
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Llama 3 lokal zu betreiben, mag aufgrund der hohen Anforderungen an Arbeitsspeicher, Grafikprozessor und Rechenleistung entmutigend erscheinen. Doch dank der Fortschritte bei den Frameworks und der Modelloptimierung ist dies heute leichter denn je. Hier ist, warum du es in Betracht ziehen solltest:
Lies unseren Artikel Die Vor- und Nachteile der Verwendung von großen Sprachmodellen (LLMs) in der Cloud vs. Lokaler Einsatz von LLMs, um mehr darüber zu erfahren, ob der lokale Einsatz von LLMs für dich geeignet ist.
GPT4ALL ist eine Open-Source-Software, mit der du beliebte große Sprachmodelle auf deinem lokalen Rechner ausführen kannst, auch ohne GPU. Sie ist benutzerfreundlich und damit auch für Personen ohne technischen Hintergrund zugänglich.
Wir beginnen mit dem Herunterladen und der Installation von GPT4ALL unter Windows, indem wir die offizielle Download-Seite besuchen.
Nachdem du die Anwendung installiert hast, starte sie und klicke auf die Schaltfläche "Downloads", um das Menü der Modelle zu öffnen. Dort kannst du nach unten scrollen und das Modell "Llama 3 Instruct" auswählen und dann auf die Schaltfläche "Download" klicken.
Nachdem der Download abgeschlossen ist, schließe die Registerkarte und wähle das Llama 3 Instruct Modell aus, indem du auf das Dropdown-Menü "Modell auswählen" klickst.
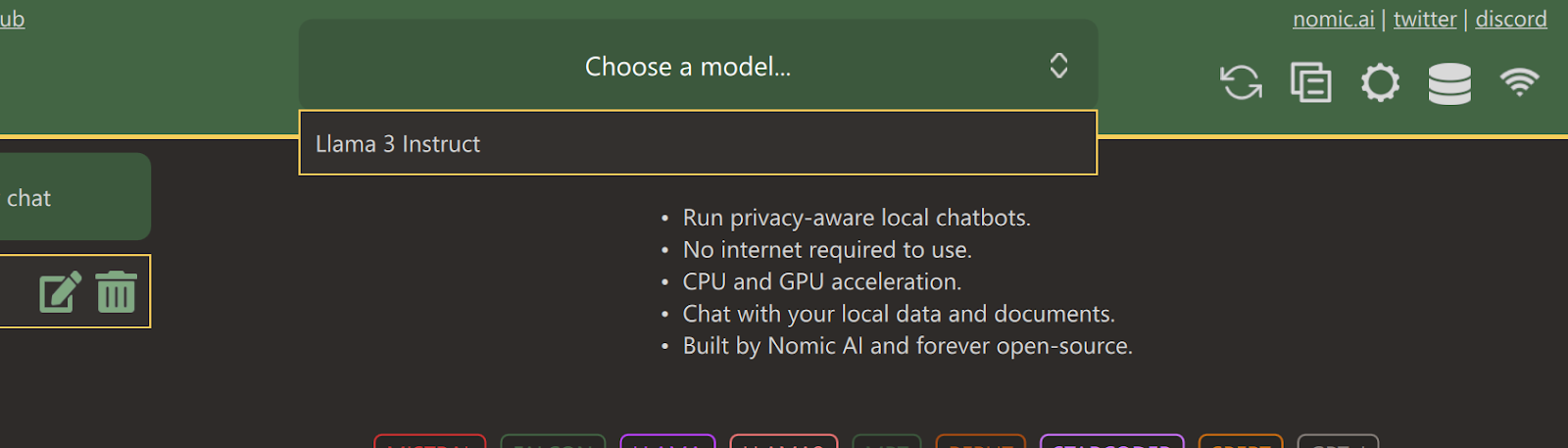
Gib eine Eingabeaufforderung ein und benutze sie wie ChatGPT. Auf dem System ist das CUDA Toolkit installiert, sodass es die GPU nutzt, um eine schnellere Antwort zu erhalten.
Jetzt wollen wir die einfachste Art ausprobieren, Llama 3 lokal zu nutzen, indem wir Ollama herunterladen und installieren.
Ollama ist ein leistungsstarkes Tool, mit dem du LLMs lokal nutzen kannst. Es ist schnell und hat eine Menge Funktionen.
Nachdem du Ollama auf deinem System installiert hast, starte die Terminal/PowerShell und gib den Befehl ein.
ollama run llama3Hinweis: Das Herunterladen der Modelldatei und das Starten des Chatbots im Terminal dauert ein paar Minuten.
Du schreibst Prompts oder stellst Fragen, und Ollama generiert die Antwort in deinem Terminal. Die Chat-Antwort ist superschnell und du kannst immer wieder Folgefragen stellen, um das Thema zu vertiefen.
