
Cursus
Développer des LLM
16 h
L'exécution locale de Llama 3 peut sembler décourageante en raison des exigences élevées en matière de RAM, de GPU et de puissance de traitement. Cependant, les progrès réalisés dans les cadres et l'optimisation des modèles ont rendu cette méthode plus accessible que jamais. Voici pourquoi vous devriez l'envisager :
Lisez notre article, Les avantages et les inconvénients de l'utilisation de grands modèles de langage (LLM) dans le cloud vs. Exécution locale des LLM, pour savoir si l'utilisation locale des LLM vous convient.
GPT4ALL est un logiciel libre qui vous permet d'exécuter des modèles linguistiques populaires sur votre machine locale, même sans GPU. Il est convivial, ce qui le rend accessible aux personnes n'ayant pas de formation technique.
Nous allons commencer par télécharger et installer GPT4ALL sur Windows en allant sur la page de téléchargement officielle.
Après avoir installé l'application, lancez-la et cliquez sur le bouton "Téléchargements" pour ouvrir le menu des modèles. Là, vous pouvez faire défiler vers le bas et sélectionner le modèle "Llama 3 Instruct", puis cliquer sur le bouton "Télécharger".
Une fois le téléchargement terminé, fermez l'onglet et sélectionnez le modèle Llama 3 Instruct en cliquant sur le menu déroulant "Choisir un modèle".
Tapez une invite et commencez à l'utiliser comme ChatGPT. Le système est équipé de la boîte à outils CUDA et utilise donc le GPU pour obtenir une réponse plus rapide.
Maintenant, essayons la façon la plus simple d'utiliser Llama 3 localement en téléchargeant et en installant Ollama.
Ollama est un outil puissant qui vous permet d'utiliser les LLM localement. Il est rapide et doté de nombreuses fonctionnalités.
Après avoir installé Ollama sur votre système, lancez le terminal/PowerShell et tapez la commande.
ollama run llama3Note : Le téléchargement du fichier modèle et le démarrage du chatbot dans le terminal prendront quelques minutes.
Rédigez des invites ou commencez à poser des questions, et Ollama générera la réponse dans votre terminal. La réponse du chat est très rapide et vous pouvez continuer à poser des questions complémentaires pour approfondir le sujet.
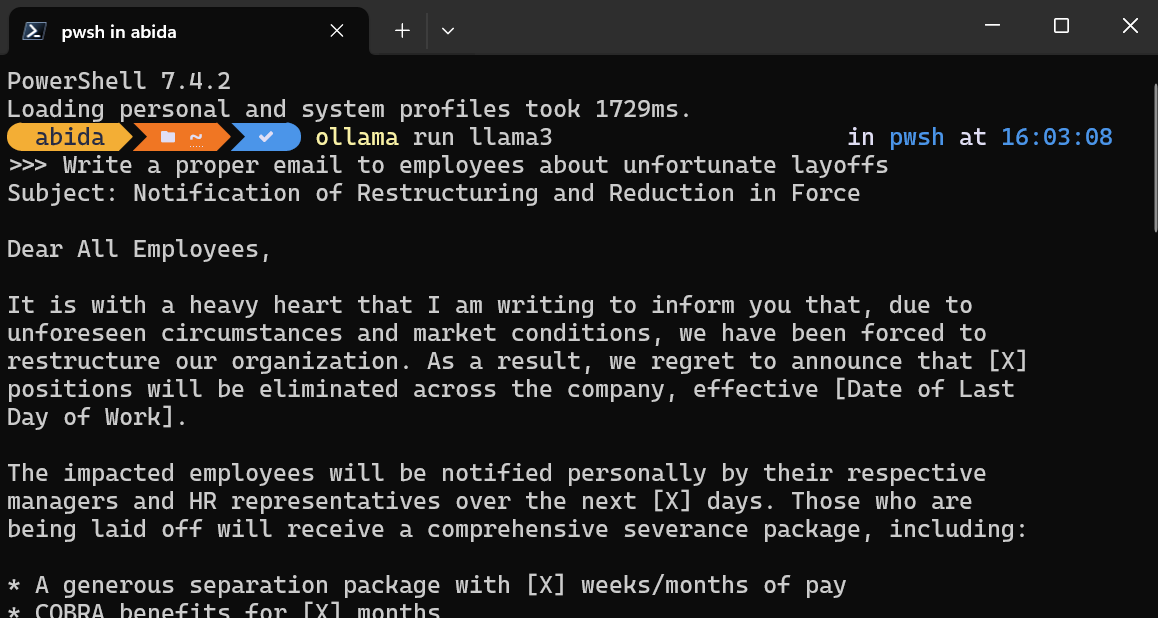
Pour quitter le chatbot, tapez simplement /bye .
