
Cursus
Associate AI Engineer pour développeurs
26 h
Imaginez que vous assemblez des meubles IKEA. Vous examinez attentivement l'étape 14 des instructions, mais vous ne parvenez pas à déterminer quelle vis doit être placée à quel endroit. Le diagramme présente certaines informations, mais cela ne me semble pas clair.
Si vous deviez demander : À quoi sert le petit élément métallique de l'étape 14 ? Un système standard de génération augmentée par la recherche (RAG) basé sur le texte ne peut pas apporter de réponse ici. La réponse se trouve dans le diagramme lui-même, et non dans le texte de la page. Les instructions IKEA sont réputées pour être dépourvues de texte.
C'est là qu'intervient le RAG multimodal.
Dans ce tutoriel, je vais vous guider dans la création d'un système RAG multimodal capable de répondre à des questions sur des documents contenant des images, des diagrammes et du contenu mixte. Nous utiliserons les instructions de montage IKEA comme cas test, car elles constituent un bon test de résistance : elles sont principalement visuelles, contiennent peu de texte et correspondent au type de document pour lequel les gens ont réellement besoin d'aide.
Nous utiliserons les modèles d'OpenAI tout au long du processus : GPT-4o pour la compréhension des images et la génération de réponses, et text-embedding-3-small pour la création de vecteurs consultables. Pour apprendre à créer des pipelines RAG avec un autre framework, je vous recommande notre cours RAG avec LangChain.
À la fin, vous disposerez d'un système opérationnel que vous pourrez exécuter localement et adapter à vos propres documents.
Le RAG multimodal étend le modèle RAG standard afin de traiter davantage que du texte. L'idée principale reste la même, mais le « contexte » inclut désormais les images, les tableaux, les diagrammes et tout autre contenu non textuel.
Pourquoi est-ce important ? Parce que les documents réels ne se limitent pas au texte.
Réfléchissez à ce avec quoi vous travaillez réellement :
Un système qui traite uniquement du texte fonctionne avec des informations incomplètes. C'est comme essayer de comprendre une recette en ne lisant que la liste des ingrédients et en ignorant les photos qui montrent ce que signifie réellement « mélanger délicatement ».
Le RAG traditionnel traite un PDF comme un flux de caractères. Il extrait le texte, le découpe en morceaux, intègre ces morceaux et considère que le travail est terminé. Certaines images peuvent être ignorées ou converties en jetons de remplacement [IMAGE]. Les tableaux se transforment en lignes de texte désordonnées qui perdent leur structure.
Le RAG multimodal adopte une approche différente : Les images sont décrites ou intégrées directement, et les tableaux sont analysés dans des formats structurés. Le système de recherche peut associer une requête telle que « schéma de topologie réseau » à la fois à des descriptions textuelles de l'architecture réseau et à des schémas visuels réels. Le modèle de génération peut analyser une image et déduire ce qu'elle représente.
|
Aspect |
Texte uniquement RAG |
RAG multimodal |
|
Types d'entrée |
Texte brut, éventuellement markdown |
Texte, images, tableaux, diagrammes, documents mixtes |
|
Ce qui est intégré |
Morceaux de texte |
Extraits de texte accompagnés de descriptions d'images ou d'intégrations d'images |
|
Modèle de génération |
Tout LLM |
Modèle de langage visuel (GPT-4o, Claude, Gemini) |
|
Idéal pour |
Documents contenant beaucoup de texte |
Manuels, rapports, diapositives, tout document contenant du contenu visuel |
Si le terme « multimodal » vous semble encore vague, cet article de blog surl'IA multimodale vous fournira des explications claires et des exemples concrets.
Le pipeline comporte davantage d'éléments mobiles que le RAG uniquement textuel, mais la structure est similaire. Les données sont traitées et intégrées, stockées dans un magasin vectoriel, puis récupérées lorsqu'une requête est effectuée.
