
Cursus
Développer des applications d'IA
21 h
Llama 3.1 est un bon choix pour RAG, une technique qui combine les systèmes de recherche avec les capacités de génération de texte des modèles de langage afin de garantir des résultats plus précis et plus pertinents.
Dans le système RAG, un système de recherche examine d'abord de vastes ensembles de données pour trouver les informations les plus pertinentes, que le modèle linguistique utilise ensuite pour générer la réponse finale. Ceci est particulièrement utile pour des tâches telles que répondre à des questions, créer des chatbots et traiter des tâches à forte teneur en informations, pour lesquelles les modèles de langage traditionnels peuvent donner des réponses obsolètes ou non pertinentes.
Avec sa capacité à gérer jusqu'à 128K tokens et la prise en charge de plusieurs langues, Llama 3.1 améliore la qualité et la fiabilité du contenu généré par l'IA dans les systèmes RAG.
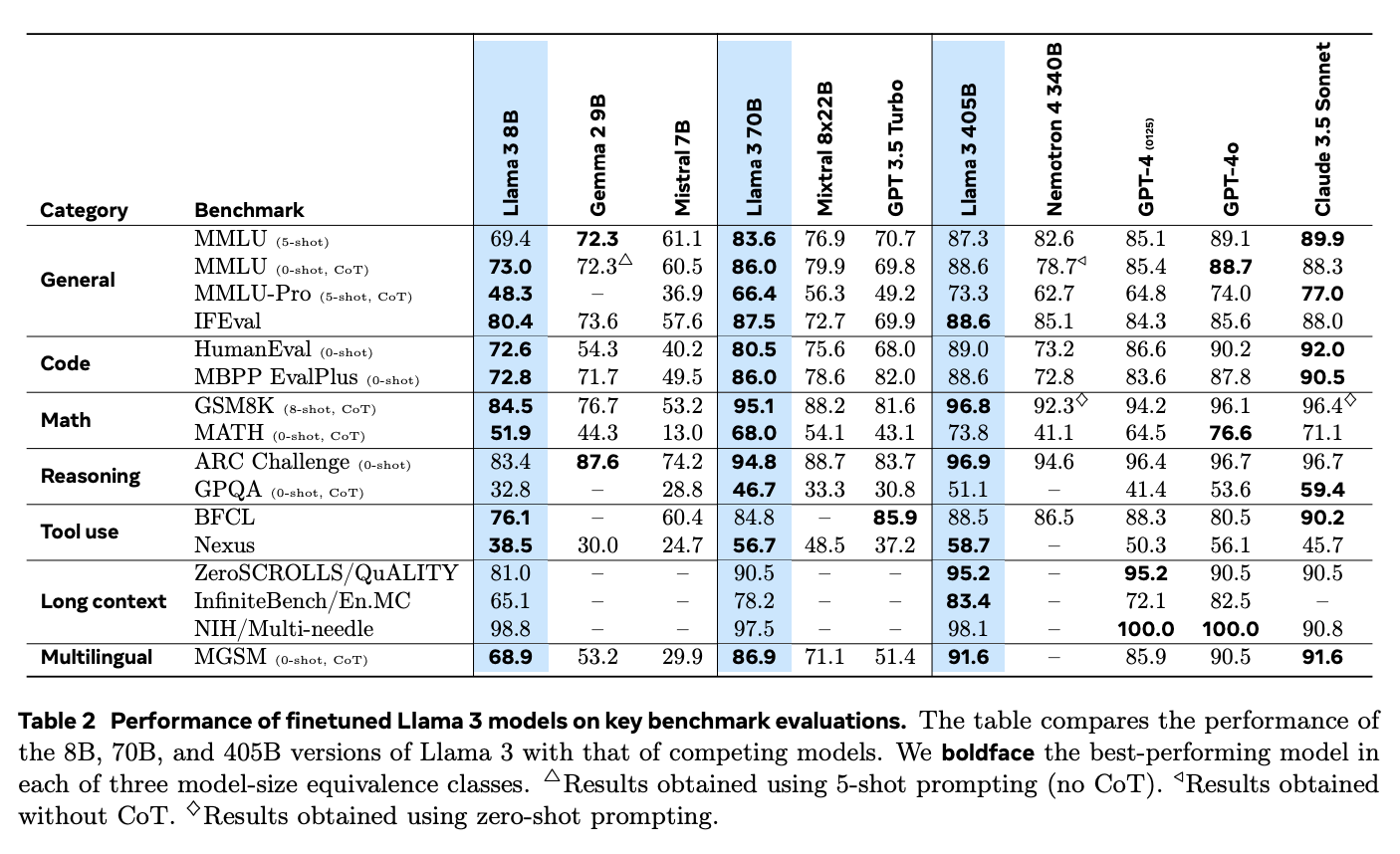
Source : Le troupeau de modèles Llama 3
En outre, Llama 3.1 se distingue dans les applications RAG par rapport aux modèles à source fermée tels que GPT-4o et Claude 3.5 Sonnet. Ses fortes capacités de raisonnement et son aptitude à traiter des textes plus longs lui permettent de mieux traiter les questions complexes et de fournir des réponses plus pertinentes.