Outre ces deux logiciels, vous pouvez consulter le site Run LLMs Locally : 7 méthodes simples guide pour explorer d'autres applications et cadres.
L'exécution d'un serveur local vous permet d'intégrer Llama 3 dans d'autres applications et de créer votre propre application pour des tâches spécifiques.
Démarrez le serveur local d'inférence de modèle en tapant la commande suivante dans le terminal.
ollama servePour vérifier si le serveur fonctionne correctement, allez dans la barre des tâches, trouvez l'icône d'Ollama et cliquez avec le bouton droit de la souris pour afficher les journaux.
Il vous emmènera dans le dossier Ollama, où vous pourrez ouvrir le fichier `server.log` pour voir les informations sur les requêtes du serveur à travers les APIs et les informations sur le serveur avec les horodatages.
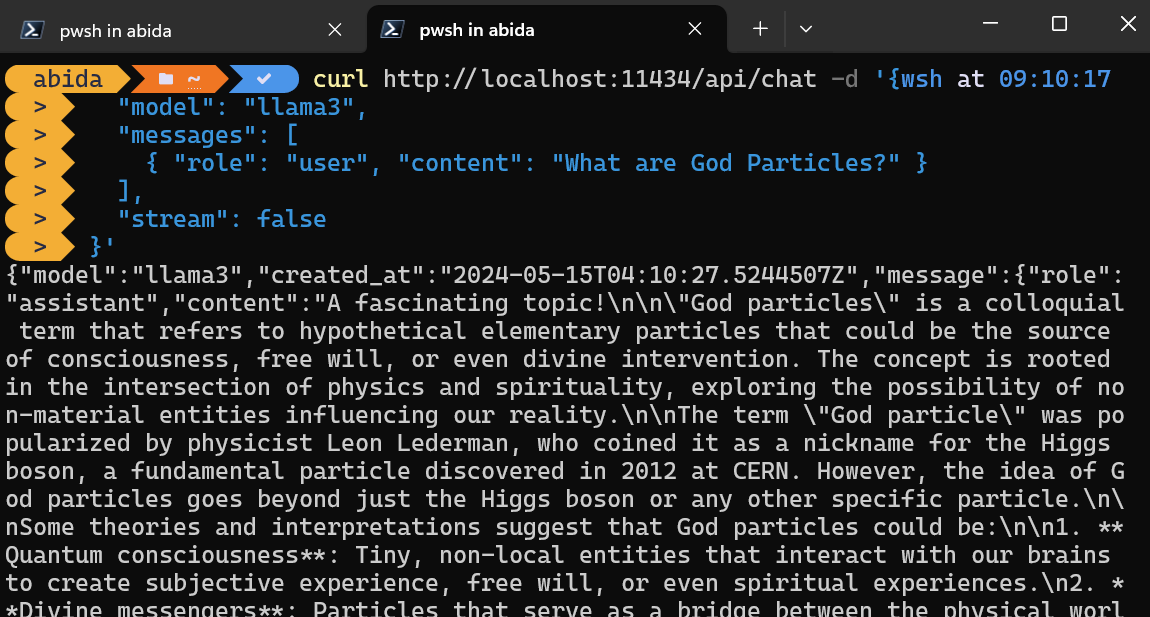
Vous pouvez simplement accéder au serveur d'inférence en utilisant la commande CURL.