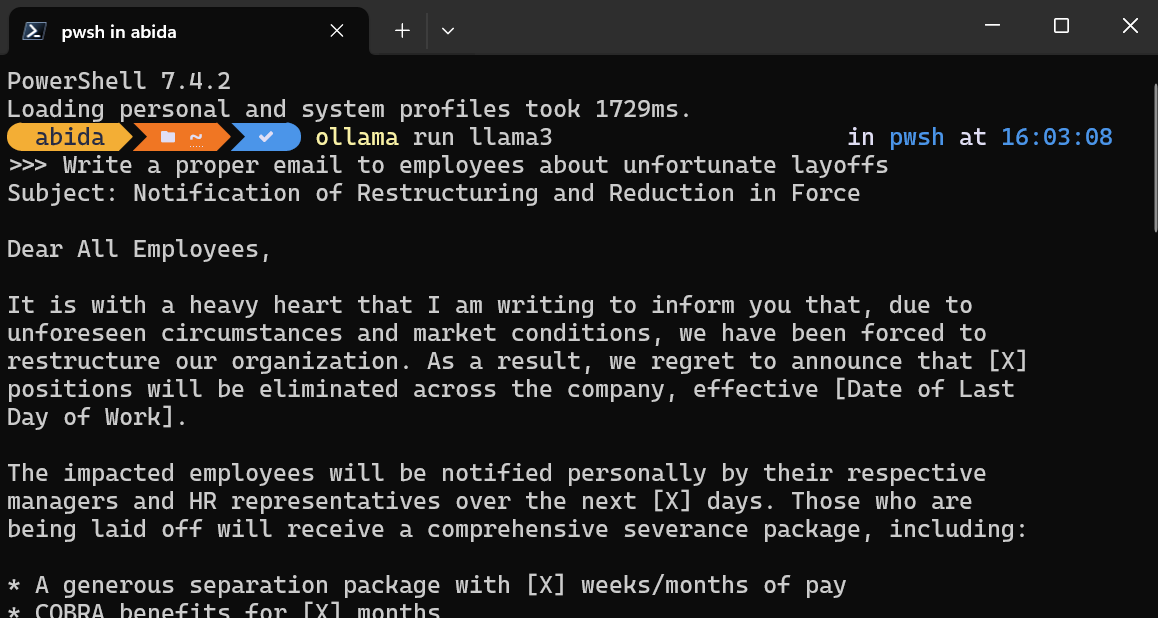
Um den Chatbot zu verlassen, gib einfach /bye ein.
Zusätzlich zu diesen beiden Programmen kannst du auch die Software Run LLMs Locally nutzen: 7 Einfache Methoden Leitfaden, um weitere Anwendungen und Frameworks zu erkunden.
Wenn du einen lokalen Server betreibst, kannst du Llama 3 in andere Anwendungen integrieren und deine eigene Anwendung für bestimmte Aufgaben erstellen.
Starte den lokalen Model Inference Server, indem du den folgenden Befehl in das Terminal eingibst.
ollama serveUm zu überprüfen, ob der Server ordnungsgemäß läuft, suche in der Taskleiste das Ollama-Symbol und klicke mit der rechten Maustaste darauf, um die Protokolle anzuzeigen.
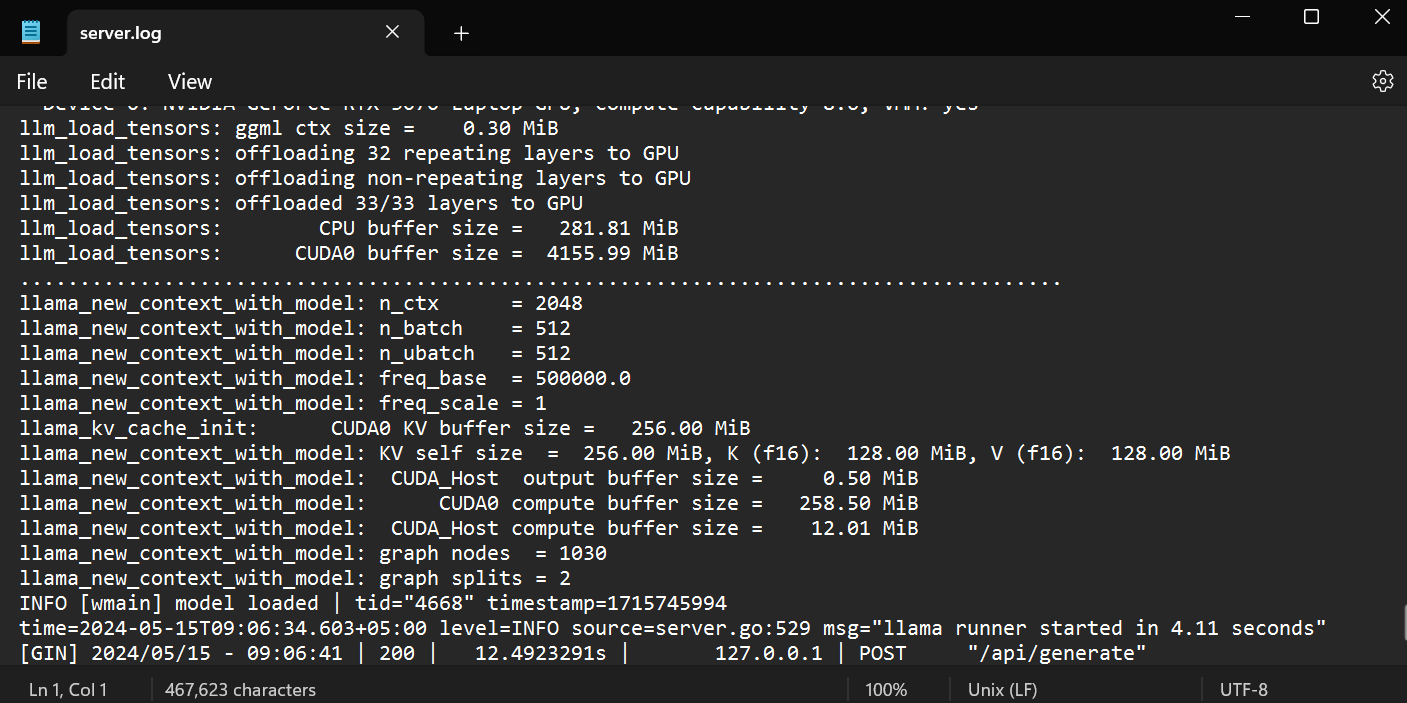
Er führt dich zum Ollama-Ordner, wo du die Datei `server.log` öffnen kannst, um Informationen über Serveranfragen durch APIs und Serverinformationen mit Zeitstempeln einzusehen.