Dans le benchmark "Needle-in-a-Haystack" (NIH), qui teste la capacité d'un modèle à trouver des éléments d'information spécifiques ("aiguilles") dans de grands volumes de texte ("bottes de foin"), Llama 3.1 excelle avec un taux d'extraction presque parfait pour toutes les tailles de modèles. Cela démontre sa capacité à gérer des tâches de recherche complexes, ce qui le rend idéal pour les systèmes RAG qui doivent extraire des informations précises à partir de grands ensembles de données.
Le modèle a également obtenu d'excellents résultats dans le test de référence "Multi-needle", qui exige la récupération précise de plusieurs éléments d'information. Les résultats quasi parfaits obtenus lors de ce test prouvent une fois de plus sa capacité à gérer des tâches de recherche complexes.
Pour mettre en place une application RAG avec Llama 3.1, plusieurs étapes sont nécessaires. Il s'agit notamment de télécharger le modèle Llama 3.1 sur votre machine locale, de configurer l'environnement, de charger les bibliothèques nécessaires et de créer un mécanisme de récupération. Enfin, nous combinerons ces éléments avec un modèle linguistique pour créer une application complète.
Vous trouverez ci-dessous un guide clair, étape par étape, qui vous aidera à mettre en œuvre une application RAG à l'aide de Llama 3.1.
Tout d'abord, installez l'application Ollama, qui nous permet d'exécuter Llama 3.1 et d'autres modèles de langage open-source sur votre machine locale. Vous pouvez télécharger l'application Ollama à partir de leur site officiel.
Une fois que vous avez installé et ouvert Ollama, l'étape suivante consiste à télécharger le modèle Llama 3.1 sur votre machine locale. Pour ce tutoriel, nous utiliserons la version du paramètre 8B. Pour le télécharger, ouvrez votre terminal et exécutez la ligne de commande suivante :
ollama run llama3.1Une fois le téléchargement du modèle terminé, nous serons prêts à le connecter à l'aide de Langchain, ce que nous vous montrerons dans les sections suivantes.
Avant de commencer, assurez-vous que les bonnes bibliothèques Python sont installées. Nous aurons besoin de bibliothèques telles que langchain, langchain_community, langchain-ollama, langchain_openai. Si vous ne les avez pas encore installés, vous pouvez le faire en utilisant pip avec cette commande :
pip install langchain langchain_community langchain-openai scikit-learn langchain-ollamaLa première étape de la création de votre système RAG consiste à charger les documents que nous voulons utiliser comme base de connaissances. Dans cet exemple, nous utiliserons des pages web comme source.
Voici comment procéder :
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# List of URLs to load documents from
urls = [
"<https://lilianweng.github.io/posts/2023-06-23-agent/>",
"<https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/>",
"<https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/>",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]Ici, WebBaseLoader est utilisé pour récupérer le contenu de chaque URL fournie. Les listes imbriquées de documents qui en résultent sont ensuite combinées en une seule liste plate appelée docs_list, ce qui nous donne une liste de documents.
Pour rendre le processus de recherche plus efficace, nous divisons les documents en morceaux plus petits à l'aide de RecursiveCharacterTextSplitter. Cela permet au système de traiter et de rechercher le texte plus efficacement.
Nous pouvons configurer le séparateur de texte en spécifiant la taille des morceaux et le chevauchement. Par exemple, dans le code ci-dessous, nous configurons un séparateur de texte avec une taille de bloc de 250 caractères et sans chevauchement.
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)Ensuite, nous devons convertir les morceaux de texte en enregistrementsqui sont ensuite stockés dans un magasin de vecteurs, ce qui permet une recherche rapide et efficace basée sur la similarité.
Pour ce faire, nous utilisons le site OpenAIEmbeddings pour générer des enchâssements pour chaque morceau de texte, qui sont ensuite stockés dans un site SKLearnVectorStore. Le magasin de vecteurs est configuré pour renvoyer les 4 documents les plus pertinents pour une requête donnée en le configurant avec as_retriever(k=4).
from langchain_community.vectorstores import SKLearnVectorStore
from langchain_openai import OpenAIEmbeddings
# Create embeddings for documents and store them in a vector store
vectorstore = SKLearnVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(openai_api_key="api_key"),
)
retriever = vectorstore.as_retriever(k=4)Dans cette étape, nous allons configurer le LLM et créer un modèle d'invite pour générer des réponses basées sur les documents récupérés.
Tout d'abord, nous devons définir un modèle d'invite qui indique au mécanisme d'apprentissage tout au long de la vie comment formuler ses réponses. Ce modèle indique au candidat qu'il doit utiliser les documents fournis pour répondre aux questions de manière concise, en trois phrases maximum. Si le modèle ne trouve pas de réponse, il doit simplement indiquer qu'il ne sait pas.
