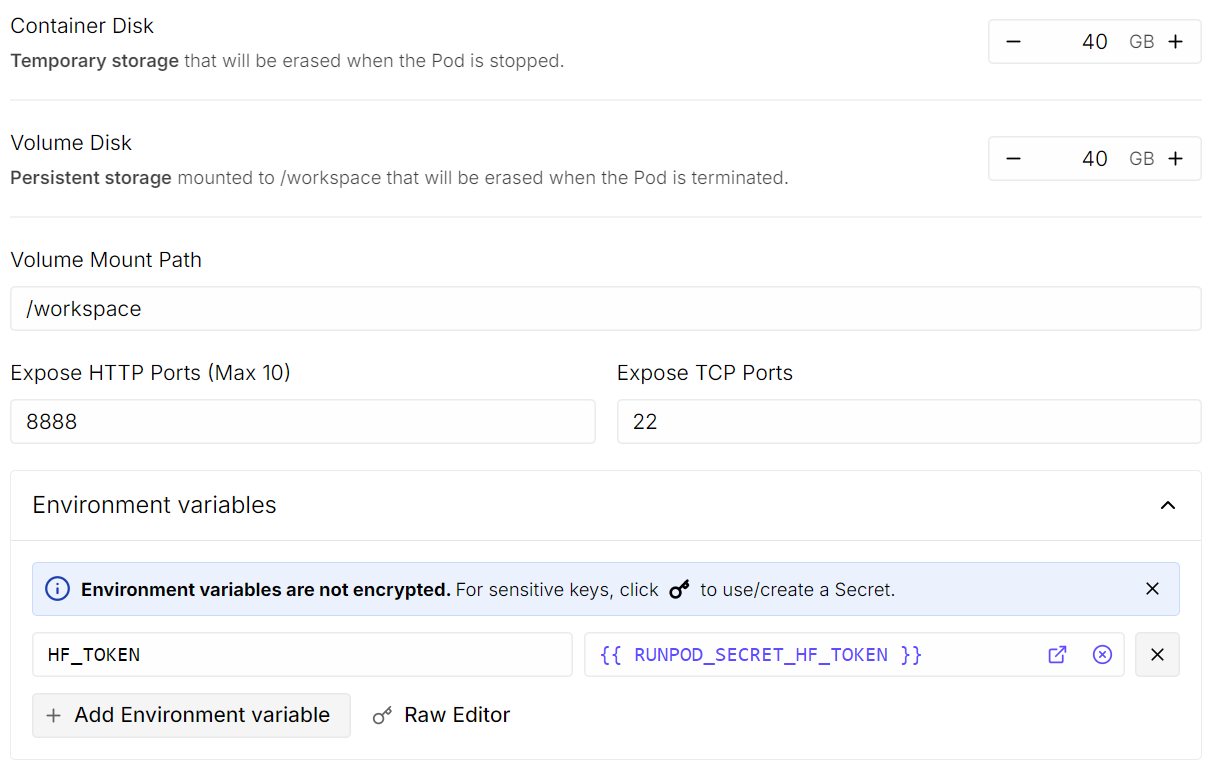
Quando terminar, salva o modelo e implanta o pod.
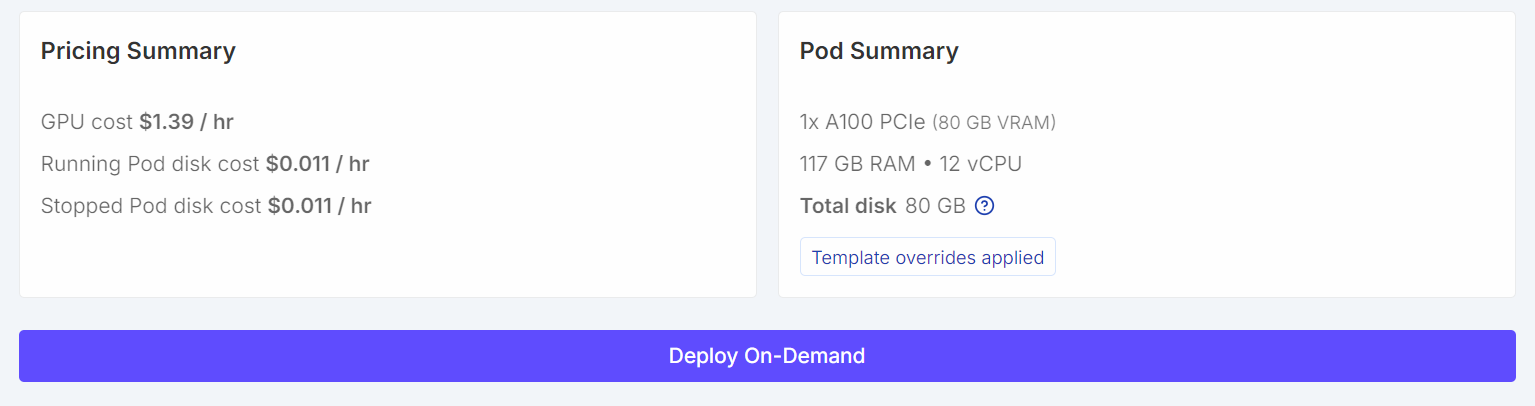
Quando o pod estiver funcionando:
Para instalar as dependências, execute a seguinte célula de código. No Jupyter, um ponto de exclamação no começo diz ao notebook para executar a linha como um comando shell em vez de código Python.