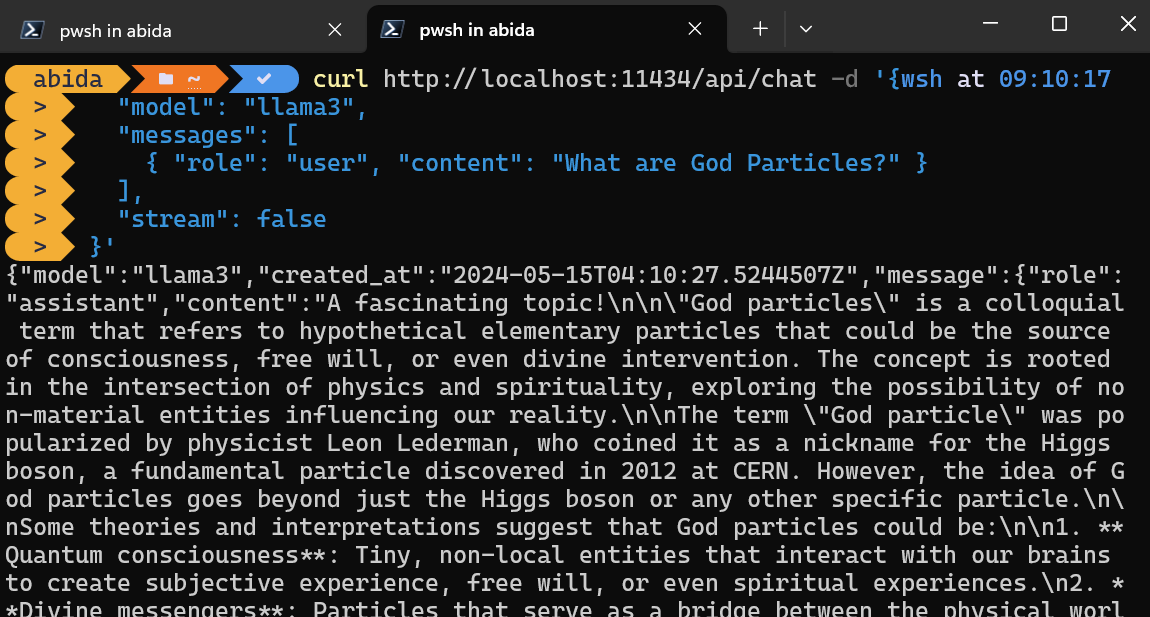
Du kannst einfach mit dem CURL-Befehl auf den Inferenzserver zugreifen.
Gib einfach den Modellnamen und die Eingabeaufforderung ein und stelle sicher, dass das Streaming ausgeschaltet ist, um die vollständige Nachricht zu erhalten.
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "What are God Particles?" }
],
"stream": false
}'Der CURL-Befehl ist nativ in Linux, aber du kannst ihn auch in der Windows PowerShell verwenden, wie unten gezeigt.
Du kannst auch das Ollama Python-Paket mit PIP installieren, um auf den Inferenzserver zuzugreifen.
pip install ollamaDer Zugriff auf die API in Python gibt dir die Möglichkeit, KI-gestützte Anwendungen und Tools zu entwickeln, und sie ist super einfach zu bedienen.
Gib einfach den Modellnamen und die Nachricht an die Funktionen von `ollama.chat` weiter, und die Antwort wird generiert.
Hinweis: Im Nachrichtenargument kannst du auch eine Systemaufforderung und eine Assistentenaufforderung hinzufügen, um den Kontext hinzuzufügen.
import ollama
response = ollama.chat(
model="llama3",
messages=[
{
"role": "user",
"content": "Tell me an interesting fact about elephants",
},
],
)
print(response["message"]["content"])
Das Ollama Python-Paket bietet außerdem Funktionen wie asynchrone Aufrufe und Streaming, die eine effektive Verwaltung von API-Anfragen ermöglichen und die wahrgenommene Geschwindigkeit des Modells erhöhen.
Ähnlich wie bei der OpenAI-API kannst du eine asynchrone Chat-Funktion erstellen und dann Streaming-Code mit der asynchronen Funktion schreiben, was eine effiziente und schnelle Interaktion mit dem Modell ermöglicht.
import asyncio
from ollama import AsyncClient
async def chat():
"""
Stream a chat from Llama using the AsyncClient.
"""
message = {
"role": "user",
"content": "Tell me an interesting fact about elephants"
}
async for part in await AsyncClient().chat(
model="llama3", messages=[message], stream=True
):
print(part["message"]["content"], end="", flush=True)
asyncio.run(chat())Wie du siehst, zeigt das Modell die Token so an, wie sie erzeugt werden.
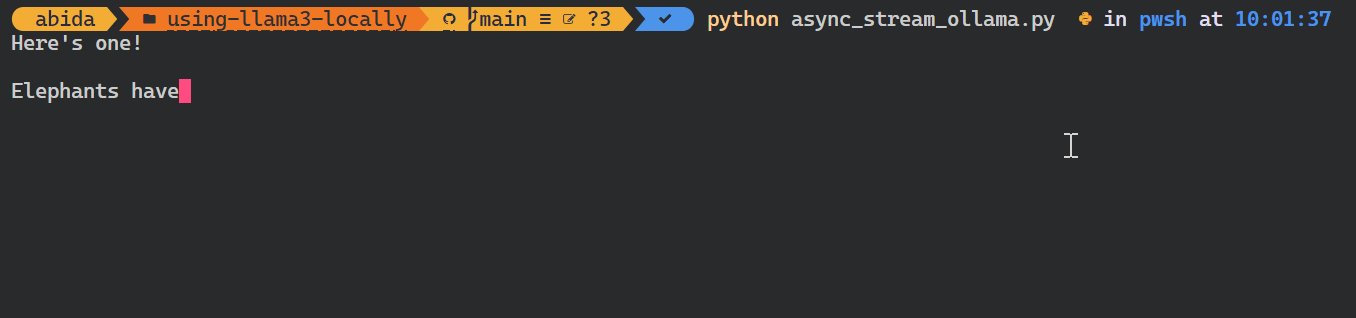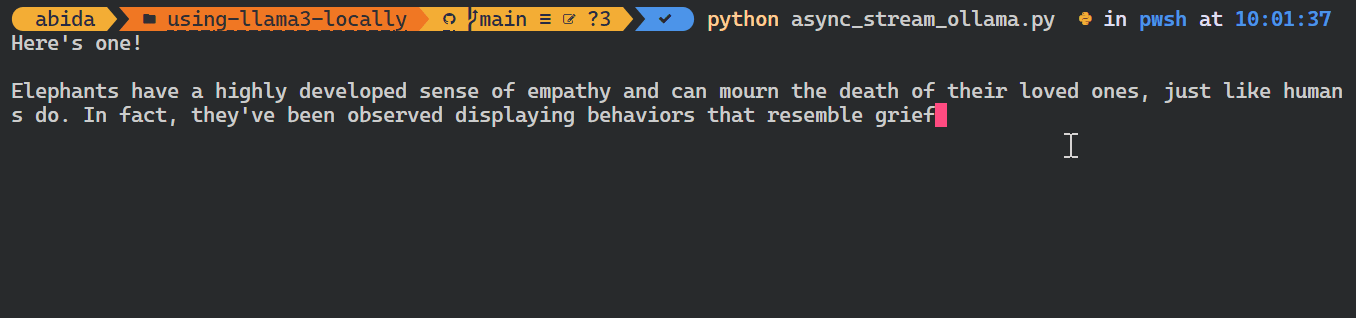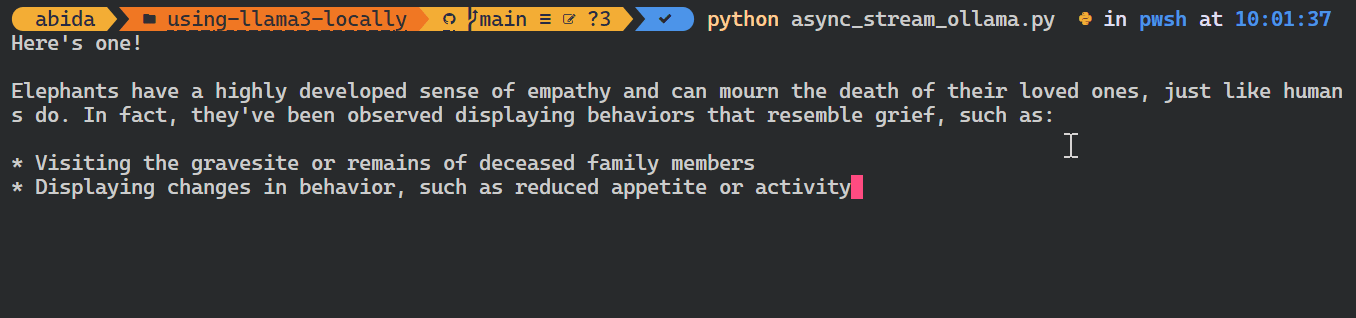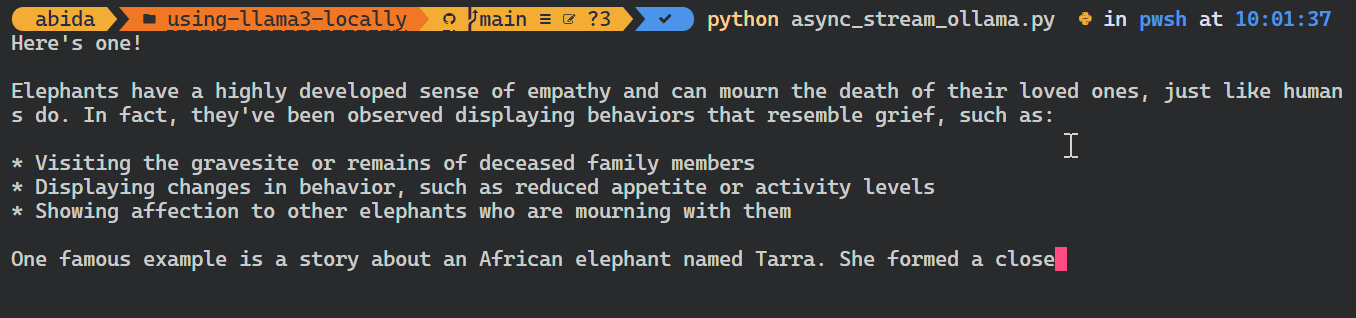
Du kannst auch die Python-API verwenden, um das benutzerdefinierte Modell zu erstellen, Text in Einbettungen umzuwandeln und Fehler zu behandeln. Du kannst die Modelle auch kopieren, löschen, ziehen und verschieben.
Du kannst Ollama nicht nur als Chatbot oder zum Generieren von Antworten verwenden, sondern es auch in VSCode integrieren und Llama 3 für Funktionen wie Autovervollständigung, kontextabhängige Codevorschläge, das Schreiben von Code, das Generieren von Docstrings, Unit-Tests und vieles mehr nutzen.
1. Zuerst müssen wir den Ollama Inferenzserver initialisieren, indem wir den folgenden Befehl in das Terminal eingeben.
ollama serve2. Gehe zu VSCode Erweiterungen, suche nach dem Tool "CodeGPT" und installiere es. Mit CodeGPT kannst du jeden Modellanbieter mit dem API-Schlüssel verbinden.

3. Richte das CodeGPT ein, indem du auf das CodeGPT-Chat-Symbol im linken Bereich klickst. Ändere den Modellanbieter auf Ollama und wähle das Modell llama3:8b. Du musst keinen API-Schlüssel angeben, da wir es lokal ausführen.
4. Schreibe die Eingabeaufforderung, um den Python-Code zu erzeugen, und klicke dann auf die Schaltfläche "Code einfügen", um den Code in deine Python-Datei zu übertragen. Du kannst auch Folgeanweisungen schreiben, um den Code zu verbessern.
