Curso
Implantar soluciones de IA en las empresas
2 h
51.9K
Microsoft presentó TNT-LLM, un potente sistema diseñado para automatizar la generación de taxonomías y la clasificación de textos, superando a los métodos tradicionales en eficacia y precisión.
TNT-LLM aprovecha la potencia de los grandes modelos lingüísticos (LLM) para automatizar y escalar la creación de taxonomías y clasificadores con una intervención humana mínima. Esto lo hace especialmente útil para aplicaciones como Bing Copilot, donde es crucial gestionar dominios textuales diversos y en evolución.
En este artículo, te guiaré en la implementación de TNT-LLM utilizando GPT-4o y LangGraph para agrupar artículos de noticias de forma eficaz.
Si quieres leer más sobre GPT-4o o LangGraph, te recomiendo estos artículos:
Si quieres saber más sobre TNT-LLM, te recomiendo el artículo original TnT-LLM: Minería de textos a escala con grandes modelos lingüísticos.
TNT-LLM (Taxonomía y Clasificación de Textos mediante Grandes Modelos Lingüísticos) es un marco en dos fases desarrollado para generar y clasificar taxonomías a partir de documentos de texto. El sistema tiene dos fases principales.
En la primera fase, el sistema toma una muestra de documentos de texto y una instrucción de uso específica, como "generar una taxonomía para agrupar artículos de noticias". Emplea un gran modelo lingüístico (LLM) para resumir cada artículo, extrayendo la información clave. Mediante un proceso iterativo, el LLM genera, actualiza y refina una taxonomía basada en estos resúmenes, produciendo finalmente un conjunto estructurado de etiquetas y descripciones que categorizan eficazmente los artículos de noticias.
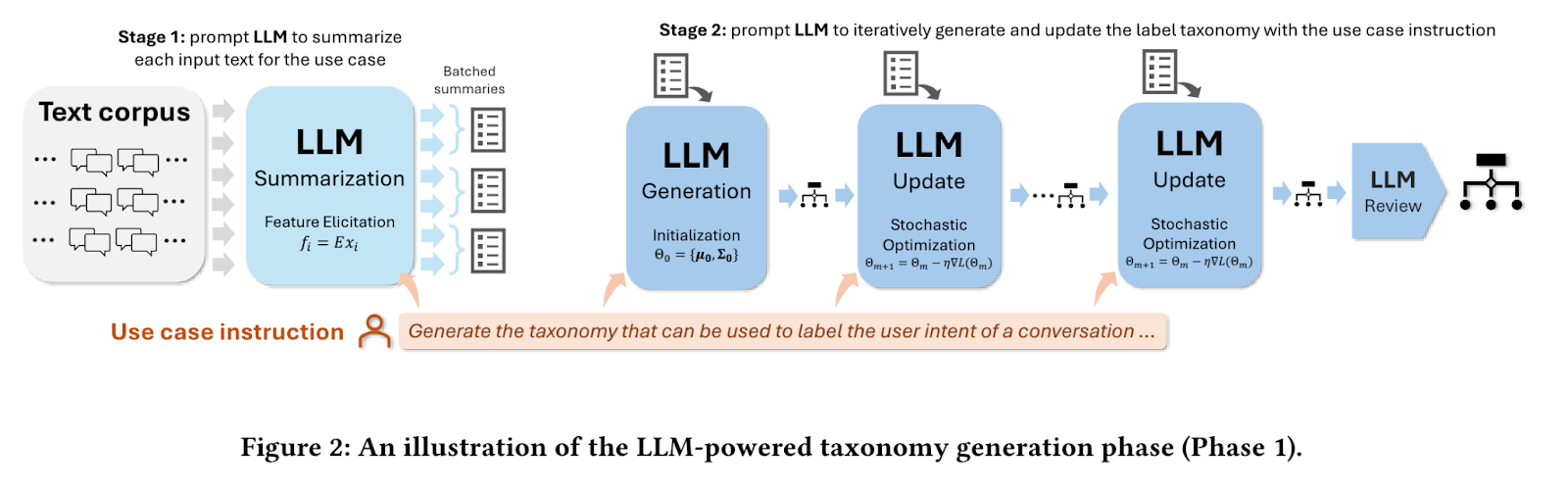
Fuente: Mengting Wan et al.
La segunda fase consiste en utilizar la taxonomía generada para etiquetar un conjunto de datos mayor. El sistema pide a un LLM que aplique estas etiquetas, que luego sirven como datos de entrenamiento para un clasificador ligero, como la regresión logística. Una vez entrenado, este clasificador puede desplegarse para etiquetar eficazmente todo el corpus o realizar una clasificación en tiempo real.
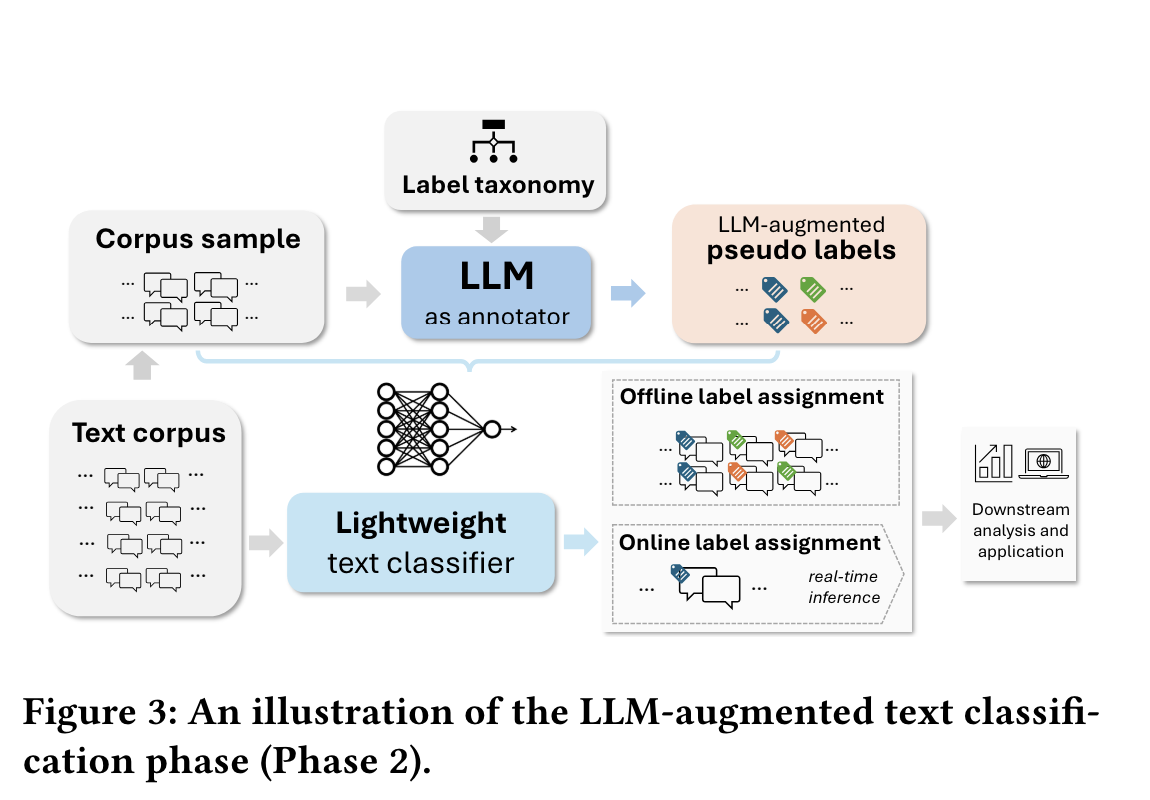
Fuente: Mengting Wan et al.
La flexibilidad de TNT-LLM lo hace aplicable a diversas tareas de clasificación de textos, como la detección de intenciones y la categorización de temas, ampliando su utilidad más allá del mero análisis de conversaciones.
TNT-LLM destaca como una potente herramienta para la minería y clasificación de textos a gran escala, ya que ofrece varias ventajas clave.
TNT-LLM simplifica la creación de taxonomías detalladas e interpretables a partir de datos de texto sin procesar. Este proceso ha automatizado una tarea laboriosa que a menudo requiere conocimientos especializados. El sistema genera taxonomías a medida para casos de uso específicos con una mínima intervención humana, lo que ahorra un tiempo y unos recursos considerables.
Utilizando las taxonomías generadas, TNT-LLM permite la clasificación escalable de textos. Permite crear modelos ligeros que pueden manejar con eficacia grandes conjuntos de datos o tareas de clasificación en tiempo real, por lo que es ideal para aplicaciones con requisitos de alto rendimiento.
TNT-LLM optimiza el uso de recursos aprovechando la utilización escalonada de LLM. Emplea modelos potentes como GPT-4 para la generación de taxonomías y opciones más económicas como GPT-3.5-Turbo para tareas de resumen. La clasificación final se realiza mediante un eficaz modelo de regresión logística, lo que reduce aún más los costes operativos.
El proceso iterativo de generación de taxonomías de TNT-LLM garantiza un perfeccionamiento continuo, que da lugar a categorizaciones de alta calidad, relevantes y precisas, adaptadas a conjuntos de datos y casos de uso específicos.
A la vez que permite la revisión y los ajustes humanos, TNT-LLM requiere una entrada manual mínima en comparación con los métodos tradicionales. Esto reduce los posibles sesgos e incoherencias en la creación de taxonomías.
TNT-LLM se adapta bien a diversas tareas y dominios de clasificación de textos, ofreciendo versatilidad en su aplicación. Su diseño modular permite la integración con diferentes LLM, métodos de incrustación y clasificadores, según sea necesario.
En general, TNT-LLM proporciona una solución sólida para las organizaciones que trabajan con grandes cantidades de datos de texto no estructurados.
Recorramos paso a paso el proceso de implantación.
Para empezar con las implementaciones de TNT-LLM, necesitas instalar los paquetes necesarios. Puedes hacerlo utilizando el siguiente comando pip:
pip install langgraph langchain langchain_openaiAdemás, establece tus variables de entorno para las claves API y los nombres de los modelos:
export AZURE_OPENAI_API_KEY='your_api_key_here' export AZURE_OPENAI_MODEL='your_deployment_name_here' export AZURE_OPENAI_ENDPOINT='deployment_endpoint'En el contexto de la TNT-LLM, comprender algunos conceptos fundamentales es crucial para aprovechar sus capacidades con eficacia.
Los documentos en TNT-LLM se refieren a datos de texto sin procesar, como registros de chat o artículos, que necesitan ser procesados. Éstas son las entradas principales para la tubería TNT-LLM. Cada documento se estructura utilizando la clase Doc, que incluye campos como id, content, y atributos opcionales como summary, explanation, y category.
Las taxonomías son agrupaciones de intenciones o temas categorizados. Organizan los datos en categorías significativas, lo que es esencial para tareas como el reconocimiento de intenciones y la clasificación de temas. La clase TaxonomyGenerationState define la estructura de estados para la generación de taxonomías. Esta clase incluye documentos en bruto, índices de minilotes y grupos de taxonomías candidatas.
Comprender los aspectos fundamentales de la TNT-LLM es crucial para aplicar eficazmente sus capacidades. Para empezar con TNT-LLM, el proceso de generación de la taxonomía implica varios pasos clave:
En primer lugar, tenemos que definir la clase de estado del grafo TaxonomyGenerationState, que gestiona los aspectos de estado de la generación y evolución de la taxonomía a lo largo de la ejecución del grafo. La clase Doc define la estructura de los documentos individuales dentro del grafo.
import operator
from typing import Annotated, List, TypedDict, Optional
class Doc(TypedDict):
id: str
content: str
summary: Optional[str]
explanation: Optional[str]
category: Optional[str]
class TaxonomyGenerationState(TypedDict):
# The raw docs; we inject summaries within them in the first step
documents: List[Doc]
# Indices to be concise
minibatches: List[List[int]]
# Candidate Taxonomies (full trajectory)
clusters: Annotated[List[List[dict]], operator.add]Antes de iniciar el proceso de generación de taxonomías, necesitamos cargar los conjuntos de datos que contienen datos de texto sin procesar, como artículos de noticias o registros de chat. Estos conjuntos de datos sirven como entrada principal para el TNT-LLM. Aquí estamos cargando artículos de noticias de Cara de abrazo.
import pandas as pd
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("okite97/news-data")
# Access the different splits if available (e.g., train, test, validation)
train_data = dataset['train']
df = pd.DataFrame(train_data)
df = df.dropna()
df.reset_index(drop=True, inplace=True)
def run_to_doc(df: pd.DataFrame) -> Doc:
all_data = []
for i in range(len(df)):
d = df.iloc[i]
all_data.append({
"id": i,
"content": d['Title'] + "\\n\\n" + d['Excerpt']
})
return all_data
# Only clustering 100 documents
docs = run_to_doc(df[:100])
print(docs[0]){'id': 0,
'content': 'Uefa Opens Proceedings against Barcelona, Juventus and Real Madrid Over European Super League Plan\\n\\nUefa has opened disciplinary proceedings against Barcelona, Juventus and Real Madrid over their involvement in the proposed European Super League.'}Por último, inicializamos un Azure-basado en OpenAI GPT-4o para que sirva como modelo lingüístico (LLM) en todos los componentes de TNT-LLM. Aunque en la práctica se pueden inicializar diferentes LLM para cada componente, simplificamos utilizando un único modelo para todas las tareas.
import os
from langchain_openai import AzureChatOpenAI
model = AzureChatOpenAI(
openai_api_version="2023-06-01-preview"
azure_deployment="gpt-4o-2024-05-13",
temperature=0.0
)Una vez cargados los conjuntos de datos, cada documento se somete a un proceso de resumen. Este paso consiste en utilizar modelos lingüísticos para generar resúmenes concisos que recojan los puntos principales de cada documento. Los resúmenes son cruciales, ya que destilan los textos largos en formas más breves y manejables, conservando la información esencial.
El código proporcionado inicializa una consulta LLM para resumir documentos utilizando TNT-LLM, analizando la salida XML para extraer resúmenes y explicaciones. Establece un canal para mapear el contenido de los documentos, procesarlo por lotes para generar resúmenes, e integra estos resúmenes de nuevo en la estructura de datos del documento original mediante pasos de mapeo y reducción.
import re
import random
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableConfig, RunnableLambda, RunnablePassthrough
summary_prompt = hub.pull("wfh/tnt-llm-summary-generation").partial(
summary_length=20, explanation_length=30
)
def parse_summary(xml_string: str) -> dict:
summary_pattern = r"<summary>(.*?)</summary>"
explanation_pattern = r"<explanation>(.*?)</explanation>"
summary_match = re.search(summary_pattern, xml_string, re.DOTALL)
explanation_match = re.search(explanation_pattern, xml_string, re.DOTALL)
summary = summary_match.group(1).strip() if summary_match else ""
explanation = explanation_match.group(1).strip() if explanation_match else ""
return {"summary": summary, "explanation": explanation}
summary_llm_chain = (
summary_prompt | model | StrOutputParser()
).with_config(run_name="GenerateSummary")
summary_chain = summary_llm_chain | parse_summary
# Input: state
# Output: state and summaries
# Processes docs in parallel
def get_content(state: TaxonomyGenerationState):
docs = state["documents"]
return [{"content": doc["content"]} for doc in docs]
map_step = RunnablePassthrough.assign(
summaries=get_content
| RunnableLambda(func=summary_chain.batch, afunc=summary_chain.abatch)
)
def reduce_summaries(combined: dict) -> TaxonomyGenerationState:
summaries = combined["summaries"]
documents = combined["documents"]
return {
"documents": [
{
"id": doc["id"],
"content": doc["content"],
"summary": summ_info["summary"],
"explanation": summ_info["explanation"],
}
for doc, summ_info in zip(documents, summaries)
]
}
# This is the summary node
map_reduce_chain = map_step | reduce_summariesDespués de resumir, el siguiente paso es organizar los documentos resumidos en minilotes. La Minibatching ayuda a procesar grandes volúmenes de datos de forma más eficaz. Al dividir el conjunto de datos en lotes más pequeños, TNT-LLM puede realizar los cálculos en paralelo, optimizando tanto el tiempo como los recursos informáticos.
def get_minibatches(state: TaxonomyGenerationState, config: RunnableConfig):
batch_size = config["configurable"].get("batch_size", 200)
original = state["documents"]
indices = list(range(len(original)))
random.shuffle(indices)
if len(indices) < batch_size:
# Don't pad needlessly if we can't fill a single batch
return [indices]
num_full_batches = len(indices) // batch_size
batches = [
indices[i * batch_size : (i + 1) * batch_size] for i in range(num_full_batches)
]
leftovers = len(indices) % batch_size
if leftovers:
last_batch = indices[num_full_batches * batch_size :]
elements_to_add = batch_size - leftovers
last_batch += random.sample(indices, elements_to_add)
batches.append(last_batch)
return {
"minibatches": batches,
}Utilizando el primer minilote de documentos resumidos, TNT-LLM inicia el proceso de generación de la taxonomía. Este paso consiste en agrupar las intenciones o temas identificados en los documentos. Analizando el contenido de cada documento, el sistema identifica temas o categorías comunes, sentando las bases iniciales de la taxonomía.
Las dos funciones principales son:
invoke_taxonomy_chain() - Esta función integra los pasos de generación de taxonomías utilizando una cadena basada en LLM (chain) configurada para tareas TNT-LLM. Construye tablas de datos XML (data_table_xml) a partir de resúmenes de documentos y agrupaciones taxonómicas previas. La función invoca la cadena LLM para actualizar la taxonomía basándose en los parámetros de configuración especificados (config ), devolviendo un estado actualizado con los nuevos grupos de taxonomía.generate_taxonomy() - Esta función orquesta la generación de grupos taxonómicos. Invoca invoke_taxonomy_chain con una cadena configurada para la generación de taxonomías (generate_taxonomy_chain) utilizando el minilote inicial de documentos (state["minibatches"][0]). Devuelve el estado actualizado de la taxonomía tras el proceso de generación inicial.from typing import Dict
from langchain_core.runnables import Runnable
def parse_taxa(output_text: str) -> Dict:
"""Extract the taxonomy from the generated output."""
cluster_pattern = r"<cluster>\\s*<id>(.*?)</id>\\s*<name>(.*?)</name>\\s*<description>(.*?)</description>\\s*</cluster>"
cluster_matches = re.findall(cluster_pattern, output_text, re.DOTALL)
clusters = [
{"id": id.strip(), "name": name.strip(), "description": description.strip()}
for id, name, description in cluster_matches
]
return {"clusters": clusters}
def format_docs(docs: List[Doc]) -> str:
xml_table = "\\n"
for doc in docs:
xml_table += f'{doc["summary"]}\\n'
xml_table += ""
return xml_table
def format_taxonomy(clusters):
xml = "\\n"
for label in clusters:
xml += " \\n"
xml += f' {label["id"]}\\n'
xml += f' {label["name"]}\\n'
xml += f' {label["description"]}\\n'
xml += " \\n"
xml += ""
return xml
def invoke_taxonomy_chain(
chain: Runnable,
state: TaxonomyGenerationState,
config: RunnableConfig,
mb_indices: List[int],
) -> TaxonomyGenerationState:
configurable = config["configurable"]
docs = state["documents"]
minibatch = [docs[idx] for idx in mb_indices]
data_table_xml = format_docs(minibatch)
previous_taxonomy = state["clusters"][-1] if state["clusters"] else []
cluster_table_xml = format_taxonomy(previous_taxonomy)
updated_taxonomy = chain.invoke(
{
"data_xml": data_table_xml,
"use_case": configurable["use_case"],
"cluster_table_xml": cluster_table_xml,
"suggestion_length": configurable.get("suggestion_length", 30),
"cluster_name_length": configurable.get("cluster_name_length", 10),
"cluster_description_length": configurable.get(
"cluster_description_length", 30
),
"explanation_length": configurable.get("explanation_length", 20),
"max_num_clusters": configurable.get("max_num_clusters", 25),
}
)
return {
"clusters": [updated_taxonomy["clusters"]],
}Veamos ahora cómo se puede integrar el modelo lingüístico en el proceso de generación de la taxonomía:
# We will share an LLM for each step of the generate -> update -> review cycle
# You may want to consider using Opus or another more powerful model for this
taxonomy_generation_llm = model
## Initial generation
taxonomy_generation_prompt = hub.pull("wfh/tnt-llm-taxonomy-generation").partial(
use_case="Generate the taxonomy that can be used to label the user intent in the conversation.",
)
taxa_gen_llm_chain = (
taxonomy_generation_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="GenerateTaxonomy")
generate_taxonomy_chain = taxa_gen_llm_chain | parse_taxa
def generate_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
return invoke_taxonomy_chain(
generate_taxonomy_chain, state, config, state["minibatches"][0]
)A medida que se procesan los siguientes minilotes, TNT-LLM actualiza y refina iterativamente la taxonomía. Este proceso iterativo permite que la taxonomía evolucione y mejore con el tiempo, incorporando nuevas percepciones y categorías descubiertas en los lotes adicionales de datos. Las actualizaciones de la taxonomía garantizan que siga siendo exhaustiva y refleje todo el conjunto de datos.
taxonomy_update_prompt = hub.pull("wfh/tnt-llm-taxonomy-update")
taxa_update_llm_chain = (
taxonomy_update_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="UpdateTaxonomy")
update_taxonomy_chain = taxa_update_llm_chain | parse_taxa
def update_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
which_mb = len(state["clusters"]) % len(state["minibatches"])
return invoke_taxonomy_chain(
update_taxonomy_chain, state, config, state["minibatches"][which_mb]
)Una vez procesados todos los minilotes y actualizada la taxonomía, el último paso consiste en revisar la taxonomía. Esta revisión es crucial para validar la exactitud y pertinencia de las etiquetas categorizadas. Garantiza que la taxonomía organiza y categoriza eficazmente el conjunto de datos de forma significativa, alineándose con el caso de uso previsto, como el reconocimiento de intenciones o la clasificación de temas.
taxonomy_review_prompt = hub.pull("wfh/tnt-llm-taxonomy-review")
taxa_review_llm_chain = (
taxonomy_review_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="ReviewTaxonomy")
review_taxonomy_chain = taxa_review_llm_chain | parse_taxa
def review_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
batch_size = config["configurable"].get("batch_size", 200)
original = state["documents"]
indices = list(range(len(original)))
random.shuffle(indices)
return invoke_taxonomy_chain(
review_taxonomy_chain, state, config, indices[:batch_size]
)Hasta ahora, los cinco primeros pasos consistían en preparar componentes individuales, como la integración de documentos, la creación de minilotes, la generación de taxonomías, la actualización y la revisión. Ahora, estamos preparados para integrar estos componentes en un canal TNT-LLM cohesionado utilizando un marco StateGraph.
Este grafo orquesta la ejecución secuencial de las tareas: resumir los documentos, generar taxonomías a partir de minilotes, actualizar las taxonomías de forma iterativa y, por último, revisar y validar la taxonomía. Los bordes condicionales garantizan que las taxonomías se actualizan hasta que se procesan todos los minilotes, tras lo cual se revisa la taxonomía final y se finaliza para su uso en tareas de etiquetado.
from langgraph.graph import StateGraph
graph = StateGraph(TaxonomyGenerationState)
graph.add_node("summarize", map_reduce_chain)
graph.add_node("get_minibatches", get_minibatches)
graph.add_node("generate_taxonomy", generate_taxonomy)
graph.add_node("update_taxonomy", update_taxonomy)
graph.add_node("review_taxonomy", review_taxonomy)
graph.add_edge("summarize", "get_minibatches")
graph.add_edge("get_minibatches", "generate_taxonomy")
graph.add_edge("generate_taxonomy", "update_taxonomy")
def should_review(state: TaxonomyGenerationState) -> str:
num_minibatches = len(state["minibatches"])
num_revisions = len(state["clusters"])
if num_revisions < num_minibatches:
return "update_taxonomy"
return "review_taxonomy"
graph.add_conditional_edges(
"update_taxonomy",
should_review,
# Optional (but required for the diagram to be drawn correctly below)
{"update_taxonomy": "update_taxonomy", "review_taxonomy": "review_taxonomy"},
)
graph.set_finish_point("review_taxonomy")
graph.set_entry_point("summarize")
app = graph.compile()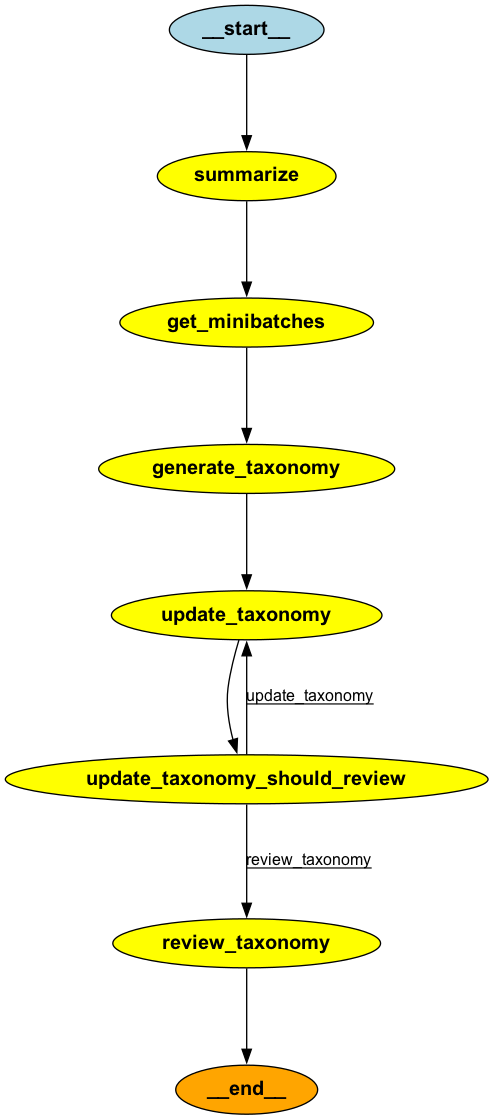
En este último paso, utilizamos TNT-LLM para agrupar artículos de noticias. La taxonomía resultante se muestra en formato Markdown, mostrando los nombres y descripciones de cada clúster.
use_case = (
"Generate the taxonomy that can be used to label the news article that would benefit the user."
)
stream = app.stream(
{"documents": docs},
{
"configurable": {
"use_case": use_case,
# Optional:
"batch_size": 10,
"suggestion_length": 30,
"cluster_name_length": 10,
"cluster_description_length": 30,
"explanation_length": 20,
"max_num_clusters": 25,
},
"max_concurrency": 2,
"recursion_limit": 50,
},
)
for step in stream:
node, state = next(iter(step.items()))
print(node, str(state)[:20] + " ...")
from IPython.display import Markdown
def format_taxonomy_md(clusters):
md = "## Final Taxonomy\\n\\n"
md += "| ID | Name | Description |\\n"
md += "|----|------|-------------|\\n"
# Iterate over each inner list of dictionaries
for cluster_list in clusters:
for label in cluster_list:
id = label["id"]
name = label["name"].replace("|", "\\\\|") # Escape any pipe characters within the content
description = label["description"].replace("|", "\\\\|") # Escape any pipe characters
md += f"| {id} | {name} | {description} |\\n"
return md
markdown_table = format_taxonomy_md(step['review_taxonomy']['clusters'])
Markdown(markdown_table)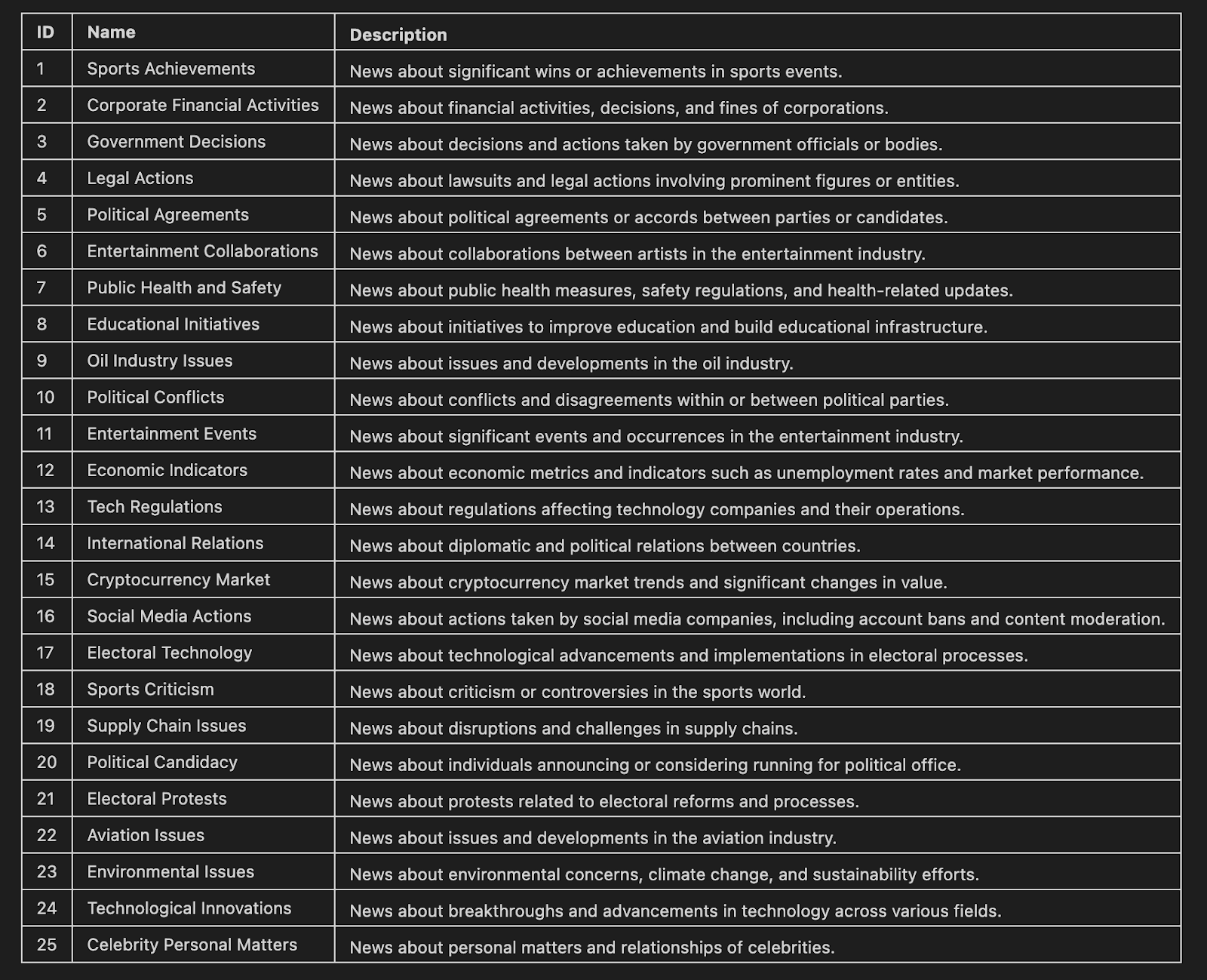
¡Y ahí lo tienes! Siguiendo estos pasos estructurados, TNT-LLM automatizó la creación de taxonomías detalladas e interpretables a partir de datos de texto sin procesar. Este enfoque simplifica lo que tradicionalmente requiere un importante esfuerzo humano y experiencia en el dominio, lo que lo convierte en una potente herramienta para tareas de minería y clasificación de textos a gran escala.
TNT-LLM representa un importante paso adelante en la minería y clasificación de textos, ya que ofrece una solución eficaz para analizar grandes volúmenes de datos no estructurados. Al automatizar la generación de taxonomías y la clasificación escalable, reduce el tiempo y el esfuerzo necesarios para descubrir ideas a partir del texto.
Con la evolución de TNT-LLM, tiene el potencial de transformar la forma en que las organizaciones analizan grandes cantidades de datos de texto. Esta herramienta permite tomar decisiones basadas en datos en todos los sectores, haciendo más accesibles e impactantes las percepciones de los datos textuales.
Si quieres aprender más sobre el desarrollo de aplicaciones LLM, te recomiendo este curso sobre Desarrollo de aplicaciones LLM con LangChain.
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Ryan Ong


