
Course
Building AI Agents with Google ADK
1 hr
6.5K
TNT-LLM (Taxonomy and Text classification using Large Language Models) is a two-phase framework developed to generate and classify taxonomies from text documents. The system has two main phases.
In the first phase, the system takes a sample of text documents and a specific use-case instruction, such as "generate a taxonomy to cluster news articles." It employs a large language model (LLM) to summarize each article, extracting key information. Through an iterative process, the LLM generates, updates, and refines a taxonomy based on these summaries, ultimately producing a structured set of labels and descriptions that effectively categorize the news articles.
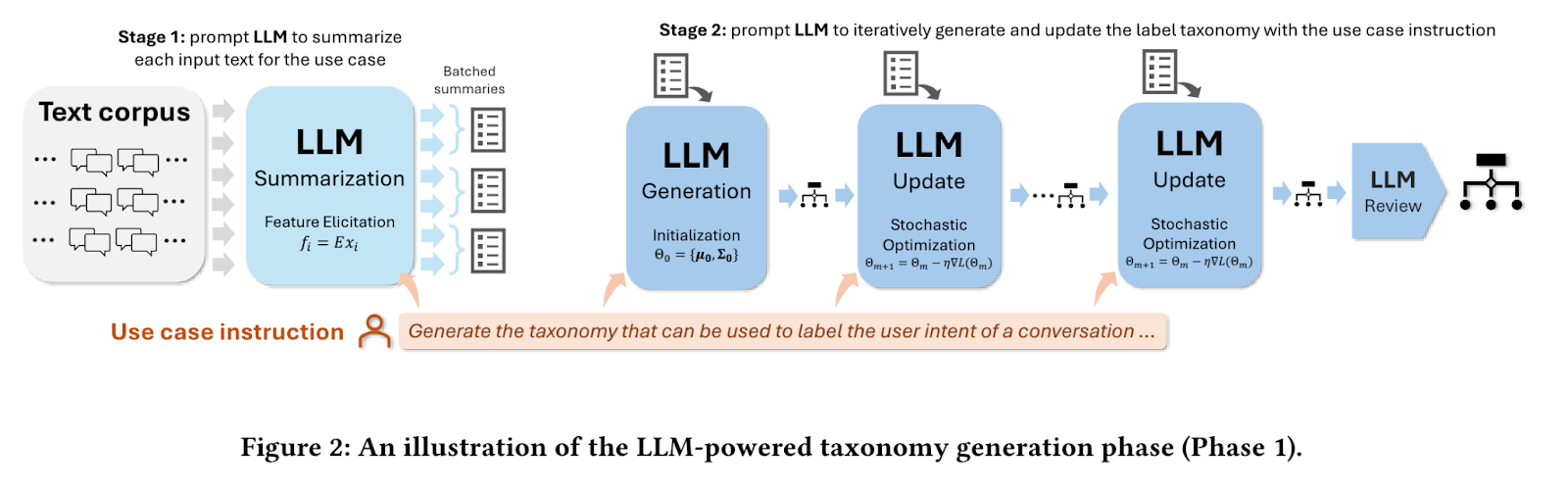
Source: Mengting Wan et al.
The second phase involves using the generated taxonomy to label a larger dataset. The system prompts an LLM to apply these labels, which then serve as training data for a lightweight classifier, such as logistic regression. Once trained, this classifier can be deployed to efficiently label the entire corpus or perform real-time classification.