Il suffit d'indiquer le nom du modèle et l'invite, et de s'assurer que le streaming est désactivé pour obtenir le message complet.
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "What are God Particles?" }
],
"stream": false
}'La commande CURL est native de Linux, mais vous pouvez également l'utiliser dans Windows PowerShell, comme indiqué ci-dessous.
Vous pouvez également installer le paquetage Python Ollama à l'aide de PIP pour accéder au serveur d'inférence.
pip install ollamaL'accès à l'API en Python vous donne le pouvoir de créer des applications et des outils alimentés par l'IA, et il est super facile à utiliser.
Fournissez simplement aux fonctions `ollama.chat` le nom du modèle et le message, et la réponse sera générée.
Note: Dans l'argument du message, vous pouvez également ajouter une invite système et une invite assistant pour ajouter le contexte.
import ollama
response = ollama.chat(
model="llama3",
messages=[
{
"role": "user",
"content": "Tell me an interesting fact about elephants",
},
],
)
print(response["message"]["content"])
Le package Python d'Ollama propose également des fonctionnalités telles que les appels asynchrones et le streaming, qui permettent de gérer efficacement les demandes d'API et d'augmenter la vitesse perçue du modèle.
À l'instar de l'API OpenAI, vous pouvez créer une fonction de chat asynchrone, puis écrire du code en continu à l'aide de la fonction asynchrone, ce qui permet des interactions efficaces et rapides avec le modèle.
import asyncio
from ollama import AsyncClient
async def chat():
"""
Stream a chat from Llama using the AsyncClient.
"""
message = {
"role": "user",
"content": "Tell me an interesting fact about elephants"
}
async for part in await AsyncClient().chat(
model="llama3", messages=[message], stream=True
):
print(part["message"]["content"], end="", flush=True)
asyncio.run(chat())Comme vous pouvez le voir, le modèle affiche les jetons au fur et à mesure qu'ils sont générés.
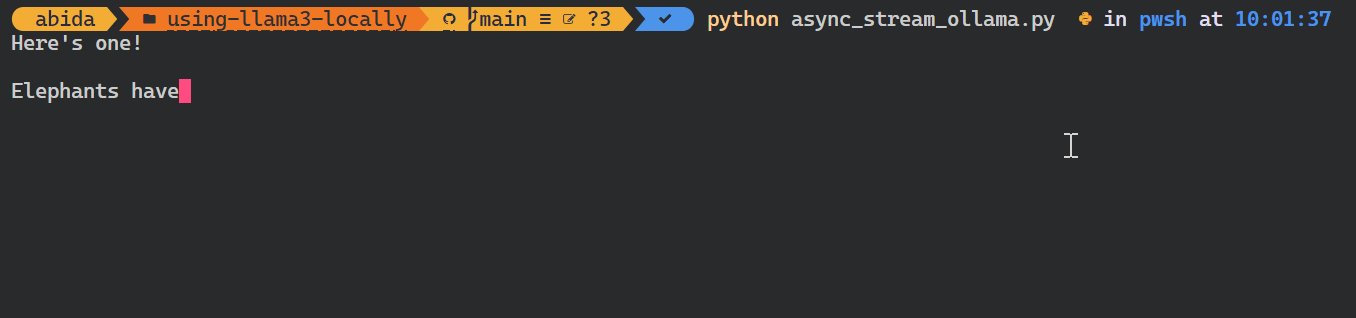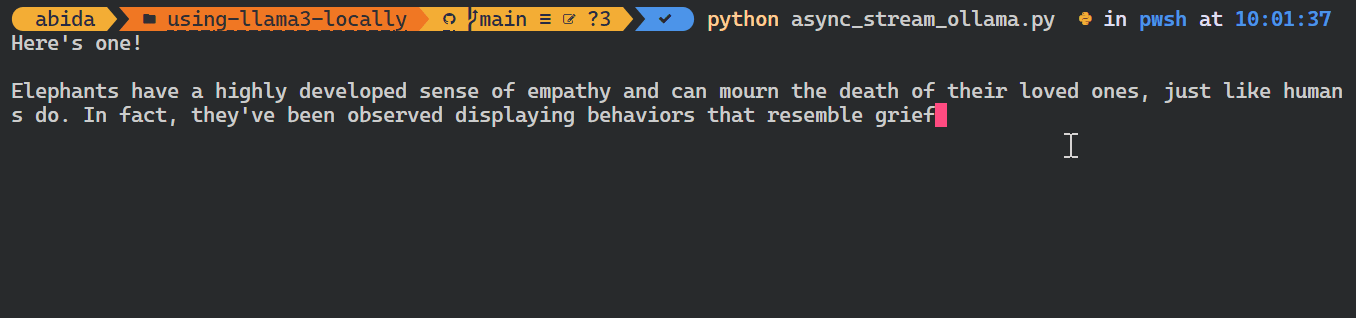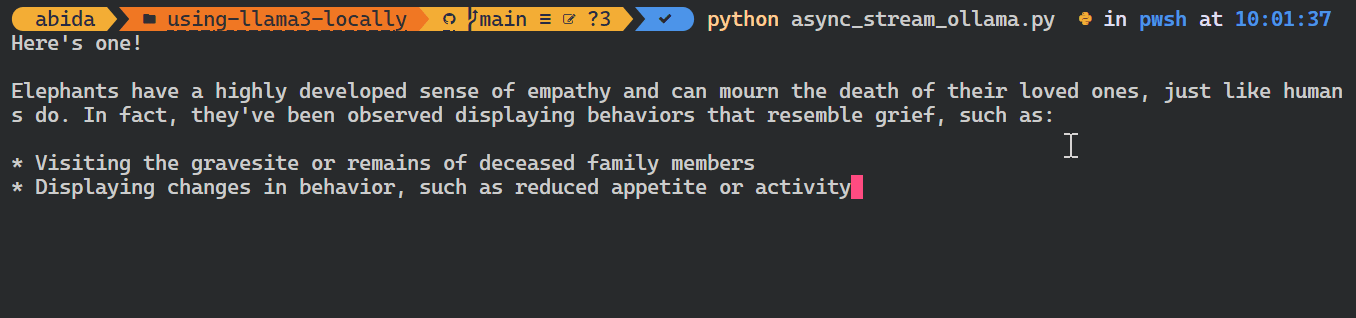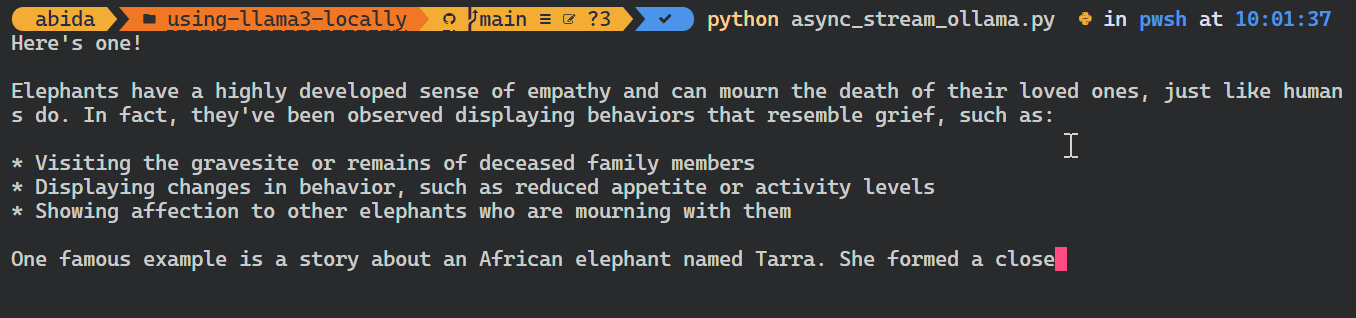
Vous pouvez également utiliser l'API Python pour créer le modèle personnalisé, convertir le texte en embeddings et gérer les erreurs. Vous pouvez également copier, supprimer, tirer et pousser les modèles.
