
programa
Llama Fundamentals
4 h
En este tutorial, te explicaré paso a paso cómo ejecutar DeepSeek-R1 localmente y cómo configurarlo utilizando Ollama. También exploraremos la construcción de una aplicación RAG sencilla que se ejecute en tu portátil utilizando el modelo R1, LangChain y Gradio.
Si sólo quieres una visión general del modelo R1, te recomiendo este artículo DeepSeek-R1. Para aprender a ajustar R1, te recomiendo este tutorial sobre el ajuste fino de DeepSeek-R1.
Ejecutar DeepSeek-R1 localmente te proporciona un control total sobre la ejecución del modelo, sin depender de servidores externos. He aquí algunas ventajas de ejecutar DeepSeek-R1 localmente:
Ollama simplifica la ejecución local de los LLM al gestionar sin problemas las descargas, la cuantización y la ejecución de los modelos.
Primero, descarga e instala Ollama desde el sitio web oficial oficial.
Una vez finalizada la descarga, instala la aplicación Ollama como harías con cualquier otra aplicación.
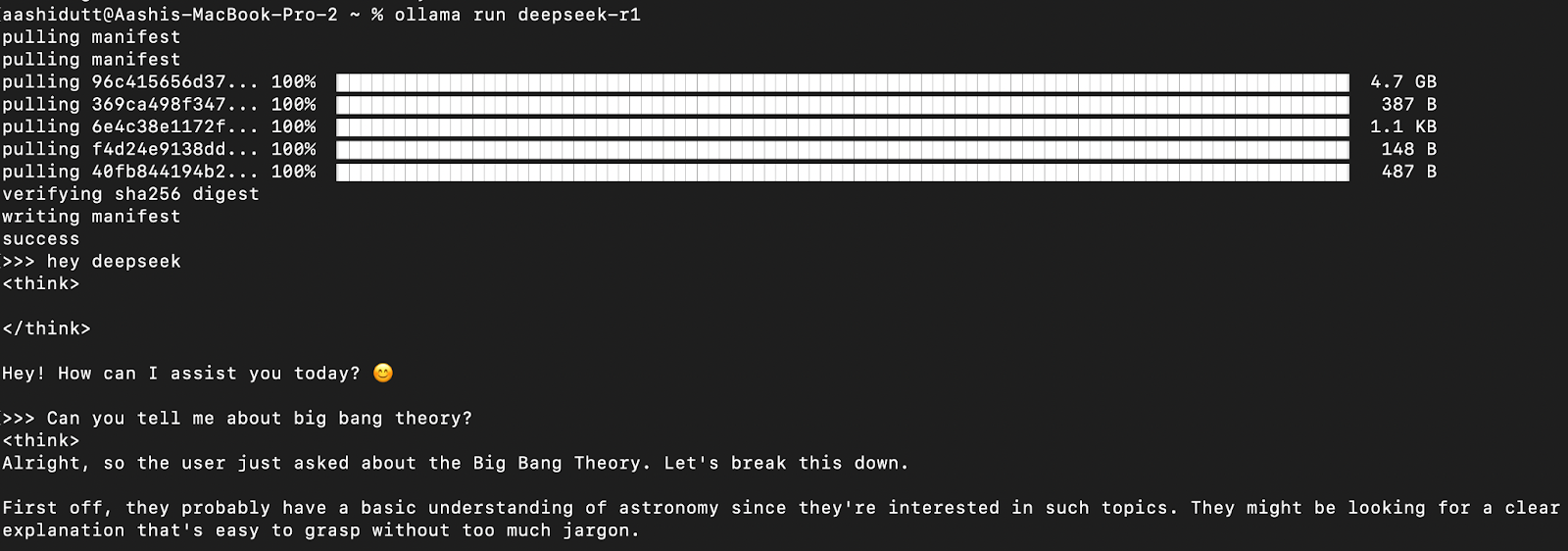
Probemos la configuración y descarguemos nuestro modelo. Inicia el terminal y escribe el siguiente comando.
ollama run deepseek-r1Ollama ofrece una gama de modelos DeepSeek R1, que abarca desde 1,5B de parámetros hasta el modelo completo de 671B de parámetros. El modelo 671B es el DeepSeek-R1 original, mientras que los modelos más pequeños son versiones destiladas basadas en las arquitecturas Qwen y Llama. Si tu hardware no admite el modelo 671B, puedes ejecutar fácilmente una versión más pequeña utilizando el siguiente comando y sustituyendo el X de abajo por el tamaño de parámetro que desees (1,5b, 7b, 8b, 14b, 32b, 70b, 671b):
ollama run deepseek-r1: XbCon esta flexibilidad, puedes utilizar las capacidades de DeepSeek-R1 aunque no dispongas de un superordenador.
Para ejecutar DeepSeek-R1 continuamente y servirlo a través de una API, inicia el servidor Ollama:
ollama serveEsto hará que el modelo esté disponible para su integración con otras aplicaciones.
Una vez descargado el modelo, puedes interactuar con DeepSeek-R1 directamente en el terminal.
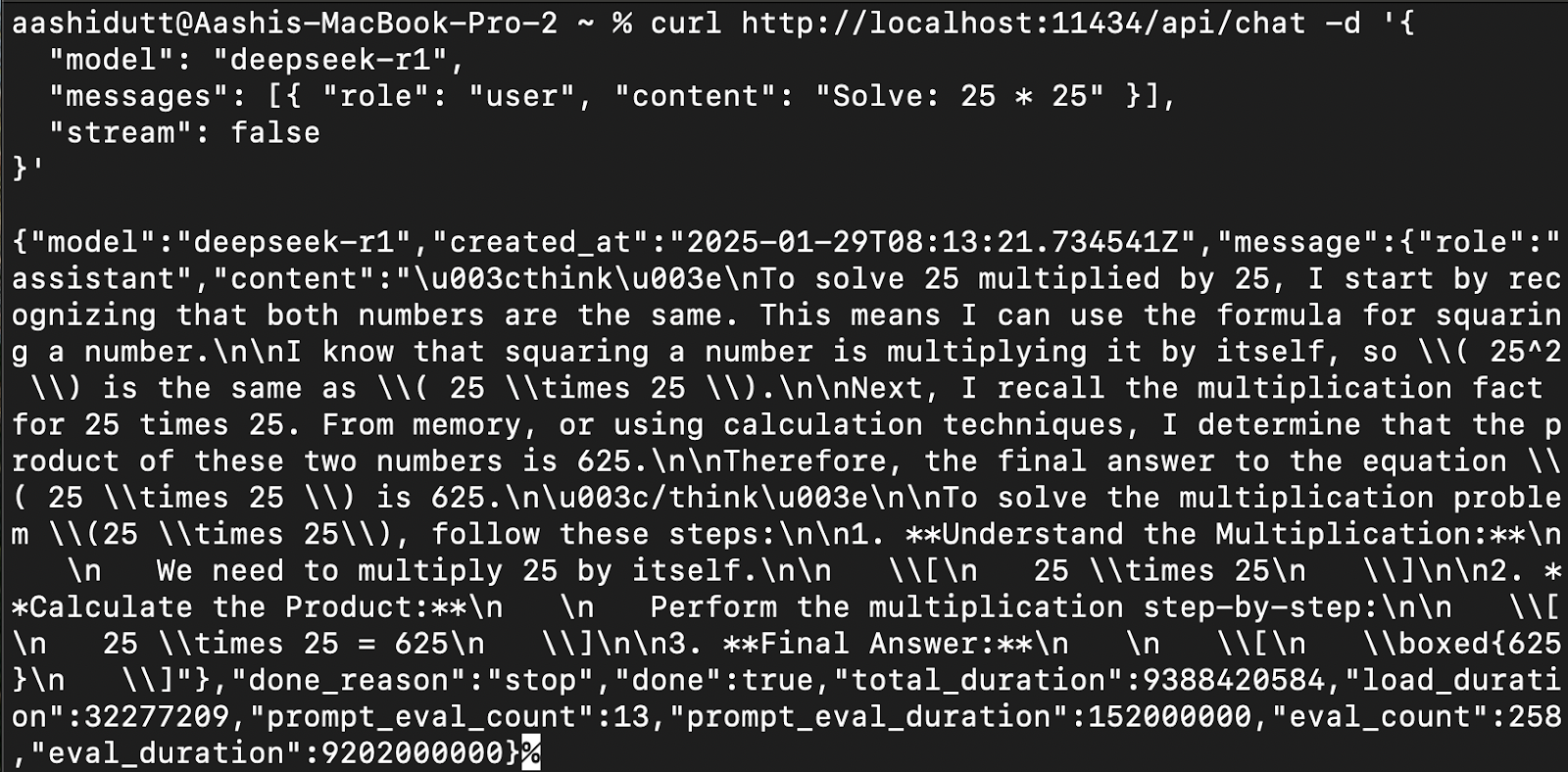
Para integrar DeepSeek-R1 en aplicaciones, utiliza la API de Ollama mediante curl:
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1",
"messages": [{ "role": "user", "content": "Solve: 25 * 25" }],
"stream": false
}'curl es una herramienta de línea de comandos nativa de Linux, pero también funciona en macOS. Permite a los usuarios hacer peticiones HTTP directamente desde el terminal, lo que la convierte en una herramienta excelente para interactuar con las API.