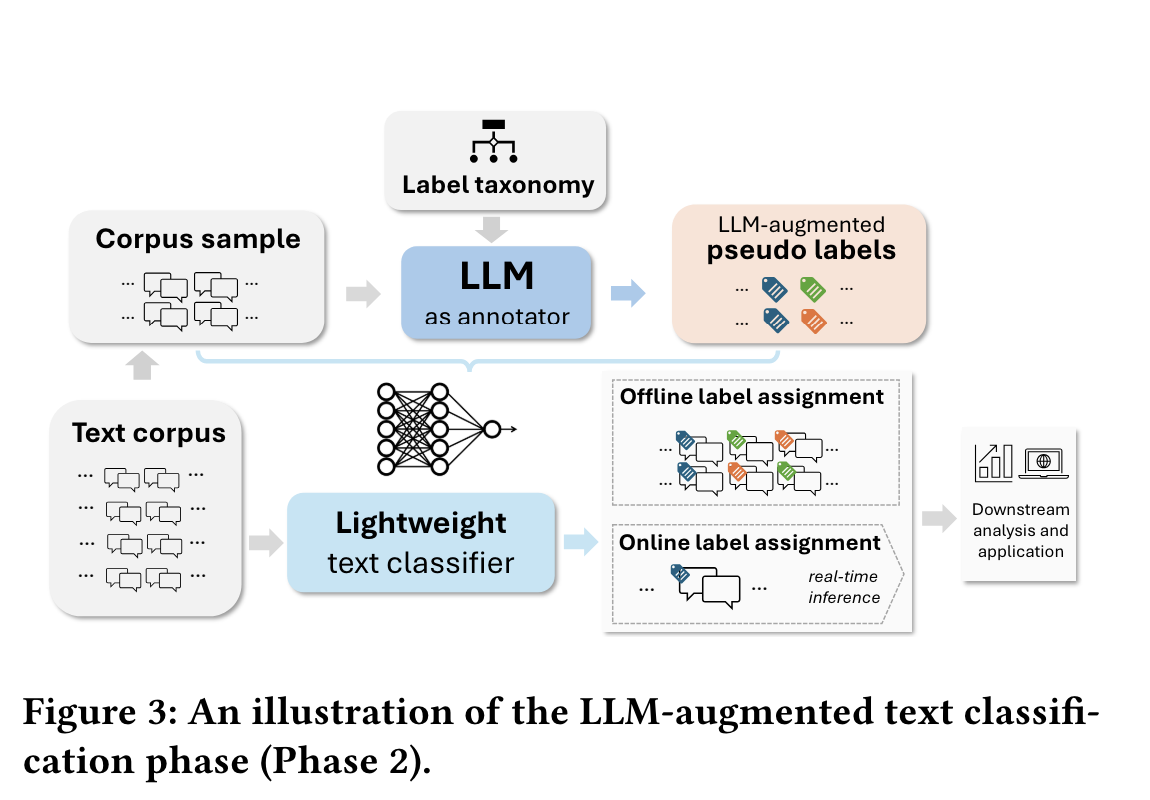
Source: Mengting Wan et al.
TNT-LLM's flexibility makes it applicable to various text classification tasks, including intent detection and topic categorization, extending its utility beyond just conversation analysis.
TNT-LLM stands out as a powerful tool for large-scale text mining and classification, offering several key advantages.
TNT-LLM simplifies the creation of detailed and interpretable taxonomies from raw text data. This process has automated a labor-intensive task that often requires domain expertise. The system generates tailored taxonomies for specific use cases with minimal human input, saving considerable time and resources.
Using the generated taxonomies, TNT-LLM enables scalable text classification. It enables the creation of lightweight models that can handle large datasets or real-time classification tasks efficiently, making it ideal for applications with high throughput requirements.
TNT-LLM optimizes resource usage by leveraging tiered LLM utilization. It employs powerful models like GPT-4 for taxonomy generation and more economical options such as GPT-3.5-Turbo for summarization tasks. Final classification is performed by an efficient logistic regression model, further reducing operational costs.
The iterative taxonomy generation process of TNT-LLM ensures continuous refinement, resulting in high-quality, relevant, and accurate categorizations tailored to specific datasets and use cases.
While allowing for human review and adjustments, TNT-LLM requires minimal manual input compared to traditional methods. This reduces potential biases and inconsistencies in taxonomy creation.
TNT-LLM adapts well to various text classification tasks and domains, offering versatility in application. Its modular design supports integration with different LLMs, embedding methods, and classifiers as needed.
Overall, TNT-LLM provides a robust solution for organizations dealing with large amounts of unstructured text data.
Let’s walk through the implementation process step-by-step.
To get started with TNT-LLM implementations, you need to install the necessary packages. You can do this using the following pip command:
pip install langgraph langchain langchain_openaiAdditionally, set your environment variables for API keys and model names:
export AZURE_OPENAI_API_KEY='your_api_key_here' export AZURE_OPENAI_MODEL='your_deployment_name_here' export AZURE_OPENAI_ENDPOINT='deployment_endpoint'In the context of TNT-LLM, understanding a few fundamental concepts is crucial for leveraging its capabilities effectively.
Documents in TNT-LLM refer to raw text data, such as chat logs or articles, that need to be processed. These are the primary inputs for the TNT-LLM pipeline. Each document is structured using the Doc class, which includes fields such as id, content, and optional attributes like summary, explanation, and category.
Taxonomies are clusters of categorized intents or topics. They organize the data into meaningful categories, which is essential for tasks like intent recognition and topic classification. The TaxonomyGenerationState class defines the state structure for taxonomy generation. This class includes raw documents, minibatch indices, and clusters of candidate taxonomies.
Understanding the foundational aspects of TNT-LLM is crucial for effectively implementing its capabilities. To begin with TNT-LLM, the taxonomy generation process involves several key steps:
Firstly, we need to define the graph state class TaxonomyGenerationState, which manages the stateful aspects of taxonomy generation and evolution throughout the graph's execution. The Doc class defines the structure for individual documents within the graph.
import operator
from typing import Annotated, List, TypedDict, Optional
class Doc(TypedDict):
id: str
content: str
summary: Optional[str]
explanation: Optional[str]
category: Optional[str]
class TaxonomyGenerationState(TypedDict):
# The raw docs; we inject summaries within them in the first step
documents: List[Doc]
# Indices to be concise
minibatches: List[List[int]]
# Candidate Taxonomies (full trajectory)
clusters: Annotated[List[List[dict]], operator.add]Before starting the taxonomy generation process, we need to load the datasets containing raw text data, such as news articles or chat logs. These datasets serve as the primary input for TNT-LLM. Here, we are loading news articles from Hugging Face.
import pandas as pd
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("okite97/news-data")
# Access the different splits if available (e.g., train, test, validation)
train_data = dataset['train']
df = pd.DataFrame(train_data)
df = df.dropna()
df.reset_index(drop=True, inplace=True)
def run_to_doc(df: pd.DataFrame) -> Doc:
all_data = []
for i in range(len(df)):
d = df.iloc[i]
all_data.append({
"id": i,
"content": d['Title'] + "\\n\\n" + d['Excerpt']
})
return all_data
# Only clustering 100 documents
docs = run_to_doc(df[:100])
print(docs[0]){'id': 0,
'content': 'Uefa Opens Proceedings against Barcelona, Juventus and Real Madrid Over European Super League Plan\\n\\nUefa has opened disciplinary proceedings against Barcelona, Juventus and Real Madrid over their involvement in the proposed European Super League.'}Finally, we initialize an Azure-based OpenAI GPT-4o model to serve as our language model (LLM) across all components of TNT-LLM. While different LLMs can be initialized for each component in practice, we simplify by using a single model for all tasks.
import os
from langchain_openai import AzureChatOpenAI
model = AzureChatOpenAI(
openai_api_version="2023-06-01-preview"
azure_deployment="gpt-4o-2024-05-13",
temperature=0.0
)Once the datasets are loaded, each document undergoes summarization. This step involves using language models to generate concise summaries that capture the main points of each document. The summaries are crucial as they distill lengthy texts into shorter, more manageable forms while retaining essential information.
The provided code initializes an LLM prompt for summarizing documents using TNT-LLM, parsing XML output to extract summaries and explanations. It sets up a pipeline to map document content, process it in batches for summary generation, and integrates these summaries back into the original document data structure using mapping and reduction steps.
import re
import random
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableConfig, RunnableLambda, RunnablePassthrough
summary_prompt = hub.pull("wfh/tnt-llm-summary-generation").partial(
summary_length=20, explanation_length=30
)
def parse_summary(xml_string: str) -> dict:
summary_pattern = r"<summary>(.*?)</summary>"
explanation_pattern = r"<explanation>(.*?)</explanation>"
summary_match = re.search(summary_pattern, xml_string, re.DOTALL)
explanation_match = re.search(explanation_pattern, xml_string, re.DOTALL)
summary = summary_match.group(1).strip() if summary_match else ""
explanation = explanation_match.group(1).strip() if explanation_match else ""
return {"summary": summary, "explanation": explanation}
summary_llm_chain = (
summary_prompt | model | StrOutputParser()
).with_config(run_name="GenerateSummary")
summary_chain = summary_llm_chain | parse_summary
# Input: state
# Output: state and summaries
# Processes docs in parallel
def get_content(state: TaxonomyGenerationState):
docs = state["documents"]
return [{"content": doc["content"]} for doc in docs]
map_step = RunnablePassthrough.assign(
summaries=get_content
| RunnableLambda(func=summary_chain.batch, afunc=summary_chain.abatch)
)
def reduce_summaries(combined: dict) -> TaxonomyGenerationState:
summaries = combined["summaries"]
documents = combined["documents"]
return {
"documents": [
{
"id": doc["id"],
"content": doc["content"],
"summary": summ_info["summary"],
"explanation": summ_info["explanation"],
}
for doc, summ_info in zip(documents, summaries)
]
}
# This is the summary node
map_reduce_chain = map_step | reduce_summariesAfter summarization, the next step is to organize the summarized documents into minibatches. Minibatching helps in processing large volumes of data more efficiently. By dividing the dataset into smaller batches, TNT-LLM can handle computations in parallel, optimizing both time and computational resources.
def get_minibatches(state: TaxonomyGenerationState, config: RunnableConfig):
batch_size = config["configurable"].get("batch_size", 200)
original = state["documents"]
indices = list(range(len(original)))
random.shuffle(indices)
if len(indices) < batch_size:
# Don't pad needlessly if we can't fill a single batch
return [indices]
num_full_batches = len(indices) // batch_size
batches = [
indices[i * batch_size : (i + 1) * batch_size] for i in range(num_full_batches)
]
leftovers = len(indices) % batch_size
if leftovers:
last_batch = indices[num_full_batches * batch_size :]
elements_to_add = batch_size - leftovers
last_batch += random.sample(indices, elements_to_add)
batches.append(last_batch)
return {
"minibatches": batches,
}Using the first minibatch of summarized documents, TNT-LLM starts the taxonomy generation process. This step involves clustering intents or topics identified within the documents. By analyzing the content of each document, the system identifies common themes or categories, laying the initial foundation of the taxonomy.
The two main functions are:
invoke_taxonomy_chain() - This function integrates taxonomy generation steps using an LLM-based chain (chain) configured for TNT-LLM tasks. It constructs XML data tables (data_table_xml) from document summaries and previous taxonomy clusters. The function invokes the LLM chain to update taxonomy based on specified configuration parameters (config), returning an updated state with new taxonomy clusters.generate_taxonomy() - This function orchestrates the generation of taxonomy clusters. It invokes invoke_taxonomy_chain with a chain configured for taxonomy generation (generate_taxonomy_chain) using the initial minibatch of documents (state["minibatches"][0]). It returns the updated taxonomy state after the initial generation process.from typing import Dict
from langchain_core.runnables import Runnable
def parse_taxa(output_text: str) -> Dict:
"""Extract the taxonomy from the generated output."""
cluster_pattern = r"<cluster>\\s*<id>(.*?)</id>\\s*<name>(.*?)</name>\\s*<description>(.*?)</description>\\s*</cluster>"
cluster_matches = re.findall(cluster_pattern, output_text, re.DOTALL)
clusters = [
{"id": id.strip(), "name": name.strip(), "description": description.strip()}
for id, name, description in cluster_matches
]
return {"clusters": clusters}
def format_docs(docs: List[Doc]) -> str:
xml_table = "\\n"
for doc in docs:
xml_table += f'{doc["summary"]}\\n'
xml_table += ""
return xml_table
def format_taxonomy(clusters):
xml = "\\n"
for label in clusters:
xml += " \\n"
xml += f' {label["id"]}\\n'
xml += f' {label["name"]}\\n'
xml += f' {label["description"]}\\n'
xml += " \\n"
xml += ""
return xml
def invoke_taxonomy_chain(
chain: Runnable,
state: TaxonomyGenerationState,
config: RunnableConfig,
mb_indices: List[int],
) -> TaxonomyGenerationState:
configurable = config["configurable"]
docs = state["documents"]
minibatch = [docs[idx] for idx in mb_indices]
data_table_xml = format_docs(minibatch)
previous_taxonomy = state["clusters"][-1] if state["clusters"] else []
cluster_table_xml = format_taxonomy(previous_taxonomy)
updated_taxonomy = chain.invoke(
{
"data_xml": data_table_xml,
"use_case": configurable["use_case"],
"cluster_table_xml": cluster_table_xml,
"suggestion_length": configurable.get("suggestion_length", 30),
"cluster_name_length": configurable.get("cluster_name_length", 10),
"cluster_description_length": configurable.get(
"cluster_description_length", 30
),
"explanation_length": configurable.get("explanation_length", 20),
"max_num_clusters": configurable.get("max_num_clusters", 25),
}
)
return {
"clusters": [updated_taxonomy["clusters"]],
}Now, let’s see how the language model can be integrated into the taxonomy generation process:
# We will share an LLM for each step of the generate -> update -> review cycle
# You may want to consider using Opus or another more powerful model for this
taxonomy_generation_llm = model
## Initial generation
taxonomy_generation_prompt = hub.pull("wfh/tnt-llm-taxonomy-generation").partial(
use_case="Generate the taxonomy that can be used to label the user intent in the conversation.",
)
taxa_gen_llm_chain = (
taxonomy_generation_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="GenerateTaxonomy")
generate_taxonomy_chain = taxa_gen_llm_chain | parse_taxa
def generate_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
return invoke_taxonomy_chain(
generate_taxonomy_chain, state, config, state["minibatches"][0]
)As subsequent minibatches are processed, TNT-LLM iteratively updates and refines the taxonomy. This iterative process allows the taxonomy to evolve and improve over time, incorporating new insights and categories discovered in the additional batches of data. Updates to the taxonomy ensure that it remains comprehensive and reflects the entire dataset.
taxonomy_update_prompt = hub.pull("wfh/tnt-llm-taxonomy-update")
taxa_update_llm_chain = (
taxonomy_update_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="UpdateTaxonomy")
update_taxonomy_chain = taxa_update_llm_chain | parse_taxa
def update_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
which_mb = len(state["clusters"]) % len(state["minibatches"])
return invoke_taxonomy_chain(
update_taxonomy_chain, state, config, state["minibatches"][which_mb]
)Once all minibatches have been processed and the taxonomy has been updated, the final step involves reviewing the taxonomy. This review is crucial to validate the accuracy and relevance of the categorized labels. It ensures that the taxonomy effectively organizes and categorizes the dataset in a meaningful way, aligning with the intended use case such as intent recognition or topic classification.
taxonomy_review_prompt = hub.pull("wfh/tnt-llm-taxonomy-review")
taxa_review_llm_chain = (
taxonomy_review_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="ReviewTaxonomy")
review_taxonomy_chain = taxa_review_llm_chain | parse_taxa
def review_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
batch_size = config["configurable"].get("batch_size", 200)
original = state["documents"]
indices = list(range(len(original)))
random.shuffle(indices)
return invoke_taxonomy_chain(
review_taxonomy_chain, state, config, indices[:batch_size]
)So far, the first five steps involved preparing individual components such as document summarization, minibatch creation, taxonomy generation, updating, and reviewing. Now, we are ready to integrate these components into a cohesive TNT-LLM pipeline using a StateGraph framework.
This graph orchestrates the sequential execution of tasks: summarizing documents, generating taxonomies from minibatches, updating taxonomies iteratively, and finally reviewing and validating the taxonomy. Conditional edges ensure that taxonomies are updated until all minibatches are processed, after which the final taxonomy is reviewed and finalized for use in labeling tasks.
from langgraph.graph import StateGraph
graph = StateGraph(TaxonomyGenerationState)
graph.add_node("summarize", map_reduce_chain)
graph.add_node("get_minibatches", get_minibatches)
graph.add_node("generate_taxonomy", generate_taxonomy)
graph.add_node("update_taxonomy", update_taxonomy)
graph.add_node("review_taxonomy", review_taxonomy)
graph.add_edge("summarize", "get_minibatches")
graph.add_edge("get_minibatches", "generate_taxonomy")
graph.add_edge("generate_taxonomy", "update_taxonomy")
def should_review(state: TaxonomyGenerationState) -> str:
num_minibatches = len(state["minibatches"])
num_revisions = len(state["clusters"])
if num_revisions < num_minibatches:
return "update_taxonomy"
return "review_taxonomy"
graph.add_conditional_edges(
"update_taxonomy",
should_review,
# Optional (but required for the diagram to be drawn correctly below)
{"update_taxonomy": "update_taxonomy", "review_taxonomy": "review_taxonomy"},
)
graph.set_finish_point("review_taxonomy")
graph.set_entry_point("summarize")
app = graph.compile()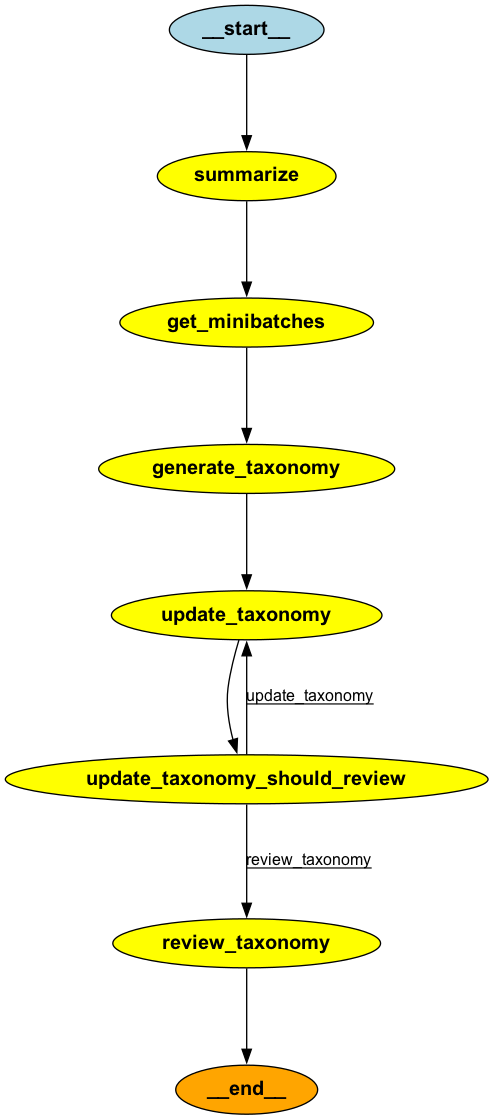
In this final step, we utilize TNT-LLM to cluster news articles. The resulting taxonomy is displayed in a Markdown format, showcasing the names and descriptions of each cluster.
use_case = (
"Generate the taxonomy that can be used to label the news article that would benefit the user."
)
stream = app.stream(
{"documents": docs},
{
"configurable": {
"use_case": use_case,
# Optional:
"batch_size": 10,
"suggestion_length": 30,
"cluster_name_length": 10,
"cluster_description_length": 30,
"explanation_length": 20,
"max_num_clusters": 25,
},
"max_concurrency": 2,
"recursion_limit": 50,
},
)
for step in stream:
node, state = next(iter(step.items()))
print(node, str(state)[:20] + " ...")
from IPython.display import Markdown
def format_taxonomy_md(clusters):
md = "## Final Taxonomy\\n\\n"
md += "| ID | Name | Description |\\n"
md += "|----|------|-------------|\\n"
# Iterate over each inner list of dictionaries
for cluster_list in clusters:
for label in cluster_list:
id = label["id"]
name = label["name"].replace("|", "\\\\|") # Escape any pipe characters within the content
description = label["description"].replace("|", "\\\\|") # Escape any pipe characters
md += f"| {id} | {name} | {description} |\\n"
return md
markdown_table = format_taxonomy_md(step['review_taxonomy']['clusters'])
Markdown(markdown_table)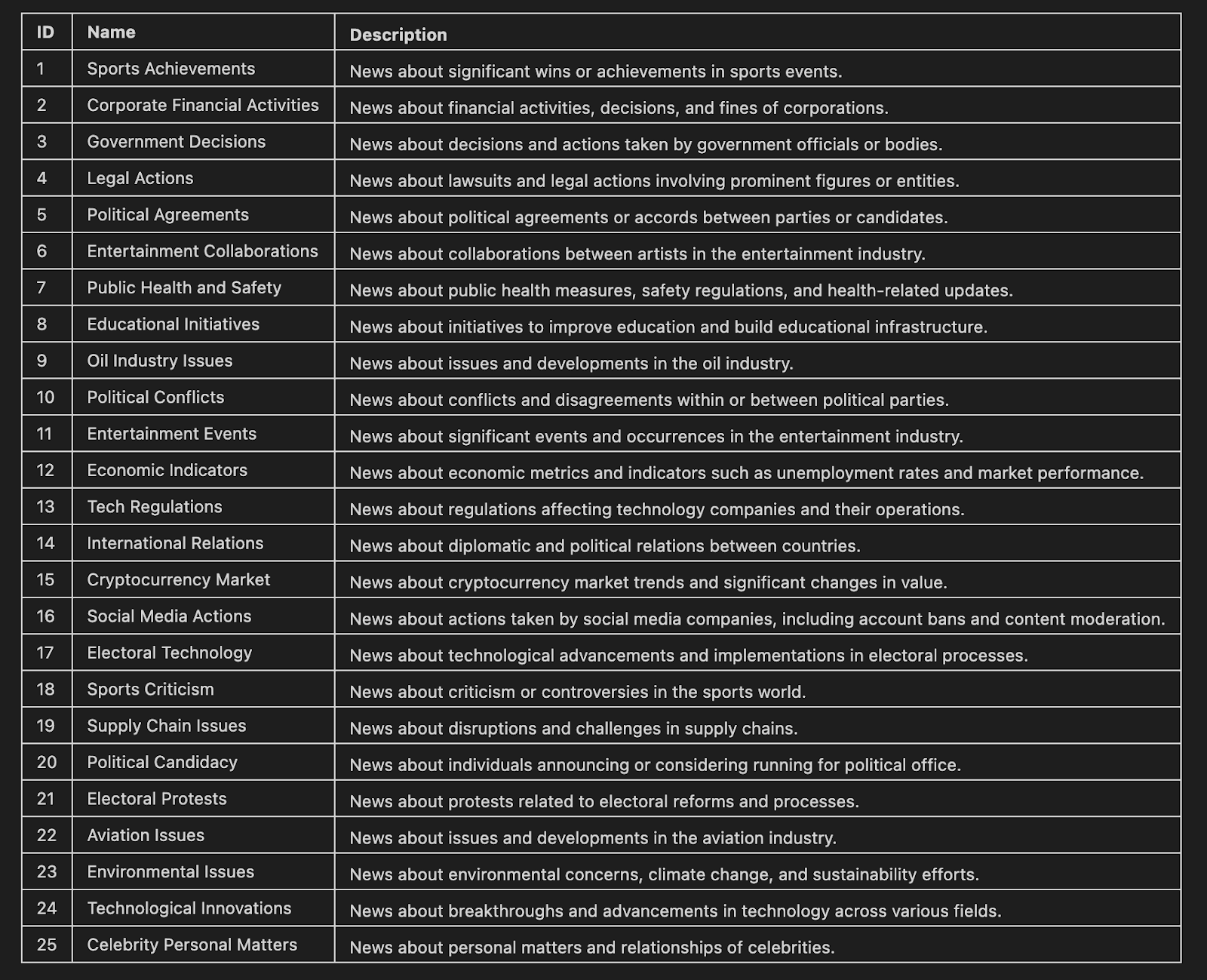
And there you have it! By following these structured steps, TNT-LLM automated the creation of detailed and interpretable taxonomies from raw text data. This approach simplifies what traditionally requires significant human effort and domain expertise, making it a powerful tool for large-scale text mining and classification tasks.
TNT-LLM represents a significant step forward in text mining and classification, offering an efficient solution for analyzing large volumes of unstructured data. By automating taxonomy generation and scalable classification, it reduces the time and effort needed to uncover insights from text.
With TNT-LLM evolves, it has the potential to transform how organizations analyze vast amounts of text data. This tool enables data-driven decision-making across industries, making insights from textual data more accessible and impactful.
If you want to learn more about developing LLM applications, I recommend this course on Developing LLM Applications with LangChain.
Learn AI with these courses!
Course
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Andrea Valenzuela
code-along
Emmanuel Pire
code-along
Richie Cotton
code-along
Andrea Valenzuela




