
Lernpfad
Grundlagen von Hugging Face
12 Std.
Qwen3-VL-8B ist das leistungsstärkste und am weitesten verbreitete Vision-Language-Modell der Qwen-Serie, das für das einheitliche Verständnis von Text, Bildern und Videos entwickelt wurde.
Es bringt echt große Verbesserungen bei der Textgenerierung, visuellen Schlussfolgerungen, räumlichen Wahrnehmung, Verarbeitung langer Kontexte und Interaktion mit Agenten, sodass es sowohl für die Forschung als auch für den Einsatz in der Praxis in Edge- und Cloud-Umgebungen super geeignet ist.
In diesem Tutorial werden wir Qwen3‑VL‑8B‑Instruct Qwen3-VL-8B-Instruct anhand von elektronischen Schaltplänen anpassen. Indem wir das Modell trainieren, schematische Symbole, Verbindungen und räumliche Beziehungen zu verstehen, kann es Schaltungsdesigns richtig erkennen und herausfinden, welche elektronischen Bauteile in einer echten Schaltung noch gebraucht werden.
Du wirst lernen, wie man:
Wenn du Hugging Face noch nicht kennst, findest du die Hugging Face Fundamentals Skill Track genau das Richtige für dich!
Bei der Arbeit mit Vision-Sprachmodellenwird der GPU-Speicher echt knapp. Hochauflösende Bilder und multimodale Encoder können den VRAM schnell belasten, deshalb ist es echt empfehlenswert, eine GPU mit viel Speicher zu verwenden.
Für dieses Tutorial starten wir eine RunPod A100 (80 GB)-Instanz mit der neuesten PyTorch. Diese Konfiguration bietet genug VRAM-Speicherplatz fürs Training und verhindert unnötige Speicherengpässe beim Fine-Tuning.
Scroll runter zum Abschnitt„Pod-Template- ”. Wähle hier dasneueste PyTorch-Image „ “ aus:. Hier kannst du auch die Speichereinstellungen anpassen und Umgebungsvariablen hinzufügen.
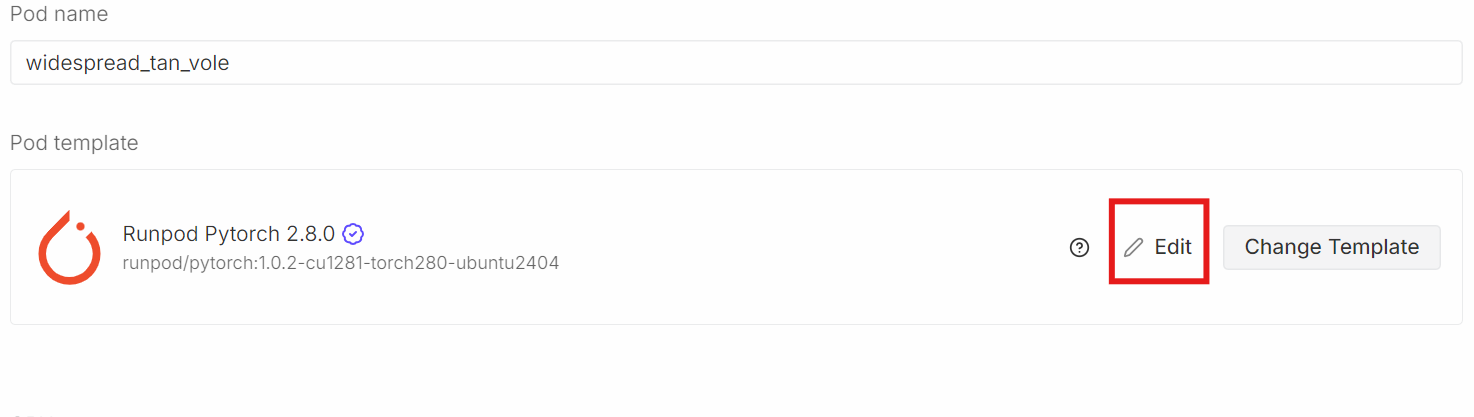
Klick Bearbeitenund nimm dann die folgenden Änderungen vor:
HF_TOKEN “ hinzu und gib als Wert deinen Hugging Face-Zugriffstoken ein (den kannst du in den Hugging Face-Einstellungen erstellen).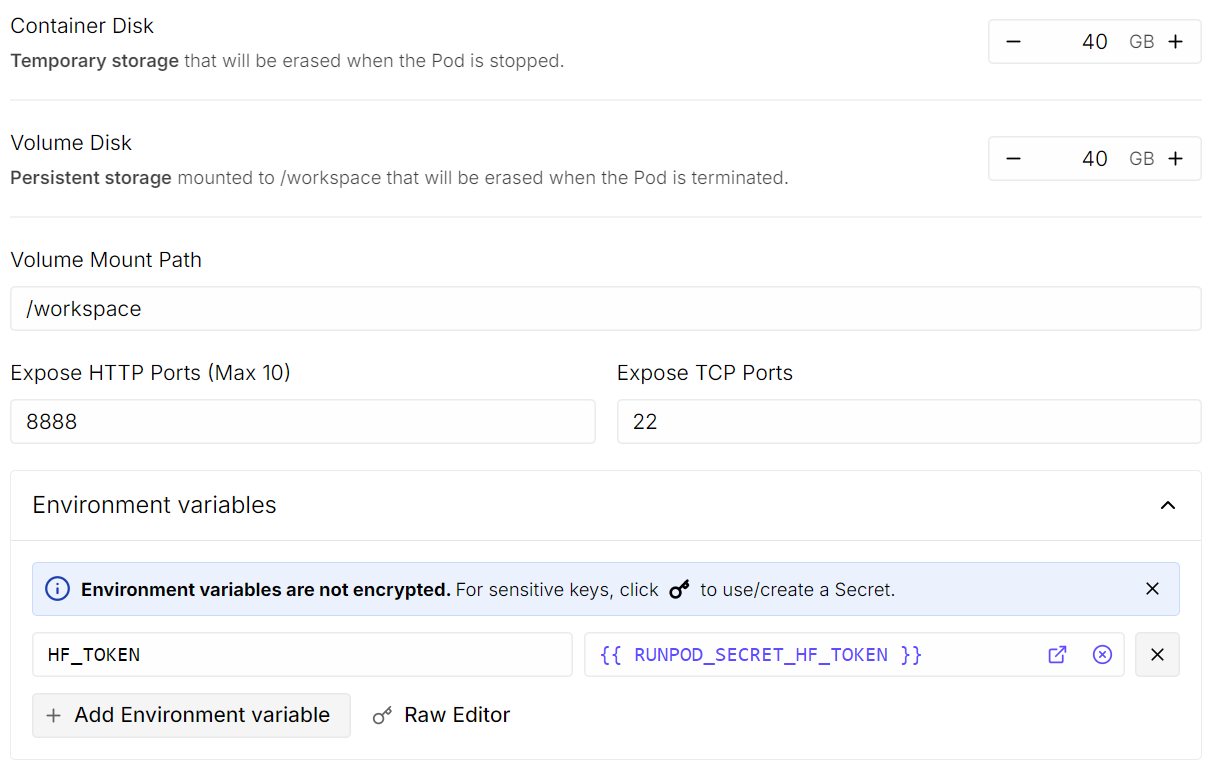
