programa
Fundamentos del negocio de la IA
12 h
QwQ-32B no es un modelo de IA normal al estilo de un chatbot, sino que pertenece a una categoría diferente: los modelos de razonamiento.
Mientras que la mayoría de los modelos de IA de propósito general, como GPT-4.5 o DeepSeek-V3están diseñados para generar textos fluidos y conversacionales sobre una amplia gama de temas, los modelos de razonamiento se centran en descomponer los problemas lógicamente, trabajar por pasos y llegar a respuestas estructuradas.
En el ejemplo siguiente, podemos ver directamente el proceso de pensamiento de QwQ-32B:
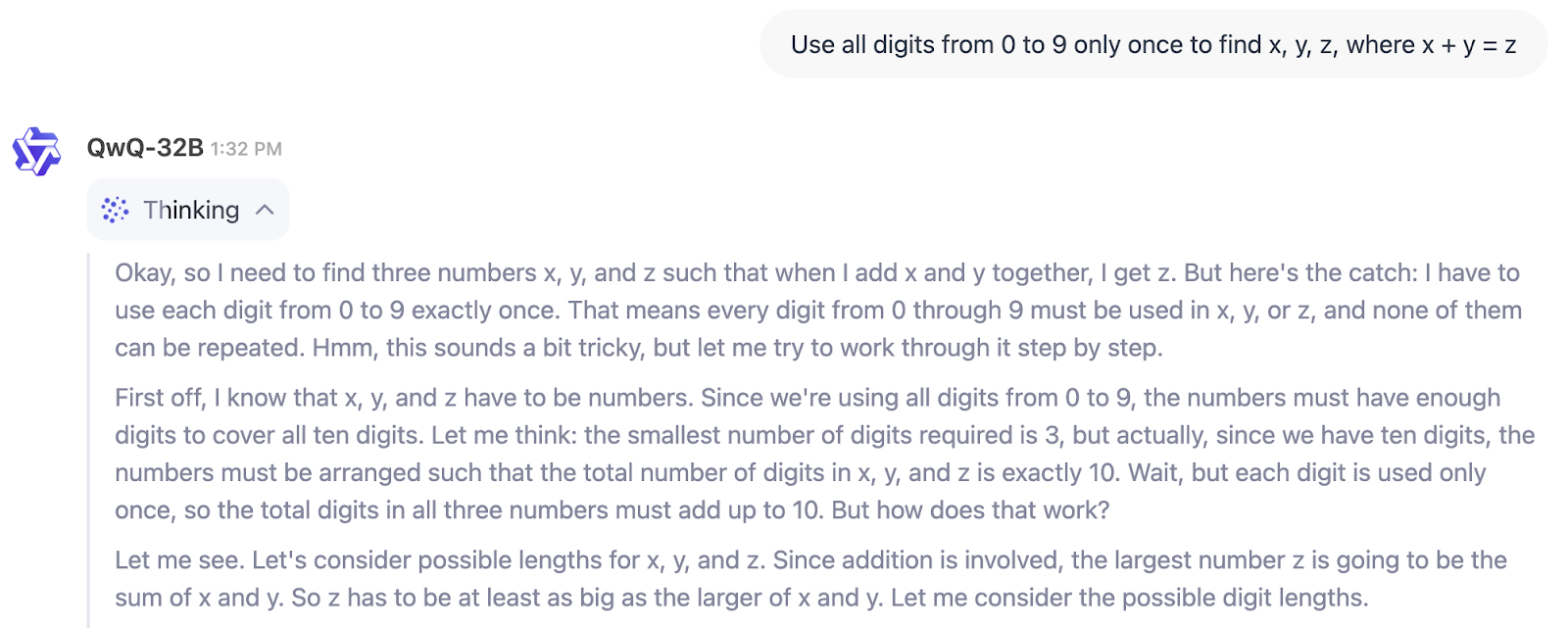
Entonces, ¿para quién es el QwQ-32B? Si buscas un modelo que te ayude a escribir, hacer una lluvia de ideas o resumir, no es éste.
Pero si necesitas algo para abordar problemas técnicos, verificar soluciones de varios pasos o ayudar en ámbitos como la investigación científica, las finanzas o el desarrollo de software, QwQ-32B está hecho para ese tipo de razonamiento estructurado. Es especialmente útil para ingenieros, investigadores y desarrolladores que necesitan una IA capaz de manejar flujos de trabajo lógicos en lugar de limitarse a generar texto.
También hay que tener en cuenta una tendencia más amplia del sector. De forma similar al auge de los pequeños modelos lingüísticos (PML)puede que estemos asistiendo con QwQ-32B a la aparición de "pequeños modelos de razonamiento" (me he inventado totalmente este término). ¿Por qué digo esto? Pues bien, hay una diferencia de 20 veces entre los parámetros 671B de DeepSeek-R1 y los 32B de QwQ-32B, aunque QwQ-32B sigue acercándose en rendimiento (como veremos más adelante en la sección sobre pruebas comparativas).
El QwQ-32B está hecho para razonar a través de problemas complejos, y gran parte de ello proviene de cómo fue entrenado. A diferencia de los modelos de IA tradicionales, que sólo se basan en el preentrenamiento y el ajuste finoQwQ-32B incorpora aprendizaje por refuerzo (RL)un método que permite al modelo refinar su razonamiento aprendiendo del ensayo y error.
Este enfoque de entrenamiento ha ido ganando adeptos en el espacio de la IA, con modelos como DeepSeek-R1 que utilizan el entrenamiento RL multietapa para conseguir mayores capacidades de razonamiento.
La mayoría de los modelos lingüísticos aprenden prediciendo la siguiente palabra de una frase basándose en grandes cantidades de datos de texto. Aunque esto funciona bien para la fluidez, no les hace necesariamente buenos en la resolución de problemas.
El aprendizaje por refuerzo cambia esto introduciendo un sistema de retroalimentación: en lugar de limitarse a generar texto, el modelo recibe recompensas por encontrar la respuesta correcta o seguir una ruta de razonamiento correcta. Con el tiempo, esto ayuda a la IA a desarrollar un mejor juicio a la hora de abordar problemas complejos como las matemáticas, la codificación y el razonamiento lógico .
QwQ-32B va más allá al integrar capacidades relacionadas con los agentes, lo que le permite adaptar su razonamiento en función de la información del entorno. Esto significa que, en lugar de limitarse a memorizar patrones, el modelo puede utilizar herramientas, verificar resultados y refinar sus respuestas dinámicamente. Estas mejoras lo hacen más fiable para tareas de razonamiento estructurado, en las que no basta con predecir palabras.
Uno de los aspectos más impresionantes del desarrollo del QwQ-32B es su eficacia. A pesar de tener sólo 32.000 millones de parámetros, consigue un rendimiento comparable al de DeepSeek-R1, que tiene 671.000 millones de parámetros (con 37.000 millones activados). Esto sugiere que ampliar el aprendizaje por refuerzo puede ser tan impactante como aumentar el tamaño del modelo.
Otro aspecto clave de su diseño es su ventana contextual de 131.072 tokens, que le permite procesar y retener información en largos pasajes de texto.
