
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
Executar o Llama 3 localmente pode parecer assustador devido aos altos requisitos de RAM, GPU e capacidade de processamento. No entanto, os avanços em estruturas e otimização de modelos tornaram isso mais acessível do que nunca. Veja por que você deve considerar essa possibilidade:
Leia nosso artigo, Os prós e contras de usar modelos de linguagem grandes (LLMs) na nuvem versus modelos de linguagem grandes (LLMs) na nuvem. Executando LLMs localmente, para saber mais sobre se o uso de LLMs localmente é adequado para você.
O GPT4ALL é um software de código aberto que permite que você execute modelos de linguagem grandes e populares em seu computador local, mesmo sem uma GPU. Ele é fácil de usar, o que o torna acessível a pessoas com formação não técnica.
Começaremos fazendo o download e a instalação do GPT4ALL no Windows, acessando a página oficial de download.
Depois de instalar o aplicativo, inicie-o e clique no botão "Downloads" para abrir o menu de modelos. Lá, você pode rolar a tela para baixo e selecionar o modelo "Llama 3 Instruct" e, em seguida, clicar no botão "Download".
Após a conclusão do download, feche a guia e selecione o modelo Llama 3 Instruct clicando no menu suspenso "Choose a model" (Escolha um modelo).
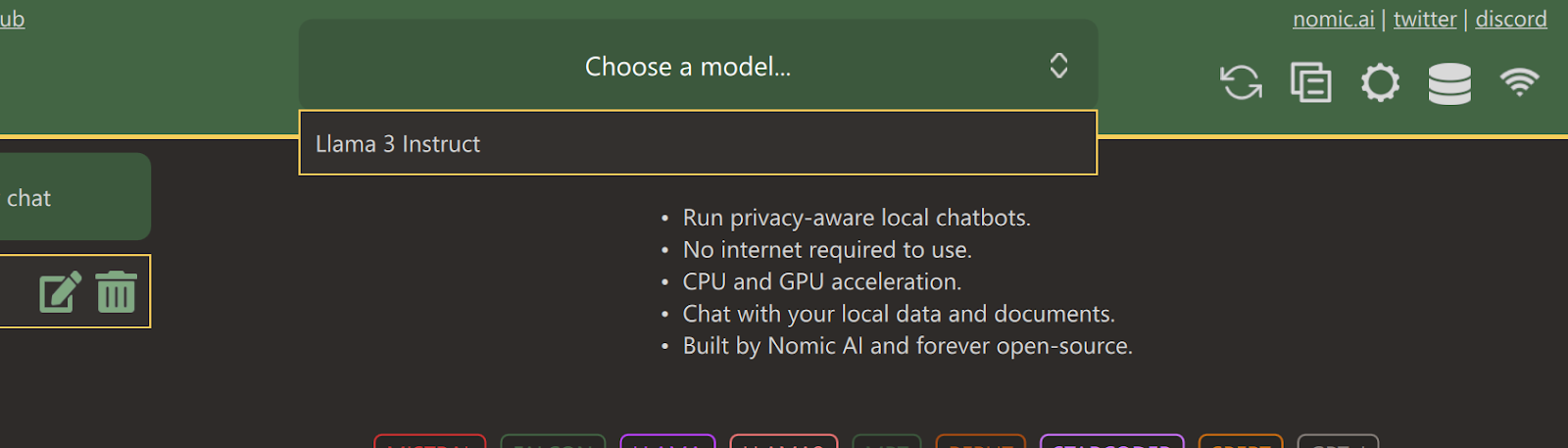
Digite um prompt e comece a usá-lo como o ChatGPT. O sistema tem o kit de ferramentas CUDA instalado, portanto, ele usa a GPU para gerar uma resposta mais rápida.
Agora, vamos tentar a maneira mais fácil de usar o Llama 3 localmente, baixando e instalando o Ollama.
O Ollama é uma ferramenta avançada que permite que você use LLMs localmente. Ele é rápido e vem com muitos recursos.
Depois de instalar o Ollama em seu sistema, abra o terminal/PowerShell e digite o comando.
ollama run llama3Observação: O download do arquivo de modelo e a inicialização do chatbot no terminal levarão alguns minutos.