En plus d'utiliser Ollama comme chatbot ou pour générer des réponses, vous pouvez l'intégrer dans VSCode et utiliser Llama 3 pour des fonctionnalités telles que l'autocomplétion, les suggestions de code en fonction du contexte, l'écriture de code, la génération de docstrings, les tests unitaires, et bien plus encore.
1. Tout d'abord, nous devons initialiser le serveur d'inférence Ollama en tapant la commande suivante dans le terminal.
ollama serve2. Allez dans les extensions VSCode, recherchez l'outil "CodeGPT" et installez-le. CodeGPT vous permet de vous connecter à n'importe quel fournisseur de modèle en utilisant la clé API.

3. Configurez le CodeGPT en cliquant sur l'icône de chat CodeGPT dans le panneau de gauche. Changez le fournisseur de modèle pour Ollama et sélectionnez le modèle llama3:8b. Vous n'avez pas besoin de fournir une clé d'API, car nous l'exécutons localement.
4. Écrivez l'invite pour générer le code Python, puis cliquez sur le bouton "Insérer le code" pour transférer le code dans votre fichier Python. Vous pouvez également rédiger des instructions de suivi pour améliorer le code.
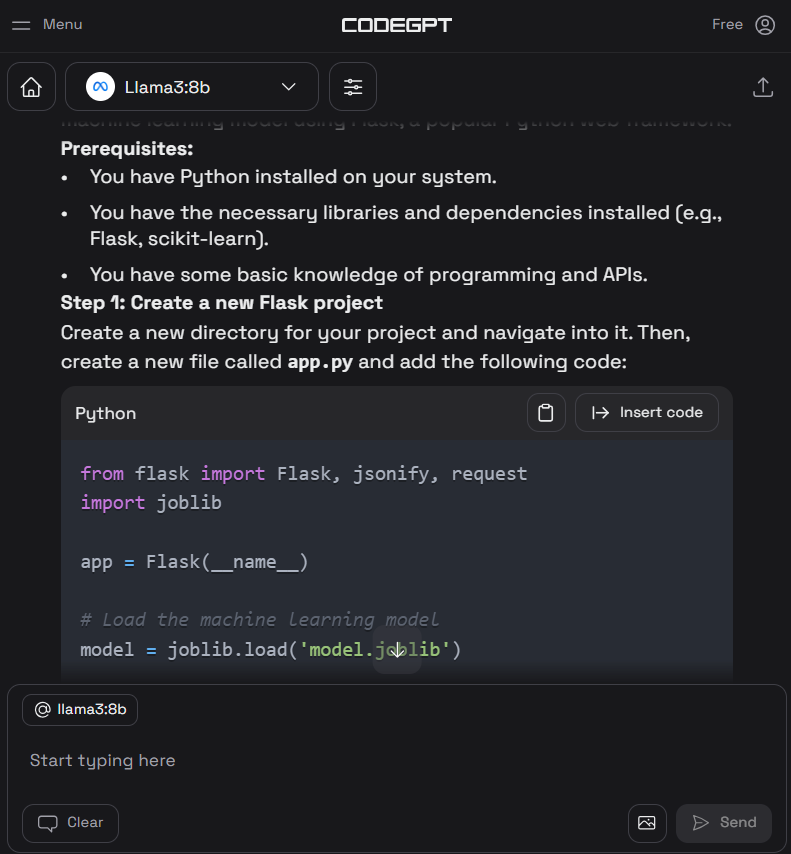
5. Outre l'assistant de codage, vous pouvez utiliser CodeGPT pour comprendre le code, le remanier, le documenter, générer les tests unitaires et résoudre les problèmes.
