
Lernpfad
Associate AI Engineer für Entwickler
26 Std.
Stell dir vor, du baust IKEA-Möbel zusammen. Du starrst auf Schritt 14 in der Anleitung, kannst aber nicht herausfinden, welche Schraube wohin gehört. Das Diagramm zeigt was, aber es macht keinen Sinn.
Wenn du fragen würdest: Wozu dient das kleine Metallteil in Schritt 14? Ein normales textbasiertes RAG-System (Retrieval-Augmented Generation) kann hier nicht weiterhelfen. Die Antwort findest du im Diagramm selbst, nicht im Text auf der Seite. IKEA-Anleitungen sind bekannt dafür, dass sie keine Worte haben.
Hier kommt multimodales RAG ins Spiel.
In diesem Tutorial zeige ich dir, wie du ein multimodales RAG-System aufbaust, das Fragen zu Dokumenten mit Bildern, Diagrammen und gemischten Inhalten beantworten kann. Wir nehmen die IKEA-Montageanleitungen als Test, weil sie ein guter Stresstest sind: Sie sind hauptsächlich visuell, haben wenig Text und sind genau das, womit die Leute tatsächlich Hilfe brauchen.
Wir werden durchgehend die Modelle von OpenAI nutzen: GPT-4o zum Verstehen von Bildern und zum Erstellen von Antworten und text-embedding-3-small zum Erstellen von durchsuchbaren Vektoren. Um zu lernen, wie man RAG-Pipelines mit einem anderen Framework baut, empfehle ich unseren Kurs „RAG mit LangChain ”.
Am Ende hast du ein funktionierendes System, das du lokal ausführen und an deine eigenen Dokumente anpassen kannst.
Multimodal RAG erweitert das normale RAG-Muster, damit es nicht nur Text verarbeiten kann. Die Grundidee bleibt gleich, aber „Kontext“ umfasst jetzt auch Bilder, Tabellen, Diagramme und andere Nicht-Text-Inhalte.
Warum ist das wichtig? Weil echte Dokumente nicht nur aus Text bestehen.
Überleg mal, womit du eigentlich arbeitest:
Ein System, das nur Text verarbeitet, arbeitet mit unvollständigen Infos. Das ist so, als würde man versuchen, ein Rezept zu verstehen, indem man nur die Zutatenliste liest und die Fotos ignoriert, die zeigen, wie „vorsichtig unterheben“ eigentlich aussieht.
Traditionelles RAG behandelt eine PDF-Datei wie einen Zeichenstrom. Es holt den Text raus, teilt ihn in Stücke, bettet diese Stücke ein und sagt, dass es fertig ist. Alle Bilder werden komplett übersprungen oder vielleicht in Platzhalter-Token „ [IMAGE] “ umgewandelt. Tabellen werden zu chaotischen Textzeilen, die ihre Struktur verlieren.
Multimodal RAG macht es anders: Bilder werden beschrieben oder direkt eingebettet, und Tabellen werden in strukturierte Formate umgewandelt. Das Suchsystem kann eine Anfrage wie „Netzwerktopologiediagramm“ sowohl mit Textbeschreibungen der Netzwerkarchitektur als auch mit tatsächlichen visuellen Diagrammen abgleichen. Das Generierungsmodell kann ein Bild checken und herausfinden, was drauf ist.
|
Aspekt |
Text-Only RAG |
Multimodal RAG |
|
Eingabetypen |
Einfacher Text, vielleicht Markdown |
Text, Bilder, Tabellen, Diagramme, gemischte Dokumente |
|
Was eingebettet wird |
Textblöcke |
Textabschnitte plus Bildbeschreibungen oder Bild-Einbettungen |
|
Generationsmodell |
Jeder LLM |
Bildverarbeitungsmodell (GPT-4o, Claude, Gemini) |
|
Am besten geeignet für |
Dokumente mit viel Text |
Handbücher, Berichte, Folien, alles mit visuellen Inhalten |
Wenn dir „multimodal“ immer noch wie so ein vager Oberbegriff vorkommt, dann ist dieser Blog übermultimodale KI genau das Richtige für dich, weil er das Thema mit konkreten Beispielen klar erklärt.
Die Pipeline hat mehr bewegliche Teile als das reine Text-RAG, aber die Struktur ist ähnlich. Die Daten werden verarbeitet und eingebettet, landen in einem Vektorspeicher und werden abgerufen, wenn jemand eine Frage stellt.
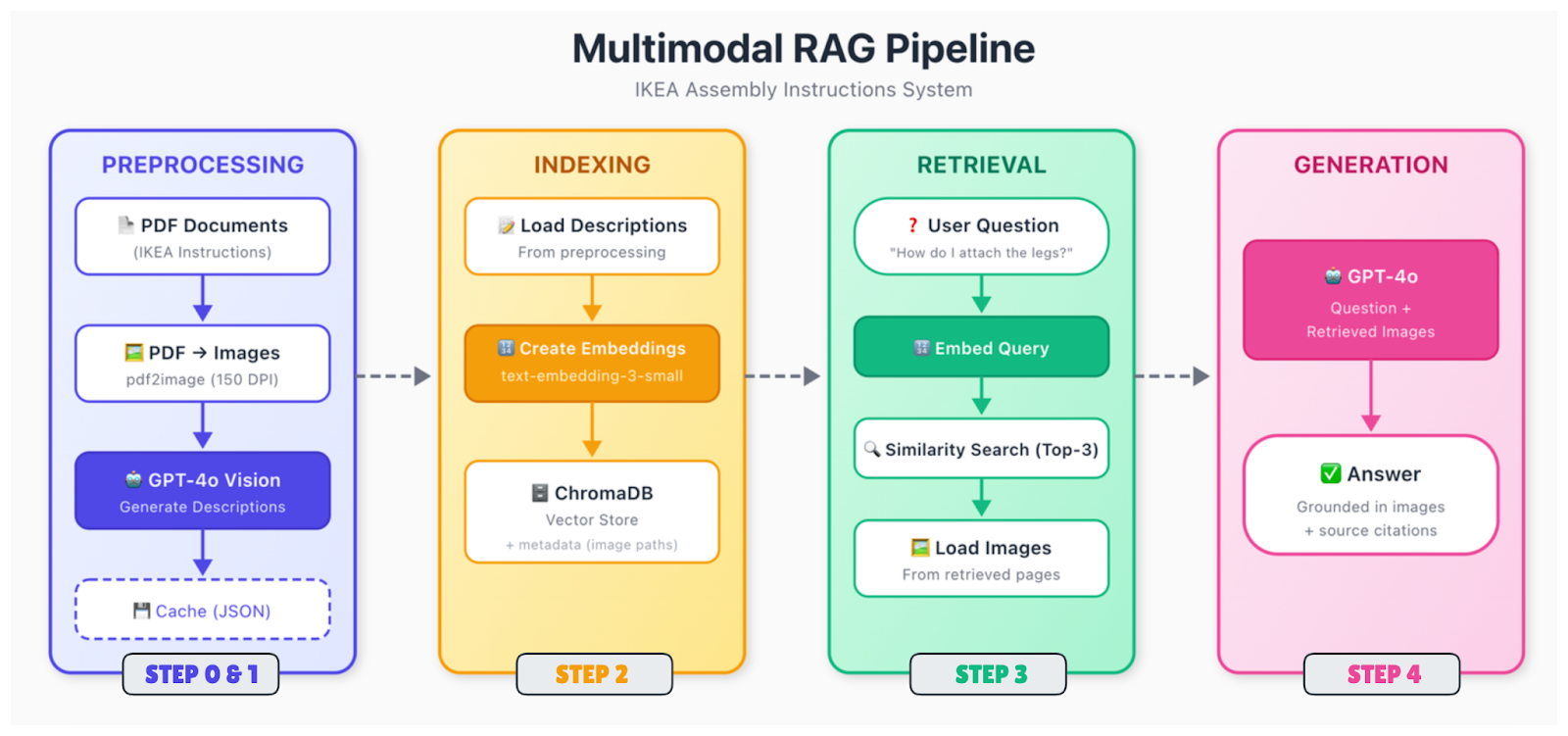
Hier ist der Ablauf:
Rohdokumente (PDFs, Bilder, Folien) werden in ihre Bestandteile zerlegt. Du extrahierst Text, erkennst Bilder, analysierst Tabellen und findest heraus, wie alles räumlich zusammenhängt. Ein Diagramm auf Seite 5 kann eine Bildunterschrift darunter und einen Verweis im Text auf Seite 4 haben. Du musst diese Beziehungen erfassen.
Verschiedene Arten von Inhalten müssen unterschiedlich behandelt werden. Für Bilder hast du zwei Möglichkeiten: Du kannst Textbeschreibungen mit einem Bildverarbeitungsmodell (wie GPT-4o) erstellen oder Bilder direkt mit einem multimodalen Encoder (wie CLIP) einbetten. Der Beschreibungsansatz ist einfacher und funktioniert mit Standard-Text-Embeddings. Tabellen werden in strukturierte Formate umgewandelt oder in natürlicher Sprache zusammengefasst.
Danach wird alles in Vektoren umgewandelt. Wenn du den Beschreibungsansatz verwendest, bettest du einfach deinen gesamten Text (Originaltext plus generierte Bildbeschreibungen) mit einem Standard-Texteinbettungsmodell ein. Der Clou ist, dass Suchanfragen zu visuellen Inhalten jetzt mit diesen Beschreibungen übereinstimmen können.
Vektoren werden in einer Datenbank mit Metadaten gespeichert, darunter das Quelldokument, die Seitenzahl, der Inhaltstyp und bei Bildern der Pfad zur Originaldatei. Du brauchst diesen Bildpfad später, wenn du ihn dem Generierungsmodell zeigen willst.
Wenn eine Anfrage reinkommt, pack sie in dasselbe Modell rein, such die nächsten Nachbarn und gib die besten Treffer zurück. Die abgerufenen Teile können sich auf Text, Bilder oder beides beziehen.
Gib die Abfrage zusammen mit dem abgerufenen Kontext an ein Bild-Sprach-Modell weiter. Wenn die abgerufenen Chunks auf Bilder verweisen, lade diese Bilder und füge sie in die Eingabeaufforderung ein. Das Modell schaut sich sowohl den Text als auch die Bilder an und macht dann eine Antwort.
Der Generierungsschritt ist der Punkt, an dem GPT-4o wirklich glänzt. Es kann sich ein IKEA-Diagramm mit der Schraubenanordnung anschauen und in einfachen Worten erklären, was da passiert. Es kann ein Diagramm lesen und den Trend zusammenfassen. Es kann Details in technischen Zeichnungen erkennen, die in einer Textbeschreibung vielleicht übersehen werden.
Lass uns das Ding bauen. Wir bauen ein System, das Fragen zu den IKEA-Montageanleitungen beantworten kann, und gehen dabei Schritt für Schritt von der Einrichtung bis hin zu einer funktionierenden Abfrageoberfläche vor.
Für dieses Tutorial halten wir es einfach:
|
Komponente |
Auswahl |
Warum |
|
Einbettungen |
text-embedding-3-small |
Günstig, gute Qualität, gleiche API |
|
Vektorspeicher |
ChromaDB |
Läuft lokal, keine Einrichtung nötig, dauerhaft |
|
Visionsmodell |
GPT-4o |
Top in Sachen Bildverständnis |
|
Generation |
GPT-4o |
Gleiches Modell, macht beides |
Du könntest Alternativen einbauen. Pinecone oder Weaviate für den Vektorspeicher, wenn du Skalierbarkeit brauchst. Claude oder Gemini sind coole Alternativen für die Generation. Die allgemeine Architektur bleibt in diesen Fällen gleich.
Warum nicht CLIP oder ColPali für Einbettungen nutzen? Du könntest. Damit kannst du Bilder direkt einbetten, ohne vorher Textbeschreibungen zu erstellen. Aber sie machen die Sache komplizierter und brauchen oft eine GPU. Der Beschreibungsansatz eignet sich gut für dokumentähnliche Inhalte, bei denen du nicht nur visuelle Ähnlichkeiten, sondern auch semantische Details erfassen möchtest.
Fangen wir mit den Abhängigkeiten und Umgebungsvariablen an, um unsere Projektumgebung einzurichten.
Zuerst musst du „ poppler “ installieren, um PDF-Dateien bearbeiten zu können.
Ubuntu/Debian: sudo apt-get install poppler-utils
macOS (mit Homebrew): brew install poppler
Windows: Lade es von der Release-Seite runter und füge es zum PATH hinzu.
Als Nächstes installierst du die Python-Pakete. Neben ChromaDB brauchen wir pdf2image, um PDFs in Bilder umzuwandeln, pillow für die Bildbearbeitung und requests zum Herunterladen der PDF-Dateien.
pip install openai chromadb pdf2image pillow requestsUm die Modelle zu nutzen, leg deinen OpenAI-API-Schlüssel als Umgebungsvariable fest.
Unix/Linux/macOS:
export OPENAI_API_KEY="your-api-key-here"Windows:
setx OPENAI_API_KEY="your-api-key-here"Jetzt richten wir die Projektstruktur ein und holen die Beispieldaten rein. Das Skript hat die Download-URLs schon drin, aber wenn du dir die PDFs erst mal anschauen willst, hier sind die direkten Links zum MALM-Schreibtisch und zum MALM-Bettgestell.
Mach eine Datei namens „ step1_setup.py “:
"""
Step 1: Setup and Download Sample Data
"""
import os
import requests
# Create directories
for d in ["data", "data/images", "data/cache"]:
os.makedirs(d, exist_ok=True)
print("✓ Created directories")
# Download IKEA assembly instructions
SAMPLE_PDFS = {
"malm_desk.pdf": "https://www.ikea.com/us/en/assembly_instructions/malm-desk-white__AA-516949-7-2.pdf",
"malm_bed.pdf": "https://www.ikea.com/us/en/assembly_instructions/malm-bed-frame-low__AA-75286-15_pub.pdf",
}
for filename, url in SAMPLE_PDFS.items():
filepath = f"data/{filename}"
if not os.path.exists(filepath):
print(f"Downloading {filename}...")
response = requests.get(url, timeout=30)
with open(filepath, "wb") as f:
f.write(response.content)
print(f" ✓ Saved ({len(response.content) / 1024:.1f} KB)")
else:
print(f"✓ {filename} already exists")Um die Ersteinrichtung abzuschließen, führ das Skript aus:
python step1_setup.pyDu solltest sehen, wie die IKEA-PDFs in deinen Ordner „ data/ ” runtergeladen werden.
Die Anleitungen von IKEA sind echt knifflig. Es sind meistens Diagramme mit wenig Text. Wir müssen PDF-Seiten in Bilder umwandeln und dann mit GPT-4o beschreiben, was auf jeder Seite zu sehen ist.
Erstell die Datei „ step2_preprocess.py “:
"""
Step 2: Preprocess Documents
Convert PDFs to images and generate descriptions with GPT-4o
"""
import os
import json
import base64
from pdf2image import convert_from_path
from openai import OpenAI
client = OpenAI()
DATA_DIR = "data"
IMAGES_DIR = "data/images"
CACHE_FILE = "data/cache/descriptions.json"
def convert_pdf_to_images(pdf_path):
"""Convert a PDF to page images."""
pdf_name = os.path.splitext(os.path.basename(pdf_path))[0]
images = convert_from_path(pdf_path, dpi=150)
image_paths = []
for i, image in enumerate(images):
image_path = f"{IMAGES_DIR}/{pdf_name}_page_{i+1:03d}.png"
image.save(image_path, "PNG")
image_paths.append(image_path)
return image_paths
def describe_page(image_path):
"""Use GPT-4o to describe an instruction page."""
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """Describe this IKEA assembly instruction page in detail.
Include: step numbers, parts shown, tools needed, actions demonstrated,
quantities (like "2x"), warnings, and part numbers if visible.
This description will help people find this page when they have questions."""
},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}},
{"type": "text", "text": "Describe this instruction page."}
]
}
],
max_tokens=500
)
return response.choices[0].message.content
def main():
# Load cache if exists
cache = {}
if os.path.exists(CACHE_FILE):
with open(CACHE_FILE, "r") as f:
cache = json.load(f)
all_pages = []
# Process each PDF
for pdf_file in os.listdir(DATA_DIR):
if not pdf_file.endswith(".pdf"):
continue
print(f"\nProcessing {pdf_file}...")
pdf_path = f"{DATA_DIR}/{pdf_file}"
# Convert to images
print(" Converting to images...")
image_paths = convert_pdf_to_images(pdf_path)
print(f" ✓ {len(image_paths)} pages")
# Generate descriptions
print(" Generating descriptions with GPT-4o...")
for i, image_path in enumerate(image_paths):
if image_path in cache:
description = cache[image_path]
status = "cached"
else:
description = describe_page(image_path)
cache[image_path] = description
# Save cache after each page
with open(CACHE_FILE, "w") as f:
json.dump(cache, f, indent=2)
status = "generated"
all_pages.append({
"source_pdf": pdf_file,
"page_number": i + 1,
"image_path": image_path,
"description": description
})
print(f" Page {i+1}/{len(image_paths)} [{status}]")
# Save all page data
with open("data/cache/all_pages.json", "w") as f:
json.dump(all_pages, f, indent=2)
print(f"\n✓ Processed {len(all_pages)} pages total")
if __name__ == "__main__":
main()Hier ist, was die Funktionen machen:
convert_pdf_to_images(pdf_path)Rendert jede PDF-Seite als PNG-Bild mit 150 DPI unter Verwendung von pdf2image. Das extrahiert Diagramme, in denen man keinen Text auswählen kann, und speichert sie mit einer einheitlichen Bezeichnung wie „ malm_desk_page_001.png “.
describe_page(image_path): codiert das Bild als „ base64 “ und schickt es mit einer maßgeschneiderten Systemaufforderung an GPT-4o. Das Modell gibt eine ausführliche Textbeschreibung zurück, die Schritte, Teile und Mengen für die semantische Suche enthält.
main(): organisiert alles: Es lädt zwischengespeicherte Beschreibungen, um eine erneute Verarbeitung zu vermeiden, wandelt PDFs in Bilder um, erstellt bei Bedarf neue Beschreibungen, speichert inkrementelle Caches und gibt „ all_pages.json “ mit Metadaten für die Indizierung aus.
Mach das Skript so:
python step2_preprocess.pyDieser Schritt dauert ein paar Minuten. GPT-4o checkt jede Seite und macht eine ausführliche Beschreibung. Die Beschreibungen werden zwischengespeichert, sodass beim erneuten Ausführen bereits verarbeitete Seiten übersprungen werden.
Was geht hier ab? Wir machen aus Bildern und Videos Text, den man durchsuchen kann. Wenn jemand fragt: „Wie befestige ich die Beine?“, sucht der Retriever in diesen Beschreibungen und findet Seiten, auf denen die Befestigung der Beine erwähnt wird, auch wenn die ursprüngliche Seite überhaupt keinen Text enthält.
Sobald du die grundlegende Pipeline aufgebaut hast, kommen die nächsten Erfolge durch Tricks beim Abrufen, wie zum Beispiel hybride Suche, Neuanordnung oder Umschreiben von Suchanfragen. Um dich damit vertraut zu machen, lies diesen Blogbeitrag über Fortgeschrittene RAG-Techniken.
Jetzt packen wir die Beschreibungen rein und speichern sie in ChromaDB.
Erstell die Datei „ step3_index.py “:
"""
Step 3: Create Embeddings and Index
"""
import os
import json
from openai import OpenAI
import chromadb
client = OpenAI()
PAGES_FILE = "data/cache/all_pages.json"
CHROMA_DIR = "data/chroma_db"
COLLECTION_NAME = "ikea_instructions"
def get_embedding(text):
"""Get embedding from OpenAI."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def main():
# Load page descriptions
with open(PAGES_FILE, "r") as f:
pages = json.load(f)
print(f"Loaded {len(pages)} pages")
# Initialize ChromaDB with persistent storage
chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
# Delete existing collection if present
try:
chroma_client.delete_collection(name=COLLECTION_NAME)
except:
pass
collection = chroma_client.create_collection(
name=COLLECTION_NAME,
metadata={"hnsw:space": "cosine"}
)
print(f"Created collection: {COLLECTION_NAME}")
# Index each page
print("\nCreating embeddings...")
for i, page in enumerate(pages):
# Combine source info with description
text_to_embed = f"Source: {page['source_pdf']}, Page {page['page_number']}\n\n{page['description']}"
embedding = get_embedding(text_to_embed)
collection.add(
ids=[f"page_{i}"],
embeddings=[embedding],
documents=[page["description"]],
metadatas=[{
"source_pdf": page["source_pdf"],
"page_number": page["page_number"],
"image_path": page["image_path"]
}]
)
if (i + 1) % 5 == 0 or i == len(pages) - 1:
print(f" Indexed {i + 1}/{len(pages)} pages")
print(f"\n✓ Index created with {collection.count()} documents")
# Quick retrieval test
print("\nTesting retrieval...")
test_query = "How do I attach the legs?"
query_embedding = get_embedding(test_query)
results = collection.query(query_embeddings=[query_embedding], n_results=2)
print(f"Query: '{test_query}'")
for meta in results["metadatas"][0]:
print(f" → {meta['source_pdf']}, Page {meta['page_number']}")
if __name__ == "__main__":
main()Hier wandelt die Funktion „ get_embedding(text) “ den Text aus der Beschreibung und den Quellinfos mithilfe des Modells „ text-embedding-3-small “ von OpenAI in einen dichten Vektor um. Da diese Vektoren 1536-dimensional sind, können sie die semantische Bedeutung für die Ähnlichkeitssuche erfassen.
main() lädt die verarbeiteten Seiten von all_pages.json aus dem vorherigen Schritt, richtet ChromaDB mit persistenter Speicherung ein, löscht/erstellt die Sammlung neu, macht Einbettungen für jede Seite, speichert sie mit umfangreichen Metadaten (Quelle, Seitenzahl, Bildpfad) und macht einen schnellen Abruftest, um zu checken, ob die Indizierung funktioniert.
Mach's einfach:
python step3_index.pyDie Metadaten sind hier echt wichtig. Wir speichern die image_path, damit wir das eigentliche Bild später abrufen und es GPT-4o während der Generierung zeigen können. Die Beschreibung ist das, was gesucht wird, aber das Bild ist das, was angezeigt wird.
Hier ist die komplette multimodale RAG-Pipeline. Eine Anfrage wird eingebettet, passende Seiten werden gefunden, Bilder geladen und GPT-4o macht eine Antwort anhand von Textbeschreibungen und Bildern.
Erstell die Datei „ step4_query.py “:
"""
Step 4: Query the Multimodal RAG System
"""
import os
import sys
import base64
from openai import OpenAI
import chromadb
client = OpenAI()
CHROMA_DIR = "data/chroma_db"
COLLECTION_NAME = "ikea_instructions"
TOP_K = 3
# Initialize ChromaDB
chroma_client = chromadb.PersistentClient(path=CHROMA_DIR)
def get_embedding(text):
"""Get embedding from OpenAI."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def retrieve(query, top_k=TOP_K):
"""Find relevant instruction pages."""
collection = chroma_client.get_collection(name=COLLECTION_NAME)
query_embedding = get_embedding(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
include=["documents", "metadatas"]
)
return results
def generate_answer(query, retrieved_results):
"""Generate answer using GPT-4o with retrieved images."""
if not retrieved_results["ids"][0]:
return "No relevant pages found.", []
# Build image content for GPT-4o
image_content = []
sources = []
for doc, metadata in zip(retrieved_results["documents"][0], retrieved_results["metadatas"][0]):
image_path = metadata["image_path"]
if not os.path.exists(image_path):
continue
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
image_content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{base64_image}"}
})
image_content.append({
"type": "text",
"text": f"[Page {metadata['page_number']} from {metadata['source_pdf']}]"
})
sources.append(f"{metadata['source_pdf']}, Page {metadata['page_number']}")
# Generate with GPT-4o
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """You answer questions about IKEA assembly based on instruction pages.
Be specific, reference page numbers when helpful, and say if something isn't clear from the images."""
},
{
"role": "user",
"content": [
{"type": "text", "text": f"Question: {query}\n\nRelevant instruction pages:"},
*image_content,
{"type": "text", "text": "Answer based on these pages."}
]
}
],
max_tokens=600
)
return response.choices[0].message.content, sources
def answer_question(query):
"""Full RAG pipeline."""
print(f"\nQuery: {query}")
print("-" * 50)
print("Retrieving relevant pages...")
results = retrieve(query)
print(f" Found {len(results['ids'][0])} pages")
print("Generating answer...")
answer, sources = generate_answer(query, results)
return answer, sources
def main():
# Check index exists
try:
collection = chroma_client.get_collection(name=COLLECTION_NAME)
print(f"Connected to index ({collection.count()} documents)")
except:
print("ERROR: Index not found. Run step2_index.py first.")
return
# Single query from command line
if len(sys.argv) > 1:
query = " ".join(sys.argv[1:])
answer, sources = answer_question(query)
print(f"\nAnswer:\n{answer}")
print(f"\nSources: {', '.join(sources)}")
return
# Interactive mode
print("\nAsk questions about IKEA assembly. Type 'quit' to exit.\n")
while True:
try:
query = input("Question: ").strip()
except KeyboardInterrupt:
break
if not query or query.lower() in ["quit", "exit"]:
break
answer, sources = answer_question(query)
print(f"\nAnswer:\n{answer}")
print(f"\nSources: {', '.join(sources)}\n")
if __name__ == "__main__":
main()Die wichtigsten Funktionen erklärt:
get_embedding(text): Erzeugt eine Vektoreinbettung für die Abfrage mithilfe von text-embedding-3-small und ermöglicht so die semantische Ähnlichkeitssuche in ChromaDB.
retrieve(query, top_k=TOP_K): fügt die Abfrage ein , fragt die Sammlung nach den k nächsten Nachbarn ab und gibt Dokumente und Metadaten (z. B. Bildpfade) über include=["documents", "metadatas"] zurück.
generate_answer(query, retrieved_results): Lädt Top-Bilder wie base64, erstellt eine multimodale GPT-4o-Eingabeaufforderung, die Seitenbeschriftungen und Bilder miteinander verknüpft, und generiert eine detaillierte Antwort mit IKEA-spezifischen Anweisungen.
answer_question(query): organisiert das Abrufen und Erstellen von Daten und hält den Fortschritt fest.
main(): Überprüft , ob der Index da ist, und unterstützt einzelne CLI-Abfragen oder den interaktiven Chat-Modus („quit“, „exit“ oder Strg+C zum Beenden).
Du kannst es starten und deine Frage eingeben oder es direkt mit einer bestimmten Frage starten, so wie hier:
python step4_query.py "How do I attach the legs to the desk?"Retrieving relevant pages...
Found 3 pages
Generating answer...
Answer:
To attach the legs to the MALM desk, follow these steps shown on pages 5-6:
1. First, insert the wooden dowels into the pre-drilled holes on the leg
pieces (you'll see "4x" indicating four dowels are needed)
2. Apply the cam locks to the desk top using the Phillips screwdriver
3. Align each leg with the corresponding holes on the underside of the desk
4. Tighten the cam locks by rotating them clockwise until the legs are
firmly attached
The instructions show this should be done with the desk top face-down on
a soft surface to avoid scratching.
Sources: malm_desk.pdf, Page 5, malm_desk.pdf, Page 6, malm_desk.pdf, Page 7Sieht gut aus! Das System sucht Seiten anhand der Beschreibungen, lädt die Bilder und GPT-4o macht eine Antwort, indem es sich die Diagramme direkt anschaut.
Ein multimodales RAG-System aufzubauen ist eine Sache. Zu wissen, ob es gut funktioniert, ist eine andere Sache. Und es zuverlässig in der Produktion zum Laufen zu bringen, bringt noch mehr Herausforderungen mit sich.
Die Standard-RAG-Metriken gelten immer noch, aber du musst sie für visuelle Inhalte erweitern.
Precision@k misst, wie viele der gefundenen Seiten wirklich relevant waren. Das würde irrelevante Seiten in Top-k benachteiligen, aber für die Generierung ist das Schlüsselbild wichtiger als das Erreichen eines perfekten Top-k.
Recall@k misst, wie oft die richtigen Seiten in deinen Top-k-Ergebnissen auftauchen. Das ist für deinen IKEA RAG-Anwendungsfall wichtiger, weil wir wollen, dass das System mindestens eine relevante Seite in den Top-k-Ergebnissen (z. B. k=3) findet. So kriegt GPT-4o den visuellen Kontext, um richtig zu antworten, auch wenn andere Ergebnisse nur Rauschen sind.
Für unser IKEA-System würdest du einen Testsatz mit vielleicht 50 Fragen erstellen und die „richtigen” Seiten für jede Frage kennzeichnen. Dann könntest du sie mit der folgenden Funktion auswerten:
def evaluate_retrieval(test_cases, top_k=3):
"""
test_cases: [{"query": str, "relevant_pages": ["image_path1", ...]}]
"""
hits = 0
for test in test_cases:
results = retrieve(test["query"], top_k=top_k)
retrieved = [m["image_path"] for m in results["metadatas"][0]]
if any(p in retrieved for p in test["relevant_pages"]):
hits += 1
return hits / len(test_cases)Was man nicht so einfach automatisch messen kann, ist die Qualität der Stromerzeugung.
Man könnte Leute Antworten nach Genauigkeit und Nützlichkeit bewerten lassen oder ein LLM als Richter einsetzen, um zu beurteilen, ob die Antworten angesichts der Quellbilder richtig sind.
Bei Diagrammen mit nummerierten Schritten solltest du checken, ob das Modell die richtigen Schrittnummern zuweist.
Weitere Untersuchungen könnten diese Fragen klären:
Findet das System bildbasierte Antworten, wenn die Antwort visuell ist?
Wenn das Modell auf etwas in einem Bild verweist, ist dieser Verweis dann korrekt?
Die müssen manuell überprüft werden, zumindest bei einer Auswahl der Anfragen.
Wenn du eine produktionsreife multimodale RAG-Pipeline aufbauen willst, solltest du ein paar Dinge beachten:
Die Vorbearbeitungskosten summieren sich: Bildbeschreibungen sind echt teuer. Bei einem großen Dokumentenkorpus solltest du die Verarbeitung in den Nebenzeiten machen und die Beschreibungen aggressiv zwischenspeichern. Wenn die Qualität für deinen Anwendungsfall okay ist, kannst du ein günstigeres Modell (in unserem Fall z. B. GPT-4o-mini) für die Beschreibungserstellung in Betracht ziehen.
Die Latenzzeit bei Abfragen ist wichtig: GPT-4o mit Bildern braucht 5 bis 10 Sekunden pro Anfrage. Streaming hilft den Nutzern, Teilergebnisse schnell zu sehen, und das Zwischenspeichern häufiger Suchanfragen hilft bei wiederholten Fragen. Wenn 2 Seiten statt 5 Seiten abgerufen werden, kann das in Bezug auf die Token einen Unterschied machen, wenn das bereits als Kontext ausreicht.
Behalte das Richtige im Auge: Beachte die Latenz beim Abrufen von Titeln (sollte bei kleinen Sammlungen unter 100 ms liegen), die Latenz beim Generieren (bei Bildern mit 5 bis 10 Sekunden rechnen), die API-Kosten pro Abfrage und das Feedback der Nutzer, falls du das sammelst.
Die Fehlerbehandlung rettet dich: Dinge gehen kaputt. Erstelle Fallbacks, wie im folgenden Code-Schnipsel gezeigt.
def answer_question_safe(query):
"""Wrapper with error handling."""
try:
return answer_question(query)
except Exception as e:
print(f"Error: {e}")
# Fall back to text-only using descriptions
results = retrieve(query)
if results["documents"][0]:
context = results["documents"][0][0][:500]
return f"Based on the instructions: {context}...", []
return "Sorry, couldn't process that question.", []Wenn deine Pipeline mehrere Schritte braucht (Suche → überprüfen → erneute Suche → antworten), Agentisches RAG helfen dir dabei, alles übersichtlich zu organisieren.
Multimodal RAG erweitert die suchgestützte Generierung, um die ganze Bandbreite an Inhalten in echten Dokumenten zu verarbeiten, wie Bilder, Diagramme, Tabellen und Grafiken.
Wir haben es erfolgreich genutzt, um IKEA-Anleitungen abzufragen, die bekanntlich sehr visuell sind und bei denen ein rein textbasierter Ansatz nicht funktioniert hätte. Die ganze Pipeline läuft lokal, außer den API-Aufrufen.
Der entscheidende Punkt ist, dass man keine komplizierten multimodalen Einbettungen braucht, damit das funktioniert. Wenn du gute Textbeschreibungen für visuelle Inhalte erstellst, kannst du mit Standard-Textsuche passende Bilder finden und dann ein Bild-Sprache-Modell die harte Arbeit beim Erstellen übernehmen lassen.
Wenn du auf dem hier behandelten Stoff aufbauen möchtest, fang deine Reise mit dem AI Engineer Karriere-Lernpfad!
RAG-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
DataCamp Team
Tutorial
Javier Canales Luna
Tutorial
Derrick Mwiti
