Curso
Implementação de Soluções de IA nos Negócios
2 h
51.7K
A Microsoft apresentou o TNT-LLM, um sistema avançado projetado para automatizar a geração de taxonomia e a classificação de textos, superando os métodos tradicionais em termos de eficiência e precisão.
O TNT-LLM aproveita o poder dos grandes modelos de linguagem (LLMs) para automatizar e dimensionar a criação de taxonomias e classificadores com o mínimo de intervenção humana. Isso o torna particularmente útil para aplicativos como o Bing Copilot, em que o gerenciamento de domínios textuais diversos e em evolução é crucial.
Neste artigo, orientarei você na implementação do TNT-LLM usando GPT-4o e LangGraph para agrupar artigos de notícias de forma eficaz.
Se você quiser ler mais sobre o GPT-4o ou o LangGraph, recomendo estes artigos:
Se você quiser saber mais sobre o TNT-LLM, recomendo o artigo original TnT-LLM: Mineração de texto em escala com grandes modelos de linguagem.
O TNT-LLM (Taxonomy and Text classification using Large Language Models) é uma estrutura de duas fases desenvolvida para gerar e classificar taxonomias a partir de documentos de texto. O sistema tem duas fases principais.
Na primeira fase, o sistema recebe uma amostra de documentos de texto e uma instrução de caso de uso específico, como "gerar uma taxonomia para agrupar artigos de notícias". Ele emprega um modelo de linguagem ampla (LLM) para resumir cada artigo, extraindo as principais informações. Por meio de um processo iterativo, o LLM gera, atualiza e refina uma taxonomia com base nesses resumos, produzindo, por fim, um conjunto estruturado de rótulos e descrições que categorizam efetivamente os artigos de notícias.
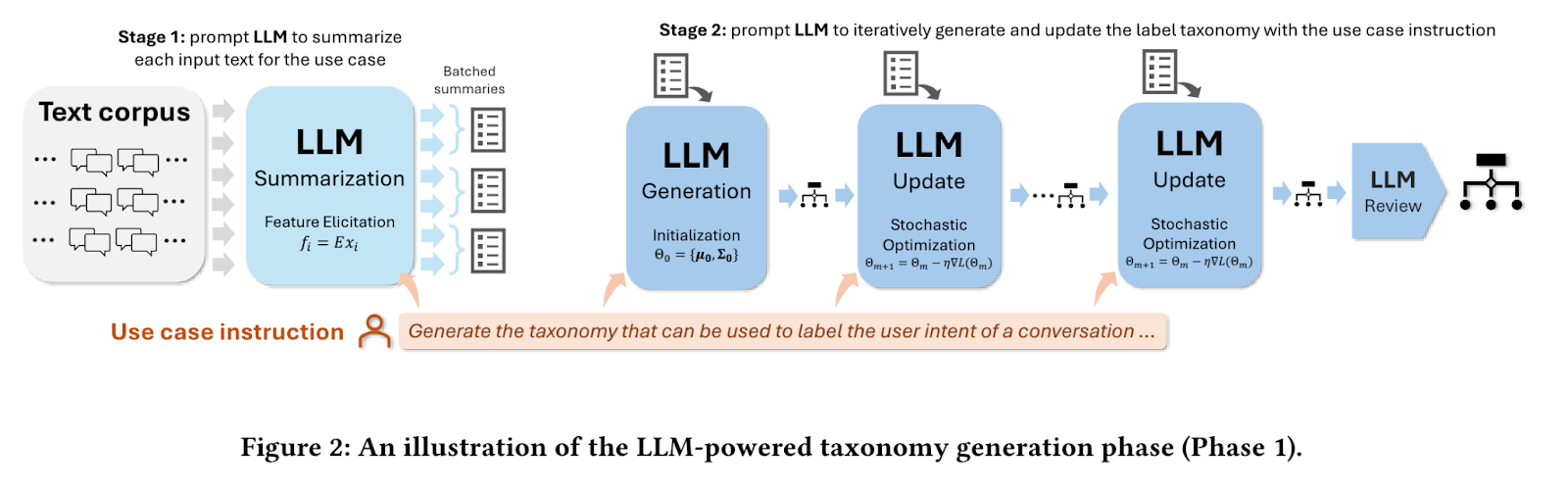
Fonte: Mengting Wan et al.
A segunda fase envolve o uso da taxonomia gerada para rotular um conjunto de dados maior. O sistema solicita que um LLM aplique esses rótulos, que servem como dados de treinamento para um classificador leve, como a regressão logística. Depois de treinado, esse classificador pode ser implantado para rotular com eficiência todo o corpus ou realizar a classificação em tempo real.
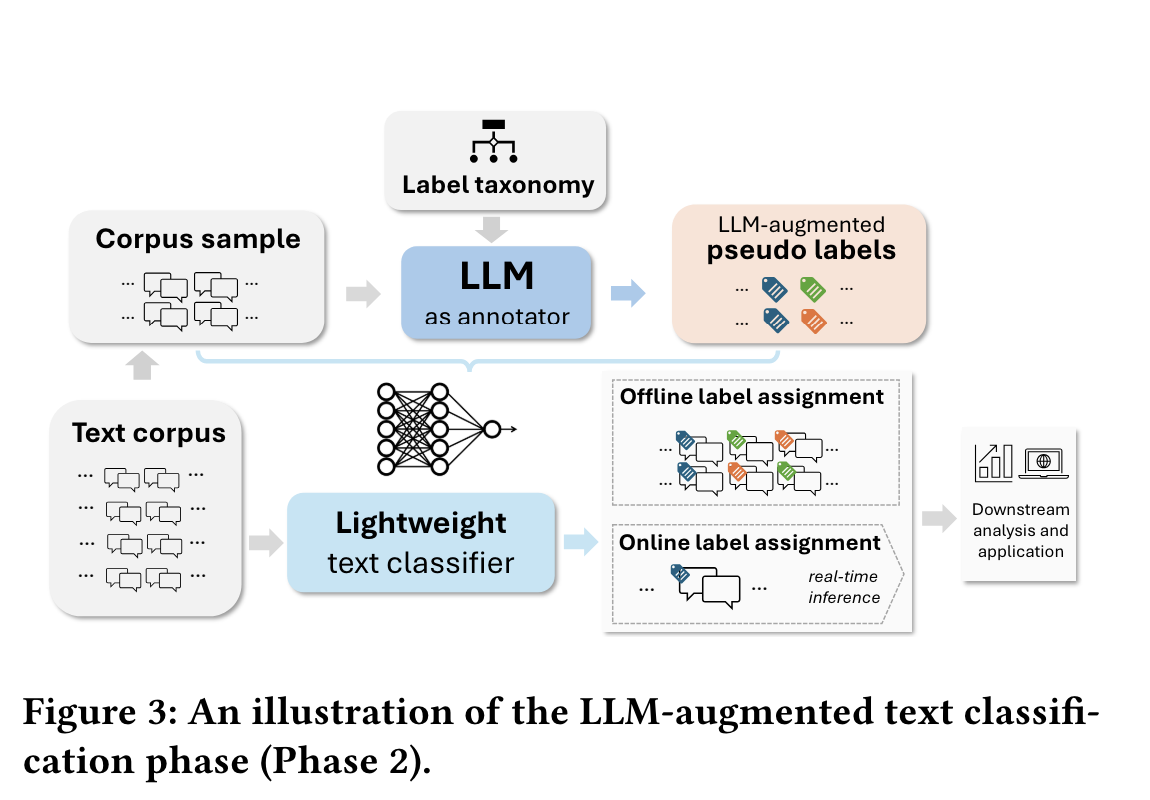
Fonte: Mengting Wan et al.
A flexibilidade do TNT-LLM o torna aplicável a várias tarefas de classificação de texto, incluindo detecção de intenção e categorização de tópicos, ampliando sua utilidade para além da análise de conversas.
O TNT-LLM se destaca como uma ferramenta avançada para mineração e classificação de textos em grande escala, oferecendo várias vantagens importantes.
O TNT-LLM simplifica a criação de taxonomias detalhadas e interpretáveis a partir de dados de texto bruto. Esse processo automatizou uma tarefa trabalhosa que, muitas vezes, exige conhecimento especializado no domínio. O sistema gera taxonomias personalizadas para casos de uso específicos com o mínimo de intervenção humana, economizando tempo e recursos consideráveis.
Usando as taxonomias geradas, o TNT-LLM permite a classificação de textos em escala. Ele permite a criação de modelos leves que podem lidar com grandes conjuntos de dados ou tarefas de classificação em tempo real de forma eficiente, tornando-o ideal para aplicativos com requisitos de alta produtividade.
O TNT-LLM otimiza o uso de recursos ao aproveitar a utilização do LLM em camadas. Ele emprega modelos avançados como o GPT-4 para geração de taxonomia e opções mais econômicas como o GPT-3.5-Turbo para tarefas de resumo. A classificação final é realizada por um modelo de regressão logística eficiente, reduzindo ainda mais os custos operacionais.
O processo iterativo de geração de taxonomia do TNT-LLM garante um refinamento contínuo, resultando em categorizações de alta qualidade, relevantes e precisas, adaptadas a conjuntos de dados e casos de uso específicos.
Ao mesmo tempo em que permite a revisão e os ajustes humanos, o TNT-LLM requer um mínimo de entrada manual em comparação com os métodos tradicionais. Isso reduz possíveis vieses e inconsistências na criação da taxonomia.
O TNT-LLM se adapta bem a várias tarefas e domínios de classificação de texto, oferecendo versatilidade na aplicação. Seu design modular permite a integração com diferentes LLMs, métodos de incorporação e classificadores, conforme necessário.
Em geral, o TNT-LLM oferece uma solução robusta para organizações que lidam com grandes quantidades de dados de texto não estruturados.
Vamos examinar o processo de implementação passo a passo.
Para começar a usar as implementações do TNT-LLM, você precisa instalar os pacotes necessários. Você pode fazer isso usando o seguinte comando pip:
pip install langgraph langchain langchain_openaiAlém disso, defina suas variáveis de ambiente para chaves de API e nomes de modelos:
export AZURE_OPENAI_API_KEY='your_api_key_here' export AZURE_OPENAI_MODEL='your_deployment_name_here' export AZURE_OPENAI_ENDPOINT='deployment_endpoint'No contexto do TNT-LLM, a compreensão de alguns conceitos fundamentais é crucial para aproveitar seus recursos de forma eficaz.
Os documentos no TNT-LLM referem-se a dados de texto bruto, como registros de bate-papo ou artigos, que precisam ser processados. Essas são as principais entradas para o pipeline TNT-LLM. Cada documento é estruturado usando a classe Doc, que inclui campos como id, content, e atributos opcionais como summary, explanation, e category.
As taxonomias são grupos de intenções ou tópicos categorizados. Eles organizam os dados em categorias significativas, o que é essencial para tarefas como reconhecimento de intenções e classificação de tópicos. A classe TaxonomyGenerationState define a estrutura de estado para a geração de taxonomia. Essa classe inclui documentos brutos, índices de minilotes e clusters de taxonomias candidatas.
Compreender os aspectos fundamentais da TNT-LLM é fundamental para a implementação eficaz de seus recursos. Para começar com o TNT-LLM, o processo de geração de taxonomia envolve várias etapas importantes:
Em primeiro lugar, precisamos definir a classe de estado do gráfico TaxonomyGenerationState, que gerencia os aspectos de estado da geração e evolução da taxonomia durante a execução do gráfico. A classe Doc define a estrutura de documentos individuais no gráfico.
import operator
from typing import Annotated, List, TypedDict, Optional
class Doc(TypedDict):
id: str
content: str
summary: Optional[str]
explanation: Optional[str]
category: Optional[str]
class TaxonomyGenerationState(TypedDict):
# The raw docs; we inject summaries within them in the first step
documents: List[Doc]
# Indices to be concise
minibatches: List[List[int]]
# Candidate Taxonomies (full trajectory)
clusters: Annotated[List[List[dict]], operator.add]Antes de iniciar o processo de geração de taxonomia, precisamos carregar os conjuntos de dados que contêm dados de texto bruto, como artigos de notícias ou registros de bate-papo. Esses conjuntos de dados servem como a principal entrada para o TNT-LLM. Aqui, estamos carregando artigos de notícias da Hugging Face.
import pandas as pd
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("okite97/news-data")
# Access the different splits if available (e.g., train, test, validation)
train_data = dataset['train']
df = pd.DataFrame(train_data)
df = df.dropna()
df.reset_index(drop=True, inplace=True)
def run_to_doc(df: pd.DataFrame) -> Doc:
all_data = []
for i in range(len(df)):
d = df.iloc[i]
all_data.append({
"id": i,
"content": d['Title'] + "\\n\\n" + d['Excerpt']
})
return all_data
# Only clustering 100 documents
docs = run_to_doc(df[:100])
print(docs[0]){'id': 0,
'content': 'Uefa Opens Proceedings against Barcelona, Juventus and Real Madrid Over European Super League Plan\\n\\nUefa has opened disciplinary proceedings against Barcelona, Juventus and Real Madrid over their involvement in the proposed European Super League.'}Por fim, inicializamos um arquivo Azure-baseado no OpenAI GPT-4o para servir como nosso modelo de linguagem (LLM) em todos os componentes do TNT-LLM. Embora LLMs diferentes possam ser inicializados para cada componente na prática, simplificamos usando um único modelo para todas as tarefas.
import os
from langchain_openai import AzureChatOpenAI
model = AzureChatOpenAI(
openai_api_version="2023-06-01-preview"
azure_deployment="gpt-4o-2024-05-13",
temperature=0.0
)Depois que os conjuntos de dados são carregados, cada documento é resumido. Essa etapa envolve o uso de modelos de linguagem para gerar resumos concisos que capturam os pontos principais de cada documento. Os resumos são cruciais, pois destilam textos extensos em formas mais curtas e gerenciáveis, mantendo as informações essenciais.
O código fornecido inicializa um prompt LLM para resumir documentos usando o TNT-LLM, analisando a saída XML para extrair resumos e explicações. Ele configura um pipeline para mapear o conteúdo do documento, processá-lo em lotes para a geração de resumos e integra esses resumos de volta à estrutura de dados do documento original usando etapas de mapeamento e redução.
import re
import random
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableConfig, RunnableLambda, RunnablePassthrough
summary_prompt = hub.pull("wfh/tnt-llm-summary-generation").partial(
summary_length=20, explanation_length=30
)
def parse_summary(xml_string: str) -> dict:
summary_pattern = r"<summary>(.*?)</summary>"
explanation_pattern = r"<explanation>(.*?)</explanation>"
summary_match = re.search(summary_pattern, xml_string, re.DOTALL)
explanation_match = re.search(explanation_pattern, xml_string, re.DOTALL)
summary = summary_match.group(1).strip() if summary_match else ""
explanation = explanation_match.group(1).strip() if explanation_match else ""
return {"summary": summary, "explanation": explanation}
summary_llm_chain = (
summary_prompt | model | StrOutputParser()
).with_config(run_name="GenerateSummary")
summary_chain = summary_llm_chain | parse_summary
# Input: state
# Output: state and summaries
# Processes docs in parallel
def get_content(state: TaxonomyGenerationState):
docs = state["documents"]
return [{"content": doc["content"]} for doc in docs]
map_step = RunnablePassthrough.assign(
summaries=get_content
| RunnableLambda(func=summary_chain.batch, afunc=summary_chain.abatch)
)
def reduce_summaries(combined: dict) -> TaxonomyGenerationState:
summaries = combined["summaries"]
documents = combined["documents"]
return {
"documents": [
{
"id": doc["id"],
"content": doc["content"],
"summary": summ_info["summary"],
"explanation": summ_info["explanation"],
}
for doc, summ_info in zip(documents, summaries)
]
}
# This is the summary node
map_reduce_chain = map_step | reduce_summariesApós o resumo, a próxima etapa é organizar os documentos resumidos em minibatches. O minibatching ajuda a processar grandes volumes de dados com mais eficiência. Ao dividir o conjunto de dados em lotes menores, o TNT-LLM pode lidar com cálculos em paralelo, otimizando o tempo e os recursos computacionais.
def get_minibatches(state: TaxonomyGenerationState, config: RunnableConfig):
batch_size = config["configurable"].get("batch_size", 200)
original = state["documents"]
indices = list(range(len(original)))
random.shuffle(indices)
if len(indices) < batch_size:
# Don't pad needlessly if we can't fill a single batch
return [indices]
num_full_batches = len(indices) // batch_size
batches = [
indices[i * batch_size : (i + 1) * batch_size] for i in range(num_full_batches)
]
leftovers = len(indices) % batch_size
if leftovers:
last_batch = indices[num_full_batches * batch_size :]
elements_to_add = batch_size - leftovers
last_batch += random.sample(indices, elements_to_add)
batches.append(last_batch)
return {
"minibatches": batches,
}Usando o primeiro minilote de documentos resumidos, o TNT-LLM inicia o processo de geração de taxonomia. Essa etapa envolve o agrupamento de intenções ou tópicos identificados nos documentos. Ao analisar o conteúdo de cada documento, o sistema identifica temas ou categorias comuns, estabelecendo a base inicial da taxonomia.
As duas principais funções são:
invoke_taxonomy_chain() - Essa função integra as etapas de geração de taxonomia usando uma cadeia baseada em LLM (chain) configurada para tarefas TNT-LLM. Ele constrói tabelas de dados XML (data_table_xml) a partir de resumos de documentos e clusters de taxonomia anteriores. A função invoca a cadeia LLM para atualizar a taxonomia com base nos parâmetros de configuração especificados (config ), retornando um estado atualizado com novos clusters de taxonomia.generate_taxonomy() - Essa função orquestra a geração de clusters de taxonomia. Você invoca invoke_taxonomy_chain com uma cadeia configurada para geração de taxonomia (generate_taxonomy_chain) usando o minibatch inicial de documentos (state["minibatches"][0]). Ele retorna o estado atualizado da taxonomia após o processo de geração inicial.from typing import Dict
from langchain_core.runnables import Runnable
def parse_taxa(output_text: str) -> Dict:
"""Extract the taxonomy from the generated output."""
cluster_pattern = r"<cluster>\\s*<id>(.*?)</id>\\s*<name>(.*?)</name>\\s*<description>(.*?)</description>\\s*</cluster>"
cluster_matches = re.findall(cluster_pattern, output_text, re.DOTALL)
clusters = [
{"id": id.strip(), "name": name.strip(), "description": description.strip()}
for id, name, description in cluster_matches
]
return {"clusters": clusters}
def format_docs(docs: List[Doc]) -> str:
xml_table = "\\n"
for doc in docs:
xml_table += f'{doc["summary"]}\\n'
xml_table += ""
return xml_table
def format_taxonomy(clusters):
xml = "\\n"
for label in clusters:
xml += " \\n"
xml += f' {label["id"]}\\n'
xml += f' {label["name"]}\\n'
xml += f' {label["description"]}\\n'
xml += " \\n"
xml += ""
return xml
def invoke_taxonomy_chain(
chain: Runnable,
state: TaxonomyGenerationState,
config: RunnableConfig,
mb_indices: List[int],
) -> TaxonomyGenerationState:
configurable = config["configurable"]
docs = state["documents"]
minibatch = [docs[idx] for idx in mb_indices]
data_table_xml = format_docs(minibatch)
previous_taxonomy = state["clusters"][-1] if state["clusters"] else []
cluster_table_xml = format_taxonomy(previous_taxonomy)
updated_taxonomy = chain.invoke(
{
"data_xml": data_table_xml,
"use_case": configurable["use_case"],
"cluster_table_xml": cluster_table_xml,
"suggestion_length": configurable.get("suggestion_length", 30),
"cluster_name_length": configurable.get("cluster_name_length", 10),
"cluster_description_length": configurable.get(
"cluster_description_length", 30
),
"explanation_length": configurable.get("explanation_length", 20),
"max_num_clusters": configurable.get("max_num_clusters", 25),
}
)
return {
"clusters": [updated_taxonomy["clusters"]],
}Agora, vamos ver como o modelo de linguagem pode ser integrado ao processo de geração de taxonomia:
# We will share an LLM for each step of the generate -> update -> review cycle
# You may want to consider using Opus or another more powerful model for this
taxonomy_generation_llm = model
## Initial generation
taxonomy_generation_prompt = hub.pull("wfh/tnt-llm-taxonomy-generation").partial(
use_case="Generate the taxonomy that can be used to label the user intent in the conversation.",
)
taxa_gen_llm_chain = (
taxonomy_generation_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="GenerateTaxonomy")
generate_taxonomy_chain = taxa_gen_llm_chain | parse_taxa
def generate_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
return invoke_taxonomy_chain(
generate_taxonomy_chain, state, config, state["minibatches"][0]
)À medida que os minibatches subsequentes são processados, o TNT-LLM atualiza e refina iterativamente a taxonomia. Esse processo iterativo permite que a taxonomia evolua e melhore com o tempo, incorporando novas percepções e categorias descobertas nos lotes adicionais de dados. As atualizações da taxonomia garantem que ela permaneça abrangente e reflita todo o conjunto de dados.
taxonomy_update_prompt = hub.pull("wfh/tnt-llm-taxonomy-update")
taxa_update_llm_chain = (
taxonomy_update_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="UpdateTaxonomy")
update_taxonomy_chain = taxa_update_llm_chain | parse_taxa
def update_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
which_mb = len(state["clusters"]) % len(state["minibatches"])
return invoke_taxonomy_chain(
update_taxonomy_chain, state, config, state["minibatches"][which_mb]
)Depois que todos os minibatches tiverem sido processados e a taxonomia tiver sido atualizada, a etapa final envolve a revisão da taxonomia. Essa revisão é fundamental para validar a precisão e a relevância dos rótulos categorizados. Isso garante que a taxonomia organize e categorize efetivamente o conjunto de dados de forma significativa, alinhando-se ao caso de uso pretendido, como reconhecimento de intenção ou classificação de tópicos.
taxonomy_review_prompt = hub.pull("wfh/tnt-llm-taxonomy-review")
taxa_review_llm_chain = (
taxonomy_review_prompt | taxonomy_generation_llm | StrOutputParser()
).with_config(run_name="ReviewTaxonomy")
review_taxonomy_chain = taxa_review_llm_chain | parse_taxa
def review_taxonomy(
state: TaxonomyGenerationState, config: RunnableConfig
) -> TaxonomyGenerationState:
batch_size = config["configurable"].get("batch_size", 200)
original = state["documents"]
indices = list(range(len(original)))
random.shuffle(indices)
return invoke_taxonomy_chain(
review_taxonomy_chain, state, config, indices[:batch_size]
)Até agora, as cinco primeiras etapas envolveram a preparação de componentes individuais, como resumo de documentos, criação de minilotes, geração de taxonomia, atualização e revisão. Agora, estamos prontos para integrar esses componentes em um pipeline TNT-LLM coeso usando uma estrutura StateGraph.
Esse gráfico orquestra a execução sequencial de tarefas: resumir documentos, gerar taxonomias a partir de minibatches, atualizar taxonomias iterativamente e, por fim, revisar e validar a taxonomia. As bordas condicionais garantem que as taxonomias sejam atualizadas até que todos os minilotes sejam processados, após o que a taxonomia final é revisada e finalizada para uso em tarefas de rotulagem.
from langgraph.graph import StateGraph
graph = StateGraph(TaxonomyGenerationState)
graph.add_node("summarize", map_reduce_chain)
graph.add_node("get_minibatches", get_minibatches)
graph.add_node("generate_taxonomy", generate_taxonomy)
graph.add_node("update_taxonomy", update_taxonomy)
graph.add_node("review_taxonomy", review_taxonomy)
graph.add_edge("summarize", "get_minibatches")
graph.add_edge("get_minibatches", "generate_taxonomy")
graph.add_edge("generate_taxonomy", "update_taxonomy")
def should_review(state: TaxonomyGenerationState) -> str:
num_minibatches = len(state["minibatches"])
num_revisions = len(state["clusters"])
if num_revisions < num_minibatches:
return "update_taxonomy"
return "review_taxonomy"
graph.add_conditional_edges(
"update_taxonomy",
should_review,
# Optional (but required for the diagram to be drawn correctly below)
{"update_taxonomy": "update_taxonomy", "review_taxonomy": "review_taxonomy"},
)
graph.set_finish_point("review_taxonomy")
graph.set_entry_point("summarize")
app = graph.compile()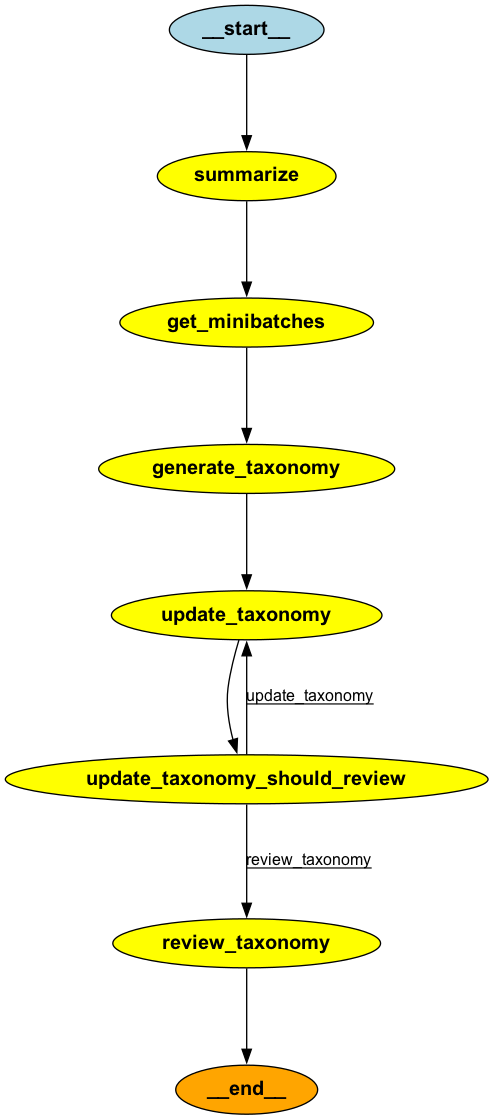
Nesta etapa final, utilizamos o TNT-LLM para agrupar artigos de notícias. A taxonomia resultante é exibida em um formato Markdown, mostrando os nomes e as descrições de cada cluster.
use_case = (
"Generate the taxonomy that can be used to label the news article that would benefit the user."
)
stream = app.stream(
{"documents": docs},
{
"configurable": {
"use_case": use_case,
# Optional:
"batch_size": 10,
"suggestion_length": 30,
"cluster_name_length": 10,
"cluster_description_length": 30,
"explanation_length": 20,
"max_num_clusters": 25,
},
"max_concurrency": 2,
"recursion_limit": 50,
},
)
for step in stream:
node, state = next(iter(step.items()))
print(node, str(state)[:20] + " ...")
from IPython.display import Markdown
def format_taxonomy_md(clusters):
md = "## Final Taxonomy\\n\\n"
md += "| ID | Name | Description |\\n"
md += "|----|------|-------------|\\n"
# Iterate over each inner list of dictionaries
for cluster_list in clusters:
for label in cluster_list:
id = label["id"]
name = label["name"].replace("|", "\\\\|") # Escape any pipe characters within the content
description = label["description"].replace("|", "\\\\|") # Escape any pipe characters
md += f"| {id} | {name} | {description} |\\n"
return md
markdown_table = format_taxonomy_md(step['review_taxonomy']['clusters'])
Markdown(markdown_table)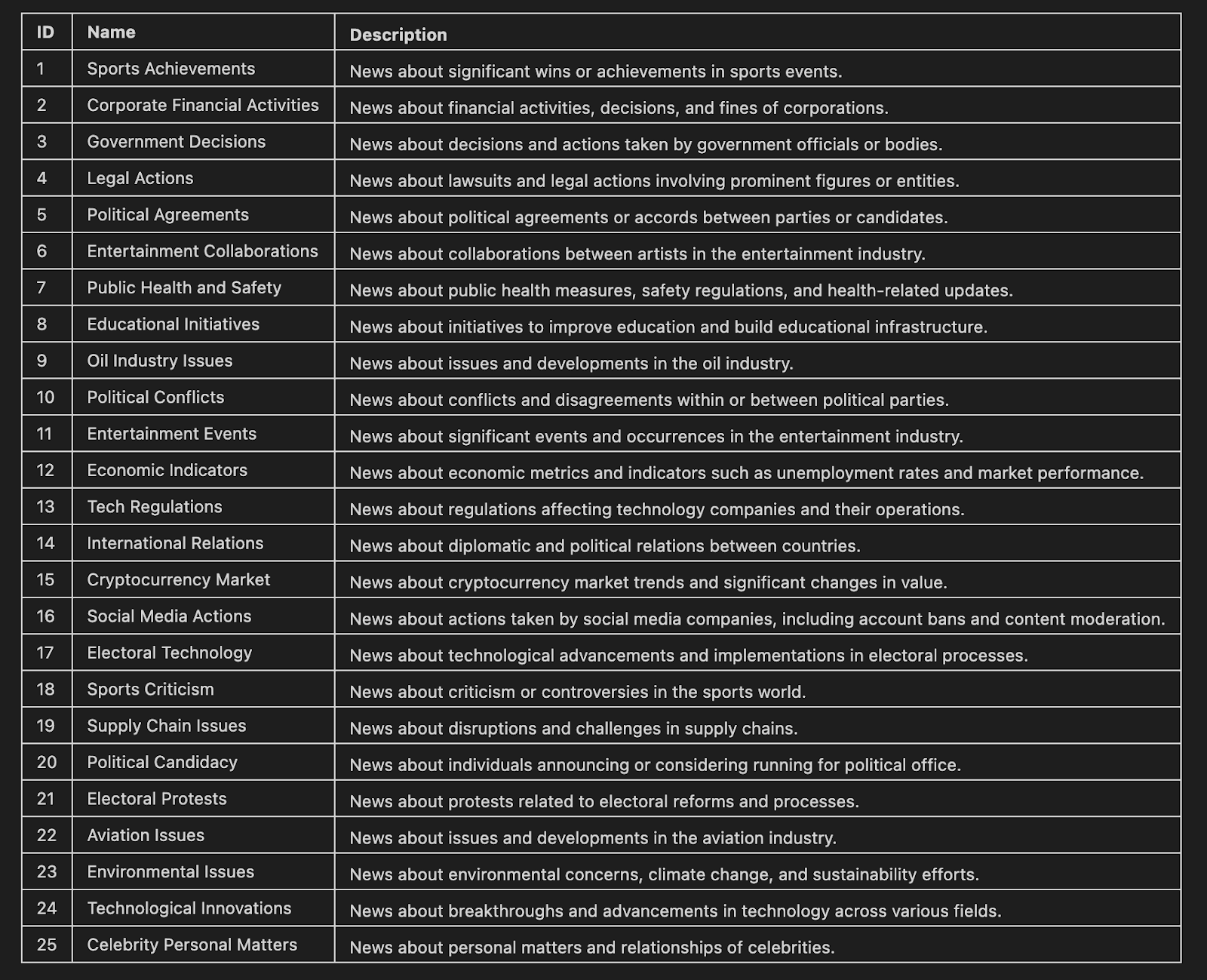
E aí está o que você precisa! Ao seguir essas etapas estruturadas, o TNT-LLM automatizou a criação de taxonomias detalhadas e interpretáveis a partir de dados de texto bruto. Essa abordagem simplifica o que tradicionalmente exige um esforço humano significativo e conhecimento especializado do domínio, tornando-a uma ferramenta poderosa para tarefas de classificação e mineração de texto em grande escala.
O TNT-LLM representa um avanço significativo na mineração e classificação de textos, oferecendo uma solução eficiente para analisar grandes volumes de dados não estruturados. Ao automatizar a geração de taxonomia e a classificação dimensionável, ele reduz o tempo e o esforço necessários para descobrir insights a partir do texto.
Com a evolução do TNT-LLM, ele tem o potencial de transformar a maneira como as organizações analisam grandes quantidades de dados de texto. Essa ferramenta permite a tomada de decisões orientada por dados em todos os setores, tornando os insights de dados textuais mais acessíveis e impactantes.
Se você quiser saber mais sobre o desenvolvimento de aplicativos LLM, recomendo este curso sobre Desenvolvimento de aplicativos LLM com LangChain.
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Stanislav Karzhev
12 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali