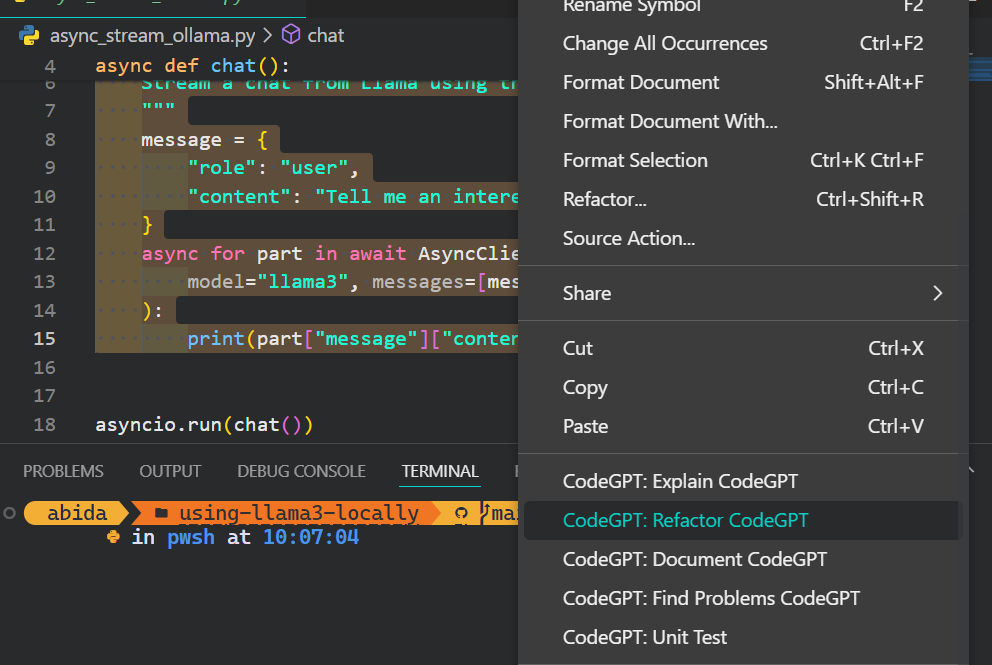
Si vous voulez vous sentir comme un pro de Python, consultez le guide Configuration de VSCode pour Python pour en savoir plus sur la fonctionnalité principale de VSCode et l'adapter à vos besoins.
Dans cette section, nous allons développer une application alimentée par l'IA qui lit les fichiers docx à partir d'un dossier désigné, les convertit en enchâssements et les stocke dans un magasin de vecteurs.
Ensuite, nous utiliserons une recherche par similarité pour retrouver les significations pertinentes et fournir des réponses contextuelles à vos questions.
Cette application vous permettra de comprendre rapidement l'essence des livres et d'approfondir le développement des personnages.
Tout d'abord, nous allons installer tous les paquets Python nécessaires pour charger les documents, le magasin de vecteurs et les cadres LLM.
pip install unstructured[docx] langchain langchainhub langchain_community langchain-chromaDémarrez ensuite le serveur d'inférence Ollama.
ollama serveLa meilleure pratique consiste à développer et à tester votre code dans Jupyter Notebook avant de créer l'application.
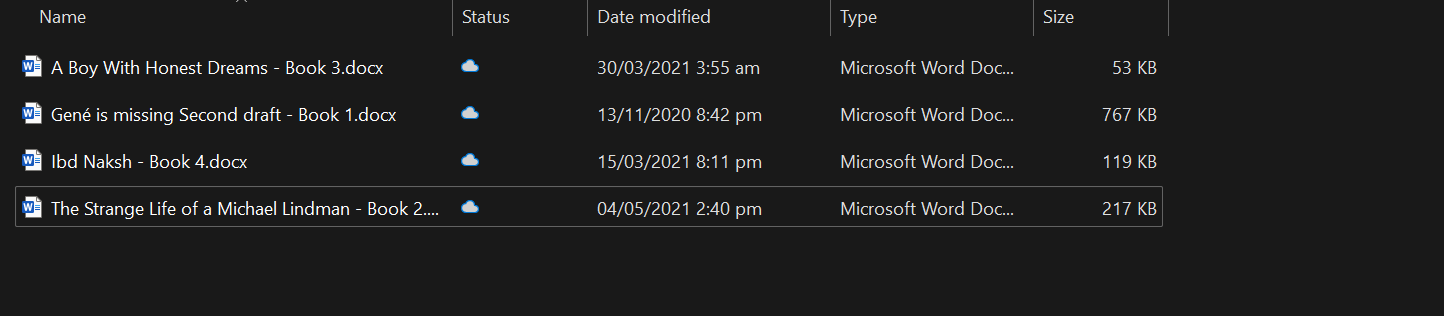
Nous chargerons tous les fichiers docx du dossier à l'aide de la commande DirectoryLoader.
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("C:/Users/abida/Desktop/Books", glob="**/*.docx")
books = loader.load()
len(books)4Vous pouvez créer votre propre chatbot tenant compte du contexte en suivant le tutoriel, Chatbot Development with ChatGPT & LangChain : Une approche contextuelle.
Il n'est pas possible d'alimenter le modèle avec un livre entier, car cela dépasserait sa fenêtre contextuelle. Pour surmonter cette limitation, nous devons diviser le texte en morceaux plus petits et plus faciles à gérer, qui s'intègrent confortablement dans la fenêtre contextuelle du modèle.
Dans notre cas, nous allons convertir les quatre livres en un bloc de 500 caractères.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(books)
Nous utiliserons Langchain pour convertir le texte en embedding et le stocker dans la base de données Chroma.
Nous utilisons le modèle Ollama Llama 3 comme modèle d'intégration.
from langchain_chroma import Chroma
from langchain_community.embeddings import OllamaEmbeddings
vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=OllamaEmbeddings(model="llama3", show_progress=True),
persist_directory="./chroma_db",
)OllamaEmbeddings: 100%|██████████| 23/23 [01:00<00:00, 2.63s/it]Testons notre base de données vectorielles en effectuant quelques recherches de similarités.
question = "Who is Zahra?"
docs = vectorstore.similarity_search(question)
docsNous avons obtenu quatre résultats similaires à la question.

Vous pouvez plonger dans le monde des bases de données vectorielles et de Chroma DB en lisant le tutoriel, Apprenez à utiliser Chroma DB : Un guide étape par étape.
Pour construire un système de recherche de questions-réponses digne de ce nom, nous utiliserons les chaînes de Langchain et commencerons à ajouter les modules.
Dans notre chaîne de questions-réponses, nous allons
En d'autres termes, avant de passer par le modèle Llama 3, votre question sera mise en contexte à l'aide de la recherche de similitudes et de l'invite RAG.
from langchain import hub
from langchain_community.llms import Ollama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
llm = Ollama(model="llama3")
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_prompt = hub.pull("rlm/rag-prompt")
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)Vous pouvez créer une application similaire en utilisant LLamaIndex. Pour ce faire, suivez le site LlamaIndex : Un cadre de données pour les applications basées sur les grands modèles linguistiques (LLM) tutorial.
Posez des questions pertinentes sur les livres pour mieux comprendre l'histoire.
question = "What is the story of the 'Gené is Missing' book?"
qa_chain.invoke(question)Comme nous pouvons le constater, l'utilisation de livres comme contexte permet d'obtenir une réponse précise.
'Based on the provided context, "Gené is Missing" appears to be a mystery novel that revolves around uncovering the truth about Gené\'s life and potential involvement in murders. The story follows different perspectives, including Simon trying to prove his innocence, flashbacks of Gené\'s past, and detective Jacob investigating the case.'Posons maintenant une question sur le personnage.
question = "Who is Arslan?"
qa_chain.invoke(question)Une réponse précise a été générée.
'Arslan is Zahra\'s brother\'s best friend. He is someone that Zahra visits in the book "A Boy with Honest Dreams" by Abid Ali Awan to gather information about Ali.'Pour construire une application d'IA à part entière qui s'exécute de manière transparente dans votre terminal, nous allons combiner tout le code des sections précédentes dans un seul fichier Python.
code AI_app.pyEn outre, nous améliorerons le code pour permettre une interrogation interactive, ce qui vous permettra de poser des questions à l'application de manière répétée jusqu'à ce que vous mettiez explicitement fin à la session en tapant "exit".
from langchain_chroma import Chroma
from langchain_community.embeddings import OllamaEmbeddings
from langchain import hub
from langchain_community.llms import Ollama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# loading the vectorstore
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=OllamaEmbeddings(model="llama3"))
# loading the Llama3 model
llm = Ollama(model="llama3")
# using the vectorstore as the retriever
retriever = vectorstore.as_retriever()
# formating the docs
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# loading the QA chain from langchain hub
rag_prompt = hub.pull("rlm/rag-prompt")
# creating the QA chain
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# running the QA chain in a loop until the user types "exit"
while True:
question = input("Question: ")
if question.lower() == "exit":
break
answer = qa_chain.invoke(question)
print(f"\nAnswer: {answer}\n")
Exécutez l'application en écrivant `Python` et le nom du fichier dans le terminal.
python AI_app.pyC'est génial. Nous avons créé notre propre application RAG AI localement avec quelques lignes de code.
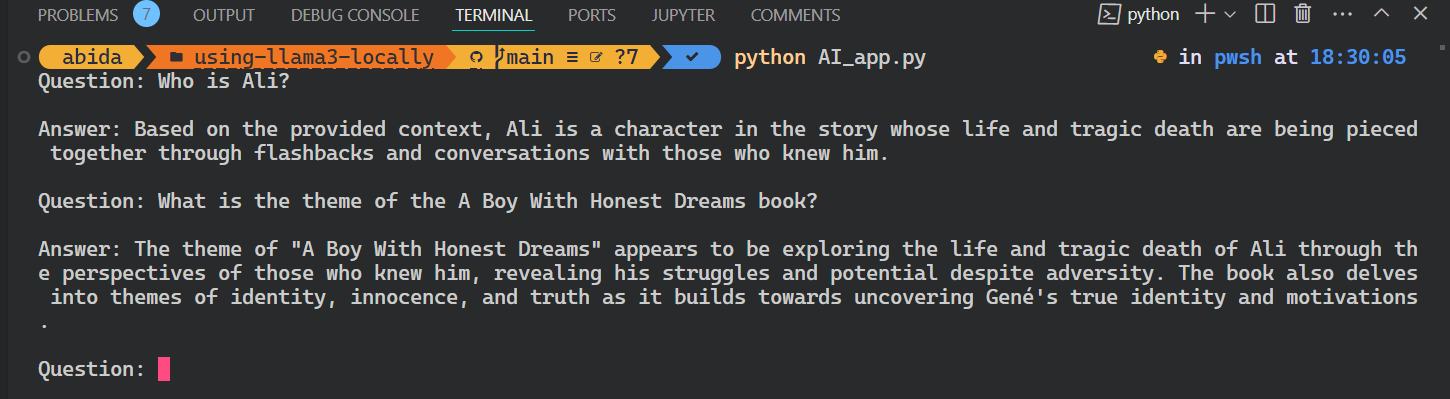
Tout le code source de ce tutoriel est disponible sur le dépôt GitHub kingabzpro/using-llama3-locally. Jetez-y un coup d'œil et n'oubliez pas d'ajouter une étoile ⭐ au dépôt.
Dans ce tutoriel, nous avons appris à utiliser Llama 3 localement sur un ordinateur portable. Nous avons également appris à connaître le serveur d'inférence et à l'utiliser pour intégrer Llama 3 dans VSCode.
Finalement, nous avons construit le système de recherche de questions-réponses en utilisant Langchain, Chroma et Ollama. Les données ne quittent jamais le système local et vous n'avez même pas eu à débourser un seul dollar pour le construire. Outre les applications les plus simples, vous pouvez construire des systèmes complexes à l'aide des mêmes outils que ceux que nous avons utilisés dans ce tutoriel.
Pour en savoir plus, je vous recommande ces tutoriels :
Apprenez l'IA avec DataCamp !
Cursus
Cursus
Cours