
programa
Llama Fundamentals
4 h
Meta acaba de anunciar el conjunto de modelos Llama 4, que incluye dos modelos lanzados -Llama4 Scout y Llama 4 Maverick- y un tercero aún en formación: Llama 4 Behemoth.
Las variantes Scout y Maverick ya están disponibles, publicadas abiertamente bajo la típica licencia de peso abierto de Meta, con una notable advertencia: si tus servicios superan los 700 millones de usuarios activos mensuales, deberás obtener una licencia aparte de Meta, que podrá conceder o no a su discreción.
Llama Scout admite una ventana de contexto de 10 millones de tokens, la mayor de cualquier modelo publicado. Llama Maverick es un modelo generalista y apunta a GPT-4o, Gemini 2.0 Flash y DeepSeek-V3. Llama Behemoth, aún en formación, sirve como modelo de maestro de alta capacidad.
Nuestro equipo está probando activamente el modelo, y publicaremos blogs separados sobre la puesta a punto de Llama 4, ejecutándolo en vLLMy sobre cómo probar su enorme ventana contextual. Actualizaré este artículo con los enlaces cuando estén listos. En este blog introductorio, te daré una visión general de la suite Llama 4.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
Llama 4 es la nueva familia de grandes modelos lingüísticos de Meta. El lanzamiento incluye dos modelos ya disponibles -Llama 4 Scout y Llama 4 Maverick- y un tercero, Llama 4 Behemoth, aún en formación.

Fuente: Meta AI
Llama 4 introduce mejoras sustanciales. En particular, incorpora una mezcla de expertos (MdE) cuyo objetivo es mejorar la eficacia y el rendimiento activando sólo los componentes necesarios para tareas específicas (hablaremos de esto más adelante). Este diseño representa un cambio hacia modelos de IA más escalables y especializados.
Llama 4 continúa la estrategia de Meta de lanzar modelos de peso abierto, pero con una advertencia. Si tu empresa opera servicios con más de 700 millones de usuarios activos mensuales, necesitarás una licencia aparte de Meta, que puede o no concederse. Dejando a un lado esta limitación, el lanzamiento sigue pareciendo un acontecimiento importante en el panorama del peso abierto, aunque el propio panorama ha cambiado rápidamente en los últimos meses.
Si Llama 2 y 3 definieron en su día la categoría, Llama 4 entra ahora en un campo mucho más competitivo. DeepSeek ha llegado con grandes capacidades de razonamiento. Alibaba Qwen de Alibaba ha obtenido buenos resultados en pruebas multilingües y de codificación. Google Gemma de Google están empujando en el mismo espacio con arquitecturas más pequeñas y eficientes. Y hace sólo unos días, OpenAI anunció sus planes de lanzar un modelo de peso abierto, un cambio que habría parecido improbable hace un año.
Averigüemos más detalles sobre cada modelo.
Llama 4 Scout es el modelo más ligero del nuevo conjunto, pero posiblemente sea el más intrigante. Funciona con una única GPU H100 y admite una ventana de contexto de 10 millones de tokens. Esto convierte a Scout en el modelo de peso abierto más ávido de contexto publicado hasta la fecha y, potencialmente, en el más útil para tareas como el resumen de documentos múltiples, el razonamiento de código largo y el análisis sintáctico de actividades.

Scout tiene 17.000 millones de parámetros activos, organizados a través de 16 expertos, con un recuento total de parámetros de 109.000 millones. Fue pre-entrenado y post-entrenado con una ventana de contexto de 256K, pero Meta dice que generaliza mucho más allá de eso (esta afirmación aún está por probar). En la práctica, eso abre la puerta a flujos de trabajo que implican bases de código enteras, historiales de sesiones o documentos legales, todo ello procesado en una sola pasada.
Arquitectónicamente, Scout se construye utilizando el marco de mezcla de expertos (MoE) de Meta, en el que sólo se activa un subconjunto de parámetros por token, a diferencia de los modelosdensos de como GPT-4o, en los que se activan todos los parámetros. Eso significa que es eficiente en el cálculo y altamente escalable.
Más allá de la arquitectura básica, Meta destacó el carácter multimodal de Scout multimodal de Scout. Fue preentrenado en datos de texto, imagen y vídeo mediante fusión temprana, lo que le permite manejar combinaciones de indicaciones textuales y visuales de forma nativa. En tareas con muchas imágenes, como la localización visual y la respuesta a preguntas visuales (VQA), Scout rinde mejor que cualquier modelo Llama anterior, y se enfrenta a sistemas mucho mayores.
En resumen, Scout está construido para ser amplio y escalar. Está diseñado para funcionar con eficacia, manejar más entradas que cualquier modelo abierto anterior y funcionar bien tanto en tareas de texto como de imagen. Pronto pondremos a prueba ese límite de 10 millones de contextos, e informaremos al respecto.
Llama 4 Maverick es el generalista de la gama, un modelo multimodal a gran escala diseñado para rendir en el chat, el razonamiento, la comprensión de imágenes y el código. Mientras que Scout lleva al límite la longitud del contexto, Maverick se centra en una producción equilibrada y de alta calidad en todas las tareas. Es la respuesta de Meta a GPT-4o, DeepSeek-V3y Géminis 2.0 Flash.

Maverick tiene los mismos 17.000 millones de parámetros activos que Scout, pero con una configuración de MoE mayor: 128 expertos y un recuento total de parámetros de 400.000 millones. Al igual que Scout, utiliza una arquitectura de mezcla de expertos, que activa sólo una parte del modelo por ficha, lo que reduce el coste de inferencia al tiempo que aumenta la capacidad. El modelo se ejecuta en un único host H100 DGX, pero también puede desplegarse con inferencia distribuida para aplicaciones a mayor escala.
Meta adoptó aquí un enfoque diferente para el post-entrenamiento, utilizando una mezcla de supervisión ligera ajuste finoen línea aprendizaje de refuerzoy optimización directa de preferencias. El objetivo era mejorar el rendimiento en las indicaciones difíciles sin forzar demasiado el modelo. Para ello, Meta filtró más del 50% de los ejemplos de entrenamiento marcados como "fáciles" por los anteriores modelos Llama y construyó un plan de estudios que hacía hincapié en tareas de razonamiento, codificación y multimodales más difíciles.
Maverick también se destiló conjuntamente de Llama 4 Behemoth, el modelo interno de Meta, mucho más grande, lo que ayudó a aumentar el rendimiento sin añadir costes de entrenamiento. Según Meta, este proceso de destilación produjo un salto notable en la calidad del razonamiento y del chat.
Llama 4 Behemoth es el modelo más potente y grande de Meta hasta la fecha, pero aún no está disponible. Aún en entrenamiento, Behemoth no es un modelo de razonamiento en el mismo sentido que DeepSeek-R1 o o3 de OpenAIde OpenAI, que están construidos y optimizados para tareas de pensamiento en cadena de varios pasos.
Por lo que sabemos hasta ahora, tampoco parece diseñado como producto de uso directo. En su lugar, actúa como un modelo de profesor, utilizado para destilar y dar forma tanto a Scout como a Maverick. Una vez publicado, podría permitir a otros destilar también sus propios modelos.

Behemoth tiene 288.000 millones de parámetros activos, organizados a través de 16 expertos, con un recuento total de parámetros cercano a los 2 billones. Meta construyó una infraestructura de formación totalmente nueva para apoyar a Behemoth a esta escala. Introdujo el aprendizaje por refuerzo asíncrono, el muestreo curricular basado en la dificultad de las indicaciones, y una nueva función de pérdida por destilación que equilibra dinámicamente los objetivos blandos y duros.
El Behemoth post-entrenamiento también requería una receta diferente. Meta descartó más del 95% de los ejemplos de SFT para limitarse a las indicaciones difíciles y centró el aprendizaje por refuerzo en el razonamiento complejo, la codificación y los escenarios multilingües. El muestreo de instrucciones variadas del sistema ayudó al modelo a generalizarse, mientras que el filtrado dinámico eliminó las instrucciones de poco valor durante el entrenamiento de la RL.
Meta ha publicado los resultados de las pruebas comparativas internas de cada uno de los modelos Llama 4, comparándolos tanto con sus variantes anteriores de Llama como con varios modelos de peso abierto y fronterizos de la competencia.
En esta sección, te guiaré a través de los puntos más destacados de Scout, Maverick y Behemoth, utilizando los propios números de Meta. Como siempre, recomiendo cautela con los puntos de referencia autoinformados, pero estas puntuaciones ofrecen un primer vistazo útil sobre el rendimiento de cada modelo en diferentes tareas y su posición en el panorama actual. Empecemos por Scout.
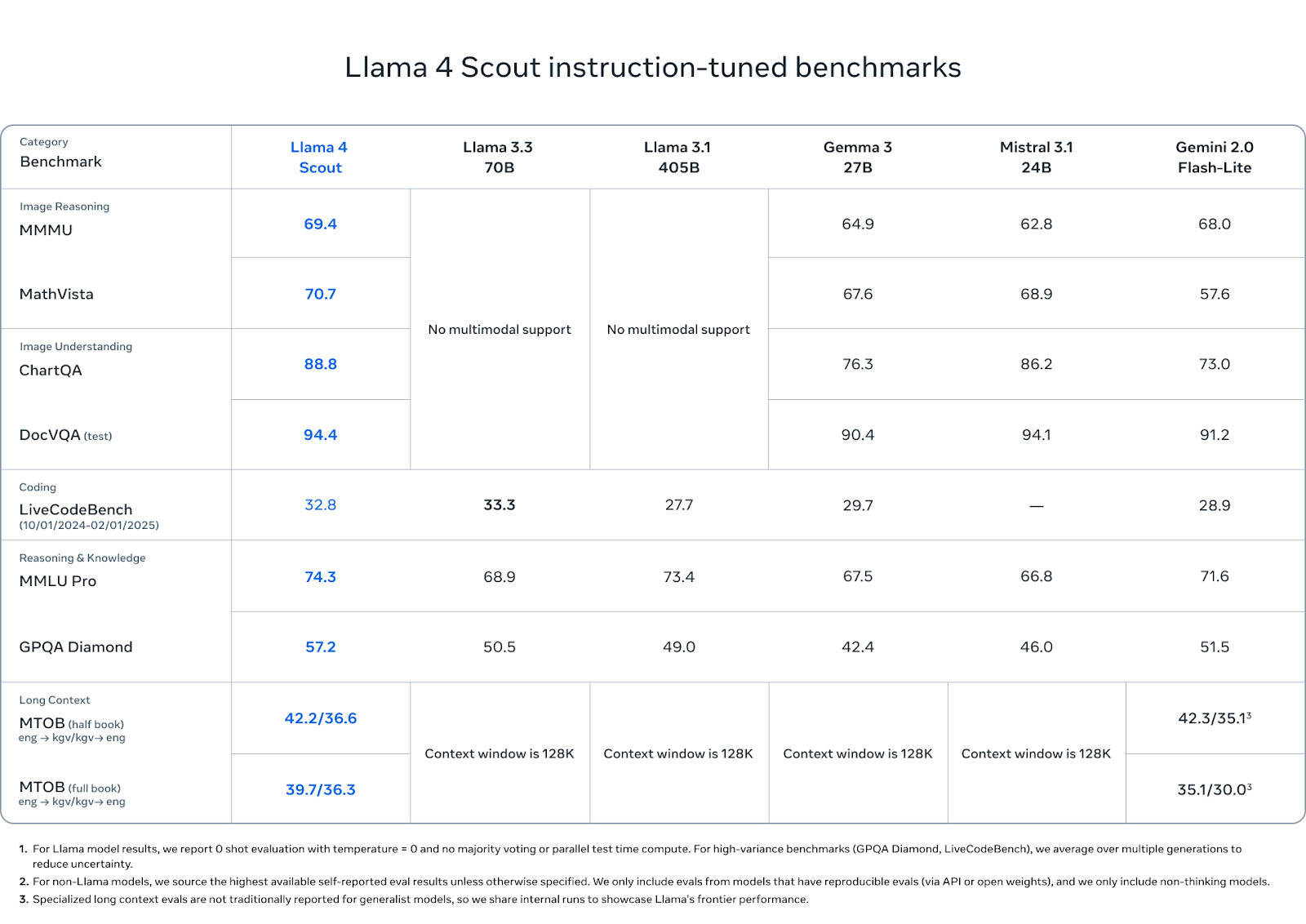
Llama 4 Scout tiene un buen rendimiento en una mezcla de pruebas de razonamiento, codificación y multimodales, especialmente teniendo en cuenta su menor número de parámetros activos y su huella en una sola GPU.
Fuente: MetaAI
En comprensión de imágenes, Scout supera a sus competidores: obtiene una puntuación de 88,8 en ChartQA y de 94,4 en DocVQA (prueba), superando a Gemini 2.0 Flash-Lite (73,0 y 91,2, respectivamente) e igualando o superando ligeramente a Mistral 3.1 y Gemma 3 27B.
En pruebas de razonamiento de imágenes como MMMU (69,4) y MathVista (70,7), también lidera el grupo de peso abierto, superando a Gemma 3 (64,9, 67,6), Mistral 3.1 (62,8, 68,9) y Gemini Flash-Lite (68,0, 57,6).
En codificación, Scout obtiene una puntuación de 32,8 en LiveCodeBench, situándose por delante de Gemini Flash-Lite (28,9) y Gemma 3 27B (29,7), aunque ligeramente por detrás de los 33,3 de Llama 3.3. No es un modelo que priorice la codificación, pero se mantiene.
En conocimiento y razonamiento, Scout alcanza 74,3 en MMLU Pro y 57,2 en GPQA Diamond, superando a todos los demás modelos de peso abierto en ambos. Estos puntos de referencia favorecen el razonamiento largo de varios pasos, por lo que el buen rendimiento de Scout aquí es notable, especialmente a esta escala.
Por último, las capacidades de contexto largo de Scout muestran un potencial en el mundo real. En la prueba MTOB (Massive Textual Overlap Benchmark), que pone a prueba la capacidad del modelo para traducir entre inglés y KGV, una lengua de pocos recursos, obtiene una puntuación de 42,2/36,6 en la prueba de medio libro y de 39,7/36,3 en la de libro completo. En la prueba de medio libro, Gemini 2.0 Flash-Lite queda ligeramente por delante con 42,3, pero Scout cierra la brecha en el libro completo, superando los 35,1/30,0 de Gemini.
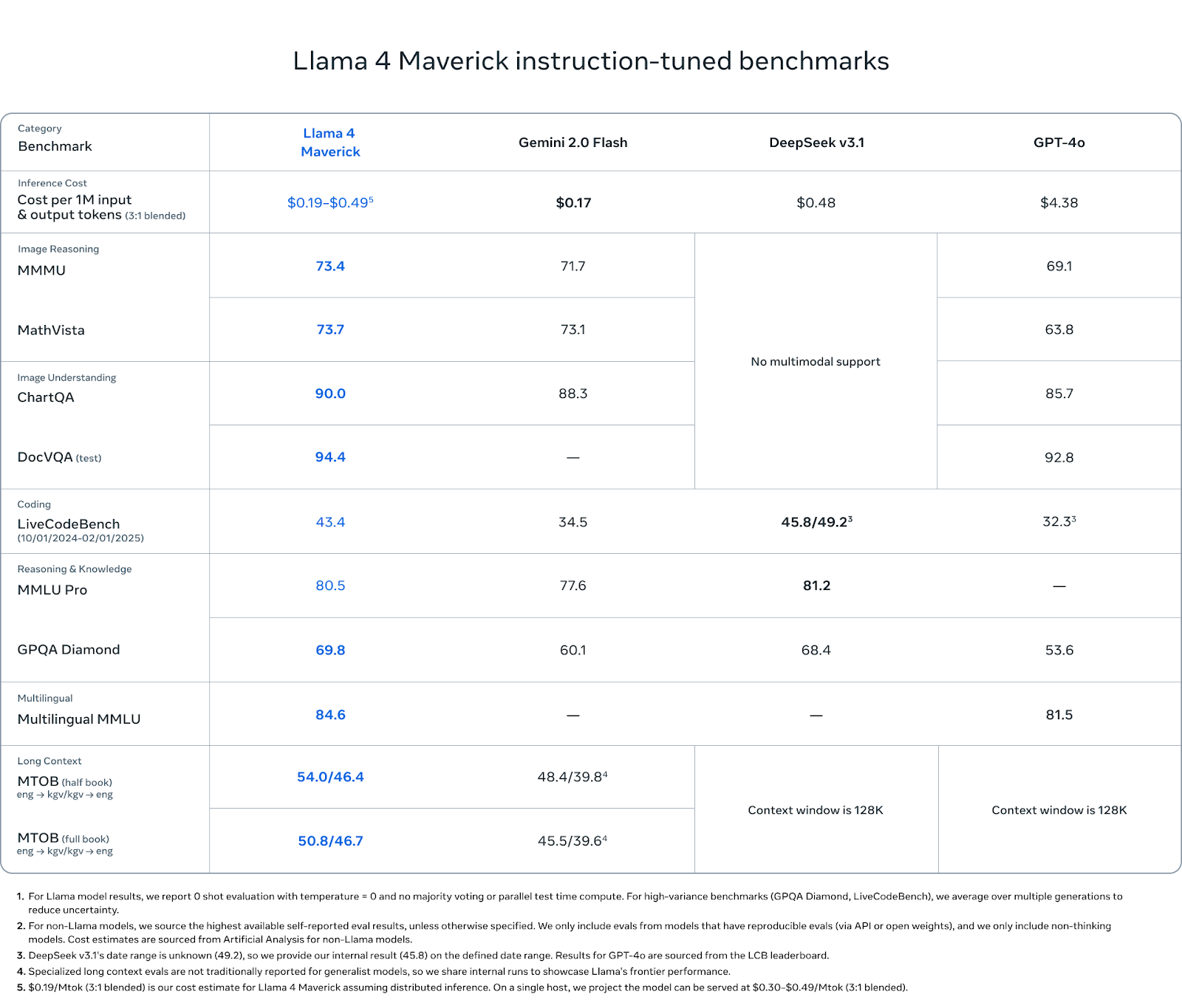
Maverick es el modelo más completo de la gama Llama 4, y los resultados de las pruebas comparativas así lo reflejan. Aunque no aspira a los extremos de longitud de contexto de Scout ni a la escala bruta de Behemoth, su rendimiento es consistente en todas las categorías que importan: razonamiento multimodal, codificación, comprensión del lenguaje y retención de contextos largos.
Fuente: MetaAI
En razonamiento de imágenes, Maverick obtiene una puntuación de 73,4 en MMMU y de 73,7 en MathVista, superando a Gemini 2.0 Flash (71,7 y 73,1) y a GPT-4o (69,1 y 63,8). En ChartQA (comprensión de la imagen), obtiene una puntuación de 90,0, ligeramente por encima del 88,3 de Gemini y muy por encima del 85,7 de GPT-4o. En DocVQA, Maverick alcanza 94,4, igualando a Scout y superando los 92,8 de GPT-4o.
En codificación, Maverick obtiene una puntuación de 43,4 en LiveCodeBench, situándose por encima de GPT-4o (32,3), Gemini Flash (34,5) y cerca de los 45,8 de DeepSeek v3.1.
En razonamiento y conocimiento, Maverick obtiene una puntuación de 80,5 en MMLU Pro y de 69,8 en GPQA Diamond, superando de nuevo a Gemini Flash (77,6 y 60,1) y a GPT-4o (sin puntuación en MMLU Pro, 53,6 en GPQA). DeepSeek v3.1 lidera por un margen de 0,7 en MMLU Pro.
Maverick también obtiene buenos resultados en comprensión multilingüe, con una puntuación de 84,6 en MMLU Multilingüe, ligeramente por encima del 81,5 de Géminis. Eso le da una ventaja para los desarrolladores que trabajan en varios idiomas o geografías.
En las evaluaciones de contexto largo (MTOB), Maverick obtiene una puntuación de 54,0/46,4 en la prueba de medio libro y de 50,8/46,7 en la de libro completo, significativamente por delante de los 48,4/39,8 y 45,5/39,6 de Géminis, respectivamente. Estas puntuaciones sugieren que, aunque Maverick no anuncia su duración contextual tan ruidosamente como Scout, sigue beneficiándose significativamente de su ventana ampliada.
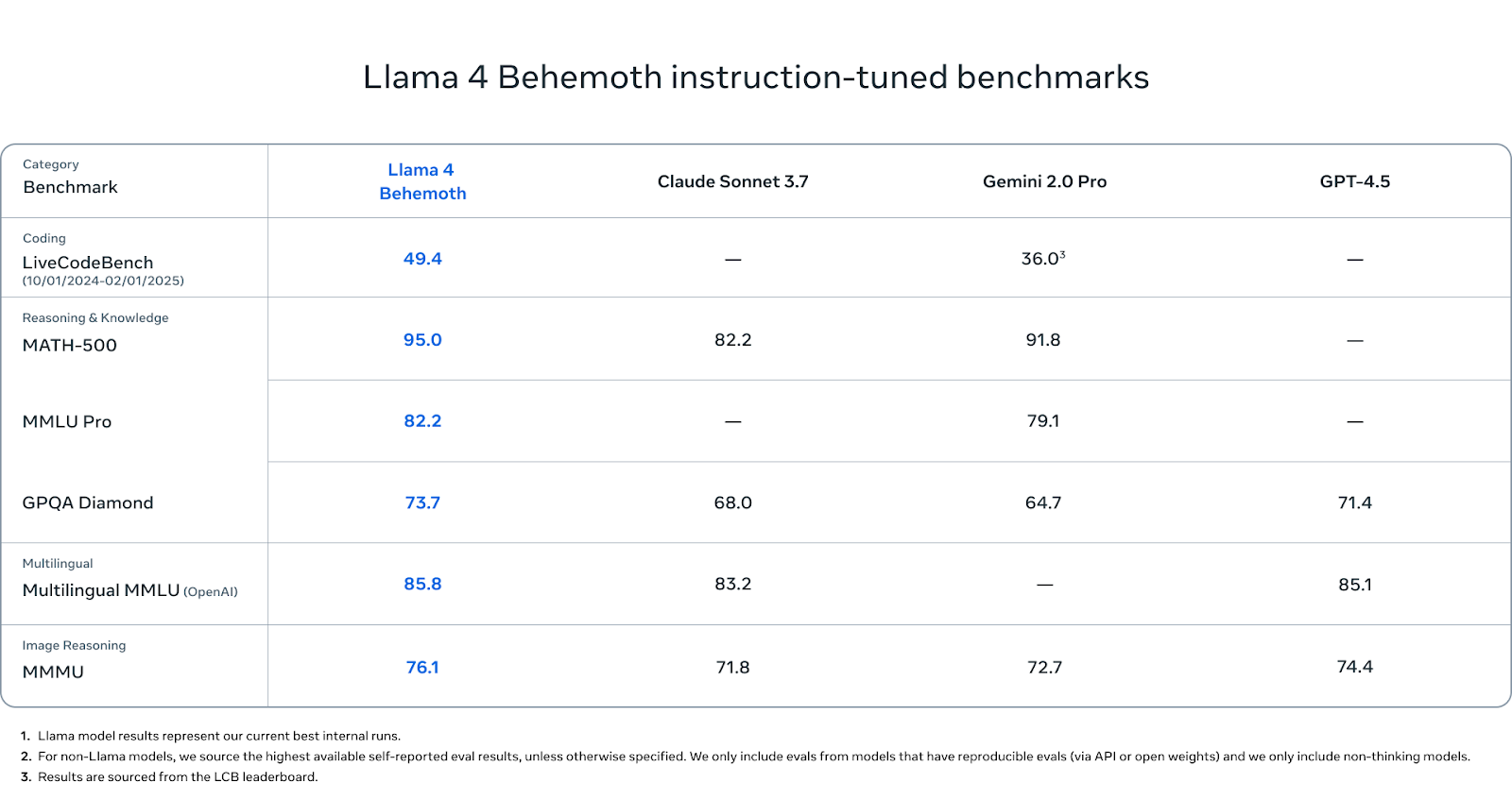
Behemoth aún no ha salido a la venta, pero merece la pena prestar atención a sus cifras de referencia.
Fuente: MetaAI
En las pruebas STEM, el Behemoth tiene un rendimiento excepcional. Obtiene una puntuación de 95,0 en MATH-500, es decir, más que Gemini 2.0 Pro (91,8) y significativamente más que Claude Sonnet 3.7 (82.2). En MMLU Pro, Behemoth obtiene una puntuación de 82,2, mientras que Gemini Pro llega a 79,1 (Claude no ha informado de ninguna puntuación). Y en GPQA Diamond, otra prueba comparativa que premia la profundidad y precisión de los hechos, Behemoth alcanza 73,7, por delante de Claude (68,0), Gemini (64,7) y GPT-4.5 (71.4).
En comprensión multilingüe, Behemoth obtiene una puntuación de 85,8 en MMLU Multilingüe, superando ligeramente a Claude Sonnet (83,2) y GPT-4.5 (85,1). Estas puntuaciones son importantes para los desarrolladores globales que trabajan fuera del inglés, y Behemoth lidera actualmente esta categoría.
En razonamiento de imagen, Behemoth alcanza 76,1 en MMMU, superando a Géminis (71,8), Claude (72,7) y GPT-4,5 (74,4). Aunque no es su objetivo principal, sigue siendo competitivo con los principales modelos multimodales.
En generación de código, Behemoth obtiene una puntuación de 49,4 en LiveCodeBench. Eso está muy por encima de Géminis 2.0 Pro (36,0).
Tanto Llama 4 Scout como Llama 4 Maverick ya están disponibles bajo la licencia de peso abierto de Meta. Puedes descargarlos directamente desde el sitio web oficial de Llama o a través de Cara de Abrazo.
Para acceder a los modelos a través de los servicios propios de Meta, puedes interactuar con Meta AI en varias plataformas: WhatsApp, Messenger, Instagram y Facebook. Actualmente, el acceso requiere iniciar sesión con una cuenta de Meta, y no existe un punto final de API independiente para Meta AI, al menos de momento.
Si piensas integrar los modelos en tus propias aplicaciones o infraestructuras, ten en cuenta la cláusula de licencia: si tu producto o servicio tiene más de 700 millones de usuarios activos mensuales, tendrás que obtener un permiso aparte de Meta. Por lo demás, los modelos son utilizables para la investigación, la experimentación y la mayoría de los casos de uso comercial.
Scout introduce una longitud de contexto sin precedentes en una sola GPU. Maverick se enfrenta a modelos más grandes en tareas de razonamiento, código y multimodales. Y Behemoth, aún en formación, ofrece una idea de cómo los modelos de profesor pueden dar forma a variantes más eficientes y desplegables.
El espacio de peso abierto es más competitivo que nunca. DeepSeek, Qwen, Gemma y pronto OpenAI están avanzando con fuertes lanzamientos. Llama 4 llega como continuación del esfuerzo continuo de Meta por ofrecer modelos escalables y de libre acceso para una serie de casos de uso.
Aprende IA con estos cursos
programa
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze