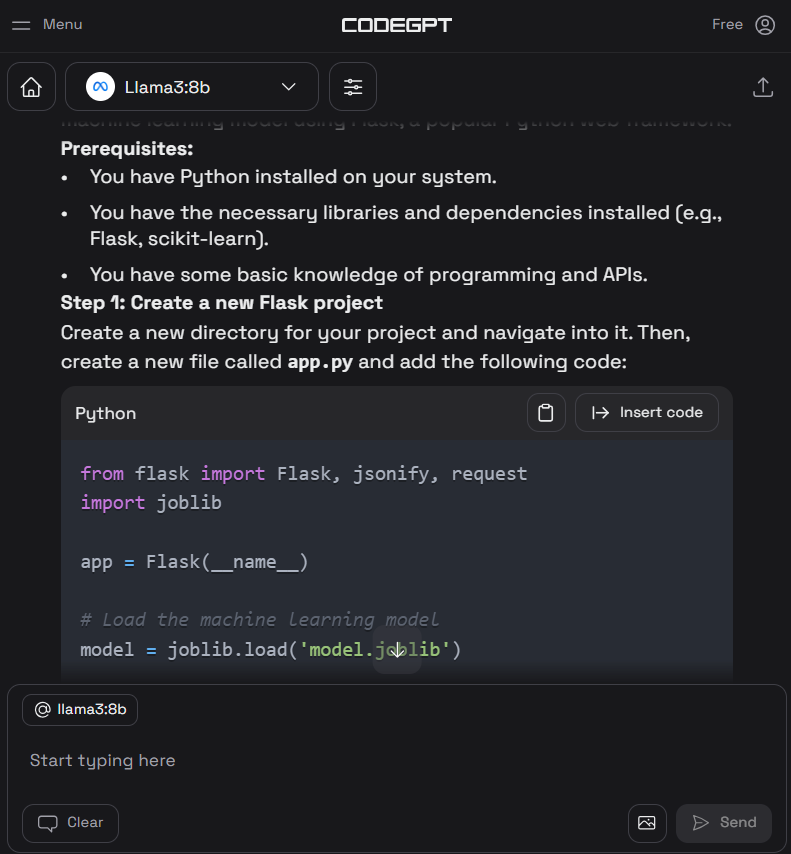
5. Neben dem Kodierassistenten kannst du CodeGPT nutzen, um den Code zu verstehen, ihn zu überarbeiten, zu dokumentieren, Unit-Tests zu erstellen und Probleme zu beheben.
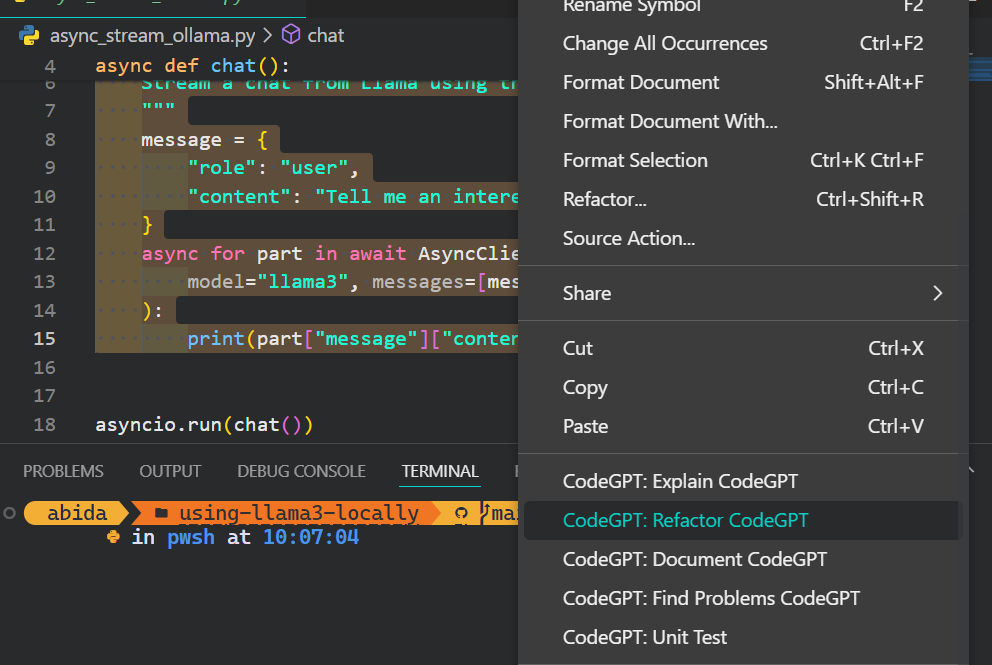
Wenn du dich wie ein Python-Profi fühlen willst, schau dir die Anleitung VSCode für Python einrichten an, um mehr über die VSCode-Kernfunktion zu erfahren und sie an deine Bedürfnisse anzupassen.
In diesem Abschnitt werden wir eine KI-gestützte Anwendung entwickeln, die docx-Dateien aus einem bestimmten Ordner liest, sie in Einbettungen umwandelt und sie in einem Vektorspeicher speichert.
Anschließend verwenden wir eine Ähnlichkeitssuche, um relevante Bedeutungen zu finden und kontextbezogene Antworten auf deine Fragen zu geben.
Mit dieser Anwendung kannst du schnell das Wesen der Bücher verstehen und tiefer in die Charakterentwicklung eintauchen.
