Programa
Desenvolvimento de aplicativos de IA
21 h
E se qualquer pessoa pudesse usar inteligência artificial avançada, não apenas as grandes empresas de tecnologia? Essa é a grande ideia por trás do Qwen, uma nova família de modelos de IA criada pela Alibaba Cloud.
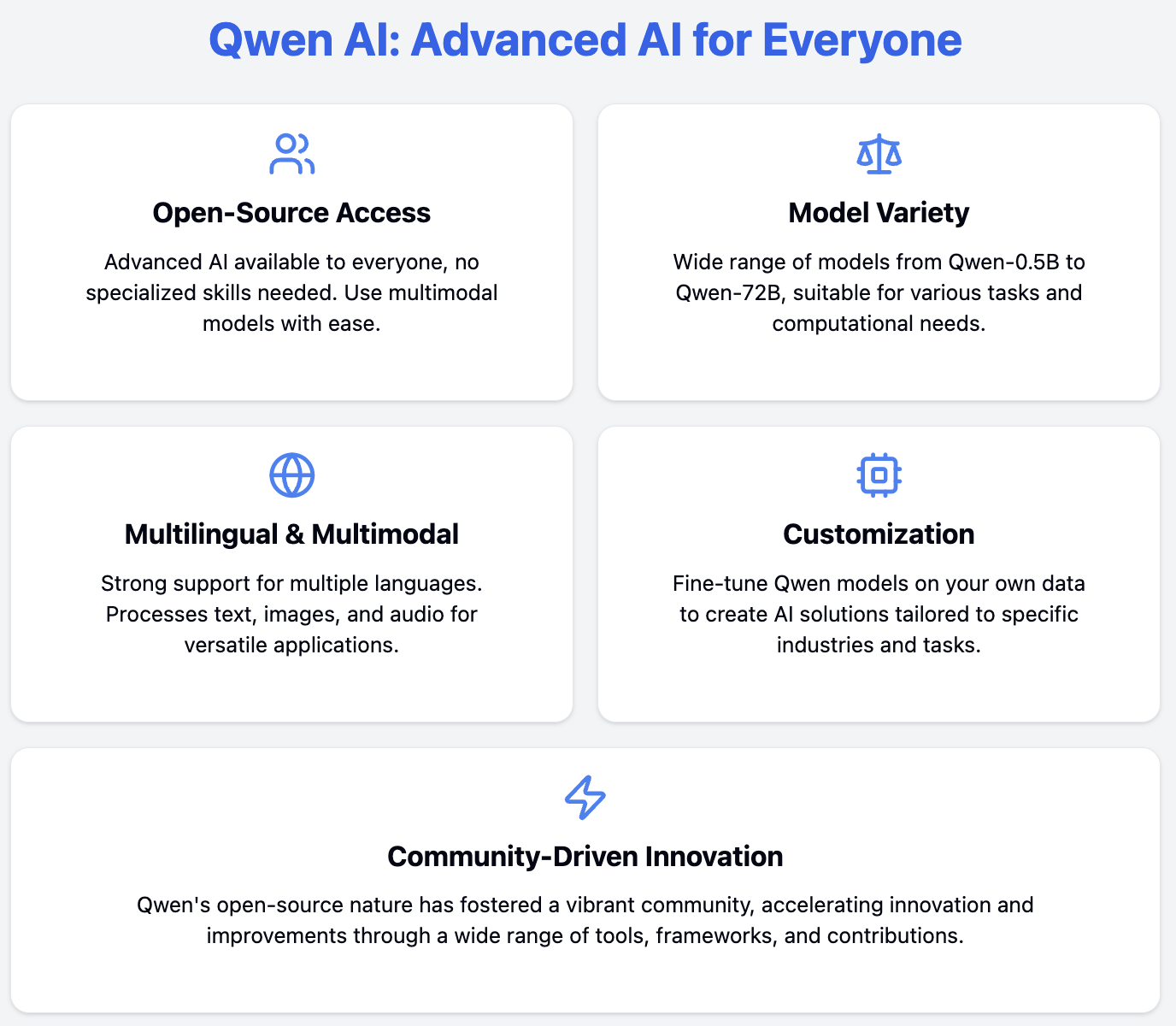
A Qwen (que é a abreviação de Tongyi Qianwen) está tentando tornar os modelos de IA facilmente acessíveis a todos com um conjunto de ferramentas de IA criadas pela Alibaba Cloud. Qwen faz isso por meio de ofertas:
Com o Qwen, você não precisa de tantos recursos ou de tanto conhecimento especializado para usar a IA avançada.

