
Course
Developing LLM Applications with LangChain
3 hr
46.2K
Llama 3.1 is a good choice for RAG, a technique that combines retrieval systems with the text-generating abilities of language models to ensure more accurate and relevant outputs.
In RAG, a retrieval system first looks through large datasets to find the most relevant information, which the language model then uses to generate the final response. This is particularly useful for tasks like answering questions, building chatbots, and handling information-heavy tasks, where traditional language models might give outdated or irrelevant answers.
With its ability to handle up to 128K tokens and support for multiple languages, Llama 3.1 enhances the quality and reliability of AI-generated content in RAG systems.
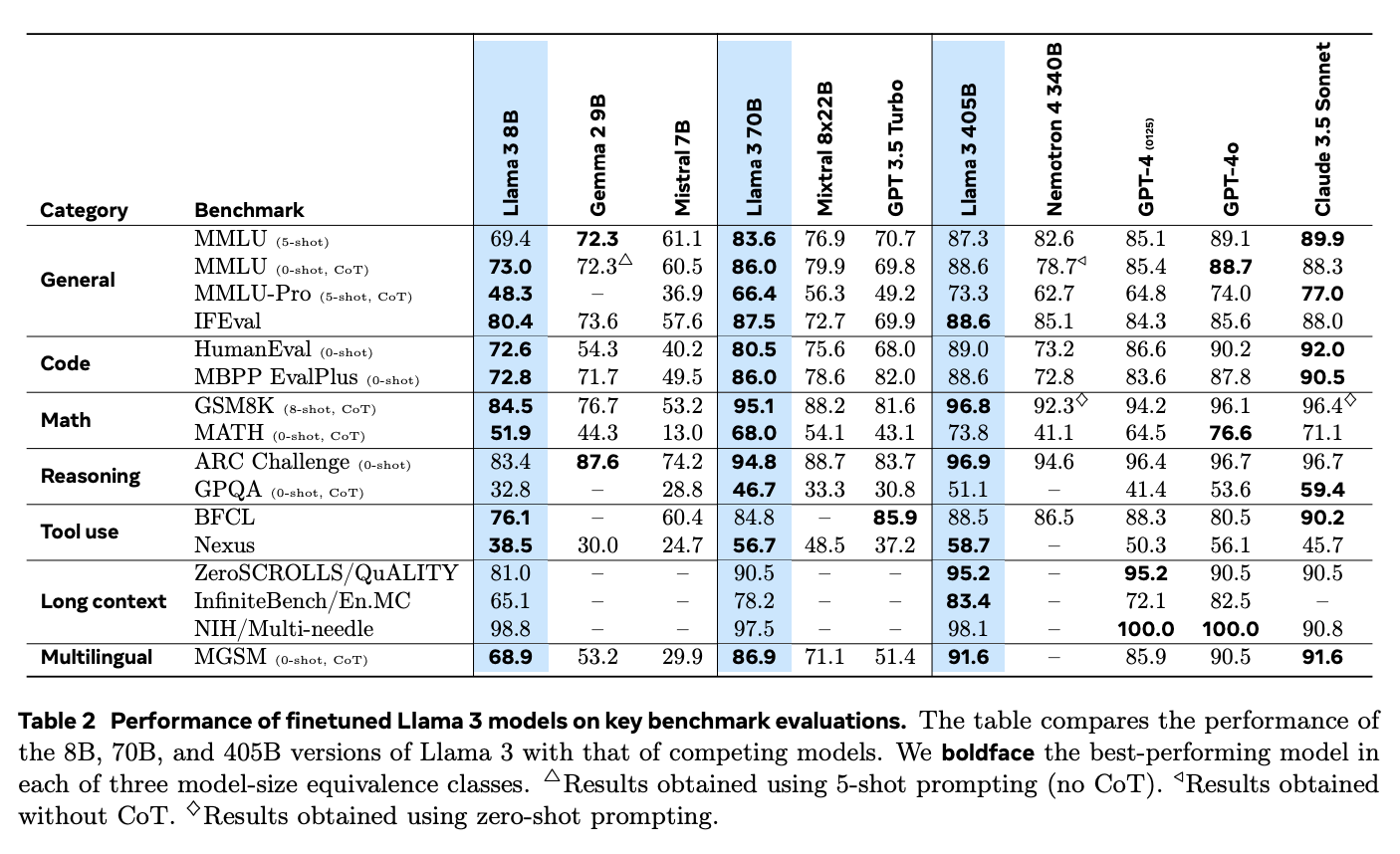
Source: The Llama 3 Herd of Models
Additionally, Llama 3.1 stands out in RAG applications when compared to closed-source models like GPT-4o and Claude 3.5 Sonnet. Its strong reasoning skills and ability to process longer texts allow it to better handle complex questions and deliver more relevant answers.
In the Needle-in-a-Haystack (NIH) benchmark, which tests a model’s ability to find specific pieces of information ("needles") in large volumes of text ("haystacks"), Llama 3.1 excels with a nearly perfect retrieval rate across all model sizes. This demonstrates its ability to manage complex search tasks, making it ideal for RAG systems that need to extract precise information from large datasets.
The model also performed exceptionally well in the Multi-needle benchmark, which requires retrieving multiple pieces of information accurately. Its near-perfect results in this test further prove its capability to handle complex retrieval tasks.
To set up a RAG application with Llama 3.1, several steps are required. These include downloading the Llama 3.1 model to your local machine, setting up the environment, loading the necessary libraries, and creating a retrieval mechanism. Finally, we’ll combine this with a language model to build a complete application.
Below is a clear, step-by-step guide to help you implement a RAG application using Llama 3.1.
First, install the Ollama application, which lets us run Llama 3.1 and other open-source language models on your local machine. You can download the Ollama app from their official website.
Once you’ve installed and opened Ollama, the next step is to download the Llama 3.1 model to your local machine. For this tutorial, we will be using the 8B parameter version. To download it, open your terminal and run the following command line:
ollama run llama3.1After the model finishes downloading, we will be ready to connect it using Langchain, which we will show you how to do it in later sections.
Before you start, make sure you have the right Python libraries installed. We will need libraries such as langchain, langchain_community, langchain-ollama, langchain_openai. If you haven’t installed them yet, you can do so using pip with this command:
pip install langchain langchain_community langchain-openai scikit-learn langchain-ollamaThe first step in creating your RAG system is to load the documents we want to use as our knowledge base. In this example, we will use web pages as our source.
Here’s how to do it:
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# List of URLs to load documents from
urls = [
"<https://lilianweng.github.io/posts/2023-06-23-agent/>",
"<https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/>",
"<https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/>",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]Here, WebBaseLoader is used to fetch content from each URL provided. The resulting nested lists of documents are then combined into a single, flat list called docs_list, giving us a list of documents.
To make the retrieval process more efficient, we divide the documents into smaller chunks using the RecursiveCharacterTextSplitter. This helps the system handle and search the text more effectively.
We can set up the text splitter by specifying the chunk size and overlap. For example, in the code below, we are setting up a text splitter with a chunk size of 250 characters and no overlap.
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)Next, we need to convert the text chunks into embeddings, which are then stored in a vector store, allowing for quick and efficient retrieval based on similarity.
To do this, we use OpenAIEmbeddings to generate embeddings for each text chunk, which are then stored in an SKLearnVectorStore. The vector store is set up to return the top 4 most relevant documents for any given query by configuring it with as_retriever(k=4).
from langchain_community.vectorstores import SKLearnVectorStore
from langchain_openai import OpenAIEmbeddings
# Create embeddings for documents and store them in a vector store
vectorstore = SKLearnVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(openai_api_key="api_key"),
)
retriever = vectorstore.as_retriever(k=4)In this step, we will set up the LLM and create a prompt template to generate responses based on the retrieved documents.
First, we need to define a prompt template that instructs the LLM on how to format its answers. This template tells the model to use the provided documents to answer questions concisely, using a maximum of three sentences. If the model cannot find an answer, it should simply state that it doesn’t know.