!pip -q install -U accelerate datasets pillow sentencepiece safetensors peft
!pip install --quiet "transformers==5.0.0rc1"
!pip install --quiet --no-deps trl
!pip install --no-cache-dir flash-attn --no-build-isolationDepois, defina uma semente aleatória fixa para garantir a reprodutibilidade e habilite as otimizações de desempenho específicas do A100.
import torch
from transformers import set_seed
set_seed(42)
# A100: TF32 gives speedups without changing your bf16 training setup
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
print("CUDA:", torch.cuda.is_available(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
print("bf16 supported:", torch.cuda.is_available() and torch.cuda.is_bf16_supported())CUDA: True NVIDIA A100 80GB PCIe
bf16 supported: TrueAgora vamos carregar o conjunto de dados Open Schematics do Hugging Face Hub ( ). Esse conjunto de dados tem imagens esquemáticas eletrônicas junto com metadados detalhados que descrevem cada circuito, o que o torna ideal para o treinamento de visão-linguagem.
import torch
from datasets import load_dataset
DATASET_ID = "bshada/open-schematics"
ds_all = load_dataset(DATASET_ID, split="train")
print(ds_all)Dataset({
features: ['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'],
num_rows: 84470
})O conjunto de dados tem mais de 84 mil amostras, cada uma combinando uma imagem esquemática com informações estruturadas, como listas de componentes e formatos legíveis por máquina (JSON e YAML).
Vamos dar uma olhada em uma amostra só pra entender melhor como o conjunto de dados tá organizado.
# quick peek
ex = ds_all[0]
print("\nSample keys:", ex.keys())
print("name:", ex.get("name"))
print("type:", ex.get("type"))
print("components_used:", (ex.get("components_used") or [])[:10])
print("has schematic:", bool(ex.get("schematic")))
print("has json/yaml:", bool(ex.get("json")), bool(ex.get("yaml")))
print("image:", ex.get("image"))Sample keys: dict_keys(['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'])
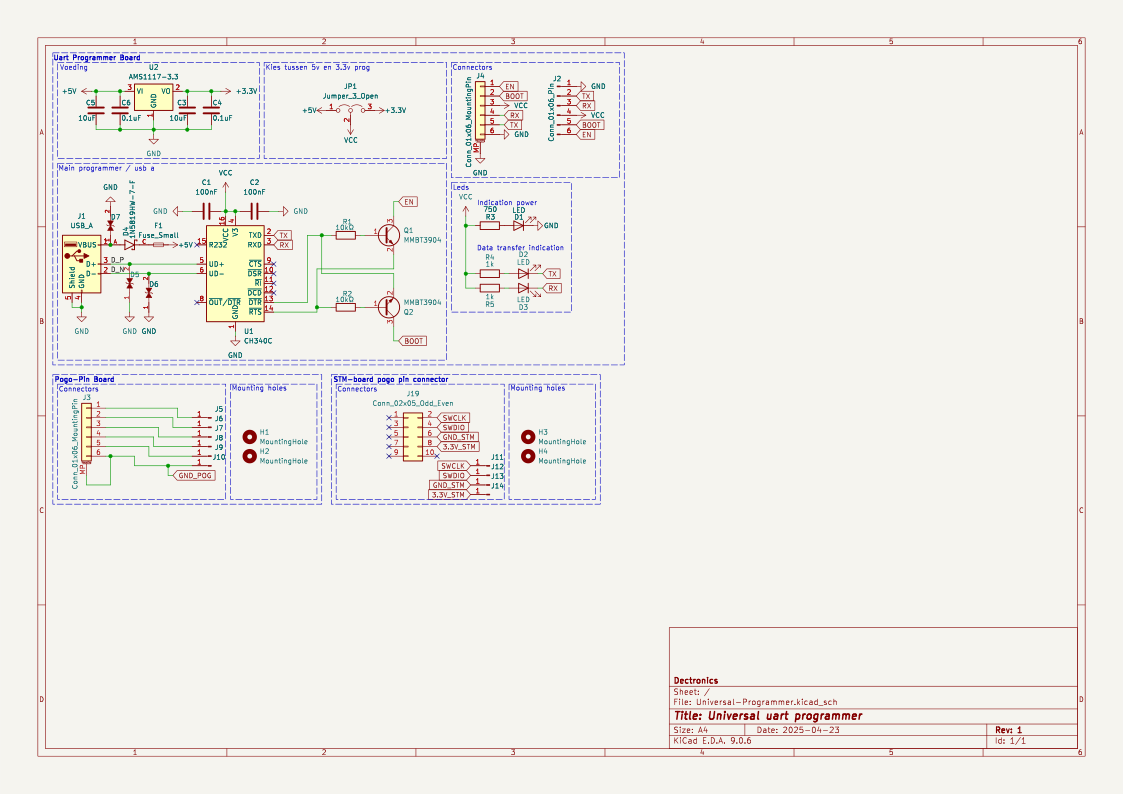
name: TiebeDeclercq/Uart-programmer
type: .kicad_sch
components_used: ['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C']
has schematic: True
has json/yaml: True True
image: <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=1123x794 at 0x7FBC6FD060F0>Isso mostra que cada amostra tem uma imagem esquemática em alta resolução, uma lista de componentes e representações estruturadas do circuito.