Neste tutorial, você verá:
O Qwen é uma série de modelos avançados treinados em conjuntos de dados multilíngues e multimodais maciços. Desenvolvido pela Alibaba Cloud, o Qwen leva a IA a novos níveis, tornando-a mais inteligente e mais útil para o processamento de linguagem natural, visão computacional e compreensão de áudio.

Esses modelos são capazes de executar uma ampla gama de tarefas, incluindo:
Os modelos Qwen são pré-treinados em diversas fontes de dados e refinados por meio de pós-treinamento em dados de alta qualidade.
A família Qwen consiste em diferentes modelos especializados projetados para diferentes necessidades e casos de uso.
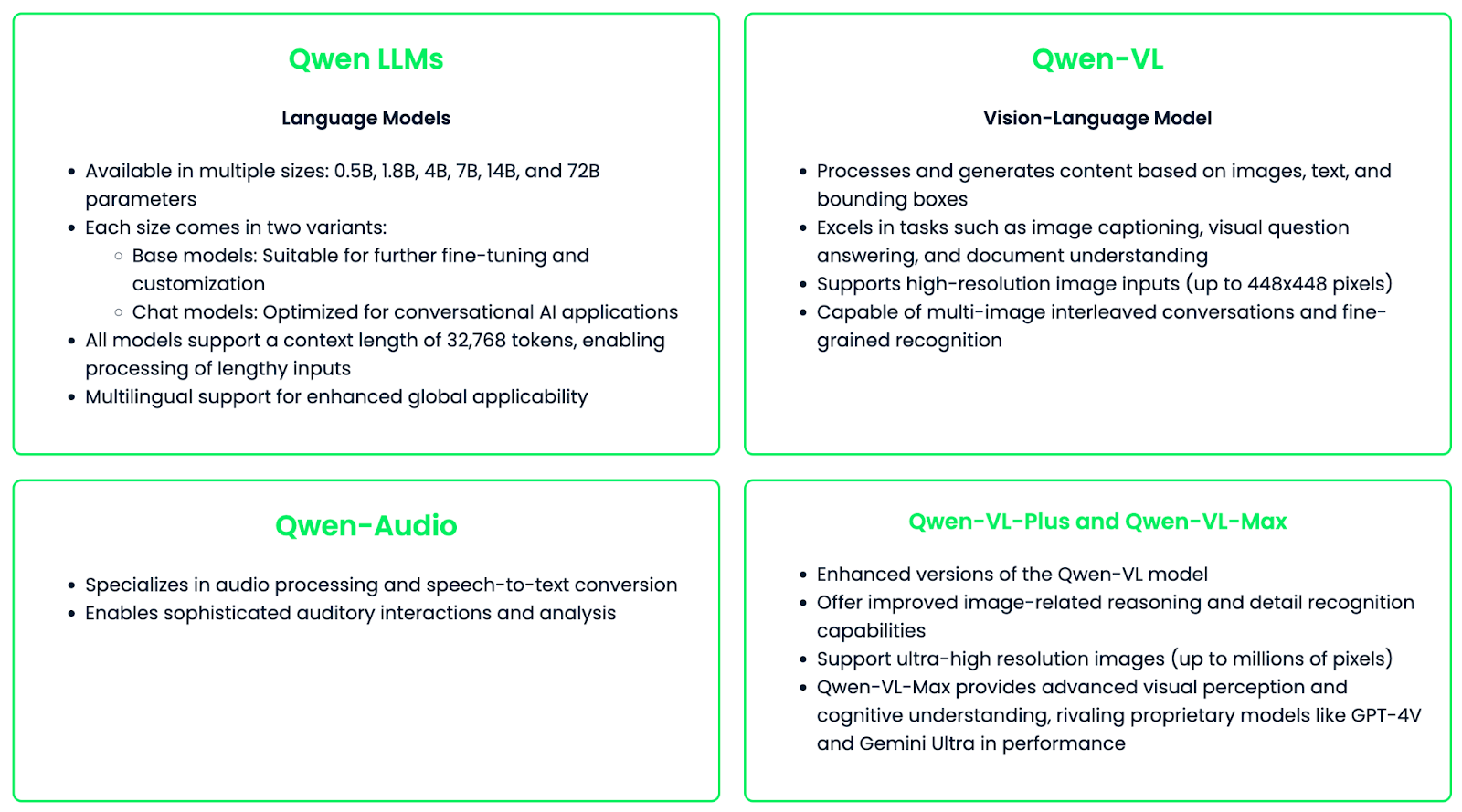
A família de modelos Qwen foi projetada para ser versátil e fácil de personalizar, oferecendo ajuste fino para aplicações ou setores específicos. Essa flexibilidade, combinada com seus recursos poderosos, faz da Qwen um ótimo recurso para a tecnologia de IA em diferentes campos.
A família de modelos da Qwen oferece uma ferramenta poderosa e versátil para vários aplicativos de IA. Vamos explorar os principais recursos que diferenciam o Qwen:
O Qwen se destaca na compreensão e geração multilíngue, com recursos sólidos em inglês e chinês, além de suporte para vários outros idiomas. Os modelos mais recentes do Qwen2 expandiram seu repertório linguístico para incluir 27 idiomas adicionais, abrangendo regiões como a Europa Ocidental, a Europa Central e Oriental, o Oriente Médio, a Ásia Oriental e a Ásia Meridional.
Esse amplo suporte a idiomas permite que o Qwen facilite a comunicação entre culturas, realize traduções de alta qualidade, lide com cenários de troca de código e atenda a aplicativos globais com geração de conteúdo localizado.
Os modelos Qwen são altamente proficientes em várias tarefas de geração de texto. Alguns dos principais aplicativos incluem:
A capacidade dos modelos de manter o contexto em sequências longas (até 32.768 tokens) permite a geração de resultados de texto extensos e coerentes.
O Qwen também é excelente para responder a perguntas factuais e abertas. Esse recurso permite que você:
Com o modelo Qwen-VL, a família Qwen amplia seus recursos para tarefas multimodais que envolvem imagens. Os principais recursos incluem:
Um dos recursos mais importantes do Qwen é sua natureza de código aberto, que traz vários benefícios para a comunidade de IA:
A abordagem de código aberto levou a um amplo suporte de projetos e ferramentas de terceiros:

Agora que você aprendeu sobre o Qwen e seus principais recursos, é hora de aprender a usá-lo na prática!
Os modelos Qwen estão disponíveis em várias plataformas, o que os torna muito acessíveis para vários casos de uso.

Nesta seção, orientarei você no processo de uso do modelo de linguagem Qwen-7B por meio de Hugging Face. Abordaremos a configuração do seu ambiente, o login no Hugging Face e a execução do modelo.
Primeiro, instale as bibliotecas necessárias:
pip install transformers torch huggingface_hubPara acessar o modelo Qwen-7B, você precisa fazer login na sua conta Hugging Face. Isso é necessário porque alguns modelos podem ter restrições de uso, mas você ainda pode acessar modelos privados que pertencem a você ou à sua organização. Isso ajuda a monitorar o uso da API e a implementar limites de taxa, se necessário.
Para fazer login, siga estas etapas:
1. Ir para Hugging Face.
2. Vá para as configurações do seu perfil e crie um token de acesso.
3. Em seu terminal, execute:
huggingface-cli login4. Quando solicitado, digite seu token de acesso.
Agora, criaremos um arquivo Python ou um arquivo do Jupyter Notebook onde começaremos a escrever nosso código.
Primeiro, importaremos duas classes da biblioteca transformers:
AutoModelForCausalLM: Essa classe seleciona automaticamente a arquitetura de modelo apropriada com base no nome do modelo que você fornece.AutoTokenizer: Essa classe carrega o tokenizador correto para o modelo que você está usando.from transformers import AutoModelForCausalLM, AutoTokenizerAgora, estamos especificando qual modelo queremos usar. "Qwen/Qwen-7B" refere-se à versão de 7 bilhões de parâmetros do modelo Qwen hospedado no hub do modelo Hugging Face, mas você pode usar outros modelos Qwen.
model_name = "Qwen/Qwen-7B"Em seguida, precisamos carregar o tokenizador.
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)Essa linha carrega o tokenizador associado ao modelo Qwen-7B. O parâmetro trust_remote_code=True é necessário porque os modelos Qwen podem exigir a execução de código personalizado durante o carregamento.
A próxima etapa é carregar o modelo.
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)Isso carrega o modelo Qwen-7B real. Novamente, usamos o site trust_remote_code=True para permitir que qualquer código personalizado associado ao modelo seja executado.
Depois de carregar o modelo, podemos testar se ele funciona gerando algum texto com uma entrada.
input_text = "Once upon a time"
inputs = tokenizer(input_text, return_tensors="pt")Aqui, estamos preparando a entrada para o modelo:
input_text como nosso prompt.return_tensors="pt" especifica que você deseja obter a saída no formato de tensor do PyTorch.Agora, vamos gerar o texto:
outputs = model.generate(**inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)A primeira linha de código informa ao modelo para gerar texto:
inputs tokenizado para o método generate.**inputs descompacta o dicionário retornado pelo tokenizador.max_new_tokens=50 limita a geração a um máximo de 50 novos tokens.generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)Essa etapa converte a saída do modelo (que está no formato de ID de token) novamente em texto legível:
outputs seleciona a primeira e a única (nesse caso) sequência gerada.skip_special_tokens=True diz ao decodificador para ignorar tokens especiais, como tokens de preenchimento ou de fim de sequência.Por fim, imprimimos o texto gerado para você ver o resultado.
print(generated_text)Once upon a time, in a far-off kingdom, there lived a young princess named Lily.
She was known throughout the land for her kindness and beauty. Despite living in a grand castle with everything she could ever want, Lily felt something was missing in her life. She longed for adventure and to see the world beyond the castle walls.
One day, while walking in the royal gardens, she stumbled upon a hidden door overgrown with vines. Curiosity got the better of her, and she decided to see where it led. As she pushed open the creaky door, she found herself stepping into a magical forest filled with talking animals and glowing flowers.
Little did Lily know that this discovery would be the beginning of an extraordinary journey that would change her life forever…Aqui estão algumas observações e dicas úteis:
trust_remote_code=True é necessário para os modelos Qwen, pois eles exigem código personalizado para serem executados corretamente.Os modelos Qwen podem ser implantados usando a Plataforma para IA (PAI) e o Elastic AI Serving (EAS) da Alibaba Cloud. Vamos ver como você pode implementar um modelo Qwen com apenas alguns cliques:

Vamos explorar alguns exemplos práticos de uso do Qwen para geração de texto e tarefas de resposta a perguntas.
O Qwen é realmente bom em gerar textos coerentes e contextualmente relevantes com base em solicitações dadas. Vamos dar uma olhada em alguns exemplos:
prompt = "The future of artificial intelligence is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)The future of artificial intelligence is bright and full of potential. As technology continues to advance, AI will play an increasingly important role in various aspects of our lives. From healthcare and education to transportation and entertainment, AI will revolutionize the way we live and work. However, it's crucial to ensure that AI is developed and used responsibly, with proper ethical considerations and safeguards in place.prompt = "Write a short poem about the changing seasons:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=100, temperature=0.7)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)Leaves of gold and crimson fall,
As autumn's whisper fills the air.
Winter's chill soon follows all,
Blanketing the earth with care.
Spring awakens with gentle rain,
Coaxing buds to bloom anew.
Summer's warmth returns again,
Painting skies in vibrant blue.
Nature's cycle, ever turning,
Each season brings its own delight.
In this dance, we're always learning,
Of life's beauty, day and night.prompt = "Write a Python function to calculate the Fibonacci sequence:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=200, temperature=0.2)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)def fibonacci(n):
"""
Calculate the Fibonacci sequence up to the nth term.
Args:
n (int): The number of terms in the sequence to calculate.
Returns:
list: A list containing the Fibonacci sequence up to the nth term.
"""
if n <= 0:
return []
elif n == 1:
return [0]
elif n == 2:
return [0, 1]
fib_sequence = [0, 1]
for i in range(2, n):
fib_sequence.append(fib_sequence[i-1] + fib_sequence[i-2])
return fib_sequence
# Example usage:
print(fibonacci(10)) [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]O Qwen pode ser usado para responder a uma ampla gama de perguntas, desde consultas factuais até perguntas mais abertas ou analíticas. Aqui estão alguns exemplos:
question = "What is the capital of France?"
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=50)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Q: {question}\nA: {answer}")Q: What is the capital of France?
A: The capital of France is Paris. Paris is the largest city in France and serves as the country's political, economic, and cultural center. It is known for its iconic landmarks such as the Eiffel Tower, the Louvre Museum, and Notre-Dame Cathedral.question = "What are the potential ethical concerns surrounding artificial intelligence?"
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=200, temperature=0.7)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Q: {question}\nA: {answer}")Q: What are the potential ethical concerns surrounding artificial intelligence?
A: There are several potential ethical concerns surrounding artificial intelligence (AI):
1. Privacy and data protection: AI systems often require large amounts of data, raising concerns about personal information collection and use.
2. Bias and discrimination: AI algorithms can perpetuate or amplify existing biases in training data, leading to unfair treatment of certain groups.
3. Job displacement: As AI becomes more advanced, it may replace human workers in various industries, potentially leading to unemployment and economic inequality.
4. Accountability and transparency: It can be challenging to understand how AI systems make decisions, making it difficult to assign responsibility for errors or harmful outcomes.
5. Autonomous weapons: The development of AI-powered weapons raises concerns about the ethics of warfare and the potential for uncontrolled escalation.
6. Superintelligence: There are concerns about the potential development of AI systems that surpass human intelligence, potentially posing existential risks to humanity.
7. Human autonomy: As AI systems become more integrated into our lives, there are concerns about the erosion of human decision-making and free will.
8. Security risks: AI systems can be vulnerable to hacking or manipulation, potentially leading to severe consequences in critical applications.
9. Social manipulation: AI-powered systems could be used to influence human behavior on a large scale, raising concerns about democracy and free will.
10. Ethical decision-making: As AI systems are tasked with making complex decisions, there are concerns about their ability to navigate ethical dilemmas appropriately.
Addressing these concerns requires ongoing dialogue between technologists, ethicists, policymakers, and the public to ensure responsible development and deployment of AI technologies.Esses exemplos demonstram como o Qwen pode lidar com vários tipos de geração de texto e tarefas de resposta a perguntas.
Você pode ajustar parâmetros como max_new_tokens e temperature para controlar a duração e a criatividade das respostas geradas para atender às suas necessidades específicas.
Ajuste fino Os modelos Qwen permitem que você os adapte a tarefas específicas, melhorando potencialmente o desempenho deles para o seu caso de uso específico. Esse processo envolve o treinamento do modelo pré-treinado em um conjunto de dados personalizado, permitindo que ele aprenda conhecimentos específicos da tarefa e, ao mesmo tempo, mantenha seus recursos gerais de compreensão da linguagem.
Nesta seção, vamos percorrer o processo de ajuste fino do modelo Qwen-7B em um conjunto de dados personalizado. Usaremos técnicas eficientes de ajuste fino para tornar esse processo gerenciável, mesmo para modelos grandes. Em nosso exemplo, estamos ajustando o modelo para melhorar seu desempenho em tarefas de tradução e resposta a perguntas factuais. Esse processo permite que o modelo aprenda com um conjunto de dados personalizado e, ao mesmo tempo, mantenha seus recursos gerais de compreensão de linguagem.
Antes de começarmos, verifique se você tem os seguintes itens instalados:
pip install datasets torch accelerate peftPrimeiro, prepare seu conjunto de dados em um formato JSON. Cada entrada deve ter um campo "prompt" e um campo "completion". Salve isso como custom_dataset.json. Usaremos este exemplo:
[
{
"prompt": "Translate to French: 'Hello, how are you?'",
"completion": "Bonjour, comment allez-vous?"
},
{
"prompt": "What is the capital of Spain?",
"completion": "The capital of Spain is Madrid."
}
]Agora, adicionamos as seguintes importações:
import torch
from transformers import TrainingArguments, Trainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_modelEm seguida, definiremos uma função para pré-processar nosso conjunto de dados e carregá-lo usando a biblioteca de conjuntos de dados Hugging Face:
def preprocess_function(examples):
inputs = [f"{prompt}\n" for prompt in examples["prompt"]]
targets = [f"{completion}\n" for completion in examples["completion"]]
model_inputs = tokenizer(inputs, max_length=512, truncation=True, padding="max_length")
labels = tokenizer(targets, max_length=512, truncation=True, padding="max_length")
model_inputs["labels"] = labels["input_ids"]
return model_inputs
dataset = load_dataset("json", data_files="custom_dataset.json")
tokenized_dataset = dataset["train"].train_test_split(test_size=0.1)
tokenized_dataset = tokenized_dataset.map(preprocess_function, batched=True, remove_columns=dataset["train"].column_names)Para tornar o ajuste fino mais eficiente, usaremos LoRA (Low-Rank Adaptation). Essa técnica nos permite fazer o ajuste fino de modelos grandes com menos parâmetros:
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)Agora, configuraremos os argumentos de treinamento que controlam vários aspectos do processo de ajuste fino:
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
evaluation_strategy="steps",
eval_steps=500,
save_strategy="steps",
save_steps=1000,
learning_rate=1e-4,
fp16=True,
gradient_checkpointing=True,
gradient_accumulation_steps=4,
)Com nosso conjunto de dados e argumentos de treinamento preparados, agora podemos criar um objeto Trainer e iniciar o processo de ajuste fino:
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
tokenizer=tokenizer,
)
trainer.train()Após a conclusão do ajuste fino, salvaremos nosso modelo para que você possa usá-lo mais tarde:
trainer.save_model("./fine_tuned_qwen")O ajuste fino do modelo Qwen-7B em seu conjunto de dados personalizado melhorará o desempenho dele em tarefas semelhantes às dos dados de treinamento. Nesse caso, o modelo deve melhorar a tradução do inglês para o francês e responder a perguntas factuais sobre as capitais.
Após o ajuste fino, você pode usar o modelo para inferência:
fine_tuned_model = AutoModelForCausalLM.from_pretrained("./fine_tuned_qwen", trust_remote_code=True)
fine_tuned_tokenizer = AutoTokenizer.from_pretrained("./fine_tuned_qwen", trust_remote_code=True)
def generate_response(prompt):
inputs = fine_tuned_tokenizer(prompt, return_tensors="pt").to(fine_tuned_model.device)
outputs = fine_tuned_model.generate(**inputs, max_new_tokens=50)
return fine_tuned_tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
prompt = "Translate to French: 'Good morning, have a nice day!'"
response = generate_response(prompt)
print(f"Prompt: {prompt}\n Response: {response}")Prompt: Translate to French: 'Good morning, have a nice day!'
Response: Bonjour, passez une bonne journée !Aqui estão algumas dicas que você deve considerar para fazer um ajuste fino eficaz:
O ajuste fino do Qwen em seu conjunto de dados personalizado permite que você crie um modelo especializado que se destaca em sua tarefa específica, mantendo o amplo conhecimento e os recursos do modelo original pré-treinado. Essa abordagem usa o poder de grandes modelos de linguagem para seus aplicativos e domínios exclusivos.
À medida que a Qwen continua a evoluir, podemos antecipar vários desenvolvimentos interessantes:
Ao concluirmos nossa exploração do Qwen, fica claro que essas ferramentas de IA representam um avanço significativo em IA acessível, poderosa e versátil. O Qwen é mais do que apenas um conjunto de modelos avançados de IA - ele representa uma visão de tornar a IA avançada acessível e adaptável para todos. Ao fornecer essas ferramentas como recursos de código aberto, a Alibaba Cloud está impulsionando a inovação e o avanço da tecnologia de IA.
Se você quiser ficar por dentro das últimas novidades em IA, recomendo estes artigos:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
5 min
Tutorial
Josep Ferrer
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita


