Curso
Implantar soluciones de IA en las empresas
2 h
51.7K
El coste computacional de entrenar grandes modelos lingüísticos (LLM) se nos está yendo cada vez más de las manos. Por ejemplo, el entrenamiento del GPT-4 costó a OpenAI aproximadamente 100 millones de dólares. El coste procede principalmente de las operaciones de multiplicación de matrices (MatMul para abreviar), y es natural que tanto investigadores como desarrolladores hayan intentado eliminarlo por completo o hacerlo más eficiente.
El artículo "Scalable MatMul-free Language Modeling " presenta un enfoque innovador que aborda esta cuestión de frente. Al eliminar por completo el MatMul de los LLM, los autores han desarrollado un modelo que mantiene un rendimiento competitivo a la vez que reduce significativamente los requisitos computacionales y de memoria.
Fuente: Rui-Jie Zhu et. al
Todos los modelos del documento están disponibles en HuggingFace:puedes probarlos en línea o localmente utilizando las bibliotecas de HuggingFace. Además, los investigadores han proporcionado su código en GitHub, lo que permite a otros entrenar sus modelos.
Si quieres comprender mejor la complejidad temporal cúbica de la multiplicación de matrices, te recomiendo esta introducción a la Notación Big-O y la Complejidad Temporal, que tiene una sección especial sobre la complejidad temporal de los LLM MatMul.
También hice una comparación entre los LLM sin MatMul y con MatMul; puedes encontrarla en este artículo: Matmul-Libres vs MatMul LLMs: Velocidad y consumo de memoria.
Los LLM modernos basados en transformadores dependen en gran medida de las operaciones de multiplicación de matrices, que son fundamentales para sus componentes principales, como los mecanismos de atención y las capas feedforward. Los costes computacionales y de memoria asociados a las operaciones MatMul son sustanciales, y afectan tanto a la fase de entrenamiento como a la de inferencia. A medida que aumenta el tamaño de los LLM, crece el número de parámetros y la complejidad de los cálculos, lo que convierte al MatMul en un importante cuello de botella.
Un ejemplo común de este problema es cuando la VRAM de una GPU es insuficiente para manejar el tamaño del modelo, obligando a los usuarios a entrenar o ejecutar la inferencia en CPUs en su lugar. Las CPU no están optimizadas para operaciones MatMul paralelizadas como las GPU, lo que da lugar a cálculos significativamente más lentos. Esto crea un bucle frustrante en el que el hardware disponible no puede utilizarse plenamente debido a las limitaciones de memoria, aunque la potencia de cálculo sea adecuada.
A lo largo de los años, los investigadores han explorado diversas estrategias para reducir la carga computacional de MatMul. La cuantificación, que consiste en reducir la precisión de los pesos y las activaciones, ha sido un enfoque popular. Al representar los números con menos bits, la cuantización puede reducir el coste computacional y la huella de memoria de las operaciones MatMul.
Sin embargo, este método suele sacrificar la precisión del modelo y no elimina por completo el MatMul. Esfuerzos notables como BitNet de Microsoft han demostrado que es posible escalar los LLM con cuantización binaria o ternaria, pero estos modelos siguen dependiendo de las operaciones MatMul para ciertas partes, como el mecanismo de autoatención.
También se han propuesto arquitecturas alternativas para resolver las ineficiencias de MatMul. Enfoques como AdderNet sustituyen las multiplicaciones por sumas en determinados componentes de la red, y las redes neuronales binarias/ternarias utilizan operaciones aritméticas simplificadas
Aunque estos métodos ofrecen algunas mejoras, normalmente no consiguen eliminar por completo el MatMul y sólo se dirigen a partes concretas del modelo. Como resultado, el coste computacional global sigue siendo elevado, lo que limita la escalabilidad y la eficacia de los LLM.
Para entender cómo funcionan los LM sin MatMul, examinemos la arquitectura subyacente y los componentes clave.
En las redes neuronales tradicionales, las capas densas (que conectan todas las neuronas entre dos capas consecutivas) se basan en MatMul para transformar los datos de entrada. Los autores las sustituyen por capas BitLineales, que utilizan pesos ternarios. En lugar de tener pesos que pueden ser cualquier número real, están limitados a sólo tres valores: -1, 0 ó 1.