Escreva prompts ou comece a fazer perguntas, e o Ollama gerará a resposta dentro do seu terminal. A resposta do bate-papo é super rápida e você pode continuar fazendo perguntas de acompanhamento para se aprofundar no assunto.
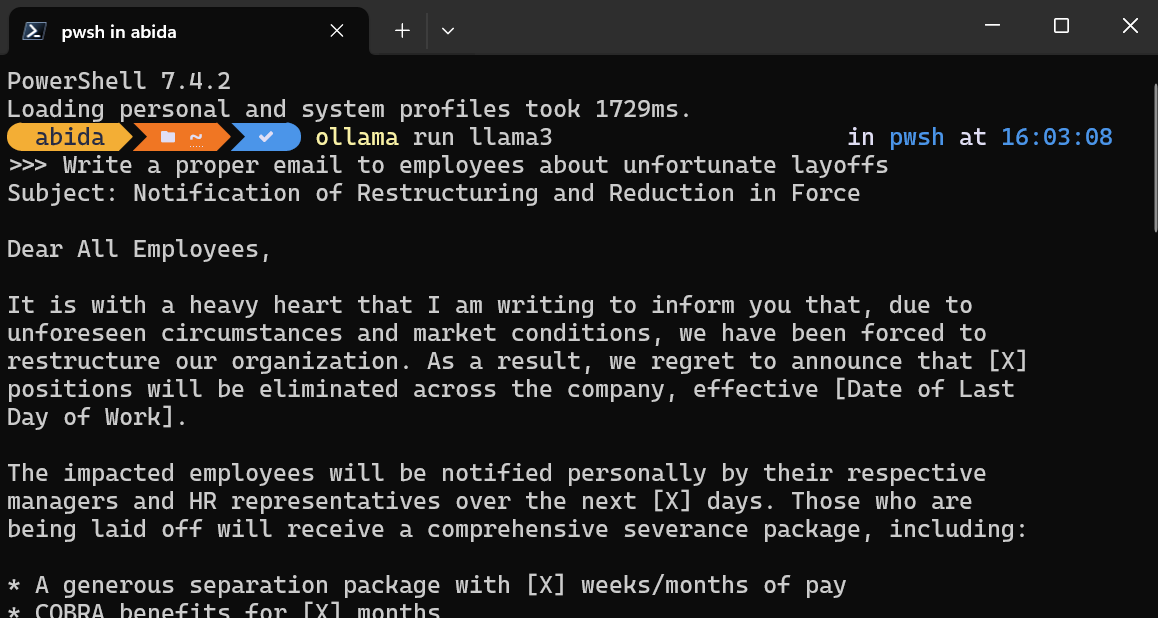
Para sair do chatbot, basta digitar /bye .
Além desses dois softwares, você pode consultar o site Run LLMs Locally: 7 Simple Methods guia para você explorar aplicativos e estruturas adicionais.
A execução de um servidor local permite que você integre o Llama 3 a outros aplicativos e crie seu próprio aplicativo para tarefas específicas.
Inicie o servidor de inferência de modelo local digitando o seguinte comando no terminal.
ollama servePara verificar se o servidor está funcionando corretamente, vá até a bandeja do sistema, localize o ícone do Ollama e clique com o botão direito do mouse para visualizar os registros.
Isso o levará à pasta Ollama, onde você poderá abrir o arquivo `server.log` para visualizar informações sobre solicitações do servidor por meio de APIs e informações do servidor com registros de data e hora.
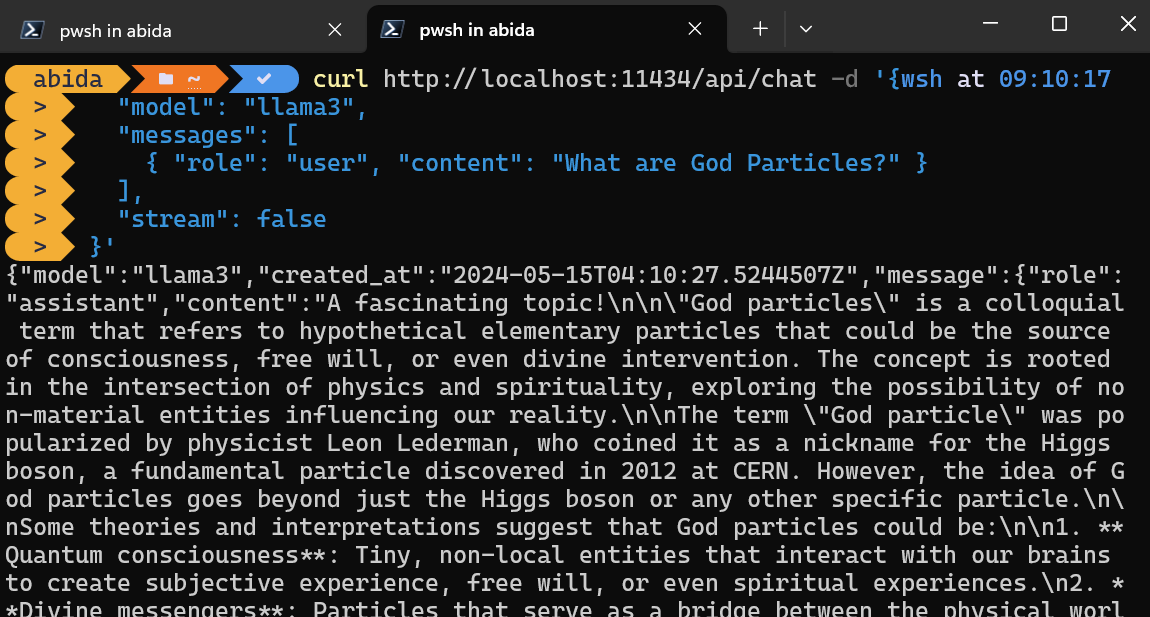
Você pode simplesmente acessar o servidor de inferência usando o comando CURL.
Basta fornecer o nome do modelo e o prompt e certificar-se de que o streaming esteja desativado para que você receba a mensagem completa.
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "What are God Particles?" }
],
"stream": false
}'O comando CURL é nativo do Linux, mas você também pode usá-lo no Windows PowerShell, conforme mostrado abaixo.
Você também pode instalar o pacote Ollama Python usando o PIP para acessar o servidor de inferência.
pip install ollamaO acesso à API em Python permite que você crie aplicativos e ferramentas com tecnologia de IA, e é muito fácil de usar.
Basta que você forneça às funções `ollama.chat` o nome do modelo e a mensagem, e ele gerará a resposta.
Observação: No argumento da mensagem, você também pode adicionar um prompt do sistema e um prompt do assistente para adicionar o contexto.
import ollama
response = ollama.chat(
model="llama3",
messages=[
{
"role": "user",
"content": "Tell me an interesting fact about elephants",
},
],
)
print(response["message"]["content"])
O pacote Ollama Python também fornece recursos como chamadas assíncronas e streaming, que permitem o gerenciamento eficaz das solicitações de API e aumentam a velocidade percebida do modelo.
Semelhante à API OpenAI, você pode criar uma função de bate-papo assíncrona e, em seguida, escrever código de streaming usando a função assíncrona, permitindo interações eficientes e rápidas com o modelo.
import asyncio
from ollama import AsyncClient
async def chat():
"""
Stream a chat from Llama using the AsyncClient.
"""
message = {
"role": "user",
"content": "Tell me an interesting fact about elephants"
}
async for part in await AsyncClient().chat(
model="llama3", messages=[message], stream=True
):
print(part["message"]["content"], end="", flush=True)
asyncio.run(chat())Como você pode ver, o modelo exibe os tokens à medida que eles são gerados.