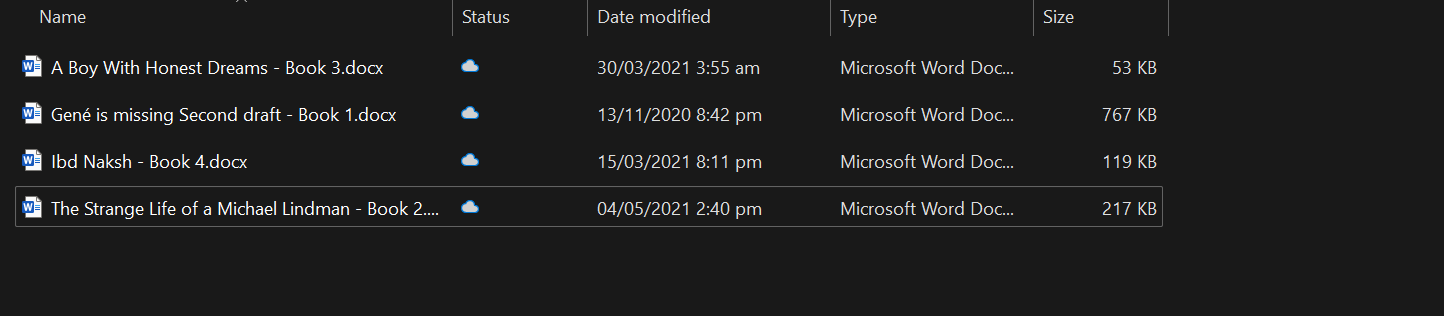
Zuerst installieren wir alle notwendigen Python-Pakete zum Laden der Dokumente, des Vektorspeichers und des LLM-Frameworks.
pip install unstructured[docx] langchain langchainhub langchain_community langchain-chromaStarte dann den Ollama-Inferenzserver.
ollama serveEs empfiehlt sich, deinen Code in Jupyter Notebook zu entwickeln und zu testen, bevor du die App erstellst.
Wir werden alle docx-Dateien aus dem Ordner laden, indem wir die DirectoryLoader verwenden.
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("C:/Users/abida/Desktop/Books", glob="**/*.docx")
books = loader.load()
len(books)4Du kannst deinen eigenen kontextabhängigen Chatbot erstellen, indem du dem Tutorial Chatbot Development with ChatGPT & LangChain folgst: Ein kontextbezogener Ansatz.
Es ist nicht möglich, ein ganzes Buch in das Modell einzuspeisen, da es sein Kontextfenster überschreiten würde. Um diese Einschränkung zu überwinden, müssen wir den Text in kleinere, überschaubare Abschnitte unterteilen, die bequem in das Kontextfenster des Modells passen.
In unserem Fall konvertieren wir alle vier Bücher in eine Chunk-Größe von 500 Zeichen.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(books)
Wir werden Langchain verwenden, um den Text in die Einbettung umzuwandeln und in der Chroma-Datenbank zu speichern.
Wir verwenden das Modell Ollama Llama 3 als Einbettungsmodell.
from langchain_chroma import Chroma
from langchain_community.embeddings import OllamaEmbeddings
vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=OllamaEmbeddings(model="llama3", show_progress=True),
persist_directory="./chroma_db",
)OllamaEmbeddings: 100%|██████████| 23/23 [01:00<00:00, 2.63s/it]Lass uns unsere Vektordatenbank testen, indem wir einige Ähnlichkeitssuchen durchführen.
question = "Who is Zahra?"
docs = vectorstore.similarity_search(question)
docsWir haben vier Ergebnisse erhalten, die der Frage ähnlich sind.

Du kannst tief in die Welt der Vektordatenbank und der Chroma DB eintauchen, indem du das Tutorial liest: Learn How to Use Chroma DB: Eine Schritt-für-Schritt-Anleitung.
Um ein richtiges Frage-und-Antwort-Retrieval-System zu bauen, werden wir Langchain-Ketten verwenden und damit beginnen, die Module hinzuzufügen.
In unserer Q&A-Kette werden wir
Einfach ausgedrückt: Bevor deine Frage das Llama 3-Modell durchläuft, wird sie mithilfe der Ähnlichkeitssuche und der RAG-Abfrage mit einem Kontext versehen.
from langchain import hub
from langchain_community.llms import Ollama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
llm = Ollama(model="llama3")
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_prompt = hub.pull("rlm/rag-prompt")
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)Du kannst eine ähnliche Anwendung mit LLamaIndex erstellen. Folge dazu dem LlamaIndex: Ein Daten-Framework für die auf Large Language Models (LLMs) basierenden Anwendungen tutorial.
Stelle relevante Fragen zu Büchern, um mehr über die Geschichte zu erfahren.
question = "What is the story of the 'Gené is Missing' book?"
qa_chain.invoke(question)Wie wir sehen können, liefert die Verwendung von Büchern als Kontext eine genaue Antwort.
'Based on the provided context, "Gené is Missing" appears to be a mystery novel that revolves around uncovering the truth about Gené\'s life and potential involvement in murders. The story follows different perspectives, including Simon trying to prove his innocence, flashbacks of Gené\'s past, and detective Jacob investigating the case.'Stellen wir nun eine Frage über die Figur.
question = "Who is Arslan?"
qa_chain.invoke(question)Es wurde eine präzise Antwort gegeben.
'Arslan is Zahra\'s brother\'s best friend. He is someone that Zahra visits in the book "A Boy with Honest Dreams" by Abid Ali Awan to gather information about Ali.'Um eine vollwertige KI-Anwendung zu erstellen, die nahtlos in deinem Terminal läuft, werden wir den gesamten Code aus den vorherigen Abschnitten in einer einzigen Python-Datei zusammenfassen.
code AI_app.pyAußerdem werden wir den Code so erweitern, dass er interaktive Abfragen ermöglicht, sodass du der App wiederholt Fragen stellen kannst, bis du die Sitzung explizit durch die Eingabe von "exit" beendest.
from langchain_chroma import Chroma
from langchain_community.embeddings import OllamaEmbeddings
from langchain import hub
from langchain_community.llms import Ollama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# loading the vectorstore
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=OllamaEmbeddings(model="llama3"))
# loading the Llama3 model
llm = Ollama(model="llama3")
# using the vectorstore as the retriever
retriever = vectorstore.as_retriever()
# formating the docs
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# loading the QA chain from langchain hub
rag_prompt = hub.pull("rlm/rag-prompt")
# creating the QA chain
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# running the QA chain in a loop until the user types "exit"
while True:
question = input("Question: ")
if question.lower() == "exit":
break
answer = qa_chain.invoke(question)
print(f"\nAnswer: {answer}\n")
Starte die Anwendung, indem du `Python` und den Dateinamen in das Terminal schreibst.
python AI_app.pyDas ist cool. Wir haben unsere eigene RAG AI-Anwendung lokal mit wenigen Zeilen Code erstellt.
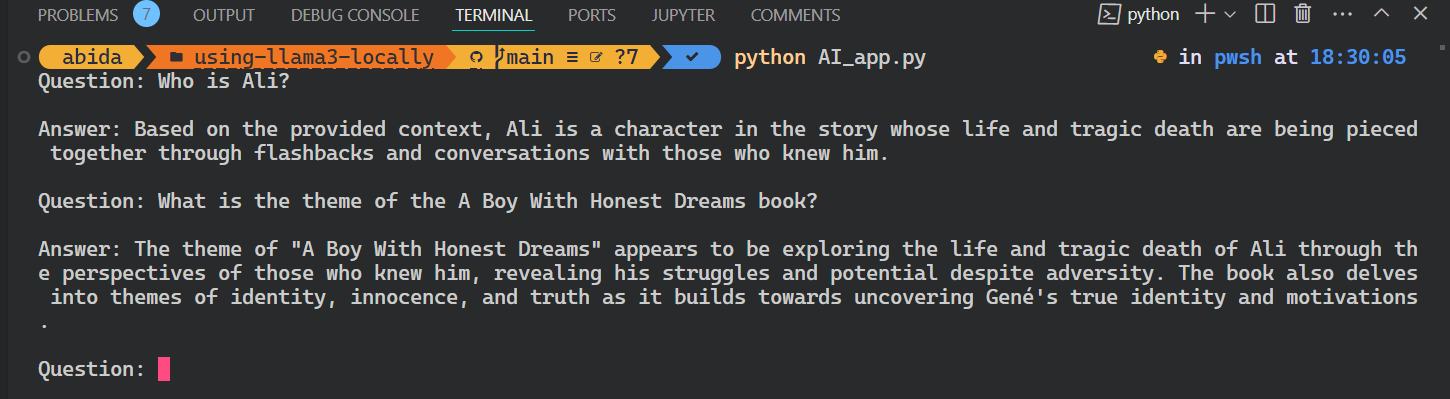
Der gesamte Quellcode für dieses Tutorial ist auf dem GitHub-Repository kingabzpro/using-llama3-locally verfügbar. Bitte schau es dir an und vergiss nicht, das Repository mit einem Stern zu versehen.
In diesem Lernprogramm haben wir gelernt, Llama 3 lokal auf einem Laptop zu benutzen. Wir haben auch etwas über den Inferenzserver gelernt und wie wir ihn nutzen können, um Llama 3 in VSCode zu integrieren.
Letztendlich haben wir das Q&A-Retrieval-System mit Langchain, Chroma und Ollama gebaut. Die Daten haben das lokale System nie verlassen, und du musstest nicht einmal einen einzigen Dollar für den Aufbau bezahlen. Abgesehen von den einfacheren Anwendungen kannst du mit denselben Werkzeugen, die wir in diesem Lernprogramm verwendet haben, auch komplexe Systeme aufbauen.
Um mehr zu erfahren, empfehle ich diese Tutorials:
Lerne KI mit DataCamp!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