Los pesos se entrenan inicialmente como valores de precisión completa, y luego, durante el entrenamiento, se cuantifican a valores ternarios mediante un proceso llamado "cuantificación absmediana". Este proceso escala la matriz de pesos por su valor absoluto medio y luego redondea cada elemento al entero ternario más próximo (-1, 0 ó 1).
Esta simplificación les permite sustituir las multiplicaciones en MatMul por sumas y restas. Por ejemplo, multiplicar un número por -1 es lo mismo que negarlo, multiplicarlo por 0 da como resultado 0, y multiplicarlo por 1 no modifica el número.
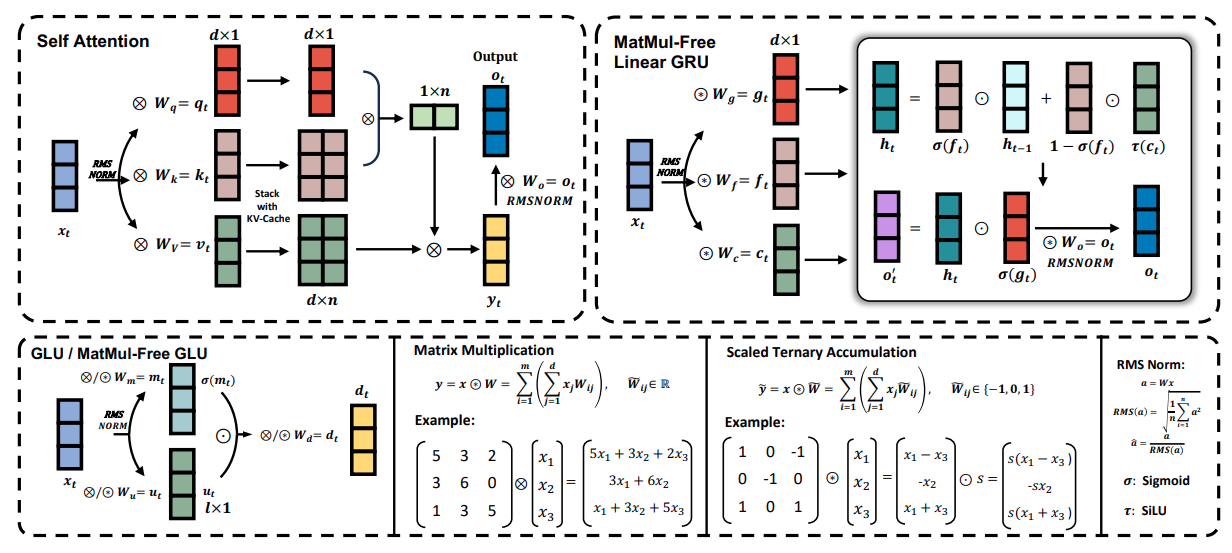
La figura siguiente ofrece una visión general de los componentes clave del Modelo de Lenguaje MatMul-Free, incluidas la Unidad Lineal Recurrente Gated MatMul-Free (MLGRU) y la Unidad Lineal Gated MatMul-Free (GLU):
Fuente: Rui-Jie Zhu et. al
La figura está dividida en varias secciones (de arriba a la izquierda y de abajo a la derecha):
La MLGRU funciona procesando la secuencia de entrada de un token cada vez. En cada paso, toma como entrada la incrustación del token actual y el estado oculto anterior. El estado oculto actúa como una memoria, almacenando información de fichas anteriores. A continuación, la MLGRU actualiza este estado oculto mediante una serie de operaciones de elemento a elemento y mecanismos de compuerta. Estas puertas, esencialmente vectores de números entre 0 y 1, controlan el flujo de información determinando qué partes del estado oculto anterior y de la incrustación de la ficha actual son más relevantes para el siguiente paso. Este proceso continúa hasta que se ha procesado toda la secuencia.
La unidad lineal cerrada (GLU) sin MatMul es otro componente clave del modelo de lenguaje sin MatMul. Mezcla información de las distintas dimensiones de la representación interna de las palabras del modelo (incrustaciones). En términos más sencillos, ayuda al modelo a comprender los distintos aspectos o características de cada palabra.