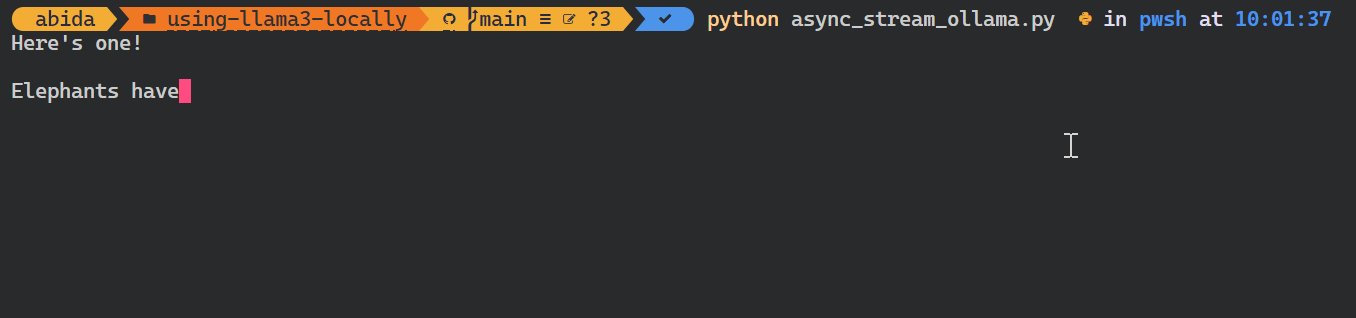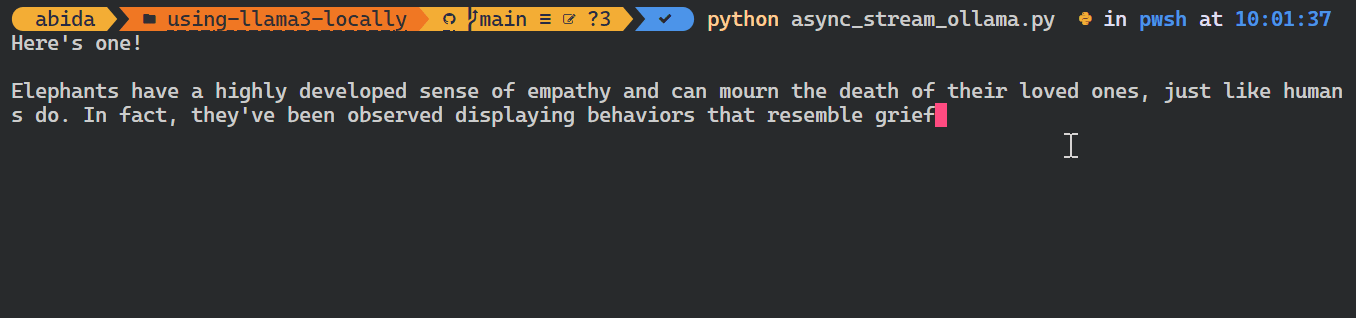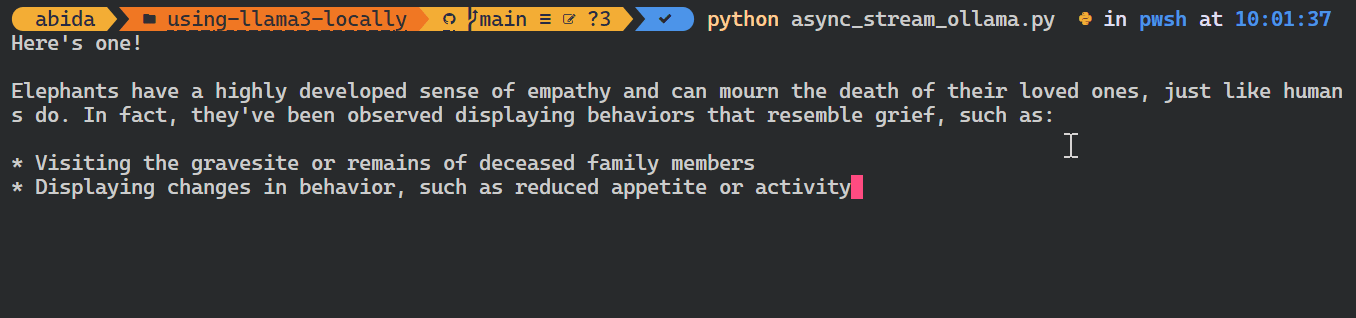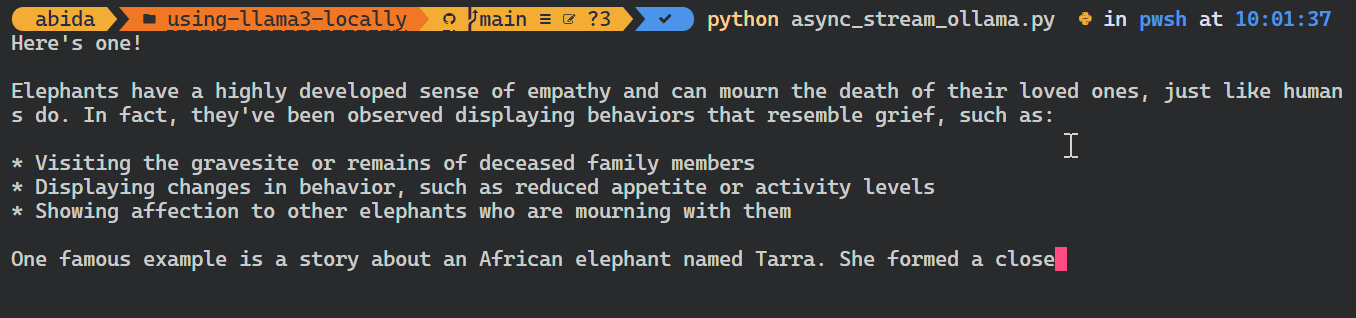
Você também pode usar a API do Python para criar o modelo personalizado, converter texto em embeddings e tratar erros. Você também pode copiar, excluir, puxar e empurrar os modelos.