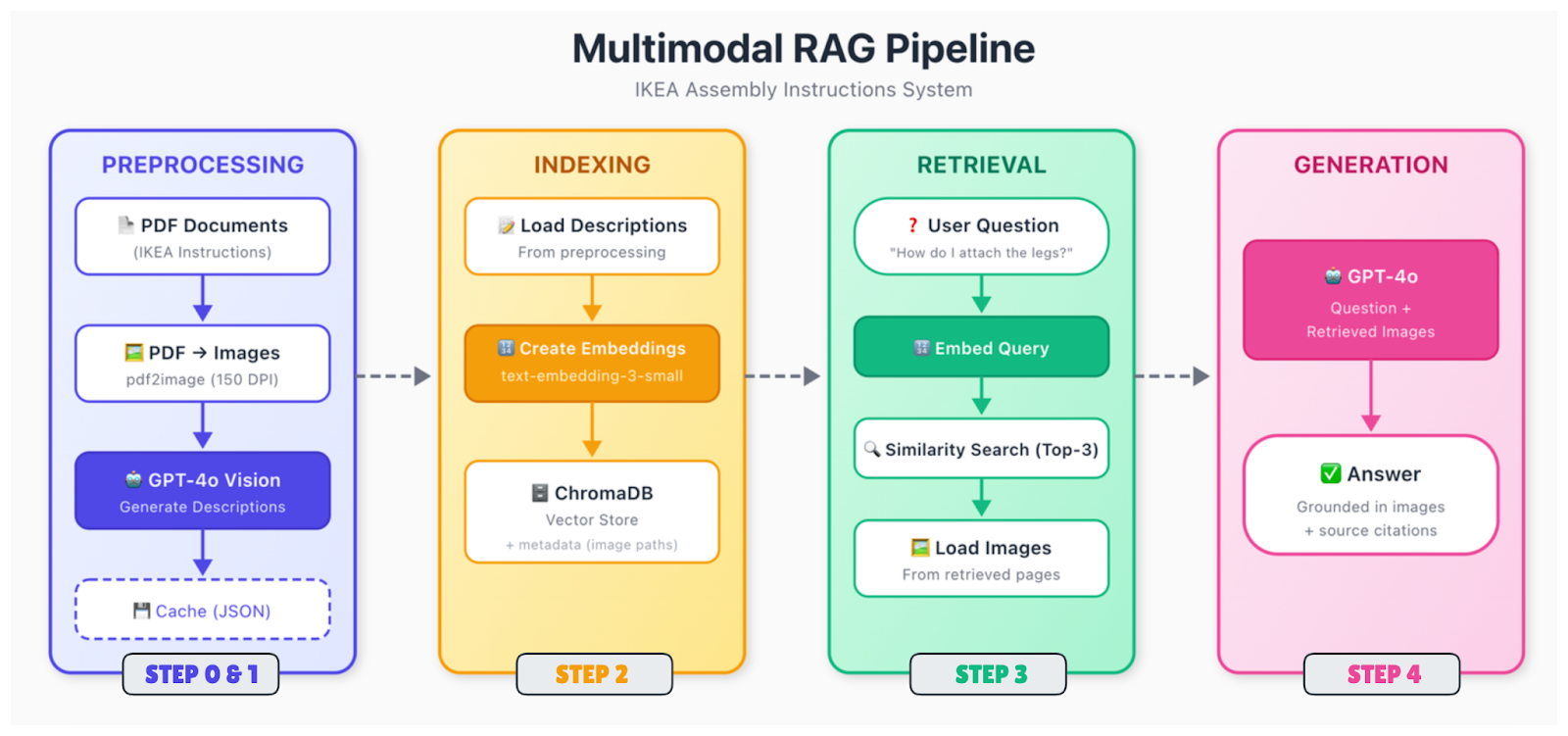
Voici le déroulement :
Les documents bruts (PDF, images, diapositives) sont décomposés en leurs éléments constitutifs. Vous extrayez du texte, identifiez des images, analysez des tableaux et déterminez comment tous ces éléments s'articulent dans l'espace. Un diagramme à la page 5 peut être accompagné d'une légende en dessous et d'une référence dans le texte à la page 4. Il est nécessaire de saisir ces relations.
Les différents types de contenu nécessitent un traitement distinct. Pour les images, deux options principales s'offrent à vous : générer des descriptions textuelles à l'aide d'un modèle de vision (tel que GPT-4o) ou intégrer directement les images à l'aide d'un encodeur multimodal (tel que CLIP). L'approche descriptive est plus simple et fonctionne avec des intégrations de texte standard. Les tableaux sont convertis en formats structurés ou résumés en langage naturel.
Par la suite, tous les éléments sont convertis en vecteurs. Si vous utilisez l'approche par description, il vous suffit d'intégrer l'ensemble de votre texte (texte original et descriptions d'images générées) à l'aide d'un modèle d'intégration de texte standard. La clé réside dans le fait que les requêtes relatives au contenu visuel peuvent désormais correspondre à ces descriptions.
Les vecteurs sont stockés dans une base de données avec des métadonnées, notamment le document source, le numéro de page, le type de contenu et, pour les images, le chemin d'accès au fichier d'origine. Vous aurez besoin de ce chemin d'accès à l'image ultérieurement lorsque vous souhaiterez l'afficher dans le modèle de génération.
Lorsqu'une requête est reçue, intégrez-la à l'aide du même modèle, recherchez les voisins les plus proches et renvoyez les correspondances les plus pertinentes. Les fragments récupérés peuvent faire référence à du texte, à des images ou aux deux.
Transmettez la requête, ainsi que le contexte récupéré, à un modèle de langage visuel. Si les segments récupérés font référence à des images, veuillez charger ces images et les inclure dans l'invite. Le modèle examine à la fois le contexte textuel et les images réelles, puis génère une réponse.
C'est au niveau de la génération que GPT-4o se distingue véritablement. Il est capable d'examiner un schéma IKEA indiquant l'emplacement des vis et d'expliquer clairement ce qui se passe. Il est capable d'analyser un graphique et de résumer la tendance. Il est capable de remarquer des détails dans les dessins techniques qui pourraient échapper à une description textuelle.
Nous allons construire cet objet. Nous allons développer un système capable de répondre aux questions relatives aux instructions de montage IKEA, en procédant étape par étape, de la configuration à la mise en place d'une interface de requête fonctionnelle.
Pour ce tutoriel, nous allons privilégier la simplicité :
|
Composant |
Choix |
Pourquoi |
|
Intégrations |
text-embedding-3-small |
Prix abordable, qualité supérieure, même API |
|
Magasin de vecteurs |
ChromaDB |
Fonctionne localement, aucune configuration requise, persistant |
|
Modèle de vision |
GPT-4o |
Le meilleur de sa catégorie pour la compréhension des images |
|
Génération |
GPT-4o |
Même modèle, convient aux deux tâches |
Il est possible d'utiliser des alternatives. Pinecone ou Weaviate pour le stockage vectoriel si vous avez besoin d'évolutivité. Claude ou Gemini constituent de bonnes alternatives pour cette génération. Dans ces cas, l'architecture générale reste inchangée.
Pourquoi ne pas utiliser CLIP ou ColPali pour les intégrations ? Vous pourriez. Ces derniers vous permettent d'intégrer des images directement sans avoir à générer au préalable des descriptions textuelles. Cependant, ils ajoutent de la complexité et nécessitent souvent un GPU. L'approche descriptive est particulièrement adaptée aux contenus de type documentaire pour lesquels il est important de saisir les détails sémantiques, et pas seulement la similitude visuelle.
Commençons par les dépendances et les variables d'environnement afin de configurer l'environnement de notre projet.
Tout d'abord, il est nécessaire d'installer poppler pour gérer le traitement des fichiers PDF.
Ubuntu/Debian : sudo apt-get install poppler-utils
macOS (à l'aide de Homebrew) : brew install poppler
Windows : Veuillez télécharger depuis la page de publication et ajouter au PATH.
Ensuite, veuillez installer les paquets Python. Outre ChromaDB, nous avons besoin de pdf2image pour convertir les fichiers PDF en images, de pillow pour le traitement des images et de requests pour télécharger les fichiers PDF.
pip install openai chromadb pdf2image pillow requestsPour utiliser les modèles, veuillez définir votre clé API OpenAI en tant que variable d'environnement.
Unix/Linux/macOS :
export OPENAI_API_KEY="your-api-key-here"Windows :
setx OPENAI_API_KEY="your-api-key-here"Maintenant, veuillez configurer la structure du projet et récupérer les données d'exemple. Le script contient déjà les URL de téléchargement, mais si vous souhaitez d'abord consulter les fichiers PDF, voici les liens directs vers le bureau MALM et le cadre de lit MALM.
Veuillez créer un fichier nommé step1_setup.py:
"""
Step 1: Setup and Download Sample Data
"""
import os
import requests
# Create directories
for d in ["data", "data/images", "data/cache"]:
os.makedirs(d, exist_ok=True)
print("✓ Created directories")
# Download IKEA assembly instructions
SAMPLE_PDFS = {
"malm_desk.pdf": "https://www.ikea.com/us/en/assembly_instructions/malm-desk-white__AA-516949-7-2.pdf",
"malm_bed.pdf": "https://www.ikea.com/us/en/assembly_instructions/malm-bed-frame-low__AA-75286-15_pub.pdf",
}
for filename, url in SAMPLE_PDFS.items():
filepath = f"data/{filename}"
if not os.path.exists(filepath):
print(f"Downloading {filename}...")
response = requests.get(url, timeout=30)
with open(filepath, "wb") as f:
f.write(response.content)
print(f" ✓ Saved ({len(response.content) / 1024:.1f} KB)")
else:
print(f"✓ {filename} already exists")Pour terminer la configuration initiale, veuillez exécuter le script :
python step1_setup.pyLes fichiers PDF IKEA devraient être téléchargés dans votre dossier « data/ ».
Les instructions IKEA peuvent être complexes. Il s'agit principalement de diagrammes accompagnés d'un minimum de texte. Nous devons convertir les pages PDF en images, puis utiliser GPT-4o pour décrire le contenu de chaque page.
Créer un step2_preprocess.py:
"""
Step 2: Preprocess Documents
Convert PDFs to images and generate descriptions with GPT-4o
"""
import os
import json
import base64
from pdf2image import convert_from_path
from openai import OpenAI
client = OpenAI()
DATA_DIR = "data"
IMAGES_DIR = "data/images"
CACHE_FILE = "data/cache/descriptions.json"
def convert_pdf_to_images(pdf_path):
"""Convert a PDF to page images."""
pdf_name = os.path.splitext(os.path.basename(pdf_path))[0]
images = convert_from_path(pdf_path, dpi=150)
image_paths = []
for i, image in enumerate(images):
image_path = f"{IMAGES_DIR}/{pdf_name}_page_{i+1:03d}.png"
image.save(image_path, "PNG")
image_paths.append(image_path)
return image_paths
def describe_page(image_path):
"""Use GPT-4o to describe an instruction page."""
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """Describe this IKEA assembly instruction page in detail.
Include: step numbers, parts shown, tools needed, actions demonstrated,
quantities (like "2x"), warnings, and part numbers if visible.
This description will help people find this page when they have questions."""
},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}},
{"type": "text", "text": "Describe this instruction page."}
]
}
],
max_tokens=500
)
return response.choices[0].message.content
def main():
# Load cache if exists
cache = {}
if os.path.exists(CACHE_FILE):
with open(CACHE_FILE, "r") as f:
cache = json.load(f)
all_pages = []
# Process each PDF
for pdf_file in os.listdir(DATA_DIR):
if not pdf_file.endswith(".pdf"):
continue
print(f"\nProcessing {pdf_file}...")
pdf_path = f"{DATA_DIR}/{pdf_file}"
# Convert to images
print(" Converting to images...")
image_paths = convert_pdf_to_images(pdf_path)
print(f" ✓ {len(image_paths)} pages")
# Generate descriptions
print(" Generating descriptions with GPT-4o...")
for i, image_path in enumerate(image_paths):
if image_path in cache:
description = cache[image_path]
status = "cached"
else:
description = describe_page(image_path)
cache[image_path] = description
# Save cache after each page
with open(CACHE_FILE, "w") as f:
json.dump(cache, f, indent=2)
status = "generated"
all_pages.append({
"source_pdf": pdf_file,
"page_number": i + 1,
"image_path": image_path,
"description": description
})
print(f" Page {i+1}/{len(image_paths)} [{status}]")
# Save all page data
with open("data/cache/all_pages.json", "w") as f:
json.dump(all_pages, f, indent=2)
print(f"\n✓ Processed {len(all_pages)} pages total")
if __name__ == "__main__":
main()Voici ce que font les fonctions :
convert_pdf_to_images(pdf_path): convertit chaque page PDF en image PNG à 150 DPI à l'aide de pdf2image. Cette fonction extrait les diagrammes qui ne contiennent pas de texte sélectionnable et les enregistre avec un nom cohérent, tel que malm_desk_page_001.png.
describe_page(image_path): encode l'image sous forme d'base64 s et l'envoie à GPT-4o avec une invite système personnalisée. Le modèle fournit une description textuelle détaillée qui inclut les étapes, les pièces et les quantités pour la recherche sémantique.
main(): coordonne l'ensemble : Il charge les descriptions mises en cache pour éviter tout nouveau traitement, convertit les fichiers PDF en images, génère de nouvelles descriptions si nécessaire, enregistre le cache incrémentiel et génère des fichiers d'all_pages.json s avec des métadonnées pour l'indexation.
Veuillez exécuter le script de la manière suivante :
python step2_preprocess.pyCette étape prend quelques minutes. GPT-4o analyse chaque page et génère une description détaillée. Les descriptions sont mises en cache, donc si vous relancez le processus, les pages déjà traitées seront ignorées.
Que se passe-t-il ici ? Nous convertissons le contenu visuel en texte pouvant faire l'objet d'une recherche. Lorsqu'un utilisateur demande « Comment fixer les pieds ? », le système de recherche va parcourir ces descriptions et trouver les pages qui mentionnent la fixation des pieds, même si la page d'origine ne contient aucun texte.
Une fois que vous avez mis en place le pipeline de base, les prochains gains proviennent des techniques de récupération, telles que la recherche hybride, le reclassement ou la réécriture des requêtes. Pour vous familiariser avec ces techniques, veuillez consulter ce blog sur les Techniques avancées de RAG.
Nous intégrons maintenant les descriptions et les stockons dans ChromaDB.
Créer un step3_index.py:
"""
Step 3: Create Embeddings and Index
"""
import os
import json
from openai import OpenAI
import chromadb
client = OpenAI()
PAGES_FILE = "data/cache/all_pages.json"
CHROMA_DIR = "data/chroma_db"
COLLECTION_NAME = "ikea_instructions"
def get_embedding(text):
"""Get embedding from OpenAI."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def main():
# Load page descriptions
with open(PAGES_FILE, "r") as f:
pages = json.load(f)
print(f"Loaded {len(pages)} pages")
# Initialize ChromaDB with persistent storage
chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
# Delete existing collection if present
try:
chroma_client.delete_collection(name=COLLECTION_NAME)
except:
pass
collection = chroma_client.create_collection(
name=COLLECTION_NAME,
metadata={"hnsw:space": "cosine"}
)
print(f"Created collection: {COLLECTION_NAME}")
# Index each page
print("\nCreating embeddings...")
for i, page in enumerate(pages):
# Combine source info with description
text_to_embed = f"Source: {page['source_pdf']}, Page {page['page_number']}\n\n{page['description']}"
embedding = get_embedding(text_to_embed)
collection.add(
ids=[f"page_{i}"],
embeddings=[embedding],
documents=[page["description"]],
metadatas=[{
"source_pdf": page["source_pdf"],
"page_number": page["page_number"],
"image_path": page["image_path"]
}]
)
if (i + 1) % 5 == 0 or i == len(pages) - 1:
print(f" Indexed {i + 1}/{len(pages)} pages")
print(f"\n✓ Index created with {collection.count()} documents")
# Quick retrieval test
print("\nTesting retrieval...")
test_query = "How do I attach the legs?"
query_embedding = get_embedding(test_query)
results = collection.query(query_embeddings=[query_embedding], n_results=2)
print(f"Query: '{test_query}'")
for meta in results["metadatas"][0]:
print(f" → {meta['source_pdf']}, Page {meta['page_number']}")
if __name__ == "__main__":
main()Ici, la fonction « get_embedding(text) » convertit le texte de la description et des informations sources en un vecteur dense à l'aide du modèle OpenAI « text-embedding-3-small ». Étant donné qu'ils sont à 1536 dimensions, ces vecteurs sont capables de saisir la signification sémantique pour la recherche par similarité.
main() charge les pages traitées à partir de all_pages.json à partir de l'étape précédente, initialise ChromaDB avec un stockage persistant, supprime/recrée la collection, génère des intégrations pour chaque page, les stocke avec des métadonnées riches (source, numéro de page, chemin d'accès à l'image) et effectue un test de récupération rapide pour vérifier que l'indexation fonctionne.
Veuillez l'exécuter :
python step3_index.pyLes métadonnées sont importantes dans ce contexte. Nous stockons l'image_path afin de pouvoir récupérer l'image réelle ultérieurement et la présenter à GPT-4o pendant la génération. La description est ce qui est recherché, mais l'image est ce qui est affiché.
Voici le pipeline RAG multimodal complet. Une requête est intégrée, les pages pertinentes sont récupérées, les images sont chargées et GPT-4o génère une réponse basée sur les descriptions textuelles et les visuels.
Créer un step4_query.py:
"""
Step 4: Query the Multimodal RAG System
"""
import os
import sys
import base64
from openai import OpenAI
import chromadb
client = OpenAI()
CHROMA_DIR = "data/chroma_db"
COLLECTION_NAME = "ikea_instructions"
TOP_K = 3
# Initialize ChromaDB
chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
def get_embedding(text):
"""Get embedding from OpenAI."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def retrieve(query, top_k=TOP_K):
"""Find relevant instruction pages."""
collection = chroma_client.get_collection(name=COLLECTION_NAME)
query_embedding = get_embedding(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
include=["documents", "metadatas"]
)
return results
def generate_answer(query, retrieved_results):
"""Generate answer using GPT-4o with retrieved images."""
if not retrieved_results["ids"][0]:
return "No relevant pages found.", []
# Build image content for GPT-4o
image_content = []
sources = []
for doc, metadata in zip(retrieved_results["documents"][0], retrieved_results["metadatas"][0]):
image_path = metadata["image_path"]
if not os.path.exists(image_path):
continue
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
image_content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{base64_image}"}
})
image_content.append({
"type": "text",
"text": f"[Page {metadata['page_number']} from {metadata['source_pdf']}]"
})
sources.append(f"{metadata['source_pdf']}, Page {metadata['page_number']}")
# Generate with GPT-4o
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """You answer questions about IKEA assembly based on instruction pages.
Be specific, reference page numbers when helpful, and say if something isn't clear from the images."""
},
{
"role": "user",
"content": [
{"type": "text", "text": f"Question: {query}\n\nRelevant instruction pages:"},
*image_content,
{"type": "text", "text": "Answer based on these pages."}
]
}
],
max_tokens=600
)
return response.choices[0].message.content, sources
def answer_question(query):
"""Full RAG pipeline."""
print(f"\nQuery: {query}")
print("-" * 50)
print("Retrieving relevant pages...")
results = retrieve(query)
print(f" Found {len(results['ids'][0])} pages")
print("Generating answer...")
answer, sources = generate_answer(query, results)
return answer, sources
def main():
# Check index exists
try:
collection = chroma_client.get_collection(name=COLLECTION_NAME)
print(f"Connected to index ({collection.count()} documents)")
except:
print("ERROR: Index not found. Run step2_index.py first.")
return
# Single query from command line
if len(sys.argv) > 1:
query = " ".join(sys.argv[1:])
answer, sources = answer_question(query)
print(f"\nAnswer:\n{answer}")
print(f"\nSources: {', '.join(sources)}")
return
# Interactive mode
print("\nAsk questions about IKEA assembly. Type 'quit' to exit.\n")
while True:
try:
query = input("Question: ").strip()
except KeyboardInterrupt:
break
if not query or query.lower() in ["quit", "exit"]:
break
answer, sources = answer_question(query)
print(f"\nAnswer:\n{answer}")
print(f"\nSources: {', '.join(sources)}\n")
if __name__ == "__main__":
main()Explication des fonctions principales :
get_embedding(text): génère un vecteur d'intégration pour la requête à l'aide d'text-embedding-3-small, permettant ainsi une recherche sémantique par similarité dans ChromaDB.
retrieve(query, top_k=TOP_K): intègre la requête, interroge la collection pour trouver les k voisins les plus proches et renvoie les documents et les métadonnées (par exemple, les chemins d'accès aux images) via include=["documents", "metadatas"].
generate_answer(query, retrieved_results): charge les images principales sous forme d'base64, crée une invite multimodale GPT-4o entrelaçant les étiquettes de page et les images, et génère une réponse détaillée avec des instructions spécifiques à IKEA.
answer_question(query): coordonne la récupération et la génération, avec journalisation de la progression.
main(): vérifie que l'index existe, prend en charge les requêtes CLI uniques ou le mode de chat interactif (« quit », « exit » ou Ctrl+C pour arrêter).
Vous pouvez l'exécuter et saisir votre question, ou l'exécuter directement avec une question spécifique, comme ceci :
python step4_query.py "How do I attach the legs to the desk?"Retrieving relevant pages...
Found 3 pages
Generating answer...
Answer:
To attach the legs to the MALM desk, follow these steps shown on pages 5-6:
1. First, insert the wooden dowels into the pre-drilled holes on the leg
pieces (you'll see "4x" indicating four dowels are needed)
2. Apply the cam locks to the desk top using the Phillips screwdriver
3. Align each leg with the corresponding holes on the underside of the desk
4. Tighten the cam locks by rotating them clockwise until the legs are
firmly attached
The instructions show this should be done with the desk top face-down on
a soft surface to avoid scratching.
Sources: malm_desk.pdf, Page 5, malm_desk.pdf, Page 6, malm_desk.pdf, Page 7Cela semble très bien. Le système récupère les pages en fonction des descriptions, charge les images réelles, et GPT-4o génère une réponse en examinant directement les diagrammes.
Construire un système RAG multimodal est une chose. Savoir si cela fonctionne efficacement est une autre question. Et le fait de le faire fonctionner de manière fiable en production ajoute une autre couche de défis.
Les mesures RAG standard restent applicables, mais il est nécessaire de les étendre au contenu visuel.
Precision@k mesure le nombre de pages récupérées qui étaient réellement pertinentes. Cela pénaliserait les pages non pertinentes dans le top-k, mais pour la génération, il est plus important d'avoir l'image clé que d'atteindre un top-k parfait.
Recall@k mesure la fréquence à laquelle les pages correctes apparaissent dans vos k premiers résultats. Cela est plus pertinent pour votre cas d'utilisation IKEA RAG, car nous souhaitons que le système trouve au moins une page pertinente dans les k premiers résultats (par exemple, k=3). De cette manière, GPT-4o obtient un contexte visuel lui permettant de répondre correctement, même si d'autres résultats sont considérés comme du bruit.
Pour notre système IKEA, vous devriez créer un ensemble de tests comprenant environ 50 questions et identifier les pages « correctes » pour chacune d'entre elles. Ensuite, vous pourriez les évaluer à l'aide de la fonction suivante :
def evaluate_retrieval(test_cases, top_k=3):
"""
test_cases: [{"query": str, "relevant_pages": ["image_path1", ...]}]
"""
hits = 0
for test in test_cases:
results = retrieve(test["query"], top_k=top_k)
retrieved = [m["image_path"] for m in results["metadatas"][0]]
if any(p in retrieved for p in test["relevant_pages"]):
hits += 1
return hits / len(test_cases)La qualité de la génération est un élément plus difficile à mesurer automatiquement.
Vous pourriez demander aux utilisateurs d'évaluer la précision et l'utilité des réponses, ou utiliser un LLM comme juge pour évaluer si les réponses sont correctes par rapport aux images sources.
Pour les diagrammes comportant des étapes numérotées, veuillez vérifier que le modèle attribue les numéros d'étape corrects.
Des évaluations supplémentaires pourraient répondre aux questions suivantes :
Le système trouve-t-il des réponses basées sur des images lorsque la réponse est visuelle ?
Lorsque le modèle fait référence à un élément dans une image, cette référence est-elle exacte ?
Ces derniers nécessitent une vérification manuelle, au moins pour un échantillon de requêtes.
Si vous souhaitez développer un pipeline RAG multimodal prêt pour la production, il est important de prendre en compte les éléments suivants :
Les coûts de prétraitement s'accumulent : Les appels à la description d'images constituent la partie la plus coûteuse. Pour un corpus de documents volumineux, il est recommandé de procéder à un traitement par lots pendant les heures creuses et de mettre en cache les descriptions de manière intensive. Envisagez un modèle plus économique (dans notre cas, par exemple, GPT-4o-mini) pour la génération de descriptions si la qualité est acceptable pour votre utilisation.
La latence des requêtes est importante : GPT-4o avec images nécessite entre 5 et 10 secondes par requête. Le streaming permet aux utilisateurs de visualiser rapidement des résultats partiels, et la mise en cache des requêtes courantes facilite le traitement des questions répétitives. Récupérer 2 pages au lieu de 5 peut faire une différence en termes de jetons si cela suffit déjà comme contexte.
Surveillez les éléments pertinents : Veuillez noter le temps de latence pour la récupération des pistes (qui devrait être inférieur à 100 ms pour les petites collections), le temps de latence pour la génération (comptez entre 5 et 10 secondes pour les images), les coûts API par requête et les commentaires des utilisateurs si vous les collectez.
La gestion des erreurs vous permet de : Les objets peuvent se casser. Créez des solutions de secours, comme dans l'extrait de code suivant.
def answer_question_safe(query):
"""Wrapper with error handling."""
try:
return answer_question(query)
except Exception as e:
print(f"Error: {e}")
# Fall back to text-only using descriptions
results = retrieve(query)
if results["documents"][0]:
context = results["documents"][0][0][:500]
return f"Based on the instructions: {context}...", []
return "Sorry, couldn't process that question.", []Lorsque votre pipeline nécessite plusieurs étapes (recherche → vérifier → recherche → répondre), RAG agentique vous aident à le structurer de manière claire.
Le RAG multimodal étend la génération augmentée par la recherche afin de traiter l'ensemble du contenu des documents du monde réel, y compris les images, les diagrammes, les tableaux et les graphiques.
Nous l'avons utilisé avec succès pour consulter les instructions IKEA, qui sont réputées pour leur aspect visuel, où une approche uniquement textuelle n'aurait pas été efficace. L'ensemble du pipeline fonctionnede manière locale, à l'exception des appels API.
L'idée principale est qu'il n'est pas nécessaire de recourir à des intégrations multimodales complexes pour que cela fonctionne. En générant des descriptions textuelles pertinentes du contenu visuel, vous pouvez utiliser la recherche textuelle standard pour trouver des images pertinentes, puis laisser un modèle de langage visuel effectuer le travail de génération.
Si vous souhaitez approfondir les sujets abordés ici, veuillez commencer votre parcours avec le parcours professionnel d'ingénieur en IA dès aujourd'hui, le cursus.
Cours RAG
Cursus
Cours
Cours