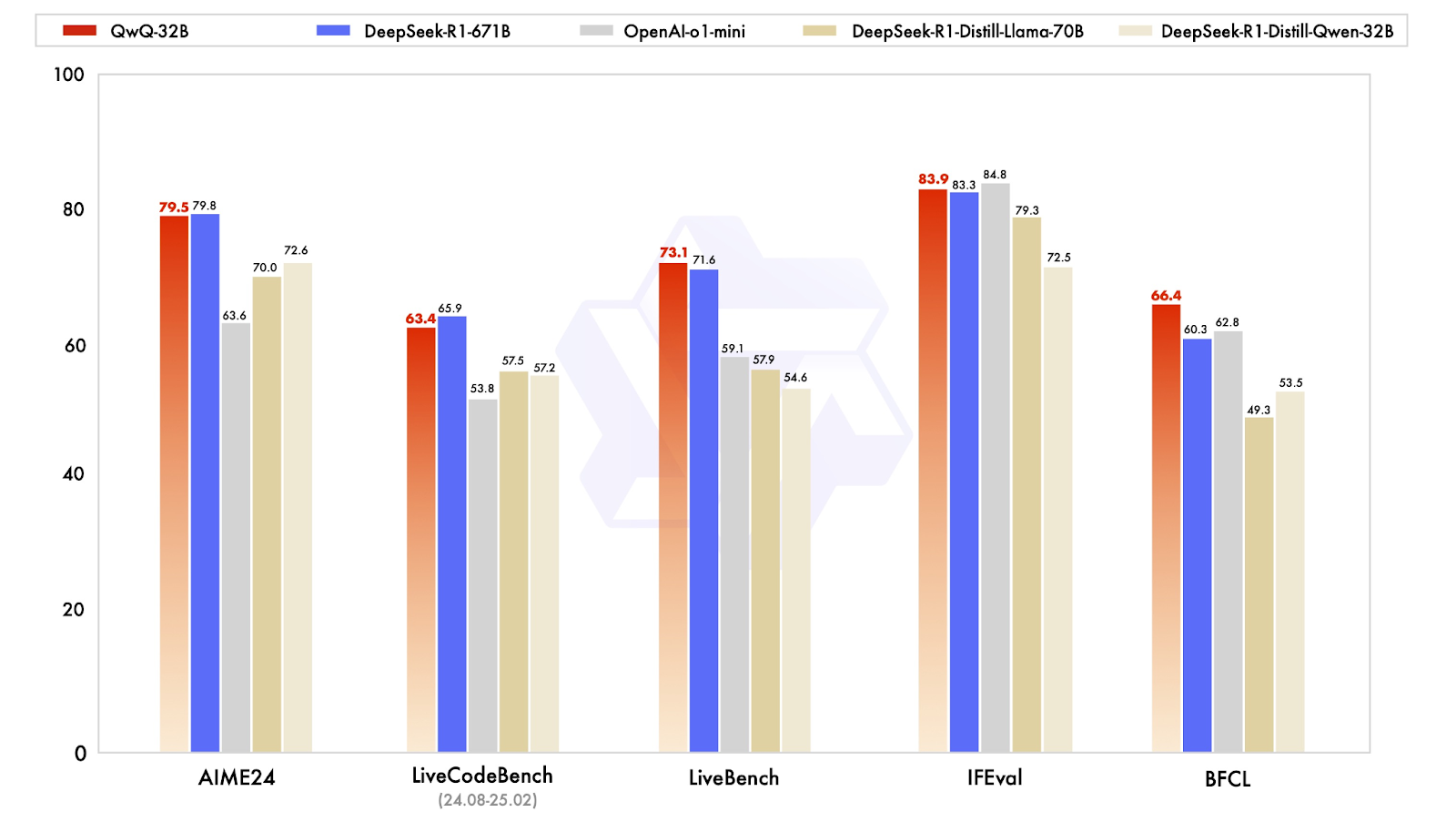
QwQ-32B está diseñado para competir con los modelos de razonamiento más avanzados, y sus resultados en las pruebas comparativas muestran que se acerca sorprendentemente a DeepSeek-R1, a pesar de tener un tamaño mucho menor. El modelo se probó en una serie de pruebas comparativas que evaluaban las matemáticas, la codificación y el razonamiento estructurado, en las que a menudo funcionaba al nivel de DeepSeek-R1 o cerca de él.
Fuente: Qwen
Uno de los resultados más reveladores procede de AIME24, una prueba de matemáticas diseñada para evaluar la resolución de problemas matemáticos. QwQ-32B obtuvo una puntuación de 79,5, justo por detrás de DeepSeek-R1 con 79,8 y muy por delante de o1-mini de OpenAI (63,6) y de DeepSeek modelos destilados (70.0-72.6). Esto es especialmente impresionante si tenemos en cuenta que QwQ-32B sólo tiene 32.000 millones de parámetros, frente a los 671.000 millones de DeepSeek-R1.
En otra prueba clave, IFEval, que evalúa el razonamiento funcional y simbólico, QwQ-32B también obtuvo un rendimiento competitivo, con una puntuación de 83,9, ¡ligeramente por encima de DeepSeek-R1! Está sólo por detrás de la o1-mini de OpenAI, que lidera esta categoría con una puntuación de 84,8.
Para los modelos de IA destinados a ayudar en el desarrollo de software, los puntos de referencia de codificación son esenciales. En LiveCodeBench, que mide la capacidad de generar y refinar código, QwQ-32B obtuvo una puntuación de 63,4, ligeramente por detrás de DeepSeek-R1, con 65,9, pero significativamente por delante de o1-mini de OpenAI, con 53,8 . Esto sugiere que el aprendizaje por refuerzo desempeñó un papel importante en la mejora de la capacidad de QwQ-32B para razonar iterativamente a través de problemas de codificación, en lugar de limitarse a generar soluciones puntuales.
QwQ-32B obtuvo una puntuación de 73,1 en LiveBench, una evaluación de la capacidad general para resolver problemas, superando ligeramente la puntuación de 71,6 de DeepSeek-R1. Ambos modelos obtuvieron una puntuación significativamente más alta que el o1-mini de OpenAI, que alcanzó una puntuación de 59,1. Esto respalda la idea de que los modelos pequeños y bien optimizados pueden acortar distancias con los sistemas propietarios masivos, al menos en tareas estructuradas.
Quizá el resultado más interesante sea el obtenido en BFCL, un punto de referencia que evalúa el razonamiento funcional amplio. Aquí, QwQ-32B alcanzó 66,4, superando a DeepSeek-R1 (60,3) y a o1-mini de OpenAI (62,8) . Esto sugiere que el enfoque de entrenamiento del QwQ-32B, en particular sus capacidades agénticas y sus estrategias de aprendizaje por refuerzo, le confieren una ventaja en áreas en las que la resolución de problemas requiere flexibilidad y adaptación, y no sólo patrones memorizados.
QwQ-32B es totalmente de código abierto, lo que lo convierte en uno de los pocos modelos de razonamiento de alto rendimiento disponibles para que cualquiera experimente con él. Tanto si quieres probarlo interactivamente, integrarlo en una aplicación o ejecutarlo en tu propio hardware, hay múltiples formas de acceder al modelo.
Para quienes sólo quieran probar el modelo sin configurar nada, Qwen Chat ofrece una forma sencilla de interactuar con QwQ-32B. La interfaz web del chatbot te permite probar directamente las capacidades de razonamiento, matemáticas y de codificación del modelo. Aunque no es tan flexible como ejecutar el modelo localmente, proporciona una forma directa de ver sus puntos fuertes en acción.
Para probarlo, tienes que acceder a https://chat.qwen.ai/ y crear una cuenta. Una vez dentro, empieza seleccionando el modelo QwQ-32B en el menú selector de modelos:
El modoPensamiento (QwQ) está activado por defecto y no se puede desactivar con este modelo. Puedes empezar a preguntar en la interfaz basada en el chat:
Los desarrolladores que deseen integrar QwQ-32B en sus propios flujos de trabajo pueden descargarlo de Cara Abrazada o ModelScope. Estas plataformas proporcionan acceso a los pesos del modelo, las configuraciones y las herramientas de inferencia, lo que facilita la implantación del modelo para su uso en investigación o producción.
QwQ-32B desafía la idea de que sólo los modelos masivos pueden rendir bien en el razonamiento estructurado. A pesar de tener muchos menos parámetros que DeepSeek-R1, ofrece resultados sólidos en matemáticas, codificación y resolución de problemas de varios pasos, lo que demuestra que técnicas de entrenamiento como el aprendizaje por refuerzo y la optimización de contextos largos pueden tener un impacto significativo.
Lo que más me llama la atención es su disponibilidad de código abierto. Mientras que muchos modelos de razonamiento de alto rendimiento permanecen encerrados tras API propietarias, QwQ-32B es accesible en Hugging Face, ModelScope y Qwen Chat, lo que facilita a investigadores y desarrolladores la realización de pruebas y la construcción con él.
Aprende IA con estos cursos
programa
programa
programa
blog
Abid Ali Awan
9 min
blog
Bhavishya Pandit
7 min
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