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Define the prompt template for the LLM
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following documents to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Documents: {documents}
Answer:
""",
input_variables=["question", "documents"],
)Ensuite, nous nous connectons au modèle Llama 3.1 en utilisant ChatOllama de Langchain, que nous avons configuré avec une température de 0 pour des réponses cohérentes.
# Initialize the LLM with Llama 3.1 model
llm = ChatOllama(
model="llama3.1",
temperature=0,
)Enfin, nous créons une chaîne qui combine le modèle d'invite avec le LLM et utilise StrOutputParser pour s'assurer que la sortie est une chaîne simple et propre adaptée à l'affichage.
# Create a chain combining the prompt template and LLM
rag_chain = prompt | llm | StrOutputParser()Dans cette étape, nous combinerons le récupérateur et la chaîne RAG pour créer une application RAG complète. Pour ce faire, nous créerons une classe appelée RAGApplication qui s'occupera à la fois de la recherche de documents et de la génération de réponses.
La classe RAGApplication possède la méthode run qui prend en compte la question de l'utilisateur, utilise le moteur de recherche pour trouver les documents pertinents, puis extrait le texte de ces documents. Il transmet ensuite la question et le texte du document à la chaîne RAG pour générer une réponse concise.
# Define the RAG application class
class RAGApplication:
def __init__(self, retriever, rag_chain):
self.retriever = retriever
self.rag_chain = rag_chain
def run(self, question):
# Retrieve relevant documents
documents = self.retriever.invoke(question)
# Extract content from retrieved documents
doc_texts = "\\n".join([doc.page_content for doc in documents])
# Get the answer from the language model
answer = self.rag_chain.invoke({"question": question, "documents": doc_texts})
return answerEnfin, nous sommes prêts à tester notre application RAG avec quelques exemples de questions pour nous assurer qu'elle fonctionne correctement. Vous pouvez ajuster le modèle d'invite ou les paramètres d'extraction pour améliorer les performances ou adapter l'application à des besoins spécifiques.
# Initialize the RAG application
rag_application = RAGApplication(retriever, rag_chain)
# Example usage
question = "What is prompt engineering"
answer = rag_application.run(question)
print("Question:", question)
print("Answer:", answer)Question: What is prompt engineering
Answer: Prompt engineering refers to methods for communicating with Large Language Models (LLMs) to steer their behavior towards desired outcomes without updating the model weights. It's an empirical science that requires experimentation and heuristics, aiming at alignment and model steerability. The goal is to optimize prompts to achieve specific results, often using techniques like iterative prompting or external tool use.Les fonctionnalités avancées de Llama 3.1 et la prise en charge de RAG en font un outil idéal pour plusieurs applications à fort impact.
Pour développement de chatbotsL'intégration de Llama 3.1 avec RAG permet aux chatbots de fournir des réponses plus précises et contextuelles en accédant à des bases de données externes ou à des bases de connaissances. Cela garantit que les informations fournies aux utilisateurs sont actuelles et pertinentes, ce qui est particulièrement important dans des domaines tels que le service à la clientèle, où des réponses précises et opportunes peuvent grandement améliorer la satisfaction et l'efficacité des utilisateurs. La prise en charge de plusieurs langues par Llama 3.1 lui permet également de servir une base d'utilisateurs diversifiée.
Dans les systèmes de réponse aux questions, Llama 3.1 répond aux limites des modèles de langage traditionnels qui reposent uniquement sur leurs ensembles de données internes. En utilisant RAG pour accéder à des informations actualisées provenant de sources externes, Llama 3.1 améliore la précision et la fiabilité de ses réponses. Ceci est particulièrement utile dans des domaines tels que les soins de santé et l'éducation l'éducationoù des informations précises et actuelles sont essentielles.
Par exemple, un assistant médical d'IA alimenté par Llama 3.1 peut fournir aux professionnels de la santé les dernières recherches ou directives de traitement en interrogeant des bases de données médicales en temps réel, contribuant ainsi à une meilleure prise de décision clinique.
Llama 3.1 est également très efficace pour les tâches à forte intensité de connaissances, telles que la production de rapports détaillés ou la réalisation de recherches approfondies. En utilisant RAG pour puiser dans un large éventail de sources, les modèles Llama 3.1 peuvent fournir des analyses plus complètes et plus nuancées, ce qui en fait des outils précieux pour les professionnels dans des domaines tels que la recherche, la finance et la planification stratégique.
La mise en œuvre d'une application RAG avec Llama 3.1 en utilisant Ollama et Langchain offre une bonne solution pour créer des modèles de langage avancés et sensibles au contexte.
En suivant les étapes décrites - configuration de l'environnement, chargement et traitement des documents, création d'enchâssements et intégration du récupérateur dans le LLM - vous pouvez construire un système RAG fonctionnel capable de récupérer des informations pertinentes et de fournir des réponses précises.
L'intégration de Llama 3.1 avec RAG est particulièrement précieuse pour les applications réelles telles que les chatbots, les systèmes de réponse aux questions et les outils de recherche, où l'accès à des informations externes actualisées est important.
Apprenez à créer des applications d'intelligence artificielle !
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach