programa
Desarrollo de aplicaciones de IA
21 h
¿Y si cualquiera pudiera utilizar la inteligencia artificial avanzada, no sólo las grandes empresas tecnológicas? Esta es la gran idea que subyace en Qwen, una nueva familia de modelos de IA creada por Alibaba Cloud.
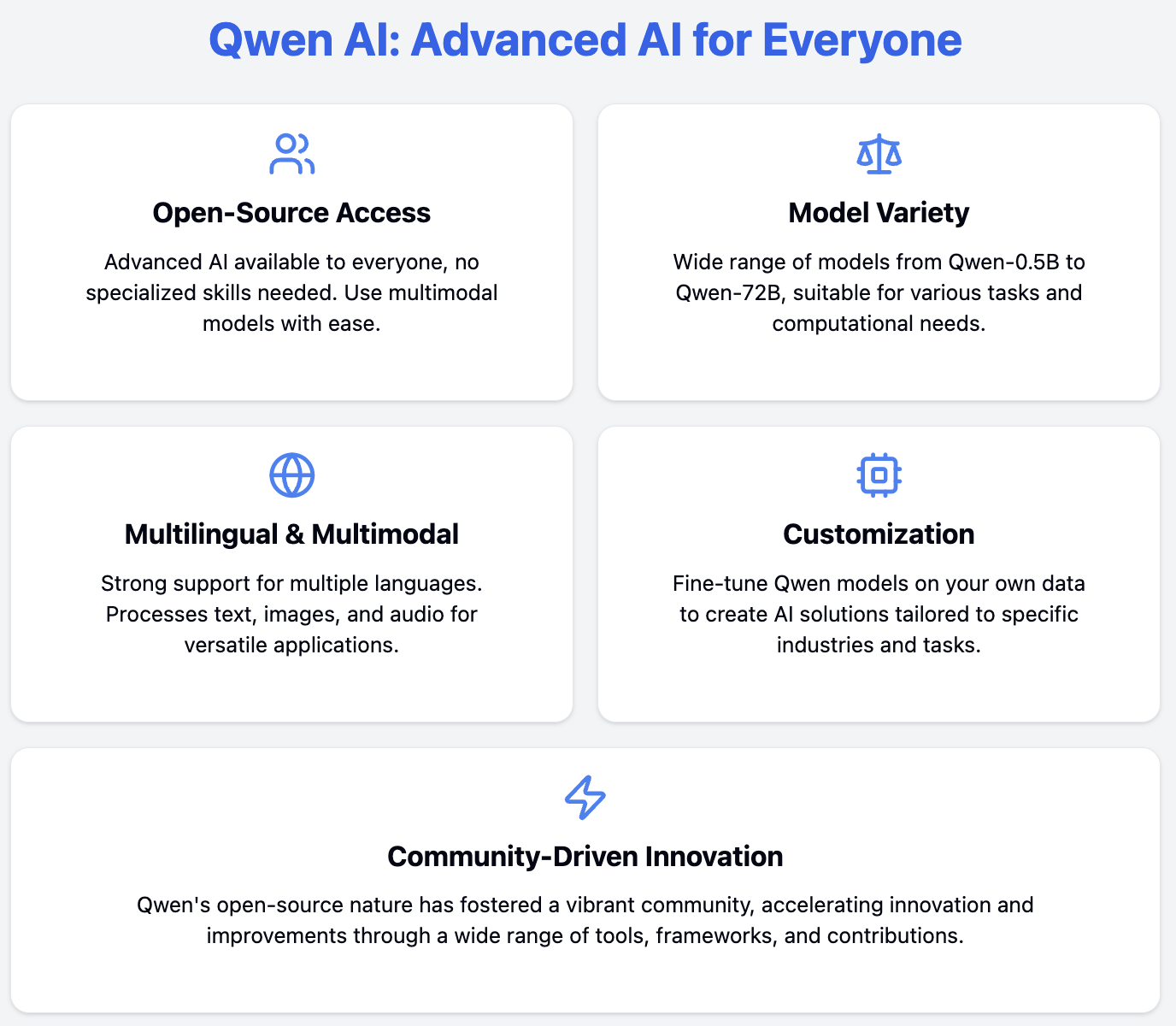
Qwen (que es la abreviatura de Tongyi Qianwen) está intentando que los modelos de IA sean fácilmente accesibles para todo el mundo con un conjunto de herramientas de IA fabricadas por Alibaba Cloud. Qwen lo hace ofreciendo:
Con Qwen, no necesitas tantos recursos ni tantos conocimientos especializados para utilizar la IA avanzada.

En este tutorial, lo haremos:
Qwen es una serie de potentes modelos entrenados en conjuntos de datos masivos multilingües y multimodales. Desarrollado por Alibaba Cloud, Qwen lleva la IA a nuevos niveles, haciéndola más inteligente y útil para el procesamiento del lenguaje natural, la visión por ordenador y la comprensión de audio.

Estos modelos son capaces de realizar una amplia gama de tareas, entre ellas:
Los modelos Qwen se preentrenan en diversas fuentes de datos y se perfeccionan mediante postentrenamiento en datos de alta calidad.
La familia Qwen consta de distintos modelos especializados diseñados para diferentes necesidades y casos de uso.
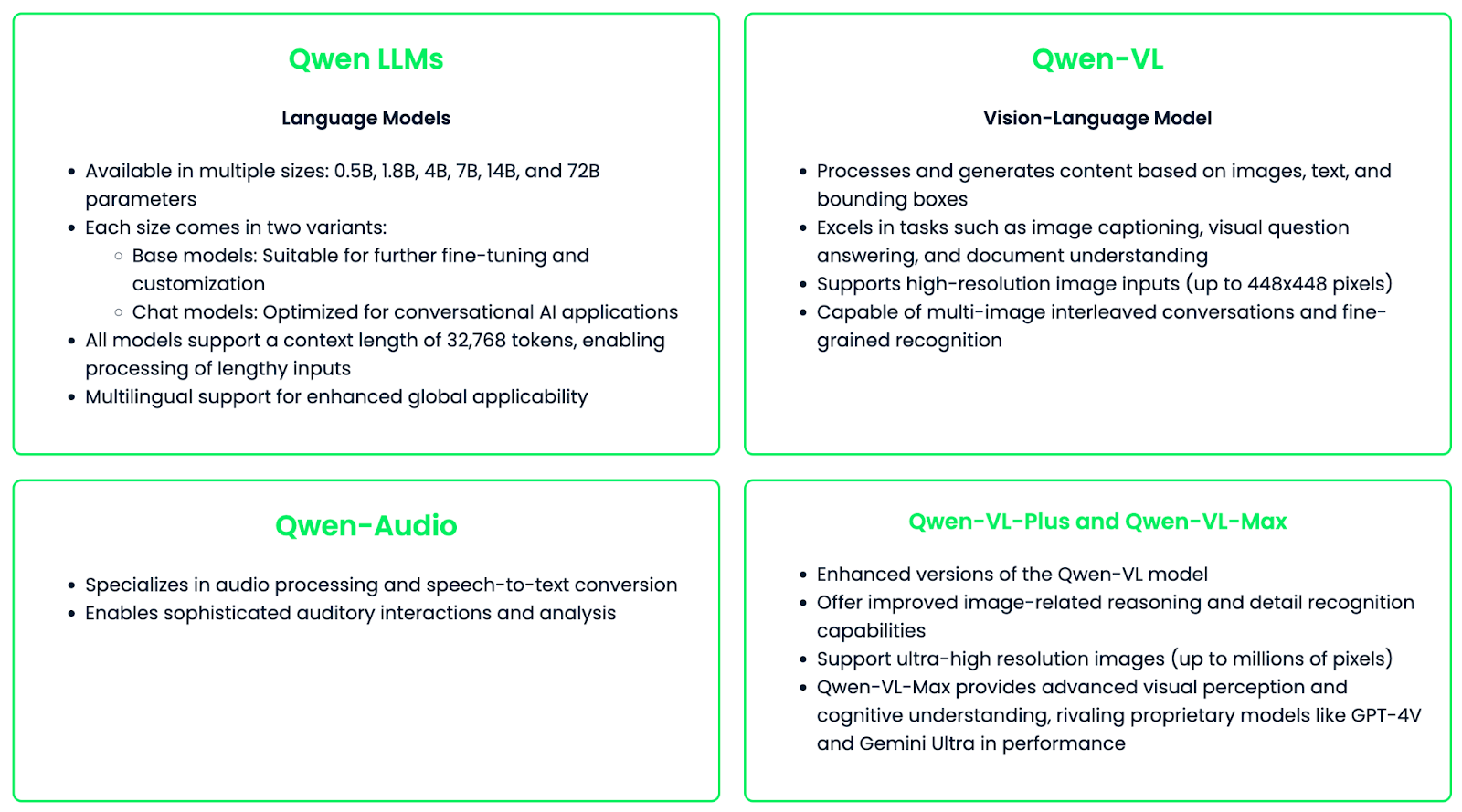
La familia de modelos Qwen está diseñada para ser versátil y fácil de personalizar, ofreciendo un ajuste fino para aplicaciones o industrias específicas. Esta flexibilidad, combinada con sus potentes capacidades, hace de Qwen un gran recurso para la tecnología de IA en distintos campos.
La familia de modelos de Qwen proporciona una herramienta potente y versátil para diversas aplicaciones de IA. Exploremos las características clave que distinguen a Qwen:
Qwen destaca en la comprensión y generación multilingües, con sólidas capacidades tanto en inglés como en chino, así como compatibilidad con otros muchos idiomas. Los últimos modelos Qwen2 han ampliado su repertorio lingüístico para incluir 27 lenguas más, que abarcan regiones como Europa Occidental, Europa Central y Oriental, Oriente Medio, Asia Oriental y Asia Meridional.
Esta amplia compatibilidad lingüística permite a Qwen facilitar la comunicación intercultural, realizar traducciones de alta calidad, manejar escenarios de cambio de código y servir a aplicaciones globales con generación de contenidos localizados.
Los modelos Qwen son muy competentes en diversas tareas de generación de texto. Algunas aplicaciones clave son:
La capacidad de los modelos para mantener el contexto en secuencias largas (hasta 32.768 tokens) permite generar salidas de texto extensas y coherentes.
Qwen también es muy bueno respondiendo a preguntas tanto objetivas como abiertas. Esta función permite:
Con el modelo Qwen-VL, la familia Qwen amplía sus capacidades a tareas multimodales con imágenes. Las características principales son:
Una de las características más significativas de Qwen es su naturaleza de código abierto, que aporta varios beneficios a la comunidad de IA:
El enfoque de código abierto ha dado lugar a un amplio apoyo de proyectos y herramientas de terceros:

Ahora que ya conoces Qwen y sus principales características, ¡es hora de aprender a utilizarlo en la práctica!
Los modelos Qwen están disponibles en varias plataformas, lo que los hace muy accesibles para diversos casos de uso.

En esta sección, te guiaré a través del proceso de utilización del modelo lingüístico Qwen-7B mediante Cara de abrazo. Cubriremos la configuración de tu entorno, el inicio de sesión en Hugging Face y la ejecución del modelo.
Primero, instala las bibliotecas necesarias:
pip install transformers torch huggingface_hubPara acceder al modelo Qwen-7B, tienes que iniciar sesión en tu cuenta de Hugging Face. Esto es necesario porque algunos modelos pueden tener restricciones de uso, pero aún así puedes acceder a modelos privados que te pertenezcan a ti o a tu organización. Esto ayuda a controlar el uso de la API e implantar límites de velocidad si es necesario.
Para conectarte, sigue estos pasos:
1. Ir a Cara de abrazo.
2. Ve a la configuración de tu perfil y crea un token de acceso.
3. En tu terminal, ejecuta
huggingface-cli login4. Cuando se te solicite, introduce tu código de acceso.
Ahora, crearemos un archivo Python o un archivo Jupyter Notebook donde empezaremos a escribir nuestro código.
En primer lugar, importaremos dos clases de la biblioteca transformers:
AutoModelForCausalLM: Esta clase selecciona automáticamente la arquitectura de modelo adecuada en función del nombre de modelo que le proporciones.AutoTokenizer: Esta clase carga el tokenizador correcto para el modelo que estás utilizando.from transformers import AutoModelForCausalLM, AutoTokenizerAhora, especificamos qué modelo queremos utilizar. "Qwen/Qwen-7B" se refiere a la versión de 7.000 millones de parámetros del modelo Qwen alojado en el centro de modelos de Cara Abrazada, pero siéntete libre de utilizar otros modelos Qwen.
model_name = "Qwen/Qwen-7B"A continuación, tenemos que cargar el tokenizador.
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)Esta línea carga el tokenizador asociado al modelo Qwen-7B. El parámetro trust_remote_code=True es necesario porque los modelos Qwen pueden requerir la ejecución de código personalizado durante la carga.
El siguiente paso es cargar el modelo.
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)Esto carga el modelo Qwen-7B real. De nuevo, utilizamos trust_remote_code=True para permitir que se ejecute cualquier código personalizado asociado al modelo.
Una vez cargado el modelo, podemos probar si funciona generando un texto a partir de una entrada.
input_text = "Once upon a time"
inputs = tokenizer(input_text, return_tensors="pt")Aquí estamos preparando la entrada para el modelo:
input_text como nuestro prompt.return_tensors="pt" especifica que queremos la salida en formato tensor PyTorch.Ahora, generamos el texto:
outputs = model.generate(**inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)La primera línea de código indica al modelo que genere texto:
inputs tokenizado al método generate.**inputs desempaqueta el diccionario devuelto por el tokenizador.max_new_tokens=50 limita la generación a un máximo de 50 fichas nuevas.generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)Este paso convierte la salida del modelo (que está en formato ID de token) de nuevo en texto legible:
outputs selecciona la primera y única (en este caso) secuencia generada.skip_special_tokens=True indica al descodificador que ignore los tokens especiales, como el relleno o los tokens de final de secuencia.Por último, imprimimos el texto generado para ver el resultado.
print(generated_text)Once upon a time, in a far-off kingdom, there lived a young princess named Lily.
She was known throughout the land for her kindness and beauty. Despite living in a grand castle with everything she could ever want, Lily felt something was missing in her life. She longed for adventure and to see the world beyond the castle walls.
One day, while walking in the royal gardens, she stumbled upon a hidden door overgrown with vines. Curiosity got the better of her, and she decided to see where it led. As she pushed open the creaky door, she found herself stepping into a magical forest filled with talking animals and glowing flowers.
Little did Lily know that this discovery would be the beginning of an extraordinary journey that would change her life forever…Aquí tienes algunas notas y consejos útiles:
trust_remote_code=True es necesario para los modelos Qwen, ya que requieren código personalizado para ejecutarse correctamente.Los modelos Qwen pueden desplegarse utilizando la Plataforma para la IA (PAI) de Alibaba Cloud y Elastic AI Serving (EAS). Veamos cómo puedes desplegar un modelo Qwen con sólo unos clics:

Exploremos algunos ejemplos prácticos de uso de Qwen para tareas de generación de texto y respuesta a preguntas.
Qwen es realmente bueno generando textos coherentes y contextualmente relevantes a partir de indicaciones dadas. Veamos algunos ejemplos:
prompt = "The future of artificial intelligence is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)The future of artificial intelligence is bright and full of potential. As technology continues to advance, AI will play an increasingly important role in various aspects of our lives. From healthcare and education to transportation and entertainment, AI will revolutionize the way we live and work. However, it's crucial to ensure that AI is developed and used responsibly, with proper ethical considerations and safeguards in place.prompt = "Write a short poem about the changing seasons:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=100, temperature=0.7)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)Leaves of gold and crimson fall,
As autumn's whisper fills the air.
Winter's chill soon follows all,
Blanketing the earth with care.
Spring awakens with gentle rain,
Coaxing buds to bloom anew.
Summer's warmth returns again,
Painting skies in vibrant blue.
Nature's cycle, ever turning,
Each season brings its own delight.
In this dance, we're always learning,
Of life's beauty, day and night.prompt = "Write a Python function to calculate the Fibonacci sequence:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=200, temperature=0.2)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)def fibonacci(n):
"""
Calculate the Fibonacci sequence up to the nth term.
Args:
n (int): The number of terms in the sequence to calculate.
Returns:
list: A list containing the Fibonacci sequence up to the nth term.
"""
if n <= 0:
return []
elif n == 1:
return [0]
elif n == 2:
return [0, 1]
fib_sequence = [0, 1]
for i in range(2, n):
fib_sequence.append(fib_sequence[i-1] + fib_sequence[i-2])
return fib_sequence
# Example usage:
print(fibonacci(10)) [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]Qwen puede utilizarse para responder a una amplia gama de preguntas, desde preguntas sobre hechos hasta preguntas más abiertas o analíticas. He aquí algunos ejemplos:
question = "What is the capital of France?"
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=50)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Q: {question}\nA: {answer}")Q: What is the capital of France?
A: The capital of France is Paris. Paris is the largest city in France and serves as the country's political, economic, and cultural center. It is known for its iconic landmarks such as the Eiffel Tower, the Louvre Museum, and Notre-Dame Cathedral.question = "What are the potential ethical concerns surrounding artificial intelligence?"
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=200, temperature=0.7)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Q: {question}\nA: {answer}")Q: What are the potential ethical concerns surrounding artificial intelligence?
A: There are several potential ethical concerns surrounding artificial intelligence (AI):
1. Privacy and data protection: AI systems often require large amounts of data, raising concerns about personal information collection and use.
2. Bias and discrimination: AI algorithms can perpetuate or amplify existing biases in training data, leading to unfair treatment of certain groups.
3. Job displacement: As AI becomes more advanced, it may replace human workers in various industries, potentially leading to unemployment and economic inequality.
4. Accountability and transparency: It can be challenging to understand how AI systems make decisions, making it difficult to assign responsibility for errors or harmful outcomes.
5. Autonomous weapons: The development of AI-powered weapons raises concerns about the ethics of warfare and the potential for uncontrolled escalation.
6. Superintelligence: There are concerns about the potential development of AI systems that surpass human intelligence, potentially posing existential risks to humanity.
7. Human autonomy: As AI systems become more integrated into our lives, there are concerns about the erosion of human decision-making and free will.
8. Security risks: AI systems can be vulnerable to hacking or manipulation, potentially leading to severe consequences in critical applications.
9. Social manipulation: AI-powered systems could be used to influence human behavior on a large scale, raising concerns about democracy and free will.
10. Ethical decision-making: As AI systems are tasked with making complex decisions, there are concerns about their ability to navigate ethical dilemmas appropriately.
Addressing these concerns requires ongoing dialogue between technologists, ethicists, policymakers, and the public to ensure responsible development and deployment of AI technologies.Estos ejemplos demuestran cómo Qwen puede manejar varios tipos de tareas de generación de texto y de respuesta a preguntas.
Puedes ajustar parámetros como max_new_tokens y temperature para controlar la longitud y la creatividad de las respuestas generadas y adaptarlas a tus necesidades específicas.
Ajuste fino Los modelos Qwen te permiten adaptarlos a tareas específicas, mejorando potencialmente su rendimiento para tu caso de uso particular. Este proceso implica entrenar el modelo preentrenado en un conjunto de datos personalizado, lo que le permite aprender conocimientos específicos de la tarea al tiempo que conserva sus capacidades generales de comprensión lingüística.
En esta sección, recorreremos el proceso de ajuste del modelo Qwen-7B en un conjunto de datos personalizado. Utilizaremos técnicas eficaces de ajuste fino para que este proceso sea manejable, incluso para modelos grandes. En nuestro ejemplo, estamos afinando el modelo para mejorar su rendimiento en tareas de traducción y en la respuesta a preguntas objetivas. Este proceso permite que el modelo aprenda de un conjunto de datos personalizado, al tiempo que conserva sus capacidades generales de comprensión lingüística.
Antes de empezar, asegúrate de que tienes instalado lo siguiente:
pip install datasets torch accelerate peftPrimero, prepara tu conjunto de datos en formato JSON. Cada entrada debe tener un campo de "indicación" y otro de "finalización". Guárdalo como custom_dataset.json. Utilizaremos este ejemplo:
[
{
"prompt": "Translate to French: 'Hello, how are you?'",
"completion": "Bonjour, comment allez-vous?"
},
{
"prompt": "What is the capital of Spain?",
"completion": "The capital of Spain is Madrid."
}
]Ahora añadimos las siguientes importaciones:
import torch
from transformers import TrainingArguments, Trainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_modelA continuación, definiremos una función para preprocesar nuestro conjunto de datos y cargarlo utilizando la biblioteca de conjuntos de datos Cara Abrazada:
def preprocess_function(examples):
inputs = [f"{prompt}\n" for prompt in examples["prompt"]]
targets = [f"{completion}\n" for completion in examples["completion"]]
model_inputs = tokenizer(inputs, max_length=512, truncation=True, padding="max_length")
labels = tokenizer(targets, max_length=512, truncation=True, padding="max_length")
model_inputs["labels"] = labels["input_ids"]
return model_inputs
dataset = load_dataset("json", data_files="custom_dataset.json")
tokenized_dataset = dataset["train"].train_test_split(test_size=0.1)
tokenized_dataset = tokenized_dataset.map(preprocess_function, batched=True, remove_columns=dataset["train"].column_names)Para que el ajuste sea más eficaz, utilizaremos LoRA (Adaptación de bajo rango). Esta técnica nos permite afinar grandes modelos con menos parámetros:
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)Ahora, configuraremos los argumentos de entrenamiento que controlan diversos aspectos del proceso de ajuste:
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
evaluation_strategy="steps",
eval_steps=500,
save_strategy="steps",
save_steps=1000,
learning_rate=1e-4,
fp16=True,
gradient_checkpointing=True,
gradient_accumulation_steps=4,
)Con nuestro conjunto de datos y argumentos de entrenamiento preparados, ya podemos crear un objeto Entrenador e iniciar el proceso de ajuste:
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
tokenizer=tokenizer,
)
trainer.train()Una vez finalizado el ajuste, guardaremos nuestro modelo para poder utilizarlo más adelante:
trainer.save_model("./fine_tuned_qwen")El ajuste fino del modelo Qwen-7B en tu conjunto de datos personalizado mejorará su rendimiento en tareas similares a las de tus datos de entrenamiento. En este caso, el modelo debería mejorar en la traducción del inglés al francés y en la respuesta a preguntas objetivas sobre las capitales.
Tras el ajuste, puedes utilizar el modelo para hacer inferencias:
fine_tuned_model = AutoModelForCausalLM.from_pretrained("./fine_tuned_qwen", trust_remote_code=True)
fine_tuned_tokenizer = AutoTokenizer.from_pretrained("./fine_tuned_qwen", trust_remote_code=True)
def generate_response(prompt):
inputs = fine_tuned_tokenizer(prompt, return_tensors="pt").to(fine_tuned_model.device)
outputs = fine_tuned_model.generate(**inputs, max_new_tokens=50)
return fine_tuned_tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
prompt = "Translate to French: 'Good morning, have a nice day!'"
response = generate_response(prompt)
print(f"Prompt: {prompt}\n Response: {response}")Prompt: Translate to French: 'Good morning, have a nice day!'
Response: Bonjour, passez une bonne journée !Aquí tienes algunos consejos a tener en cuenta para un ajuste eficaz:
El ajuste fino de Qwen en tu conjunto de datos personalizado te permite crear un modelo especializado que destaque en tu tarea específica, conservando al mismo tiempo los amplios conocimientos y capacidades del modelo original preentrenado. Este enfoque utiliza la potencia de los grandes modelos lingüísticos para tus aplicaciones y dominios únicos.
A medida que Qwen siga evolucionando, podemos anticipar varios desarrollos emocionantes:
Al concluir nuestra exploración de Qwen, está claro que estas herramientas de IA representan un importante salto adelante en la IA accesible, potente y versátil. Qwen es algo más que un conjunto de potentes modelos de IA: representa la visión de hacer que la IA avanzada sea accesible y adaptable para todos. Al proporcionar estas herramientas como recursos de código abierto, Alibaba Cloud está impulsando la innovación y el avance de la tecnología de IA.
Si quieres estar al día de lo último en IA, te recomiendo estos artículos:
Aprende IA con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Matt Crabtree
13 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Moez Ali



