
Programa
Associate AI Engineer para desenvolvedores
26 h
Imagina que você está montando móveis da IKEA. Você fica olhando para o passo 14 das instruções, mas não consegue descobrir qual parafuso vai em cada lugar. O diagrama mostra algo, mas não está fazendo sentido.
Se você perguntasse: “Pra que serve a peça pequena de metal na etapa 14?”, um sistema padrão de geração aumentada por recuperação (RAG) baseado em texto não pode ajudar aqui. A resposta está no próprio diagrama, não em nenhum texto na página. As instruções da IKEA são famosas por não terem palavras.
É aí que entra o RAG multimodal.
Neste tutorial, vou te mostrar como criar um sistema RAG multimodal que pode responder perguntas sobre documentos com imagens, diagramas e conteúdo misto. Vamos usar as instruções de montagem da IKEA como nosso caso de teste, porque elas são um bom teste de estresse: principalmente visuais, com pouco texto e do tipo que as pessoas realmente precisam de ajuda.
Vamos usar os modelos da OpenAI em todo o processo: GPT-4o para entender imagens e gerar respostas, e text-embedding-3-small para criar vetores pesquisáveis. Pra aprender a montar pipelines RAG com uma estrutura diferente, recomendo nosso curso RAG com LangChain.
No final, você vai ter um sistema que funciona, que pode rodar localmente e adaptar para seus próprios documentos.
O RAG multimodal amplia o padrão RAG padrão para lidar com mais do que apenas texto. A ideia principal continua a mesma, mas agora o “contexto” inclui imagens, tabelas, diagramas e outros conteúdos que não são texto.
Por que isso é importante? Porque documentos reais não são só texto.
Pense no que você realmente trabalha:
Um sistema que só processa texto está trabalhando com informações incompletas. É como tentar entender uma receita só lendo a lista de ingredientes e ignorando as fotos que mostram como é realmente “misturar delicadamente”.
O RAG tradicional trata um PDF como um fluxo de caracteres. Ele pega o texto, divide em pedaços, coloca esses pedaços e pronto. Todas as imagens são ignoradas completamente ou talvez convertidas em tokens de espaço reservado [IMAGE]. As tabelas viram linhas de texto bagunçadas que perdem a estrutura.
O RAG multimodal tem uma abordagem diferente: As imagens são descritas ou incorporadas diretamente, e as tabelas são analisadas em formatos estruturados. O sistema de recuperação pode combinar uma consulta como “diagrama de topologia de rede” com descrições de texto da arquitetura de rede e diagramas visuais reais. O modelo de geração pode analisar uma imagem e deduzir o que ela representa.
|
Aspecto |
RAG somente texto |
Multimodal RAG |
|
Tipos de entrada |
Texto simples, talvez markdown |
Texto, imagens, tabelas, diagramas, documentos mistos |
|
O que fica incorporado |
Trechos de texto |
Trechos de texto mais descrições de imagens ou incorporações de imagens |
|
Modelo de geração |
Any LLM |
Modelo de linguagem visual (GPT-4o, Claude, Gemini) |
|
Ideal para |
Documentos com muito texto |
Manuais, relatórios, slides, qualquer coisa com conteúdo visual |
Se “multimodal” ainda parece um termo genérico e confuso, este blog sobreIA multimodal é uma explicação clara com exemplos concretos.
O pipeline tem mais partes móveis do que o RAG só de texto, mas a estrutura é parecida. Os dados são processados e incorporados, vão parar em um armazenamento vetorial e são recuperados quando alguém faz uma pergunta.
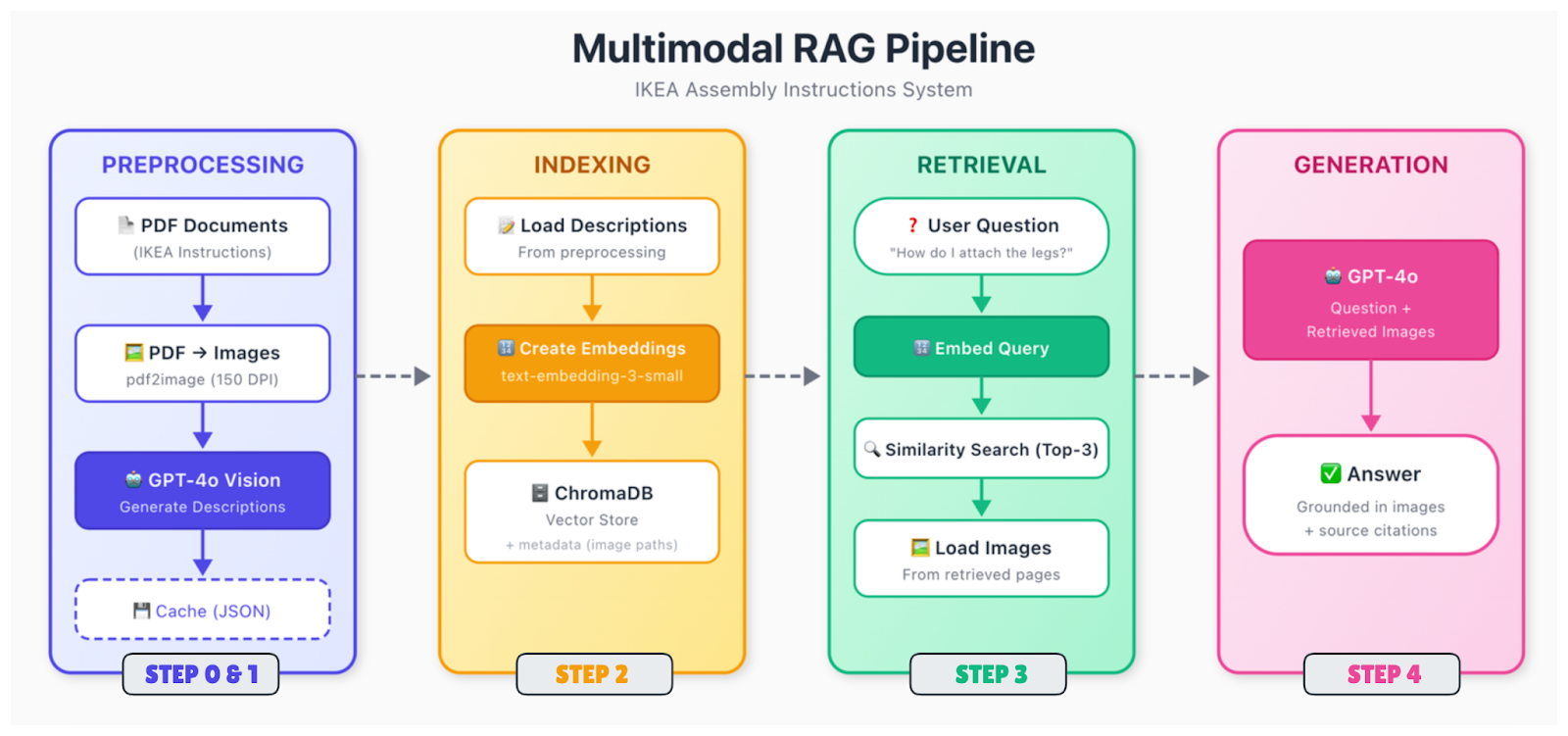
E aí, o fluxo é assim:
Os documentos brutos (PDFs, imagens, slides) são divididos em suas partes componentes. Você extrai texto, identifica imagens, analisa tabelas e descobre como tudo se relaciona espacialmente. Um diagrama na página 5 pode ter uma legenda abaixo dele e uma referência no texto da página 4. Você precisa entender essas relações.
Tipos de conteúdo diferentes precisam de um tratamento diferente. Para imagens, você tem duas opções principais: gerar descrições de texto usando um modelo de visão (como o GPT-4o) ou incorporar imagens diretamente usando um codificador multimodal (como o CLIP). A abordagem descritiva é mais direta e funciona com incorporações de texto padrão. As tabelas são convertidas para formatos estruturados ou resumidas em linguagem natural.
Depois disso, tudo é convertido em vetores. Se você estiver usando a abordagem de descrição, basta incorporar todo o seu texto (texto original mais descrições de imagens geradas) com um modelo padrão de incorporação de texto. O importante é que agora as consultas sobre conteúdo visual podem corresponder a essas descrições.
Os vetores são guardados em um banco de dados com metadados, incluindo o documento original, o número da página, o tipo de conteúdo e, para imagens, o caminho para o arquivo original. Você vai precisar desse caminho da imagem mais tarde, quando quiser mostrá-la ao modelo de geração.
Quando receber uma consulta, use o mesmo modelo, procure os vizinhos mais próximos e mostre os resultados mais relevantes. Os trechos recuperados podem fazer referência a texto, imagens ou ambos.
Passe a consulta, junto com o contexto recuperado, para um modelo de linguagem visual. Se os trechos recuperados fizerem referência a imagens, carregue essas imagens e inclua-as no prompt. O modelo analisa tanto o contexto do texto quanto as imagens reais e, em seguida, gera uma resposta.
A etapa de geração é onde o GPT-4o realmente se destaca. Ele pode olhar um diagrama da IKEA mostrando a colocação dos parafusos e explicar o que está acontecendo em linguagem simples. Ele consegue ler um gráfico e resumir a tendência. Ele consegue perceber detalhes em desenhos técnicos que uma descrição em texto pode deixar passar.
Vamos construir isso. Vamos criar um sistema que possa responder a perguntas sobre as instruções de montagem da IKEA, passo a passo, desde a configuração até uma interface de consulta funcional.
Pra esse tutorial, vamos manter as coisas simples:
|
Componente |
Escolha |
Por que |
|
Incorporações |
text-embedding-3-small |
Barato, boa qualidade, mesma API |
|
Armazenamento vetorial |
ChromaDB |
Funciona localmente, sem configuração, persistente |
|
Modelo de visão |
GPT-4o |
O melhor da categoria em compreensão de imagens |
|
Geração |
GPT-4o |
O mesmo modelo dá conta das duas tarefas |
Você pode trocar por alternativas. Pinecone ou Weaviate para o armazenamento de vetores, se você precisar de escala. Claude ou Gemini são boas alternativasivas para a geração. A arquitetura geral continua a mesma nesses casos.
Por que não usar CLIP ou ColPali para incorporações? Você poderia. Esses permitem que você insira imagens diretamente, sem precisar criar descrições de texto antes. Mas eles tornam tudo mais complicado e muitas vezes precisam de uma GPU. A abordagem descritiva funciona bem para conteúdos do tipo documento, onde você quer capturar detalhes semânticos, e não apenas semelhanças visuais.
Vamos começar com as dependências e variáveis de ambiente para configurar o ambiente do nosso projeto.
Primeiro, você precisa instalar o poppler para lidar com o processamento de PDF.
Ubuntu/Debian: sudo apt-get install poppler-utils
macOS (usando Homebrew): brew install poppler
Windows: Baixe na página de lançamento e adicione ao PATH
Depois, instale os pacotes Python. Além do ChromaDB, precisamos do pdf2image pra converter PDFs em imagens, do pillow pra processamento de imagens e do requests pra baixar os arquivos PDF.
pip install openai chromadb pdf2image pillow requestsPara usar os modelos, defina sua chave API OpenAI como uma variável de ambiente.
Unix/Linux/macOS:
export OPENAI_API_KEY="your-api-key-here"Windows:
setx OPENAI_API_KEY="your-api-key-here"Agora, vamos configurar a estrutura do projeto e extrair os dados de amostra. O script já inclui os URLs para download, mas se você quiser dar uma olhada nos PDFs primeiro, aqui estão os links diretos para a mesa MALM e a estrutura da cama MALM.
Crie um arquivo chamado step1_setup.py:
"""
Step 1: Setup and Download Sample Data
"""
import os
import requests
# Create directories
for d in ["data", "data/images", "data/cache"]:
os.makedirs(d, exist_ok=True)
print("✓ Created directories")
# Download IKEA assembly instructions
SAMPLE_PDFS = {
"malm_desk.pdf": "https://www.ikea.com/us/en/assembly_instructions/malm-desk-white__AA-516949-7-2.pdf",
"malm_bed.pdf": "https://www.ikea.com/us/en/assembly_instructions/malm-bed-frame-low__AA-75286-15_pub.pdf",
}
for filename, url in SAMPLE_PDFS.items():
filepath = f"data/{filename}"
if not os.path.exists(filepath):
print(f"Downloading {filename}...")
response = requests.get(url, timeout=30)
with open(filepath, "wb") as f:
f.write(response.content)
print(f" ✓ Saved ({len(response.content) / 1024:.1f} KB)")
else:
print(f"✓ {filename} already exists")Para terminar a configuração inicial, execute o script:
python step1_setup.pyVocê deve ver os PDFs da IKEA sendo baixados para a sua pasta “ data/ ”.
As instruções da IKEA são complicadas. São principalmente diagramas com pouco texto. Precisamos converter as páginas PDF em imagens e, em seguida, usar o GPT-4o para descrever o que cada página mostra.
Criar um step2_preprocess.py:
"""
Step 2: Preprocess Documents
Convert PDFs to images and generate descriptions with GPT-4o
"""
import os
import json
import base64
from pdf2image import convert_from_path
from openai import OpenAI
client = OpenAI()
DATA_DIR = "data"
IMAGES_DIR = "data/images"
CACHE_FILE = "data/cache/descriptions.json"
def convert_pdf_to_images(pdf_path):
"""Convert a PDF to page images."""
pdf_name = os.path.splitext(os.path.basename(pdf_path))[0]
images = convert_from_path(pdf_path, dpi=150)
image_paths = []
for i, image in enumerate(images):
image_path = f"{IMAGES_DIR}/{pdf_name}_page_{i+1:03d}.png"
image.save(image_path, "PNG")
image_paths.append(image_path)
return image_paths
def describe_page(image_path):
"""Use GPT-4o to describe an instruction page."""
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """Describe this IKEA assembly instruction page in detail.
Include: step numbers, parts shown, tools needed, actions demonstrated,
quantities (like "2x"), warnings, and part numbers if visible.
This description will help people find this page when they have questions."""
},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}},
{"type": "text", "text": "Describe this instruction page."}
]
}
],
max_tokens=500
)
return response.choices[0].message.content
def main():
# Load cache if exists
cache = {}
if os.path.exists(CACHE_FILE):
with open(CACHE_FILE, "r") as f:
cache = json.load(f)
all_pages = []
# Process each PDF
for pdf_file in os.listdir(DATA_DIR):
if not pdf_file.endswith(".pdf"):
continue
print(f"\nProcessing {pdf_file}...")
pdf_path = f"{DATA_DIR}/{pdf_file}"
# Convert to images
print(" Converting to images...")
image_paths = convert_pdf_to_images(pdf_path)
print(f" ✓ {len(image_paths)} pages")
# Generate descriptions
print(" Generating descriptions with GPT-4o...")
for i, image_path in enumerate(image_paths):
if image_path in cache:
description = cache[image_path]
status = "cached"
else:
description = describe_page(image_path)
cache[image_path] = description
# Save cache after each page
with open(CACHE_FILE, "w") as f:
json.dump(cache, f, indent=2)
status = "generated"
all_pages.append({
"source_pdf": pdf_file,
"page_number": i + 1,
"image_path": image_path,
"description": description
})
print(f" Page {i+1}/{len(image_paths)} [{status}]")
# Save all page data
with open("data/cache/all_pages.json", "w") as f:
json.dump(all_pages, f, indent=2)
print(f"\n✓ Processed {len(all_pages)} pages total")
if __name__ == "__main__":
main()E aí, o que as funções estão fazendo:
convert_pdf_to_images(pdf_path): transforma cada página do PDF numa imagem PNG com 150 DPI usando pdf2image. Isso pega diagramas que não têm texto selecionável e salva com nomes consistentes, tipo malm_desk_page_001.png.
describe_page(image_path): codifica a imagem como base64 e a manda pro GPT-4o com um prompt de sistema personalizado. O modelo mostra uma descrição detalhada em texto com etapas, peças e quantidades para pesquisa semântica.
main(): organiza tudo: Ele carrega descrições em cache para evitar o reprocessamento, converte PDFs em imagens, gera novas descrições conforme necessário, salva o cache incremental e gera um arquivo ` all_pages.json ` com metadados para indexação.
Execute o script assim:
python step2_preprocess.pyEsse passo leva alguns minutos. O GPT-4o dá uma olhada em cada página e faz uma descrição detalhada. As descrições ficam guardadas no cache, então, se você rodar de novo, ele pula as páginas que já foram processadas.
O que tá rolando aqui? A gente está transformando conteúdo visual em texto que dá pra pesquisar. Quando alguém pergunta: “Como faço para prender as pernas?”, o recuperador vai procurar nessas descrições e achar páginas que falam sobre como prender as pernas, mesmo que a página original não tenha nenhum texto.
Depois de montar o pipeline básico, as próximas vitórias vêm de truques de recuperação, como pesquisa híbrida, reclassificação ou reescrita de consultas. Pra se familiarizar com elas, dá uma olhada nesse blog sobre Técnicas avançadas de RAG.
Agora, vamos incorporar as descrições e guardá-las no ChromaDB.
Criar um step3_index.py:
"""
Step 3: Create Embeddings and Index
"""
import os
import json
from openai import OpenAI
import chromadb
client = OpenAI()
PAGES_FILE = "data/cache/all_pages.json"
CHROMA_DIR = "data/chroma_db"
COLLECTION_NAME = "ikea_instructions"
def get_embedding(text):
"""Get embedding from OpenAI."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def main():
# Load page descriptions
with open(PAGES_FILE, "r") as f:
pages = json.load(f)
print(f"Loaded {len(pages)} pages")
# Initialize ChromaDB with persistent storage
chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
# Delete existing collection if present
try:
chroma_client.delete_collection(name=COLLECTION_NAME)
except:
pass
collection = chroma_client.create_collection(
name=COLLECTION_NAME,
metadata={"hnsw:space": "cosine"}
)
print(f"Created collection: {COLLECTION_NAME}")
# Index each page
print("\nCreating embeddings...")
for i, page in enumerate(pages):
# Combine source info with description
text_to_embed = f"Source: {page['source_pdf']}, Page {page['page_number']}\n\n{page['description']}"
embedding = get_embedding(text_to_embed)
collection.add(
ids=[f"page_{i}"],
embeddings=[embedding],
documents=[page["description"]],
metadatas=[{
"source_pdf": page["source_pdf"],
"page_number": page["page_number"],
"image_path": page["image_path"]
}]
)
if (i + 1) % 5 == 0 or i == len(pages) - 1:
print(f" Indexed {i + 1}/{len(pages)} pages")
print(f"\n✓ Index created with {collection.count()} documents")
# Quick retrieval test
print("\nTesting retrieval...")
test_query = "How do I attach the legs?"
query_embedding = get_embedding(test_query)
results = collection.query(query_embeddings=[query_embedding], n_results=2)
print(f"Query: '{test_query}'")
for meta in results["metadatas"][0]:
print(f" → {meta['source_pdf']}, Page {meta['page_number']}")
if __name__ == "__main__":
main()Aqui, a função get_embedding(text) transforma o texto da descrição e das informações de origem num vetor denso usando o modelo text-embedding-3-small da OpenAI. Por terem 1536 dimensões, esses vetores conseguem captar o significado semântico para a pesquisa de similaridade.
main() carrega as páginas processadas de all_pages.json da etapa anterior, inicializa o ChromaDB com armazenamento persistente, exclui/recria a coleção, gera incorporações para cada página, armazena-as com metadados ricos (fonte, número da página, caminho da imagem) e executa um teste de recuperação rápida para verificar se a indexação funciona.
Execute:
python step3_index.pyOs metadados são importantes aqui. A gente guarda o image_path pra poder pegar a imagem de verdade depois e mostrar pro GPT-4o durante a geração. A descrição é o que é pesquisado, mas a imagem é o que aparece.
Aqui está o pipeline RAG multimodal completo. Uma consulta é incorporada, as páginas relevantes são recuperadas, as imagens são carregadas e o GPT-4o gera uma resposta com base em descrições de texto e recursos visuais.
Criar um step4_query.py:
"""
Step 4: Query the Multimodal RAG System
"""
import os
import sys
import base64
from openai import OpenAI
import chromadb
client = OpenAI()
CHROMA_DIR = "data/chroma_db"
COLLECTION_NAME = "ikea_instructions"
TOP_K = 3
# Initialize ChromaDB
chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
def get_embedding(text):
"""Get embedding from OpenAI."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def retrieve(query, top_k=TOP_K):
"""Find relevant instruction pages."""
collection = chroma_client.get_collection(name=COLLECTION_NAME)
query_embedding = get_embedding(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
include=["documents", "metadatas"]
)
return results
def generate_answer(query, retrieved_results):
"""Generate answer using GPT-4o with retrieved images."""
if not retrieved_results["ids"][0]:
return "No relevant pages found.", []
# Build image content for GPT-4o
image_content = []
sources = []
for doc, metadata in zip(retrieved_results["documents"][0], retrieved_results["metadatas"][0]):
image_path = metadata["image_path"]
if not os.path.exists(image_path):
continue
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
image_content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{base64_image}"}
})
image_content.append({
"type": "text",
"text": f"[Page {metadata['page_number']} from {metadata['source_pdf']}]"
})
sources.append(f"{metadata['source_pdf']}, Page {metadata['page_number']}")
# Generate with GPT-4o
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """You answer questions about IKEA assembly based on instruction pages.
Be specific, reference page numbers when helpful, and say if something isn't clear from the images."""
},
{
"role": "user",
"content": [
{"type": "text", "text": f"Question: {query}\n\nRelevant instruction pages:"},
*image_content,
{"type": "text", "text": "Answer based on these pages."}
]
}
],
max_tokens=600
)
return response.choices[0].message.content, sources
def answer_question(query):
"""Full RAG pipeline."""
print(f"\nQuery: {query}")
print("-" * 50)
print("Retrieving relevant pages...")
results = retrieve(query)
print(f" Found {len(results['ids'][0])} pages")
print("Generating answer...")
answer, sources = generate_answer(query, results)
return answer, sources
def main():
# Check index exists
try:
collection = chroma_client.get_collection(name=COLLECTION_NAME)
print(f"Connected to index ({collection.count()} documents)")
except:
print("ERROR: Index not found. Run step2_index.py first.")
return
# Single query from command line
if len(sys.argv) > 1:
query = " ".join(sys.argv[1:])
answer, sources = answer_question(query)
print(f"\nAnswer:\n{answer}")
print(f"\nSources: {', '.join(sources)}")
return
# Interactive mode
print("\nAsk questions about IKEA assembly. Type 'quit' to exit.\n")
while True:
try:
query = input("Question: ").strip()
except KeyboardInterrupt:
break
if not query or query.lower() in ["quit", "exit"]:
break
answer, sources = answer_question(query)
print(f"\nAnswer:\n{answer}")
print(f"\nSources: {', '.join(sources)}\n")
if __name__ == "__main__":
main()Explicação das principais funções:
get_embedding(text): gera uma incorporação vetorial para a consulta usando text-embedding-3-small, permitindo a pesquisa de similaridade semântica no ChromaDB.
retrieve(query, top_k=TOP_K): incorpora a consulta, consulta a coleção para os k vizinhos mais próximos e retorna documentos e metadados (por exemplo, caminhos de imagem) por meio de include=["documents", "metadatas"].
generate_answer(query, retrieved_results)Carrega as imagens principais como base64, cria um prompt multimodal GPT-4o intercalando rótulos de páginas e imagens e gera uma resposta detalhada com instruções específicas da IKEA.
answer_question(query): coordena a recuperação e a geração, com registro do progresso.
main(): verifica se o índice existe, aceita consultas únicas pela CLI ou o modo de bate-papo interativo (“quit”, “exit” ou Ctrl+C para sair).
Você pode executá-lo e digitar sua pergunta ou executá-lo diretamente com uma pergunta específica, assim:
python step4_query.py "How do I attach the legs to the desk?"Retrieving relevant pages...
Found 3 pages
Generating answer...
Answer:
To attach the legs to the MALM desk, follow these steps shown on pages 5-6:
1. First, insert the wooden dowels into the pre-drilled holes on the leg
pieces (you'll see "4x" indicating four dowels are needed)
2. Apply the cam locks to the desk top using the Phillips screwdriver
3. Align each leg with the corresponding holes on the underside of the desk
4. Tighten the cam locks by rotating them clockwise until the legs are
firmly attached
The instructions show this should be done with the desk top face-down on
a soft surface to avoid scratching.
Sources: malm_desk.pdf, Page 5, malm_desk.pdf, Page 6, malm_desk.pdf, Page 7Parece ótimo! O sistema pega as páginas com base nas descrições, carrega as imagens reais e o GPT-4o gera uma resposta olhando diretamente para os diagramas.
Construir um sistema RAG multimodal é uma coisa. Saber se funciona bem é outra coisa. E fazer com que ele funcione de forma confiável na produção adiciona mais um nível de desafios.
As métricas padrão do RAG ainda valem, mas você precisa ampliá-las para o conteúdo visual.
A precisão mede quantas das páginas que você encontrou eram realmente relevantes. Isso penalizaria páginas irrelevantes no top-k, mas, para a geração, ter a imagem principal é mais importante do que conseguir um top-k perfeito.
O Recall@k mede a frequência com que as páginas corretas aparecem nos seus primeiros k resultados. Isso é mais relevante para o seu caso de uso do IKEA RAG, porque queremos que o sistema encontre pelo menos uma página relevante nos primeiros k (por exemplo, k=3) resultados. Assim, o GPT-4o consegue o contexto visual pra responder direitinho, mesmo que outros resultados sejam só ruído.
Para o nosso sistema IKEA, você criaria um conjunto de testes com, talvez, 50 perguntas e marcaria as páginas “corretas” para cada uma delas. Então, você pode avaliá-los usando a seguinte função:
def evaluate_retrieval(test_cases, top_k=3):
"""
test_cases: [{"query": str, "relevant_pages": ["image_path1", ...]}]
"""
hits = 0
for test in test_cases:
results = retrieve(test["query"], top_k=top_k)
retrieved = [m["image_path"] for m in results["metadatas"][0]]
if any(p in retrieved for p in test["relevant_pages"]):
hits += 1
return hits / len(test_cases)Algo que é mais difícil de medir automaticamente é a qualidade da geração.
Você pode pedir para as pessoas avaliarem as respostas quanto à precisão e utilidade, ou usar um LLM como juiz para avaliar se as respostas estão corretas, considerando as imagens de origem.
Para diagramas com etapas numeradas, veja se o modelo atribui os números corretos às etapas.
Outras avaliações poderiam responder às seguintes perguntas:
O sistema encontra respostas baseadas em imagens quando a resposta é visual?
Quando o modelo fala de algo numa imagem, essa referência é precisa?
Isso precisa de uma revisão manual, pelo menos para uma amostra de consultas.
Se você quer criar um pipeline RAG multimodal pronto para produção, tem algumas coisas que você precisa lembrar:
Os custos de pré-processamento aumentam: As chamadas de visão para descrição de imagens são a parte cara. Para um grande conjunto de documentos, processe em lote durante os horários de menor movimento e armazene as descrições em cache de forma agressiva. Pense em usar um modelo mais barato (no nosso caso, por exemplo, o GPT-4o-mini) para gerar descrições, se a qualidade for boa o suficiente para o que você precisa.
A latência da consulta é importante: O GPT-4o com imagens leva de 5 a 10 segundos por consulta. O streaming ajuda os usuários a ver resultados parciais rapidinho, e o cache de consultas comuns ajuda com perguntas repetidas. Recuperar 2 páginas em vez de 5 pode fazer diferença em termos de tokens, se isso já for contexto suficiente.
Fique de olho no que é importante: Latencia de recuperação de programas (deve ser inferior a 100 ms para coleções pequenas), latencia de geração (espere de 5 a 10 segundos com imagens), custos de API por consulta e feedback do usuário, se você estiver coletando.
O tratamento de erros te ajuda a: As coisas quebram. Crie alternativas, como no trecho de código a seguir.
def answer_question_safe(query):
"""Wrapper with error handling."""
try:
return answer_question(query)
except Exception as e:
print(f"Error: {e}")
# Fall back to text-only using descriptions
results = retrieve(query)
if results["documents"][0]:
context = results["documents"][0][0][:500]
return f"Based on the instructions: {context}...", []
return "Sorry, couldn't process that question.", []Quando seu pipeline precisa passar por várias etapas (pesquisar → verificar → pesquisar novamente → responder), RAG ajudam você a estruturar tudo de forma clara.
O RAG multimodal amplia a geração aumentada por recuperação para lidar com toda a gama de conteúdos em documentos do mundo real, incluindo imagens, diagramas, tabelas e gráficos.
Usamos isso com sucesso para consultar as instruções da IKEA, que são bem visuais, onde uma abordagem só com texto não teria funcionado. Todo o pipeline funciona localmente, exceto pelas chamadas API.
A ideia principal é que você não precisa de incorporações multimodais complexas para fazer isso funcionar. Ao criar boas descrições de texto para o conteúdo visual, você pode usar a recuperação de texto padrão para encontrar imagens relevantes e, em seguida, deixar que um modelo de linguagem visual faça o trabalho pesado na hora da geração.
Se você quiser continuar com o que falamos aqui, comece sua jornada com o carreira de Engenheiro de IA hoje mesmo!
Cursos RAG
Programa
Curso
Curso
blog
Natassha Selvaraj
10 min
blog
Javier Canales Luna
8 min
blog
Hesam Sheikh Hassani
15 min
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