Wenn du fertig bist, speicher die Vorlage und stell den Pod bereit.
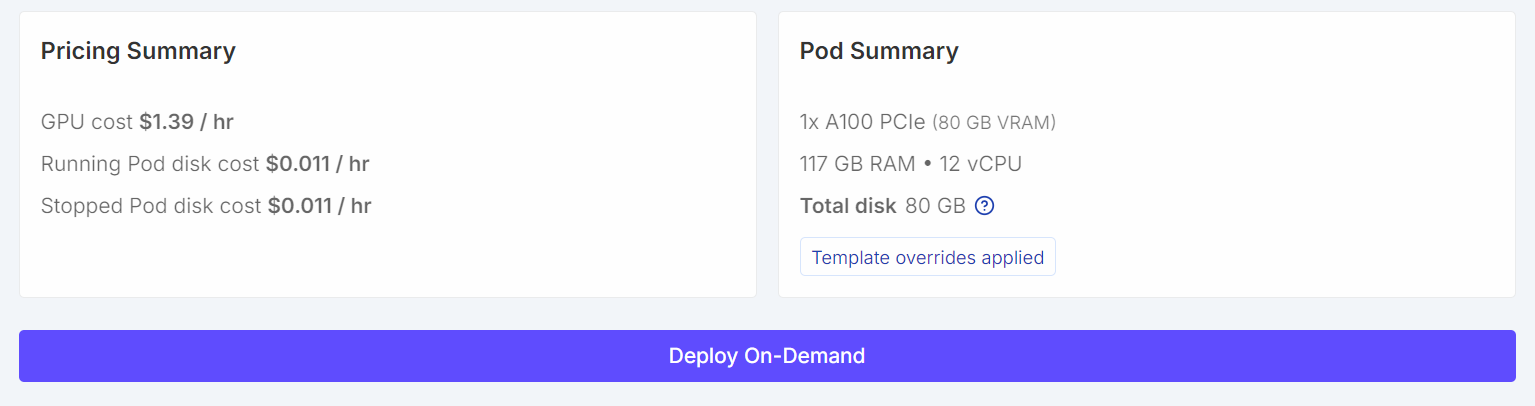
Sobald der Pod läuft:
Um die Abhängigkeiten zu installieren, machst du einfach den folgenden Code. In Jupyter sagt ein Ausrufezeichen am Anfang dem Notebook, dass es die Zeile als shell-Befehl und nicht als Python-Code ausführen soll.
!pip -q install -U accelerate datasets pillow sentencepiece safetensors peft
!pip install --quiet "transformers==5.0.0rc1"
!pip install --quiet --no-deps trl
!pip install --no-cache-dir flash-attn --no-build-isolationAls Nächstes legst du einen festen Zufallsstartwert für die Reproduzierbarkeit fest und aktivierst die A100-spezifischen Leistungsoptimierungen.
import torch
from transformers import set_seed
set_seed(42)
# A100: TF32 gives speedups without changing your bf16 training setup
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
print("CUDA:", torch.cuda.is_available(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
print("bf16 supported:", torch.cuda.is_available() and torch.cuda.is_bf16_supported())CUDA: True NVIDIA A100 80GB PCIe
bf16 supported: TrueWir laden jetzt den Datensatz „ “ von Open Schematics aus dem Hugging Face Hub. Dieser Datensatz hat elektronische Schaltplanbilder und viele Metadaten, die jede Schaltung beschreiben, und ist damit super für das Training von Bild-Sprache-Verbindungen.
import torch
from datasets import load_dataset
DATASET_ID = "bshada/open-schematics"
ds_all = load_dataset(DATASET_ID, split="train")
print(ds_all)Dataset({
features: ['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'],
num_rows: 84470
})Der Datensatz hat über 84.000 Beispiele, wobei jedes Beispiel ein schematisches Bild mit strukturierten Infos wie Komponentenlisten und maschinenlesbaren Formaten (JSON und YAML) kombiniert.
Schauen wir uns mal ein einzelnes Beispiel an, um die Struktur des Datensatzes besser zu verstehen.
# quick peek
ex = ds_all[0]
print("\nSample keys:", ex.keys())
print("name:", ex.get("name"))
print("type:", ex.get("type"))
print("components_used:", (ex.get("components_used") or [])[:10])
print("has schematic:", bool(ex.get("schematic")))
print("has json/yaml:", bool(ex.get("json")), bool(ex.get("yaml")))
print("image:", ex.get("image"))Sample keys: dict_keys(['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'])
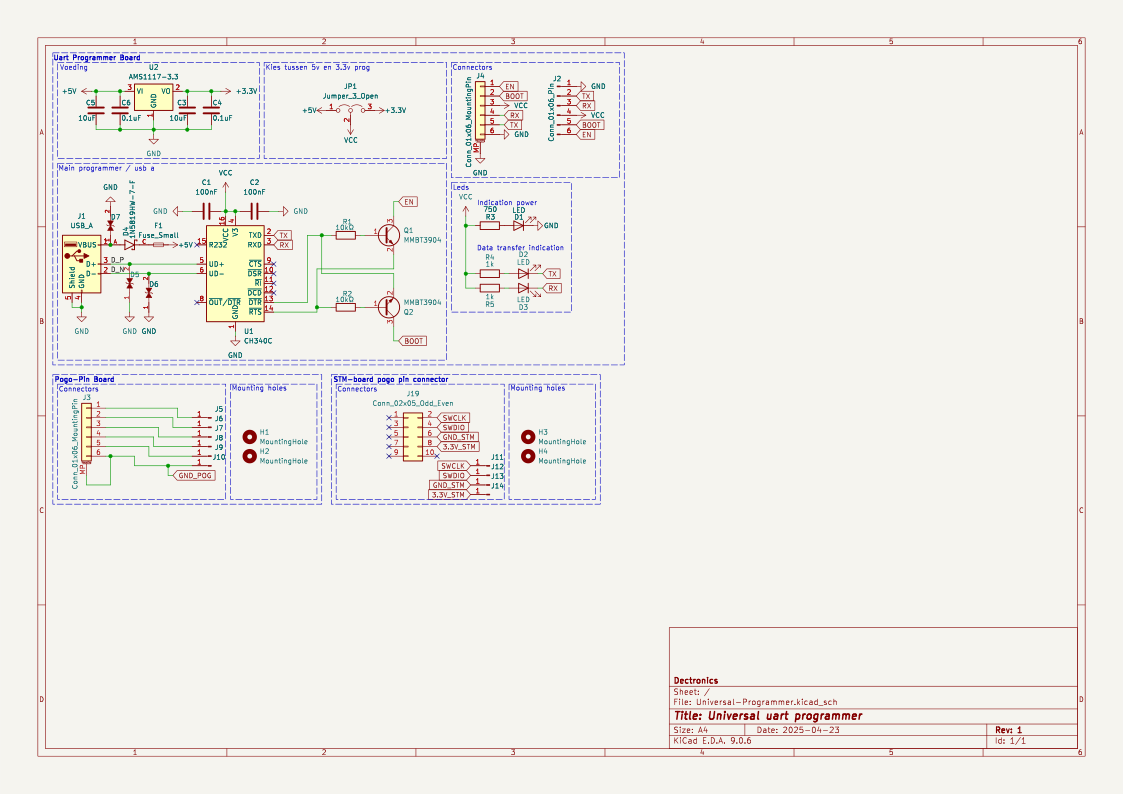
name: TiebeDeclercq/Uart-programmer
type: .kicad_sch
components_used: ['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C']
has schematic: True
has json/yaml: True True
image: <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=1123x794 at 0x7FBC6FD060F0>Das heißt, jede Probe hat ein hochauflösendes schematisches Bild, eine Liste der Teile und strukturierte Darstellungen der Schaltung.
Jetzt können wir das Schema direkt im Jupyter-Notebook anzeigen.
ex.get("image")
Zum Schluss schauen wir uns die komplette Liste der Teile an, die in diesem Schaltplan verwendet werden.
print(ex.get("components_used"))['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C', 'Jumper_3_Open', 'MountingHole', 'AMS1117-3.3', 'MMBT3904', '1N5819HW-7-F', 'LESD5D5.0CT1G', '+3.3V', '+5V', 'GND', 'VCC']Diese Komponentenliste macht den Zusammenhang zwischen dem Schaltplan und den elektronischen Bauteilen im Schaltkreis klar.
Vor dem Training putzen und filtern wir den Datensatz, um sicherzustellen, dass jede Probe die Mindestinformationen enthält, die fürs Lernen von Bild-Sprache-Verbindungen nötig sind. Wir konzentrieren uns vor allem darauf, Beispiele zu behalten, die gültige Komponentenanmerkungen und ein passendes schematisches Bild haben.
Zuerst schauen wir, wie viele Proben fehlende, leere oder ungültige Einträge im Feld „ components_used “ haben.
need_cols = [c for c in ["components_used", "schematic", "name", "type"] if c in ds_all.column_names]
ds_small = ds_all.select_columns(need_cols)
missing_key = none_components = empty_components = missing_any = 0
has_schematic_but_missing = 0
for ex in ds_small:
if "components_used" not in ex:
missing_key += 1
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
continue
cu = ex["components_used"]
bad = (cu is None) or (isinstance(cu, list) and len(cu) == 0)
if cu is None:
none_components += 1
elif isinstance(cu, list) and len(cu) == 0:
empty_components += 1
if bad:
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
print("\n=== Missing components report ===")
print("Total:", len(ds_all))
print("Missing key:", missing_key)
print("None:", none_components)
print("Empty list:", empty_components)
print("Missing (any):", missing_any)
if "schematic" in need_cols:
print("Has schematic but missing components:", has_schematic_but_missing)=== Missing components report ===
Total: 84470
Missing key: 0
None: 47558
Empty list: 8
Missing (any): 47566
Has schematic but missing components: 47566Die Zusammenfassung unten zeigt, dass viele Proben zwar schematische Daten haben, aber keine brauchbaren Anmerkungen zu den Komponenten.
Um unnötigen Speicherverbrauch beim Filtern zu vermeiden, deaktivieren wir die Bilddekodierung extra. Dadurch wird sichergestellt, dass Hugging Face beim Anwenden von Filtern keine Bilder in den Speicher lädt.
from datasets.features import Image as HFImage
ds_all = ds_all.cast_column("image", HFImage(decode=False))Dann machen wir einen Filter, der nur Samples mit einer nicht leeren Komponentenliste und einer gültigen Bildreferenz behält.
def keep_components_and_image(components_used, image):
# keep only rows with components
if not (isinstance(components_used, list) and len(components_used) > 0):
return False
# image must exist
if image is None:
return False
# when decode=False, image is dict-like: {"path": ...} or {"bytes": ...}
if isinstance(image, dict):
return bool(image.get("path")) or bool(image.get("bytes"))
return TrueDurch diesen Filter wird der Datensatz auf hochwertige, voll nutzbare Proben reduziert.
ds_clean = ds_all.filter(
keep_components_and_image,
input_columns=["components_used", "image"],
)
print("Original:", len(ds_all))
print("Clean:", len(ds_clean))
print("Dropped:", len(ds_all) - len(ds_clean))Original: 84470
Clean: 33275
Dropped: 51195Nach dem Filtern haben wir über 33.000 saubere Beispiele, die sowohl gültige Schaltplanbilder als auch klare Komponentenbeschriftungen haben. Dieser bereinigte Datensatz ist eine solide Basis für die nächsten Schritte der Vorverarbeitung und des Modelltrainings.
Jetzt laden wir das Qwen3-VL-8B-Instruct Modell zusammen mit dem passenden Prozessor. Dieses Modell ist ein großes Bild-Sprach-Modell, das Bilder und Text zusammen analysieren kann, was es super für Aufgaben zum schematischen Verstehen macht.
Das Modell wird mit bfloat16-Genauigkeit geladen, um den Speicherverbrauch zu reduzieren und gleichzeitig die numerische Stabilität zu erhalten. Wir haben auch Flash Attention 2 aktiviert, damit die A100-GPU schneller und speichereffizienter arbeiten kann. Die Option „ device_map="auto" “ legt die Modellebenen automatisch auf der verfügbaren GPU ab.
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
MODEL_ID = "Qwen/Qwen3-VL-8B-Instruct"
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(MODEL_ID)Dieser Schritt erklärt einfache Tools zum Vorbereiten von Eingabeaufforderungen, Zielen und Bildern für das Training von Bildverarbeitung und Sprache. Eine einzige Pipeline kann für verschiedene Aufgaben genutzt werden, indem man die Variable „ TASK “ (Komponenten, YAML, JSON oder schematische Rekonstruktion) umstellt.
Es gibt grundlegende Sicherheitsgrenzen, um die Ziellänge und Bildgröße zu kontrollieren, was dabei hilft, das Training stabil und speichereffizient zu halten.
from PIL import Image
TASK = "components" # "components" | "yaml" | "json" | "schematic"
MAX_TARGET_CHARS = 5000 # safety cap for long targets like schematic/json
MAX_IMAGE_SIDE = 1024 # bigger side
MAX_IMAGE_PIXELS = 1024 * 1024 # safety cap (1.0 MP). raise to 1.5MP if stableDie Funktion „ build_prompt() “ baut den Befehlstext auf, der an das Modell weitergegeben wird. Es nutzt Metadaten aus Datensätzen für den Kontext und setzt strenge Ausgabebeschränkungen durch, um Halluzinationen zu reduzieren und die Überwachung über alle Aufgaben hinweg konsistent zu halten.
def build_prompt(example):
# Use dataset fields to give better context (name/type are helpful)
name = example.get("name") or "Unknown project"
ftype = example.get("type") or "unknown format"
if TASK == "components":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, extract all component labels and identifiers exactly as shown "
"(part numbers, values, footprints, net labels like +5V/GND).\n"
"Output only a comma-separated list. Do not generalize or add extra text."
)
if TASK == "yaml":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce YAML metadata for the design.\n"
"Return valid YAML only. No markdown, no explanations."
)
if TASK == "json":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce a JSON representation of the schematic structure.\n"
"Return valid JSON only. No markdown, no explanations."
)
if TASK == "schematic":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, reconstruct the raw KiCad schematic content.\n"
"Return only the schematic text. No markdown, no explanations."
)
raise ValueError("Unknown TASK")Die Funktion „ build_target() “ holt die Ground-Truth-Ausgabe für die ausgewählte Aufgabe direkt aus dem Datensatz. Der Inhalt wird wortwörtlich zurückgegeben, um das Modell auf exakte Wiedergabe zu trainieren, nicht auf Paraphrasierung.
def build_target(example):
if TASK == "components":
comps = example.get("components_used") or []
return ", ".join(comps)
if TASK == "yaml":
return (example.get("yaml") or "").strip()
if TASK == "json":
return (example.get("json") or "").strip()
if TASK == "schematic":
return (example.get("schematic") or "").strip()
raise ValueError("Unknown TASK")Die Funktion „ clamp_text() “ setzt eine strenge Zeichenbegrenzung für Ziele. Das verhindert, dass zu große JSON-, YAML- oder Schema-Dateien beim Training Speicherprobleme verursachen.
def clamp_text(s: str, max_chars: int = MAX_TARGET_CHARS) -> str:
s = (s or "").strip()
return s if len(s) <= max_chars else s[:max_chars].rstrip()Die Funktion „ _resize_pil() “ normalisiert und skaliert Schema-Bilder vor der Verarbeitung. Es sorgt dafür, dass die maximale Seitenlänge und die maximale Gesamtpixelanzahl eingehalten werden, was eine vorhersehbare GPU-Speichernutzung gewährleistet und gleichzeitig die visuellen Details beibehält.
def _resize_pil(pil: Image.Image, max_side: int = MAX_IMAGE_SIDE, max_pixels: int = MAX_IMAGE_PIXELS) -> Image.Image:
pil = pil.convert("RGB")
w, h = pil.size
# Scale down if max side too large
scale_side = min(1.0, max_side / float(max(w, h)))
# Scale down if too many pixels (area cap)
scale_area = (max_pixels / float(w * h)) ** 0.5 if (w * h) > max_pixels else 1.0
scale = min(scale_side, scale_area)
if scale < 1.0:
nw, nh = max(1, int(w * scale)), max(1, int(h * scale))
pil = pil.resize((nw, nh), resample=Image.BICUBIC)
return pilIn diesem Schritt wandeln wir jede bereinigte Datensatzprobe in ein multimodales Chat-Format um, das direkt vom Qwen-Vision-Sprachmodell genutzt werden kann. Dieses Format verbindet das schematische Bild direkt mit einer Textanweisung und dem dazugehörigen Zielergebnis.
def to_messages(example):
prompt = build_prompt(example)
target = clamp_text(build_target(example))
example["messages"] = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": prompt},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": target}],
},
]
return exampleWir mischen den Datensatz, um Verzerrungen bei der Reihenfolge zu vermeiden, und wählen eine kleine Teilmenge für erste Experimente aus.
Dann wird der Datensatz über „ to_messages() “ abgebildet, um multimodale Trainingsbeispiele zu erstellen. Schließlich wird die Bilddekodierung wieder aktiviert, sodass Bilder nur während des Trainings geladen werden, was die Vorverarbeitung schlank und speichereffizient hält.
# Start small (increase later)
train_ds = ds_clean.shuffle(seed=42).select(range(min(800, len(ds_clean)))).map(to_messages)
train_ds = train_ds.cast_column("image", HFImage(decode=True))Bevor wir uns mit der Feinabstimmung beschäftigen, schauen wir uns mal an, wie das Qwen3-VL 8B Instruct-Modell bei unserer Aufgabe so aus der Box heraus abschneidet. Diese Basislinie hilft uns zu verstehen, wie gut das vortrainierte Modell Infos aus schematischen Bildern extrahieren kann, ohne dass eine aufgabenspezifische Anpassung nötig ist.
Die Funktion „ run_inference() “ macht einen einzigen Vorwärtsdurchlauf für ein Beispiel und benutzt dabei die gleiche Eingabeaufforderung und Bildvorverarbeitungslogik, die später beim Training verwendet wird.
import torch
def run_inference(model_, example, max_new_tokens=256):
prompt = build_prompt(example)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": _resize_pil(example["image"])},
{"type": "text", "text": prompt},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
).to(model_.device)
with torch.inference_mode():
out = model_.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
gen = out[0][inputs["input_ids"].shape[1]:]
return processor.decode(gen, skip_special_tokens=True)
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]Zuerst checken wir das Modell anhand einer zufällig ausgewählten Stichprobe aus dem Trainingssatz.
print("\n--- BASELINE OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- BASELINE OUTPUT ---
J1,Conn_02x11_Odd_Even,CINT6,CINT5,CINT4,CINT3,CINT2,CINT1,CINT0,CINT15,CINT14,CINT13,CINT12,CINT11,CINT10,CINT9,CINT8,CINT7,CINT16,CINT17,CINT18,CINT19,CINT20,CINT21,CINT22,CINT23,CINT24,CINT25,CINT26,CINT27,CINT28,CINT29,CINT30,CINT31,CINT32,CINT33,CINT34,CINT35,CINT36,CINT37,CINT38,CINT39,CINT40,CINT41,CINT42,CINT43,CINT44,CINT45,CINT46,CINT47,CINT48,CINT49,CINT50,CINT51,CINT52,CINT53,CINT54,CINT55,CINT56,CINT57,CINT58,CINT59,CINT60,CINT61,CINT62
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GNDIn diesem Beispiel erkennt das Modell zwar einige strukturelle Elemente richtig, generiert aber zu viele Pin- und Signalnamen und schafft es nicht, die genauen Komponentenbezeichnungen aus dem Datensatz wiederherzustellen. Als ich die Beispiele durchgesehen habe, ist mir dasselbe Muster immer wieder aufgefallen.
Insgesamt zeigen diese Basisergebnisse, dass das Modell zwar über ein starkes allgemeines visuelles und textuelles Verständnis verfügt, aber nicht mit den datensatzspezifischen Komponentenannotationen übereinstimmt. Dieses Verhalten zeigt, dass man noch ein bisschen feilen muss, um die falschen Ergebnisse zu reduzieren und die Genauigkeit zu verbessern.
Hier wird ein benutzerdefinierter Daten-Collator beschrieben, der multimodale Chat-Batches für das Training vorbereitet. Es macht aus jedem Beispiel modellfertige Tensoren, indem es Text und Bilder zusammen codiert, und sorgt dabei dafür, dass der Verlust nur anhand der Antwort des Assistenten berechnet wird.
Der Collator erstellt zwei Versionen des Chat-Textes: eine Vollversion (Prompt und Ziel) für die Eingabeverschlüsselung und eine reine Prompt-Version, um die Länge der Prompt-Token zu berechnen. Mit diesen Längen werden alle Prompt- und Padding-Token in den Labels ausgeblendet, sodass nur die Ausgabe des Assistenten zum Verlust beiträgt. Bilder werden einheitlich in der Größe angepasst, und für die Speicherverwaltung wird eine feste maximale Sequenzlänge festgelegt.
from typing import List, Dict, Any
import torch
MAX_LEN = 1500
def collate_fn(batch: List[Dict[str, Any]]):
# 1) Build full chat text (includes assistant answer)
full_texts = [
processor.apply_chat_template(
ex["messages"],
tokenize=False,
add_generation_prompt=False,
)
for ex in batch
]
# 2) Build prompt-only text (up to user turn; generation prompt on)
prompt_texts = [
processor.apply_chat_template(
ex["messages"][:-1],
tokenize=False,
add_generation_prompt=True,
)
for ex in batch
]
# 3) Images
images = [_resize_pil(ex["image"]) for ex in batch]
# 4) Tokenize full inputs ONCE (text + images)
enc = processor(
text=full_texts,
images=images,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
)
input_ids = enc["input_ids"]
pad_id = processor.tokenizer.pad_token_id
# 5) Compute prompt lengths with TEXT-ONLY tokenization (much cheaper than text+images)
prompt_ids = processor.tokenizer(
prompt_texts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
add_special_tokens=False, # chat template already includes special tokens
)["input_ids"]
# Count non-pad tokens in prompt
prompt_lens = (prompt_ids != pad_id).sum(dim=1)
# 6) Labels: copy + mask prompt tokens + mask padding
labels = input_ids.clone()
bs, seqlen = labels.shape
for i in range(bs):
pl = int(prompt_lens[i].item())
pl = min(pl, seqlen)
labels[i, :pl] = -100
# Mask padding positions too
labels[labels == pad_id] = -100
# If your processor produces pixel_values / image_grid_thw, keep them
enc["labels"] = labels
return encDieser Sortierer macht es möglich, die Feinabstimmung von Bildverarbeitung und Sprache effizient und richtig zu überwachen.
Jetzt richten wir LoRA (Low-Rank Adaptation) ein, um das Qwen3-VL-Modell effizient zu optimieren, ohne alle Modellgewichte zu aktualisieren. LoRA packt trainierbare Low-Rank-Matrizen in ausgewählte Projektionsschichten rein, was den Speicherverbrauch echt runterbringt, ohne dass die Leistung darunter leidet.
from peft import LoraConfig, TaskType, get_peft_model
lora = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM,
target_modules=[
"q_proj","k_proj","v_proj","o_proj",
"gate_proj","up_proj","down_proj"
],
)Dann legen wir die Trainingskonfiguration mit „ SFTConfig “ fest und stellen dabei die Batchgröße, die Lernrate, die Präzision und die Protokollierungsoptionen so ein, dass sie für eine stabile Feinabstimmung auf der A100-GPU passen.
from trl import SFTTrainer, SFTConfig
args = SFTConfig(
output_dir=f"qwen3vl-open-schematics-{TASK}-lora",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=False,
learning_rate=1e-4,
warmup_steps=10,
weight_decay=0.01,
max_grad_norm=1.0,
bf16=True,
fp16=False,
lr_scheduler_type="cosine",
logging_steps=10,
report_to="none",
remove_unused_columns=False,
)Zum Schluss starten wir die „ SFTTrainer “, wo wir das Modell, den Datensatz, den benutzerdefinierten Collator und die LoRA-Konfiguration zusammenbringen, um mit dem überwachten Fine-Tuning loszulegen.
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=train_ds,
data_collator=collate_fn,
peft_config=lora
)Jetzt fangen wir mit der Feinabstimmung an, indem wir den konfigurierten Trainer nutzen.
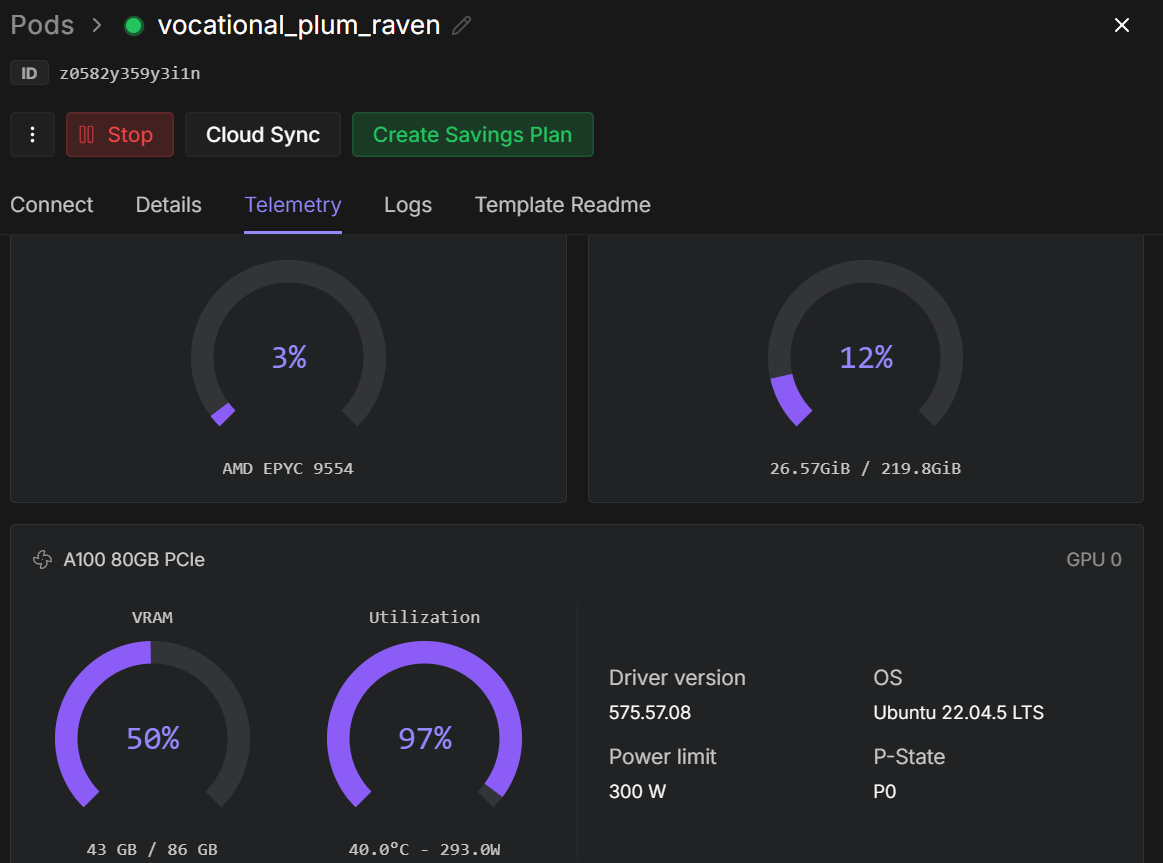
trainer.train()Sobald das Training losgeht, kannst du das RunPod-Telemetrie-Dashboard im Auge behalten. Auf einer A100-Instanz mit 80 GB braucht der Prozess normalerweise etwa 40 bis 45 GB VRAM und nutzt die GPU fast komplett aus, was auf eine effiziente Hardware-Nutzung hindeutet.
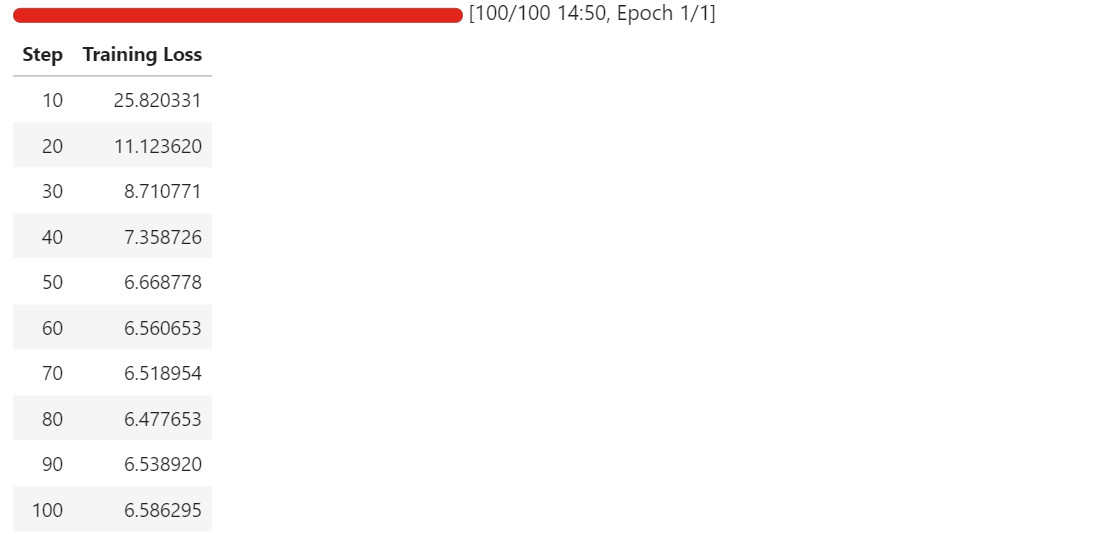
Im Laufe des Trainings solltest du beobachten, wie der Trainingsverlust stetig abnimmt, bevor er sich stabilisiert. Bei uns konvergiert der Verlust und bleibt bei etwa 6,5, was als Basisindikator dafür dient, dass sich das Modell an die schematische Komponentenextraktion angepasst hat.
Jetzt sind die LoRA-Adapter fertig optimiert und können getestet und exportiert werden.
Nachdem die Feinabstimmung fertig ist, speichern wir erst mal die trainierten LoRA-Adapter und den dazugehörigen Prozessor auf dem Rechner.
out_dir = trainer.args.output_dir # from your SFTConfig/TrainingArguments
trainer.save_model(out_dir) # saves model/adapters into output_dir
processor.save_pretrained(out_dir) # save processor (tokenizer + image processor)Als Nächstes stellen wir das fein abgestimmte Modell auf dem Hugging Face Hub zur Verfügung. Dadurch können die Adapter und der Prozessor für die Inferenz oder weitere Feinabstimmungen wiederverwendet werden.
import os
repo_id = "kingabzpro/qwen3vl-open-schematics-lora" # replace with your username/repo
# Push model/adapters
trainer.model.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
# Push processor
processor.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
Sobald der Upload fertig ist, sind die optimierten LoRA-Adapter und der Prozessor öffentlich im angegebenen Repositoryverfügbar.
Nach der Feinabstimmung laden wir das Modell und den Prozessor direkt vom Hugging Face Hub neu. Dadurch wird sichergestellt, dass die Bewertung mit den exportierten LoRA-Adaptern durchgeführt wird, genau wie sie in einer echten Inferenzumgebung verwendet würden.
model = Qwen3VLForConditionalGeneration.from_pretrained(
repo_id,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(repo_id)
```
We now repeat the same inference procedure used during the baseline evaluation, allowing for a direct comparison between pre-fine-tuning and post-fine-tuning behavior.
```python
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- FINETUNED OUTPUT ---
Conn_02x11_0dd_Even, P3.3V
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GNDIm Vergleich zur Basisversion liefert das optimierte Modell viel kürzere und fokussiertere Ergebnisse und vermeidet die massenhafte Übergenerierung von Pin-Namen und abgeleiteten Signalen.
Auch wenn die Vorhersage noch nicht ganz fertig ist und ein paar kleine Fehler hat, zeigt sie doch klar, dass wir uns in Richtung datensatzbasierter Komponentenidentifikatoren bewegen.
Wir schauen uns jetzt ein zweites Beispiel an, um dieses Verhalten zu bestätigen.
baseline_ex = train_ds.shuffle(seed=170).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))--- FINETUNED OUTPUT ---
ATMEGA328P-PU, +5V, GND, R, C, C16MHz, SERVO_A, SERVO_B, SERVO_C, SERVO_D, SERVO_E, SERVO_F, SERVO_G
--- TARGET (dataset) ---
+5V, 7.62MM-3P, 7.62MM-3P_1, 7.62MM-3P_2, 7.62MM-3P_3, 7.62MM-3P_4, 7.62MM-3P_5, 7.62MM-3P_6, ATMEGA328P-PU, ATMEGA328P-PU_1, GND, MBB02070C1002FCT00, MBB02070C1002FCT00_1, Unknown_0_-806, X49SD16MSD2SC, Y5P102K2KV16CC0224, Y5P102K2KV16CC0224_1, Y5P102K2KV16CC0224_2Hier erkennt das fein abgestimmte Modell Kernkomponenten wie den Mikrocontroller und die Stromnetze richtig und reduziert irrelevante Signal-Halluzinationen deutlich. Allerdings werden einige Teile immer noch abstrahiert oder verallgemeinert, anstatt die genauen datensatzspezifischen Identifikatoren zu übernehmen.
Insgesamt zeigen diese Ergebnisse, dass die Feinabstimmung die Übergenerierung erfolgreich unterdrückt und die Übereinstimmung mit der Extraktion von Komponenten auf schematischer Ebene verbessert. Auch wenn die Genauigkeit mit mehr Epochen, größeren Trainingssätzen oder strengeren Ausgabebeschränkungen noch verbessert werden kann, ist das Verhalten nach dem Fine-Tuning eine klare und messbare Verbesserung gegenüber der Ausgangsbasis.
Wenn du beim Ausführen des Codes in diesem Tutorial Probleme hast, schau bitte in das dazugehörigen Notizbuch.
Vision-Sprachmodelle sind total anders als reine Textmodelle, und wenn man sie gleich behandelt, kriegt man meistens schlechte Ergebnisse.
Wenn du nicht aufpasst, kann es schnell zu Speicherfehlern kommen, selbst bei einer Stapelgröße von eins, oder du optimierst ein Modell, das zwar zu trainieren scheint, aber die Aufgabe nicht wirklich lernt. Das hab ich auf die harte Tour gelernt.
Was am Ende den Unterschied gemacht hat, war, dass wir uns auf die Details konzentriert haben, die für multimodales Training wichtig sind.
Das Anpassen der Bildgröße auf sichere Grenzen, das Bereinigen des Datensatzes, um kaputte oder unbrauchbare Beispiele zu entfernen, und das Sicherstellen, dass nur gültige Bild-Text-Paare an das Modell weitergegeben werden, sind alles wichtige Schritte. Wenn du irgendwas davon überspringst, wird es schnell instabil oder verschwendet Rechenleistung.
Beim Modellieren hat die Verwendung nur der relevanten LoRA-Zielschichten dazu beigetragen, das Training effizient und fokussiert zu halten, während die sorgfältige Abstimmung der Trainingsargumente die Konvergenz verbessert hat, ohne den Speicherbedarf zu erhöhen.
Durch die Optimierung für die A100-GPU, die Aktivierung von Flash Attention und die Verwendung von bfloat16 blieb das Training stabil, während die Laufzeit deutlich reduziert wurde. In der Praxis verkürzen diese Optimierungen die Trainingszeit fast um die Hälfte, ohne dass die Qualität darunter leidet.
Die Endergebnisse zeigen, dass selbst ein starkes vortrainiertes Bild-Sprach-Modell von einer domänenspezifischen Feinabstimmung echt profitiert. Mit der richtigen Vorverarbeitung, Konfiguration und hardwareorientierten Optimierungen kann man große multimodale Modelle zuverlässig und effizient anpassen.
Wenn du dich für die Feinabstimmung interessierst, empfehle ich dir den Kurs Feinabstimmung mit Llama 3 zu machen.
LLM-Kurse
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Tutorial
DataCamp Team
Tutorial
Adel Nehme
Tutorial
Matt Crabtree