Agora podemos renderizar a imagem esquemática diretamente dentro do notebook Jupyter.
ex.get("image")
Por fim, vamos dar uma olhada na lista completa de componentes usados neste esquema.
print(ex.get("components_used"))['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C', 'Jumper_3_Open', 'MountingHole', 'AMS1117-3.3', 'MMBT3904', '1N5819HW-7-F', 'LESD5D5.0CT1G', '+3.3V', '+5V', 'GND', 'VCC']Essa lista de componentes ajuda a entender melhor a relação entre o esquema e os elementos eletrônicos que estão no circuito.
Antes do treinamento, limpamos e filtramos o conjunto de dados para garantir que cada amostra tenha o mínimo de informação necessária para o aprendizado de visão-linguagem. Em especial, a gente se concentra em manter exemplos que tenham anotações de componentes válidas e uma imagem esquemática correspondente.
Primeiro, vamos ver quantas amostras têm entradas components_used faltando, vazias ou inválidas.
need_cols = [c for c in ["components_used", "schematic", "name", "type"] if c in ds_all.column_names]
ds_small = ds_all.select_columns(need_cols)
missing_key = none_components = empty_components = missing_any = 0
has_schematic_but_missing = 0
for ex in ds_small:
if "components_used" not in ex:
missing_key += 1
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
continue
cu = ex["components_used"]
bad = (cu is None) or (isinstance(cu, list) and len(cu) == 0)
if cu is None:
none_components += 1
elif isinstance(cu, list) and len(cu) == 0:
empty_components += 1
if bad:
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
print("\n=== Missing components report ===")
print("Total:", len(ds_all))
print("Missing key:", missing_key)
print("None:", none_components)
print("Empty list:", empty_components)
print("Missing (any):", missing_any)
if "schematic" in need_cols:
print("Has schematic but missing components:", has_schematic_but_missing)=== Missing components report ===
Total: 84470
Missing key: 0
None: 47558
Empty list: 8
Missing (any): 47566
Has schematic but missing components: 47566O resumo abaixo mostra que uma grande parte das amostras contém dados esquemáticos, mas não tem anotações de componentes utilizáveis.
Para evitar o uso desnecessário de memória durante a filtragem, desativamos explicitamente a decodificação de imagens. Isso garante que o Hugging Face não carregue imagens na memória enquanto aplica filtros.
from datasets.features import Image as HFImage
ds_all = ds_all.cast_column("image", HFImage(decode=False))Depois, a gente define um filtro que só deixa passar amostras com uma lista de componentes que não está vazia e uma referência de imagem válida.
def keep_components_and_image(components_used, image):
# keep only rows with components
if not (isinstance(components_used, list) and len(components_used) > 0):
return False
# image must exist
if image is None:
return False
# when decode=False, image is dict-like: {"path": ...} or {"bytes": ...}
if isinstance(image, dict):
return bool(image.get("path")) or bool(image.get("bytes"))
return TrueUsar esse filtro reduz bastante o conjunto de dados para amostras de alta qualidade e totalmente úteis.
ds_clean = ds_all.filter(
keep_components_and_image,
input_columns=["components_used", "image"],
)
print("Original:", len(ds_all))
print("Clean:", len(ds_clean))
print("Dropped:", len(ds_all) - len(ds_clean))Original: 84470
Clean: 33275
Dropped: 51195Depois de filtrar, ficamos com mais de 33 mil amostras limpas que têm imagens esquemáticas válidas e anotações explícitas dos componentes. Esse conjunto de dados limpo é uma base confiável para as etapas seguintes de pré-processamento e treinamento do modelo.
Agora vamos carregar o modelo Qwen3-VL-8B-Instruct junto com o processador que combina com ele. Esse modelo é um modelo de visão-linguagem em grande escala capaz de raciocinar conjuntamente sobre imagens e texto, tornando-o adequado para tarefas de compreensão esquemática.
O modelo é carregado com precisão bfloat16 para reduzir o uso de memória, mantendo a estabilidade numérica. Também ativamos o Flash Attention 2 para uma atenção mais rápida e eficiente em termos de memória na GPU A100. A opção “ device_map="auto" ” coloca automaticamente as camadas do modelo na GPU disponível.
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
MODEL_ID = "Qwen/Qwen3-VL-8B-Instruct"
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(MODEL_ID)Essa etapa define utilitários leves para preparar prompts, alvos e imagens para o treinamento de visão-linguagem. Um único pipeline é usado para várias tarefas, mudando a variável TASK (componentes, YAML, JSON ou reconstrução esquemática).
Limites básicos de segurança são usados para controlar o comprimento do alvo e o tamanho da imagem, ajudando a manter o treinamento estável e eficiente em termos de memória.
from PIL import Image
TASK = "components" # "components" | "yaml" | "json" | "schematic"
MAX_TARGET_CHARS = 5000 # safety cap for long targets like schematic/json
MAX_IMAGE_SIDE = 1024 # bigger side
MAX_IMAGE_PIXELS = 1024 * 1024 # safety cap (1.0 MP). raise to 1.5MP if stableA função ` build_prompt() ` cria o texto da instrução que vai para o modelo. Ele usa metadados do conjunto de dados para contexto e impõe restrições de saída rigorosas para reduzir alucinações e manter a supervisão consistente entre as tarefas.
def build_prompt(example):
# Use dataset fields to give better context (name/type are helpful)
name = example.get("name") or "Unknown project"
ftype = example.get("type") or "unknown format"
if TASK == "components":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, extract all component labels and identifiers exactly as shown "
"(part numbers, values, footprints, net labels like +5V/GND).\n"
"Output only a comma-separated list. Do not generalize or add extra text."
)
if TASK == "yaml":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce YAML metadata for the design.\n"
"Return valid YAML only. No markdown, no explanations."
)
if TASK == "json":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce a JSON representation of the schematic structure.\n"
"Return valid JSON only. No markdown, no explanations."
)
if TASK == "schematic":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, reconstruct the raw KiCad schematic content.\n"
"Return only the schematic text. No markdown, no explanations."
)
raise ValueError("Unknown TASK")A função “ build_target() ” pega a resposta certa para a tarefa escolhida direto do conjunto de dados. O conteúdo é devolvido literalmente para treinar o modelo na reprodução exata, sem parafrasear.
def build_target(example):
if TASK == "components":
comps = example.get("components_used") or []
return ", ".join(comps)
if TASK == "yaml":
return (example.get("yaml") or "").strip()
if TASK == "json":
return (example.get("json") or "").strip()
if TASK == "schematic":
return (example.get("schematic") or "").strip()
raise ValueError("Unknown TASK")A função ` clamp_text() ` coloca um limite rígido de caracteres nos alvos. Isso evita que arquivos JSON, YAML ou esquemáticos muito grandes causem problemas de memória durante o treinamento.
def clamp_text(s: str, max_chars: int = MAX_TARGET_CHARS) -> str:
s = (s or "").strip()
return s if len(s) <= max_chars else s[:max_chars].rstrip()A função “ _resize_pil() ” normaliza e redimensiona imagens esquemáticas antes do processamento. Ele impõe um comprimento lateral máximo e uma contagem total máxima de pixels, garantindo um uso previsível da memória da GPU e preservando os detalhes visuais.
def _resize_pil(pil: Image.Image, max_side: int = MAX_IMAGE_SIDE, max_pixels: int = MAX_IMAGE_PIXELS) -> Image.Image:
pil = pil.convert("RGB")
w, h = pil.size
# Scale down if max side too large
scale_side = min(1.0, max_side / float(max(w, h)))
# Scale down if too many pixels (area cap)
scale_area = (max_pixels / float(w * h)) ** 0.5 if (w * h) > max_pixels else 1.0
scale = min(scale_side, scale_area)
if scale < 1.0:
nw, nh = max(1, int(w * scale)), max(1, int(h * scale))
pil = pil.resize((nw, nh), resample=Image.BICUBIC)
return pilNesta etapa, a gente transforma cada amostra do conjunto de dados limpo num formato multimodal tipo chat que pode ser usado direto pelo modelo de visão-linguagem Qwen. Esse formato mostra bem a imagem esquemática junto com uma instrução textual e o resultado esperado.
def to_messages(example):
prompt = build_prompt(example)
target = clamp_text(build_target(example))
example["messages"] = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": prompt},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": target}],
},
]
return exampleA gente embaralha o conjunto de dados pra tirar o viés de ordenação e escolhe um pequeno subconjunto pra fazer os primeiros experimentos.
O conjunto de dados é então mapeado através de to_messages() para gerar exemplos de treinamento multimodal. Por fim, a decodificação de imagens é reativada, de modo que as imagens são carregadas apenas durante o treinamento, mantendo o pré-processamento leve e eficiente em termos de memória.
# Start small (increase later)
train_ds = ds_clean.shuffle(seed=42).select(range(min(800, len(ds_clean)))).map(to_messages)
train_ds = train_ds.cast_column("image", HFImage(decode=True))Antes de ajustar tudo, a gente avalia o desempenho inicial do modelo Qwen3-VL 8B Instruct na nossa tarefa. Essa linha de base nos ajuda a entender como o modelo pré-treinado consegue extrair informações de imagens esquemáticas sem precisar de nenhuma adaptação específica para a tarefa.
A função “ run_inference() ” faz uma única passagem direta em um exemplo usando a mesma lógica de solicitação e pré-processamento de imagem que vai ser usada mais tarde durante o treinamento.
import torch
def run_inference(model_, example, max_new_tokens=256):
prompt = build_prompt(example)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": _resize_pil(example["image"])},
{"type": "text", "text": prompt},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
).to(model_.device)
with torch.inference_mode():
out = model_.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
gen = out[0][inputs["input_ids"].shape[1]:]
return processor.decode(gen, skip_special_tokens=True)
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]Primeiro, a gente avalia o modelo em uma amostra escolhida aleatoriamente do conjunto de treinamento.
print("\n--- BASELINE OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- BASELINE OUTPUT ---
J1,Conn_02x11_Odd_Even,CINT6,CINT5,CINT4,CINT3,CINT2,CINT1,CINT0,CINT15,CINT14,CINT13,CINT12,CINT11,CINT10,CINT9,CINT8,CINT7,CINT16,CINT17,CINT18,CINT19,CINT20,CINT21,CINT22,CINT23,CINT24,CINT25,CINT26,CINT27,CINT28,CINT29,CINT30,CINT31,CINT32,CINT33,CINT34,CINT35,CINT36,CINT37,CINT38,CINT39,CINT40,CINT41,CINT42,CINT43,CINT44,CINT45,CINT46,CINT47,CINT48,CINT49,CINT50,CINT51,CINT52,CINT53,CINT54,CINT55,CINT56,CINT57,CINT58,CINT59,CINT60,CINT61,CINT62
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GNDNeste exemplo, o modelo identifica corretamente alguns elementos estruturais, mas gera nomes de pinos e sinais em excesso, sem conseguir recuperar os identificadores exatos dos componentes usados no conjunto de dados. Eu vi esse mesmo padrão em vários outros exemplos quando os analisei.
No geral, esses resultados de referência mostram que, embora o modelo tenha uma compreensão visual e textual geral forte, ele não está alinhado com as anotações de componentes específicas do conjunto de dados. Esse comportamento mostra que é preciso ajustar as coisas para diminuir os resultados alucinados e melhorar a precisão.
Essa seção define um classificador de dados personalizado que prepara lotes multimodais no estilo de bate-papo para treinamento. Ele transforma cada exemplo em tensores prontos para o modelo, codificando texto e imagens juntos, enquanto garante que a perda seja calculada só na resposta do assistente.
O comparador cria duas versões do texto do chat: uma versão completa (prompt e destino) para codificação de entrada e uma versão só com prompt para calcular os comprimentos dos tokens do prompt. Usando esses comprimentos, todos os tokens de prompt e preenchimento são mascarados nos rótulos, então só a saída do assistente contribui para a perda. As imagens são redimensionadas de forma consistente e um comprimento máximo fixo da sequência é aplicado para controle da memória.
from typing import List, Dict, Any
import torch
MAX_LEN = 1500
def collate_fn(batch: List[Dict[str, Any]]):
# 1) Build full chat text (includes assistant answer)
full_texts = [
processor.apply_chat_template(
ex["messages"],
tokenize=False,
add_generation_prompt=False,
)
for ex in batch
]
# 2) Build prompt-only text (up to user turn; generation prompt on)
prompt_texts = [
processor.apply_chat_template(
ex["messages"][:-1],
tokenize=False,
add_generation_prompt=True,
)
for ex in batch
]
# 3) Images
images = [_resize_pil(ex["image"]) for ex in batch]
# 4) Tokenize full inputs ONCE (text + images)
enc = processor(
text=full_texts,
images=images,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
)
input_ids = enc["input_ids"]
pad_id = processor.tokenizer.pad_token_id
# 5) Compute prompt lengths with TEXT-ONLY tokenization (much cheaper than text+images)
prompt_ids = processor.tokenizer(
prompt_texts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
add_special_tokens=False, # chat template already includes special tokens
)["input_ids"]
# Count non-pad tokens in prompt
prompt_lens = (prompt_ids != pad_id).sum(dim=1)
# 6) Labels: copy + mask prompt tokens + mask padding
labels = input_ids.clone()
bs, seqlen = labels.shape
for i in range(bs):
pl = int(prompt_lens[i].item())
pl = min(pl, seqlen)
labels[i, :pl] = -100
# Mask padding positions too
labels[labels == pad_id] = -100
# If your processor produces pixel_values / image_grid_thw, keep them
enc["labels"] = labels
return encEsse comparador permite uma supervisão eficiente e correta para o ajuste fino da visão-linguagem.
Agora vamos configurar o LoRA (Low-Rank Adaptation) para ajustar o modelo Qwen3-VL de forma eficiente, sem atualizar todos os pesos do modelo. O LoRA coloca matrizes de baixa classificação que podem ser treinadas em camadas de projeção selecionadas, reduzindo bastante o uso de memória e mantendo o desempenho.
from peft import LoraConfig, TaskType, get_peft_model
lora = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM,
target_modules=[
"q_proj","k_proj","v_proj","o_proj",
"gate_proj","up_proj","down_proj"
],
)Depois, a gente define a configuração do treinamento usando SFTConfig, ajustando o tamanho do lote, a taxa de aprendizagem, a precisão e as opções de registro adequadas para um ajuste fino estável na GPU A100.
from trl import SFTTrainer, SFTConfig
args = SFTConfig(
output_dir=f"qwen3vl-open-schematics-{TASK}-lora",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=False,
learning_rate=1e-4,
warmup_steps=10,
weight_decay=0.01,
max_grad_norm=1.0,
bf16=True,
fp16=False,
lr_scheduler_type="cosine",
logging_steps=10,
report_to="none",
remove_unused_columns=False,
)Por fim, a gente inicializa o SFTTrainer, juntando o modelo, o conjunto de dados, o classificador personalizado e a configuração LoRA para começar o ajuste fino supervisionado.
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=train_ds,
data_collator=collate_fn,
peft_config=lora
)Agora vamos começar o processo de ajuste fino usando o treinador configurado.
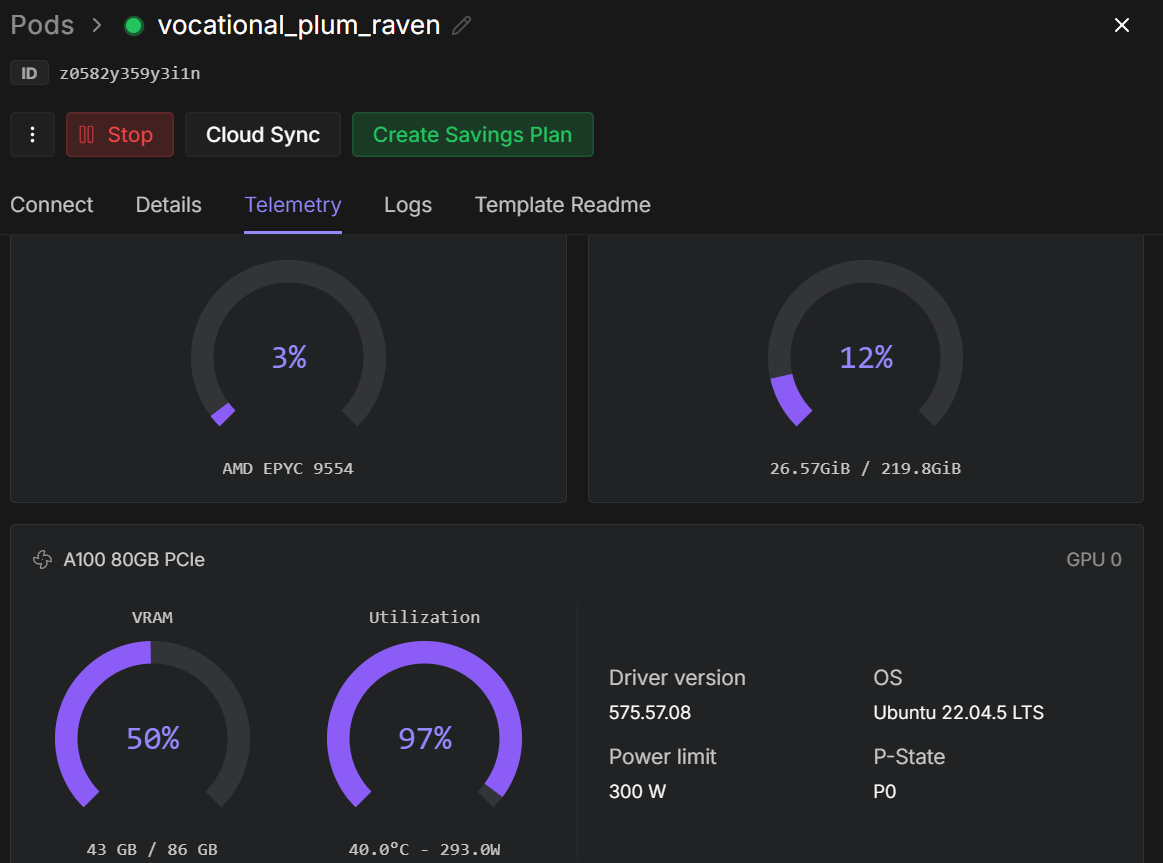
trainer.train()Assim que o treinamento começar, você pode acompanhar o painel de telemetria do RunPod. Em uma instância A100 de 80 GB, o processo normalmente usa cerca de 40 a 45 GB de VRAM e chega quase à utilização total da GPU, mostrando que o hardware está sendo usado de forma eficiente.
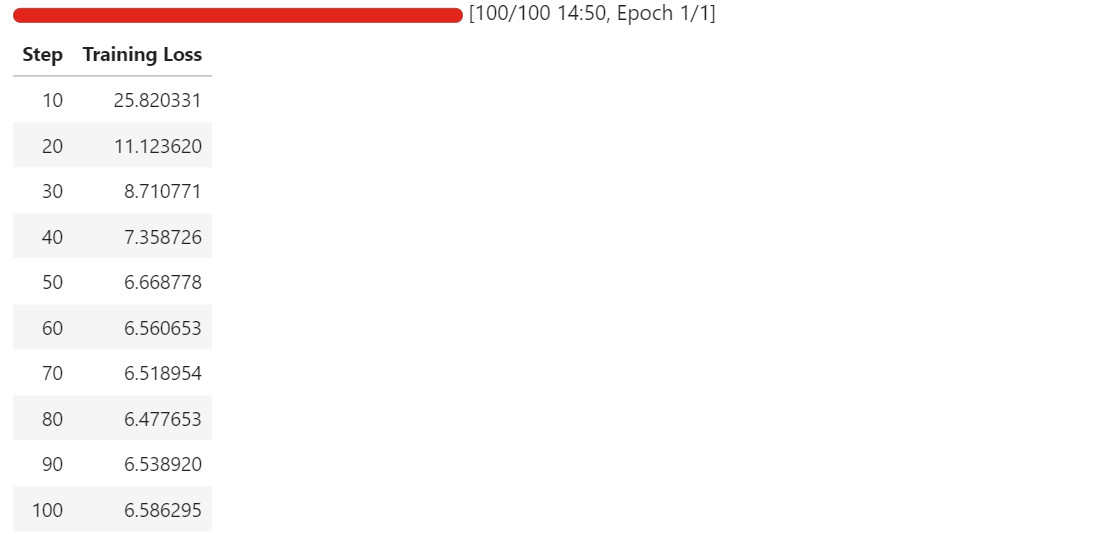
Conforme o treinamento vai rolando, você deve ver a perda de treinamento diminuindo de forma constante antes de se estabilizar. No nosso caso, a perda converge e se estabiliza em aproximadamente 6,5, o que serve como um indicador de referência de que o modelo se adaptou à tarefa de extração de componentes esquemáticos.
Neste ponto, os adaptadores LoRA estão bem ajustados e prontos para avaliação e exportação.
Depois que o ajuste fino estiver pronto, primeiro salvamos os adaptadores LoRA treinados e o processador associado localmente.
out_dir = trainer.args.output_dir # from your SFTConfig/TrainingArguments
trainer.save_model(out_dir) # saves model/adapters into output_dir
processor.save_pretrained(out_dir) # save processor (tokenizer + image processor)Depois, a gente publica o modelo ajustado no Hugging Face Hub. Isso permite que os adaptadores e o processador sejam reutilizados para inferência ou ajustes adicionais.
import os
repo_id = "kingabzpro/qwen3vl-open-schematics-lora" # replace with your username/repo
# Push model/adapters
trainer.model.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
# Push processor
processor.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
Quando o upload estiver pronto, os adaptadores LoRA ajustados e o processador vão ficar disponíveis pra todo mundo no repositório especificado.
Depois de ajustar tudo, recarregamos o modelo e o processador direto do Hugging Face Hub. Isso garante que a avaliação seja feita usando os adaptadores LoRA exportados, exatamente como eles seriam usados em uma configuração de inferência real.
model = Qwen3VLForConditionalGeneration.from_pretrained(
repo_id,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(repo_id)
```
We now repeat the same inference procedure used during the baseline evaluation, allowing for a direct comparison between pre-fine-tuning and post-fine-tuning behavior.
```python
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- FINETUNED OUTPUT ---
Conn_02x11_0dd_Even, P3.3V
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GNDComparado com a linha de base, o modelo ajustado produz um resultado muito mais curto e focado, evitando a geração excessiva em grande escala de nomes de pinos e sinais inferidos.
Embora a previsão ainda esteja incompleta e tenha alguns erros pequenos, ela mostra um movimento claro em direção a identificadores de componentes alinhados com o conjunto de dados.
Agora vamos dar uma olhada em um segundo exemplo pra confirmar esse comportamento.
baseline_ex = train_ds.shuffle(seed=170).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- FINETUNED OUTPUT ---
ATMEGA328P-PU, +5V, GND, R, C, C16MHz, SERVO_A, SERVO_B, SERVO_C, SERVO_D, SERVO_E, SERVO_F, SERVO_G
--- TARGET (dataset) ---
+5V, 7.62MM-3P, 7.62MM-3P_1, 7.62MM-3P_2, 7.62MM-3P_3, 7.62MM-3P_4, 7.62MM-3P_5, 7.62MM-3P_6, ATMEGA328P-PU, ATMEGA328P-PU_1, GND, MBB02070C1002FCT00, MBB02070C1002FCT00_1, Unknown_0_-806, X49SD16MSD2SC, Y5P102K2KV16CC0224, Y5P102K2KV16CC0224_1, Y5P102K2KV16CC0224_2Aqui, o modelo ajustado identifica corretamente os componentes principais, como o microcontrolador e as redes de energia, e reduz significativamente as alucinações irrelevantes no nível do sinal. Mas ainda abstrai ou generaliza alguns componentes em vez de reproduzir os identificadores específicos do conjunto de dados.
No geral, esses resultados mostram que o ajuste fino consegue suprimir a geração excessiva e melhorar o alinhamento com a extração de componentes em nível esquemático. Embora a precisão possa ser melhorada ainda mais com épocas adicionais, conjuntos de treinamento maiores ou restrições de saída mais rigorosas, o comportamento pós-ajuste fino representa uma melhoria clara e mensurável em relação à linha de base.
Se você tiver algum problema ao executar o código deste tutorial, dê uma olhada no caderno que vem junto.
Os modelos de visão-linguagem são bem diferentes dos modelos só de texto, e tratar os dois da mesma forma quase sempre dá em resultados ruins.
Se você não tomar cuidado, é muito fácil encontrar erros de memória insuficiente, mesmo com um tamanho de lote de um, ou ajustar um modelo que parece treinar, mas não consegue realmente aprender a tarefa. Isso é algo que aprendi da maneira mais difícil.
O que acabou fazendo a diferença foi prestar atenção aos detalhes que importam especificamente para o treinamento multimodal.
Redimensionar imagens para limites seguros, limpar o conjunto de dados para tirar amostras quebradas ou inutilizáveis e garantir que só pares válidos de imagem-texto sejam passados para o modelo são etapas essenciais. Pular qualquer uma dessas etapas leva rapidamente à instabilidade ou ao desperdício de recursos computacionais.
No lado da modelagem, usar só as camadas-alvo relevantes do LoRA ajudou a manter o treinamento eficiente e focado, enquanto o ajuste cuidadoso dos argumentos de treinamento melhorou a convergência sem aumentar a pressão sobre a memória.
Otimizar para a GPU A100, ativar o Flash Attention e usar bfloat16 permitiu que o treinamento continuasse estável, reduzindo bastante o tempo de execução. Na prática, essas otimizações reduzem o tempo de treinamento quase pela metade, sem perder a qualidade.
Os resultados finais mostram que mesmo um modelo de visão-linguagem pré-treinado forte se beneficia muito do ajuste fino específico do domínio. Com o pré-processamento, a configuração e as otimizações adequadas para o hardware, dá pra adaptar modelos multimodais grandes de forma confiável e eficiente.
Se você quiser continuar praticando o ajuste fino, recomendo fazer o curso Ajustes finos com Llama 3 .
Cursos de LLM
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze