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Define the prompt template for the LLM
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following documents to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Documents: {documents}
Answer:
""",
input_variables=["question", "documents"],
)Next, we are connecting to the Llama 3.1 model using ChatOllama from Langchain, which we have configured with a temperature setting of 0 for consistent responses.
# Initialize the LLM with Llama 3.1 model
llm = ChatOllama(
model="llama3.1",
temperature=0,
)Finally, we create a chain that combines the prompt template with the LLM and uses StrOutputParser to ensure the output is a clean, simple string suitable for display.
# Create a chain combining the prompt template and LLM
rag_chain = prompt | llm | StrOutputParser()In this step, we will combine the retriever and the RAG chain to create a complete RAG application. We will do this by creating a class called RAGApplication that will handle both the retrieval of documents and the generation of answers.
The RAGApplication class has the run method that takes in the user’s question, uses the retriever to find relevant documents, and then extracts the text from those documents. It then passes the question and the document text to the RAG chain to generate a concise answer.
# Define the RAG application class
class RAGApplication:
def __init__(self, retriever, rag_chain):
self.retriever = retriever
self.rag_chain = rag_chain
def run(self, question):
# Retrieve relevant documents
documents = self.retriever.invoke(question)
# Extract content from retrieved documents
doc_texts = "\\n".join([doc.page_content for doc in documents])
# Get the answer from the language model
answer = self.rag_chain.invoke({"question": question, "documents": doc_texts})
return answerFinally, we are ready to test our RAG application with some sample questions to make sure it works correctly. You can adjust the prompt template or retrieval settings to improve the performance or tailor the application to specific needs.
# Initialize the RAG application
rag_application = RAGApplication(retriever, rag_chain)
# Example usage
question = "What is prompt engineering"
answer = rag_application.run(question)
print("Question:", question)
print("Answer:", answer)Question: What is prompt engineering
Answer: Prompt engineering refers to methods for communicating with Large Language Models (LLMs) to steer their behavior towards desired outcomes without updating the model weights. It's an empirical science that requires experimentation and heuristics, aiming at alignment and model steerability. The goal is to optimize prompts to achieve specific results, often using techniques like iterative prompting or external tool use.Llama 3.1's advanced features and support for RAG make it ideal for several impactful applications.
For chatbot development, integrating Llama 3.1 with RAG allows chatbots to provide more accurate and context-aware responses by accessing external databases or knowledge bases. This ensures that the information provided to users is current and relevant, which is particularly important in fields like customer service, where timely and accurate answers can greatly enhance user satisfaction and efficiency. Llama 3.1’s support for multiple languages also makes it effective for serving a diverse user base.
In question-answering systems, Llama 3.1 addresses the limitations of traditional language models that rely only on their internal datasets. By using RAG to access up-to-date information from external sources, Llama 3.1 improves the accuracy and reliability of its answers. This is especially useful in fields like healthcare and education, where precise and current information is essential.
For instance, a medical AI assistant powered by Llama 3.1 can provide healthcare professionals with the latest research or treatment guidelines by querying medical databases in real time, thus aiding in better clinical decision-making.
Llama 3.1 is also highly effective for knowledge-intensive tasks such as generating detailed reports or conducting thorough research. By using RAG to draw from a wide range of sources, Llama 3.1 models can deliver more comprehensive and nuanced analyses, making them valuable tools for professionals in areas like research, finance, and strategic planning.
Implementing a RAG application with Llama 3.1 using Ollama and Langchain offers a good solution for creating advanced, context-aware language models.
By following the outlined steps—setting up the environment, loading and processing documents, creating embeddings, and integrating the retriever with the LLM—you can build a functional RAG system capable of retrieving relevant information and providing accurate responses.
Llama 3.1’s integration with RAG is particularly valuable for real-world applications such as chatbots, question-answering systems, and research tools, where access to up-to-date external information is important.
Learn to build AI applications!
Course
Course
Course
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
code-along
Dan Becker