La GLU lo consigue utilizando un mecanismo de compuerta para controlar el flujo de información entre los distintos canales de incrustación. Este mecanismo de compuerta es similar a las compuertas de la MLGRU, pero actúa sobre la dimensión del canal en lugar de sobre la dimensión del testigo.
La GLU sin MatMul es una versión modificada de la GLU estándar, adaptada para eliminar las multiplicaciones matriciales mediante el uso de capas BitLineales, que son capas densas que emplean pesos ternarios (pesos que sólo pueden tomar los valores -1, 0 ó 1). En la GLU sin MatMul, la entrada se transforma primero utilizando dos capas BitLineales separadas. La salida de una capa se pasa a través de la función de activación SiLU y luego se multiplica elemento a elemento con la salida de la otra capa. Esta salida se pasa por otra capa BitLinear para producir la salida final.
Esto es sólo una explicación de alto nivel de los componentes MLGRU y GLU. Te animo a que consultes el trabajo de investigación original para conocer con más detalle su funcionamiento interno y sus formulaciones matemáticas.
La investigación estudia las leyes de escalado de los modelos sin MatMul, comparando su rendimiento con el de las arquitecturas Transformer tradicionales a medida que aumenta el tamaño del modelo.
Sorprendentemente, los resultados revelan que la diferencia de rendimiento entre estos dos enfoques se reduce a medida que aumenta el tamaño del modelo. Se trata de una observación significativa porque sugiere que los modelos sin MatMul son cada vez más competitivos con los Transformadores tradicionales a medida que aumentan de escala, pudiendo llegar a superarlos a escalas muy grandes.
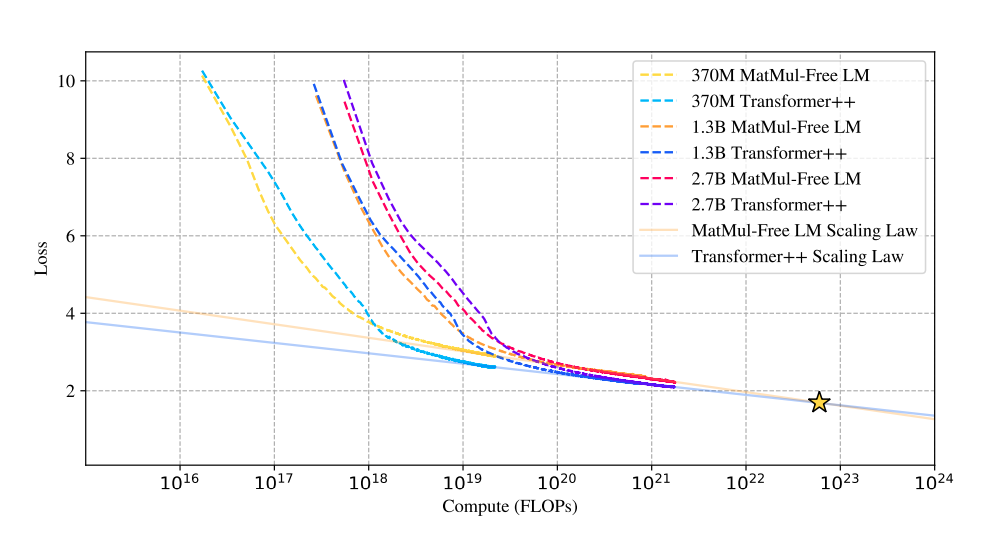
Fuente: Rui-Jie Zhu et. al
Este gráfico de comparación de leyes de escalado muestra que las curvas de pérdida de los LM sin MatMul y de los transformadores tradicionales convergen a medida que aumenta el número de operaciones en coma flotante (FLOPs).
Inicialmente, los LM sin MatMul presentan mayores pérdidas debido a las restricciones de los pesos ternarios. Sin embargo, esta diferencia disminuye a medida que aumenta el tamaño del modelo, y en cierto punto (estrella), las curvas de pérdida se cruzan, lo que indica un rendimiento comparable. Esto sugiere una ley de escalado más pronunciada para los modelos sin MatMul, lo que significa que su rendimiento mejora más rápidamente al aumentar el tamaño en comparación con los Transformadores tradicionales.
El rendimiento competitivo de los LM sin MatMul se ve reforzado por sus buenos resultados en varias pruebas de aprendizaje sin disparos. En tareas como ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA y OpenbookQA, estos modelos a menudo rinden a la par o superan a los Transformers tradicionales, a pesar de su complejidad computacional significativamente reducida. Esto demuestra la eficacia de las operaciones alternativas y las opciones arquitectónicas empleadas en los LM sin MatMul.
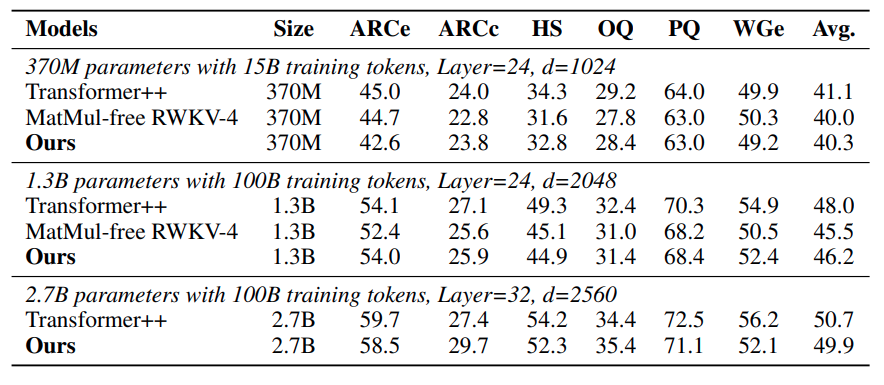
Fuente: Rui-Jie Zhu et. al
La tabla sobre la precisión del tiro cero muestra que los LM sin MatMul tienen un rendimiento competitivo en varias tareas. Por ejemplo, en el ARC-Challenge, una prueba de referencia especialmente difícil, el LM sin MatMul de 2,7B parámetros consigue una precisión superior a la de un modelo de transformador tradicional.
Del mismo modo, en las tareas Winogrande y OpenbookQA, los LM sin MatMul muestran un rendimiento sólido, lo que indica que la eliminación de MatMul no compromete la capacidad del modelo para comprender y generar lenguaje.
Una de las ventajas más llamativas de los LM sin MatMul es su excepcional eficiencia de memoria. Al sustituir las operaciones pesadas de multiplicación por sumas y restas más sencillas que permiten los pesos ternarios, estos modelos consiguen reducciones sustanciales en el uso de memoria.
Durante el entrenamiento, una implementación optimizada en la GPU puede reducir el consumo de memoria hasta un 61% en comparación con los modelos no optimizados. En inferencia, el ahorro de memoria es aún más espectacular, con reducciones de más de diez veces. Esto hace que los LM sin MatMul sean especialmente atractivos para su despliegue en dispositivos con recursos limitados, como los smartphones, donde la memoria suele ser un factor limitante.
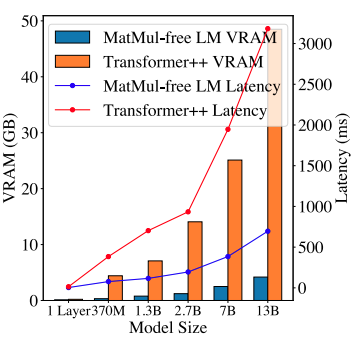
Fuente: Rui-Jie Zhu et. al
Este gráfico comparativo de la memoria y la latencia de la GPU ilustra la mayor eficiencia de los LM sin MatMul. El consumo de memoria de inferencia de un LM sin MatMul de 2,7B parámetros es significativamente menor que el de un Transformador tradicional comparable. Esta huella de memoria reducida no sólo permite desplegar modelos más grandes en un hardware limitado, sino que también se traduce en una latencia menor, lo que hace que estos modelos sean más adecuados para aplicaciones en tiempo real en las que la capacidad de respuesta es crucial.
Uno de los principales avances presentados en el artículo es la implementación optimizada en la GPU de los LM sin MatMul. Los autores consiguieron un aumento del 25,6% en la velocidad de entrenamiento y una reducción de hasta el 61,0% en el uso de memoria utilizando núcleos fusionados en su propia implementación de GPU. Estos núcleos combinan múltiples operaciones en un único proceso más eficiente, reduciendo la sobrecarga asociada al acceso a la memoria y al movimiento de datos.
Para explotar aún más las operaciones ligeras de los LM sin MatMul, los autores desarrollaron un acelerador FPGA personalizado en SystemVerilog. Las FPGAs (Field-Programmable Gate Arrays) ofrecen una plataforma de hardware flexible y eficiente para implementar tareas computacionales especializadas.
El acelerador personalizado se diseñó para aprovechar la simplicidad de las operaciones ternarias y los productos por elementos, consiguiendo un aumento sustancial de la eficiencia. La implementación RTL (Nivel de Transferencia de Registro) es fundamental en el proceso de diseño de la FPGA. Implica especificar el comportamiento del hardware a alto nivel, que luego se sintetiza en la configuración real de la FPGA. El diseño RTL personalizado para los LM sin MatMul garantiza que la FPGA pueda manejar eficazmente las operaciones ligeras, reduciendo el consumo de energía y aumentando el rendimiento.
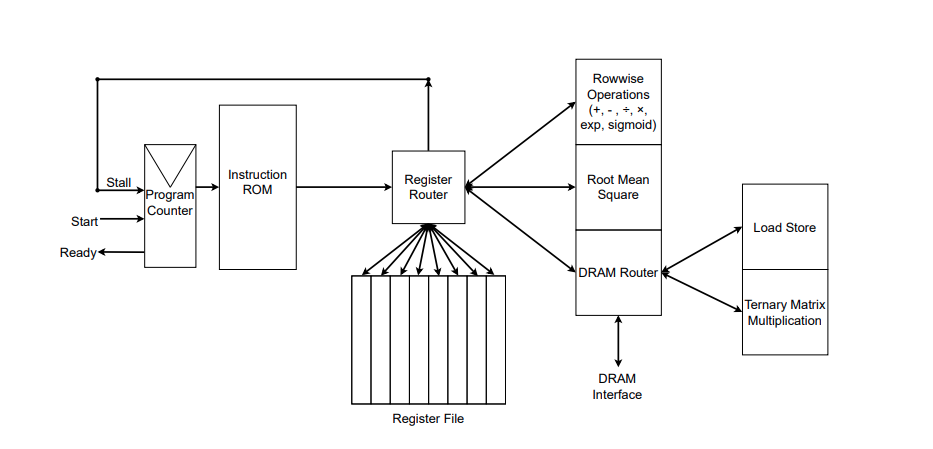
Fuente: Rui-Jie Zhu et. al
La figura ilustra la implementación RTL del acelerador FPGA personalizado. Puedes ver las funciones que implementa a la derecha del encaminador de registros. Los autores también desarrollaron su propio ensamblador para convertir los archivos ensambladores con instrucciones personalizadas en una ROM de instrucciones, que puedes ver a la derecha de la figura. Las instrucciones se dan al Enrutador de Registros, que gestiona la memoria (Archivo de Registros) y ejecuta la instrucción.
Además, los autores mencionaron en un comentario a la edición de GitHub que todavía se están optimizando las especificaciones completas de su implementación FPGA, y que el código SystemVerilog se hará público más adelante.
La tabla siguiente muestra la utilización de recursos y las métricas de rendimiento de la implementación en FPGA de la generación de fichas sin MatMul.
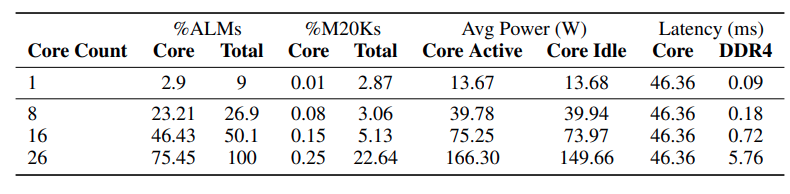
Fuente: Rui-Jie Zhu et. al
Los datos demuestran que a medida que aumenta el número de núcleos (unidades de procesamiento) dentro de la FPGA, la latencia global permanece inicialmente relativamente estable. Sin embargo, la latencia aumenta significativamente de 16 a 26 núcleos, lo que sugiere que la interfaz DDR4, responsable de la transferencia de datos, se está convirtiendo en un cuello de botella a medida que la demanda de transferencia de datos crece con el número de núcleos.
Aunque la operación de multiplicación matricial ternaria domina actualmente la latencia global, los autores prevén que la optimización de esta unidad en futuras implementaciones desplazará el cuello de botella a la interfaz DDR4.
Una de las afirmaciones más intrigantes del artículo es que su enfoque sin MatMul acerca a los LLM a una eficiencia similar a la del cerebro en términos de cálculo y consumo de energía. Los autores sostienen que sus modelos imitan la eficacia de las redes neuronales biológicas y alcanzan una velocidad de lectura similar a la humana.
Sin embargo, comparar directamente la eficacia de estos modelos con el intrincado funcionamiento de las redes neuronales biológicas es una cuestión compleja que requiere más investigación. Los mecanismos de cálculo del cerebro son muy diferentes y mucho más complejos que las operaciones simplificadas que se utilizan en los LM sin MatMul.
El artículo "Scalable MatMul-free Language Modeling" cuestiona un supuesto fundamental en el procesamiento del lenguaje natural: que la multiplicación matricial (MatMul) es esencial para construir LLM de alto rendimiento.
Al demostrar la viabilidad de las arquitecturas sin MatMul, esta investigación abre una nueva frontera en el diseño de LLM, fomentando la exploración de operaciones y paradigmas computacionales alternativos. Esto podría dar lugar a una oleada de innovación, en la que los investigadores desarrollarían nuevas arquitecturas de modelos.
Este cambio hacia modelos sin MatMul no sólo afecta al software, sino también al hardware. Los chips tradicionales, como las GPU, son excelentes para la multiplicación matricial, pero no son necesariamente los más adecuados para estos modelos nuevos y ligeros.
El acelerador FPGA personalizado construido por los investigadores es un atisbo del futuro del hardware de IA: chips especializados diseñados para exprimir hasta el último gramo de rendimiento de estos eficientes modelos. Esto podría dar lugar a toda una nueva generación de dispositivos impulsados por IA que sean más rápidos, más eficientes energéticamente y accesibles a un público más amplio.
Como persona que se preocupa por el medio ambiente, me entusiasma especialmente el potencial de los modelos sin MatMul para reducir la huella de carbono de la IA. El enorme consumo de energía de los grandes modelos lingüísticos actuales es realmente preocupante. Al reducir significativamente las demandas computacionales, esta investigación podría allanar el camino hacia tecnologías de IA más eficientes energéticamente y con una menor huella medioambiental.
Aunque el artículo "Scalable MatMul-free Language Modeling" supone un gran avance, también abre varias vías para seguir investigando: explorar diferentes arquitecturas sin MatMul, evaluar su rendimiento en una gama más amplia de tareas y comprender matemáticamente los límites teóricos de este enfoque son sólo algunas de las interesantes direcciones de investigación.
Además, el desarrollo de puntos de referencia estandarizados y métricas de evaluación específicas para los modelos sin MatMul facilitaría las comparaciones justas y aceleraría el progreso en este campo. El camino hacia una IA realmente eficaz y accesible no ha hecho más que empezar, y las posibilidades son ilimitadas. Además, ¡personalmente me hace mucha ilusión probar los futuros chatbots asistentes sin MatMul!
El artículo "Scalable MatMul-free Language Modeling" supone una importante contribución al campo de los LLM al introducir un novedoso enfoque que elimina las operaciones de multiplicación de matrices (MatMul).
Este avance aborda los cuellos de botella computacionales y de memoria asociados a los LLM tradicionales, allanando el camino para modelos más eficientes y escalables. Aprovechando las operaciones aditivas y los pesos ternarios, los autores demuestran que es posible mantener un rendimiento competitivo reduciendo significativamente la demanda de recursos.
El impacto potencial de esta investigación en el futuro del desarrollo y despliegue del LLM es profundo. Los modelos sin MatMul ofrecen una alternativa viable a las arquitecturas convencionales, permitiendo la creación de modelos ligeros y eficientes, muy adecuados para entornos con recursos limitados, como los dispositivos de borde y las plataformas móviles.
Si quieres aprender más sobre inteligencia artificial, consulta estos cursos de IA.
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
blog
Natassha Selvaraj
15 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali

