
programa
Associate AI Engineer para desarrolladores
26 h
Imagina que estás montando muebles de IKEA. Miras fijamente el paso 14 de las instrucciones, pero no logras averiguar qué tornillo va en cada sitio. El diagrama muestra algo, pero no lo entiendo.
Si preguntaras: «¿Para qué sirve la pequeña pieza metálica del paso 14?». Un sistema estándar de generación aumentada por recuperación (RAG) basado en textono puede ayudar en este caso. La respuesta se encuentra en el propio diagrama, no en ningún texto de la página. Las instrucciones de IKEA son famosas por no incluir texto.
Aquí es donde entra en juego el RAG multimodal.
En este tutorial, te guiaré a través del proceso de creación de un sistema RAG multimodal capaz de responder preguntas sobre documentos que contienen imágenes, diagramas y contenido mixto. Usaremos las instrucciones de montaje de IKEA como caso de prueba, ya que son una buena prueba de resistencia: principalmente visuales, con un texto mínimo y del tipo de cosas con las que la gente realmente necesita ayuda.
Utilizaremos los modelos de OpenAI en todo momento: GPT-4o para comprender imágenes y generar respuestas, y text-embedding-3-small para crear vectores buscables. Para aprender a crear canalizaciones RAG con un marco diferente, recomiendo nuestro curso RAG con LangChain.
Al final, tendrás un sistema operativo que podrás ejecutar localmente y adaptar a tus propios documentos.
El RAG multimodal amplía el patrón RAG estándar para manejar más que solo texto. La idea central sigue siendo la misma, pero ahora el «contexto» incluye imágenes, tablas, diagramas y otros contenidos que no son texto.
¿Por qué es importante esto? Porque los documentos reales no son solo texto.
Piensa en con qué trabajas realmente:
Un sistema que solo procesa texto está trabajando con información incompleta. Es como intentar entender una receta leyendo solo la lista de ingredientes e ignorando las fotos que muestran cómo se hace realmente «mezclar suavemente».
El RAG tradicional trata un PDF como un flujo de caracteres. Extrae el texto, lo divide en fragmentos, incrusta esos fragmentos y da por terminado el proceso. Las imágenes se omiten por completo o se convierten en marcadores de posición « [IMAGE] ». Las tablas se convierten en filas de texto desordenadas que pierden su estructura.
El RAG multimodal adopta un enfoque diferente: Las imágenes se describen o se incrustan directamente, y las tablas se analizan en formatos estructurados. El sistema de recuperación puede relacionar una consulta como «diagrama de topología de red» tanto con descripciones textuales de la arquitectura de red como con diagramas visuales reales. El modelo generativo puede examinar una imagen y razonar sobre lo que representa.
|
Aspecto |
Solo texto RAG |
RAG multimodal |
|
Tipos de entrada |
Texto sin formato, tal vez marcado |
Texto, imágenes, tablas, diagramas, documentos mixtos. |
|
Lo que se incrusta |
Fragmentos de texto |
Fragmentos de texto más descripciones de imágenes o incrustaciones de imágenes. |
|
Modelo de generación |
Cualquier máster en Derecho |
Modelo de lenguaje visual (GPT-4o, Claude, Gemini) |
|
Ideal para |
Documentos con mucho texto |
Manuales, informes, diapositivas, cualquier cosa con contenido visual. |
Si «multimodal» todavía te parece un término genérico y poco claro, este blog sobreIA multimodal te ofrece una explicación detallada con ejemplos concretos.
El proceso tiene más partes móviles que el RAG solo de texto, pero la estructura es similar. Los datos se procesan e integran, se almacenan en un repositorio vectorial y se recuperan cuando alguien formula una pregunta.