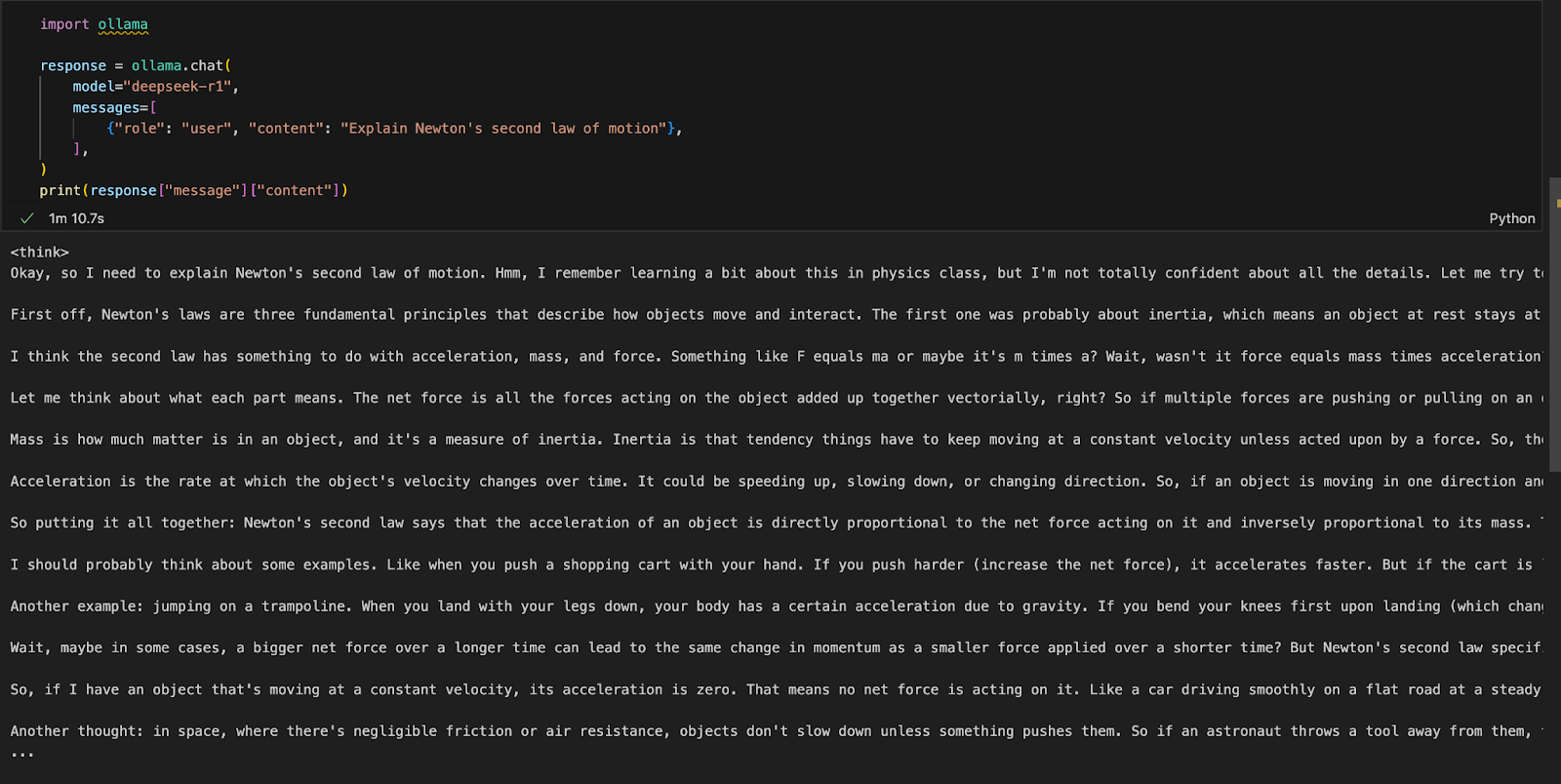
Podemos ejecutar Ollama en cualquier entorno de desarrollo integrado (IDE) de nuestra elección. Puedes instalar el paquete Ollama Python utilizando el siguiente código:
!pip install ollamaUna vez instalado Ollama, utiliza el siguiente script para interactuar con el modelo:
import ollama
response = ollama.chat(
model="deepseek-r1",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])La función ollama.chat() toma el nombre del modelo y una indicación del usuario, procesándolo como un intercambio conversacional. A continuación, el script extrae e imprime la respuesta del modelo.
Vamos a crear una sencilla aplicación de demostración utilizando Gradio para consultar y analizar documentos con DeepSeek-R1.
Antes de sumergirnos en la implementación, asegurémonos de que tenemos instaladas las siguientes herramientas y bibliotecas:
Ejecuta los siguientes comandos para instalar las dependencias necesarias:
!pip install langchain chromadb gradio
!pip install -U langchain-communityUna vez instaladas las dependencias anteriores, ejecuta los siguientes comandos de importación:
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import ollamaUna vez importadas las bibliotecas, procesaremos el PDF cargado.
def process_pdf(pdf_bytes):
if pdf_bytes is None:
return None, None, None
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
embeddings = OllamaEmbeddings(model="deepseek-r1")
vectorstore=Chroma.from_documents(documents=chunks, embedding=embeddings)
retriever = vectorstore.as_retriever()
return text_splitter, vectorstore, retrieverLa función process_pdf:
PyMuPDFLoader.RecursiveCharacterTextSplitter.OllamaEmbeddings.Una vez recuperadas las incrustaciones, tenemos que unirlas. La función combine_docs() fusiona varios trozos de documento recuperados en una sola cadena.
def combine_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)Dado que los modelos basados en la recuperación extraen extractos relevantes en lugar de documentos enteros, esta función garantiza que el contenido extraído siga siendo legible y tenga el formato adecuado antes de pasarlo a DeepSeek-R1.
Ahora, nuestra entrada al modelo está lista. Vamos a configurar DeepSeek R1 utilizando Ollama.
def ollama_llm(question, context):
formatted_prompt = f"Question: {question}\n\nContext: {context}"
response = ollama.chat(model="deepseek-r1", messages=[{'role': 'user', 'content': formatted_prompt}])
response_content = response['message']['content']
# Remove content between <think> and </think> tags to remove thinking output
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerLa función ollama_llm() formatea la pregunta del usuario y el contexto del documento recuperado en una pregunta estructurada. Esta entrada formateada se envía a DeepSeek-R1 a través de ollama.chat(), que procesa la pregunta dentro del contexto dado y devuelve una respuesta relevante. Si necesitas la respuesta sin el guión de pensamiento del modelo, utiliza la función strip() para obtener la respuesta final.
Ahora que tenemos todos los componentes necesarios, vamos a construir la canalización RAG para nuestra demostración.
def rag_chain(question, text_splitter, vectorstore, retriever):
retrieved_docs = retriever.invoke(question)
formatted_content = combine_docs(retrieved_docs)
return ollama_llm(question, formatted_content)La función anterior busca primero en el almacén de vectores mediante retriever.invoke(question), devolviendo los fragmentos de documentos más relevantes. Estos extractos se formatean en una entrada estructurada mediante la función combine_docs y se envían a ollama_llm, lo que garantiza que DeepSeek-R1 genere respuestas bien informadas basadas en el contenido recuperado.
Ya tenemos en marcha nuestra tubería RAG. Ahora, podemos construir localmente la interfaz Gradio junto con el modelo DeepSeek-R1 para procesar la entrada PDF y hacer preguntas relacionadas con ella.
def ask_question(pdf_bytes, question):
text_splitter, vectorstore, retriever = process_pdf(pdf_bytes)
if text_splitter is None:
return None # No PDF uploaded
result = rag_chain(question, text_splitter, vectorstore, retriever)
return {result}
interface = gr.Interface(
fn=ask_question,
inputs=[gr.File(label="Upload PDF (optional)"), gr.Textbox(label="Ask a question")],
outputs="text",
title="Ask questions about your PDF",
description="Use DeepSeek-R1 to answer your questions about the uploaded PDF document.",
)
interface.launch()Realizamos los siguientes pasos:
process_pdf para extraer texto y generar documentos incrustados.rag_chain() para recuperar la información relevante y generar una respuesta contextualmente precisa.gr.Interface(), que acepta un archivo PDF y una consulta de texto como entradas.interface.launch() para permitir preguntas y respuestas interactivas basadas en documentos a través de un navegador web.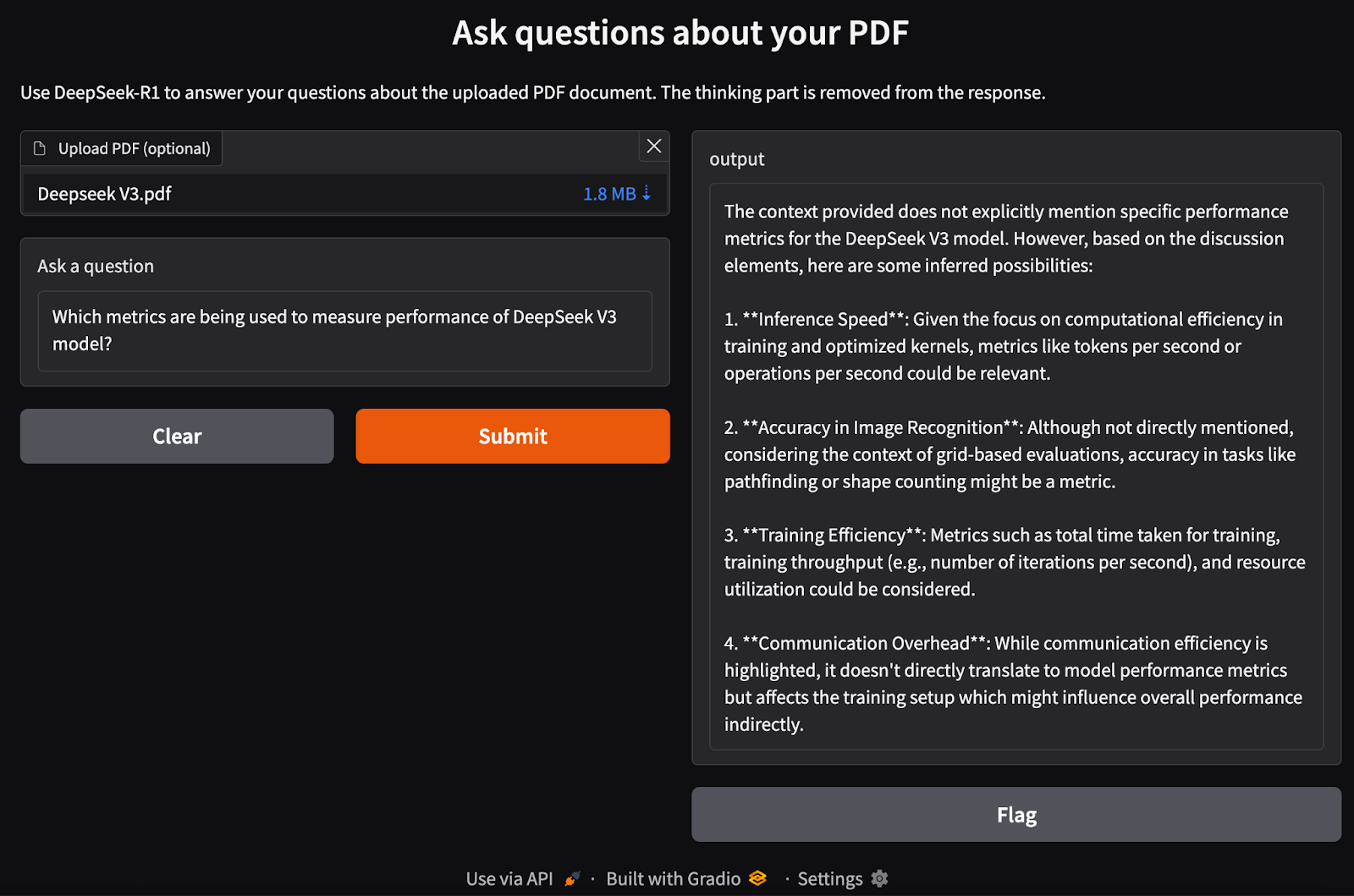
Ejecutar DeepSeek-R1 localmente con Ollama permite una inferencia del modelo más rápida, privada y rentable. Con un sencillo proceso de instalación, interacción CLI, compatibilidad con API e integración con Python, puedes utilizar DeepSeek-R1 para diversas aplicaciones de IA, desde consultas generales hasta complejas tareas basadas en la recuperación.
Para estar al día de los últimos avances en IA, te recomiendo estos blogs:
Aprende IA con estos cursos
programa
Curso
Curso
Tutorial
Ryan Ong
Tutorial
Dimitri Didmanidze
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