Além de usar o Ollama como um chatbot ou para gerar respostas, você pode integrá-lo ao VSCode e usar o Llama 3 para recursos como autocompletar, sugestões de código com reconhecimento de contexto, escrita de código, geração de docstrings, teste de unidade e muito mais.
1. Primeiro, temos que inicializar o servidor de inferência Ollama digitando o seguinte comando no terminal.
ollama serve2. Acesse as extensões do VSCode, procure a ferramenta "CodeGPT" e instale-a. O CodeGPT permite que você conecte qualquer provedor de modelo usando a chave da API.

3. Configure o CodeGPT clicando no ícone de bate-papo do CodeGPT no painel esquerdo. Altere o provedor do modelo para Ollama e selecione o modelo llama3:8b. Você não precisa fornecer uma chave de API, pois estamos executando-a localmente.
4. Escreva o prompt para gerar o código Python e, em seguida, clique no botão "Insert the code" (Inserir o código) para transferir o código para seu arquivo Python. Você também pode escrever instruções de acompanhamento para melhorar o código.
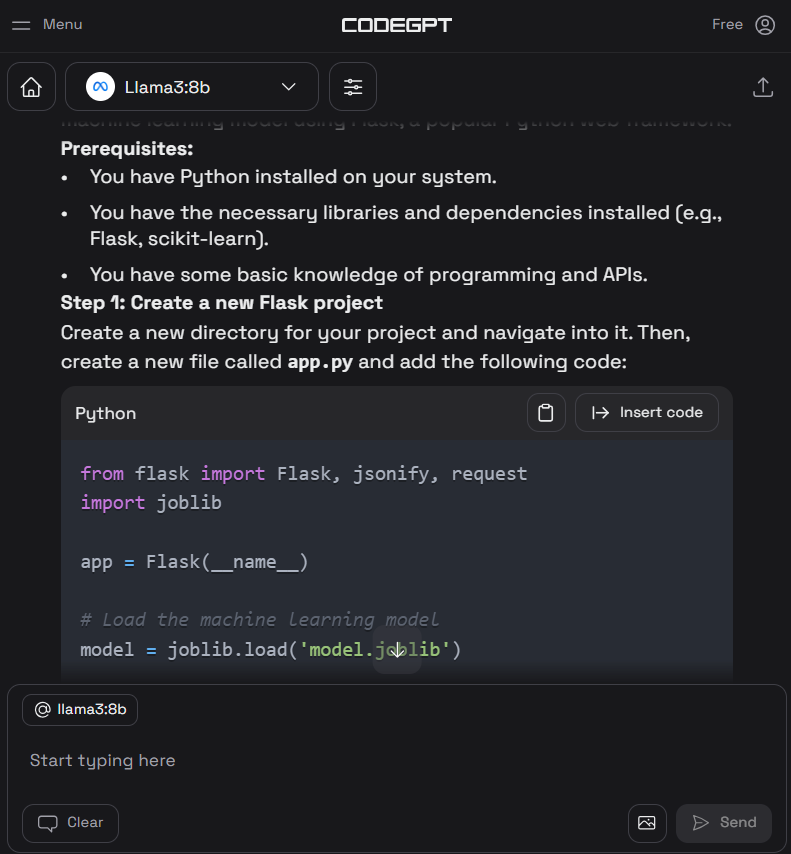
5. Além do assistente de codificação, você pode usar o CodeGPT para entender o código, refatorá-lo, documentá-lo, gerar o teste de unidade e resolver os problemas.
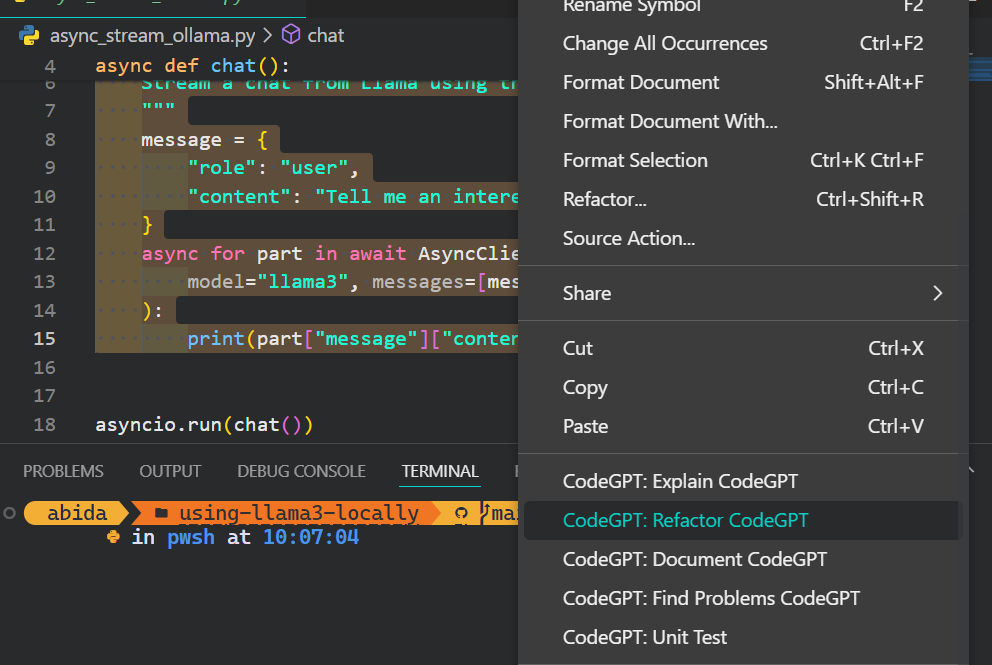
Se você quiser se sentir como um profissional em Python, consulte o guia Configurando o VSCode para Python para saber mais sobre o recurso principal do VSCode e personalizá-lo de acordo com suas necessidades.
Nesta seção, desenvolveremos um aplicativo com tecnologia de IA que lê arquivos docx de uma pasta designada, converte-os em embeddings e os armazena em um repositório de vetores.
Depois disso, usaremos uma pesquisa de similaridade para recuperar significados relevantes e fornecer respostas contextuais às suas perguntas.
Esse aplicativo permitirá que você compreenda rapidamente a essência dos livros e se aprofunde no desenvolvimento dos personagens.
Primeiro, instalaremos todos os pacotes Python necessários para carregar os documentos, o armazenamento de vetores e as estruturas LLM.
pip install unstructured[docx] langchain langchainhub langchain_community langchain-chromaEm seguida, inicie o servidor de inferência Ollama.
ollama serveÉ uma prática recomendada desenvolver e testar seu código no Jupyter Notebook antes de criar o aplicativo.
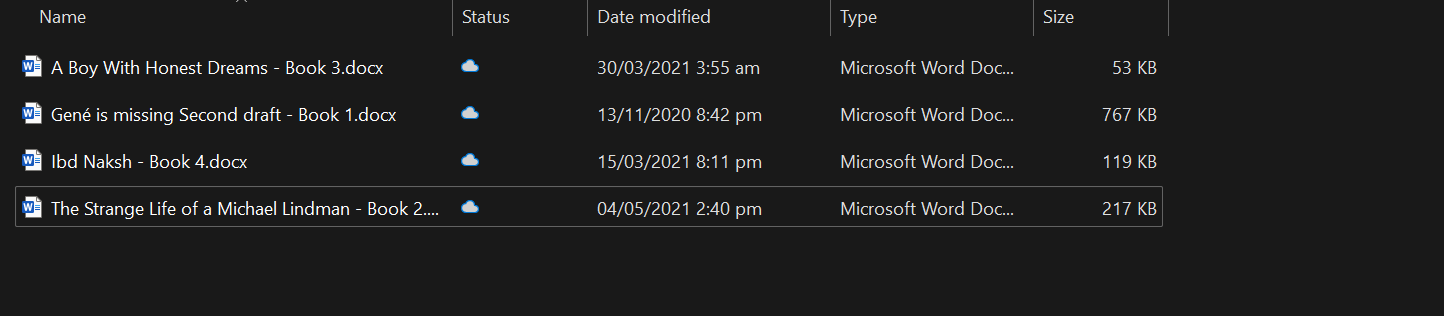
Carregaremos todos os arquivos docx da pasta usando o endereço DirectoryLoader.
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("C:/Users/abida/Desktop/Books", glob="**/*.docx")
books = loader.load()
len(books)4Você pode criar seu próprio chatbot com reconhecimento de contexto seguindo o tutorial, Chatbot Development with ChatGPT & LangChain: Uma abordagem com reconhecimento de contexto.
Não é possível alimentar o modelo com um livro inteiro, pois isso ultrapassaria sua janela de contexto. Para superar essa limitação, precisamos dividir o texto em partes menores e mais gerenciáveis que se encaixem confortavelmente na janela de contexto do modelo.
No nosso caso, converteremos todos os quatro livros em um tamanho de bloco de 500 caracteres.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(books)
Usaremos o Langchain para converter o texto em incorporação e armazená-lo no banco de dados do Chroma.
Estamos usando o modelo Ollama Llama 3 como um modelo de incorporação.
from langchain_chroma import Chroma
from langchain_community.embeddings import OllamaEmbeddings
vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=OllamaEmbeddings(model="llama3", show_progress=True),
persist_directory="./chroma_db",
)OllamaEmbeddings: 100%|██████████| 23/23 [01:00<00:00, 2.63s/it]Vamos testar nosso banco de dados de vetores realizando algumas pesquisas de similaridade.
question = "Who is Zahra?"
docs = vectorstore.similarity_search(question)
docsObtivemos quatro resultados que são semelhantes à pergunta.

Você pode se aprofundar no mundo do banco de dados vetorial e do Chroma DB lendo o tutorial . Aprenda a usar o Chroma DB: Um guia passo a passo.
Para criar um sistema adequado de recuperação de perguntas e respostas, usaremos cadeias Langchain e começaremos a adicionar os módulos.
Em nossa cadeia de perguntas e respostas, vamos
Simplificando, antes de passá-la pelo modelo Llama 3, sua pergunta será contextualizada usando a pesquisa de similaridade e o prompt RAG.
from langchain import hub
from langchain_community.llms import Ollama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
llm = Ollama(model="llama3")
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_prompt = hub.pull("rlm/rag-prompt")
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)Você pode criar um aplicativo semelhante usando o LLamaIndex. Para fazer isso, siga o endereço LlamaIndex: Uma estrutura de dados para os aplicativos baseados em modelos de linguagem grandes (LLMs) tutorial.
Faça perguntas relevantes sobre os livros para entender mais sobre a história.
question = "What is the story of the 'Gené is Missing' book?"
qa_chain.invoke(question)Como podemos ver, o uso de livros como contexto fornece uma resposta precisa.
'Based on the provided context, "Gené is Missing" appears to be a mystery novel that revolves around uncovering the truth about Gené\'s life and potential involvement in murders. The story follows different perspectives, including Simon trying to prove his innocence, flashbacks of Gené\'s past, and detective Jacob investigating the case.'Vamos agora fazer uma pergunta sobre o personagem.
question = "Who is Arslan?"
qa_chain.invoke(question)Foi gerada uma resposta precisa.
'Arslan is Zahra\'s brother\'s best friend. He is someone that Zahra visits in the book "A Boy with Honest Dreams" by Abid Ali Awan to gather information about Ali.'Para criar um aplicativo de IA completo que seja executado sem problemas no seu terminal, combinaremos todo o código das seções anteriores em um único arquivo Python.
code AI_app.pyAlém disso, aprimoraremos o código para habilitar a consulta interativa, permitindo que você faça perguntas ao aplicativo repetidamente até encerrar explicitamente a sessão digitando 'exit'.
from langchain_chroma import Chroma
from langchain_community.embeddings import OllamaEmbeddings
from langchain import hub
from langchain_community.llms import Ollama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# loading the vectorstore
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=OllamaEmbeddings(model="llama3"))
# loading the Llama3 model
llm = Ollama(model="llama3")
# using the vectorstore as the retriever
retriever = vectorstore.as_retriever()
# formating the docs
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# loading the QA chain from langchain hub
rag_prompt = hub.pull("rlm/rag-prompt")
# creating the QA chain
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# running the QA chain in a loop until the user types "exit"
while True:
question = input("Question: ")
if question.lower() == "exit":
break
answer = qa_chain.invoke(question)
print(f"\nAnswer: {answer}\n")
Execute o aplicativo escrevendo `Python` e o nome do arquivo no terminal.
python AI_app.pyIsso é legal. Criamos nosso próprio aplicativo RAG AI localmente com poucas linhas de código.
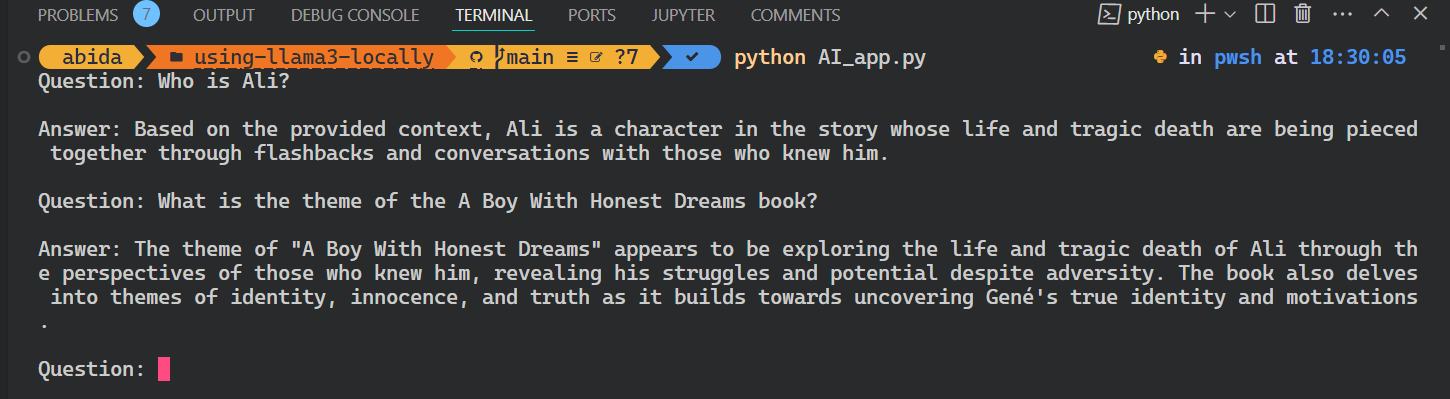
Todo o código-fonte deste tutorial está disponível no repositório do GitHub kingabzpro/using-llama3-locally. Dê uma olhada e lembre-se de marcar com uma estrela o repositório.
Neste tutorial, aprendemos a usar o Llama 3 localmente em um laptop. Também aprendemos sobre o servidor de inferência e como podemos usá-lo para integrar o Llama 3 ao VSCode.
Por fim, criamos o sistema de recuperação de perguntas e respostas usando Langchain, Chroma e Ollama. Os dados nunca saíram do sistema local, e você nem precisou pagar um único dólar para construí-lo. Além dos aplicativos mais simples, você pode criar sistemas complexos usando as mesmas ferramentas que usamos neste tutorial.
Para saber mais, recomendo estes tutoriais:
Aprenda IA com a DataCamp!
Programa
Programa
Curso
blog
Abid Ali Awan
9 min
Tutorial
Ryan Ong
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita