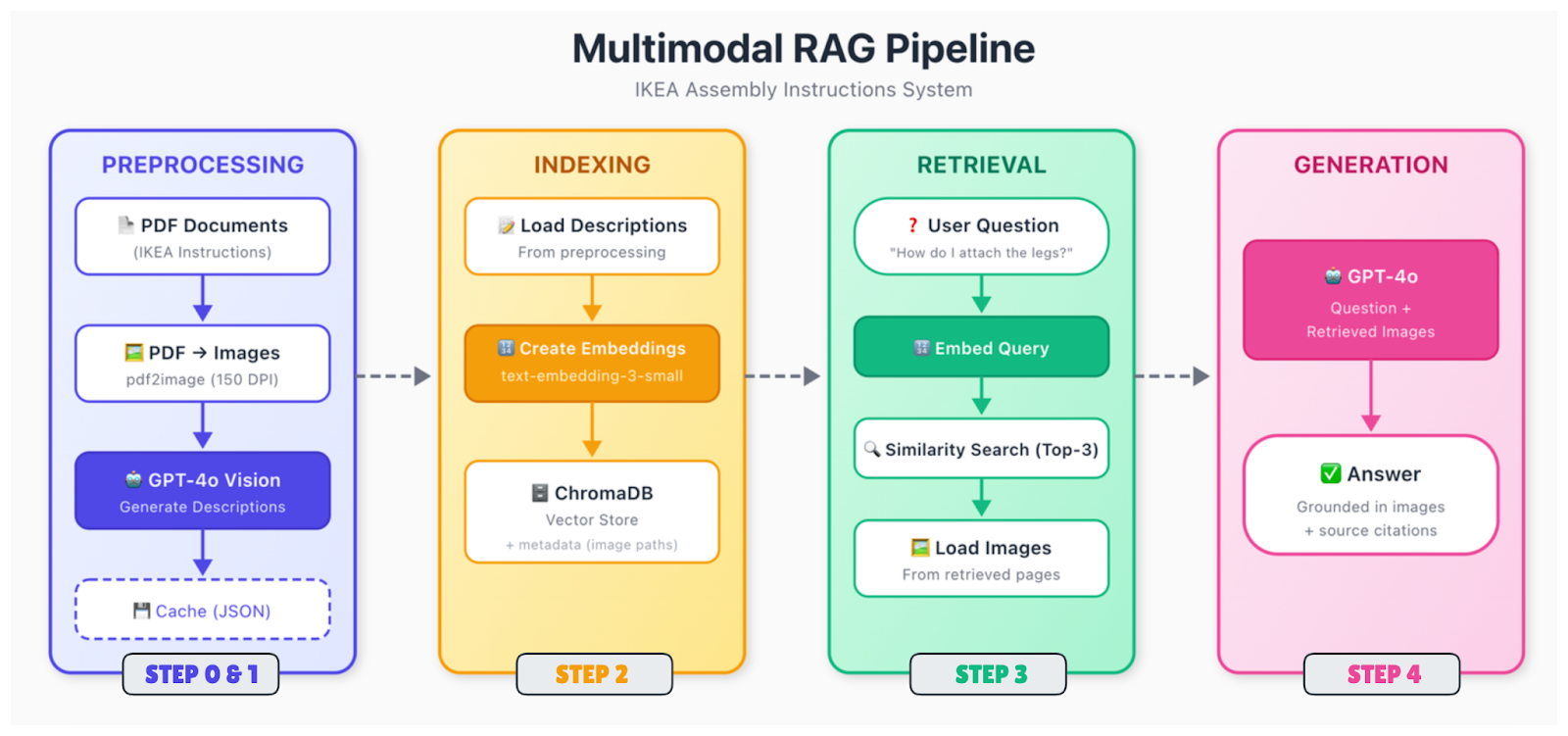
Este es el proceso:
Los documentos sin procesar (PDF, imágenes, diapositivas) se descomponen en sus partes componentes. Extraes texto, identificas imágenes, analizas tablas y averiguas cómo se relaciona todo espacialmente. Un diagrama de la página 5 puede tener una leyenda debajo y una referencia en el texto de la página 4. Es necesario capturar esas relaciones.
Los diferentes tipos de contenido requieren un tratamiento diferente. Para las imágenes, tienes dos opciones principales: generar descripciones de texto utilizando un modelo de visión (como GPT-4o) o incrustar imágenes directamente utilizando un codificador multimodal (como CLIP). El enfoque descriptivo es más sencillo y funciona con incrustaciones de texto estándar. Las tablas se convierten a formatos estructurados o se resumen en lenguaje natural.
Después de esto, todo se convierte a vectores. Si utilizas el enfoque de descripción, solo tienes que incrustar todo el texto (el texto original más las descripciones de imágenes generadas) con un modelo de incrustación de texto estándar. La clave es que ahora las consultas sobre contenido visual pueden coincidir con esas descripciones.
Los vectores se almacenan en una base de datos con metadatos, incluyendo el documento fuente, el número de página, el tipo de contenido y, en el caso de las imágenes, la ruta al archivo original. Necesitarás esa ruta de imagen más adelante, cuando quieras mostrarla al modelo de generación.
Cuando se recibe una consulta, incrústala utilizando el mismo modelo, busca los vecinos más cercanos y devuelve las coincidencias más relevantes. Los fragmentos recuperados pueden hacer referencia a texto, imágenes o ambos.
Pasa la consulta, junto con el contexto recuperado, a un modelo de visión-lenguaje. Si los fragmentos recuperados hacen referencia a imágenes, carga esas imágenes e inclúyelas en el mensaje. El modelo analiza tanto el contexto del texto como las imágenes reales y, a continuación, genera una respuesta.
El paso de generación es donde GPT-4o realmente destaca. Puede mirar un diagrama de IKEA que muestra la ubicación de los tornillos y explicar lo que está sucediendo en un lenguaje sencillo. Puede leer un gráfico y resumir la tendencia. Puede detectar detalles en los dibujos técnicos que una descripción textual podría pasar por alto.
Construyamos esto. Crearemos un sistema que pueda responder preguntas sobre las instrucciones de montaje de IKEA, pasando paso a paso desde la configuración hasta una interfaz de consulta funcional.
Para este tutorial, lo mantendremos sencillo:
|
Componente |
Elección |
¿Por qué? |
|
Incrustaciones |
text-embedding-3-small |
Barato, buena calidad, misma API. |
|
Almacén vectorial |
ChromaDB |
Se ejecuta localmente, sin configuración, persistente. |
|
Modelo de visión |
GPT-4o |
El mejor en su clase para la comprensión de imágenes |
|
Generación |
GPT-4o |
El mismo modelo, realiza ambas tareas. |
Podrías cambiarlo por alternativas. Pinecone o Weaviate para el almacén de vectores si necesitas escalabilidad. Claude o Gemini son buenas alternativaspara esta generación. La arquitectura general sigue siendo la misma en esos casos.
¿Por qué no utilizar CLIP o ColPali para las incrustaciones? Podrías. Te permiten incrustar imágenes directamente sin tener que generar primero descripciones de texto. Pero añaden complejidad y a menudo requieren una GPU. El enfoque descriptivo funciona bien para contenidos de tipo documental en los que se desea capturar detalles semánticos, y no solo similitudes visuales.
Comencemos con las dependencias y las variables de entorno para configurar el entorno de tu proyecto.
En primer lugar, necesitas tener instalad poppler para gestionar el procesamiento de PDF.
Ubuntu/Debian: sudo apt-get install poppler-utils
macOS (utilizando Homebrew): brew install poppler
Windows: Descárgalo desde la página de lanzamiento y añádelo a PATH.
A continuación, instala los paquetes de Python. Además de ChromaDB, necesitáis pdf2image para convertir archivos PDF a imágenes, pillow para procesar imágenes y requests para descargar los archivos PDF.
pip install openai chromadb pdf2image pillow requestsPara utilizar los modelos, configura tu clave API de OpenAI como variable de entorno.
Unix/Linux/macOS:
export OPENAI_API_KEY="your-api-key-here"Ventanas:
setx OPENAI_API_KEY="your-api-key-here"Ahora, vamos a configurar la estructura del proyecto y extraer los datos de muestra. El script ya incluye las URL de descarga, pero si deseas echar un vistazo primero a los archivos PDF, aquí tienes los enlaces directos al escritorio MALM y al somier MALM.
Crea un archivo llamado step1_setup.py:
"""
Step 1: Setup and Download Sample Data
"""
import os
import requests
# Create directories
for d in ["data", "data/images", "data/cache"]:
os.makedirs(d, exist_ok=True)
print("✓ Created directories")
# Download IKEA assembly instructions
SAMPLE_PDFS = {
"malm_desk.pdf": "https://www.ikea.com/us/en/assembly_instructions/malm-desk-white__AA-516949-7-2.pdf",
"malm_bed.pdf": "https://www.ikea.com/us/en/assembly_instructions/malm-bed-frame-low__AA-75286-15_pub.pdf",
}
for filename, url in SAMPLE_PDFS.items():
filepath = f"data/{filename}"
if not os.path.exists(filepath):
print(f"Downloading {filename}...")
response = requests.get(url, timeout=30)
with open(filepath, "wb") as f:
f.write(response.content)
print(f" ✓ Saved ({len(response.content) / 1024:.1f} KB)")
else:
print(f"✓ {filename} already exists")Para finalizar la configuración inicial, ejecuta el script:
python step1_setup.pyDeberías ver los archivos PDF de IKEA descargados en tu carpeta « data/ » (Descargas).
Las instrucciones de IKEA son complicadas. En su mayoría son diagramas con muy poco texto. Necesitamos convertir las páginas PDF en imágenes y, a continuación, utilizar GPT-4o para describir lo que muestra cada página.
Crear un step2_preprocess.py:
"""
Step 2: Preprocess Documents
Convert PDFs to images and generate descriptions with GPT-4o
"""
import os
import json
import base64
from pdf2image import convert_from_path
from openai import OpenAI
client = OpenAI()
DATA_DIR = "data"
IMAGES_DIR = "data/images"
CACHE_FILE = "data/cache/descriptions.json"
def convert_pdf_to_images(pdf_path):
"""Convert a PDF to page images."""
pdf_name = os.path.splitext(os.path.basename(pdf_path))[0]
images = convert_from_path(pdf_path, dpi=150)
image_paths = []
for i, image in enumerate(images):
image_path = f"{IMAGES_DIR}/{pdf_name}_page_{i+1:03d}.png"
image.save(image_path, "PNG")
image_paths.append(image_path)
return image_paths
def describe_page(image_path):
"""Use GPT-4o to describe an instruction page."""
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """Describe this IKEA assembly instruction page in detail.
Include: step numbers, parts shown, tools needed, actions demonstrated,
quantities (like "2x"), warnings, and part numbers if visible.
This description will help people find this page when they have questions."""
},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}},
{"type": "text", "text": "Describe this instruction page."}
]
}
],
max_tokens=500
)
return response.choices[0].message.content
def main():
# Load cache if exists
cache = {}
if os.path.exists(CACHE_FILE):
with open(CACHE_FILE, "r") as f:
cache = json.load(f)
all_pages = []
# Process each PDF
for pdf_file in os.listdir(DATA_DIR):
if not pdf_file.endswith(".pdf"):
continue
print(f"\nProcessing {pdf_file}...")
pdf_path = f"{DATA_DIR}/{pdf_file}"
# Convert to images
print(" Converting to images...")
image_paths = convert_pdf_to_images(pdf_path)
print(f" ✓ {len(image_paths)} pages")
# Generate descriptions
print(" Generating descriptions with GPT-4o...")
for i, image_path in enumerate(image_paths):
if image_path in cache:
description = cache[image_path]
status = "cached"
else:
description = describe_page(image_path)
cache[image_path] = description
# Save cache after each page
with open(CACHE_FILE, "w") as f:
json.dump(cache, f, indent=2)
status = "generated"
all_pages.append({
"source_pdf": pdf_file,
"page_number": i + 1,
"image_path": image_path,
"description": description
})
print(f" Page {i+1}/{len(image_paths)} [{status}]")
# Save all page data
with open("data/cache/all_pages.json", "w") as f:
json.dump(all_pages, f, indent=2)
print(f"\n✓ Processed {len(all_pages)} pages total")
if __name__ == "__main__":
main()Esto es lo que hacen las funciones:
convert_pdf_to_images(pdf_path): convierte cada página PDF en una imagen PNG a 150 ppp utilizando pdf2image. Esto extrae diagramas que carecen de texto seleccionable y los guarda con nombres coherentes, como malm_desk_page_001.png.
describe_page(image_path): codifica la imagen como base64 y la envía a GPT-4o con un mensaje del sistema personalizado. El modelo devuelve una descripción textual detallada que recoge los pasos, las piezas y las cantidades para la búsqueda semántica.
main(): coordina todo: Carga descripciones almacenadas en caché para evitar volver a procesarlas, convierte archivos PDF en imágenes, genera nuevas descripciones según sea necesario, guarda la caché incremental y genera un archivo all_pages.json con metadatos para su indexación.
Ejecuta el script de la siguiente manera:
python step2_preprocess.pyEste paso tarda unos minutos. GPT-4o analiza cada página y genera una descripción detallada. Las descripciones se almacenan en caché, por lo que si lo ejecutas de nuevo, se omiten las páginas que ya se han procesado.
¿Qué está pasando aquí? Estamos convirtiendo contenido visual en texto que se puede buscar. Cuando alguien pregunta «¿Cómo se colocan las patas?», el buscador buscará estas descripciones y encontrará páginas que mencionen la colocación de las patas, aunque la página original no contenga ningún texto.
Una vez que hayas creado el canal básico, los siguientes avances provienen de trucos de recuperación, como la búsqueda híbrida, la reclasificación o la reescritura de consultas. Para familiarizarte con ellas, lee este blog sobre Técnicas avanzadas de RAG.
Ahora incrustamos las descripciones y las almacenamos en ChromaDB.
Crear un step3_index.py:
"""
Step 3: Create Embeddings and Index
"""
import os
import json
from openai import OpenAI
import chromadb
client = OpenAI()
PAGES_FILE = "data/cache/all_pages.json"
CHROMA_DIR = "data/chroma_db"
COLLECTION_NAME = "ikea_instructions"
def get_embedding(text):
"""Get embedding from OpenAI."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def main():
# Load page descriptions
with open(PAGES_FILE, "r") as f:
pages = json.load(f)
print(f"Loaded {len(pages)} pages")
# Initialize ChromaDB with persistent storage
chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
# Delete existing collection if present
try:
chroma_client.delete_collection(name=COLLECTION_NAME)
except:
pass
collection = chroma_client.create_collection(
name=COLLECTION_NAME,
metadata={"hnsw:space": "cosine"}
)
print(f"Created collection: {COLLECTION_NAME}")
# Index each page
print("\nCreating embeddings...")
for i, page in enumerate(pages):
# Combine source info with description
text_to_embed = f"Source: {page['source_pdf']}, Page {page['page_number']}\n\n{page['description']}"
embedding = get_embedding(text_to_embed)
collection.add(
ids=[f"page_{i}"],
embeddings=[embedding],
documents=[page["description"]],
metadatas=[{
"source_pdf": page["source_pdf"],
"page_number": page["page_number"],
"image_path": page["image_path"]
}]
)
if (i + 1) % 5 == 0 or i == len(pages) - 1:
print(f" Indexed {i + 1}/{len(pages)} pages")
print(f"\n✓ Index created with {collection.count()} documents")
# Quick retrieval test
print("\nTesting retrieval...")
test_query = "How do I attach the legs?"
query_embedding = get_embedding(test_query)
results = collection.query(query_embeddings=[query_embedding], n_results=2)
print(f"Query: '{test_query}'")
for meta in results["metadatas"][0]:
print(f" → {meta['source_pdf']}, Page {meta['page_number']}")
if __name__ == "__main__":
main()Aquí, la función « get_embedding(text) » convierte el texto de la descripción y la información de origen en un vector denso utilizando el modelo « text-embedding-3-small » de OpenAI. Al tener 1536 dimensiones, esos vectores son capaces de capturar el significado semántico para la búsqueda por similitud.
main() Carga las páginas procesadas desde all_pages.json del paso anterior, inicializa ChromaDB con almacenamiento persistente, elimina/recrea la colección, genera incrustaciones para cada página, las almacena con metadatos enriquecidos (fuente, número de página, ruta de la imagen) y ejecuta una prueba de recuperación rápida para verificar que la indexación funciona.
Ejecuta:
python step3_index.pyLos metadatos son importantes en este caso. Almacenamos image_path para poder recuperar la imagen real más tarde y mostrársela a GPT-4o durante la generación. La descripción es lo que se busca, pero la imagen es lo que se muestra.
Aquí está el proceso RAG multimodal completo. Se incrusta una consulta, se recuperan las páginas relevantes, se cargan las imágenes y GPT-4o genera una respuesta basada en descripciones de texto e imágenes.
Crear un step4_query.py:
"""
Step 4: Query the Multimodal RAG System
"""
import os
import sys
import base64
from openai import OpenAI
import chromadb
client = OpenAI()
CHROMA_DIR = "data/chroma_db"
COLLECTION_NAME = "ikea_instructions"
TOP_K = 3
# Initialize ChromaDB
chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
def get_embedding(text):
"""Get embedding from OpenAI."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def retrieve(query, top_k=TOP_K):
"""Find relevant instruction pages."""
collection = chroma_client.get_collection(name=COLLECTION_NAME)
query_embedding = get_embedding(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
include=["documents", "metadatas"]
)
return results
def generate_answer(query, retrieved_results):
"""Generate answer using GPT-4o with retrieved images."""
if not retrieved_results["ids"][0]:
return "No relevant pages found.", []
# Build image content for GPT-4o
image_content = []
sources = []
for doc, metadata in zip(retrieved_results["documents"][0], retrieved_results["metadatas"][0]):
image_path = metadata["image_path"]
if not os.path.exists(image_path):
continue
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
image_content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{base64_image}"}
})
image_content.append({
"type": "text",
"text": f"[Page {metadata['page_number']} from {metadata['source_pdf']}]"
})
sources.append(f"{metadata['source_pdf']}, Page {metadata['page_number']}")
# Generate with GPT-4o
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """You answer questions about IKEA assembly based on instruction pages.
Be specific, reference page numbers when helpful, and say if something isn't clear from the images."""
},
{
"role": "user",
"content": [
{"type": "text", "text": f"Question: {query}\n\nRelevant instruction pages:"},
*image_content,
{"type": "text", "text": "Answer based on these pages."}
]
}
],
max_tokens=600
)
return response.choices[0].message.content, sources
def answer_question(query):
"""Full RAG pipeline."""
print(f"\nQuery: {query}")
print("-" * 50)
print("Retrieving relevant pages...")
results = retrieve(query)
print(f" Found {len(results['ids'][0])} pages")
print("Generating answer...")
answer, sources = generate_answer(query, results)
return answer, sources
def main():
# Check index exists
try:
collection = chroma_client.get_collection(name=COLLECTION_NAME)
print(f"Connected to index ({collection.count()} documents)")
except:
print("ERROR: Index not found. Run step2_index.py first.")
return
# Single query from command line
if len(sys.argv) > 1:
query = " ".join(sys.argv[1:])
answer, sources = answer_question(query)
print(f"\nAnswer:\n{answer}")
print(f"\nSources: {', '.join(sources)}")
return
# Interactive mode
print("\nAsk questions about IKEA assembly. Type 'quit' to exit.\n")
while True:
try:
query = input("Question: ").strip()
except KeyboardInterrupt:
break
if not query or query.lower() in ["quit", "exit"]:
break
answer, sources = answer_question(query)
print(f"\nAnswer:\n{answer}")
print(f"\nSources: {', '.join(sources)}\n")
if __name__ == "__main__":
main()Explicación de las funciones principales:
get_embedding(text): genera una incrustación vectorial para la consulta utilizando text-embedding-3-small, lo que permite realizar búsquedas semánticas por similitud en ChromaDB.
retrieve(query, top_k=TOP_K): incrusta la consulta, consulta la colección para obtener los k vecinos más cercanos y devuelve documentos y metadatos (por ejemplo, rutas de imágenes) a través de include=["documents", "metadatas"].
generate_answer(query, retrieved_results): carga las imágenes principales como base64, crea una indicación multimodal GPT-4o intercalando etiquetas de página e imágenes, y genera una respuesta detallada con instrucciones específicas de IKEA.
answer_question(query): coordina la recuperación y la generación, con registro del progreso.
main(): comprueba que el índice existe, admite consultas únicas CLI o modo de chat interactivo («quit», «exit» o Ctrl+C para detener).
Puedes ejecutarlo y escribir tu pregunta, o ejecutarlo directamente con una pregunta específica, así:
python step4_query.py "How do I attach the legs to the desk?"Retrieving relevant pages...
Found 3 pages
Generating answer...
Answer:
To attach the legs to the MALM desk, follow these steps shown on pages 5-6:
1. First, insert the wooden dowels into the pre-drilled holes on the leg
pieces (you'll see "4x" indicating four dowels are needed)
2. Apply the cam locks to the desk top using the Phillips screwdriver
3. Align each leg with the corresponding holes on the underside of the desk
4. Tighten the cam locks by rotating them clockwise until the legs are
firmly attached
The instructions show this should be done with the desk top face-down on
a soft surface to avoid scratching.
Sources: malm_desk.pdf, Page 5, malm_desk.pdf, Page 6, malm_desk.pdf, Page 7¡Se ve bien! El sistema recupera páginas basándose en las descripciones, carga las imágenes reales y GPT-4o genera una respuesta observando directamente los diagramas.
Crear un sistema RAG multimodal es una cosa. Saber si funciona bien es otra cosa. Y conseguir que funcione de forma fiable en producción añade otra capa de desafíos.
Las métricas RAG estándar siguen siendo válidas, pero es necesario ampliarlas para el contenido visual.
Precision@k mide cuántas de las páginas recuperadas eran realmente relevantes. Esto penalizaría a las páginas irrelevantes en el top-k, pero para la generación, tener la imagen clave es más importante que lograr un top-k perfecto.
Recall@k mide la frecuencia con la que las páginas correctas aparecen entre los k primeros resultados. Es más relevante para tu caso de uso de IKEA RAG porque queremos que el sistema encuentre al menos una página relevante entre los primeros k resultados (por ejemplo, k=3). De esta manera, GPT-4o obtiene contexto visual para responder correctamente, incluso si otros resultados son ruido.
Para nuestro sistema IKEA, crearías un conjunto de pruebas con unas 50 preguntas y etiquetarías las páginas «correctas» para cada una de ellas. A continuación, podrías evaluarlos utilizando la siguiente función:
def evaluate_retrieval(test_cases, top_k=3):
"""
test_cases: [{"query": str, "relevant_pages": ["image_path1", ...]}]
"""
hits = 0
for test in test_cases:
results = retrieve(test["query"], top_k=top_k)
retrieved = [m["image_path"] for m in results["metadatas"][0]]
if any(p in retrieved for p in test["relevant_pages"]):
hits += 1
return hits / len(test_cases)Algo que es más difícil de medir automáticamente es la calidad de la generación.
Podrías pedir a los usuarios que califiquen las respuestas en función de su precisión y utilidad, o utilizar un LLM como juez para evaluar si las respuestas son correctas teniendo en cuenta las imágenes de origen.
Para los diagramas con pasos numerados, verifica que el modelo asigne los números de paso correctos.
Otras evaluaciones podrían responder a las siguientes preguntas:
¿El sistema encuentra respuestas basadas en imágenes cuando la respuesta es visual?
Cuando el modelo hace referencia a algo en una imagen, ¿esa referencia es precisa?
Esto requiere una revisión manual, al menos para una muestra de consultas.
Si deseas crear un canal RAG multimodal listo para la producción, hay algunas cosas que debes tener en cuenta:
Los costes de preprocesamiento se acumulan: Las llamadas de Vision para describir imágenes son la parte más costosa. Para un corpus de documentos grande, procesa por lotes durante las horas de menor actividad y almacena en caché las descripciones de forma agresiva. Considera un modelo más económico (en nuestro caso, por ejemplo, GPT-4o-mini) para la generación de descripciones si la calidad es aceptable para tu caso de uso.
La latencia de las consultas es importante: GPT-4o con imágenes tarda entre 5 y 10 segundos por consulta. El streaming ayuda a los usuarios a ver resultados parciales rápidamente, y el almacenamiento en caché de consultas comunes ayuda con las preguntas repetidas. Recuperar 2 páginas en lugar de 5 puede marcar la diferencia en cuanto a tokens si ese contexto ya es suficiente.
Supervisa lo que debes supervisar: Latencia de recuperación de programas (debería ser inferior a 100 ms para colecciones pequeñas), latencia de generación (entre 5 y 10 segundos con imágenes), costes de API por consulta y comentarios de los usuarios, si los recopilas.
El manejo de errores te ahorra: Las cosas se rompen. Crea soluciones alternativas, como en el siguiente fragmento de código.
def answer_question_safe(query):
"""Wrapper with error handling."""
try:
return answer_question(query)
except Exception as e:
print(f"Error: {e}")
# Fall back to text-only using descriptions
results = retrieve(query)
if results["documents"][0]:
context = results["documents"][0][0][:500]
return f"Based on the instructions: {context}...", []
return "Sorry, couldn't process that question.", []Cuando tu canalización necesita dar varios pasos (buscar → verificar → volver a buscar → responder), RAG te ayudan a estructurarlo de forma clara.
El RAG multimodal amplía la generación aumentada por recuperación para manejar toda la gama de contenidos de los documentos del mundo real, incluyendo imágenes, diagramas, tablas y gráficos.
Lo utilizamos con éxito para consultar las instrucciones de IKEA, que son muy visuales, donde un enfoque basado únicamente en texto no habría funcionado. Todo el proceso se ejecuta localmentamente, excepto las llamadas a la API.
La idea clave es que no necesitas incrustaciones multimodales complejas para que esto funcione. Al generar buenas descripciones textuales del contenido visual, puedes utilizar la recuperación de texto estándar para encontrar imágenes relevantes y, a continuación, dejar que un modelo de lenguaje visual se encargue del trabajo pesado en el momento de la generación.
Si deseas ampliar los conocimientos adquiridos aquí, comienza tu andadura con el ingeniero de IA hoy mismo.
Cursos RAG
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan



