
Track
Developing AI Applications
21 hr
What if anyone could use advanced artificial intelligence, not only big tech companies? This is the big idea behind Qwen, a new family of AI models created by Alibaba Cloud.
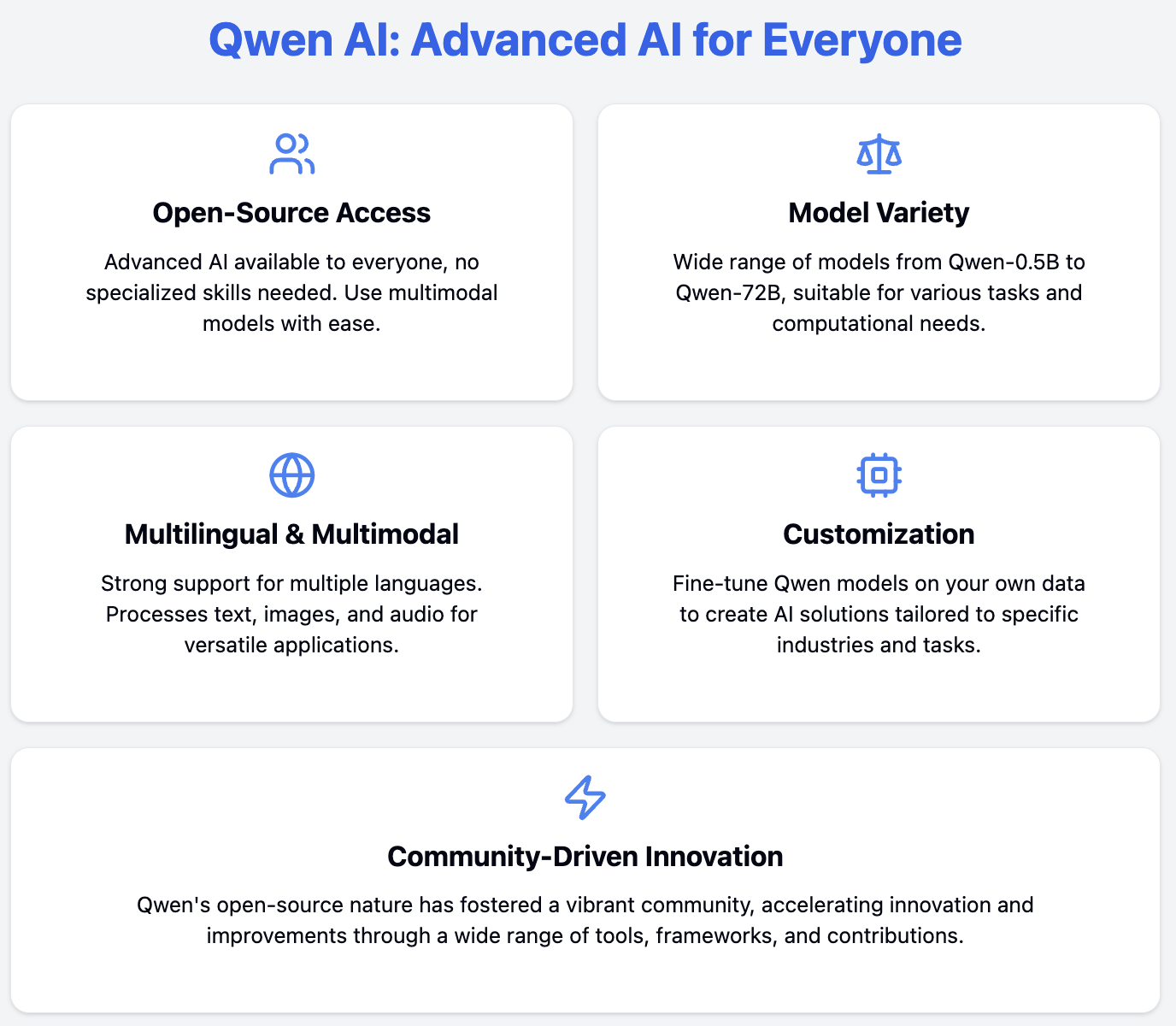
Qwen (which is short for Tongyi Qianwen) is trying to make AI models easily accessible for everyone with a set of AI tools made by Alibaba Cloud. Qwen does this by offering:
With Qwen, you don't need as many resources or as much specialized knowledge to use advanced AI.

In this tutorial, we will:
Qwen is a series of powerful models trained on massive multilingual and multimodal datasets. Developed by Alibaba Cloud, Qwen pushes AI to new levels, making it smarter and more useful for natural language processing, computer vision, and audio understanding.

These models are capable of performing a wide range of tasks, including:
The Qwen models are pre-trained on diverse data sources and refined through post-training on high-quality data.
The Qwen family consists of different specialized models designed for different needs and use cases.
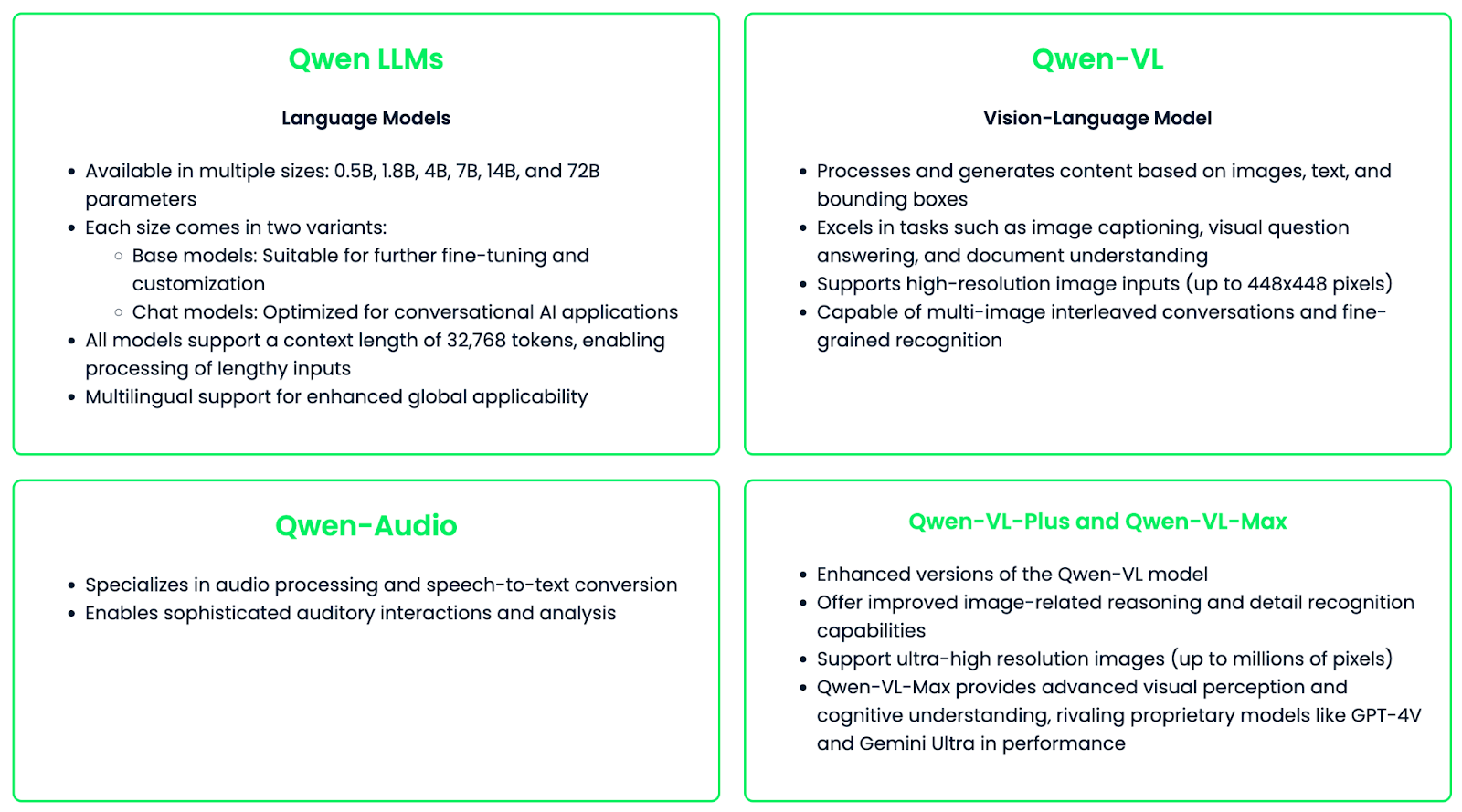
The Qwen family of models is designed for versatility and easy customization, offering fine-tuning for specific applications or industries. This flexibility, combined with their powerful capabilities, makes Qwen a great resource for AI technology across different fields.
Qwen's family of models provides a powerful and versatile tool for various AI applications. Let's explore the key features that set Qwen apart:
Qwen excels in multilingual understanding and generation, with strong capabilities in both English and Chinese, as well as support for numerous other languages. The latest Qwen2 models have expanded their linguistic repertoire to include 27 additional languages, covering regions such as Western Europe, Eastern and Central Europe, the Middle East, Eastern Asia, and Southern Asia.
This extensive language support enables Qwen to facilitate cross-cultural communication, perform high-quality translations, handle code-switching scenarios, and serve global applications with localized content generation.
Qwen models are highly proficient in various text generation tasks. Some key applications include:
The models' ability to maintain context over long sequences (up to 32,768 tokens) allows for the generation of extensive and coherent text outputs.
Qwen is also great in both factual and open-ended question answering. This feature enables:
With the Qwen-VL model, the Qwen family extends its capabilities to multimodal tasks involving images. Key features include:
One of Qwen's most significant features is its open-source nature, which brings several benefits to the AI community:
The open-source approach has led to widespread support from third-party projects and tools:

Now that you have learned about Qwen and its key features, it’s time to learn how to use it in practice!
Qwen models are available on several platforms, which makes it very accessible for various use cases.

In this section, I will guide you through the process of using the Qwen-7B language model via Hugging Face. We'll cover setting up your environment, logging in to Hugging Face, and running the model.
First, install the necessary libraries:
pip install transformers torch huggingface_hubTo access the Qwen-7B model, you need to log in to your Hugging Face account. This is necessary because some models might have usage restrictions, but you can still access private models belonging to yourself or your organization. This helps with monitoring API usage and implementing rate limits if necessary.
To log in, follow these steps:
1. Go to Hugging Face.
2. Go to your profile settings and create an access token.
3. In your terminal, run:
huggingface-cli login4. When prompted, enter your access token.
Now, we will create a Python file or Jupyter Notebook file where we will start writing our code.
First, we will import two classes from the transformers library:
AutoModelForCausalLM: This class automatically selects the appropriate model architecture based on the model name you provide.AutoTokenizer: This class loads the correct tokenizer for the model you're using.from transformers import AutoModelForCausalLM, AutoTokenizerNow, we're specifying which model we want to use. "Qwen/Qwen-7B" refers to the 7 billion parameter version of the Qwen model hosted on the Hugging Face model hub, but feel free to use other Qwen models.
model_name = "Qwen/Qwen-7B"Next, we need to load the tokenizer.
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)This line loads the tokenizer associated with the Qwen-7B model. The trust_remote_code=True parameter is necessary because Qwen models may require custom code to be executed during loading.
The next step is to load the model.
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)This loads the actual Qwen-7B model. Again, we use trust_remote_code=True to allow any custom code associated with the model to run.
Once we have loaded the model, we can test whether it works by generating some text given an input.
input_text = "Once upon a time"
inputs = tokenizer(input_text, return_tensors="pt")Here, we're preparing the input for the model:
input_text as our prompt.return_tensors="pt" argument specifies that we want the output in PyTorch tensor format.Now, we generate the text:
outputs = model.generate(**inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)The first line of code tells the model to generate text:
inputs to the generate method.**inputs unpacks the dictionary returned by the tokenizer.max_new_tokens=50 limits the generation to a maximum of 50 new tokens.generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)This step converts the model's output (which is in token ID format) back into readable text:
outputs selects the first and the only (in this case) generated sequence.skip_special_tokens=True tells the decoder to ignore special tokens like padding or end-of-sequence tokens.Finally, we print the generated text to see the result.
print(generated_text)Once upon a time, in a far-off kingdom, there lived a young princess named Lily.
She was known throughout the land for her kindness and beauty. Despite living in a grand castle with everything she could ever want, Lily felt something was missing in her life. She longed for adventure and to see the world beyond the castle walls.
One day, while walking in the royal gardens, she stumbled upon a hidden door overgrown with vines. Curiosity got the better of her, and she decided to see where it led. As she pushed open the creaky door, she found herself stepping into a magical forest filled with talking animals and glowing flowers.
Little did Lily know that this discovery would be the beginning of an extraordinary journey that would change her life forever…Here are some useful notes and tips:
trust_remote_code=True parameter is necessary for Qwen models as they require custom code to run properly.Qwen models can be deployed using Alibaba Cloud’s Platform for AI (PAI) and Elastic AI Serving (EAS). Let’s see how you can deploy a Qwen model with just a few clicks:

Let's explore some practical examples of using Qwen for text generation and question-answering tasks.
Qwen is really good at generating coherent and contextually relevant text based on given prompts. Let’s look at some examples:
prompt = "The future of artificial intelligence is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)The future of artificial intelligence is bright and full of potential. As technology continues to advance, AI will play an increasingly important role in various aspects of our lives. From healthcare and education to transportation and entertainment, AI will revolutionize the way we live and work. However, it's crucial to ensure that AI is developed and used responsibly, with proper ethical considerations and safeguards in place.prompt = "Write a short poem about the changing seasons:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=100, temperature=0.7)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)Leaves of gold and crimson fall,
As autumn's whisper fills the air.
Winter's chill soon follows all,
Blanketing the earth with care.
Spring awakens with gentle rain,
Coaxing buds to bloom anew.
Summer's warmth returns again,
Painting skies in vibrant blue.
Nature's cycle, ever turning,
Each season brings its own delight.
In this dance, we're always learning,
Of life's beauty, day and night.prompt = "Write a Python function to calculate the Fibonacci sequence:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=200, temperature=0.2)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)def fibonacci(n):
"""
Calculate the Fibonacci sequence up to the nth term.
Args:
n (int): The number of terms in the sequence to calculate.
Returns:
list: A list containing the Fibonacci sequence up to the nth term.
"""
if n <= 0:
return []
elif n == 1:
return [0]
elif n == 2:
return [0, 1]
fib_sequence = [0, 1]
for i in range(2, n):
fib_sequence.append(fib_sequence[i-1] + fib_sequence[i-2])
return fib_sequence
# Example usage:
print(fibonacci(10)) [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]Qwen can be used to answer a wide range of questions, from factual queries to more open-ended or analytical questions. Here are some examples:
question = "What is the capital of France?"
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=50)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Q: {question}\nA: {answer}")Q: What is the capital of France?
A: The capital of France is Paris. Paris is the largest city in France and serves as the country's political, economic, and cultural center. It is known for its iconic landmarks such as the Eiffel Tower, the Louvre Museum, and Notre-Dame Cathedral.question = "What are the potential ethical concerns surrounding artificial intelligence?"
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=200, temperature=0.7)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Q: {question}\nA: {answer}")Q: What are the potential ethical concerns surrounding artificial intelligence?
A: There are several potential ethical concerns surrounding artificial intelligence (AI):
1. Privacy and data protection: AI systems often require large amounts of data, raising concerns about personal information collection and use.
2. Bias and discrimination: AI algorithms can perpetuate or amplify existing biases in training data, leading to unfair treatment of certain groups.
3. Job displacement: As AI becomes more advanced, it may replace human workers in various industries, potentially leading to unemployment and economic inequality.
4. Accountability and transparency: It can be challenging to understand how AI systems make decisions, making it difficult to assign responsibility for errors or harmful outcomes.
5. Autonomous weapons: The development of AI-powered weapons raises concerns about the ethics of warfare and the potential for uncontrolled escalation.
6. Superintelligence: There are concerns about the potential development of AI systems that surpass human intelligence, potentially posing existential risks to humanity.
7. Human autonomy: As AI systems become more integrated into our lives, there are concerns about the erosion of human decision-making and free will.
8. Security risks: AI systems can be vulnerable to hacking or manipulation, potentially leading to severe consequences in critical applications.
9. Social manipulation: AI-powered systems could be used to influence human behavior on a large scale, raising concerns about democracy and free will.
10. Ethical decision-making: As AI systems are tasked with making complex decisions, there are concerns about their ability to navigate ethical dilemmas appropriately.
Addressing these concerns requires ongoing dialogue between technologists, ethicists, policymakers, and the public to ensure responsible development and deployment of AI technologies.These examples demonstrate how Qwen can handle various types of text generation and question-answering tasks.
You can adjust parameters like max_new_tokens and temperature to control the length and creativity of the generated responses to suit your specific needs.
Fine-tuning Qwen models allows you to adapt them to specific tasks, potentially improving their performance for your particular use case. This process involves training the pre-trained model on a custom dataset, allowing it to learn task-specific knowledge while retaining its general language understanding capabilities.
In this section, we'll walk through the process of fine-tuning the Qwen-7B model on a custom dataset. We'll use efficient fine-tuning techniques to make this process manageable, even for large models. In our example, we're fine-tuning the model to improve its performance on translation tasks and answering factual questions. This process allows the model to learn from a custom dataset while retaining its general language understanding capabilities.
Before we begin, make sure you have the following installed:
pip install datasets torch accelerate peftFirst, prepare your dataset in a JSON format. Each entry should have a "prompt" and a "completion" field. Save this as custom_dataset.json. We will use this example:
[
{
"prompt": "Translate to French: 'Hello, how are you?'",
"completion": "Bonjour, comment allez-vous?"
},
{
"prompt": "What is the capital of Spain?",
"completion": "The capital of Spain is Madrid."
}
]We now add the following imports:
import torch
from transformers import TrainingArguments, Trainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_modelNext, we'll define a function to preprocess our dataset and load it using the Hugging Face datasets library:
def preprocess_function(examples):
inputs = [f"{prompt}\n" for prompt in examples["prompt"]]
targets = [f"{completion}\n" for completion in examples["completion"]]
model_inputs = tokenizer(inputs, max_length=512, truncation=True, padding="max_length")
labels = tokenizer(targets, max_length=512, truncation=True, padding="max_length")
model_inputs["labels"] = labels["input_ids"]
return model_inputs
dataset = load_dataset("json", data_files="custom_dataset.json")
tokenized_dataset = dataset["train"].train_test_split(test_size=0.1)
tokenized_dataset = tokenized_dataset.map(preprocess_function, batched=True, remove_columns=dataset["train"].column_names)To make fine-tuning more efficient, we'll use LoRA (Low-Rank Adaptation). This technique allows us to fine-tune large models with fewer parameters:
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)Now, we'll set up the training arguments that control various aspects of the fine-tuning process:
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
evaluation_strategy="steps",
eval_steps=500,
save_strategy="steps",
save_steps=1000,
learning_rate=1e-4,
fp16=True,
gradient_checkpointing=True,
gradient_accumulation_steps=4,
)With our dataset and training arguments prepared, we can now create a Trainer object and start the fine-tuning process:
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
tokenizer=tokenizer,
)
trainer.train()After fine-tuning is complete, we'll save our model so we can use it later:
trainer.save_model("./fine_tuned_qwen")Fine-tuning the Qwen-7B model on your custom dataset will improve its performance on tasks similar to those in your training data. In this case, the model should improve at translating English to French and answering factual questions about capital cities.
After fine-tuning, you can use the model for inference:
fine_tuned_model = AutoModelForCausalLM.from_pretrained("./fine_tuned_qwen", trust_remote_code=True)
fine_tuned_tokenizer = AutoTokenizer.from_pretrained("./fine_tuned_qwen", trust_remote_code=True)
def generate_response(prompt):
inputs = fine_tuned_tokenizer(prompt, return_tensors="pt").to(fine_tuned_model.device)
outputs = fine_tuned_model.generate(**inputs, max_new_tokens=50)
return fine_tuned_tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
prompt = "Translate to French: 'Good morning, have a nice day!'"
response = generate_response(prompt)
print(f"Prompt: {prompt}\n Response: {response}")Prompt: Translate to French: 'Good morning, have a nice day!'
Response: Bonjour, passez une bonne journée !Here are some tips to consider for effective fine-tuning:
Fine-tuning Qwen on your custom dataset allows you to create a specialized model that excels at your specific task while retaining the broad knowledge and capabilities of the original pre-trained model. This approach uses the power of large language models for your unique applications and domains.
As Qwen continues to evolve, we can anticipate several exciting developments:
As we wrap up our exploration of Qwen, it's clear that these AI tools represent a significant leap forward in accessible, powerful, and versatile AI. Qwen is more than just a set of powerful AI models—it represents a vision of making advanced AI accessible and adaptable for everyone. Providing these tools as open-source resources, Alibaba Cloud is driving innovation and advancement in AI technology.
If you want to keep up with the latest in AI, I recommend these articles:
Learn AI with these courses!
Track
Course
Course
blog
Adel Nehme
7 min
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Andrea Valenzuela
Tutorial
Dimitri Didmanidze
